深入浅出 Java 虚拟机之基础原理
开篇词:JVM,一块难啃的骨头
我曾任京东金融、陌陌科技高级架构师,专注分享基础架构方面的知识。
JVM 目前情况
我在工作期间,因为接触的都是比较底层的中间件和操作系统,会涉及大量高并发场景下的调优工作。其中,JVM 的调优和故障排查,是非常重要的一项工作内容。 许多同学对 JVM 有一些恐惧,这是可以理解的。JVM 是“Java 虚拟机”的意思,“虚拟”这两个字,证明了它要实现一个庞大的生态,有点类似于“操作系统”,内容肯定是非常多的。 而随着互联网进入下半场,好公司对程序员的要求也水涨船高,各大互联网公司的岗位描述中,JVM 几乎是逃不掉的关键词,我们举几个来自拉勾网的 JD 实例。
你会发现,在 Java 高级工程师岗位要求中,JVM 几乎成了必须掌握的技能点,而在面经里涉及 JVM 的知识也数不胜数,本专栏各课时涉及的知识点,也正是各大厂 Java 高级工程师面试的高频考题。 只要你是在做 Java 方面的工作,JVM 便是必备的知识。
JVM 在学习过程中的难点和问题
实践资料太少,不太容易系统化
其实,我们开发人员离 JVM 很近,它也没有那么神秘。许多问题,你可能在平常的工作中就已经遇到了。
- 正在运行的 Java 进程,可能突然就 OOM 内存溢出了。
- 线上系统产生卡顿,CPU 疯狂运转,GC 时间飙升,严重影响了服务响应时间。
- 面对一堆 JVM 的参数无从下手,错失了性能提升的可能,或者因为某个参数的错误配置,产生了尴尬的负面效果。
- 想要了解线上应用的垃圾回收状况,却不知从何开始,服务监控状况无法掌控。
- 一段代码有问题,执行效率低,但就是无法找到深层次原因。
这些都是经常发生的事情,我就不止一次在半夜被报警铃声叫起,并苦于问题的追踪。别担心,我也是从这个阶段过来的,通过大量的线上实操,积累了非常丰富的经验。还记得当时花了整整一周时间,才定位到一个棘手的堆外内存泄漏问题。现在再回头看这些问题,就显得比较风轻云淡了。
相关问题太多,概念太杂了
同时,JVM 的版本更新很快,造成了很多同学会对 JVM 有一些疑问。网络上的一些博主,可能会从自己的角度去分析问题,读者无法产生代入感。甚至,一些错误的知识会产生比较严重的后果,你会经常看到一些有冲突的概念。
- Java 源代码是怎么变成字节码的,字节码又是怎么进入 JVM 的?
- JVM 是怎么执行字节码的?哪些数据放在栈?哪些数据放在堆?
- Java 的一些特性是如何与字节码产生关联的?
- 如何监控 JVM 的运行,才能够做到问题自动发现?
如果你有这方面的疑问,那再正常不过了。我们在专栏中将从实际的应用场景出发,来探讨一些比较深入的问题。 那为什么要学习 JVM?不学习 JVM 会影响我写 Java 代码么?严格意义上来说,并不会。但是,如果不学习 JVM 你可能可以写出功能完善的代码,但是一定无法写出更加高效的代码。更别说常见的性能优化和故障排查了。
学习 JVM 有什么用?
由于 JVM 是一个虚拟的体系,它拥有目前最前沿的垃圾回收算法实现,虽然 JVM 也有一些局限性,但学习它之后,在遇到其他基于“虚拟机”的语言时,便能够触类旁通。
- 面试必考
学习 JVM 最重要的一点就是体系化,仅靠零零散散的知识是无法形成有效的知识系统的。这样,在回答面试官的问题时,便会陷入模棱两可的境地。如果你能够触类旁通,既有深度又有广度地做进一步升华,会让面试官眼前一亮。
- 职业提升
JVM 是 Java 体系中非常重要的内容,不仅仅因为它是面试必考,更因为它与我们的工作息息相关。同时,我们也认识到,JVM 是一块难啃的骨头。市面上有很多大牛分享的书籍,但大部分都是侧重于理论,不会教你什么时候用什么参数,也不会教你怎么去优化代码。理论与实践是有很大出入的,你可能非常了解 JVM 的内存模型,但等到真正发生问题时,还是会一头雾水。
如果能够理论联系实际,在面临一些棘手问题时,就能够快速定位到它的根本问题,为你的职业发展助力。
- 业务场景强相关
不同的业务,JVM 的配置肯定也是不同的。比如高并发的互联网业务,与传统的报表导出业务,就是完全不同的两个应用场景:它们有的对服务响应时间 RT 要求比较高,不允许有长尾请求;有的对功能完整度要求比较高,不能运行到一半就宕机了。所以大家在以后的 JVM 优化前,一定要先确立场景,如果随便从网络上搬下几个配置参数进行设置,那是非常危险的。
鉴于以上这些问题,我会在课程中分享一些对线上 JVM 的实践和思考。课程中还会有很多代码示例来配合讲解,辅之以实战案例,让你对理论部分的知识有更深的理解。本门课程,我就以自己对 JVM 的理解,用尽量简单、活泼的语言,来解答这些问题。
JVM 怎么学?
为了准备这个课程,我同时研读了大量的中英文资料。我发现这方面的内容,有一个非常显著的特点,就是比较晦涩。很多大牛讲得比较深入,但你可能读着读着就进行不下去了。很容易产生当时感觉非常有道理,过几天就忘了的结果。 我在公众号(xjjdog)上分享了大量高价值的文章,但有些需要系统性讲解的知识点,我决定做成精品课程,JVM 就是其中优先级比较高的。问题探讨会产生更多思想碰撞,也能加深记忆,大家可以多多交流。 我将整个课程分为四个部分,一个问题可能会从不同的角度去解析,每个课时都会做一个简单的总结。
- 基础原理:主要讲解 JVM 基础概念,以及内存区域划分和类加载机制等。最后,会根据需求实现一个自定义类加载器。
- 垃圾回收:Java 中有非常丰富的垃圾回收器,此部分以理论为主,是通往高级工程师之路无法绕过的知识点。我会横向比较工作中常用的垃圾回收器并以主题深入的方式讲解 G1、GMS、ZGC 等主流垃圾回收器。
- 实战部分:我会模拟工作中涉及的 OOM 溢出全场景,用 23 个大型工作实例分析线上问题,并针对这些问题提供排查的具体工具的使用介绍,还会提供一个高阶的对堆外内存问题的排查思路。
- 进阶部分:介绍 JMM,以及从字节码层面来剖析 Java 的基础特性以及并发方面的问题。还会重点分析应用较多的 Java Agent 技术。这部分内容比较底层,可以加深我们对 Java 底层实现的理解。
- 彩蛋:带你回顾 JVM 的历史并展望未来,即使 JVM 版本不断革新也能够洞悉未来掌握先机,最后会给你提供一份全面的 JVM 面试题,助力高级 Java 岗位面试。
你将获得什么?
建立完整的 JVM 知识体系
通过这门课程,你可以系统地学习 JVM 相关知识,而不是碎片化获取。我会以大量的实例来增加你的理解和记忆,理论结合实践,进而加深对 Java 语言的理解。
能够对线上应用进行优化和故障排查
课程中包含大量的实战排查工具,掌握它们,你能够非常容易地定位到应用中有问题的点,并提供优化思路,尤其是 MAT 等工具的使用,这通常是普通开发人员非常缺乏的一项技能。 我还会分享一些在线的 JVM 监控系统建设方案,让你实时掌控整个 JVM 的健康状况,辅助故障的排查。
面试中获取 Offer 的利器
本课程的每小节,都是 Java 面试题的重灾区。在课程中以实际工作场景为出发点来解答面试中的问题,既能在面试中回答问题的理论知识,又能以实际工作场景为例与面试官深入探讨问题,可以说通过本课程学习 JVM 是成为 Java 高级、资深工程师的必经之路。
第01讲:一探究竟:为什么需要JVM?它处在什么位置?
从本课时开始我们就正式进入 JVM 的学习,如果你是一名软件开发工程师,在日常工作中除了 Java 这个关键词外,还有一个名词也一定经常被提及,那就是 JVM。提到 JVM 我们经常会在面试中遇到这样的问题:
- 为什么 Java 研发系统需要 JVM?
- 对你 JVM 的运行原理了解多少?
- 我们写的 Java 代码到底是如何运行起来的?
想要在面试中完美地回答这三个问题,就需要首先了解 JVM 是什么?它和 Java 有什么关系?又与 JDK 有什么渊源?接下来,我就带你拨开这些问题的层层迷雾,想要弄清楚这些问题,我们首先需要从这三个维度去思考:
- JVM 和操作系统的关系?
- JVM、JRE、JDK 的关系?
- Java 虚拟机规范和 Java 语言规范的关系?
弄清楚这几者的关系后,我们再以一个简单代码示例来看一下一个 Java 程序到底是如何执行的。
JVM 和操作系统的关系

在武侠小说中,想要炼制一把睥睨天下的宝剑,是需要下一番功夫的。除了要有上等的铸剑技术,还需要一鼎经百炼的剑炉,而工程师就相当于铸剑的剑师,JVM 便是剑炉。
JVM 全称 Java Virtual Machine,也就是我们耳熟能详的 Java 虚拟机。它能识别 .class后缀的文件,并且能够解析它的指令,最终调用操作系统上的函数,完成我们想要的操作。
一般情况下,使用 C++ 开发的程序,编译成二进制文件后,就可以直接执行了,操作系统能够识别它;但是 Java 程序不一样,使用 javac 编译成 .class 文件之后,还需要使用 Java 命令去主动执行它,操作系统并不认识这些 .class 文件。
你可能会想,我们为什么不能像 C++ 一样,直接在操作系统上运行编译后的二进制文件呢?而非要搞一个处于程序与操作系统中间层的虚拟机呢?
这就是 JVM 的过人之处了。大家都知道,Java 是一门抽象程度特别高的语言,提供了自动内存管理等一系列的特性。这些特性直接在操作系统上实现是不太可能的,所以就需要 JVM 进行一番转换。
有了上面的介绍,我们就可以做如下的类比。
- JVM:等同于操作系统;
- Java 字节码:等同于汇编语言。
Java 字节码一般都比较容易读懂,这从侧面上证明 Java 语言的抽象程度比较高。你可以把 JVM 认为是一个翻译器,会持续不断的翻译执行 Java 字节码,然后调用真正的操作系统函数,这些操作系统函数是与平台息息相关的。
如果你还是对上面的介绍有点模糊,可以参考下图:
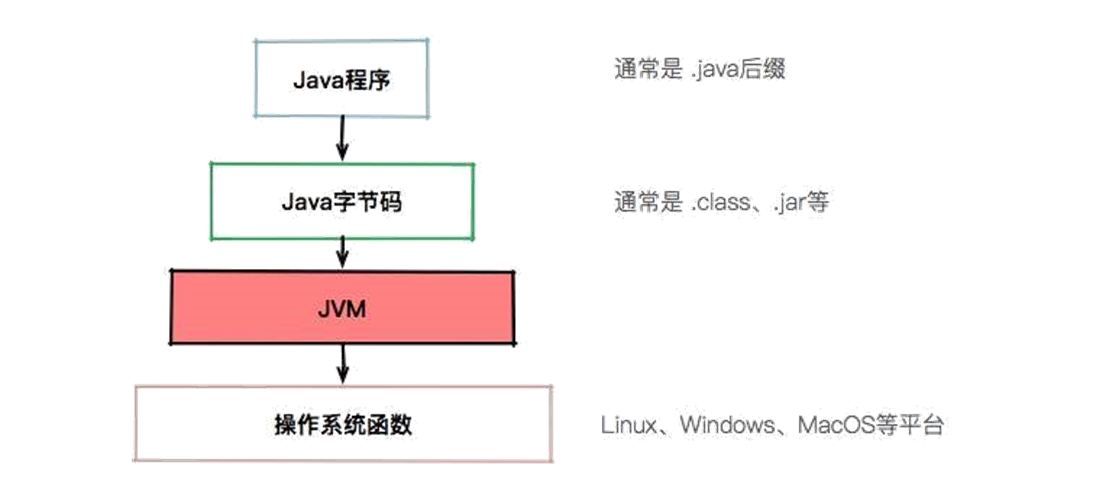
从图中可以看到,有了 JVM 这个抽象层之后,Java 就可以实现跨平台了。JVM 只需要保证能够正确执行 .class 文件,就可以运行在诸如 Linux、Windows、MacOS 等平台上了。
而 Java 跨平台的意义在于一次编译,处处运行,能够做到这一点 JVM 功不可没。比如我们在 Maven 仓库下载同一版本的 jar 包就可以到处运行,不需要在每个平台上再编译一次。
现在的一些 JVM 的扩展语言,比如 Clojure、JRuby、Groovy 等,编译到最后都是 .class 文件,Java 语言的维护者,只需要控制好 JVM 这个解析器,就可以将这些扩展语言无缝的运行在 JVM 之上了。
我们用一句话概括 JVM 与操作系统之间的关系:JVM 上承开发语言,下接操作系统,它的中间接口就是字节码。
而 Java 程序和我们通常使用的 C++ 程序有什么不同呢?这里用两张图进行说明。
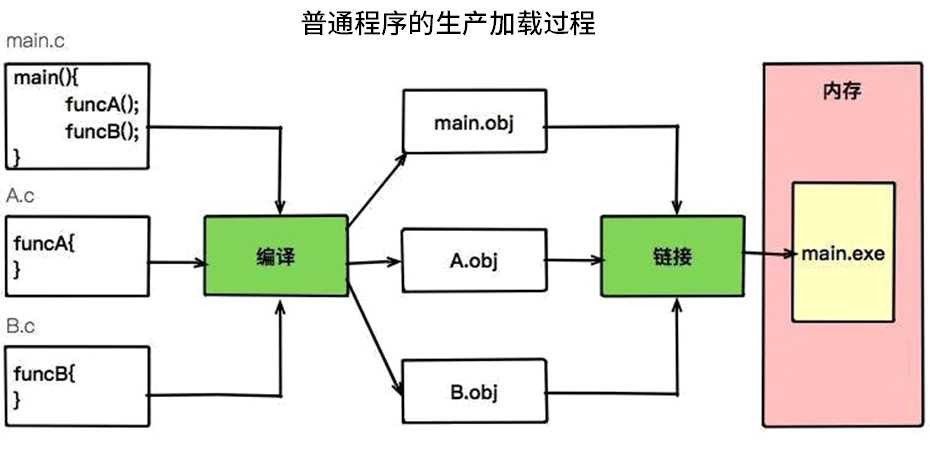
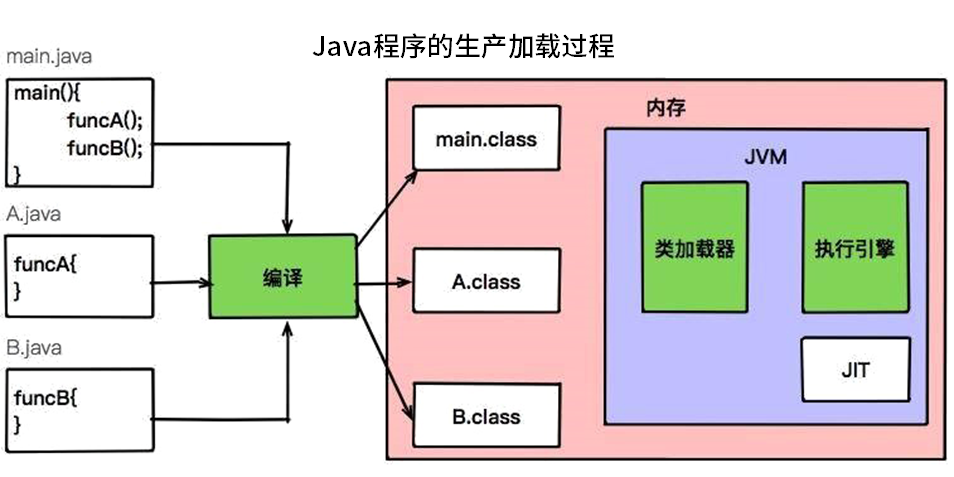
对比这两张图可以看到 C++ 程序是编译成操作系统能够识别的 .exe 文件,而 Java 程序是编译成 JVM 能够识别的 .class 文件,然后由 JVM 负责调用系统函数执行程序。
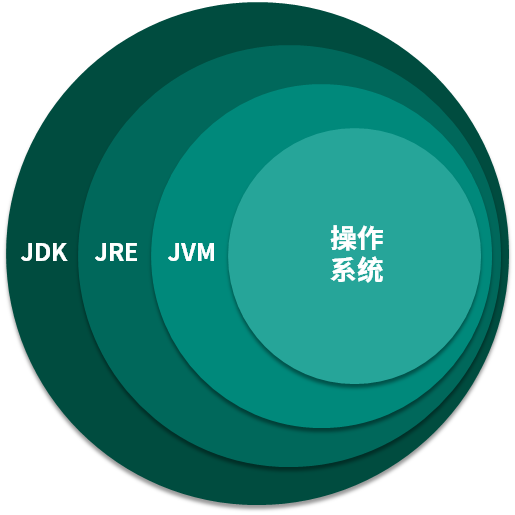
JVM、JRE、JDK的关系

通过上面的学习我们了解到 JVM 是 Java 程序能够运行的核心。但是需要注意,JVM 自己什么也干不了,你需要给它提供生产原料(.class 文件)。俗语说的好,巧妇难为无米之炊。它虽然功能强大,但仍需要为它提供 .class 文件。
仅仅是 JVM,是无法完成一次编译,处处运行的。它需要一个基本的类库,比如怎么操作文件、怎么连接网络等。而 Java 体系很慷慨,会一次性将 JVM 运行所需的类库都传递给它。JVM 标准加上实现的一大堆基础类库,就组成了 Java 的运行时环境,也就是我们常说的 JRE(Java Runtime Environment)。
有了 JRE 之后,我们的 Java 程序便可以在浏览器中运行了。大家可以看一下自己安装的 Java 目录,如果是只需要执行一些 Java 程序,只需要一个 JRE 就足够了。
对于 JDK 来说,就更庞大了一些。除了 JRE,JDK 还提供了一些非常好用的小工具,比如 javac、java、jar 等。它是 Java 开发的核心,让外行也可以炼剑!
我们也可以看下 JDK 的全拼,Java Development Kit。我非常怕 kit(装备)这个单词,它就像一个无底洞,预示着你永无休止的对它进行研究。JVM、JRE、JDK 它们三者之间的关系,可以用一个包含关系表示。
- JDK>JRE>JVM
Java 虚拟机规范和 Java 语言规范的关系
我们通常谈到 JVM,首先会想到它的垃圾回收器,其实它还有很多部分,比如对字节码进行解析的执行引擎等。广义上来讲,JVM 是一种规范,它是最为官方、最为准确的文档;狭义上来讲,由于我们使用 Hotspot 更多一些,我们一般在谈到这个概念时,会将它们等同起来。
如果再加上我们平常使用的 Java 语言的话,可以得出下面这样一张图。这是 Java 开发人员必须要搞懂的两个规范。
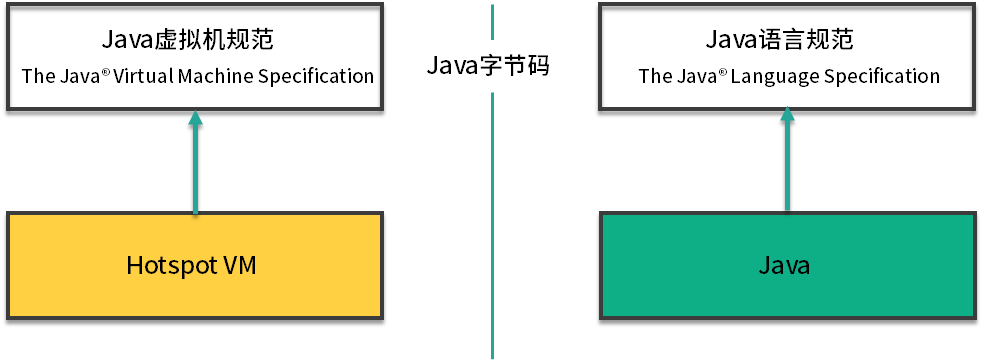
左半部分是 Java 虚拟机规范,其实就是为输入和执行字节码提供一个运行环境。右半部分是我们常说的 Java 语法规范,比如 switch、for、泛型、lambda 等相关的程序,最终都会编译成字节码。而连接左右两部分的桥梁依然是 Java 的字节码。
如果 .class 文件的规格是不变的,这两部分是可以独立进行优化的。但 Java 也会偶尔扩充一下 .class 文件的格式,增加一些字节码指令,以便支持更多的特性。
我们可以把 Java 虚拟机可以看作是一台抽象的计算机,它有自己的指令集以及各种运行时内存区域,学过《计算机组成结构》的同学会在课程的后面看到非常多的相似性。
你可能会有疑问,如果我不学习 JVM,会影响我写 Java 代码么?理论上,这两者没有什么必然的联系。它们之间通过 .class 文件进行交互,即使你不了解 JVM,也能够写大多数的 Java 代码。就像是你写 C++ 代码一样,并不需要特别深入的了解操作系统的底层是如何实现的。
但是,如果你想要写一些比较精巧、效率比较高的代码,就需要了解一些执行层面的知识了。了解 JVM,主要用在调优以及故障排查上面,你会对运行中的各种资源分配,有一个比较全面的掌控。
我们写的 Java 代码到底是如何运行起来的
最后,我们简单看一下一个 Java 程序的执行过程,它到底是如何运行起来的。
这里的 Java 程序是文本格式的。比如下面这段 HelloWorld.java,它遵循的就是 Java 语言规范。其中,我们调用了 System.out 等模块,也就是 JRE 里提供的类库。
public class HelloWorld {public static void main(String[] args) {System.out.println("Hello World");}
}
使用 JDK 的工具 javac 进行编译后,会产生 HelloWorld 的字节码。
我们一直在说 Java 字节码是沟通 JVM 与 Java 程序的桥梁,下面使用 javap 来稍微看一下字节码到底长什么样子。
0 getstatic #2 <java/lang/System.out>
3 ldc #3 <Hello World>
5 invokevirtual #4 <java/io/PrintStream.println>
8 return
Java 虚拟机采用基于栈的架构,其指令由操作码和操作数组成。这些字节码指令,就叫作 opcode。其中,getstatic、ldc、invokevirtual、return 等,就是 opcode,可以看到是比较容易理解的。
我们继续使用 hexdump 看一下字节码的二进制内容。与以上字节码对应的二进制,就是下面这几个数字(可以搜索一下)。
b2 00 02 12 03 b6 00 04 b1
我们可以看一下它们的对应关系。
0xb2 getstatic 获取静态字段的值
0x12 ldc 常量池中的常量值入栈
0xb6 invokevirtual 运行时方法绑定调用方法
0xb1 return void 函数返回
opcode 有一个字节的长度(0~255),意味着指令集的操作码个数不能操作 256 条。而紧跟在 opcode 后面的是被操作数。比如 b2 00 02,就代表了 getstatic #2 。
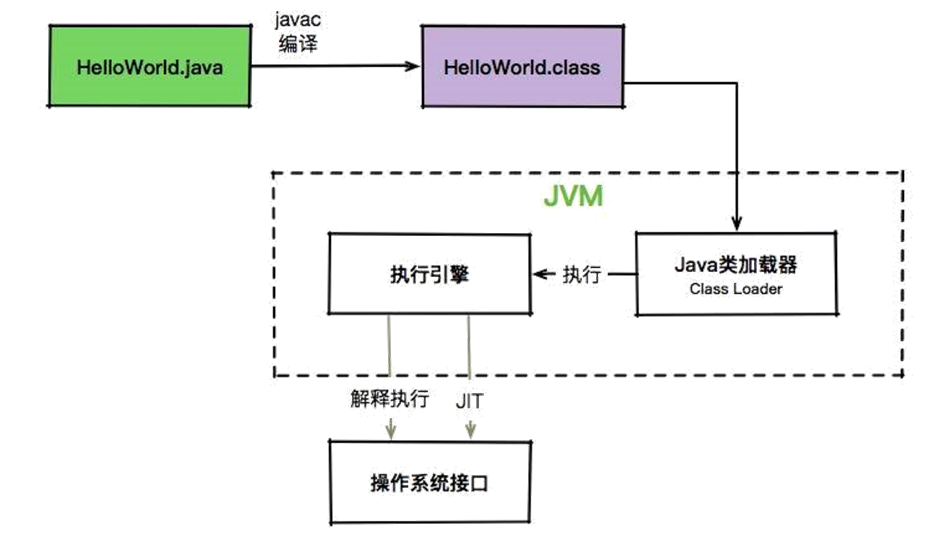
JVM 就是靠解析这些 opcode 和操作数来完成程序的执行的。当我们使用 Java 命令运行 .class 文件的时候,实际上就相当于启动了一个 JVM 进程。
然后 JVM 会翻译这些字节码,它有两种执行方式。常见的就是解释执行,将 opcode + 操作数翻译成机器代码;另外一种执行方式就是 JIT,也就是我们常说的即时编译,它会在一定条件下将字节码编译成机器码之后再执行。
这些 .class 文件会被加载、存放到 metaspace 中,等待被调用,这里会有一个类加载器的概念。
而 JVM 的程序运行,都是在栈上完成的,这和其他普通程序的执行是类似的,同样分为堆和栈。比如我们现在运行到了 main 方法,就会给它分配一个栈帧。当退出方法体时,会弹出相应的栈帧。你会发现,大多数字节码指令,就是不断的对栈帧进行操作。
而其他大块数据,是存放在堆上的。Java 在内存划分上会更为细致,关于这些概念,我们会在接下来的课时里进行详细介绍。
最后大家看下面的图,其中 JVM 部分,就是我们课程的要点。
选用的版本
既然 JVM 只是一个虚拟机规范,那肯定有非常多的实现。其中,最流行的要数 Oracle 的 HotSpot。
目前,最新的版本是 Java13(注意最新的LTS版本是11)。学技术当然要学最新的,我们以后的课时就以 13 版本的 Java 为基准,来讲解发生在 JVM 上的那些事儿。
为了完成这个过程,你可以打开浏览器,输入下载网址(https://www.oracle.com/technetwork/java/ javase/downloads/jdk13-downloads-5672538.html)并安装软件。当然你也可以用稍低点的版本,但是有些知识点会有些许差异。相信对于聪明的你来说,这写都不算问题,因为整个 JVM,包括我们的调优,就是在不断试错中完成的。
小结
我们再回头看看上面的三个问题。
- 为什么 Java 研发系统需要 JVM?
JVM 解释的是类似于汇编语言的字节码,需要一个抽象的运行时环境。同时,这个虚拟环境也需要解决字节码加载、自动垃圾回收、并发等一系列问题。JVM 其实是一个规范,定义了 .class 文件的结构、加载机制、数据存储、运行时栈等诸多内容,最常用的 JVM 实现就是 Hotspot。
- 对你 JVM 的运行原理了解多少?
JVM 的生命周期是和 Java 程序的运行一样的,当程序运行结束,JVM 实例也跟着消失了。JVM 处于整个体系中的核心位置,关于其具体运行原理,我们在下面的课时中详细介绍。
- 我们写的 Java 代码到底是如何运行起来的?
一个 Java 程序,首先经过 javac 编译成 .class 文件,然后 JVM 将其加载到元数据区,执行引擎将会通过混合模式执行这些字节码。执行时,会翻译成操作系统相关的函数。JVM 作为 .class 文件的黑盒存在,输入字节码,调用操作系统函数。
过程如下:Java 文件->编译器>字节码->JVM->机器码。
总结
到这里本课时的内容就全部讲完了,今天我们分别从三个角度,了解了 JVM 在 Java 研发体系中的位置,并以一个简单的程序,看了下一个 Java 程序基本的执行过程。
我们所说的 JVM,狭义上指的就 HotSpot。如非特殊说明,我们都以 HotSpot 为准。我们了解到,Java 之所以成为跨平台,就是由于 JVM 的存在。Java 的字节码,是沟通 Java 语言与 JVM 的桥梁,同时也是沟通 JVM 与操作系统的桥梁。
JVM 是一个非常小的集合,我们常说的 Java 运行时环境,就包含 JVM 和一部分基础类库。如果加上我们常用的一些开发工具,就构成了整个 JDK。我们讲解 JVM 就聚焦在字节码的执行上面。
Java 虚拟机采用基于栈的架构,有比较丰富的 opcode。这些字节码可以解释执行,也可以编译成机器码,运行在底层硬件上,可以说 JVM 是一种混合执行的策略。
第02讲:大厂面试题:你不得不掌握的JVM内存管理
本课时我们主要讲解 JVM 的内存划分以及栈上的执行过程。这块内容在面试中主要涉及以下这 3 个面试题:
- JVM 是如何进行内存区域划分的?
- JVM 如何高效进行内存管理?
- 为什么需要有元空间,它又涉及什么问题?
带着这 3 个问题,我们开始今天的学习,关于内存划分的知识我希望在本课时你能够理解就可以,不需要死记硬背,因为在后面的课时我们会经常使用到本课时学习的内容,也会结合工作中的场景具体问题具体分析,这样你可以对 JVM 的内存获得更深刻的认识。 首先,第一个问题:JVM的内存区域是怎么高效划分的?这也是一个高频的面试题。很多同学可能通过死记硬背的方式来应对这个问题,这样不仅对知识没有融会贯通在面试中还很容易忘记答案。 为什么要问到 JVM 的内存区域划分呢?因为 Java 引以为豪的就是它的自动内存管理机制。相比于 C++的手动内存管理、复杂难以理解的指针等,Java 程序写起来就方便的多。 然而这种呼之即来挥之即去的内存申请和释放方式,自然也有它的代价。为了管理这些快速的内存申请释放操作,就必须引入一个池子来延迟这些内存区域的回收操作。 我们常说的内存回收,就是针对这个池子的操作。我们把上面说的这个池子,叫作堆,可以暂时把它看成一个整体。
JVM 内存布局
程序想要运行,就需要数据。有了数据,就需要在内存上存储。那你可以回想一下,我们的 C++ 程序是怎么运行的?是不是也是这样? Java 程序的数据结构是非常丰富的。其中的内容,举一些例子:
- 静态成员变量
- 动态成员变量
- 区域变量
- 短小紧凑的对象声明
- 庞大复杂的内存申请
这么多不同的数据结构,到底是在什么地方存储的,它们之间又是怎么进行交互的呢?是不是经常在面试的时候被问到这些问题? 我们先看一下 JVM 的内存布局。随着 Java 的发展,内存布局一直在调整之中。比如,Java 8 及之后的版本,彻底移除了持久代,而使用 Metaspace 来进行替代。这也表示着 -XX:PermSize 和 -XX:MaxPermSize 等参数调优,已经没有了意义。但大体上,比较重要的内存区域是固定的。
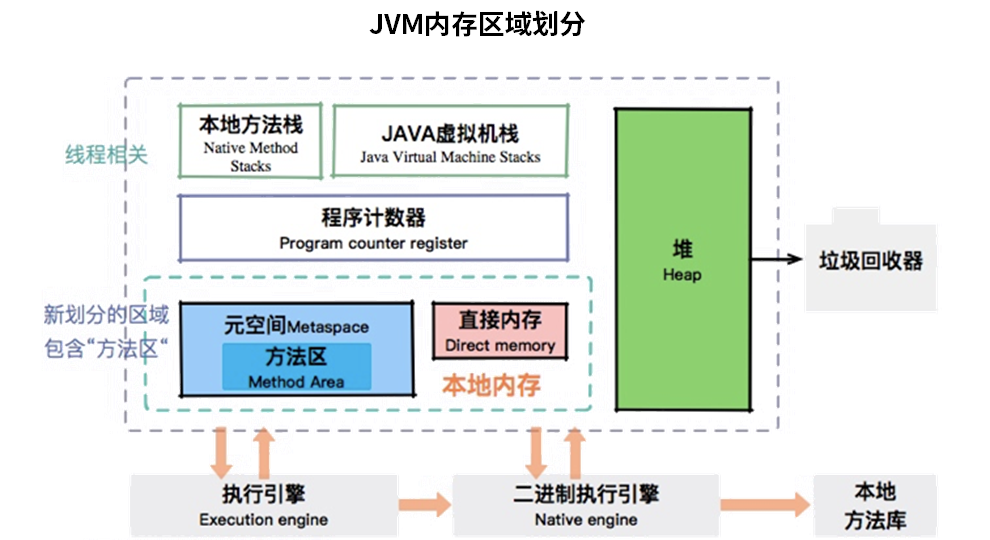
JVM 内存区域划分如图所示,从图中我们可以看出:
- JVM 堆中的数据是共享的,是占用内存最大的一块区域。
- 可以执行字节码的模块叫作执行引擎。
- 执行引擎在线程切换时怎么恢复?依靠的就是程序计数器。
- JVM 的内存划分与多线程是息息相关的。像我们程序中运行时用到的栈,以及本地方法栈,它们的维度都是线程。
- 本地内存包含元数据区和一些直接内存。
一般情况下,只要你能答出上面这些主要的区域,面试官都会满意的点头。但如果深挖下去,可能就有同学就比较头疼了。下面我们就详细看下这个过程。
虚拟机栈

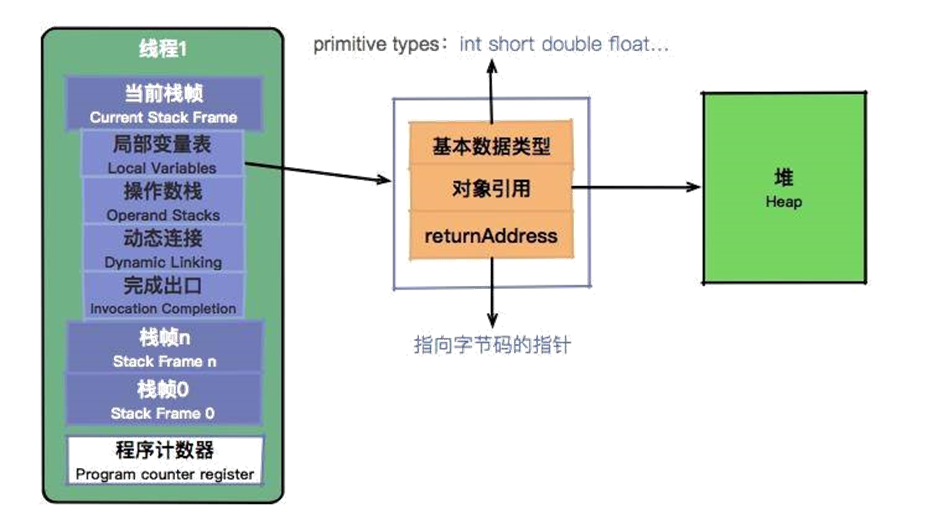
栈是什么样的数据结构?你可以想象一下子弹上膛的这个过程,后进的子弹最先射出,最上面的子弹就相当于栈顶。 我们在上面提到,Java 虚拟机栈是基于线程的。哪怕你只有一个 main() 方法,也是以线程的方式运行的。在线程的生命周期中,参与计算的数据会频繁地入栈和出栈,栈的生命周期是和线程一样的。 栈里的每条数据,就是栈帧。在每个 Java 方法被调用的时候,都会创建一个栈帧,并入栈。一旦完成相应的调用,则出栈。所有的栈帧都出栈后,线程也就结束了。每个栈帧,都包含四个区域:
- 局部变量表
- 操作数栈
- 动态连接
- 返回地址
我们的应用程序,就是在不断操作这些内存空间中完成的。
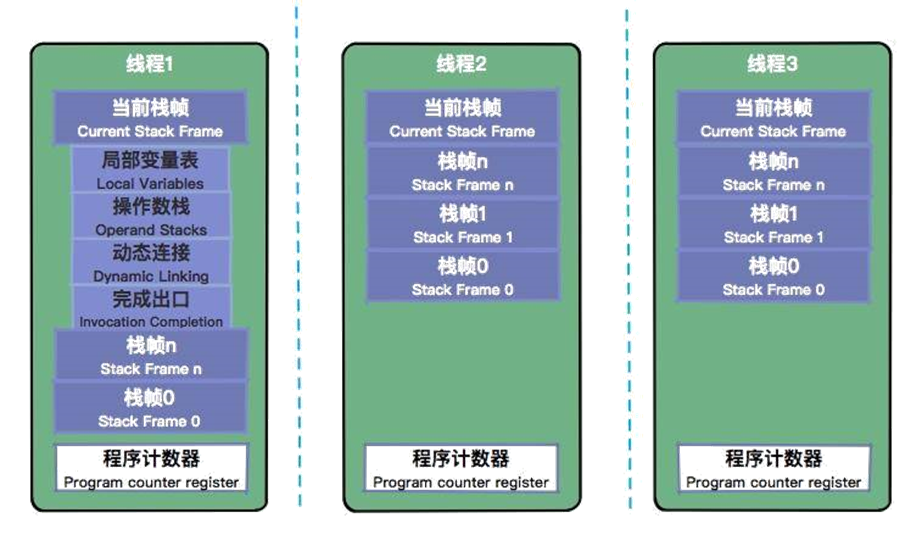
本地方法栈是和虚拟机栈非常相似的一个区域,它服务的对象是 native 方法。你甚至可以认为虚拟机栈和本地方法栈是同一个区域,这并不影响我们对 JVM 的了解。 这里有一个比较特殊的数据类型叫作 returnAdress。因为这种类型只存在于字节码层面,所以我们平常打交道的比较少。对于 JVM 来说,程序就是存储在方法区的字节码指令,而 returnAddress 类型的值就是指向特定指令内存地址的指针。
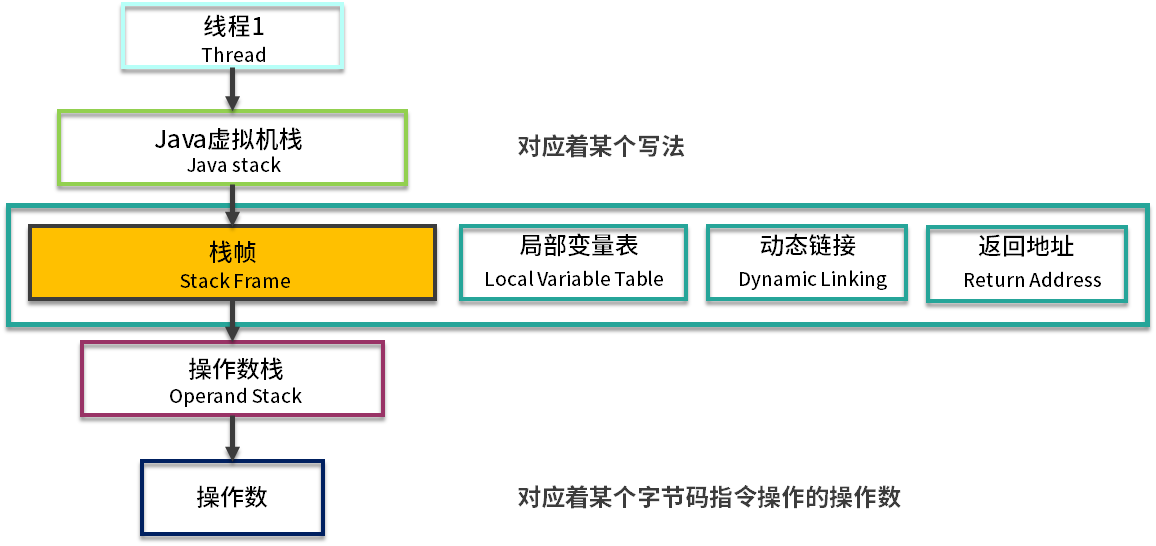
这部分有两个比较有意思的内容,面试中说出来会让面试官眼前一亮。
- 这里有一个两层的栈。第一层是栈帧,对应着方法;第二层是方法的执行,对应着操作数。注意千万不要搞混了。
- 你可以看到,所有的字节码指令,其实都会抽象成对栈的入栈出栈操作。执行引擎只需要傻瓜式的按顺序执行,就可以保证它的正确性。
这一点很神奇,也是基础。我们接下来从线程角度看一下里面的内容。
程序计数器
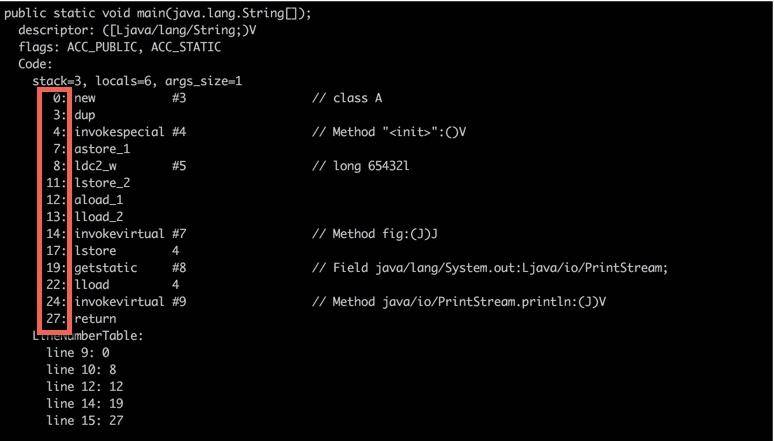
那么你设想一下,如果我们的程序在线程之间进行切换,凭什么能够知道这个线程已经执行到什么地方呢? 既然是线程,就代表它在获取 CPU 时间片上,是不可预知的,需要有一个地方,对线程正在运行的点位进行缓冲记录,以便在获取 CPU 时间片时能够快速恢复。 就好比你停下手中的工作,倒了杯茶,然后如何继续之前的工作? 程序计数器是一块较小的内存空间,它的作用可以看作是当前线程所执行的字节码的行号指示器。这里面存的,就是当前线程执行的进度。下面这张图,能够加深大家对这个过程的理解。
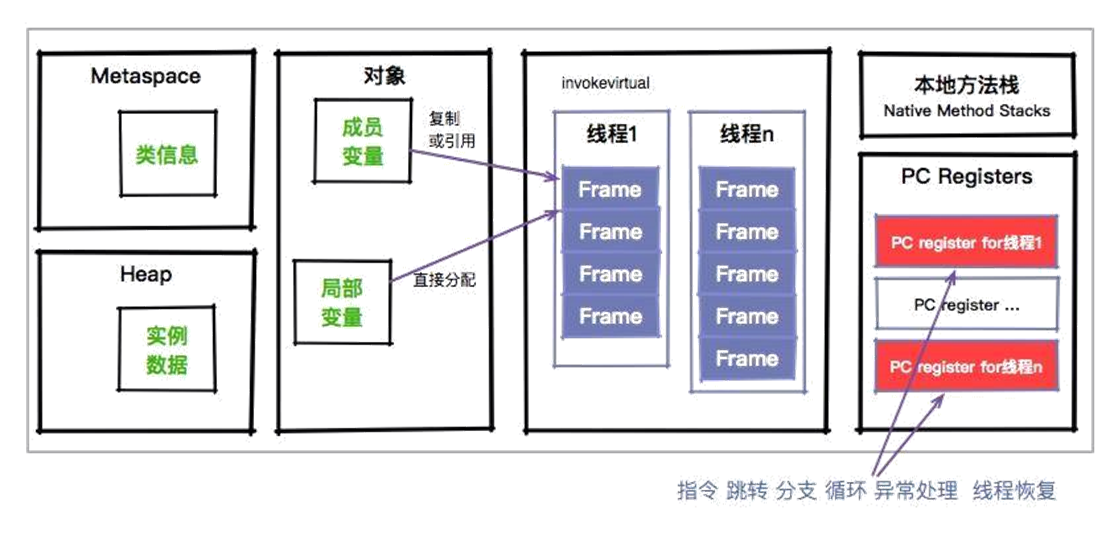
可以看到,程序计数器也是因为线程而产生的,与虚拟机栈配合完成计算操作。程序计数器还存储了当前正在运行的流程,包括正在执行的指令、跳转、分支、循环、异常处理等。 我们可以看一下程序计数器里面的具体内容。下面这张图,就是使用 javap 命令输出的字节码。大家可以看到在每个 opcode 前面,都有一个序号。就是图中红框中的偏移地址,你可以认为它们是程序计数器的内容。
堆
堆是 JVM 上最大的内存区域,我们申请的几乎所有的对象,都是在这里存储的。我们常说的垃圾回收,操作的对象就是堆。 堆空间一般是程序启动时,就申请了,但是并不一定会全部使用。 随着对象的频繁创建,堆空间占用的越来越多,就需要不定期的对不再使用的对象进行回收。这个在 Java 中,就叫作 GC(Garbage Collection)。 由于对象的大小不一,在长时间运行后,堆空间会被许多细小的碎片占满,造成空间浪费。所以,仅仅销毁对象是不够的,还需要堆空间整理。这个过程非常的复杂,我们会在后面有专门的课时进行介绍。 那一个对象创建的时候,到底是在堆上分配,还是在栈上分配呢?这和两个方面有关:对象的类型和在 Java 类中存在的位置。 Java 的对象可以分为基本数据类型和普通对象。 对于普通对象来说,JVM 会首先在堆上创建对象,然后在其他地方使用的其实是它的引用。比如,把这个引用保存在虚拟机栈的局部变量表中。 对于基本数据类型来说(byte、short、int、long、float、double、char),有两种情况。 我们上面提到,每个线程拥有一个虚拟机栈。当你在方法体内声明了基本数据类型的对象,它就会在栈上直接分配。其他情况,都是在堆上分配。 注意,像 int[] 数组这样的内容,是在堆上分配的。数组并不是基本数据类型。
这就是 JVM 的基本的内存分配策略。而堆是所有线程共享的,如果是多个线程访问,会涉及数据同步问题。这同样是个大话题,我们在这里先留下一个悬念。
元空间
关于元空间,我们还是以一个非常高频的面试题开始:“为什么有 Metaspace 区域?它有什么问题?” 说到这里,你应该回想一下类与对象的区别。对象是一个活生生的个体,可以参与到程序的运行中;类更像是一个模版,定义了一系列属性和操作。那么你可以设想一下。我们前面生成的 A.class,是放在 JVM 的哪个区域的? 想要问答这个问题,就不得不提下 Java 的历史。在 Java 8 之前,这些类的信息是放在一个叫 Perm 区的内存里面的。更早版本,甚至 String.intern 相关的运行时常量池也放在这里。这个区域有大小限制,很容易造成 JVM 内存溢出,从而造成 JVM 崩溃。 Perm 区在 Java 8 中已经被彻底废除,取而代之的是 Metaspace。原来的 Perm 区是在堆上的,现在的元空间是在非堆上的,这是背景。关于它们的对比,可以看下这张图。
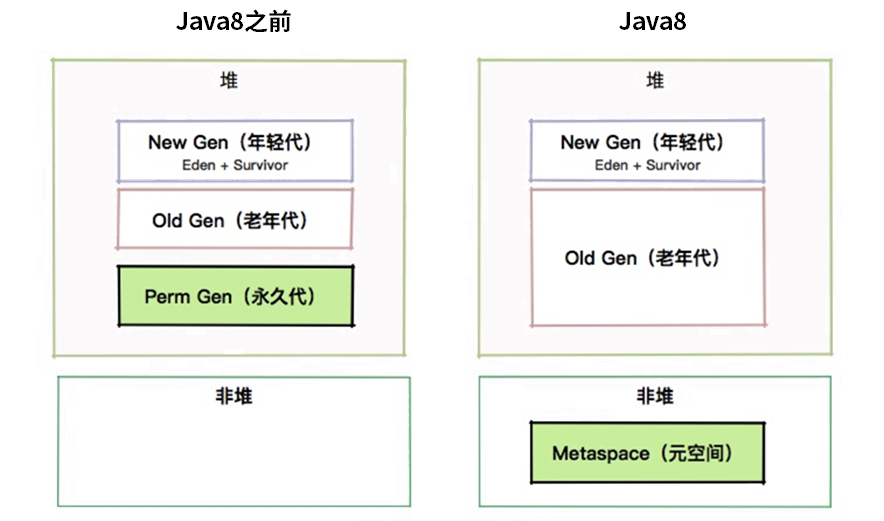
然后,元空间的好处也是它的坏处。使用非堆可以使用操作系统的内存,JVM 不会再出现方法区的内存溢出;但是,无限制的使用会造成操作系统的死亡。所以,一般也会使用参数 -XX:MaxMetaspaceSize 来控制大小。 方法区,作为一个概念,依然存在。它的物理存储的容器,就是 Metaspace。我们将在后面的课时中,再次遇到它。现在,你只需要了解到,这个区域存储的内容,包括:类的信息、常量池、方法数据、方法代码就可以了。
小结
好了,到这里本课时的基本内容就讲完了,针对这块的内容在面试中还经常会遇到下面这两个问题。
- 我们常说的字符串常量,存放在哪呢?
由于常量池,在 Java 7 之后,放到了堆中,我们创建的字符串,将会在堆上分配。
- 堆、非堆、本地内存,有什么关系?
关于它们的关系,我们可以看一张图。在我的感觉里,堆是软绵绵的,松散而有弹性;而非堆是冰冷生硬的,内存非常紧凑。
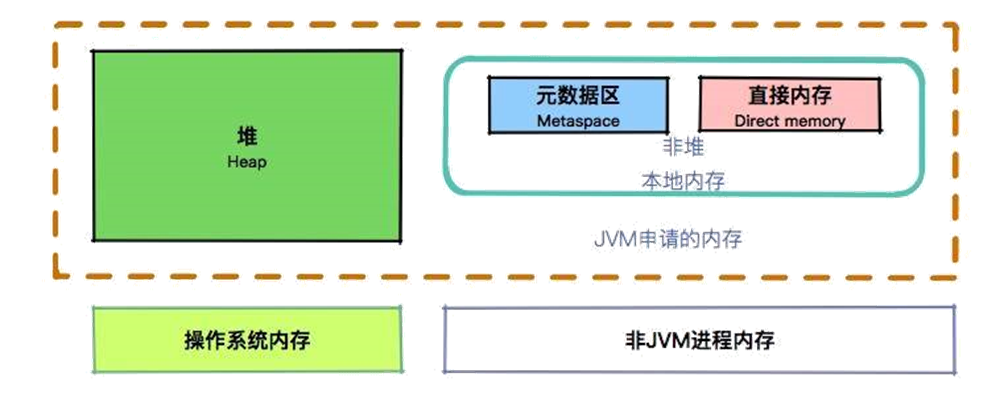
大家都知道,JVM 在运行时,会从操作系统申请大块的堆内内存,进行数据的存储。但是,堆外内存也就是申请后操作系统剩余的内存,也会有部分受到 JVM 的控制。比较典型的就是一些 native 关键词修饰的方法,以及对内存的申请和处理。 在 Linux 机器上,使用 top 或者 ps 命令,在大多数情况下,能够看到 RSS 段(实际的内存占用),是大于给 JVM 分配的堆内存的。 如果你申请了一台系统内存为 2GB 的主机,可能 JVM 能用的就只有 1GB,这便是一个限制。
总结
JVM 的运行时区域是栈,而存储区域是堆。很多变量,其实在编译期就已经固定了。.class 文件的字节码,由于助记符的作用,理解起来并不是那么吃力,我们将在课程最后几个课时,从字节码层面看一下多线程的特性。 JVM 的运行时特性,以及字节码,是比较偏底层的知识。本课时属于初步介绍,有些部分并未深入讲解。希望你应该能够在脑海里建立一个 Java 程序怎么运行的概念,以便我们在后面的课时中,提到相应的内存区域时,有个整体的印象。
第03讲:大厂面试题:从覆盖JDK的类开始掌握类的加载机制
本课时我们主要从覆盖 JDK 的类开始讲解 JVM 的类加载机制。其实,JVM 的类加载机制和 Java 的类加载机制类似,但 JVM 的类加载过程稍有些复杂。
前面课时我们讲到,JVM 通过加载 .class 文件,能够将其中的字节码解析成操作系统机器码。那这些文件是怎么加载进来的呢?又有哪些约定?接下来我们就详细介绍 JVM 的类加载机制,同时介绍三个实际的应用场景。
我们首先看几个面试题。
- 我们能够通过一定的手段,覆盖 HashMap 类的实现么?
- 有哪些地方打破了 Java 的类加载机制?
- 如何加载一个远程的 .class 文件?怎样加密 .class 文件?
关于类加载,很多同学都知道双亲委派机制,但这明显不够。面试官可能要你讲出几个能打破这个机制的例子,这个时候不要慌。上面几个问题,是我在接触的一些比较高级的面试场景中,遇到的一些问法。在平常的工作中,也有大量的相关应用,我们会理论联系实践综合分析这些问题。
类加载过程
现实中并不是说,我把一个文件修改成 .class 后缀,就能够被 JVM 识别。类的加载过程非常复杂,主要有这几个过程:加载、验证、准备、解析、初始化。这些术语很多地方都出现过,我们不需要死记硬背,而应该要了解它背后的原理和要做的事情。
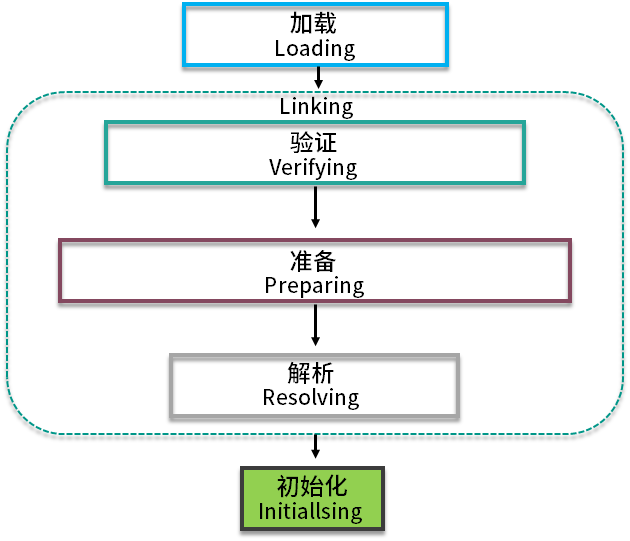
如图所示。大多数情况下,类会按照图中给出的顺序进行加载。下面我们就来分别介绍下这个过程。
加载
加载的主要作用是将外部的 .class 文件,加载到 Java 的方法区内,你可以回顾一下我们在上一课时讲的内存区域图。加载阶段主要是找到并加载类的二进制数据,比如从 jar 包里或者 war 包里找到它们。
验证
肯定不能任何 .class 文件都能加载,那样太不安全了,容易受到恶意代码的攻击。验证阶段在虚拟机整个类加载过程中占了很大一部分,不符合规范的将抛出 java.lang.VerifyError 错误。像一些低版本的 JVM,是无法加载一些高版本的类库的,就是在这个阶段完成的。
准备
从这部分开始,将为一些类变量分配内存,并将其初始化为默认值。此时,实例对象还没有分配内存,所以这些动作是在方法区上进行的。
我们顺便看一道面试题。下面两段代码,code-snippet 1 将会输出 0,而 code-snippet 2 将无法通过编译。
code-snippet 1:public class A {static int a ;public static void main(String[] args) {System.out.println(a);}}code-snippet 2:public class A {public static void main(String[] args) {int a;System.out.println(a);}}
为什么会有这种区别呢?
这是因为局部变量不像类变量那样存在准备阶段。类变量有两次赋初始值的过程,一次在准备阶段,赋予初始值(也可以是指定值);另外一次在初始化阶段,赋予程序员定义的值。
因此,即使程序员没有为类变量赋值也没有关系,它仍然有一个默认的初始值。但局部变量就不一样了,如果没有给它赋初始值,是不能使用的。
解析
解析在类加载中是非常非常重要的一环,是将符号引用替换为直接引用的过程。这句话非常的拗口,其实理解起来也非常的简单。
符号引用是一种定义,可以是任何字面上的含义,而直接引用就是直接指向目标的指针、相对偏移量。
直接引用的对象都存在于内存中,你可以把通讯录里的女友手机号码,类比为符号引用,把面对面和你吃饭的人,类比为直接引用。
解析阶段负责把整个类激活,串成一个可以找到彼此的网,过程不可谓不重要。那这个阶段都做了哪些工作呢?大体可以分为:
- 类或接口的解析
- 类方法解析
- 接口方法解析
- 字段解析
我们来看几个经常发生的异常,就与这个阶段有关。
- java.lang.NoSuchFieldError 根据继承关系从下往上,找不到相关字段时的报错。
- java.lang.IllegalAccessError 字段或者方法,访问权限不具备时的错误。
- java.lang.NoSuchMethodError 找不到相关方法时的错误。
解析过程保证了相互引用的完整性,把继承与组合推进到运行时。
初始化
如果前面的流程一切顺利的话,接下来该初始化成员变量了,到了这一步,才真正开始执行一些字节码。
接下来是另一道面试题,你可以猜想一下,下面的代码,会输出什么?
public class A {static int a = 0 ;static {a = 1;b = 1;}static int b = 0;public static void main(String[] args) {System.out.println(a);System.out.println(b);}}
结果是 1 0。a 和 b 唯一的区别就是它们的 static 代码块的位置。
这就引出一个规则:static 语句块,只能访问到定义在 static 语句块之前的变量。所以下面的代码是无法通过编译的。
static {b = b + 1;}static int b = 0;
我们再来看第二个规则:JVM 会保证在子类的初始化方法执行之前,父类的初始化方法已经执行完毕。
所以,JVM 第一个被执行的类初始化方法一定是 java.lang.Object。另外,也意味着父类中定义的 static 语句块要优先于子类的。
与
说到这里,不得不再说一个面试题: 方法和方法有什么区别?
主要是为了让你弄明白类的初始化和对象的初始化之间的差别。
public class A {static {System.out.println("1");}public A() {System.out.println("2");}
}public class B extends A {static {System.out.println("a");}public B() {System.out.println("b");}public static void main(String[] args) {A ab = new B();ab = new B();}
}
先公布下答案:
1
a
2
b
2
b
你可以看下这张图。其中 static 字段和 static 代码块,是属于类的,在类的加载的初始化阶段就已经被执行。类信息会被存放在方法区,在同一个类加载器下,这些信息有一份就够了,所以上面的 static 代码块只会执行一次,它对应的是 方法。
而对象初始化就不一样了。通常,我们在 new 一个新对象的时候,都会调用它的构造方法,就是 ,用来初始化对象的属性。每次新建对象的时候,都会执行。
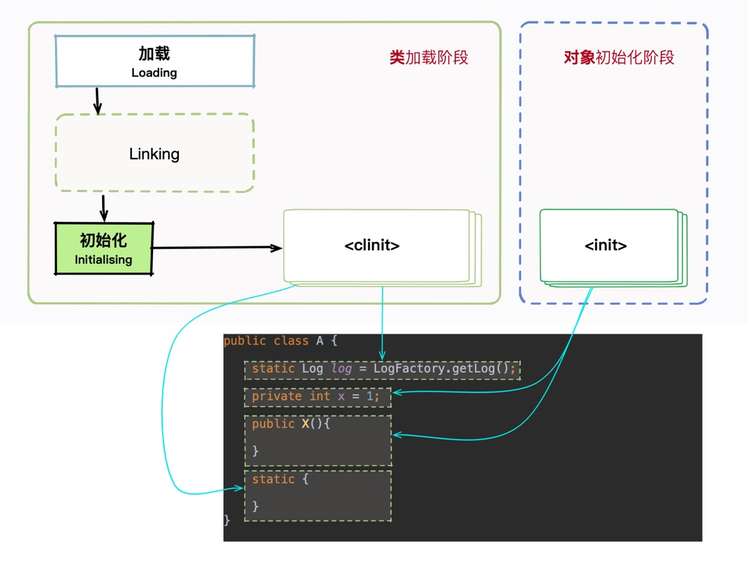
所以,上面代码的 static 代码块只会执行一次,对象的构造方法执行两次。再加上继承关系的先后原则,不难分析出正确结果。
类加载器
整个类加载过程任务非常繁重,虽然这活儿很累,但总得有人干。类加载器做的就是上面 5 个步骤的事。
如果你在项目代码里,写一个 java.lang 的包,然后改写 String 类的一些行为,编译后,发现并不能生效。JRE 的类当然不能轻易被覆盖,否则会被别有用心的人利用,这就太危险了。
那类加载器是如何保证这个过程的安全性呢?其实,它是有着严格的等级制度的。
几个类加载器
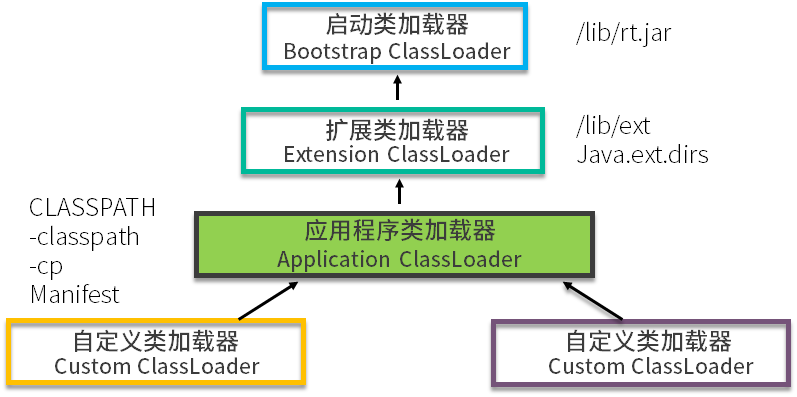
首先,我们介绍几个不同等级的类加载器。
- Bootstrap ClassLoader
这是加载器中的大 Boss,任何类的加载行为,都要经它过问。它的作用是加载核心类库,也就是 rt.jar、resources.jar、charsets.jar 等。当然这些 jar 包的路径是可以指定的,-Xbootclasspath 参数可以完成指定操作。
这个加载器是 C++ 编写的,随着 JVM 启动。
- Extention ClassLoader
扩展类加载器,主要用于加载 lib/ext 目录下的 jar 包和 .class 文件。同样的,通过系统变量 java.ext.dirs 可以指定这个目录。
这个加载器是个 Java 类,继承自 URLClassLoader。
- App ClassLoader
这是我们写的 Java 类的默认加载器,有时候也叫作 System ClassLoader。一般用来加载 classpath 下的其他所有 jar 包和 .class 文件,我们写的代码,会首先尝试使用这个类加载器进行加载。
- Custom ClassLoader
自定义加载器,支持一些个性化的扩展功能。
双亲委派机制
关于双亲委派机制的问题面试中经常会被问到,你可能已经倒背如流了。
双亲委派机制的意思是除了顶层的启动类加载器以外,其余的类加载器,在加载之前,都会委派给它的父加载器进行加载。这样一层层向上传递,直到祖先们都无法胜任,它才会真正的加载。
打个比方。有一个家族,都是一些听话的孩子。孙子想要买一块棒棒糖,最终都要经过爷爷过问,如果力所能及,爷爷就直接帮孙子买了。
但你有没有想过,“类加载的双亲委派机制,双亲在哪里?明明都是单亲?”
我们还是用一张图来讲解。可以看到,除了启动类加载器,每一个加载器都有一个parent,并没有所谓的双亲。但是由于翻译的问题,这个叫法已经非常普遍了,一定要注意背后的差别。
我们可以翻阅 JDK 代码的 ClassLoader#loadClass 方法,来看一下具体的加载过程。和我们描述的一样,它首先使用 parent 尝试进行类加载,parent 失败后才轮到自己。同时,我们也注意到,这个方法是可以被覆盖的,也就是双亲委派机制并不一定生效。
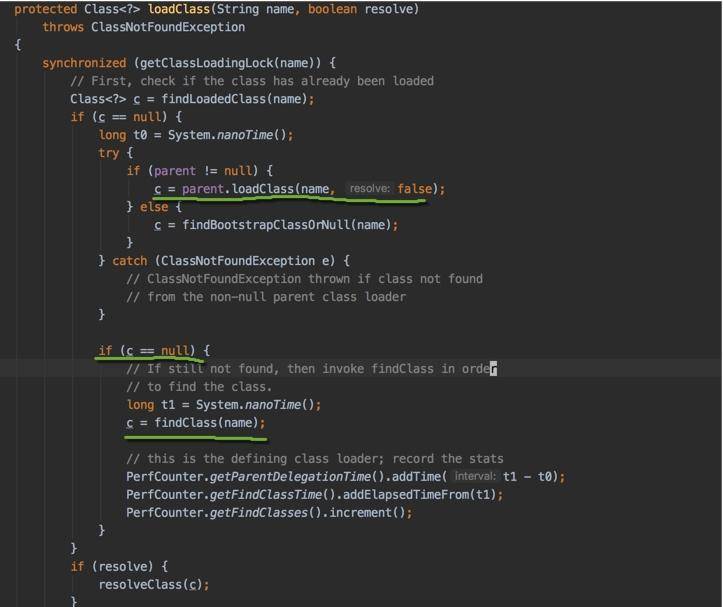
这个模型的好处在于 Java 类有了一种优先级的层次划分关系。比如 Object 类,这个毫无疑问应该交给最上层的加载器进行加载,即使是你覆盖了它,最终也是由系统默认的加载器进行加载的。
如果没有双亲委派模型,就会出现很多个不同的 Object 类,应用程序会一片混乱。
一些自定义加载器
下面我们就来聊一聊可以打破双亲委派机制的一些案例。为了支持一些自定义加载类多功能的需求,Java 设计者其实已经作出了一些妥协。
案例一:tomcat
tomcat 通过 war 包进行应用的发布,它其实是违反了双亲委派机制原则的。简单看一下 tomcat 类加载器的层次结构。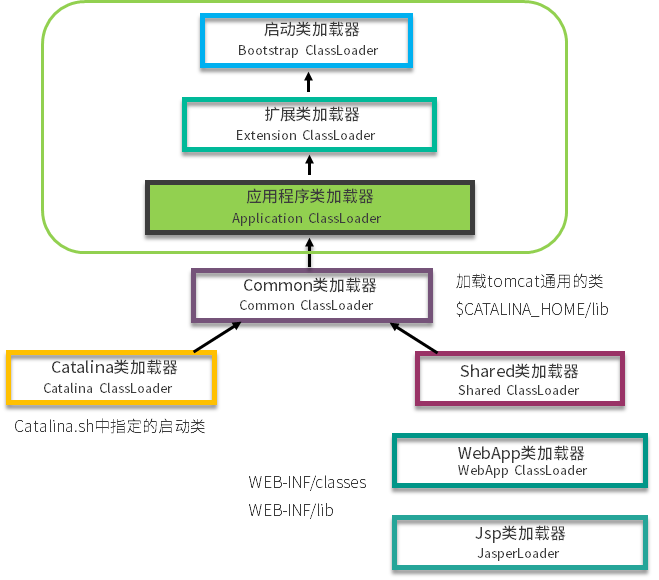
对于一些需要加载的非基础类,会由一个叫作 WebAppClassLoader 的类加载器优先加载。等它加载不到的时候,再交给上层的 ClassLoader 进行加载。这个加载器用来隔绝不同应用的 .class 文件,比如你的两个应用,可能会依赖同一个第三方的不同版本,它们是相互没有影响的。
如何在同一个 JVM 里,运行着不兼容的两个版本,当然是需要自定义加载器才能完成的事。
那么 tomcat 是怎么打破双亲委派机制的呢?可以看图中的 WebAppClassLoader,它加载自己目录下的 .class 文件,并不会传递给父类的加载器。但是,它却可以使用 SharedClassLoader 所加载的类,实现了共享和分离的功能。
但是你自己写一个 ArrayList,放在应用目录里,tomcat 依然不会加载。它只是自定义的加载器顺序不同,但对于顶层来说,还是一样的。
案例二:SPI
Java 中有一个 SPI 机制,全称是 Service Provider Interface,是 Java 提供的一套用来被第三方实现或者扩展的 API,它可以用来启用框架扩展和替换组件。
这个说法可能比较晦涩,但是拿我们常用的数据库驱动加载来说,就比较好理解了。在使用 JDBC 写程序之前,通常会调用下面这行代码,用于加载所需要的驱动类。
Class.forName("com.mysql.jdbc.Driver")
这只是一种初始化模式,通过 static 代码块显式地声明了驱动对象,然后把这些信息,保存到底层的一个 List 中。这种方式我们不做过多的介绍,因为这明显就是一个接口编程的思路,没什么好奇怪的。
但是你会发现,即使删除了 Class.forName 这一行代码,也能加载到正确的驱动类,什么都不需要做,非常的神奇,它是怎么做到的呢?
我们翻开 MySQL 的驱动代码,发现了一个奇怪的文件。之所以能够发生这样神奇的事情,就是在这里实现的。
路径:
mysql-connector-java-8.0.15.jar!/META-INF/services/java.sql.Driver
里面的内容是:
com.mysql.cj.jdbc.Driver
通过在 META-INF/services 目录下,创建一个以接口全限定名为命名的文件(内容为实现类的全限定名),即可自动加载这一种实现,这就是 SPI。
SPI 实际上是“基于接口的编程+策略模式+配置文件”组合实现的动态加载机制,主要使用 java.util.ServiceLoader 类进行动态装载。
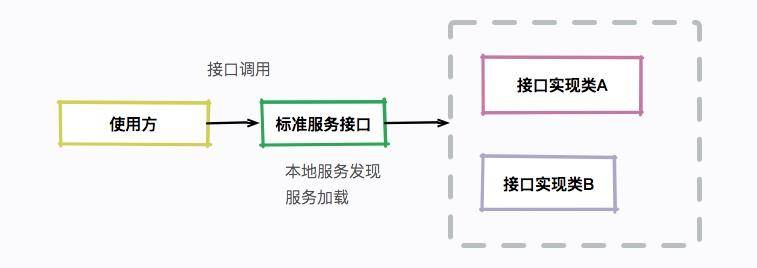
这种方式,同样打破了双亲委派的机制。
DriverManager 类和 ServiceLoader 类都是属于 rt.jar 的。它们的类加载器是 Bootstrap ClassLoader,也就是最上层的那个。而具体的数据库驱动,却属于业务代码,这个启动类加载器是无法加载的。这就比较尴尬了,虽然凡事都要祖先过问,但祖先没有能力去做这件事情,怎么办?
我们可以一步步跟踪代码,来看一下这个过程。
//part1:DriverManager::loadInitialDrivers
//jdk1.8 之后,变成了lazy的ensureDriversInitialized...ServiceLoader <Driver> loadedDrivers = ServiceLoader.load(Driver.class);Iterator<Driver> driversIterator = loadedDrivers.iterator();...//part2:ServiceLoader::loadpublic static <T> ServiceLoader<T> load(Class<T> service) {ClassLoader cl = Thread.currentThread().getContextClassLoader();return ServiceLoader.load(service, cl);}
通过代码你可以发现 Java 玩了个魔术,它把当前的类加载器,设置成了线程的上下文类加载器。那么,对于一个刚刚启动的应用程序来说,它当前的加载器是谁呢?也就是说,启动 main 方法的那个加载器,到底是哪一个?
所以我们继续跟踪代码。找到 Launcher 类,就是 jre 中用于启动入口函数 main 的类。我们在 Launcher 中找到以下代码。
public Launcher() {Launcher.ExtClassLoader var1;try {var1 = Launcher.ExtClassLoader.getExtClassLoader();} catch (IOException var10) {throw new InternalError("Could not create extension class loader", var10);}try {this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);} catch (IOException var9) {throw new InternalError("Could not create application class loader", var9);}Thread.currentThread().setContextClassLoader(this.loader);...
}
到此为止,事情就比较明朗了,当前线程上下文的类加载器,是应用程序类加载器。使用它来加载第三方驱动,是没有什么问题的。
我们之所以花大量的篇幅来介绍这个过程,第一,可以让你更好的看到一个打破规则的案例。第二,这个问题面试时出现的几率也是比较高的,你需要好好理解。
案例三:OSGi
OSGi 曾经非常流行,Eclipse 就使用 OSGi 作为插件系统的基础。OSGi 是服务平台的规范,旨在用于需要长运行时间、动态更新和对运行环境破坏最小的系统。
OSGi 规范定义了很多关于包生命周期,以及基础架构和绑定包的交互方式。这些规则,通过使用特殊 Java 类加载器来强制执行,比较霸道。
比如,在一般 Java 应用程序中,classpath 中的所有类都对所有其他类可见,这是毋庸置疑的。但是,OSGi 类加载器基于 OSGi 规范和每个绑定包的 manifest.mf 文件中指定的选项,来限制这些类的交互,这就让编程风格变得非常的怪异。但我们不难想象,这种与直觉相违背的加载方式,肯定是由专用的类加载器来实现的。
随着 jigsaw 的发展(旨在为 Java SE 平台设计、实现一个标准的模块系统),我个人认为,现在的 OSGi,意义已经不是很大了。OSGi 是一个庞大的话题,你只需要知道,有这么一个复杂的东西,实现了模块化,每个模块可以独立安装、启动、停止、卸载,就可以了。
不过,如果你有机会接触相关方面的工作,也许会不由的发出感叹:原来 Java 的类加载器,可以玩出这么多花样。
如何替换 JDK 的类
让我们回到本课时开始的问题,如何替换 JDK 中的类?比如,我们现在就拿 HashMap为例。
当 Java 的原生 API 不能满足需求时,比如我们要修改 HashMap 类,就必须要使用到 Java 的 endorsed 技术。我们需要将自己的 HashMap 类,打包成一个 jar 包,然后放到 -Djava.endorsed.dirs 指定的目录中。注意类名和包名,应该和 JDK 自带的是一样的。但是,java.lang 包下面的类除外,因为这些都是特殊保护的。
因为我们上面提到的双亲委派机制,是无法直接在应用中替换 JDK 的原生类的。但是,有时候又不得不进行一下增强、替换,比如你想要调试一段代码,或者比 Java 团队早发现了一个 Bug。所以,Java 提供了 endorsed 技术,用于替换这些类。这个目录下的 jar 包,会比 rt.jar 中的文件,优先级更高,可以被最先加载到。
小结
通过本课时的学习我们可以了解到,一个 Java 类的加载,经过了加载、验证、准备、解析、初始化几个过程,每一个过程都划清了各自负责的事情。
接下来,我们了解到 Java 自带的三个类加载器。同时了解到,main 方法的线程上下文加载器,其实是 Application ClassLoader。
一般情况下,类加载是遵循双亲委派机制的。我们也认识到,这个双亲,很有问题。通过 3 个案例的学习和介绍,可以看到有很多打破这个规则的情况。类加载器通过开放的 API,让加载过程更加灵活。
Java 的类加载器是非常重要的知识点,也是面试常考的知识点,本课时提供了多个面试题,你可以实际操作体验一下。
第04讲:动手实践:从栈帧看字节码是如何在JVM中进行流转的
在上一课时我们掌握了 JVM 的内存区域划分,以及 .class 文件的加载机制。也了解到很多初始化动作是在不同的阶段发生的。
但你可能仍对以下这些问题有疑问:
- 怎么查看字节码文件?
- 字节码文件长什么样子?
- 对象初始化之后,具体的字节码又是怎么执行的?
带着这些疑问,我们进入本课时的学习,本课时将带你动手实践,详细分析一个 Java 文件产生的字节码,并从栈帧层面看一下字节码的具体执行过程。
工具介绍
工欲善其事,必先利其器。在开始本课时的内容之前,先给你介绍两个分析字节码的小工具。
javap
第一个小工具是 javap,javap 是 JDK 自带的反解析工具。它的作用是将 .class 字节码文件解析成可读的文件格式。我们在第一课时,就是用的它输出了 HelloWorld 的内容。
在使用 javap 时我一般会添加 -v 参数,尽量多打印一些信息。同时,我也会使用 -p 参数,打印一些私有的字段和方法。使用起来大概是这样:
javap -p -v HelloWorld
在 Stack Overflow 上有一个非常有意思的问题:我在某个类中增加一行注释之后,为什么两次生成的 .class 文件,它们的 MD5 是不一样的?
这是因为在 javac 中可以指定一些额外的内容输出到字节码。经常用的有
- javac -g:lines 强制生成 LineNumberTable。
- javac -g:vars 强制生成 LocalVariableTable。
- javac -g 生成所有的 debug 信息。
为了观察字节码的流转,我们本课时就会使用到这些参数。
jclasslib
如果你不太习惯使用命令行的操作,还可以使用 jclasslib,jclasslib 是一个图形化的工具,能够更加直观的查看字节码中的内容。它还分门别类的对类中的各个部分进行了整理,非常的人性化。同时,它还提供了 Idea 的插件,你可以从 plugins 中搜索到它。
如果你在其中看不到一些诸如 LocalVariableTable 的信息,记得在编译代码的时候加上我们上面提到的这些参数。
jclasslib 的下载地址:https://github.com/ingokegel/jclasslib
类加载和对象创建的时机
接下来,我们来看一个稍微复杂的例子,来具体看一下类加载和对象创建的过程。
首先,我们写一个最简单的 Java 程序 A.java。它有一个公共方法 test,还有一个静态成员变量和动态成员变量。
class B {private int a = 1234;static long C = 1111;public long test(long num) {long ret = this.a + num + C;return ret;}
}public class A {private B b = new B();public static void main(String[] args) {A a = new A();long num = 4321;long ret = a.b.test(num);System.out.println(ret);}
}
前面我们提到,类的初始化发生在类加载阶段,那对象都有哪些创建方式呢?除了我们常用的 new,还有下面这些方式:
- 使用 Class 的 newInstance 方法。
- 使用 Constructor 类的 newInstance 方法。
- 反序列化。
- 使用 Object 的 clone 方法。
其中,后面两种方式没有调用到构造函数。
当虚拟机遇到一条 new 指令时,首先会检查这个指令的参数能否在常量池中定位一个符号引用。然后检查这个符号引用的类字节码是否加载、解析和初始化。如果没有,将执行对应的类加载过程。
拿我们上面的代码来说,执行 A 代码,在调用 private B b = new B() 时,就会触发 B 类的加载。
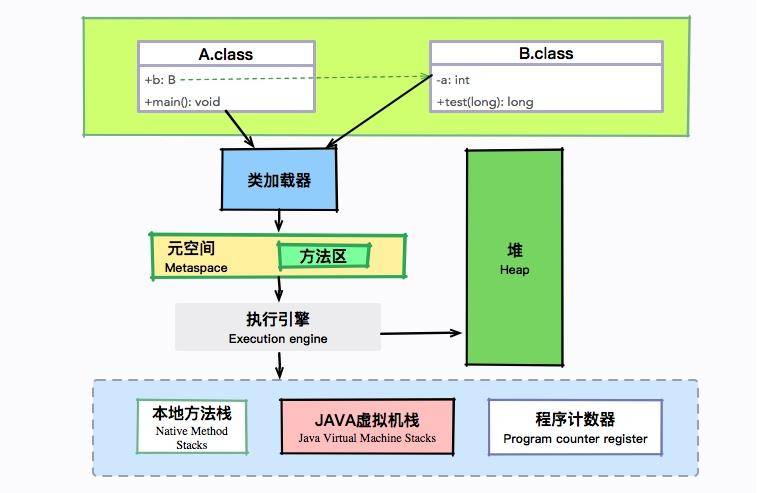
让我们结合上图回顾一下前面章节的内容。A 和 B 会被加载到元空间的方法区,进入 main 方法后,将会交给执行引擎执行。这个执行过程是在栈上完成的,其中有几个重要的区域,包括虚拟机栈、程序计数器等。接下来我们详细看一下虚拟机栈上的执行过程。
查看字节码
命令行查看字节码
使用下面的命令编译源代码 A.java。如果你用的是 Idea,可以直接将参数追加在 VM options 里面。
javac -g:lines -g:vars A.java
这将强制生成 LineNumberTable 和 LocalVariableTable。
然后使用 javap 命令查看 A 和 B 的字节码。
javap -p -v A
javap -p -v B
这个命令,不仅会输出行号、本地变量表信息、反编译汇编代码,还会输出当前类用到的常量池等信息。由于内容很长,这里就不具体展示了,你可以使用上面的命令实际操作一下就可以了。
注意 javap 中的如下字样。
<1>
1: invokespecial #1 // Method java/lang/Object."<init>":()V
可以看到对象的初始化,首先是调用了 Object 类的初始化方法。注意这里是 而不是 。
<2>
#2 = Fieldref #6.#27 // B.a:I
它其实直接拼接了 #13 和 #14 的内容。
#6 = Class #29 // B
#27 = NameAndType #8:#9 // a:I
...
#8 = Utf8 a
#9 = Utf8 I
<3>
你会注意到 :I 这样特殊的字符。它们也是有意义的,如果你经常使用 jmap 这种命令,应该不会陌生。大体包括:
- B 基本类型 byte
- C 基本类型 char
- D 基本类型 double
- F 基本类型 float
- I 基本类型 int
- J 基本类型 long
- S 基本类型 short
- Z 基本类型 boolean
- V 特殊类型 void
- L 对象类型,以分号结尾,如 Ljava/lang/Object;
- [Ljava/lang/String; 数组类型,每一位使用一个前置的”[“字符来描述
我们注意到 code 区域,有非常多的二进制指令。如果你接触过汇编语言,会发现它们之间其实有一定的相似性。但这些二进制指令,并不是操作系统能够认识的,它们是提供给 JVM 运行的源材料。
可视化查看字节码
接下来,我们就可以使用更加直观的工具 jclasslib,来查看字节码中的具体内容了。
我们以 B.class 文件为例,来查看它的内容。
<1>
首先,我们能够看到 Constant Pool(常量池),这些内容,就存放于我们的 Metaspace 区域,属于非堆。
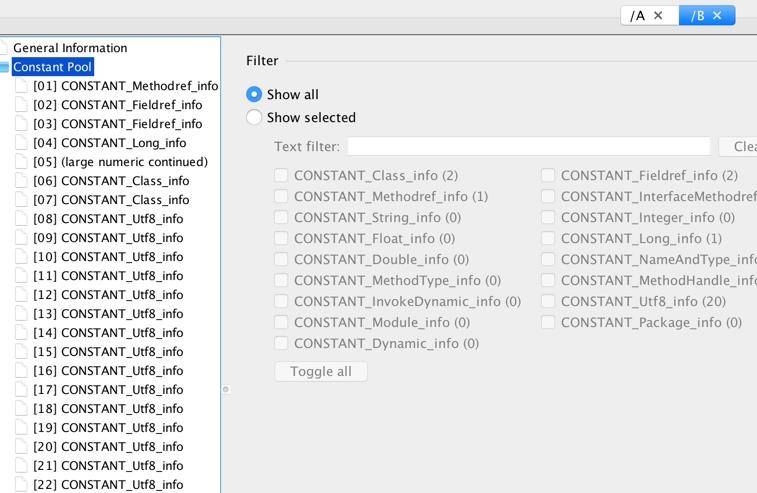
常量池包含 .class 文件常量池、运行时常量池、String 常量池等部分,大多是一些静态内容。
<2>
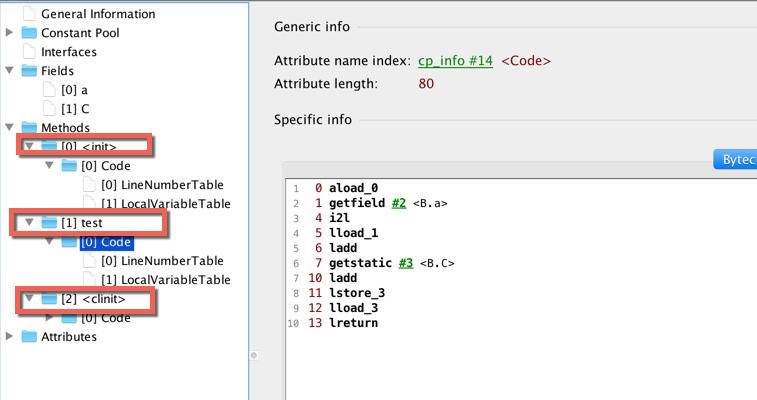
接下来,可以看到两个默认的 和 方法。以下截图是 test 方法的 code 区域,比命令行版的更加直观。
<3>
继续往下看,我们看到了 LocalVariableTable 的三个变量。其中,slot 0 指向的是 this 关键字。该属性的作用是描述帧栈中局部变量与源码中定义的变量之间的关系。如果没有这些信息,那么在 IDE 中引用这个方法时,将无法获取到方法名,取而代之的则是 arg0 这样的变量名。
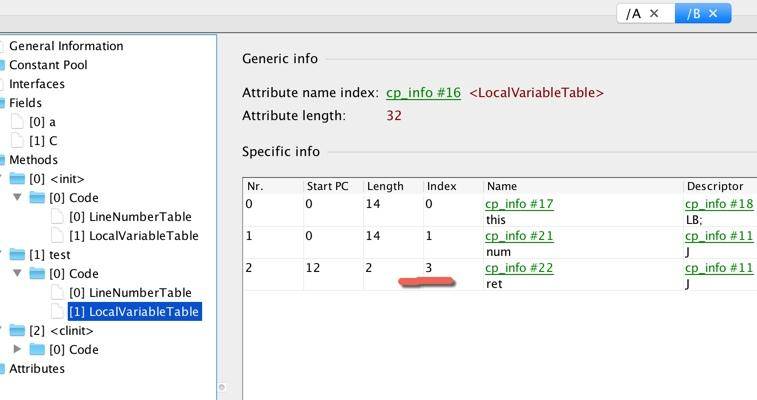
本地变量表的 slot 是可以复用的。注意一个有意思的地方,index 的最大值为 3,证明了本地变量表同时最多能够存放 4 个变量。
另外,我们观察到还有 LineNumberTable 等选项。该属性的作用是描述源码行号与字节码行号(字节码偏移量)之间的对应关系,有了这些信息,在 debug 时,就能够获取到发生异常的源代码行号。
test 函数执行过程
Code 区域介绍
test 函数同时使用了成员变量 a、静态变量 C,以及输入参数 num。我们此时说的函数执行,内存其实就是在虚拟机栈上分配的。下面这些内容,就是 test 方法的字节码。
public long test(long);descriptor: (J)Jflags: ACC_PUBLICCode:stack=4, locals=5, args_size=20: aload_01: getfield #2 // Field a:I4: i2l5: lload_16: ladd7: getstatic #3 // Field C:J10: ladd11: lstore_312: lload_313: lreturnLineNumberTable:line 13: 0line 14: 12LocalVariableTable:Start Length Slot Name Signature0 14 0 this LB;0 14 1 num J12 2 3 ret J
我们介绍一下比较重要的 3 三个数值。 <1>
首先,注意 stack 字样,它此时的数值为 4,表明了 test 方法的最大操作数栈深度为 4。JVM 运行时,会根据这个数值,来分配栈帧中操作栈的深度。
<2>
相对应的,locals 变量存储了局部变量的存储空间。它的单位是 Slot(槽),可以被重用。其中存放的内容,包括:
- this
- 方法参数
- 异常处理器的参数
- 方法体中定义的局部变量
<3>
args_size 就比较好理解。它指的是方法的参数个数,因为每个方法都有一个隐藏参数 this,所以这里的数字是 2。
字节码执行过程
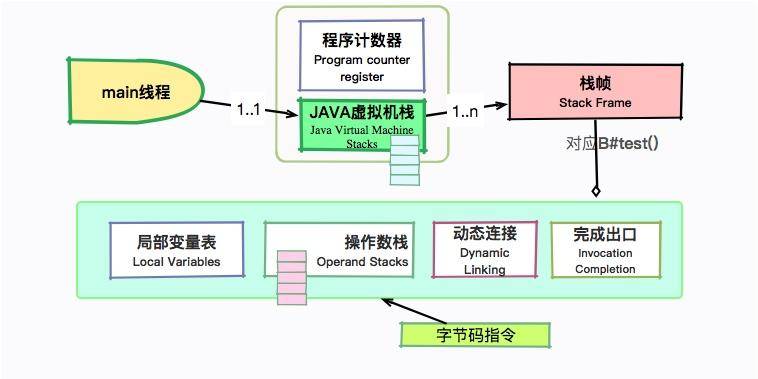
我们稍微回顾一下 JVM 运行时的相关内容。main 线程会拥有两个主要的运行时区域:Java 虚拟机栈和程序计数器。其中,虚拟机栈中的每一项内容叫作栈帧,栈帧中包含四项内容:局部变量报表、操作数栈、动态链接和完成出口。
我们的字节码指令,就是靠操作这些数据结构运行的。下面我们看一下具体的字节码指令。
(1)0: aload_0
把第 1 个引用型局部变量推到操作数栈,这里的意思是把 this 装载到了操作数栈中。
对于 static 方法,aload_0 表示对方法的第一个参数的操作。

(2)1: getfield #2
将栈顶的指定的对象的第 2 个实例域(Field)的值,压入栈顶。#2 就是指的我们的成员变量 a。
#2 = Fieldref #6.#27 // B.a:I
...
#6 = Class #29 // B
#27 = NameAndType #8:#9 // a:I

(3)i2l
将栈顶 int 类型的数据转化为 long 类型,这里就涉及我们的隐式类型转换了。图中的信息没有变动,不再详解介绍。
(4)lload_1
将第一个局部变量入栈。也就是我们的参数 num。这里的 l 表示 long,同样用于局部变量装载。你会看到这个位置的局部变量,一开始就已经有值了。

(5)ladd
把栈顶两个 long 型数值出栈后相加,并将结果入栈。

(6)getstatic #3
根据偏移获取静态属性的值,并把这个值 push 到操作数栈上。

(7)ladd
再次执行 ladd。

(8)lstore_3
把栈顶 long 型数值存入第 4 个局部变量。
还记得我们上面的图么?slot 为 4,索引为 3 的就是 ret 变量。

(9)lload_3
正好与上面相反。上面是变量存入,我们现在要做的,就是把这个变量 ret,压入虚拟机栈中。

(10)lreturn
从当前方法返回 long。
到此为止,我们的函数就完成了相加动作,执行成功了。JVM 为我们提供了非常丰富的字节码指令。详细的字节码指令列表,可以参考以下网址:
https://docs.oracle.com/javase/specs/jvms/se8/html/jvms-6.html
注意点
注意上面的第 8 步,我们首先把变量存放到了变量报表,然后又拿出这个值,把它入栈。为什么会有这种多此一举的操作?原因就在于我们定义了 ret 变量。JVM 不知道后面还会不会用到这个变量,所以只好傻瓜式的顺序执行。
为了看到这些差异。大家可以把我们的程序稍微改动一下,直接返回这个值。
public long test(long num) {return this.a + num + C;
}
再次看下,对应的字节码指令是不是简单了很多?
0: aload_0
1: getfield #2 // Field a:I
4: i2l
5: lload_1
6: ladd
7: getstatic #3 // Field C:J
10: ladd
11: lreturn
那我们以后编写程序时,是不是要尽量少的定义成员变量?
这是没有必要的。栈的操作复杂度是 O(1),对我们的程序性能几乎没有影响。平常的代码编写,还是以可读性作为首要任务。
小结
本课时,我们学会了使用 javap 和 jclasslib 两个工具。平常工作中,掌握第一个就够了,后者主要为我们提供更加直观的展示。
我们从实际分析一段代码开始,详细介绍了几个字节码指令对程序计数器、局部变量表、操作数栈等内容的影响,初步接触了 Java 的字节码文件格式。
希望你能够建立起一个运行时的脉络,在看到相关的 opcode 时,能够举一反三的思考背后对这些数据结构的操作。这样理解的字节码指令,根本不会忘。
你还可以尝试着对 A 类的代码进行分析,我们这里先留下一个悬念。课程后面会详细介绍 JVM 在方法调用上的一些特点。