【ICCV 2025】Bridging the Skeleton-Text Modality Gap:扩散模型驱动零样本骨架动作识别

Bridging the Skeleton-Text Modality Gap: Diffusion-Powered Modality Alignment for Zero-shot Skeleton-based Action Recognition
DOI:https://doi.org/10.48550/arXiv.2411.10745
零样本骨架动作识别:训练阶段仅用 “已见类” 数据(骨架 + 文本),推理时,输入 “未见类骨架” 和 “所有未见类动作的文本提示”,实现对骨架数据的动作分类,实验结果以识别准确率呈现。
摘要:在零样本骨架动作识别(ZSAR)中,将骨架特征与动作标签的文本特征进行对齐,对于准确预测未见过的动作至关重要。ZSAR在弥合这两种特征之间的模态差距方面面临根本性挑战,这严重限制了其对未见动作的泛化能力。先前的方法侧重于骨架和文本潜在空间之间的直接对齐,但这些空间之间的模态差距阻碍了鲁棒的泛化学习。受多模态对齐(如文本到图像、文本到视频)中扩散模型成功的启发,我们首先提出了一种用于ZSAR的基于扩散的骨架-文本对齐框架。我们的方法,即用于骨架-文本匹配的三元组扩散(Triplet Diffusion for Skeleton-Text Matching, TDSM),侧重于扩散模型的交叉对齐能力,而非其生成能力。具体而言,TDSM通过将文本特征纳入反向扩散过程,将骨架特征与文本提示对齐,在文本指导下对骨架特征进行去噪,形成一个统一的骨架-文本潜在空间以进行鲁棒匹配。为了增强判别能力,我们引入了一种三元组扩散(TD)损失,鼓励我们的TDSM在将骨架-文本匹配项推开以区分不同动作类别的同时对其进行校正。我们的TDSM显著优于最近的所有先进方法,差距很大,达到了2.36个百分点至13.05个百分点,通过有效的骨架-文本匹配,在零样本设置中展示了卓越的准确性和可扩展性。
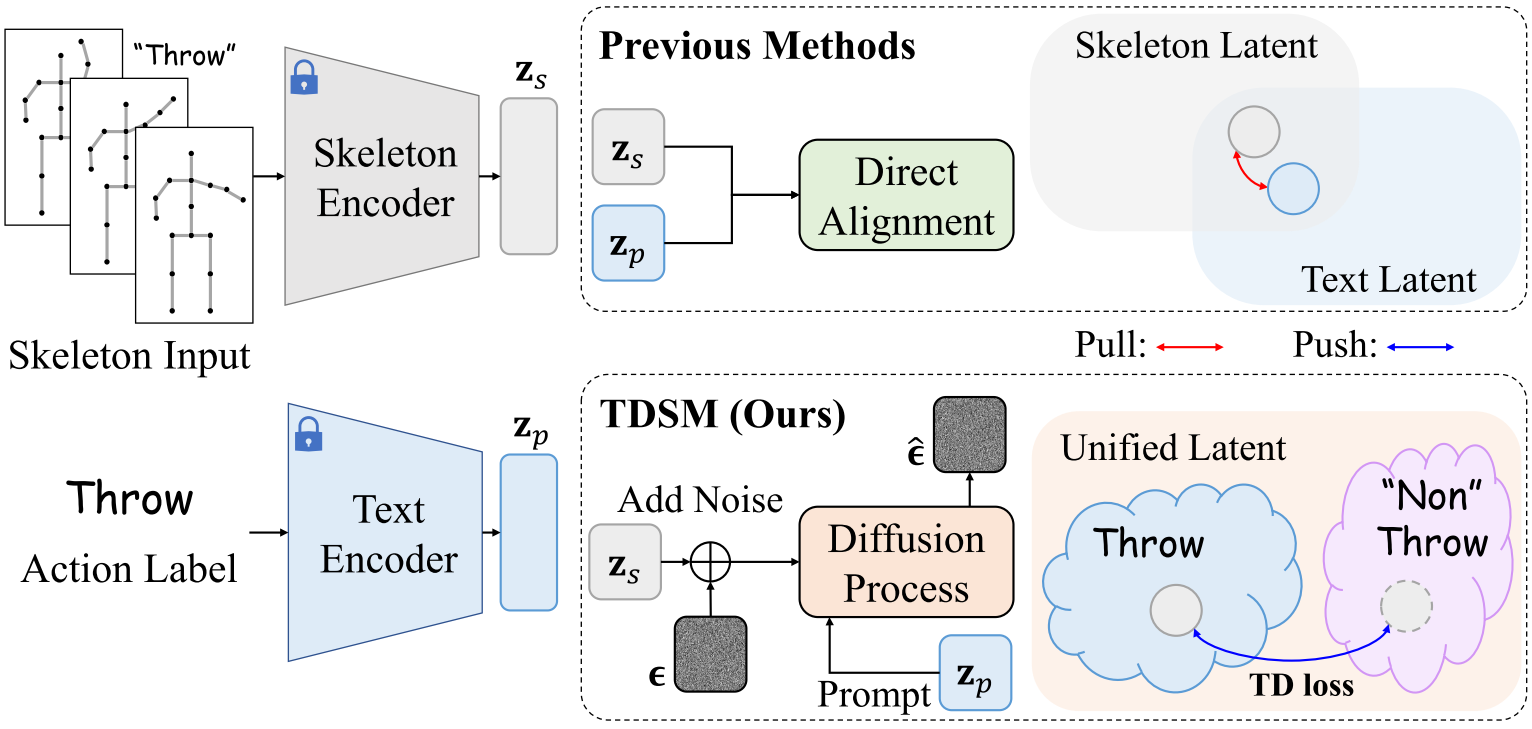
以前的方法依赖于骨架和文本潜在空间之间的直接对齐,从而受到限制泛化的通道间隙的影响,但TDSM通过利用扩散模型的跨通道对齐能力克服了这一挑战,为有效的跨通道匹配建立了更统一和健壮的骨架-文本表示。
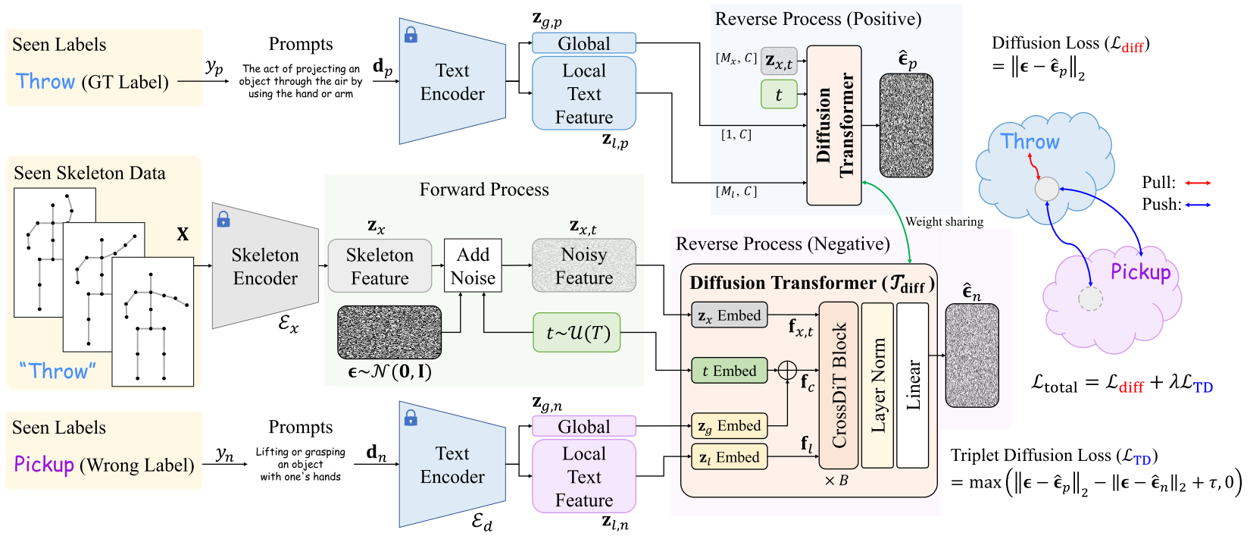
使用ShiftGCN对骨架数据进行时空特征提取,Clip模型对文本数据进行特征提取,预训练权重stabilityai/stable-diffusion-2-1-base下载地址:https://huggingface.co/stabilityai/stable-diffusion-2-1-base。给干净的骨架特征添加随机高斯噪声,模拟 “数据从干净到噪声” 的过程,为后续 “反向去噪” 提供学习目标 —— 让模型学会 “在文本引导下,从噪声中恢复与文本匹配的干净骨架特征”。反向扩散分为正样本分支和负样本分支,双分支共享权重。正样本分支:匹配文本引导去噪,学习 “正确文本引导下的去噪规则”,使去噪后的骨架特征与文本语义紧密对齐。负样本分支:不匹配文本引导去噪,为 “三元组损失” 提供对比项,让模型学会 “区分正确 / 错误的骨架 - 文本对”。
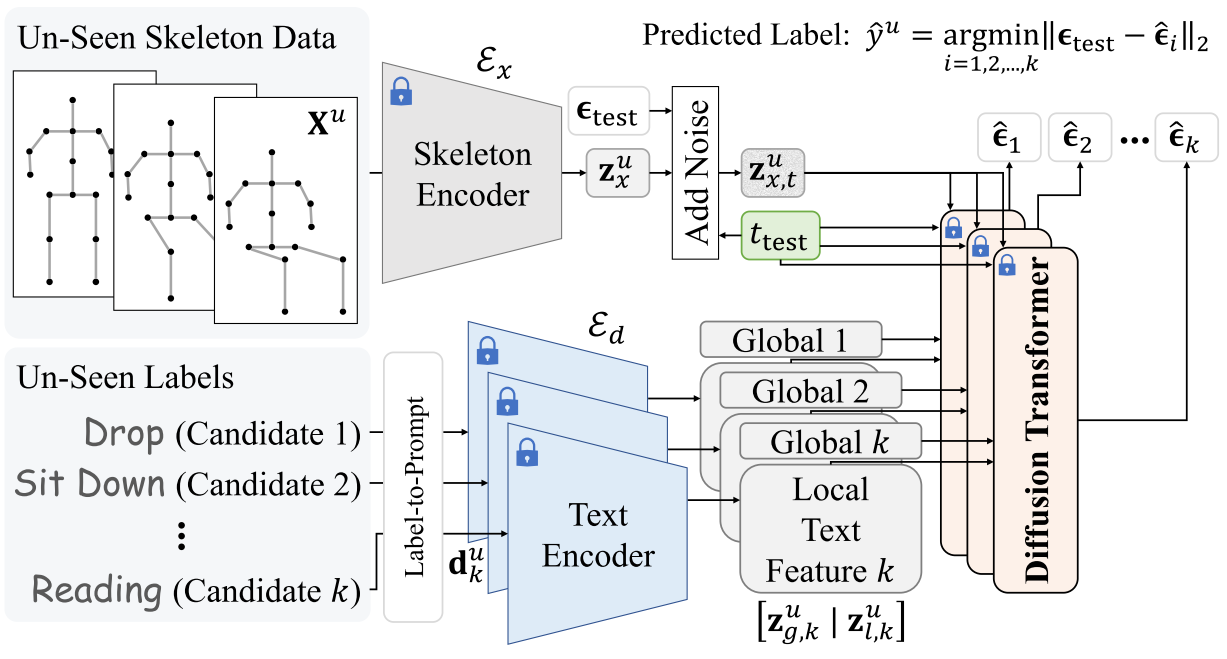
推理阶段流程:输入未见类骨架数据与所有候选未见类标签,未见类骨架数据经骨架编码器编码并加噪得到带噪声的骨架特征,同时生成测试时间步;各候选标签经 “标签 - 提示” 转换为文本提示后,由文本编码器编码为全局和局部文本特征;随后,带噪声的骨架特征、测试时间步与各候选的文本特征输入扩散 Transformer,分别预测对应噪声;最终计算测试噪声与各候选预测噪声的范数,选择距离最小的候选标签作为未见类动作的预测结果。
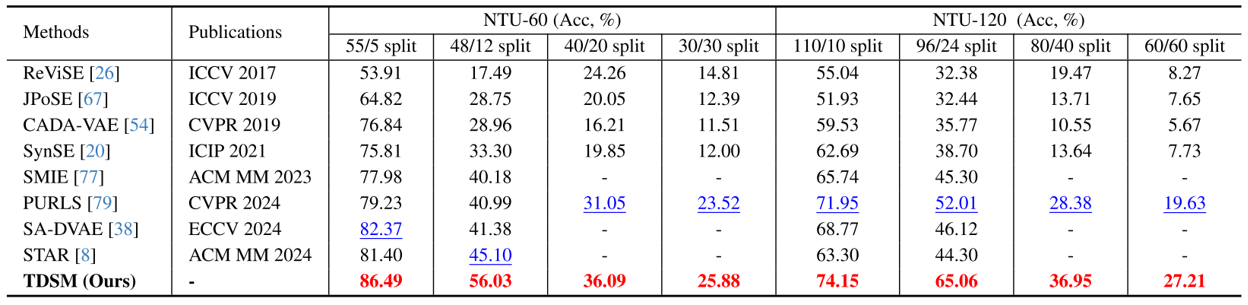
实验结果,55/5为55个已见类,5个未见类,论文作者仅提供了55/5和48/12数据集,40/20和30/30需自行制作。
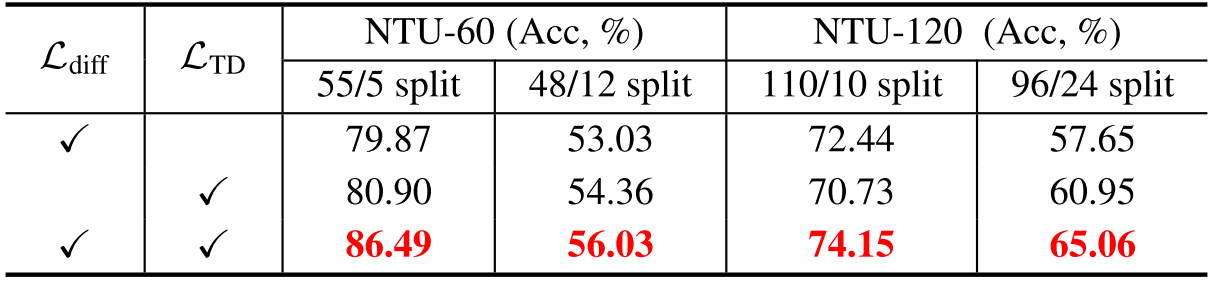
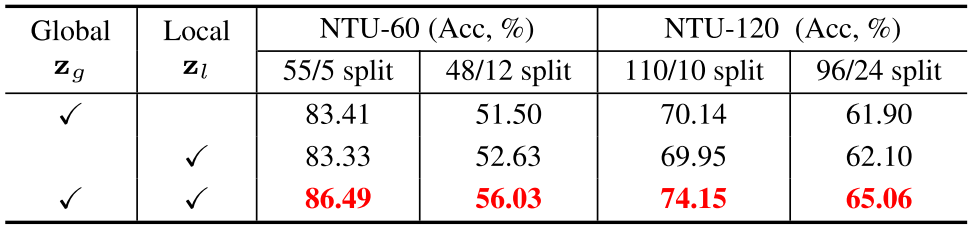
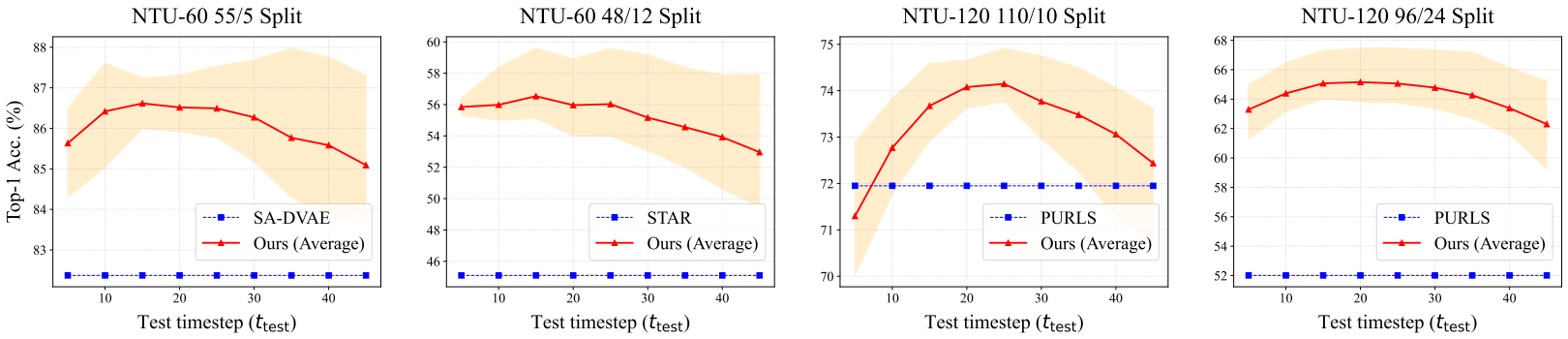
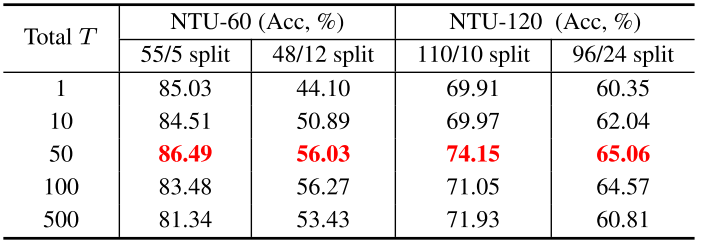
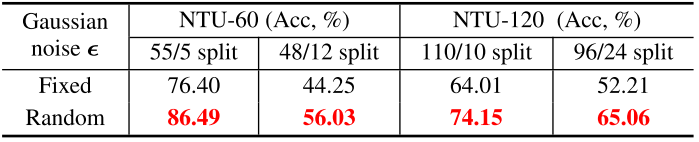
消融实验
结论
TDSM 是首个将扩散模型应用于零样本基于骨架的动作识别的框架。其选择性去噪过程促进了骨架与文本特征的稳健融合,使模型能够构建一个具有判别性的特征空间,该空间可泛化到未见的动作标签。此外,通过TD 损失增强了判别性融合 —— 该损失旨在有效对真实(GT)骨架 - 文本对进行去噪,同时防止已见数据集中错误对的融合。大量实验表明, TDSM 在各类基准数据集上以显著优势大幅超越了最新的 SOTA 模型。