360开源FG-CLIP2,给人工智能升级了精准的视觉解析系统
目录
前言
一、第一代AI视觉的“近视”根源
二、FG-CLIP2如何治好“近视”:一套全新的训练范式
2.1 两阶段分层学习:从“博学”到“精通”
2.2 “五位一体”的目标函数:精细化理解的核心引擎
三、实证为王:性能全面超越国际巨头
四、从“可用”到“好用”:FG-CLIP2的现实意义
结语:当AI看清了世界

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 360开源FG-CLIP2
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在人工智能的进化史上,让机器“看见”并理解世界,是一个里程碑式的成就。几年前,OpenAI发布的CLIP模型,通过学习海量的图文数据,第一次让AI具备了连接图像和文字的能力。你可以给它看一张猫的照片,它能知道这是一只“猫”。这解决了AI从“失明”到“看见”的问题。
但很快,我们就发现了这第一代AI视觉的天花板:它虽然“看得见”,却“看不清”。
你给它看一张复杂的照片,比如“一只金毛寻回犬在半空中接住了红色的飞盘”,它可能会识别出“狗”和“公园”,但对于“半空中”、“红色飞盘”这些精确的细节、动作和物体间的关系,它却常常感到困惑。这种“差不多”式的理解,就像一个高度近视的人看世界,只能把握一个模糊的轮廓,却无法分辨精细的纹理。
这个“细粒度理解”的瓶颈,长久以来限制了AI在许多专业领域的应用。而最近,一家中国公司——360集团的人工智能研究院,向前迈出了关键一步,他们开源的新一代视觉语言对齐模型FG-CLIP2,就像是给AI量身打造一台图像翻译机。
一、第一代AI视觉的“近视”根源
要理解FG-CLIP2的突破,我们得先知道为什么之前的模型都是“近视眼”。原因主要有两点:
(1)粗放的数据和单一的目标:第一代模型学习了数十亿张从互联网上抓取的图片和配文。但这些配文通常很粗糙,只是和图片主题相关(比如一张海滩照配文“夏日度假”),而不是精确描述。模型的训练目标也很单一:只要把“这张图”和“这段话”的整体特征对齐就行。这种训练方式,让模型擅长抓主题,却从未被系统性地要求去关注“一个穿蓝色T恤的男孩在画面左侧”这样的局部细节。
(2)语言的壁垒与评测的缺失:在FG-CLIP2之前,这个领域的研究几乎完全集中在英语世界,中文的细粒度理解能力严重滞后。更关键的是,中文世界甚至缺少一个公认的、能严格评估模型“看得清不清”的综合性测试标准。没有清晰的“视力表”,开发者们自然也缺乏明确的优化方向。
二、FG-CLIP2如何治好“近视”:一套全新的训练范式
FG-CLIP2的代际突破,不在于堆砌更多的数据或更大的参数,而在于一套从根本上改变模型学习方式的全新范式。
2.1 两阶段分层学习:从“博学”到“精通”
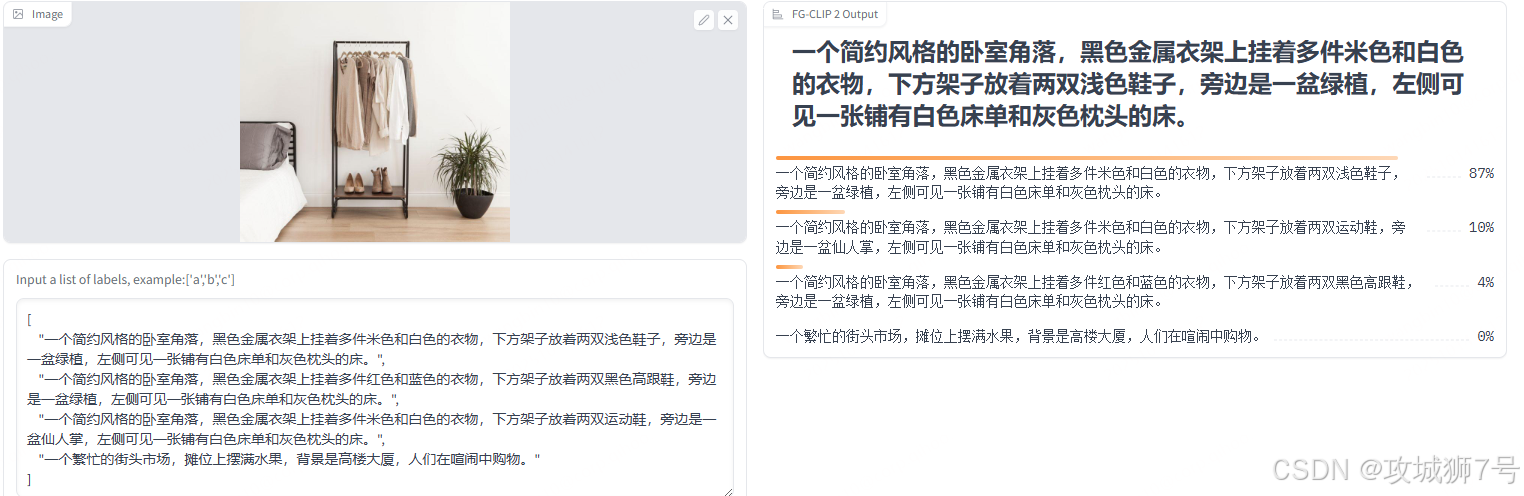
FG-CLIP2的训练过程,模拟了人类从宽泛认知到深入理解的学习路径,分为两个阶段:
(1)第一阶段:构建坚实的语义基座。在这个阶段,模型的目标是建立广泛的图文联系。它不再只学习图片的简短标题,而是同时学习一个由大模型生成的、内容详尽的长描述。短文本提供了核心标签,长描述则注入了丰富的上下文、物体属性和结构化知识。通过同时消化这两种文本,模型在初期就构建了远比过去深厚的语义基础。
(2)第二阶段:精雕细琢的细粒度对齐。当模型具备了扎实的全局理解能力后,训练重心彻底转向“细节”。这个阶段引入了带有精确“边界框”(bounding box)和对应区域描述的数据集。这就好比告诉模型:“注意看,图中这个框里的区域,对应的描述是‘一只红色的猫’”。
2.2 “五位一体”的目标函数:精细化理解的核心引擎
为了让模型真正学会“看细节”,FG-CLIP2不再使用单一的训练目标,而是设计了一套由五个目标函数组成的“组合拳”,从不同维度打磨模型的能力:
(1)全局对齐:延续并优化传统方法,确保模型在追求细节的同时,不会丢失对整体场景的把握。
(2)细粒度视觉学习:这是实现“视觉聚焦”的关键。它训练模型将图像中特定区域的视觉特征与该区域的文本描述对齐,迫使模型学会关注局部。
(3)细粒度文本学习:为了提升语言上的辨别力,这个目标引入了“难负样本”机制。比如,当模型学习“一只红色的猫”时,会给它看大量“一只橙色的猫”、“两只红色的猫”这样的“干扰项”,训练它分辨出这些细微的语言差异。
(4)跨模态排序损失:强化正确图文对的“优势地位”,要求正确匹配的得分要比错误匹配的得分高出一个明显的“安全边界”。
(5)文本域内对比损失:这是解决细粒度文本混淆问题的关键。很多区域描述本身就非常相似(如“一扇绿色的木门”和“一扇漆成绿色的门”),这个目标专门在文本内部进行对比学习,迫使模型为这些“近义词”分配出有区分度的表征。
通过这套精心设计的约束,FG-CLIP2被系统性地塑造成为一个既能把握全局,又能洞察微末,并且能驾驭中英双语复杂性的第二代跨模态模型。
三、实证为王:性能全面超越国际巨头
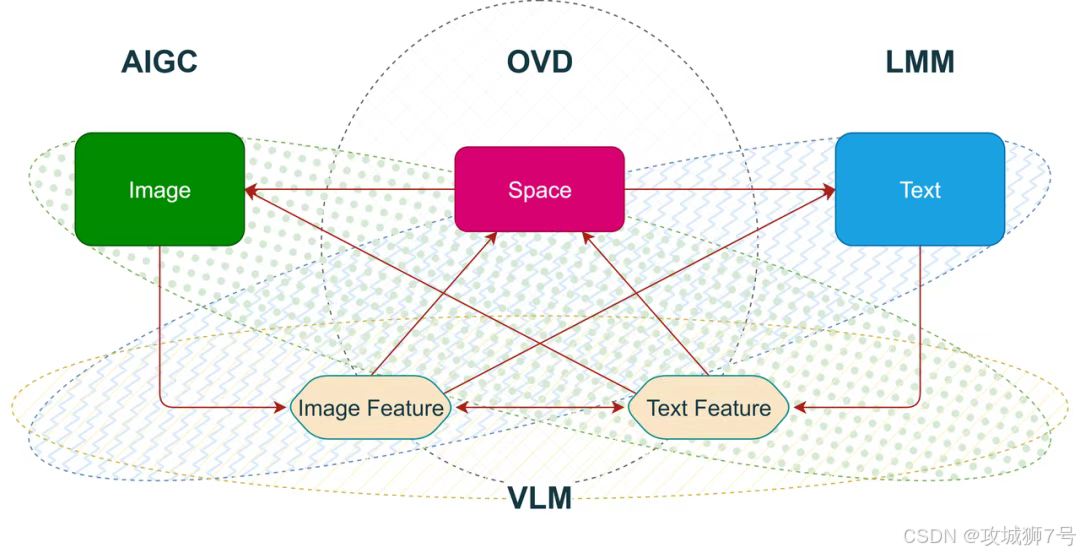
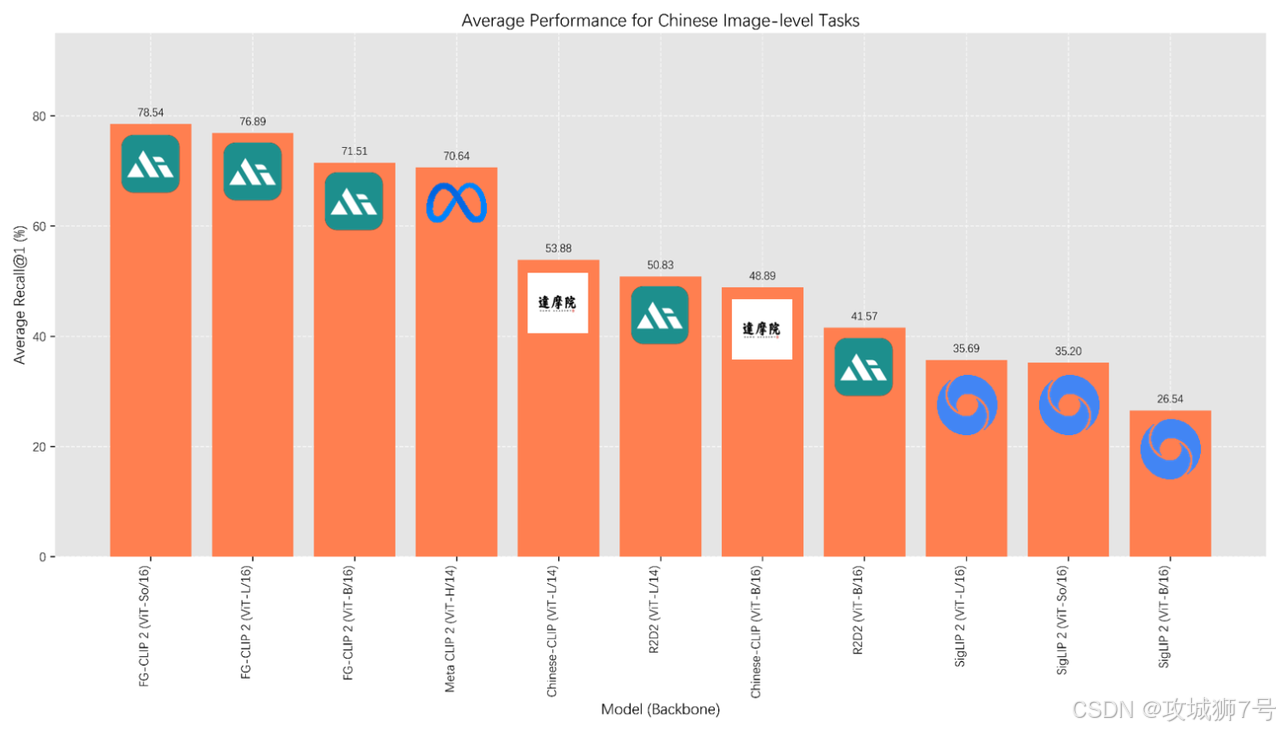
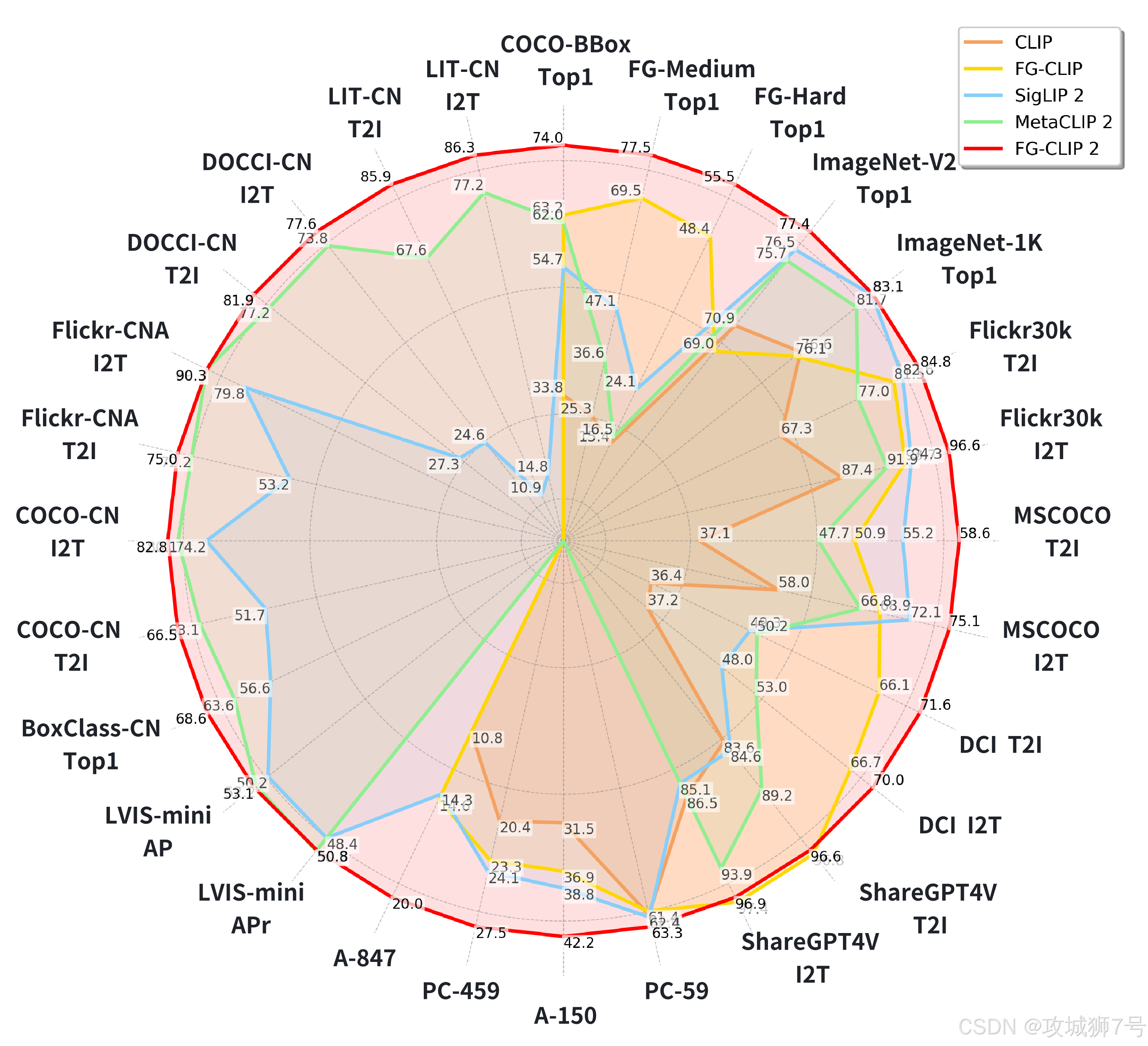
FG-CLIP2的先进性,最终体现在了横跨8大类、29个公开数据集的测试结果上。
(1)树立中文评测新标杆:首先,为了解决中文领域“视力表”缺失的问题,360团队构建并推出了一套全新的中文评测基准,填补了行业空白。
(2)核心任务突破:在最能体现细粒度理解能力的各项测试中,FG-CLIP2都以大幅领先的优势取得了当前最佳(SOTA)成绩,无论是在英文还是中文数据集上。
(3)更小的模型,更强的性能:尤其值得一提的是,在多个中英文榜单上,10亿参数的FG-CLIP2,其表现甚至超越了18亿参数的Meta CLIP 2。这有力地证明了其领先是源于训练范式的高效,是“代际领先”而非“参数堆砌”。
四、从“可用”到“好用”:FG-CLIP2的现实意义
这项技术的突破,绝非仅仅是刷新了几个榜单。它将从根本上提升AI在现实世界中的应用能力,推动AI从“感知”走向“认知”,从“可用”走向“好用”。
(1)更精准的以图搜图:未来,你可以用更复杂的语言进行图片搜索,比如“找一张左边是山、右边是湖、湖上有一艘白帆小船的风景照”,AI将能精确地理解并找到它。
(2)更强大的内容生成:当AI作画或生成视频时,它能更准确地理解和执行复杂的指令,比如“生成一只左爪抬起、右耳耷拉的斑点狗”,画面的细节将变得更加可控和自然。
(3)更可靠的专业应用:在工业质检、自动驾驶、医疗影像分析等对细节识别有极致要求的领域,FG-CLIP2这样的技术将成为关键的视觉底座。它能帮助自动驾驶系统看清躲在树荫下的行人,帮助医生发现蛋白质分子的细微变化。
(4)更聪明的多模态大模型:当FG-CLIP2被用作视觉编码器(即AI的“眼睛”)集成到更大的多模态模型中时,能全面提升这些大模型在高级推理任务上的表现,是构建下一代LMM的理想基石。
结语:当AI看清了世界
从CLIP到FG-CLIP2,我们见证了AI视觉能力的一次关键跃迁。如果说第一代模型解决了“图文能否对齐”的问题,那么FG-CLIP2引领的第二代模型,则致力于解决“能否深入理解”的核心难题。
这次全球领先的突破,来自一家中国的企业,这本身就极具意义。它标志着中国AI正在从应用层的快速跟进,走向更基础、更核心的底层技术创新。
当AI终于拥有了一双能看清世界的“高清眼睛”,它所能创造的价值和可能性将被极大地拓展。而这个世界,也将因此重新看见AI。
FG-CLIP2模型的开源地址为:
https://github.com/360cvgroup/fg-clip
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!