C++进阶模板

目录
前言:
一 .非类型模板参数
二.array
三.typename的一个小tip
四.模板的特化
1.函数模板特化
2.类模板特化
(1)全特化
(2)偏(半)特化
五.为什么模板不可以进行声明和定义分离
结言:
前言:
其实在这篇文章之前还应该有一个list和priority_queue的但是感觉这两个说起来有点麻烦所以博主打算放到后面了(其实就是博主比较懒),这篇文章就当奖励自己了qwq。不过博主依旧不水文的下面就开始对进阶模板的讲解了!!
一 .非类型模板参数
在之前的一篇文章中我们说到了模板,但是当时没有合适的应用场景所以说的并不是特别的全。在之前我们学到了类型模板参数就设置一个类型的模板。那么我们自考一个问题当我们想要设置一个静态的栈要怎么去实现呢?回想一下在C语言中我们一般是通过宏来改变栈的大小。但是想要设置两个不同大小的栈是就没有办法了。这时我们不得不去写两个栈。不过这个问题在我们C++中就很好解决了。
template<class T,size_t N>
class stack{
private:T _data[N];T _top;
};int main()
{stack<int, 10> s1;
}不过需要注意的是我们的非类型模板参数在c++20之前只支持int类型,在C++20之后我们可以使用其他的内置类型进行非类型模板。不过自定义类型依然不可以。
同宏定义一样非类型模板参数也是一个常量他是不可以进行修改的。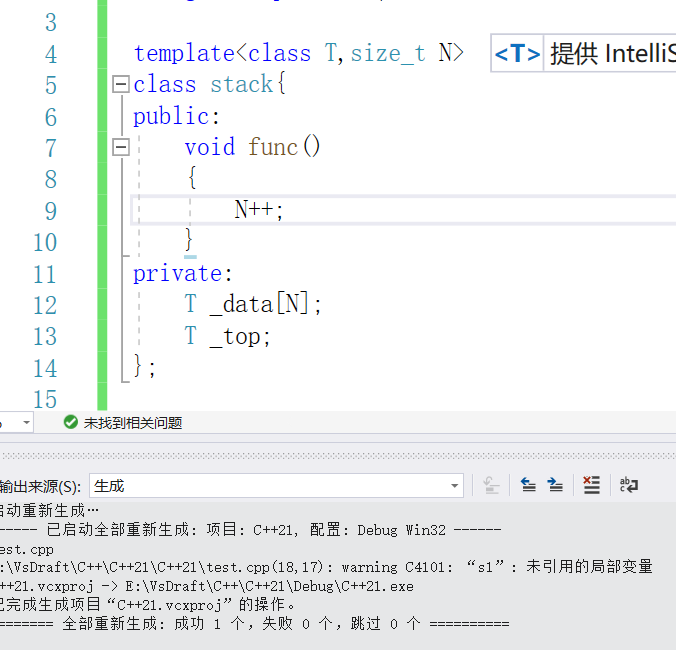
为什么会通过呢?这也是我们今天要讲的一个小内容。
叫作按需实例化,意思就是虽然你创建了这个类的变量但是你不调用里面的函数时并不会生成,所以在编译器编译的时候也不会报错。当我们调用时我们去看一下结果
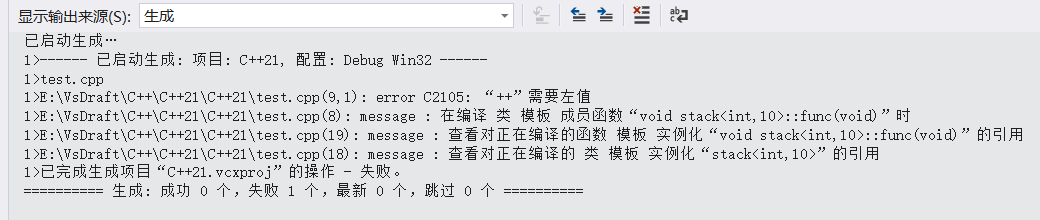
二.array
我们C++自己的创建数组的函数,不过这个设计是有点鸡肋的。他跟C语言内直接创建数组的方式最大的区别就是它会严格的检查越界。在C语言中我们去进行读数据时即使越界了也不会报错。但是array会报错。这是因为数组的检查是一个随机性的抽查,即使我们对C语言的数组进行写的时候如果跳的过多也不会进行报错。
好了说完它的优点下面就该是它的缺点了。

它鸡肋就鸡肋在它的前面有一个vector它跟vector的功能几乎是一模一样的。vector也可以严格的检查越界。还有就是array它创建的内存是在栈上的。导致压栈的风险。所以array是比较鸡肋的一个类。
三.typename的一个小tip
我们思考一下当我们去写一个打印函数当涉及到多个类型的时候应该怎么办?那肯定是要用到我们的函数模板了。那么话不多说直接手搓一个vector的打印函数
void VectorPrint(const vector<T>& v)
{vector<T>::const_iterator begin = v.begin();while (begin != v.end()){cout << *begin << ' ';begin++;}cout << endl;
}
int main()
{vector<int>v1 = { 1,2,3,4,5,6 };vector<double>v2 = { 1.1,2.2,3.1,4.4,5.5,6.6 };VectorPrint(v1);VectorPrint(v2);}我相信大多人会写成这样,不过: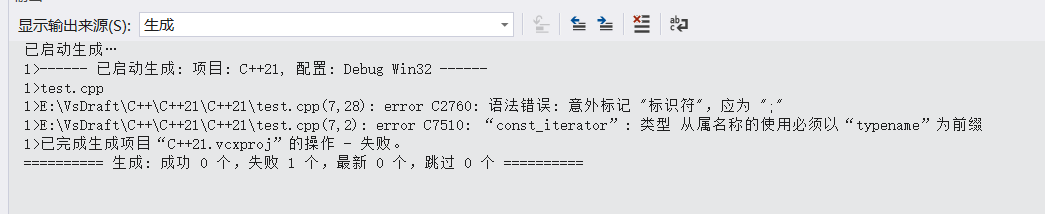
很可惜呀是错的。那么这时是为什么呢?这就需要提到我们上面讲的按需实例化了。在不调用类时编译器不会检测类里面的具体内容。只要类的整体框架不错,编译器是不会报错的。这就导致vector<T>::const_iterator begin = v.begin();这串代码中编译器不敢确认const_iterator是一个变量还是一个类型。导致编译器撂挑子,这时我们就需要typename给我们做一个担保,这里面肯定是一个类型。这样编译器才会放心的去访问。
template<class T>
void VectorPrint(const vector<T>& v)
{typename vector<T>::const_iterator begin = v.begin();while (begin != v.end()){cout << *begin << ' ';begin++;}cout << endl;
}
int main()
{vector<int>v1 = { 1,2,3,4,5,6 };vector<double>v2 = { 1.1,2.2,3.1,4.4,5.5,6.6 };VectorPrint(v1);VectorPrint(v2);}
那么这时候就有人要问了:博主博主这样的代码还是太吃操作了有没有更加简单又强势的写法。
有的兄弟有的,那么有请我们的auto登场!!!
template<class T>
void VectorPrint(const vector<T>& v)
{//typename vector<T>::const_iterator begin = v.begin();auto begin = v.begin();while (begin != v.end()){cout << *begin << ' ';begin++;}cout << endl;
}
int main()
{vector<int>v1 = { 1,2,3,4,5,6 };vector<double>v2 = { 1.1,2.2,3.1,4.4,5.5,6.6 };VectorPrint(v1);VectorPrint(v2);}四.模板的特化
1.函数模板特化
比如我们要去比较两个自定义类型时我们可以单独的写一个模板函数去进行各种类型的比较。不过当有人不清楚我们的代码内部把原本应该传值的函数传成了指针应该怎么办呢?这时候就要用到我们的特化了
template<class T>
bool relate(T s1, T s2)
{return s1 > s2;
}
int main()
{string s1 = "asdawd";string s2 = "asdawdm";cout << relate(s1, s2) << endl;string* ps1 = &s1;string* ps2 = &s2;cout<<relate(ps1, ps2)<<endl;return 0;
}
可以看到结果完全不一样。
bool relate(T s1, T s2)
{return s1 > s2;
}
template<>
bool relate<string*>(string* s1, string* s2)
{return *s1 > *s2;
}
int main()
{string s1 = "asdawd";string s2 = "asdawdm";cout << relate(s1, s2) << endl;string* ps1 = &s1;string* ps2 = &s2;cout<<relate(ps1, ps2)<<endl;return 0;
}
这就是我们的函数特化了,不过它也是有缺陷的,它对于新手来说并不友好,当参数为传引用加const的时候应该去怎么加呢?直接按照模板的格式吗?不是的它的方法可能会有点古怪。
bool relate<string*>(string*const & s1, string* const& s2)
{return *s1 > *s2;
}这还是要因为const的特性当const在*的前面时修饰的是s1指向的内容但是我们不想让s1的指向发生改变所以要把const放在*的后面,不过我们可以通过函数重载来替代特化。
bool relate(const string*& s1, const string*& s2)
{return *s1 > *s2;
}这个函数也可以很好的解决问题。
2.类模板特化
这个就相比函数模板特化就有用很多了。这里我们还有细分为全特化和偏特化。下面我给大家分开讲解。
(1)全特化
我们先拿出来代码再来详细的讲
template<class T1,class T2>
class Prove {
public:Prove(){cout << "类模板" << endl;}
};
template<>
class Prove<int,int> {
public:Prove(){cout << "类模板特化" << endl;}
};
int main()
{Prove<int, int> t1;Prove<char, char>t2;return 0;
}这个也是对数据处理类型的一个筛选方便的更完整的去改善我们的代码。全特化的还不是那么方便,我们的半特化或者说是偏特化能更细致的筛选出我们需要处理的数据。
(2)偏(半)特化
意思同名字一样就是特化一部分内容比如以下
template<class T1,class T2>
class Prove {
public:Prove(){cout << "类模板" << endl;}
};
template<>
class Prove<int,int> {
public:Prove(){cout << "全int类模板特化" << endl;}
};
template<class T2>
class Prove<int,T2> {
public:Prove(){cout << "单int类模板特化" << endl;}
};
int main()
{Prove<int, int> t1;Prove<int, char>t2;Prove<char, char>t3;return 0;
}这样我们就可以着重晒窜一下第一个参数是int的数据,或者还可以筛选指针类型:
template<class T1,class T2>
class Prove {
public:Prove(){cout << "类模板" << endl;}
};
template<>
class Prove<int,int> {
public:Prove(){cout << "全int类模板特化" << endl;}
};
template<class T2>
class Prove<int,T2> {
public:Prove(){cout << "单int类模板特化" << endl;}
};
template<class T1,class T2>
class Prove<T1*, T2*> {
public:Prove(){cout << "指针类模板特化" << endl;}
};
int main()
{Prove<int, int> t1;Prove<int, char>t2;Prove<char, char>t3;Prove<int*, char*>t4;return 0;
}这样我们就可以筛选出指针类型的数据,可以非常好的增加我们代码的健壮性。
那么在筛选指针的那个代码中看一下,里面的T1,T2到底是什么类型的变量呢?指针还是什么呢?我们有typeid来看一下
template<class T1,class T2>
class Prove<T1*, T2*> {
public:Prove(){cout << typeid(T1).name() << endl << typeid(T2).name() << endl;}
};
int main()
{Prove<int*, char*>t4;return 0;
}
是不是有点诧异。不过这样的话可以更方便的对T1和T1*进行操作,如果传过来的是T1*到时对T1的操作更是别扭了。我们先简单的认识一下类模板的特化,后面我们肯定会遇到关于特化的列子,我们以后再去讲解。
包括引用和引用指针混搭也可以识别。总的来说特化对我们进行数据筛选进行了很大的作用。
五.为什么模板不可以进行声明和定义分离
现在把之前讲模板时遗留下来的问题给解决。主要的原因还是编译和链接的时候的问题。在C语言中我们学习了编译和链接。我们知道.h文件并不会进行编译。当包有.h的文件编译时会把.h文件展开这时,test和定义文件都会有一份声明,这时test文件中的传入的参数会在test上的声明上,但是test上找不到定义。而定义的文件中有定义但是不知道声明的类型,所以也没有办法进行编译。不过我们也是有解决办法的,就是显示实例化。不过这种方法并不推荐。因为这样会使自己的代码过于臃肿。下面写一段代码大家看一下。
#include"Func.h"template<class T>
T Add(const T& left, const T& right)
{cout << "T Add(const T& left, const T& right)" << endl;return left + right;
}// 显示实例化,这种解决方式很被动,需要不断添加显示实例化
template
int Add(const int& left, const int& right);template
double Add(const double& left, const double& right);template<class T>
T Add(const T& left, const T& right);// 最佳解决方案:不要分离到两个文件,写到一个文件
// 解决的原理:调用的地方,就有定义,就直接实例化结言:
好了我们基本是就把模板的内容给讲完了,我会尽快的把之前的内容补上。大家喜欢博主的内容可以关注一下哦!博主会不定时更新学习内容的!让我们一起进步,加油!