大模型-vllm云端部署模型快速上手体验-5
一、环境部署
官方教程 LLM Class | vLLM 中文站,这里面的官方教程非常详细,可以多看看。
1.1. 使用虚拟环境配置环境
在虚拟环境中安装vllm
直接创建虚拟环境运行部署vllm
Sudo apt-get update
sudo apt-get install python3.10 python3-distutils libpython3.10
sudo python3.10 -m venv asr-vllmsource asr-vllm/bin/activat
pip install vllm==0.11.0 -i https://mirrors.aliyun.com/pypi/simple/1.2 直接拉取镜像
拉取包含vllm的官方镜像,使用docker 进行启动容器,那么启动的容器中就已经包含了vllm。
Using Docker - vLLM
docker run --runtime nvidia --gpus all \-v ~/.cache/huggingface:/root/.cache/huggingface \--env "HF_TOKEN=$HF_TOKEN" \-p 8000:8000 \--ipc=host \vllm/vllm-openai:latest \--model Qwen/Qwen3-0.6B1.3 拉取源码,进行自己编译
git clone https://github.com/vllm-project/vllm.git
cd vllm
python use_existing_torch.py
pip install -r requirements-build.txt
pip install -e . --no-build-isolation二、离线部署
vllm是开源项目,支持使用python api 进行的模型的离线推理,达到本地快速验证的功能,以下一个快速本地部署验证的示例:
# _*_ coding:utf-8_*_from vllm import LLM, SamplingParamsprompts = ["你好,介绍深圳,字数在100","中国的首都在哪里",
]# ------------------------------------------------------sampling_params = SamplingParams(temperature=0.8,top_p=0.95,max_tokens=100
)llm = LLM(model="/home/shengqing.liu/vllm/qwen3-1.7B/",trust_remote_code=True,max_model_len=1024
)
outputs = llm.generate(prompts, sampling_params)
for output in outputs:prompt = output.promptgenerated_text = output.outputs[0].textprint("=" * 50)print(f"Prompt: {prompt}")print(f"Generated text: {generated_text}")
轉換成utf8的格式
iconv -f GBK -t UTF-8 vllm_infer_demo_utf8.py -o vllm_infer_demo_fixed.py
或者
:set fileencoding=utf-8
:wq
python ./offline_infer_qwen.py三、在线部署
设置gpu-memory-utilization的利用率==0.7,不然内存不够,容易显卡的内存溢出 再次使用指令启动服务端:
python -m vllm.entrypoints.openai.api_server \--model /home/shengqing.liu/vllm/qwen3-1.7B/ \--port 8000 \--host 0.0.0.0 \--tensor-parallel-size 1 \--dtype auto--gpu-memory-utilization 0.7
参数含义
--model模型路径(本地或 HuggingFace 名称)
--port服务监听端口
--host允许远程访问
--tensor-parallel-sizeGPU并行数(单卡设为 1)
--dtype auto自动选择 FP16/BF16/FP32
--api-key(可选)自定义访问密钥提供以下的访问接口:
POST http://<ip>:8000/v1/completions
POST http://<ip>:8000/v1/chat/completions列出模型list
curl http://localhost:8000/v1/models查看托管模型列表。

curl的快速访问测试:
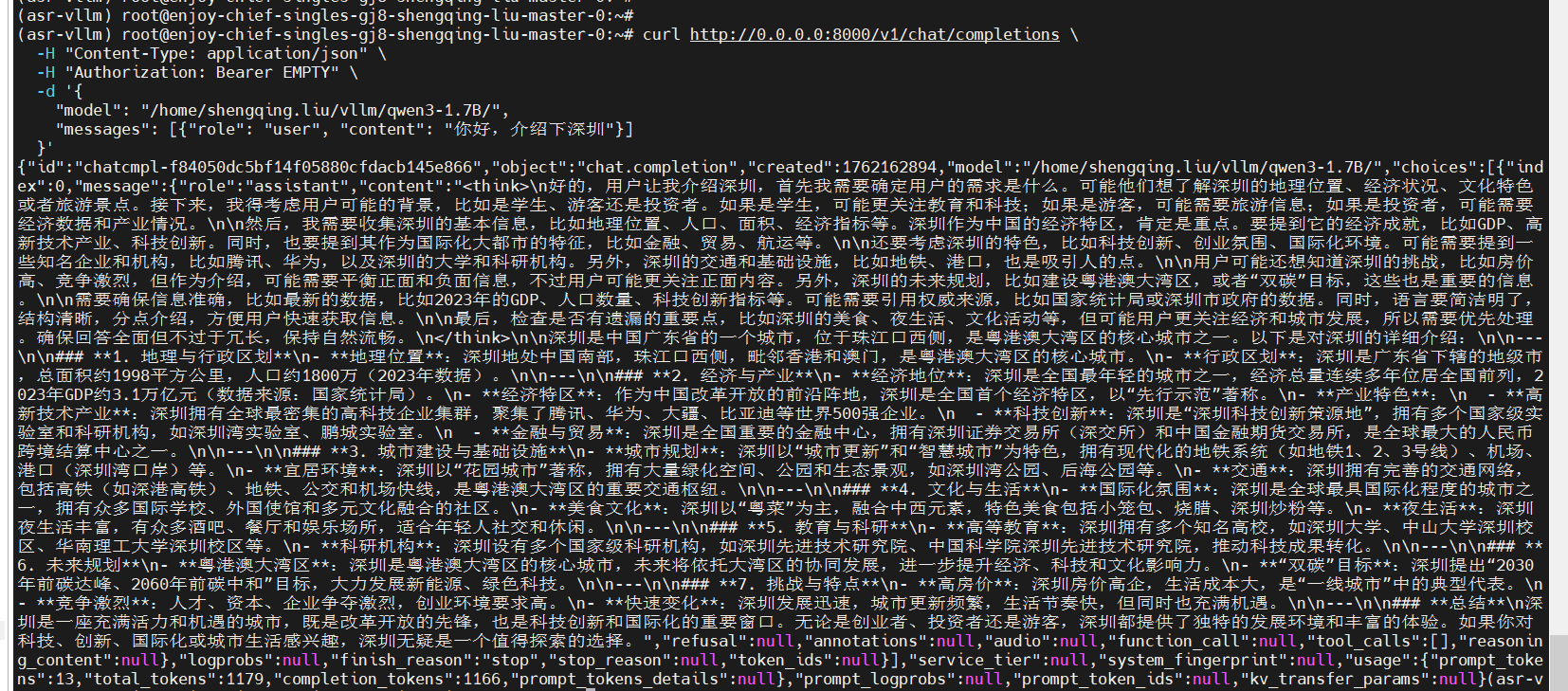
curl http://0.0.0.0:8000/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer EMPTY" \-d '{"model": "/home/shengqing.liu/vllm/qwen3-1.7B/","messages": [{"role": "user", "content": "你好,介绍下深圳"}]}'
运行结果如下:
客户端的python 访问:
from openai import OpenAI# 连接到本地 vLLM 服务
client = OpenAI(base_url="http://0.0.0.1:8000/v1", api_key="EMPTY")resp = client.chat.completions.create(model="/home/shengqing.liu/vllm/qwen3-1.7B/",messages=[{"role": "system", "content": "你是一个中文智能助手"},{"role": "user", "content": "请解释量子计算的原理"}],
)print(resp.choices[0].message.content)
使用英伟达的官方镜像启动服务:
docker run --gpus all -it --rm \-v /data/models:/models \-p 8000:8000 \nvcr.io/nvidia/pytorch:24.04-py3 \bash -c "pip install vllm==0.11.0 && \python -m vllm.entrypoints.openai.api_server \--model /models/Qwen2.5-7B-Instruct --host 0.0.0.0 --port 8000"