(undone) MIT6.S081 Lec14 File systems 学习笔记
url: https://mit-public-courses-cn-translatio.gitbook.io/mit6-s081/lec14-file-systems-frans
Why Interesting
从一个问题开始:既然你每天都使用了文件系统,XV6的文件系统与你正在使用的文件系统有什么区别。接下来我会点名:
学生回答:其中一点是,XV6支持的文件大小远小于其他文件系统。其次一些文件的文件名也较短。第三点,我不认为
XV6的文件系统有copy-on-write。
Frans教授:很好,那有什么相似的地方吗?
学生回答:基本的结构是类似的,比如说都有文件名,都有inode,目录等等。
Fans教授:很好,我再问一个同学,XV6的文件系统与你正在使用的文件系统有什么异同?
学生回答:文件目录结构都是层级的。
接下来让我列出一些文件系统突出的特性:
- 其中一点刚刚有同学提到了,就是对于用户友好的文件名,具体来说就是层级的路径名,这可以帮助用户组织目录中的文件。
- 通过将文件命名成方便易记的名字,可以在用户之间和进程之间更简单的共享文件。
- 相比我们已经看过的XV6其他子系统,这一点或许是最重要的,文件系统提供了持久化。这意味着,我可以关闭一个计算机,过几天再开机而文件仍然在那,我可以继续基于文件工作。这一点与进程和其他资源不一样,这些资源在计算机重启时就会消失,之后你需要重新启动它们,但是文件系统就可以提供持久化。

所以你们都使用了文件系统,接下来几节课我们将学习它内部是如何工作的。出于以下原因,文件系统背后的机制还比较有意思:
- 文件系统对硬件的抽象较为有用,所以理解文件系统对于硬件的抽象是如何实现的还是有点意思的。
- 除此之外,还有个关键且有趣的地方就是crash safety。有可能在文件系统的操作过程中,计算机崩溃了,在重启之后你的文件系统仍然能保持完好,文件系统的数据仍然存在,并且你可以继续使用你的大部分文件。如果文件系统操作过程中计算机崩溃了,然后你重启之后文件系统不存在了或者磁盘上的数据变了,那么崩溃的将会是你。所以crash safety是一个非常重要且经常出现的话题,我们下节课会专门介绍它。
- 之后是一个通用的问题,如何在磁盘上排布文件系统。例如目录和文件,它们都需要以某种形式在磁盘上存在,这样当你重启计算机时,所有的数据都能恢复。所以在磁盘上有一些数据结构表示了文件系统的结构和内容。在XV6中,使用的数据结构非常简单,因为XV6是专门为教学目的创建的。真实的文件系统通常会更加复杂。但是它们都是磁盘上保存的数据结构,我们在今天的课程会重点看这部分。
- 最后一个有趣的话题是性能。文件系统所在的硬件设备通常都较慢,比如说向一个SSD磁盘写数据将会是毫秒级别的操作,而在一个毫秒内,计算机可以做大量的工作,所以尽量避免写磁盘很重要,我们将在几个地方看到提升性能的代码。比如说,所有的文件系统都有buffer cache或者叫block cache。同时这里会有更多的并发,比如说你正在查找文件路径名,这是一个多次交互的操作,首先要找到文件结构,然后查找一个目录的文件名,之后再去查找下一个目录等等。你会期望当一个进程在做路径名查找时,另一个进程可以并行的运行。这样的并行运行在文件系统中将会是一个大的话题。
除此之外,你会对文件系统感兴趣是因为这是接下来两个lab的内容。下一个lab完全关注在文件系统,下下个lab结合了虚拟内存和文件系统。即使是这周的lab,也会尝试让buffer cache可以支持更多的并发。所以这就是为什么文件系统是有趣的。
File system实现概述
为了理解文件系统必须提供什么能力,让我们再看一下一些与文件系统相关的基础系统调用。从这些系统调用接口,我们将可以推断出有关文件系统实现的一些细节,这些系统调用我们在之前的课程已经看过了。首先让我们来看一个简单的场景,假设我们创建了文件“x/y”,或者说在目录x中创建了文件y,同时我们需要提供一些标志位,现在我们还不太关心标志位所以我会忽略它。
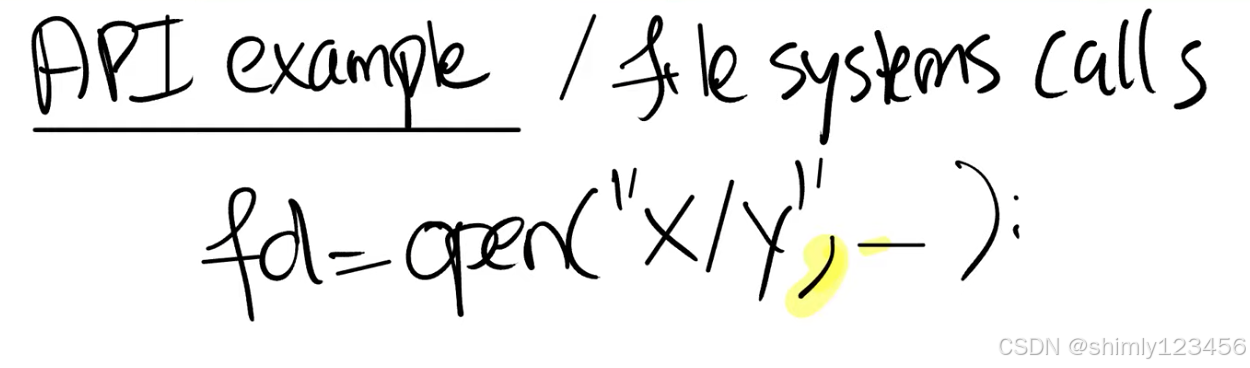
上面的系统调用会创建文件,并返回文件描述符给调用者。调用者也就是用户应用程序可以对文件描述符调用write,有关write我们在之前已经看过很多次了,这里我们向文件写入“abc”三个字符。
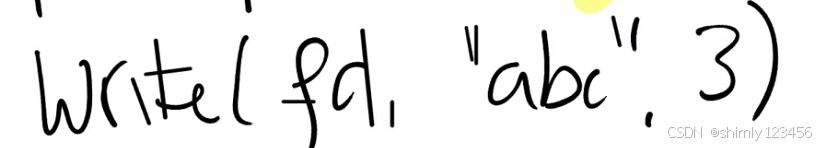
从这两个调用已经可以看出一些信息了:
- 首先出现在接口中的路径名是可读的名字,而不是一串数字,它是由用户选择的字符串。
- write系统调用并没有使用offset作为参数,所以写入到文件的哪个位置是隐式包含在文件系统中,文件系统在某个位置必然保存了文件的offset。因为如果你再调用write系统调用,新写入的数据会从第4个字节开始。
除此之外,还有一些我们之前没有看过的有趣的系统调用。例如XV6和所有的Unix文件系统都支持通过系统调用创建链接,给同一个文件指定多个名字。你可以通过调用link系统调用,为之前创建的文件“x/y”创建另一个名字“x/z”。
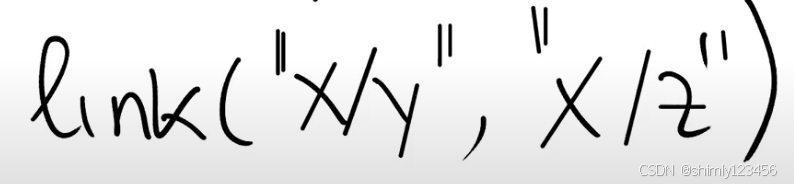
所以文件系统内部需要以某种方式跟踪指向同一个文件的多个文件名。
我们还可能会在文件打开时,删除或者更新文件的命名空间。例如,用户可以通过unlink系统调用来删除特定的文件名。如果此时相应的文件描述符还是打开的状态,那我们还可以向文件写数据,并且这也能正常工作。
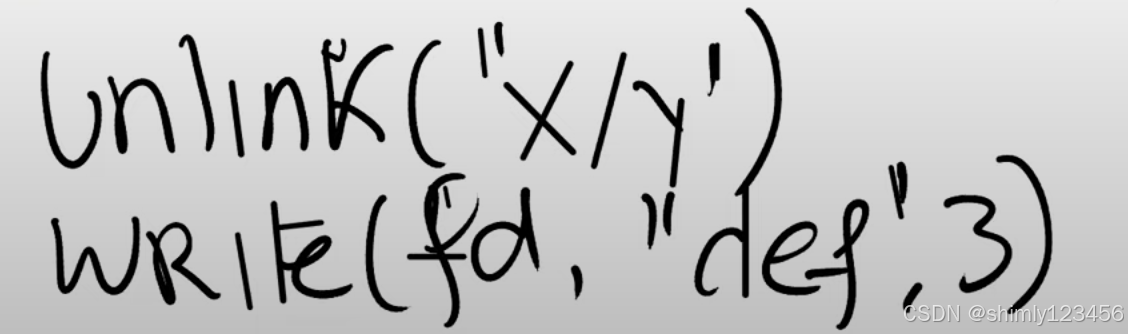
所以,在文件系统内部,文件描述符必然与某个对象关联,而这个对象不依赖文件名。这样,即使文件名变化了,文件描述符仍然能够指向或者引用相同的文件对象。所以,实际上操作系统内部需要对于文件有内部的表现形式,并且这种表现形式与文件名无关。

除此之外,我还想提一点。文件系统的目的是实现上面描述的API,也即是典型的文件系统API。但是,这并不是唯一构建一个存储系统的方式。如果只是在磁盘上存储数据,你可以想出一个完全不同的API。举个例子,数据库也能持久化的存储数据,但是数据库就提供了一个与文件系统完全不一样的API。所以记住这一点很重要:还存在其他的方式能组织存储系统。我们这节课关注在文件系统,文件系统通常由操作系统提供,而数据库如果没有直接访问磁盘的权限的话,通常是在文件系统之上实现的(注,早期数据库通常直接基于磁盘构建自己的文件系统,因为早期操作系统自带的文件系统在性能上较差,且写入不是同步的,进而导致数据库的ACID不能保证。不过现代操作系统自带的文件系统已经足够好,所以现代的数据库大部分构建在操作系统自带的文件系统之上)。
学生提问:link增加了了对于文件的一个引用,unlink减少了一个引用?
Frans教授:是的。我们稍后会介绍更多相关的内容。
学生提问:能介绍一下soft link和hard link吗?
Frans教授:我今天不会讨论这些内容。但是你们将会在下一个File system lab中实现soft link。所以XV6本身实现
了hard link,需要你们来实现soft link。
学生提问:link是对inode做操作,而不是对文件描述符做操作,对吧?
Frans教授:是的,link是对inode做操作,我们接下来介绍这部分内容。
接下来我们看一下文件系统的结构。文件系统究竟维护了什么样的结构来实现前面介绍的API呢?
首先,最重要的可能就是inode,这是代表一个文件的对象,并且它不依赖于文件名。实际上,inode是通过自身的编号来进行区分的,这里的编号就是个整数。所以文件系统内部通过一个数字,而不是通过文件路径名引用inode。同时,基于之前的讨论,inode必须有一个link count来跟踪指向这个inode的文件名的数量。一个文件(inode)只能在link count为0的时候被删除。实际的过程可能会更加复杂,实际中还有一个openfd count,也就是当前打开了文件的文件描述符计数。一个文件只能在这两个计数器都为0的时候才能被删除。
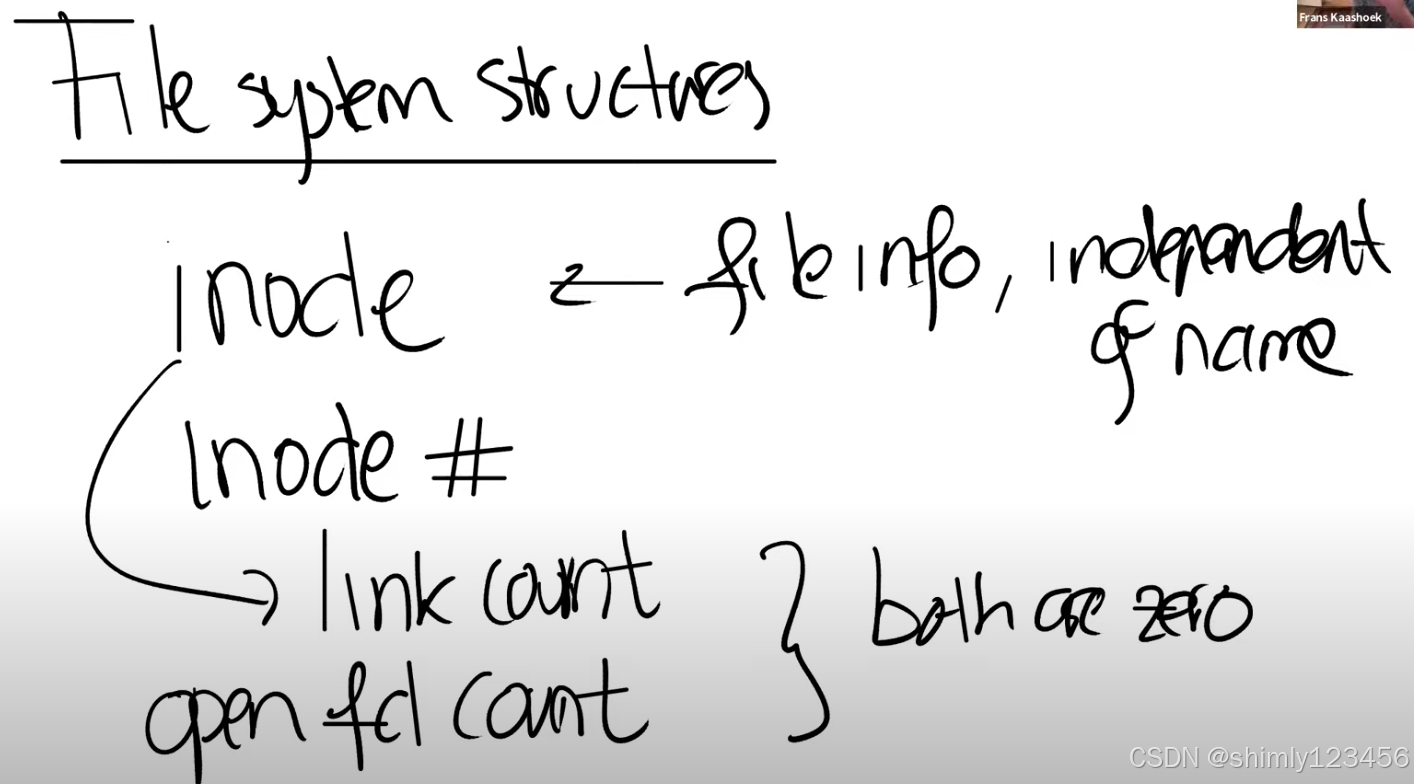
同时基于之前的讨论,我们也知道write和read都没有针对文件的offset参数,所以文件描述符必然自己悄悄维护了对于文件的offset。

文件系统中核心的数据结构就是inode和file descriptor。后者主要与用户进程进行交互。
尽管文件系统的API很相近并且内部实现可能非常不一样。但是很多文件系统都有类似的结构。因为文件系统还挺复杂的,所以最好按照分层的方式进行理解。可以这样看:
- 在最底层是磁盘,也就是一些实际保存数据的存储设备,正是这些设备提供了持久化存储。
- 在这之上是buffer cache或者说block cache,这些cache可以避免频繁的读写磁盘。这里我们将磁盘中的数据保存在了内存中。
- 为了保证持久性,再往上通常会有一个logging层。许多文件系统都有某种形式的logging,我们下节课会讨论这部分内容,所以今天我就跳过它的介绍。
- 在logging层之上,XV6有inode cache,这主要是为了同步(synchronization),我们稍后会介绍。inode通常小于一个disk block,所以多个inode通常会打包存储在一个disk block中。为了向单个inode提供同步操作,XV6维护了inode cache。
- 再往上就是inode本身了。它实现了read/write。
- 再往上,就是文件名,和文件描述符操作。

不同的文件系统组织方式和每一层可能都略有不同,有的时候分层也没有那么严格,即使在XV6中分层也不是很严格,但是从概念上来说这里的结构对于理解文件系统还是有帮助的。实际上所有的文件系统都有组件对应这里不同的分层,例如buffer cache,logging,inode和路径名。
How file system uses disk
TODO: here