DeepSeek DeepEP学习(二)normal notify dispatch
背景
相对于low latency的追求延迟,normal版本追求更高的带宽,传统all2all算子在发送到同一台机器的不同rank时,会存在重复token的发送,而DeepSeek团队使用的机型的机内带宽大于机间带宽,因此DeepSeek提出了两阶段的all2all算法,第一阶段将发往同一机器所有token发送给当前机器的同号卡,然后再通过这个gpu进行机内的转发。
dispatch的过程分为两步,第一步通过notify dispatch计算一些meta信息,比如每台机器将会收到多少token,然后再执行实际的dispatch,本节主要介绍notify dispatch。
用法
还是以github中的demo为例
- 首先获取nvlink和rdma各需要占多少内存
- 然后初始化Buffer
- dispatch
a. get_dispatch_layout获取meta信息,比如发送到每个expert多少token
b. 执行dispatch
def get_buffer(group: dist.ProcessGroup, hidden_bytes: int) -> Buffer:
num_nvl_bytes, num_rdma_bytes = 0, 0
for config in (Buffer.get_dispatch_config(group.size()), Buffer.get_combine_config(group.size())):
num_nvl_bytes = max(config.get_nvl_buffer_size_hint(hidden_bytes, group.size()), num_nvl_bytes)
num_rdma_bytes = max(config.get_rdma_buffer_size_hint(hidden_bytes, group.size()), num_rdma_bytes)
# Allocate a buffer if not existed or not enough buffer size
# NOTES: the adaptive routing configuration of the network **must be off**
if _buffer is None or _buffer.group != group or _buffer.num_nvl_bytes < num_nvl_bytes or _buffer.num_rdma_bytes < num_rdma_bytes:
_buffer = Buffer(group, num_nvl_bytes, num_rdma_bytes)
return _buffer
def dispatch_forward(...):
# Calculate layout before actual dispatch
num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, previous_event = \
_buffer.get_dispatch_layout(...)
# Do MoE dispatch
# NOTES: the CPU will wait for GPU's signal to arrive, so this is not compatible with CUDA graph
# For more advanced usages, please refer to the docs of the `dispatch` function
recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event = \
_buffer.dispatch(...)
# For event management, please refer to the docs of the `EventOverlap` class
return recv_x, recv_topk_idx, recv_topk_weights, num_recv_tokens_per_expert_list, handle, event
Buffer创建和初始化
num_nvl_bytes和num_rdma_bytes分别表示nvlink和rdma各需要多少buffer,这个等到介绍dispatch的时候再看。
rdma_rank表示节点号,nvl_rank表示机内的卡号。
Buffer::Buffer(int rank, int num_ranks, int64_t num_nvl_bytes, int64_t num_rdma_bytes, bool low_latency_mode) {
// Task fifo memory
int64_t fifo_bytes = sizeof(int) * NUM_MAX_FIFO_SLOTS;
int64_t buffer_ptr_bytes = sizeof(void*) * NUM_MAX_NVL_PEERS;
int64_t task_ptr_bytes = sizeof(int*) * NUM_MAX_NVL_PEERS;
// Get ranks
CUDA_CHECK(cudaGetDevice(&device_id));
rdma_rank = rank / NUM_MAX_NVL_PEERS, nvl_rank = rank % NUM_MAX_NVL_PEERS;
num_rdma_ranks = std::max(1, num_ranks / NUM_MAX_NVL_PEERS), num_nvl_ranks = std::min(num_ranks, NUM_MAX_NVL_PEERS);
}
然后开始通过cudaMalloc一次性分配所有的内存到buffer_ptrs[nvl_rank],并通过cudaIpcGetMemHandle获取ipc handle,之后会广播给其他rank。buffer_ptr的组成如下图
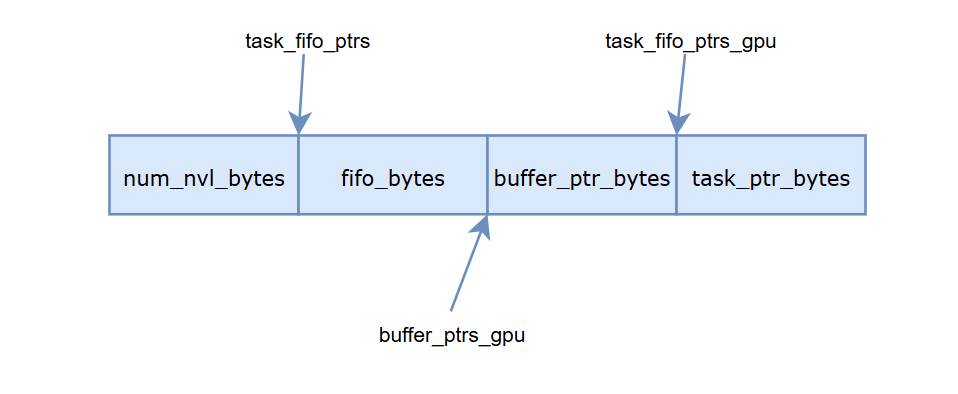
if (num_nvl_bytes > 0) {
// Local IPC: alloc local memory and set local IPC handle
CUDA_CHECK(cudaMalloc(&buffer_ptrs[nvl_rank], num_nvl_bytes + fifo_bytes + buffer_ptr_bytes + task_ptr_bytes));
CUDA_CHECK(cudaIpcGetMemHandle(&ipc_handles[nvl_rank], buffer_ptrs[nvl_rank]));
buffer_ptrs_gpu = reinterpret_cast<void**>(reinterpret_cast<uint8_t*>(buffer_ptrs[nvl_rank]) + num_nvl_bytes + fifo_bytes);
// Set task fifo
task_fifo_ptrs[nvl_rank] = reinterpret_cast<int*>(reinterpret_cast<uint8_t*>(buffer_ptrs[nvl_rank]) + num_nvl_bytes);
task_fifo_ptrs_gpu = reinterpret_cast<int**>(reinterpret_cast<uint8_t*>(buffer_ptrs[nvl_rank]) + num_nvl_bytes + fifo_bytes + buffer_ptr_bytes);
}
然后分配用于cpu和gpu同步的内存,通过cudaMallocHost分配host的内存,然后通过cudaHostGetDevicePointer获取device端访问这段内存的地址。
CUDA_CHECK(cudaMallocHost(&moe_recv_counter, sizeof(int64_t), cudaHostAllocMapped));
CUDA_CHECK(cudaHostGetDevicePointer(&moe_recv_counter_mapped, const_cast<int*>(moe_recv_counter), 0));
*moe_recv_counter = -1;
// MoE expert-level counter
CUDA_CHECK(cudaMallocHost(&moe_recv_expert_counter, sizeof(int) * NUM_MAX_LOCAL_EXPERTS, cudaHostAllocMapped));
CUDA_CHECK(cudaHostGetDevicePointer(&moe_recv_expert_counter_mapped, const_cast<int*>(moe_recv_expert_counter), 0));
for (int i = 0; i < NUM_MAX_LOCAL_EXPERTS; ++ i)
moe_recv_expert_counter[i] = -1;
// MoE RDMA-level counter
if (num_rdma_ranks > 0) {
CUDA_CHECK(cudaMallocHost(&moe_recv_rdma_counter, sizeof(int), cudaHostAllocMapped));
CUDA_CHECK(cudaHostGetDevicePointer(&moe_recv_rdma_counter_mapped, const_cast<int*>(moe_recv_rdma_counter), 0));
*moe_recv_rdma_counter = -1;
}
然后通过allgather获取全局的所有ipc handle,由于normal算子是同号卡进行互联,所以rdma_rank为0的所有卡都会执行创建unique_id的过程,然后广播unique_id,每个rank的root_unique_id就是rdma_rank0机器的同号卡的unique_id。
ipc_handles = [None, ] * self.group_size
local_ipc_handle = self.runtime.get_local_ipc_handle()
dist.all_gather_object(ipc_handles, local_ipc_handle, group)
# Synchronize NVSHMEM unique IDs
root_unique_id = None
if self.runtime.get_num_rdma_ranks() > 1 or low_latency_mode:
nvshmem_unique_ids = [None, ] * self.group_size
if (low_latency_mode and self.rank == 0) or (not low_latency_mode and self.runtime.get_rdma_rank() == 0):
root_unique_id = self.runtime.get_local_nvshmem_unique_id()
dist.all_gather_object(nvshmem_unique_ids, root_unique_id, group)
root_unique_id = nvshmem_unique_ids[0 if low_latency_mode else self.runtime.get_root_rdma_rank(True)]
# Make CPP runtime available
self.runtime.sync(device_ids, ipc_handles, root_unique_id)
sync的过程中会将当前机器上其他卡的ipc handle通过cudaIpcOpenMemHandle映射到自己地址空间,保存到buffer_ptrs[i],这样就可以访问其他卡的空间了。
void Buffer::sync(...) {
if (num_nvl_bytes > 0) {
for (int i = 0, offset = rdma_rank * num_nvl_ranks; i < num_nvl_ranks; ++ i) {
EP_HOST_ASSERT(all_gathered_handles[offset + i].has_value());
auto handle_str = std::string(all_gathered_handles[offset + i].value());
if (offset + i != rank) {
std::memcpy(ipc_handles[i].reserved, handle_str.c_str(), CUDA_IPC_HANDLE_SIZE);
CUDA_CHECK(cudaIpcOpenMemHandle(&buffer_ptrs[i], ipc_handles[i], cudaIpcMemLazyEnablePeerAccess));
task_fifo_ptrs[i] = reinterpret_cast<int*>(reinterpret_cast<uint8_t*>(buffer_ptrs[i]) + num_nvl_bytes);
} else {
EP_HOST_ASSERT(std::memcmp(ipc_handles[i].reserved, handle_str.c_str(), CUDA_IPC_HANDLE_SIZE) == 0);
}
}
// Copy all buffer and task pointers to GPU
CUDA_CHECK(cudaMemcpy(buffer_ptrs_gpu, buffer_ptrs, sizeof(void*) * NUM_MAX_NVL_PEERS, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaMemcpy(task_fifo_ptrs_gpu, task_fifo_ptrs, sizeof(int*) * NUM_MAX_NVL_PEERS, cudaMemcpyHostToDevice));
CUDA_CHECK(cudaDeviceSynchronize());
}
...
}
buffer初始化后执行get_dispatch_layout,这里就是通过遍历topk_idx,计算出num_tokens_per_rank等信息,表示当前rank会有多少token发送到每一个rank,每一个节点等。
def get_dispatch_layout(self, topk_idx: torch.Tensor, num_experts: int,
previous_event: Optional[EventOverlap] = None, async_finish: bool = False,
allocate_on_comm_stream: bool = False) -> \
Tuple[torch.Tensor, Optional[torch.Tensor], torch.Tensor, torch.Tensor, EventOverlap]:
"""
Calculate the layout required for later communication.
Arguments:
topk_idx: `[num_tokens, num_topk]`, dtype must be `torch.int64`, the expert indices selected by each token,
`-1` means no selections.
num_experts: the number of experts.
previous_event: the event to wait before actually executing the kernel.
async_finish: the current stream will not wait for the communication kernels to be finished if set.
allocate_on_comm_stream: control whether all the allocated tensors' ownership to be on the communication stream.
Returns:
num_tokens_per_rank: `[num_ranks]` with `torch.int`, the number of tokens to be sent to each rank.
num_tokens_per_rdma_rank: `[num_rdma_ranks]` with `torch.int`, the number of tokens to be sent to each RDMA
rank (with the same GPU index), return `None` for intranode settings.
num_tokens_per_expert: `[num_experts]` with `torch.int`, the number of tokens to be sent to each expert.
is_token_in_rank: `[num_tokens, num_ranks]` with `torch.bool`, whether a token be sent to a rank.
event: the event after executing the kernel (valid only if `async_finish` is set).
"""
num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, event = \
self.runtime.get_dispatch_layout(topk_idx, num_experts, getattr(previous_event, 'event', None),
async_finish, allocate_on_comm_stream)
return num_tokens_per_rank, num_tokens_per_rdma_rank, num_tokens_per_expert, is_token_in_rank, EventOverlap(event)
基础数据结构
DeepEP引入了多种buffer用于多个sm管理向多个rank发送和接收的数据。
Buffer
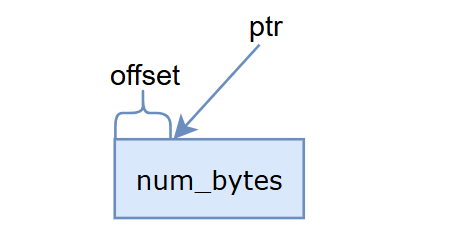
buffer管理一段num_bytes长度的内存,offset默认为0
SymBuffer
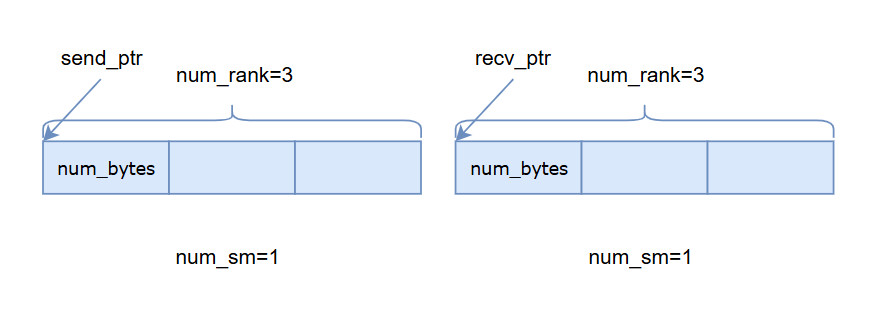
SymBuffer用于多个sm对一段内存的统一访存,如下图,展示了一个SymBuffer,假设rank数为3,2个sm,那么sm为1的线程的send_ptr和recv_ptr如箭头所示。

AsymBuffer
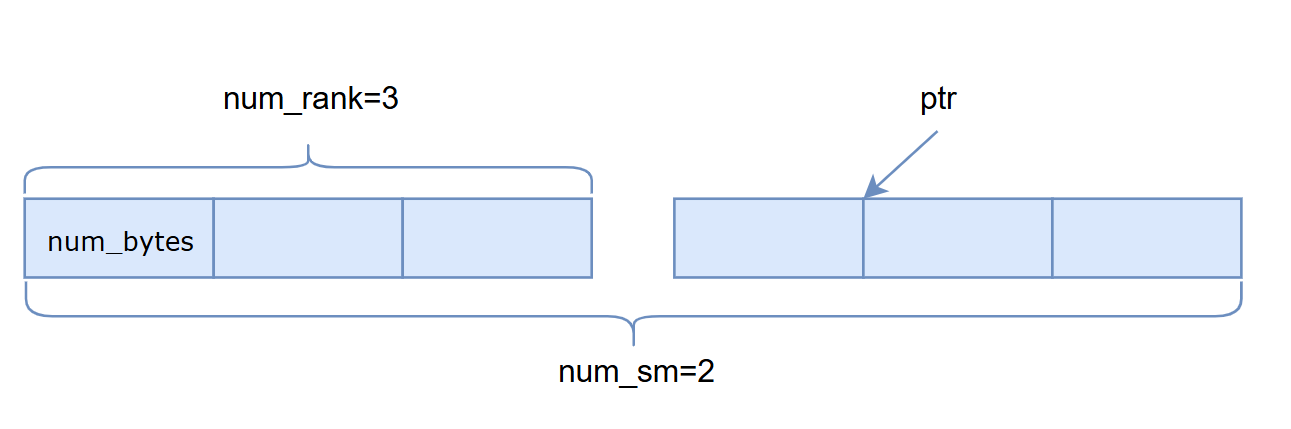
AsymBuffer同样用于多个sm对一段内存的统一访存,如下图,假设rank数为3,2个sm,offset为1,offset表示使用第几个rank部分的内存,那么sm为1的线程的ptr如下图所示。另外,AsymBuffer支持管理多块buffer,这里没有展示。
notify_dispatch
num_rdma_ranks为节点数,num_rdma_experts表示一个节点有多少expert,num_nvl_experts表示一个rank多少expert
__global__ void notify_dispatch(...) {
auto sm_id = static_cast<int>(blockIdx.x);
auto thread_id = static_cast<int>(threadIdx.x), warp_id = thread_id / 32, lane_id = get_lane_id();
auto num_threads = static_cast<int>(blockDim.x), num_warps = num_threads / 32;
auto rdma_rank = rank / NUM_MAX_NVL_PEERS, nvl_rank = rank % NUM_MAX_NVL_PEERS;
auto num_rdma_experts = num_experts / kNumRDMARanks, num_nvl_experts = num_rdma_experts / NUM_MAX_NVL_PEERS;
...
}
sm0
notify_dispatch的sm[0]会将自己的num_tokens_per_rank等信息发送给其他的rank,首先是执行一个全局barrier,因为是同号卡建通信组,所以这里的第32个线程通过nvshmem_barrier进行机器间同号卡的barrier,然后warp0执行barrier_device进行机内所有卡的barrier。
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
// Communication with others
// Global barrier: the first warp do intra-node sync, the second warp do internode sync
EP_DEVICE_ASSERT(num_warps > 1);
EP_DEVICE_ASSERT(kNumRDMARanks <= num_threads);
if (thread_id == 32)
nvshmem_barrier_with_same_gpu_idx<kLowLatencyMode>(rdma_team);
barrier_device<NUM_MAX_NVL_PEERS>(task_fifo_ptrs, head, nvl_rank);
move_fifo_slots<NUM_MAX_NVL_PEERS>(head);
__syncthreads();
}
...
}
__forceinline__ __device__ void barrier_device(int **task_fifo_ptrs, int head, int rank, int tag = 0) {
auto thread_id = static_cast<int>(threadIdx.x);
EP_DEVICE_ASSERT(kNumRanks <= 32);
if (thread_id < kNumRanks) {
atomicAdd_system(task_fifo_ptrs[rank] + head + thread_id, FINISHED_SUM_TAG);
memory_fence();
atomicSub_system(task_fifo_ptrs[thread_id] + head + rank, FINISHED_SUM_TAG);
}
timeout_check<kNumRanks>(task_fifo_ptrs, head, rank, 0, tag);
}
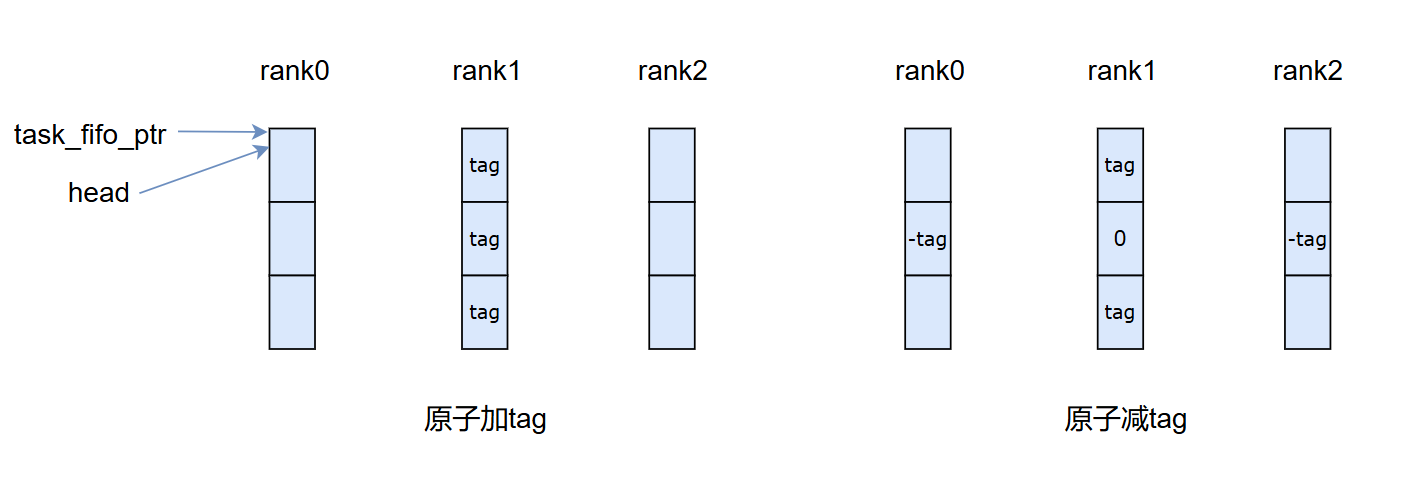
如下图所示,假设当前rank为1,机器上共有3个gpu,那么rank1的当前warp往自己的task_fifo_ptrs的所有rank原子加tag,然后去其他所有卡的task_fifo_ptrs的第1个位置减去tag,然后开始轮询自己的task_fifo_ptrs每个位置,如果都为0,说明所有rank都执行到了这一步,就完成了barrier。
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
auto rdma_buffer_ptr_int = reinterpret_cast<int*>(rdma_buffer_ptr);
auto rdma_recv_num_tokens_mixed = SymBuffer<int>(rdma_buffer_ptr, NUM_MAX_NVL_PEERS + num_rdma_experts + 1, kNumRDMARanks);
// Clean up for later data dispatch
EP_DEVICE_ASSERT(rdma_recv_num_tokens_mixed.total_bytes <= rdma_clean_offset * sizeof(int));
#pragma unroll
for (int i = thread_id; i < rdma_num_int_clean; i += num_threads)
rdma_buffer_ptr_int[rdma_clean_offset + i] = 0;
}
...
}
然后开始初始化发送数据,rdma_buffer_ptr就是通过nvshmem分配的对称内存,通过创建SymBuffer rdma_recv_num_tokens_mixed进行管理。
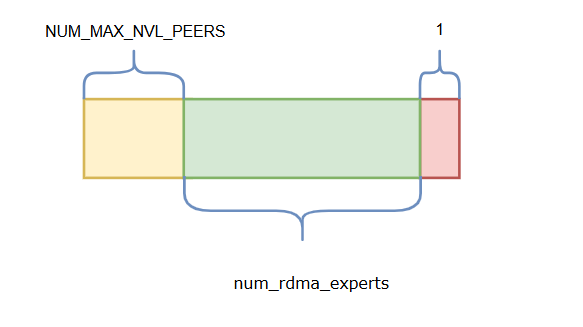
与上图不同的是rdma_recv_num_tokens_mixed只有一个sm,num_bytes为NUM_MAX_NVL_PEERS + num_rdma_experts + 1,总rank数为节点数
其中发往每一个rdma_rank的num_bytes的数据组织格式如下图,黄色部分长度为NUM_MAX_NVL_PEERS,用于存储当前gpu向对端rdma_rank上的每一个gpu发送多少token,绿色部分长度为num_rdma_experts,表示当前gpu向对端rdma_rank上每一个expert发送多少token,红色部分长度为1,表示当前gpu向对端rdma_rank上发送多少token。
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
// Copy to send buffer
#pragma unroll
for (int i = thread_id; i < num_ranks; i += num_threads)
rdma_recv_num_tokens_mixed.send_buffer(i / NUM_MAX_NVL_PEERS)[i % NUM_MAX_NVL_PEERS] = num_tokens_per_rank[i];
#pragma unroll
for (int i = thread_id; i < num_experts; i += num_threads)
rdma_recv_num_tokens_mixed.send_buffer(i / num_rdma_experts)[NUM_MAX_NVL_PEERS + i % num_rdma_experts] = num_tokens_per_expert[i];
if (thread_id < kNumRDMARanks)
rdma_recv_num_tokens_mixed.send_buffer(thread_id)[NUM_MAX_NVL_PEERS + num_rdma_experts] = num_tokens_per_rdma_rank[thread_id];
__syncthreads();
}
...
}
假设当前rank向rdma_rank为1的三个卡分别发送6,5,9个token,那么当前rank在填充rdma_rank1 num_tokens_per_rank之后的send buffer如下所示
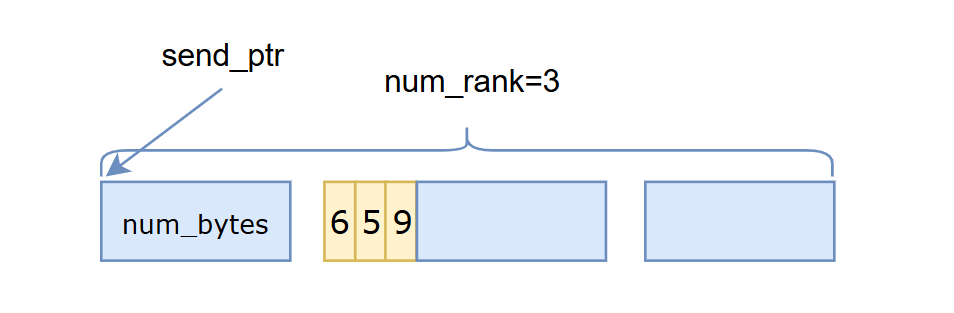
同理填充num_tokens_per_expert和num_tokens_per_rdma_rank。
填充好send_buffer之后开始执行数据的发送
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
if (thread_id < kNumRDMARanks) {
nvshmem_int_put_nbi(rdma_recv_num_tokens_mixed.recv_buffer(rdma_rank), rdma_recv_num_tokens_mixed.send_buffer(thread_id),
NUM_MAX_NVL_PEERS + num_rdma_experts + 1,
translate_dst_rdma_rank<kLowLatencyMode>(thread_id, nvl_rank));
}
__syncthreads();
if (thread_id == 0)
nvshmem_barrier_with_same_gpu_idx<kLowLatencyMode>(rdma_team);
__syncthreads();
}
}
每个线程负责一个机器,将send_buffer通过rdma write发送给dst_rdma_rank,假设当前为rank1,那么会放到dst_rdma_rank的rank1位置,然后通过nvshmem_barrier_with_same_gpu_idx执行barrier保证数据发送完成。
发送完成之后开始处理其他节点发送过来的数据。
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
// NVL buffers
auto nvl_send_buffer = thread_id < NUM_MAX_NVL_PEERS ? buffer_ptrs[thread_id] : nullptr;
auto nvl_recv_buffer = buffer_ptrs[nvl_rank];
auto nvl_reduced_num_tokens_per_expert = Buffer<int>(nvl_recv_buffer, num_rdma_experts).advance_also(nvl_send_buffer);
auto nvl_send_num_tokens_per_rank = AsymBuffer<int>(nvl_send_buffer, kNumRDMARanks, NUM_MAX_NVL_PEERS);
auto nvl_send_num_tokens_per_expert = AsymBuffer<int>(nvl_send_buffer, num_nvl_experts, NUM_MAX_NVL_PEERS);
auto nvl_recv_num_tokens_per_rank = AsymBuffer<int>(nvl_recv_buffer, kNumRDMARanks, NUM_MAX_NVL_PEERS);
auto nvl_recv_num_tokens_per_expert = AsymBuffer<int>(nvl_recv_buffer, num_nvl_experts, NUM_MAX_NVL_PEERS);
}
...
}
nvl_send_buffer就是当前机器上其他gpu的buffer_ptr,一个线程对应一个peer,nvl_recv_buffer指向自己的buffer_ptr
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
if (thread_id < num_rdma_experts) {
int sum = 0;
#pragma unroll
for (int i = 0; i < kNumRDMARanks; ++ i)
sum += rdma_recv_num_tokens_mixed.recv_buffer(i)[NUM_MAX_NVL_PEERS + thread_id];
nvl_reduced_num_tokens_per_expert[thread_id] = sum;
}
__syncthreads();
if (thread_id == 0) {
int sum = 0;
#pragma unroll
for (int i = 0; i < kNumRDMARanks; ++ i) {
sum += rdma_recv_num_tokens_mixed.recv_buffer(i)[NUM_MAX_NVL_PEERS + num_rdma_experts];
recv_rdma_rank_prefix_sum[i] = sum;
}
while (ld_volatile_global(moe_recv_rdma_counter_mapped) != -1);
*moe_recv_rdma_counter_mapped = sum;
}
...
}
然后开始计算当前机器每个expert接收同号卡发送过来tokens的数量,以thread0为例,他要计算的是当前机器上第0个expert,所以就是如下图,黄色部分长度NUM_MAX_NVL_PEERS,绿色部分是存储当前机器expert[0]的token数,所以只需要将绿色部分累加起来就是当前机器第0个expert接受到所有机器同号卡发送过来token数,nvl_reduced_num_tokens_per_expert[thread_id]表示当前机器的第thread_id个expert会收到来自同号卡的多少个token。
同理对于当前机器总的token数,这里会计算一个前缀和recv_rdma_rank_prefix_sum[x],表示前x台机器的同号卡一共发送过来多少token,总和写入moe_recv_rdma_counter_mapped。

__global__ void notify_dispatch(...) {
if (sm_id == 0) {
auto nvl_send_num_tokens_per_rank = AsymBuffer<int>(nvl_send_buffer, kNumRDMARanks, NUM_MAX_NVL_PEERS);
auto nvl_send_num_tokens_per_expert = AsymBuffer<int>(nvl_send_buffer, num_nvl_experts, NUM_MAX_NVL_PEERS);
EP_DEVICE_ASSERT(NUM_MAX_NVL_PEERS <= num_threads);
if (thread_id < NUM_MAX_NVL_PEERS) {
#pragma unroll
for (int i = 0; i < kNumRDMARanks; ++ i)
nvl_send_num_tokens_per_rank.buffer(nvl_rank)[i] = rdma_recv_num_tokens_mixed.recv_buffer(i)[thread_id];
#pragma unroll
for (int i = 0; i < num_nvl_experts; ++ i)
nvl_send_num_tokens_per_expert.buffer(nvl_rank)[i] = nvl_reduced_num_tokens_per_expert[thread_id * num_nvl_experts + i];
}
memory_fence();
__syncthreads();
barrier_device<NUM_MAX_NVL_PEERS>(task_fifo_ptrs, head, nvl_rank);
move_fifo_slots<NUM_MAX_NVL_PEERS>(head);
__syncthreads();
}
...
}
每一个线程对应当前机器的一个peer,比如thread[0]持有的nvl_send_buffer位于gpu[0]的buffer_ptr。然后开始计算当前rank一共需要向当前机器的其他rank转发多少token,还是以thread[0]为例,他将计算发往gpu[0]的token数,rdma_recv_num_tokens_mixed.recv_buffer(i)[thread_id]表示第i个rdma_rank的同号卡会向当前节点的第thread_id个gpu发送多少token,然后将他将会写到gpu[thread_id]的nvl_send_num_tokens_per_rank.buffer(nvl_rank)[i],表示gpu[nvl_rank]将会向gpu[thread_id]转发这么多的token,这些token来自第i个rdma_rank的同号卡。
同理,nvl_reduced_num_tokens_per_expert[thread_id * num_nvl_experts + i]表示当前机器的gpu[thread_id]上的第i个expert收到同号卡发送过来的token数,记录到gpu[thread_id]的nvl_send_num_tokens_per_expert.buffer(nvl_rank)[i],表示gpu[nvl_rank]将会向gpu[thread_id]的第i个expert转发这么多token。
这些信息在机内互相转发之后,然后执行机内barrier,再执行reduce
__global__ void notify_dispatch(...) {
if (sm_id == 0) {
if (thread_id == 0) {
int sum = 0;
#pragma unroll
for (int i = 0; i < num_ranks; ++ i) {
int src_rdma_rank = i / NUM_MAX_NVL_PEERS, src_nvl_rank = i % NUM_MAX_NVL_PEERS;
sum += nvl_recv_num_tokens_per_rank.buffer(src_nvl_rank)[src_rdma_rank];
recv_gbl_rank_prefix_sum[i] = sum;
}
while (ld_volatile_global(moe_recv_counter_mapped) != -1);
*moe_recv_counter_mapped = sum;
}
if (thread_id < num_nvl_experts) {
int sum = 0;
#pragma unroll
for (int i = 0; i < NUM_MAX_NVL_PEERS; ++ i)
sum += nvl_recv_num_tokens_per_expert.buffer(i)[thread_id];
sum = (sum + expert_alignment - 1) / expert_alignment * expert_alignment;
while (ld_volatile_global(moe_recv_expert_counter_mapped + thread_id) != -1);
moe_recv_expert_counter_mapped[thread_id] = sum;
}
...
}
}
nvl_recv_num_tokens_per_rank就是对应其他gpu发送时写的nvl_send_num_tokens_per_rank,如上所述,nvl_recv_num_tokens_per_rank.buffer(src_nvl_rank)[src_rdma_rank]表示的是当前机器的src_nvl_rank个gpu将会转发来自他的同号卡的第src_rdma_rank个机器多少token,其实就是rank[i]发送给当前rank多少token,这里会用thread0求一个前缀和recv_gbl_rank_prefix_sum[x],表示前x个rank发送过来的token总数。所有rank发送的token总和写入moe_recv_counter_mapped 。
同理,nvl_recv_num_tokens_per_expert.buffer(i)[thread_id]表示当前机器第i个gpu转发过来到当前卡第thread_id个expert的token数,因此sum表示当前卡第thread_id个expert将会收到的token总数,并写入moe_recv_expert_counter_mapped[thread_id]。
其他sm
其他的sm负责计算channel对应的meta信息,每个sm对应一个dst_rdma_rank,每个warp计算一个channel对应的meta信息,total_count表示当前rank的这个channel向dst_rdma_rank一共发送了多少tokens,per_nvl_rank_count[j]表示当前rank的这个channel向dst_rdma_rank的第j个gpu一共发送了多少tokens。
__global__ void notify_dispatch(...) {
else {
int dst_rdma_rank = sm_id - 1;
for (int channel_id = warp_id; channel_id < num_channels; channel_id += num_warps) {
int token_start_idx, token_end_idx;
get_channel_task_range(num_tokens, num_channels, channel_id, token_start_idx, token_end_idx);
// Iterate over tokens
int total_count = 0, per_nvl_rank_count[NUM_MAX_NVL_PEERS] = {0};
for (int64_t i = token_start_idx + lane_id; i < token_end_idx; i += 32) {
EP_STATIC_ASSERT(NUM_MAX_NVL_PEERS * sizeof(bool) == sizeof(uint64_t), "Invalid number of NVL peers");
auto is_token_in_rank_uint64 = *reinterpret_cast<const uint64_t*>(is_token_in_rank + i * num_ranks + dst_rdma_rank * NUM_MAX_NVL_PEERS);
auto is_token_in_rank_values = reinterpret_cast<const bool*>(&is_token_in_rank_uint64);
#pragma unroll
for (int j = 0; j < NUM_MAX_NVL_PEERS; ++ j)
per_nvl_rank_count[j] += is_token_in_rank_values[j];
total_count += (is_token_in_rank_uint64 != 0);
}
...
}
}
}
首先通过get_channel_task_range获取这个channel处理的tokens区间为token_start_idx到token_end_idx。然后遍历这个区间的token,对于第i个token,is_token_in_rank_values[j]表示当前机器的channel是否需要向dst_rdma_rank的j个gpu发送这个token,如果需要,那么per_nvl_rank_count[j] + 1,is_token_in_rank_uint64表示是否需要向dst_rdma_rank发送token,如果需要,那么total_count + 1。每个线程执行warp reduce之后就可以拿到了全局结果。
__global__ void notify_dispatch(...) {
else {
total_count = warp_reduce_sum(total_count);
#pragma unroll
for (int i = 0; i < NUM_MAX_NVL_PEERS; ++ i)
per_nvl_rank_count[i] = warp_reduce_sum(per_nvl_rank_count[i]);
// Write into channel matrix
if (lane_id == 0) {
#pragma unroll
for (int i = 0; i < NUM_MAX_NVL_PEERS; ++ i)
gbl_channel_prefix_matrix[(dst_rdma_rank * NUM_MAX_NVL_PEERS + i) * num_channels + channel_id] = per_nvl_rank_count[i];
rdma_channel_prefix_matrix[dst_rdma_rank * num_channels + channel_id] = total_count;
}
}
}
将total_count写入rdma_channel_prefix_matrix[dst_rdma_rank * num_channels + channel_id],将per_nvl_rank_count[i]写入gbl_channel_prefix_matrix
__global__ void notify_dispatch(...) {
else {
__syncthreads();
EP_STATIC_ASSERT(kNumRDMARanks <= 32, "Invalid number of RDMA ranks");
if (thread_id < kNumRDMARanks) {
auto prefix_row = rdma_channel_prefix_matrix + dst_rdma_rank * num_channels;
#pragma unroll
for (int i = 1; i < num_channels; ++ i)
prefix_row[i] += prefix_row[i - 1];
}
EP_STATIC_ASSERT(NUM_MAX_NVL_PEERS <= 32, "Invalid number of NVL peers");
if (thread_id < NUM_MAX_NVL_PEERS) {
auto prefix_row = gbl_channel_prefix_matrix + (dst_rdma_rank * NUM_MAX_NVL_PEERS + thread_id) * num_channels;
#pragma unroll
for (int i = 1; i < num_channels; ++ i)
prefix_row[i] += prefix_row[i - 1];
}
}
}
最后开始求前缀和,prefix_row为rdma_channel_prefix_matrix[dst_rdma_rank * num_channels]开始的num_channel个位置,prefix_row[i]表示当前rank发送到dst_rdma_rank中前i个channel的token数;
同理,假设prefix_row,gbl_channel_prefix_matrix[(dst_rdma_rank * NUM_MAX_NVL_PEERS + thread_id) * num_channels]开始的num_channel个位置,prefix_row[i]表示当前rank发送到dst_rdma_rank的第thread_id个gpu中前i个c