自动驾驶大模型---特斯拉FSD模型架构终浮出水面
1 前言
在今年的ICCV会议上,特斯拉FSD的负责人,分享了特斯拉FSD最近的研究进展。
会议时间地点:2025年10月20日于夏威夷。



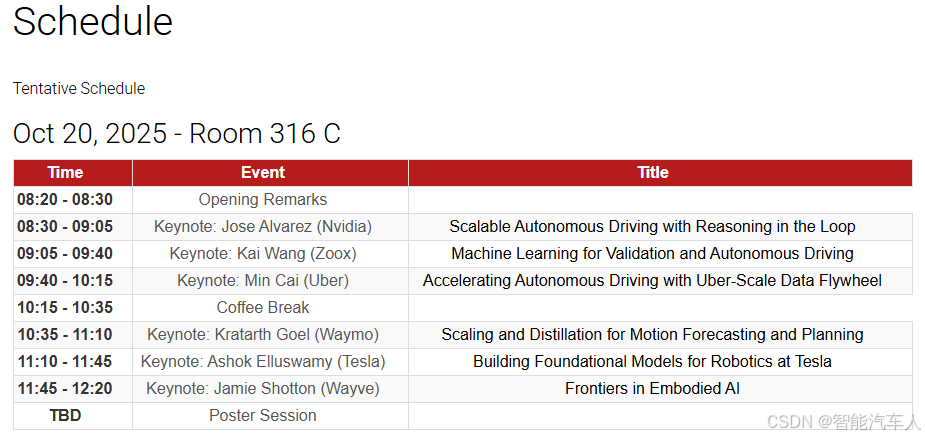
2 FSD V14
特斯拉从2023年开始使用一个单一的、大型的端到端神经网络,它可以接收像素和其他传感器数据作为输入,然后直接产生下一个动作作为输出。
对于什么是端到端?Ashok给出了一个解释:端到端的唯一要求是梯度必须全程流动(flow all the way)。
怎么理解呢?一个真正的端到端自动驾驶系统,其本质在于创建一个单一的、可微的计算图,使得在训练过程中,来自最终驾驶表现的反馈信号(梯度)能够无损耗地贯穿整个系统,从而引导从图像处理到方向盘控制的每一个参数进行协同自我改进。
2.1 一个NN的背景
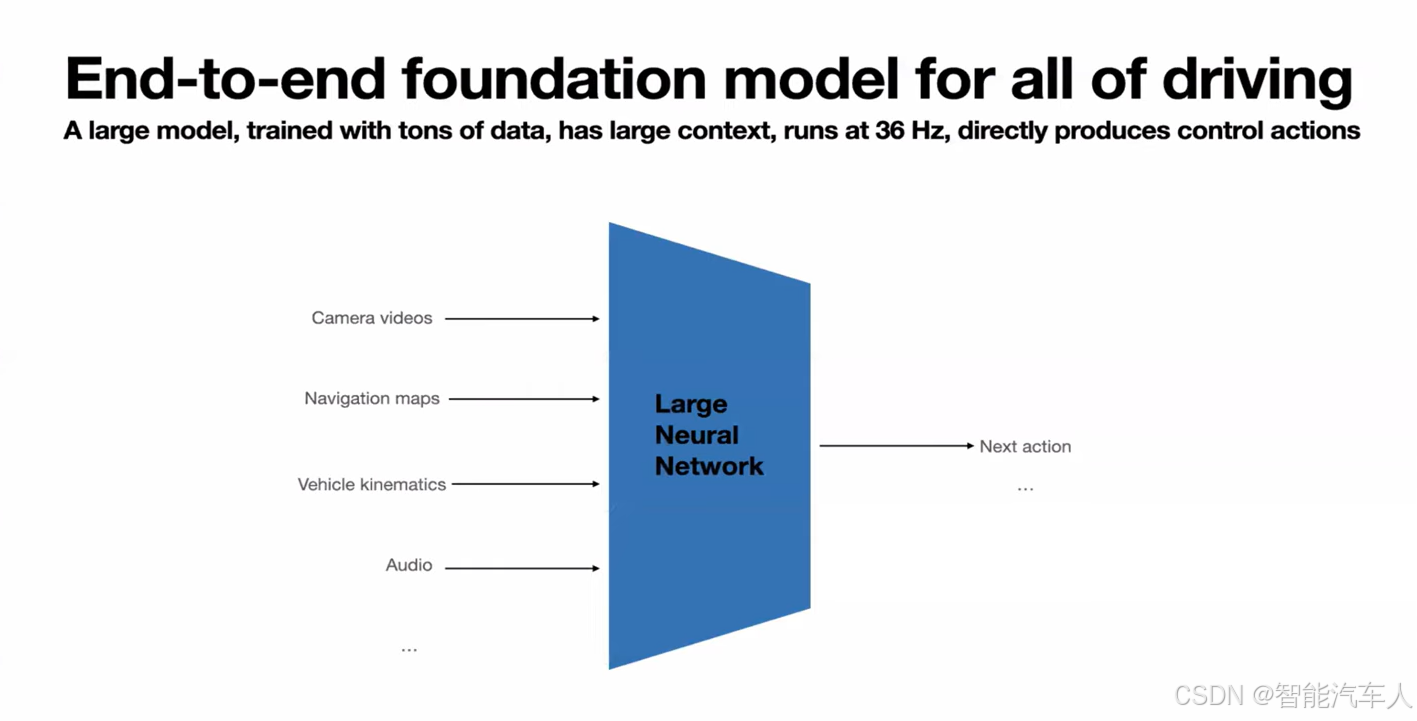
- 神经网络的输入:
- 摄像头
- 导航地图
- 车辆运动学
- 音频
- ...
- 神经网络的输出:
- 下一个动作(油门,转向)
特斯拉宣传的一直都是输出控制信号,但目前国内很多企业认为:针对不同的车型输出控制信号是非常难的。但是,特斯拉NN多了一个输入---车辆运动学,如果有了这个输入信息,使得输出控制信号成为了可能,如果真的如此,只能说特斯拉的模型确实强大(很多车主的测试视频展示了特斯拉控制的流畅性和舒适性,因为在传统的控制模块中,为了匹配表现,依然会有很多参数或者场景的适配)。
这个神经网络不再对车辆、道路边界或类似事物进行显式的感知。 它们可以是隐式的,也可以作为辅助任务进行训练。 但总的来说,视频流输入进去,然后要采取的实际行动由一个神经网络产生。
(1)原因阐述
采取一个神经网络的原因,Ashok做了解释:过去采用显式的模块化方法(perception-planning等模块),因为它更容易调试等等。 但我们发现,将人类价值观这样的东西编入代码真的很难。例如,你可以为障碍物刹车,或者绕开它,你可以开得尽可能快,然后晚一点刹车,或者早一点刹车以获得更平稳的驾驶体验。这实际上归结为偏好与人类价值观的对齐,而不是存在一个客观的价值,比如刹车力度多大以及何时刹车。你也不想刹车太早,因为那样你会太慢。你也不想刹车太晚,那样会非常不舒服。并且这因情况而异,在高低速时情况非常不同。
所以真的很难把人类到底想要什么编入代码,你无法用代码把它写出来,至少写得不是很好。而且,传统感知和规划之间的接口定义非常糟糕。它可能是有损的,并丢失关键信息,而你可能需要将不确定性在整个系统中传播。
转向端到端神经网络还允许你的计算变得同构化。因为如果你使用传统的分支计算,你可能会有不确定的延迟量。而在一个实时系统中,你不想有不确定的延迟,你想要的是可预测的、确定性的延迟,而这样一个单一神经网络来完成所有事情就能提供这一点。
(2)举例说明

例如,这辆车正行驶在一条双向道路上,前面有一个大水坑,为了避开这个水坑,你必须开到对向车道去。如果你要用显式的成本函数来编写这个逻辑,可能会非常困难,因为你知道,通常你不想进入对向车道。但是,驶过一个水坑的痛苦与驶入对向车道的风险相比,这很难用显式代码来编写,但很明显,如果你看一下这个场景,你显然可以开过去,这里的视野很好,没有来车,你绝对应该开到对向车道去。
(3)个人思考
针对上述场景,我们扩展两个类似的场景:如果对向车道有来车(车流少),FSD会进行减速,然后等对象车驶过之后,进行借道绕行水坑吗?
当对象车道车流比较多时,FSD还会借道绕行水坑吗?笔者倾向于会减速过水坑,而不会借道。
因此,可以看到规则的代码针对场景是无穷尽的,靠老司机的开车技巧训练神经网络是必须的选择。
2.2 困难

设计这样一个神经网络,会遇到什么困难,这里提到了三个点,Ashok也分别给出了解释:
(1)curse of dimensionality
首先是维度灾难(curse of dimensionality)。输入的上下文是相当庞大的,尤其是我们的车,根据车型的不同,有 7 个或 8 个摄像头。每个摄像头都会产生500 万像素的摄像头视频流,以高帧率运行。即使你想要大约 30 秒的上下文或类似的东西,再加上其他必要的输入,比如路线、车速和其他运动数据,它输入可以轻松超过几十亿的 token,比如 30 秒的上下文窗口就需要 20 亿个 token。而如果我们天真地只使用某种一个巨大的 Transformer,这将是一个非常困难的任务,即把 20 亿个 token 映射到大约 2 个 token。这 2 个 token 就是汽车应该采取的下一个转向和加速。

幸运的是,特斯拉在这里有一个巨大的优势,那就是特斯拉的车队非常庞大。所以它基本上拥有尼亚加拉瀑布量级的数据,特斯拉要做的就是利用这些数据来解决这个问题。你显然不希望从 20 亿个 token 到 2 个 token 之间产生伪相关性。你想要的是正确的相关性,即为什么那 2 个输出 token 必须是正确的 token。所以我们所做的,是提炼这些车队多年的驾驶数据,这些数据显然比我们集群上能存储的要多得多,提炼到必要的数据量,这些数据覆盖了驾驶的全部范围。我们有不同的方法来收集这些数据,基于特定的触发器,或针对特定场景的小型神经网络,或者像不断评估模型的预测与实际发生的情况等等。我们可以使用这样的技巧来提取我们训练所需要的、恰到好处的数据量、正确的质量和数据类型。

举例说明:
这里有一些例子,展示了那种corner case数据可能是什么样子。 这些是人工驾驶中的例子,就像,人们只是在开车,他们遇到了这种罕见的场景。我们可以有触发器来缓存这些数据。这些数据对于训练来说非常非常有用。并且这些数据是通常无法获取的,你无法轻易地摆拍出这些场景,因为它需要整个场景、所有车辆的速度在状态空间(state space)中。这真的很难实现,而特斯拉在这里拥有独特的优势,它可以利用整个车队来获取这些数据。一旦我们获得了这些数据,你就可以用它来训练我们的端到端模型,就像我之前提到的。它就是能泛化到像这样的极端场景,并且不仅仅是在最后一刻做出反应,而是能做到主动安全。

我想做一个演示,说明这是如何体现的,比如一个正在运行的特斯拉FSD系统,行驶在高速公路上,遇到了一起交通事故。
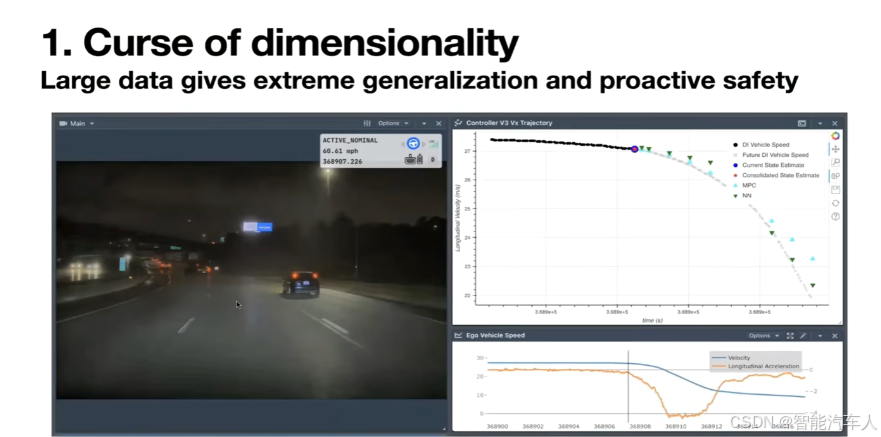
我们前面的车失控了,然后撞上了护栏,自动驾驶系统安全地靠边停车了。但非常有趣的是,如果你再看一遍视频,暂停在自车刹车的那个地方,就像这里如果你注意到这辆车,它就像失控一样打转,它即将撞上护栏,并且会反弹回我们的车道。这需要非常高的智能才能知道这里不是一阶碰撞(first order collision)。在这一帧,特斯拉已经判断出这辆车出了点问题,并开始刹车了。它没有等到这辆车撞上护栏,然后反弹回来,看到它的速度发生变化或类似情况才刹车,这是一个它需要建模的二阶效应(second order effect)。
系统本可以把这归因于这辆车的变道,但它没有。 系统理解了情况的严重性,因为它请求了大约 4 米每平方秒的刹车加速度,这不是一个轻微的刹车量。 这只有在你拥有海量数据并覆盖了所有这些极端案例的情况下才可能做到。
这就是你如何能同时提供安全又平稳的驾驶体验,因为一个不够智能的系统会等到对向改变了,或者某些坏事已经发生了才会反应。 刹车发生在真正出问题之前的好一会儿。 这就是你通过端到端系统和海量数据所能得到的。
个人思考:特斯拉FSD应该是训练了事故发生时的驾驶数据,对于不符合车辆运动学的动态障碍物,车辆提前靠边停车。(目前还没见到国内车企演示过这种case,静态施工或者双闪场景都没什么问题)
(2)Interpretability and safety guarantees

其次,你可能会问这是一个端到端系统,你们怎么调试呢?你们到底是如何知道开发这个东西的? 如果出了问题,你们怎么知道?仅仅因为它是一个端到端系统,并不意味着它不能预测任何其他东西。同一个模型可以被提示(prompted)去预测任意事物,包括 3D 占用(3D occupancy)、其他物体、交通信号灯、交通标志、道路边界。甚至只是用语言。你可以问它为什么做出了某些决定,它是否理解这个场景,等等?所有这些都有助于解释模型对场景的理解,也在某种程度上为整个系统的安全性提供一些保证。
所以在实践中,它看起来有点像这样,如下图所示:
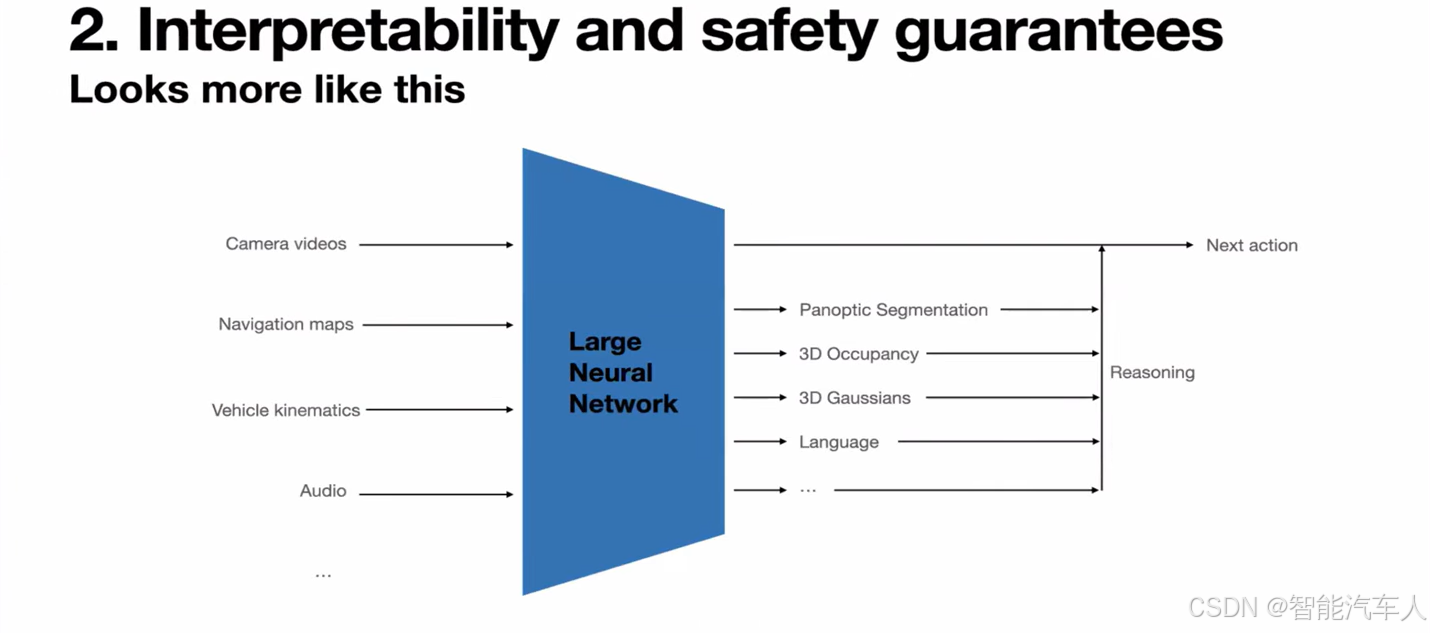
你可以输入任意的传感器数据,并被提示去产生任意的东西。但最终,在车里唯一真正重要的是它产生的控制动作。其他一切都是辅助性的,但它们对于预测正确的控制动作可能非常有帮助。
注意到这里Network和Next action中间有一些其它的东西:
- Reasoning
- Panoptic Segmentation
- 3D Occupancy
- 3D Gaussians
- Language
- ...

我想深入探讨的一个特定任务是高斯溅射(Gaussian Splatting),这在过去几年中在该领域非常突出。 我在这里左侧展示的是传统的高斯溅射,它看起来真的很糟糕,我特意挑了一个糟糕的例子来展示。
问题在于,车辆通常是线性向前行驶的,没有太多的基线。正因为如此,如果你只是拿车辆运动的相同摄像机视角,运行传统的高斯溅射,我不知道,用 NeRF Studio 或其它什么,并使用相同的摄像机视角来查看,那些接近训练视角的渲染视图看起来很棒。但是,如果你切换到远离训练视角的新视角,效果就崩溃得很厉害。
但我们在中间这一列展示的是特斯拉版本的高斯溅射,同一个模型可以产生高斯。在与左侧相同的、有限的摄像机视角下,特斯拉的泛化能力要好得多。如第三列所示,它还可以产生语义(semantics)。
有趣的是,与传统的高斯溅射可能需要花费数十分钟相比,它的运行速度快得离谱。而且,它跳过了像 COLMAP 这样的步骤来生成相机位姿,传统方法需要来自这类显式求解器的初始化才能做得好。

所以你可以看到这特斯拉的方法可以非常迅速地更新场景。如果你使用相同的传统溅射,很多新视角渲染出来可能看起来很模糊或像蒙了一层雾。但是,当在 3D 空间中旋转视角时,特斯拉版本的很多结构仍然保持完整。这种可解释的表征可以用来调试系统,比如它开得快了还是慢了,你可以很容易地观察到它是否安全地避开了一些障碍物?
下面是一个比较重要的部分,FSD到底和国内的VLA或者WM有什么不同,FSD到底有没有使用LLM或者LLM在FSD中是一个什么样的角色。

就像我之前提到的,我们也可以使用自然语言与模型互动。同一个模型可以指向某些东西,解释它为什么做了某个决定。我们实时驾驶时,不应该需要所有这些功能。但是,如果你确实需要,你总是可以思考更长时间并产生推理 tokens(reasoning tokens),然后再产生正确的行动。 这个行动与整个推理过程的推理是一致的。同样,这可以是车里运行的同一个模型,但根据情况,它可以使用推理功能,也可以直接产生控制动作。
并不是要求对每一件事都进行如此详细的推理,因为如果你对每件事都保持详细的推理,那么将会导致太多的延迟。但是,在需要的地方,它可以推理更长时间以产生正确的答案。
这里对应上面架构图中的 Large Neural Network 对应的 Language的输出。
听到这里,乍一看,这个模式有点像理想汽车之前的双系统,VLM针对复杂场景辅助另一个端到端系统进行决策,但存在耗时较大且系统间匹配的问题,因此只用于复杂场景。而且VLA和FSD当前的架构有什么区别?
注意:三者之间还是有不少区别的。在后续的博客中,笔者也会跟进。
(3)Evaluation
评估(特别是闭环评估,现有的很多端到端模型都是基于开源评估的)这一块确实是非常重要的一部分,因为直接影响的是车辆的表现,当然Ashok也给出了解释。

这三个问题中最困难的就是(闭环)评估。 如果你只是从驾驶员那里训练了一堆数据,然后训练模型,并只是扩大它,你的开环性能可能看起来很棒,但它可能无法很好地转化为汽车的实际驾驶表现。
这有很多原因, 我不想在这里深入探讨细节,但它确实是一个非常重要的问题,需要大量的关注才能从系统中获得好的、好的性能。它还需要一个详尽的评估集。不只是从你的车队中随机采样数据,大部分将是无聊的高速公路驾驶数据,你不想只是在评估高速公路驾驶。这就是我之前提到的数据引擎方法派上用场的地方,我们可以构建一个平衡的、完全覆盖的评估集,这工作极其重要,但非常繁琐。
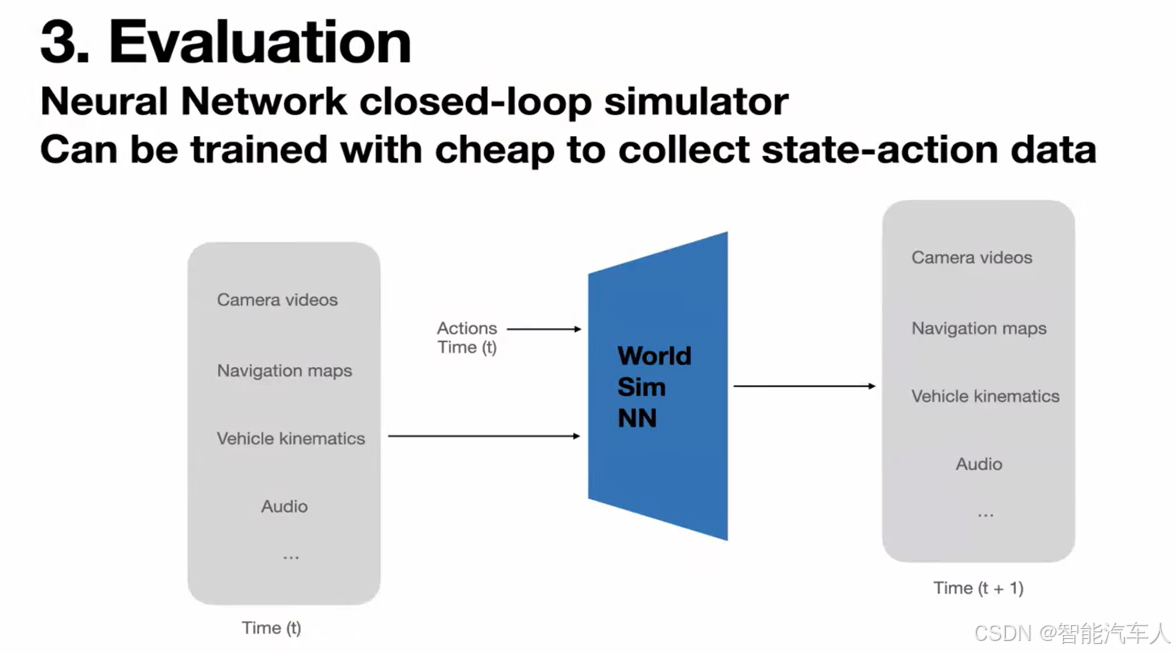
我们发现的一件很棒的事情是,我们可以使用那些易于收集的状态-动作对(state-action pairs),将其反转(invert),然后基本上构建一个世界模拟器(world simulator),在给定过去的状态和动作的情况下,你可以合成出新的状态。这个模拟器以动作为条件,这数据是相当容易收集的,因为你可以免费获得它。你不需要最优驾驶或类似的东西,任何类型的垃圾驾驶数据都足够好,可以用来训练。
这个部分很像是世界模型。
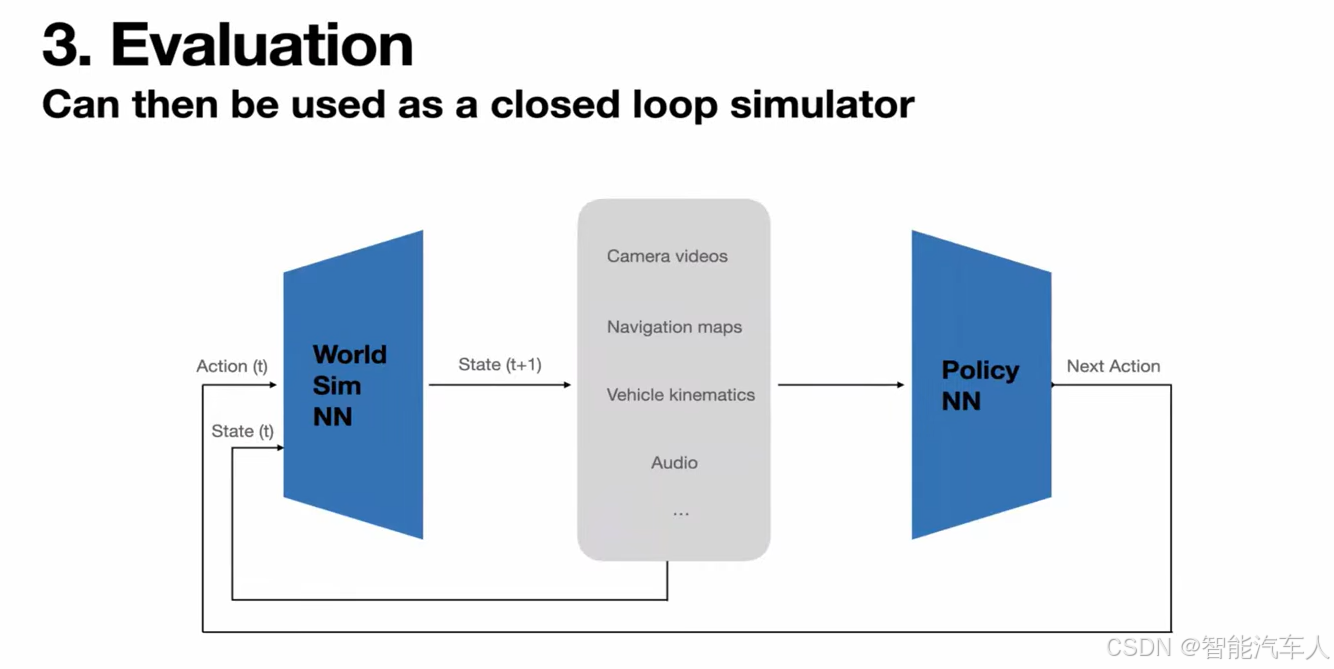
这种模拟器,因为它需要模拟那些边缘案例(edge cases)。一旦你有了这个,你就可以把它和我们用来驾驶汽车的策略神经网络(policy neural network)连接起来。它们可以按顺序在一个循环中一起运行,以模拟这个世界。
这里是一个示例,展示了我们通过一个学成的神经网络模拟器(learned neural network simulator)进行的推演(rollout)。

顶行是汽车向前行驶的所有前置摄像头,中间的是左侧和右侧的摄像头,底行是后视摄像头。所有 8 个摄像头都是由一个神经网络同时生成的,模拟器接收动作作为输入,所以你可以驾驭这个网络模拟器,在接下来的几张幻灯片中展示它是如何工作的。
但是我们完全被不同摄像头之间画面生成的一致性所震撼。即使是车辆的轮毂、交通信号灯都是一致的。这是长达一分钟、一分半钟的 8 路 500 万像素视频流的生成结果。

此外,你可以拿来过去的问题(如上图所示),比如拿一个一年前的问题,然后你可以重新运行最新的神经网络,看看它们的表现会如何。 这里的左侧是最初的失败案例,车辆可能离行人有点太近了,然后在右侧,我们正在评估一个新神经网络来驾驶这辆车。 你可以看到,新策略在行人一从车后出现时,就更早地开始偏移车辆。
这对于这类评估超级有用,因为你不想只是在新的驾驶里程上重新评估。你只是想,如果你有一个历史问题数据库,你就想重放它们,并验证你在这些历史问题上做得很好。你还可以合成地(synthetically)创造新问题。
在这种情况下,左侧的原始视频,那辆车只是在它自己的车道上向前行驶。但在右侧,我们可以条件化(condition)这辆车,让它横切过我们的路径,然后注入这种对抗性事件(adversarial event),以测试系统的极端案例(corner cases)。你可以看到,视频场景和场景的其余部分保持一致。

所有其他车辆都以同样的方式移动,只是这一辆”车横切了过来。这就是你如何能制造大量的合成数据集(synthetic data sets)来验证自动驾驶系统的极端案例性能。如果你愿意稍微降低“测试时计算量”(test time compute),你可以获得接近实时的渲染性能。这是同一个模型,以较低的测试时计算量,渲染 8 个摄像头的画面。
你可以看到,你实际上可以实时地驾驶这个模拟器。它的 FPS帧率足够高,即使它在并行生成 8 路 500 万像素的视频流。所以很明显,你可以看到它在响应用户的驾驶命令。他们可以,比如转向和刹车,然后就像在这个世界中导航,就像他们在真实世界中驾驶一样。
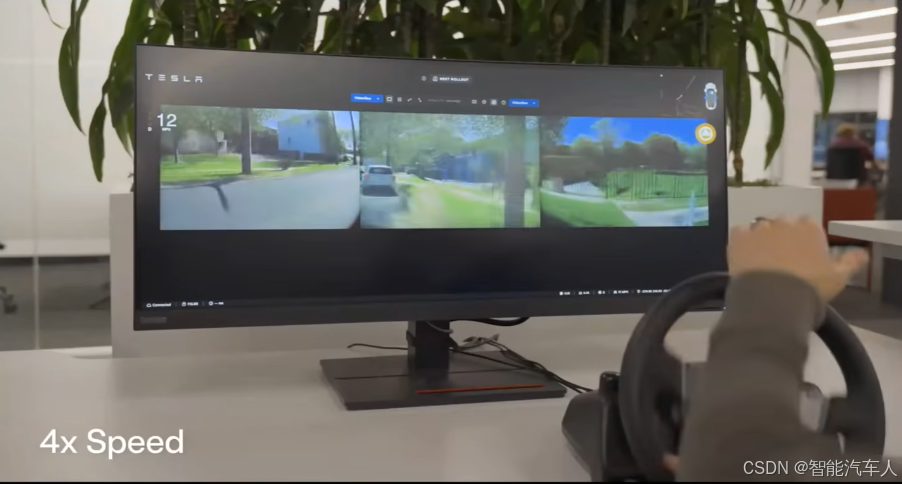
但整个画面都是神经网络生成的视频流。我想这个驾驶员正试图做一些对抗性的操作,比如开上路沿,生成的视频流,角度视角都会随着变化,然后只是为了展示这个模拟器的泛化能力是相当好的。
这整个视频有 6 分钟长,你可以看到在很长一段时间内它都能有一致的视频生成,并响应控制命令。因此你可以想象,这个工具是多么强大,既可以用于评估目的,也可以用于闭环强化学习(closed-loop reinforcement learning),你可以让汽车在模拟器里一直开,然后验证它在很长一段时间内不会与任何东西发生碰撞。那么,下一步是什么? 我们想要,你知道的,扩展这项服务,使其变得更好、更好,然后解锁整个特斯拉车队,使其都能完全自动驾驶。
这是 Cyber Cab,这是我们的下一代汽车,它只有座位,是专为 robotaxi的目的而设计的。它将拥有最低的交通成本,甚至低于公共交通,并且全部由你之前看到的相同神经网络方法提供动力。我们发现,我们所采取的方法是具有高度可扩展性的(scalable),它可以扩展到不同的车辆平台、不同的地理位置、不同的天气条件,并且总的来说,为用户提供了非常安全、舒适和快速的乘坐体验。
2.3 Optimus
还有一件事,那就是这不仅仅是将自动驾驶扩展到所有的车辆,还要将它扩展到其他形式的机器人。

特斯拉制造人形机器人,我们称之为 Optimus(擎天柱)。我们在这里为自动驾驶开发的相同技术,也可以无缝地转移到其他形式的机器人上。我将在这里展示一个例子,就像,视频生成技术也适用于Optimus。所以这是 Optimus 在特斯拉工厂里导航。所有这些都是生成的视频。 你可以看到它们都非常一致。你也可以,就像我们对汽车所做的那样,对它进行动作条件化(action-condition)。所以这里左上角是机器人径直往前走。这是地面真实情况(ground truth),但你可以有不同的动作,比如向左、向右或某个其他方向。然后模型可以为这些动作正确地生成像素画面。并且这是同一个神经网络,只是添加了一些来自 Optimus 的更多数据,它就泛化到了其他的机器人形态因子(form factors)上。
3 总结
特斯拉在ICCV 2025会议上展示了 FSD 架构:采用单一端到端神经网络处理多传感器输入,直接输出控制指令。该系统通过海量车队数据训练,能处理极端场景(如预判失控车辆),并开发了神经模拟器用于评估和生成合成数据。
技术还扩展至Optimus人形机器人,展现了强大的跨平台泛化能力。特斯拉强调该方法具有高度可扩展性,能实现安全舒适的自动驾驶体验,并计划推出专为Robotaxi设计的CyberCab。