RT-DETRv4:利用视觉基础模型轻松推进实时目标检测
论文信息
| 项目 | 内容 |
|---|---|
| 论文标题 | RT-DETRv4: Painlessly Furthering Real-Time Object Detection with Vision Foundation Models |
| 作者 | Zijun Liao, Yian Zhao, Xin Shan, Yu Yan, Chang Liu, Lei Lu, Xiangyang Ji, Jie Chen |
| 所属机构 | 1. 北京大学深圳研究生院电子与计算机工程学院 2. 清华大学自动化系及BNRist |
| 论文地址 | https://arxiv.org/abs/2510.25257 |
| 开源状态 | 作者在论文中提及“代码和模型很快会开源” |
| 核心创新 | 提出一种仅用于训练的蒸馏框架,通过深度语义注入器(DSI) 和梯度引导的自适应调制(GAM),将视觉基础模型(VFM)的语义知识迁移到实时检测器中,且不增加推理成本 。 |
| 性能指标 | 在COCO数据集上取得SOTA性能: • RT-DETRv4-X: 57.0 AP @ 78 FPS • RT-DETRv4-L: 55.4 AP @ 124 FPS • RT-DETRv4-M: 53.5 AP @ 169 FPS • RT-DETRv4-S: 49.7 AP @ 273 FPS |
摘要
实时目标检测通过精心设计的架构和优化策略取得了实质性进展。然而,通过轻量级网络设计追求高速推理通常会导致特征表示退化,这阻碍了性能的进一步提升和实际的端侧部署。在本文中,我们提出了一种成本效益高且高度适应的蒸馏框架,该框架利用快速发展的视觉基础模型(VFMs)的能力来增强轻量级目标检测器。鉴于VFM与资源受限检测器之间存在显著的架构和学习目标差异,实现稳定且任务对齐的语义传递具有挑战性。为了解决这个问题,一方面,我们引入了深度语义注入器(DSI)模块,以促进将VFM的高级表示集成到检测器的深层中。另一方面,我们设计了一种梯度引导的自适应调制(GAM)策略,该策略基于梯度范数比率动态调整语义传递的强度。在不增加部署和推理开销的情况下,我们的方法轻松地为基于DETR的各种模型带来了显著且一致的性能提升,突显了其在实时检测中的实际效用。我们的新模型系列RT-DETRv4在COCO上取得了最先进的结果,在相应速度为273/169/124/78 FPS时,达到了49.7/53.5/55.4/57.0的AP分数。
1. 引言
实时目标检测是计算机视觉中的一项基本任务,它支撑着许多需要即时感知和决策的交互式和安全关键型应用,例如自动驾驶[5]、具身智能[21]和人机交互[16]。
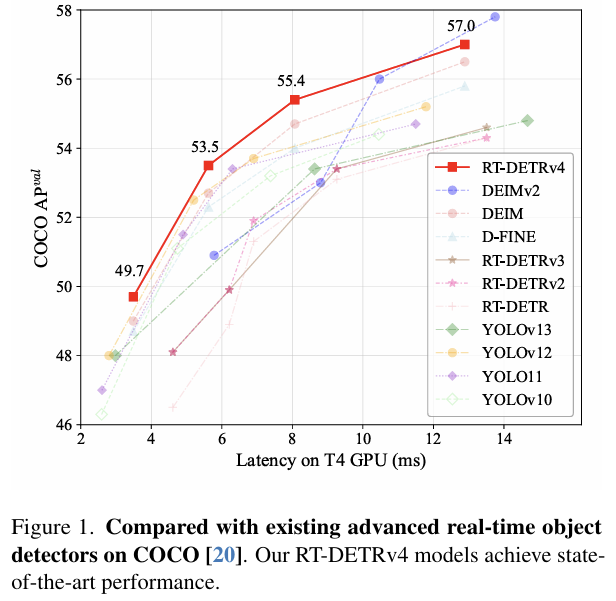
在过去的十年中,通过日益高效的网络架构和端到端学习框架,取得了显著的进展。特别是,两个代表性系列YOLO[30]和DETR[3]深刻影响了目标检测范式的演变。YOLO系列强调快速的单阶段检测,实现了高推理速度和实际部署效率;而DETR系列通过统一建模对象查询和基于集合的预测,重塑了检测范式。在其变体中,RT-DETR [38] 标志着第一个实时DETR的里程碑,通过在速度和精度上都超越YOLO模型,将DETR家族引入了实时社区。
尽管取得了显著进展,但一个长期存在的挑战依然存在:设计轻量级模型以实现高推理速度与采用复杂架构以改进特征表示之间的内在权衡。
为了满足实时约束,检测器通常采用轻量级主干网络和精心设计的计算模块,这不可避免地降低了它们捕获高级语义的能力,并导致语义瓶颈。这种限制不仅阻碍了性能的进一步提升,也增加了实际端侧部署的难度。
在本文中,受视觉基础模型(VFMs)[13, 31]快速发展的启发,我们提出了一种成本效益高且高度适应的蒸馏框架,该框架利用VFM强大的表示能力来增强轻量级目标检测器。通过在训练期间将VFM的丰富语义转移到实时检测器中,同时在推理期间保持检测器架构不变,我们的方法能够在不引入任何额外推理或部署成本的情况下实现显著增强。这一优势对于实际的实时检测应用尤为重要。
然而,由于VFM与资源受限检测器之间存在巨大的架构和学习目标差异,实现稳定且任务对齐的语义传递具有挑战性。为了解决这个问题,我们首先引入了深度语义注入器(DSI)模块,该模块能够将VFM的高级表示集成到检测器的深层中。为了确保稳定和高效的优化,我们进一步设计了梯度引导的自适应调制(GAM)策略,该策略基于梯度范数比率动态调整语义注入的强度,从而协调语义传递和检测目标的学习。
大量实验证明,所提出的框架在不增加推理或部署开销的情况下,对先进的基于DETR的检测器实现了一致且显著的性能改进,突显了其有效性。总之,我们的主要贡献如下:
- 我们提出了一种成本效益高且高度适应的蒸馏框架,该框架利用VFM不断发展的能力来轻松增强实时检测器,为将基础级语义转移到轻量级架构提供了一条可扩展的途径。
- 我们提出了深度语义注入器(DSI)和梯度引导的自适应调制(GAM),它们能够在具有显著不同架构和学习目标的VFM和检测器之间实现稳定且任务对齐的语义传递。
- 我们建立了一个新的模型系列RT-DETRv4-S/M/L/X,在COCO [20]数据集上达到了49.7/53.5/55.4/57.0的AP分数,速度分别为273/169/124/78 FPS,在COCO数据集上设立了新的SOTA。
2. 相关工作
2.1. 实时目标检测
实时目标检测的发展长期以来一直由YOLO(You Only Look Once)系列[30]驱动,该系列通过高效统一的检测流程普及了单阶段范式。在过去的几年里,这一系列经历了快速的迭代,在主干设计、标签分配和优化策略方面引入了持续的改进[2, 9, 10,18, 28,29,34, 35]。最近的几代甚至进一步扩展了设计空间:YOLOv10 [33] 消除了YOLO系列长期依赖的NMS,YOLO11[11] 改进了架构层次和颈部连接,YOLOv12 [32] 结合了注意力机制以进行更好的上下文推理,YOLOv13[17] 探索了超图表示以捕获高阶特征依赖性。这些进展推动了卷积和混合架构的性能-效率前沿,逐渐缩小了实时检测器与高精度检测器之间的差距。
与此同时,另一条研究路线围绕DEtection TRansformer(DETR)[3]发展,它将目标检测重新定义为集合预测问题,并消除了手工设计的组件,如锚点设计和NMS。这种基于Transformer的范式激发了许多变体,包括Deformable DETR[39]、Conditional DETR[24]和DAB-DETR [22],它们专注于改进收敛和定位精度。后来的工作,如DN-DETR[19]、DINO[37]和Group-DETR[6],引入了去噪目标和分组监督,以进一步提高训练稳定性和表示质量。
在此基础上,RT-DETR[38]建立了第一个实时端到端Transformer检测器,其性能达到并有时超过了同期的YOLO模型。后续工作继续改进其训练效率和表示学习,而不产生推理开销。例如,RT-DETRv2[23]和RT-DETRv3[36]引入了辅助监督以增强梯度流,D-FINE [26]采用自蒸馏来细化语义表示,DEIM[15]引入了密集匹配以实现更精确的特征对齐。总的来说,这些发展说明了一个明显的趋势:随着架构效率趋于饱和,训练监督和语义表示成为进一步进展的主要杠杆。我们的工作基于这一见解,通过深度语义传递来加强核心表示,在不增加额外部署或推理成本的情况下实现更高的精度。
2.2. 视觉基础模型
视觉基础模型(VFMs)已成为从大规模图像语料库中以最少或无需人工监督学习通用视觉表征的主导范式。
早期的进展源于自监督和弱监督学习方法,这些方法使得模型能够从未标记或松散标记的数据中捕获高级语义。代表性方法包括对比学习框架,如SimCLR [7]和MoCo [12],它们通过强制同一图像的不同增强视图之间的一致性,同时与其他图像形成对比来学习区分性特征。CLIP[27]进一步将这一思想扩展到大规模图像-文本对比训练,对齐视觉和语言嵌入,并在多样化的任务上展示了强大的零样本可迁移性。
受NLP中掩码语言建模的启发,掩码图像建模(MIM)方法被引入来重建被掩码的图像区域,从而学习上下文感知和整体表示。值得注意的方法包括MAE[13]和BEiT[1]。基于这些进展,DINO系列[4, 25,31]集成了对比、基于重建和自蒸馏目标,以产生高度语义化和可迁移的特征。特别是,DINOv3 [31]展示了大规模自监督学习的可扩展性和有效性,无需人工标注即可获得丰富且鲁棒的表征。
3. 方法
3.1. 概览
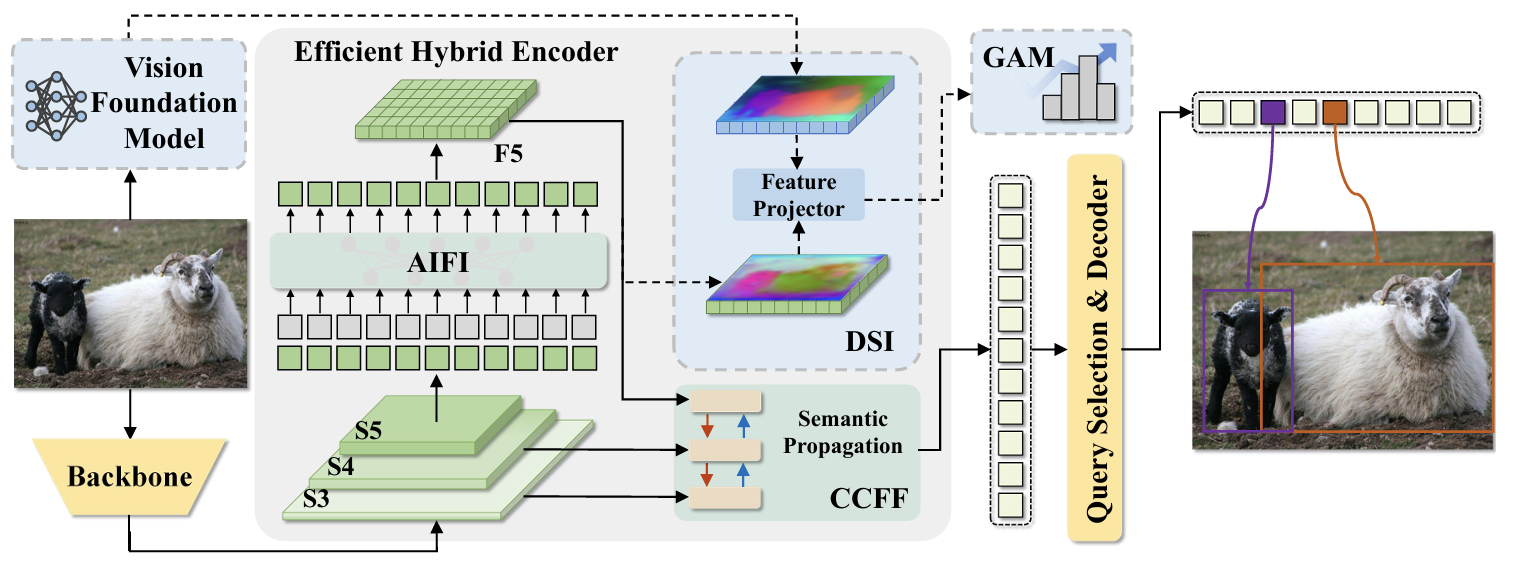
在这项工作中,我们专注于将我们的框架应用于基于DETR的实时目标检测器,即RT-DETR模型[38]。我们方法的整体框架如图2所示,其中提出的模块以蓝色突出显示。
预备知识。我们的模型建立在RT-DETR架构之上,特别是其高效的混合编码器,如整体框架所示。编码器处理从CNN主干提取的多尺度特征图(S3, S4, S5)(S_{3},\,S_{4},\,S_{5})(S3,S4,S5)。它包含两个主要组件:
- 基于注意力的尺度内特征交互(AIFI):为了保持计算效率,自注意力仅应用于最高层级的特征图S5 ∈S_{5}~\inS5 ∈ RH/32×W/32×C\mathbb{R}^{H/32\times W/32\times C}RH/32×W/32×C。AIFI捕获全局上下文和长程依赖关系,产生一个增强的表示,记为F5F_{5}F5。
- 基于CNN的跨尺度特征融合(CCFF):语义增强后的F5F_{5}F5进一步与较低层级的特征图S3S_{3}S3和S4S_{4}S4融合,以将高级语义传播到更浅层的特征,生成最终的多尺度输出P3,P4,P5P_{3},P_{4},P_{5}P3,P4,P5用于解码器。
动机。混合编码器的设计使得特征图F5F_{5}F5的质量尤为关键。作为唯一接受自注意力处理的特征,F5F_{5}F5是整个模型高级全局语义信息的主要来源。它的质量直接影响后续CCFF模块中的跨尺度融合、初始查询选择,并最终影响解码器的性能。这种依赖性导致了我们所谓的F5F_5F5语义瓶颈。然而,产生F5F_{5}F5的AIFI模块仅接受间接监督进行训练,因为来自最终检测损失的梯度在到达F5F_{5}F5之前必须通过解码器和CCFF反向传播。这种间接监督可能不足以充分优化F5F_{5}F5。
为了解决这个问题,我们提出了深度语义注入器(DSI),这是一个仅用于训练的轻量级模块,它通过将深层特征F5F_{5}F5与来自视觉基础模型的语义丰富表示进行显式对齐,为特征图F5F_{5}F5提供明确且强大的监督。这种有针对性的监督增强了F5F_{5}F5的语义表达能力,并允许其梯度流回AIFI和主干网络,从而协同改进这两个模块。
引入DSI后,总训练目标定义为:
Ltotal=Ldet+λLDSI,\mathcal{L}_{\mathrm{total}}=\mathcal{L}_{\mathrm{det}}+\lambda\mathcal{L}_{\mathrm{DSI}},Ltotal=Ldet+λLDSI,
其中Ldet\mathcal{L}_{\mathrm{det}}Ldet表示标准检测损失(例如,分类和边界框回归),LDSI\mathcal{L}_{\mathrm{DSI}}LDSI表示提出的语义对齐损失。然而,由于VFM与资源受限检测器之间存在巨大的架构和学习目标差异,实现稳定且任务对齐的语义传递具有挑战性。不恰当的λ\lambdaλ选择可能在早期阶段提供不足的语义监督,或在后期阶段过度主导检测目标,最终阻碍收敛并降低性能。为了适应训练期间不断变化的优化动态,我们提出了梯度引导的自适应调制(GAM),这是一种基于梯度统计动态调整X的机制,确保检测和语义监督之间的平衡优化。
3.2. 深度语义注入器
为了解决F5语义瓶颈,我们引入了深度语义注入器(DSI),这是一个仅用于训练的模块,旨在为特征图F5F_{5}F5提供明确且强大的监督。DSI的目标是通过将F5F_{5}F5与来自高容量语义教师(记为T\mathcal{T}T)的表示对齐来丰富F5F_{5}F5的语义质量。给定输入图像,T\mathcal{T}T产生高质量的特征表示FT∈RH′×W′×CTF_{\mathcal{T}}\in\mathbb{R}^{H^{\prime}\times W^{\prime}\times C_{\mathcal{T}}}FT∈RH′×W′×CT。
特征投影器。为了将检测器的特征图F5 ∈ RH5×W5×C5F_{5}\;\in\;\mathbb{R}^{H_{5}\times W_{5}\times C_{5}}F5∈RH5×W5×C5与教师的表示FTF_{\mathcal{T}}FT对齐,必须协调空间分辨率和通道维度的差异。教师模型通常是ViT [8],输出一系列图像块标记TpT_pTp。为了进行空间比较,TpT_pTp被重塑为二维网格表示FTsp∈RHT×WT×CTF_{\mathcal{T}}^{\mathrm{sp}}\in\mathbb{R}^{H_{\mathcal{T}}\times W_{\mathcal{T}}\times C_{\mathcal{T}}}FTsp∈RHT×WT×CT,其中Np=HT×WTN_p = H_{\mathcal{T}} \times W_{\mathcal{T}}Np=HT×WT。
然后,我们引入一个轻量级特征投影器P\mathcal{P}P来实现双重对齐。首先,将FTspF_{\mathcal{T}}^{\mathrm{sp}}FTsp插值以匹配F5F_{5}F5的空间分辨率。同时,P\mathcal{P}P调整F5F_{5}F5的通道维度以与教师的语义空间对齐。完整的投影过程总结如下:
FTsp=Reshape(Tp),FTsp∈RHT×WT×CT,FT′=Interpolate(FTsp,(H5,W5)),F5′=P(F5),F5′∈RH5×W5×CT.\begin{array}{r}{{F_{\mathcal{T}}^{\mathrm{sp}}=\mathrm{Reshape}(T_{p}),\quad F_{\mathcal{T}}^{\mathrm{sp}}\in\mathbb{R}^{H_{\mathcal{T}}\times W_{\mathcal{T}}\times C_{\mathcal{T}}},}}\\ {{F_{\mathcal{T}}^{\prime}=\mathrm{Interpolate}(F_{\mathcal{T}}^{\mathrm{sp}},(H_{5},W_{5})),}}\\ {{F_{5}^{\prime}=\mathcal{P}(F_{5}),\quad F_{5}^{\prime}\in\mathbb{R}^{H_{5}\times W_{5}\times C_{\mathcal{T}}}.}}\end{array}FTsp=Reshape(Tp),FTsp∈RHT×WT×CT,FT′=Interpolate(FTsp,(H5,W5)),F5′=P(F5),F5′∈RH5×W5×CT.
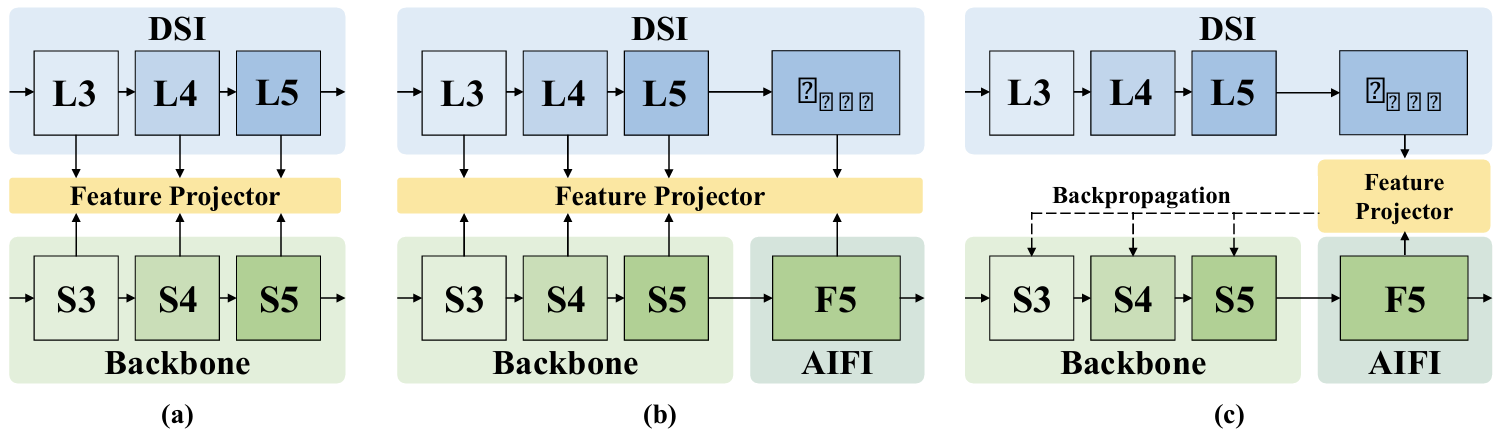
语义注入。如图3所示,我们设计了三种逐步增强的语义注入配置。在配置(a)和(b)中,DSI模块通过特征投影器在不同层次深度执行特征对齐,将来自冻结VFM的语义知识注入到检测器的特征层次结构中。在配置©中,考虑到AIFI模块在混合编码器中的关键作用,对齐在其输出F5F_{5}F5上进行,该输出包含最丰富的语义。不断开梯度,允许DSI损失反向传播,从而更新轻量级主干网络。因此,前向传播利用增强的F5F_{5}F5来指导CCFF模块中的跨尺度融合,而后向路径则强制执行语义一致性并加强主干网络的表示能力。这种双向监督实现了检测器的统一语义增强。
对齐损失。为了鼓励检测器捕获教师表示的丰富语义,我们采用余弦相似度损失。我们最大化检测器的投影特征F5′F_{5}^{\prime}F5′与教师的投影特征FT′F_{\mathcal{T}}^{\prime}FT′之间的逐块余弦相似度,公式化为最小化所有空间位置(i,j)(i,j)(i,j)上的平均负余弦相似度:
LDSI(F5′,FT′)=−1H5W5∑i,jF5′(i,j)⋅FT′(i,j)∥F5′(i,j)∥∥FT′(i,j)∥.\mathcal{L}_{D S I}(F_{5}^{\prime},F_{\mathcal{T}}^{\prime})=-\frac{1}{H_{5}W_{5}}\sum_{i,j}\frac{F_{5}^{\prime}(i,j)\cdot F_{\mathcal{T}}^{\prime}(i,j)}{\|F_{5}^{\prime}(i,j)\|\|F_{\mathcal{T}}^{\prime}(i,j)\|}.LDSI(F5′,FT′)=−H5W51i,j∑∥F5′(i,j)∥∥FT′(i,j)∥F5′(i,j)⋅FT′(i,j).
3.3. 梯度引导的自适应调制
为了确保稳定和自适应的语义监督,我们提出了一种动态的梯度引导自适应调制(GAM)机制,该机制根据其梯度范数比率而不是原始损失幅度来调节DSI损失的相对贡献。这种基于梯度的调节自适应地将DSI的有效贡献维持在期望范围内,从而实现模型组件之间的平衡优化。
具体来说,对于周期eee内的每个训练步ttt,我们计算每个主要组件(包括主干、AIFI、CCFF和解码器)的梯度L1L_{1}L1范数:
C={Backbone,AIFI,CCFF,Decoder},\mathcal{C}=\{\mathrm{Backbone},\mathrm{AIFI},\mathrm{CCFF},\mathrm{Decoder}\},C={Backbone,AIFI,CCFF,Decoder},
Gt(C)=∥∇θCLtotal∥1.G_{t}^{(\mathcal{C})}=\|\nabla_{\theta_{\mathcal{C}}}\mathcal{L}_{t o t a l}\|_{1}.Gt(C)=∥∇θCLtotal∥1.
总梯度大小由下式给出:
Gt(total)=∑CGt(C),G_{t}^{(t o t a l)}=\sum_{\mathcal{C}}G_{t}^{(\mathcal{C})},Gt(total)=C∑Gt(C),
AIFI在步ttt的相对梯度贡献定义为:
rt=Gt(AIFI)Gt(total).r_{t}=\frac{G_{t}^{(\mathrm{AIFI})}}{G_{t}^{(t o t a l)}}.rt=Gt(total)Gt(AIFI).
然后,我们将周期eee内所有训练步的梯度比率平均,得到:
rˉe=1Te∑t=1Tert,\bar{r}_{e}=\frac{1}{T_{e}}\sum_{t=1}^{T_{e}}r_{t},rˉe=Te1t=1∑Tert,
其中TeT_{e}Te表示周期eee中的步数。
两个超参数控制调制过程:
- 目标比率 (ρ\rhoρ):AIFI期望的平均梯度比率,代表其对优化的理想相对贡献。
- 容忍区间 (δ\deltaδ):一个裕度,定义了围绕目标比率的可接受偏差范围[ρ−δ,ρ+δ][\rho-\delta,\rho + \delta][ρ−δ,ρ+δ]。
在每个周期结束时,GAM检查rˉe\bar{r}_erˉe是否位于目标区间内。如果rˉe∈[ρ − δ,ρ + δ]\bar{r}_e\in\left[\rho\!-\!\delta,\rho\!+\!\delta\right]rˉe∈[ρ−δ,ρ+δ],则LDSI\mathcal{L}_{\mathrm{DSI}}LDSI的权重λe\lambda_eλe保持不变。否则,调整λϵ\lambda_{\epsilon}λϵ,使得下一周期的AIFI梯度比率被引导朝向目标范围的边界而不是其中点,因为只有一部分AIFI的梯度源自LDSI\mathcal{L}_{\mathrm{DSI}}LDSI。基于边界的调整在平衡点附近产生更稳定的收敛。
λe+1={λe⋅ρ−δrˉe,if rˉe>ρ+δ,λe⋅ρ+δrˉe,if rˉe<ρ−δ,λe,otherwise.\lambda_{e+1}=\left\{\begin{aligned}{}&{{}\lambda_{e}\cdot\frac{\rho-\delta}{\bar{r}_{e}},}&{}&{{}\mathrm{if}\;\bar{r}_{e}>\rho+\delta,}\\ {}&{{}\lambda_{e}\cdot\frac{\rho+\delta}{\bar{r}_{e}},}&{}&{{}\mathrm{if}\;\bar{r}_{e}<\rho-\delta,}\\ {}&{{}\lambda_{e},}&{}&{{}\mathrm{otherwise}.}\end{aligned}\right.λe+1=⎩⎨⎧λe⋅rˉeρ−δ,λe⋅rˉeρ+δ,λe,ifrˉe>ρ+δ,ifrˉe<ρ−δ,otherwise.
该更新规则驱动AIFI的有效梯度贡献收敛到期望的操作范围内,同时防止振荡。超参数ρ\rhoρ和δ\deltaδ提供了对训练动态的显式控制:ρ\rhoρ定义了期望的监督强度,而δ\deltaδ调节了响应速度和稳定性之间的权衡。较小的δ\deltaδ能够实现更快的适应但有不稳定的风险,而较大的δ\deltaδ则产生更平滑但更慢的收敛。在实践中,GAM提供了稳定的收敛性,并在不增加额外调整开销的情况下持续改进语义对齐。
4. 实验
4.1. 设置
数据集和指标。所有实验均在COCO 2017 [20]数据集上进行,使用train2017分割进行训练,使用val2017进行验证。我们报告标准的COCO指标,包括AP(在0.50到0.95的IoU阈值范围内以0.05为步长均匀采样取平均)、AP50\mathrm{AP_{50}}AP50、AP75\mathrm{AP_{75}}AP75,以及在不同尺度下的AP:APS\mathrm{AP}_{S}APS、APM\mathrm{AP}_{M}APM、APL\mathrm{AP}_{L}APL。
实现细节。我们的实验基于RT-DETR架构[38],并包含了RT-DETRv2 [23]、D-FINE [26]和DEIM[15]的额外架构和训练改进。为了公平比较,核心超参数与相应基线保持一致。DSI采用预训练且冻结的DINOv3-ViT-B模型作为语义教师。所有评估均使用COCO AP指标进行,推理延迟(毫秒)是在单个NVIDIA T4 GPU上使用TensorRT FP16精度测量的。
4.2. 与SOTA的比较
我们将我们提出的RT-DETRv4与最近最先进的实时检测器进行了比较,包括最新的YOLO系列(YOLOv10[33]、YOLOv11[11]、YOLOv12[32]和YOLOv13 [17])和基于DETR的检测器(RT-DETR[38]、RT-DETRv2[23]、RT-DETRv3[36]、D-FINE [26]、DEIM[15]和DEIMv2[14])。结果如图1所示,详细统计数据见表1。结果表明,RT-DETRv4在所有模型尺度(S、M、L和X)上均实现了最佳性能,且未引入任何额外的推理和部署开销。
具体来说,我们的RT-DETRv4-L在COCO上达到55.4 AP,速度为124 FPS,在相当或更低的计算预算下优于YOLOv13-L(53.4 AP)和DEIM-L(54.7 AP)。最大的变体RT-DETRv4-X达到了57.0 AP,超过了DEIM-X(56.5 AP),且未引入任何推理开销。在较小尺度上,RT-DETRv4-S和RT-DETRv4-M分别获得49.7和53.5 AP,均明显超过了它们的DEIM对应版本(49.0和52.7 AP)。
为了在相似的延迟范围内进行公平比较,我们仅在图表1中报告了DEIMv2 [14]的结果,并将其从表1中排除,因为它们的模型通常表现出更高的推理延迟。在相当的推理速度下,我们的RT-DETRv4-M大幅超过了DEIMv2-S(53.5 AP vs. 50.9 AP,169 FPS vs. 173 FPS),并且RT-DETRv4-L进一步优于DEIMv2-M(55.4 AP vs. 53.0 AP,124 FPS vs. 113 FPS)。这些结果充分证明了所提出方法的有效性和巨大潜力。
虽然DEIMv2-X实现了更强的性能,但其延迟也高于RT-DETRv4-X。此外,直接采用DINOv3作为主干来获得语义丰富性从根本上受到模型大小和部署成本的限制,使其仅限于DINOv3的Tiny或Small变体,并且难以扩展到更强大的大型模型。相比之下,我们的框架对VFM类型和规模都不可知,不引入推理或部署开销,提供了一个更灵活和部署友好的解决方案。
4.3. 消融研究
我们进行了一系列消融实验来验证所提出模块的有效性。除非另有说明,所有消融实验均训练36个周期。未指定的超参数或配置遵循相应实验设置的最佳设置。
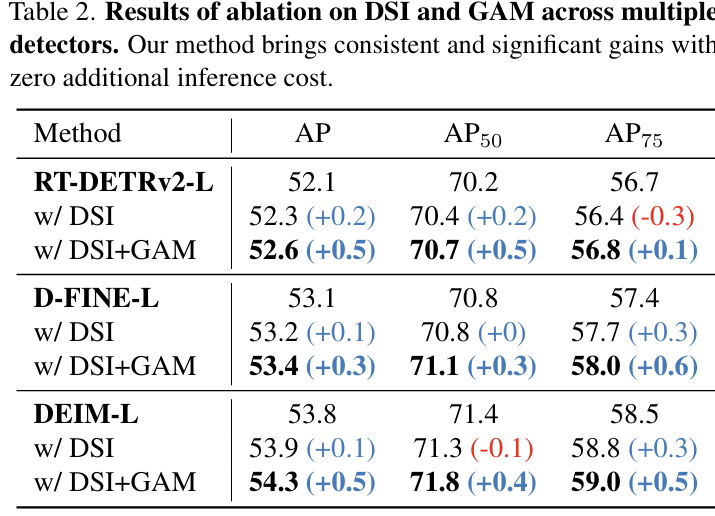
关于DSI和GAM的消融。我们首先评估DSI和GAM的有效性。如表2所示,应用DSI可以带来轻微的性能提升,而进一步应用GAM可以显著提高性能增益(0.5 AP),这充分证明了两者的有效性。为了验证我们方法的普遍适用性,我们还在RT-DETRv2和D-FINE上进行了实验,结果表明我们的方法可以为不同的检测器带来一致的性能提升。
关于语义注入位置的消融。为了验证注入位置的选择,我们比较了图3所示的策略。表3中的结果表明,直接将语义监督应用于主干特征(S3, S4, 或 S5)(S_{3},\,S_{4},\,\mathrm{或}\,\,S_{5})(S3,S4,或S5)(单独或联合)没有带来改进。类似地,对齐主干和F5F_{5}F5特征的混合方法(策略(b))也没有带来增益(53.8 AP)。
相比之下,我们的设计(策略©),即仅对齐AIFI输出F5F_{5}F5,实现了清晰的0.5 AP改进(54.3 AP)。这表明在F5F_{5}F5中保持更丰富的语义对于提高检测性能至关重要,因为它在将高级语义信息传播到后续特征层次中起着关键作用。
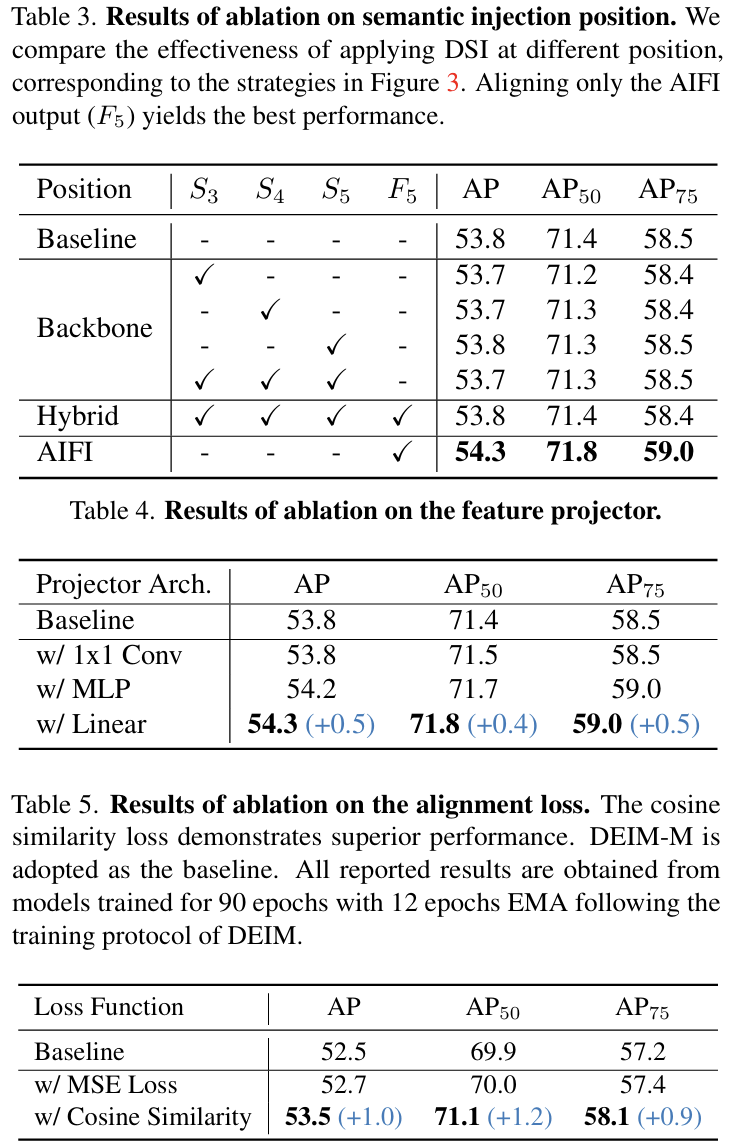
此外,混合方法的无效性表明,同时对齐来自基于CNN的主干和基于Transformer的AIFI的特征可能会引入优化冲突或语义失准。我们选择的策略不仅更有效,而且更高效。它避免了多个中间投影和插值的复杂性,并且来自单个F5F_{5}F5对齐损失的梯度自然流回,以协同更新AIFI和主干,通过单一、有针对性的目标实现一致的增强。
特征投影器的设计。特征投影器是连接学生和教师特征空间的关键组件。我们探索了几种架构选择,详见表4。基于线性层的投影器产生了最好的结果,在表达能力和参数效率之间取得了最佳平衡。
损失函数的选择。我们进一步研究了DSI的对齐损失。我们在表5中比较了均方误差(MSE)损失和余弦相似度损失,后者优于前者,验证了我们的假设,即对齐特征方向更为关键。
GAM与静态权重的比较。最后,我们验证了提出的GAM与静态权重相比的性能。GAM在导航训练动态方面的优越性在图5中进一步说明,该图绘制了各周期内的验证AP曲线。如图所示,GAM的曲线始终保持在基线和所有静态权重配置之上,在整个训练过程中展示了清晰且稳定的性能优势。
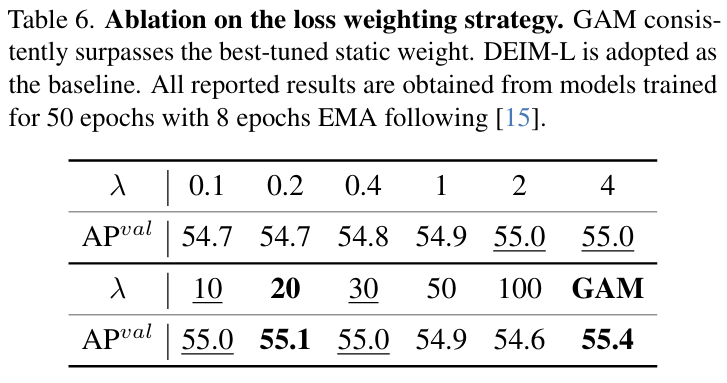
表6详细列出了静态权重和GAM的结果。对于静态加权,性能在λ=20\lambda=20λ=20时达到峰值,达到55.1 AP,但在值更小或更大时性能下降。然而,观察图5中的训练曲线,我们发现即使这个最优的静态权重(λ=20)(\lambda=20)(λ=20)也会导致在早中期收敛较慢,这凸显了固定超参数的固有局限性。我们的实验表明,GAM实现了最佳性能(55.4 AP)。
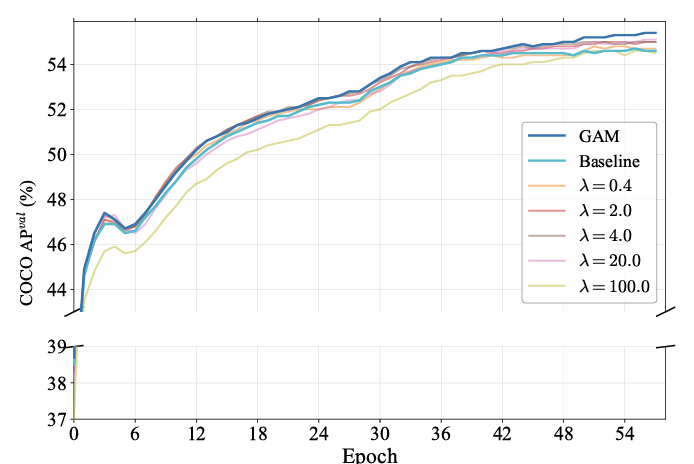
图 5. 训练期间COCO上的验证AP演变。我们将我们的动态GAM与基线模型和DSI损失的几个静态λ\lambdaλ值进行了比较。GAM策略 consistently outperforms all static configurations,展示了其在训练过程中提供稳定有效监督的能力
特征可视化。图4直观地比较了DEIM-L和我们的RT-DETRv4-L之间的特征图。值得注意的是,我们的模型丰富了AIFI特征F5F_{5}F5的语义内容,导致在后续的多尺度特征P3, P4.P_{3},\,P_{4}.P3,P4.和P5P_{5}P5上具有更精确和可区分的物体轮廓和背景。特别是,P5对物体区域表现出明显更强且更集中的响应。

图 4. 密集特征比较。我们通过使用PCA将密集输出投影到RGB空间来比较DEIM-L(顶部)和RT-DETRv4-L(底部)的特征图质量。可视化显示,我们的DSI模块显著增强了AIFI特征的语义表示,这反过来又有利于后续的CCFF特征。从左到右:输入图像、AIFI特征图和跨尺度CCFF特征P3,P4,P5P_{3},P_{4},P_{5}P3,P4,P5
5. 讨论
为了进一步强调我们的框架相对于现有方法的优势,我们从部署效率、可扩展性和训练效率方面进行讨论。
部署效率。我们的方法对检测器架构进行了零修改,并且不改变推理流程,确保不产生额外的计算成本或延迟。这种部署友好特性对于工业应用至关重要,因为实时检测器通常紧密集成到现有系统和硬件受限的环境中。
可扩展性。该框架具有高度通用性,可以无缝应用于具有不同架构的检测器,包括基于CNN和基于Transformer的检测器。它使所有类型的实时检测器都能快速受益于视觉基础模型(VFMs)的快速发展。此外,该框架不受任何特定类型或规模的VFM的限制。它可以灵活地合并不同的基础模型,例如DINOv3[31]、MAE [13]或CLIP[27],甚至可以利用任意大的模型将语义蒸馏到实时检测器中。这种灵活性也为多VFM语义集成开辟了有前景的方向,进一步证明了该框架的通用性和可扩展性。
训练效率。我们的方法是轻量级且易于实现的。由于检测器结构和优化流程都没有因为引入VFM而被修改,因此额外的训练成本仍然很小。这种效率突显了我们的方法在大规模应用和实时工业部署中的实用性。
6. 结论
在这项工作中,我们提出了一种成本效益高且适应性强的语义蒸馏框架,该框架在不增加推理或部署开销的情况下增强了基于DETR的实时目标检测器。通过提出的深度语义注入器(DSI)和梯度引导的自适应调制(GAM),我们的方法以稳定且任务对齐的方式将视觉基础模型的高级语义有效地转移到轻量级检测器中。在COCO上进行的大量实验证明了跨多个模型尺度的一致且显著的性能增益,最终形成了最先进的RT-DETRv4系列。这些结果突显了显式语义监督在弥合大规模基础模型与资源高效检测架构之间差距方面的有效性。总的来说,我们的工作为释放基础模型在高效视觉感知方面的潜力提供了一条实用途径。