【机器学习的4种学习范式】
可以用一个非常简单的比喻来解释机器学习的学习范式,就像教小朋友认识动物一样。
🎯 核心概念:什么是学习范式?
学习范式 = 老师如何教学生
- 老师 = 我们人类
- 学生 = 机器学习模型
- 教材 = 数据
- 考试 = 模型的预测能力
📚 四种主要学习范式
1. 全监督学习 - 手把手教学 🎓
就像:爸爸指着图片教孩子
- “这是猫”、“这是狗”、“这是兔子”
- 特点:每个例子都有标准答案
- 你的情况:有25个完整标签的测试集样本
- 比喻:老师给每道题都提供了答案
2. 无监督学习 - 自己发现规律 🔍
就像:给孩子一堆玩具让他自己分类
- 孩子根据颜色、形状自己分组
- 特点:没有标准答案,让模型自己找规律
- 比喻:老师给一堆东西,让学生自己找共同点
3. 半监督学习 - 先教后自学 🎓+🔍
就像:先教孩子认识几种动物,然后让他自己看图书
- 先教:“这是猫、这是狗”
- 然后给很多动物图片让孩子自己学习
- 特点:少量有标签 + 大量无标签数据
- 你的情况:25个有标签 + 86个无标签 = 完美匹配!
- 比喻:老师先教几道例题,然后让学生自己做练习题
4. 自监督学习 - 自己出题自己答 🧩
就像:拼图游戏
- 把一张图片切成几块,让孩子拼回去
- 特点:从数据本身生成"伪标签"
- 比喻:老师把文章单词挖空,让学生填空
🎯 用一个具体的医学图像分割学习项目来理解
假如的我们持有的数据情况如下:
📁 训练集:86个医学图像(无标签)← 很多练习题
📁 测试集:25个医学图像(有标签)← 少量标准答案
对应学习范式:
| 学习范式 | 是否适合? | 原因 |
|---|---|---|
| 全监督 | ❌ 不适合 | 缺少86个训练标签 |
| 无监督 | ❌ 不适合 | 你需要具体的分割结果 |
| 半监督 | ✅ 完美适合 | 正好有标签+无标签数据 |
| 自监督 | ⚠️ 可以尝试 | 比较复杂 |
🛠️ 推荐方案
半监督学习(最适合新手)
就像:
- 先学习:用25个有标签样本认真学习
- 再练习:用86个无标签样本自己尝试
- 反复改进:根据练习结果调整学习方法
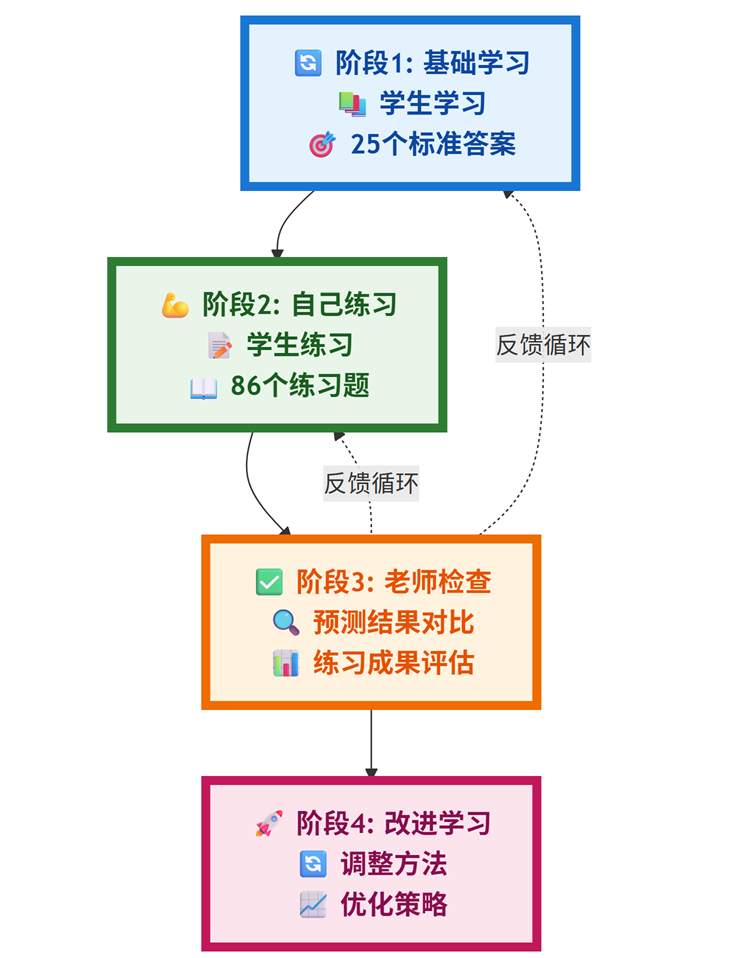
具体步骤:
# 阶段1:基础学习(用25个有标签的)
学生学习(25个标准答案)# 阶段2:自己练习(用86个无标签的)
学生练习(86个练习题)# 阶段3:老师检查(用预测结果对比)
老师检查(练习成果)# 阶段4:改进学习(调整方法)
学生改进学习方法()
💡 为什么半监督学习适合你?
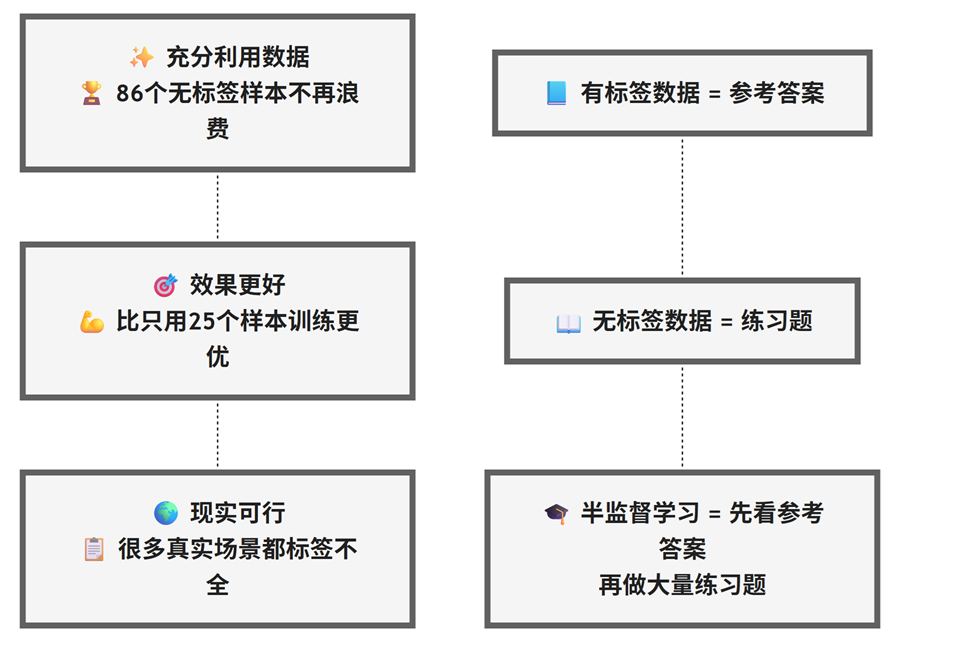
优点:
- 充分利用数据:86个无标签样本不再浪费
- 效果更好:比只用25个样本训练要好
- 现实可行:很多真实场景都标签不全
简单理解:
- 有标签数据 = 参考答案
- 无标签数据 = 练习题
- 半监督学习 = 先看参考答案,再做大量练习题
🎮 终极比喻:玩游戏
- 全监督:游戏有完整攻略
- 无监督:自由探索的沙盒游戏
- 半监督:先看几个关卡攻略,然后自己探索
- 自监督:游戏内的解谜小游戏
📝 总结
对于上述举例的医学图像分割项目:
- 现状:标签不全(86无标签 + 25有标签)
- 最佳选择:半监督学习
- 原因:既能用有限的标签,又能利用大量的无标签数据
- 新手友好度:⭐⭐⭐⭐☆(4星,相对容易理解)
现在你可以自信地说:“我的项目适合用半监督学习范式!” 🎉