爬虫数据清洗可视化链家房源
网站:长沙二手房房源_长沙二手房出售|买卖|交易信息-长沙链家
温馨提示: 本案例仅供学习交流使用
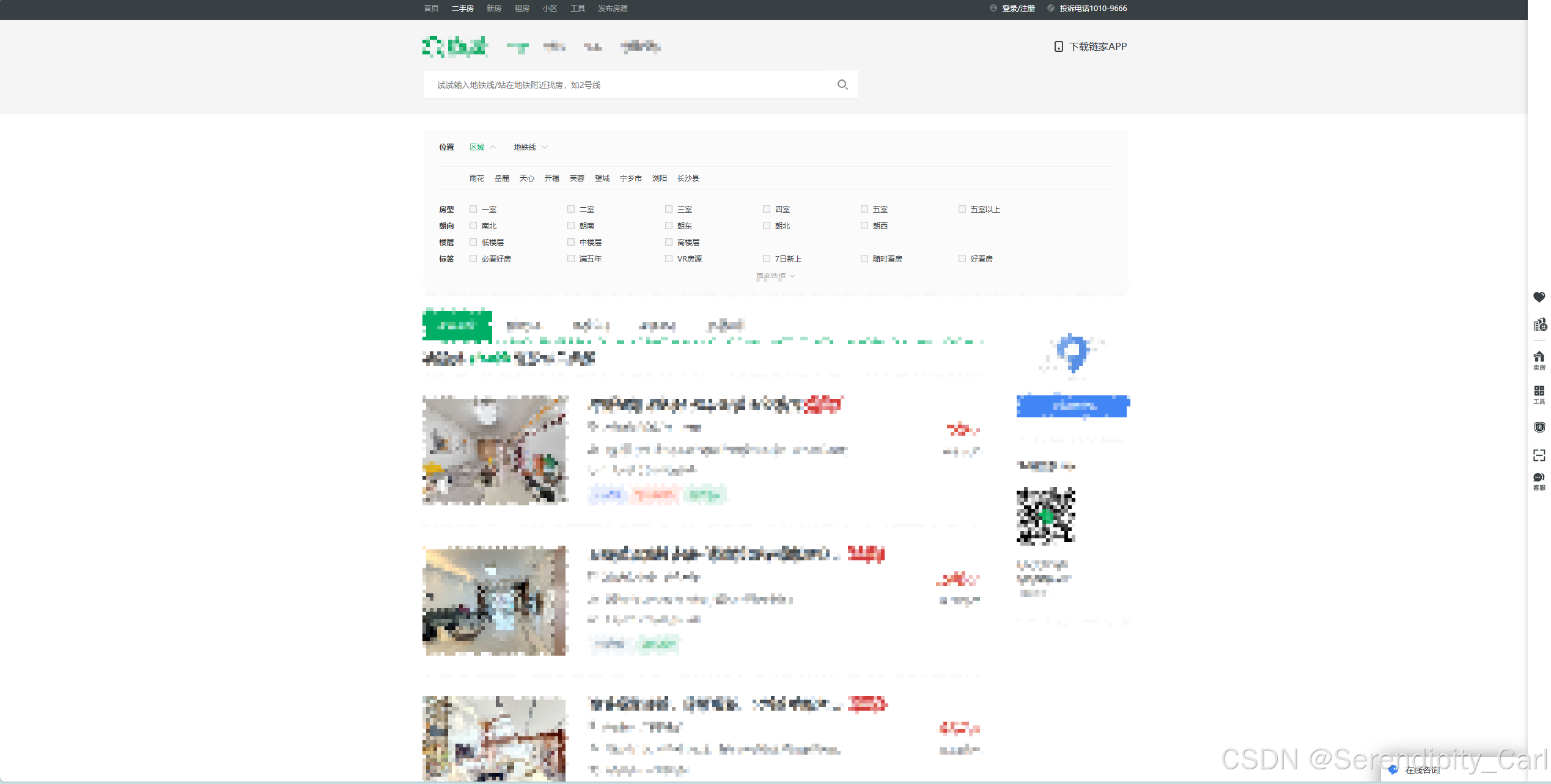
首先 明确爬取的数据
- 标题
- 地址
- 房屋信息
- 关注人数 发布时间
- 价格 每平方米的价格
步骤:
- 简单分析界面 对前端的html结构有个了解
- 构建请求 模拟浏览器向服务器发送请求
- 解析数据 提取我们所需要的数据
- 保存数据 对数据进行持久化保存 如csv excel mysql
一.发送请求
右键查看源代码 查看是否为静态数据
Ctrl+F 打开搜索框 查看是否包含我们爬取的数据
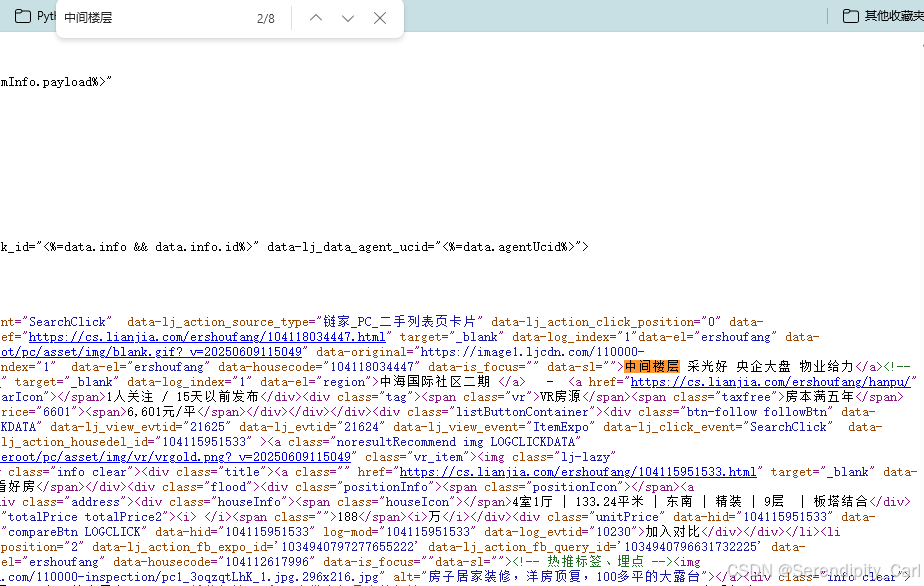
发现可以搜到我们想要爬取的数据 因此为静态数据
接着我们构建请求体 复制浏览器中的Url
# 导包
import requests
import parsel
import pprint# 网址
url = 'https://cs.lianjia.com/ershoufang/'# 请求体
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','referer':'https://cs.lianjia.com/','cookie':'select_city=430100; lianjia_uuid=40cfad10-6028-4fa5-98e7-f64cc30f5e1f; Hm_lvt_46bf127ac9b856df503ec2dbf942b67e=1761456276; HMACCOUNT=2EDE6B4FF192C403; _jzqc=1; _jzqckmp=1; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2219a1ef9c78e6c6-07959c473245b58-4c657b58-3686400-19a1ef9c78fc3f%22%2C%22%24device_id%22%3A%2219a1ef9c78e6c6-07959c473245b58-4c657b58-3686400-19a1ef9c78fc3f%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _qzjc=1; _ga=GA1.2.232101018.1761456287; _gid=GA1.2.1226634737.1761456287; crosSdkDT2019DeviceId=-rpv6dr--190h9s-lgasbfwtoyze63k-gir0i2fuf; _jzqa=1.172784459768417000.1761456277.1761456277.1761459496.2; Hm_lpvt_46bf127ac9b856df503ec2dbf942b67e=1761459550; _qzja=1.2127940051.1761456277714.1761456277714.1761459496327.1761459544138.1761459550314.0.0.0.6.2; _qzjto=6.2.0; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZTE4YzBjN2Q2NWEwMTM1MzU5ODMzYjM4OTlmODM5NGRiZWRiOTUyODBlNmM2Zjg3MjU2YzNkMTQ4MjJmOWFlZTQ4M2I1MzljODVmMGJjYzYyZTM5NmUwYzc1YzQ4OTExYTAwNjFjZjAyZmM1YzgyODcwMjkyNzBkOWM1Zjg0MGNlM2NjZGIxOTU1NjBiY2RhNzhkMDBlZjE2OGZiNTg4NmJkMzExZTBmZTE0NmJmMDY4MjRlZGJhMjJmYzlkZDBmMzU2OTkzYjliZTE5Y2IwZTJkZGU1MjBmYzY1NGFiNTVlZThjZmViYWIyNTZkM2U0NGNjMDAyNTMxYWFlOTAxOFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJhNWQ4Zjk5YVwifSIsInIiOiJodHRwczovL2NzLmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvIiwib3MiOiJ3ZWIiLCJ2IjoiMC4xIn0=; _ga_4JBJY7Y7MX=GS2.2.s1761459508$o2$g1$t1761459562$j6$l0$h0; lianjia_ssid=53f9dd1f-4942-34e4-1128-73bc6a6017cd'
}# 返回的响应
resp = requests.get(url, headers=headers)打开页面 F12 or 右击检查 打开开发者工具
点击左上角的这个像鼠标的 然后去页面中去选要爬取的数据 查看分析节点

通过分析可得 每个房屋的所有信息都在class属性为sellListContent Ul标签中的li标签中
OK 简单地分析了结构之后 我们开始写代码
首先复制 浏览器中的地址 接着构建请求体 UserAgent(包含浏览器的基本信息 载荷 浏览器类型等) Referen(防盗链 简单来说就是你目前这个页面是从哪里跳转过来的) Cookie(包含了用户的一些登陆基本信息 ) 在浏览器复制就可以了
二. 解析数据 提取数据
数据解析模块是用的parsel 需要pip 安装 pip install parsel
这里我们选择使用css取提取数据 也可以使用 re xpath 看大家的习惯
# 将浏览器返回的文本 转换成Selector对象
select = parsel.Selector(resp.text)lis = select.css('.sellListContent li')
# 找到包含所有房屋信息的跟标签 循环遍历接着继续提取爬取的数据
点击开发者工具左上角的箭头 选择爬取的数据 分析页面结构
标题:
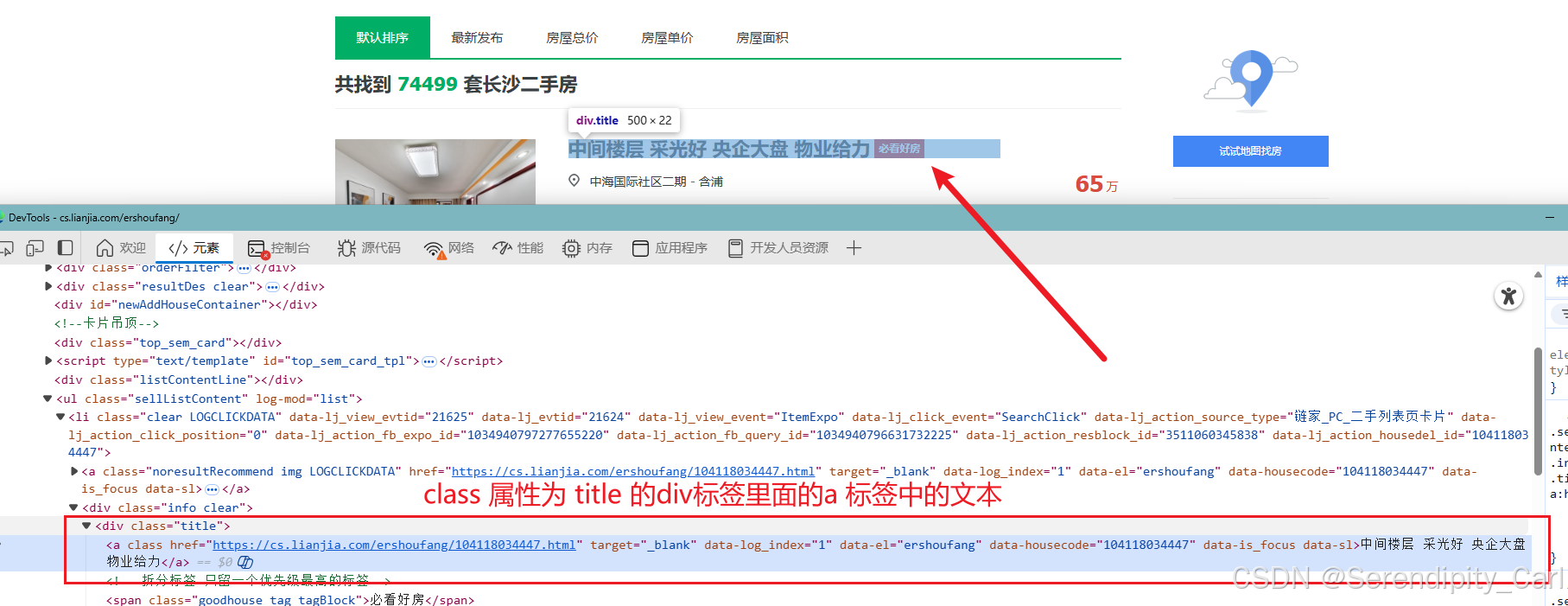
其它也类似 这里就不多演示了
温馨提示: 如果标签中有多个 class属性 中间用.隔开 如提取价格的时候
如果要提取表中的属性 使用attr(attract的缩写 提取对应的属性) 如提取图片的时候
for li in lis:title = li.css('.title a::text').get()address = li.css('.positionInfo a::text').get()house_info = li.css('.houseInfo ::text').get()follow = li.css('.followInfo ::text').get()price = li.css('.totalPrice.totalPrice2 span::text').get()square_price = li.css('.unitPrice span::text').get()img = li.css('.lj-lazy ::attr(src)').get()以上的数据提取完毕 我们可以在控制台打印看看 是否满足我们想要的格式效果

可以看到house_info中的信息有点冗余了 我们给它做个细分
以 ' | '分割 会返回一个列表 通过列表取值 得到详细的划分 然后重新赋值字段名
这里有个问题 就是 存在获取到的数据内容为None的情况 此时需要做个判断 如果获取到的内容是空的就跳过本次循环

取好变量名
注意到 不是每个房屋信息里面都有这个 年份的信息 这个时候可以使用三元运算符 做个判断
如果年在这个信息里面 就取 反之 返回 None
for li in lis:title = li.css('.title a::text').get()address = li.css('.positionInfo a::text').get()if li.css('.houseInfo ::text'):house_info = li.css('.houseInfo ::text').get().split('|')rooms = house_info[0]area = house_info[1]orient = house_info[2]house_type = house_info[3]floor = house_info[4]year = house_info[-2] if '年' in house_info[-2] else 'None'room_architecture = house_info[-1]else:continuefollow = li.css('.followInfo ::text').get().split('/')[0]issue_time = li.css('.followInfo ::text').get().split('/')[-1]price = li.css('.totalPrice.totalPrice2 span::text').get()square_price = li.css('.unitPrice span::text').get()img = li.css('.lj-lazy ::attr(data-original)').get()接着我们需要保存数据
-
保存为Excel文件
首先存储到字典中 之后定义一个空列表 将字典添加到列表中 Like this
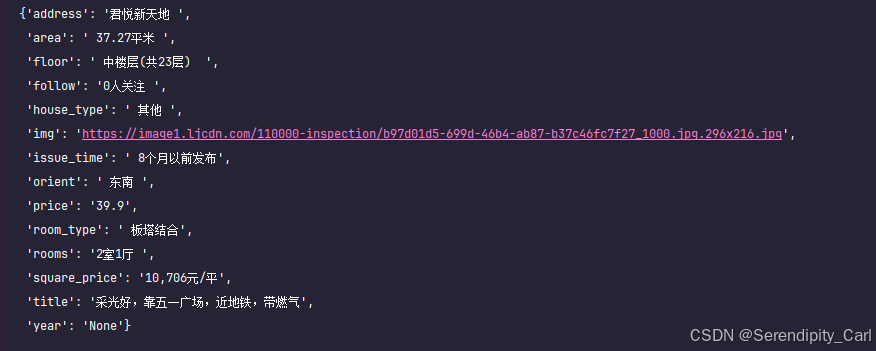
此时我们可以使用 美化打印模块 输出打印看看我们所需要的数据
dit = {'title': title,'address': address,'rooms': rooms,'area': area,'orient': orient,'house_type': house_type,'floor': floor,'year': year,'room_type': room_architecture,'follow': follow,'issue_time': issue_time,'price': price,'square_price': square_price,'img': img,}pprint.pprint(dit)这样就清新很多
多页爬取的话 在Url中加个参数就可以了 pg=页码
爬虫部分的源代码 供大家学习参考
import requests
import parsel
import pprint
import pandas as pdall_data = []
for i in range(1,11):url = f'https://cs.lianjia.com/ershoufang/pg{i}/'# 请求体headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/141.0.0.0 Safari/537.36 Edg/141.0.0.0','referer':'https://cs.lianjia.com/','cookie':'select_city=430100; lianjia_uuid=40cfad10-6028-4fa5-98e7-f64cc30f5e1f; Hm_lvt_46bf127ac9b856df503ec2dbf942b67e=1761456276; HMACCOUNT=2EDE6B4FF192C403; _jzqc=1; _jzqckmp=1; sajssdk_2015_cross_new_user=1; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2219a1ef9c78e6c6-07959c473245b58-4c657b58-3686400-19a1ef9c78fc3f%22%2C%22%24device_id%22%3A%2219a1ef9c78e6c6-07959c473245b58-4c657b58-3686400-19a1ef9c78fc3f%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24latest_referrer_host%22%3A%22%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%7D%7D; _qzjc=1; _ga=GA1.2.232101018.1761456287; _gid=GA1.2.1226634737.1761456287; crosSdkDT2019DeviceId=-rpv6dr--190h9s-lgasbfwtoyze63k-gir0i2fuf; _jzqa=1.172784459768417000.1761456277.1761456277.1761459496.2; Hm_lpvt_46bf127ac9b856df503ec2dbf942b67e=1761459550; _qzja=1.2127940051.1761456277714.1761456277714.1761459496327.1761459544138.1761459550314.0.0.0.6.2; _qzjto=6.2.0; srcid=eyJ0Ijoie1wiZGF0YVwiOlwiZTE4YzBjN2Q2NWEwMTM1MzU5ODMzYjM4OTlmODM5NGRiZWRiOTUyODBlNmM2Zjg3MjU2YzNkMTQ4MjJmOWFlZTQ4M2I1MzljODVmMGJjYzYyZTM5NmUwYzc1YzQ4OTExYTAwNjFjZjAyZmM1YzgyODcwMjkyNzBkOWM1Zjg0MGNlM2NjZGIxOTU1NjBiY2RhNzhkMDBlZjE2OGZiNTg4NmJkMzExZTBmZTE0NmJmMDY4MjRlZGJhMjJmYzlkZDBmMzU2OTkzYjliZTE5Y2IwZTJkZGU1MjBmYzY1NGFiNTVlZThjZmViYWIyNTZkM2U0NGNjMDAyNTMxYWFlOTAxOFwiLFwia2V5X2lkXCI6XCIxXCIsXCJzaWduXCI6XCJhNWQ4Zjk5YVwifSIsInIiOiJodHRwczovL2NzLmxpYW5qaWEuY29tL2Vyc2hvdWZhbmcvIiwib3MiOiJ3ZWIiLCJ2IjoiMC4xIn0=; _ga_4JBJY7Y7MX=GS2.2.s1761459508$o2$g1$t1761459562$j6$l0$h0; lianjia_ssid=53f9dd1f-4942-34e4-1128-73bc6a6017cd'}resp = requests.get(url, headers=headers)select = parsel.Selector(resp.text)lis = select.css('.sellListContent li')for li in lis:title = li.css('.title a::text').get()address = li.css('.positionInfo a::text').get()if li.css('.houseInfo ::text'):house_info = li.css('.houseInfo ::text').get().split('|')rooms = house_info[0]area = house_info[1]orient = house_info[2]house_type = house_info[3]floor = house_info[4]year = house_info[-2] if '年' in house_info[-2] else 'None'room_architecture = house_info[-1]else:continuefollow = li.css('.followInfo ::text').get().split('/')[0]issue_time = li.css('.followInfo ::text').get().split('/')[-1]price = li.css('.totalPrice.totalPrice2 span::text').get()square_price = li.css('.unitPrice span::text').get()img = li.css('.lj-lazy ::attr(data-original)').get()dit = {'title': title,'address': address,'rooms': rooms,'area': area,'orient': orient,'house_type': house_type,'floor': floor,'year': year,'room_type': room_architecture,'follow': follow,'issue_time': issue_time,'price': price,'square_price': square_price,'img': img,}all_data.append(dit)pd.DataFrame(all_data).to_excel('lianjia.xlsx', index=False)
以下是爬取十页的数据
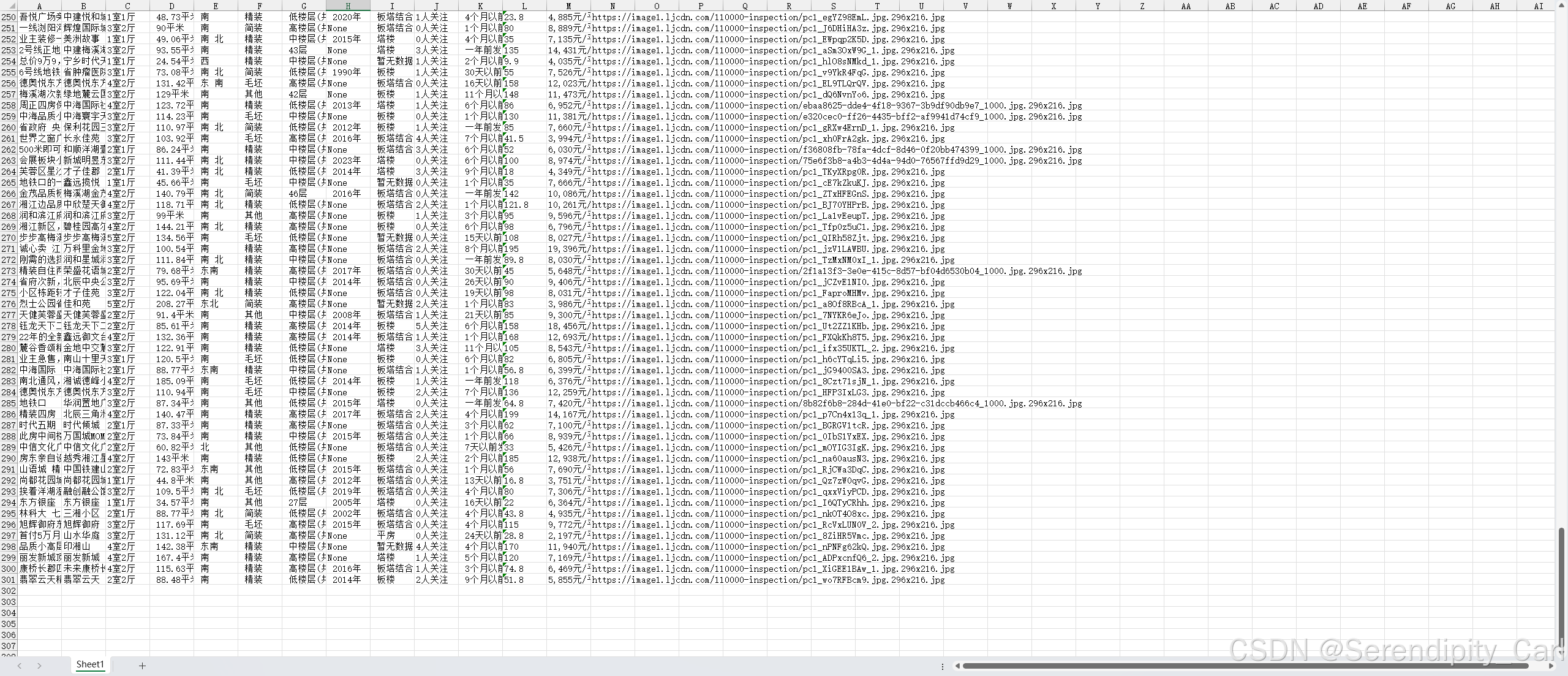
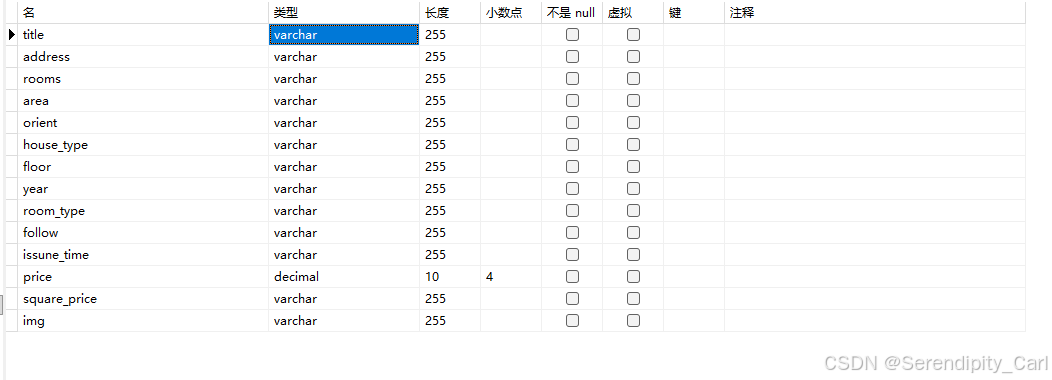
保存到数据库
前提需要建库建表 定义字段 (navicat)
# 导包
import pymysql# 连接信息
connect = pymysql.connect(host='localhost',user='root',password='112233',database='spider',
)# 拿到游标
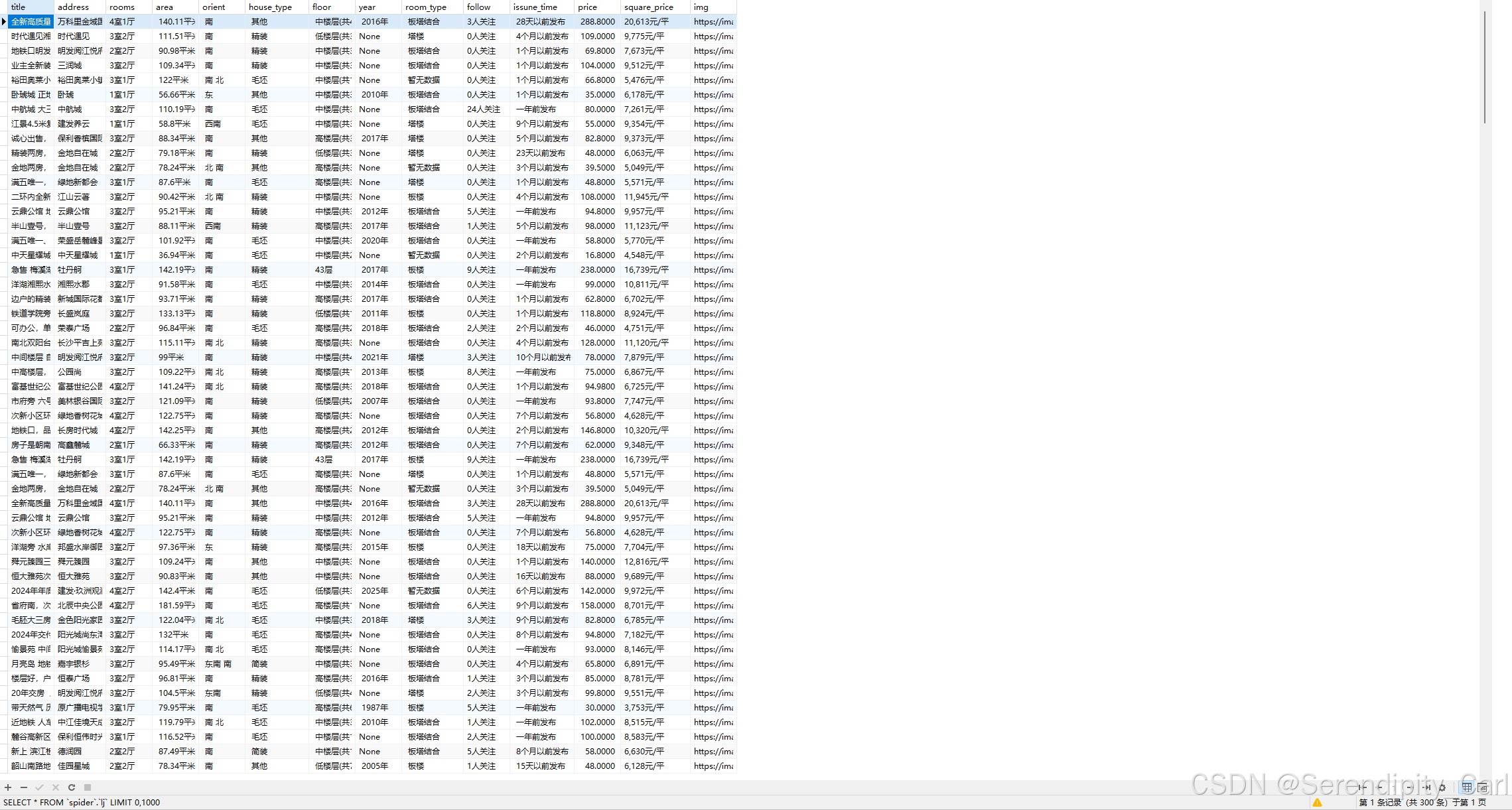
cursor = connect.cursor()# 准备sql语句sql = 'insert into lj values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'cursor.executemany(sql, [(title, address, rooms, area, orient, house_type, floor, year, room_architecture,follow, issue_time, price, square_price, img)])# 提交事务connect.commit()以下是保存成功的数据
保存为Csv文件
import csvcsv_writer = csv.DictWriter(open('lianjia.csv', 'w', encoding='utf-8-sig', newline=''), fieldnames=['title','address','rooms','area','orient','house_type','floor','year','room_type','follow','issue_time','price','square_price','img'
])
csv_writer.writeheader()dit = {'title': title,'address': address,'rooms': rooms,'area': area,'orient': orient,'house_type': house_type,'floor': floor,'year': year,'room_type': room_architecture,'follow': follow,'issue_time': issue_time,'price': price,'square_price': square_price,'img': img,}csv_writer.writerow(dit)二.数据清洗

第一题:
# 导包
import numpy as np
import pandas as pd# 读取数据
df = pd.read_excel('lianjia.xlsx')# 第一题 可以采用替换 正则表达式提取
# method_1
# df['area'] = df['area'].replace('平米', '', regex=True)
# method_2
df['area'] = df['area'].str.extract(r'(\d+.\d+)', expand=False)
df['area'] = pd.to_numeric(df['area'], errors='ignore').round(2)df['follow'] = df['follow'].str.extract(r'(\d+)')
df['follow'] = pd.to_numeric(df['follow'], errors='coerce').round(2)
第二题:
# 获取现在的日期
current_time = datetime.datetime.now().date()# 写个函数
def ts_time(str):# 如果字符串中存在个月 则将月份提取出来 转换成int类型 然后用现在的日期减去天数# 其它同理if '个月' in str:month = int(str.split('个月')[0])return current_time - datetime.timedelta(days=month * 30)if '天' in str:day = int(str.split('天')[0])return current_time - datetime.timedelta(days=day)# 应为数据中有 “一年前发布" 的信息 因此得转换成数字1 无法使用map 暂时只能这样处理了# 如果有好的方法 可以打在评论区if '年' in str:year = 1 if '一' in str else str.split('年')[0]return current_time - datetime.timedelta(days=year * 365)df['issue_time'] = df['issue_time'].apply(ts_time)第三题:
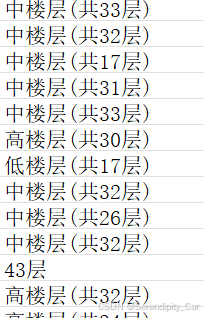
目标格式 中|33
考虑到数据存在这两种格式 因此 我们可以通过特殊特征 分别处理
会发现括号是区别这两者的最好方式
如果字符串中存在( 则以楼字分割字符串 此时会返回一个列表 对列表取值就可以得到 楼层的高度
接着以 "|"拼接隔开 接着以共字分割 取后半部分 此时返回的是33层)再以层分割取前面就可以得到数字了
里面用不了正则提取 不然会方便很多
只含有楼层数量的就不解释了
def ts_floor(str):if ')' in str:return str.split('楼')[0] + '|' + str.split('共')[-1].split('层')[0]else:return str.split('层')[0]df['floor'] = df['floor'].apply(ts_floor)接着 floor这列的数据就变成了 中|33 这样格式的 我们需要将此以"|"分开 赋值到两个变量中
# expand = True 将结果变成DataFrame的形式
# 数据中存在| 的 就分割成两列
# 不存在的则将新的列名 赋值成原来的
def ts_2_floor(str):if '|' in str:df[['current_total', 'total_floor']] = df['floor'].str.split('|', expand=True)return df[['current_total', 'total_floor']]else:df['total_floor'] = df['floor']return df['total_floor']df['floor'] = df['floor'].apply(ts_2_floor)
# 然后删除之前的floor列名
df.drop(columns=['floor'], inplace=True)第四题:
# 这里我们不适合像题目那样做 直接将年份为空的数据删除就好了df.dropna(subset='year', inplace=True)第五题:
# 异常值的处理 iqr
lo_iqr = df['price'].quantile(0.25)
up_iqr = df['price'].quantile(0.75)
iqr = up_iqr - lo_iqr
lower_iqr = lo_iqr - 1.5 * iqr
upper_iqr = up_iqr - 1.5 * iqr# 将超出最小值的数值 用最小的临界值填充
df['price'] = np.where(df['price'] < lower_iqr,lower_iqr,df['price']
)
# 同理
df['price'] = np.where(df['price'] > upper_iqr,upper_iqr,df['price']
)第六题:
这里注意空格 原数据中字体前后有空格 可以用以下的方法查看
print(df['orient'].unique())或者将原本的空格通过字符串方法去除 然后在映射
orientation_map = {' 南 ': 'S', ' 北 ': 'N', ' 东 ': 'E', ' 西 ': 'W',' 东南 南 ': 'ES S', '东北': 'NE', ' 西南 ': 'SW', '西北': 'NW',' 南 北 ': 'S N', ' 北 南 ': 'N S', ' 东南 ': 'E S'
}
df['orient'] = df['orient'].map(orientation_map)最后保存数据 将清洗完的数据保存到新的文件
df.to_excel('cleaned_lianjia.xlsx', index=False)
三.可视化
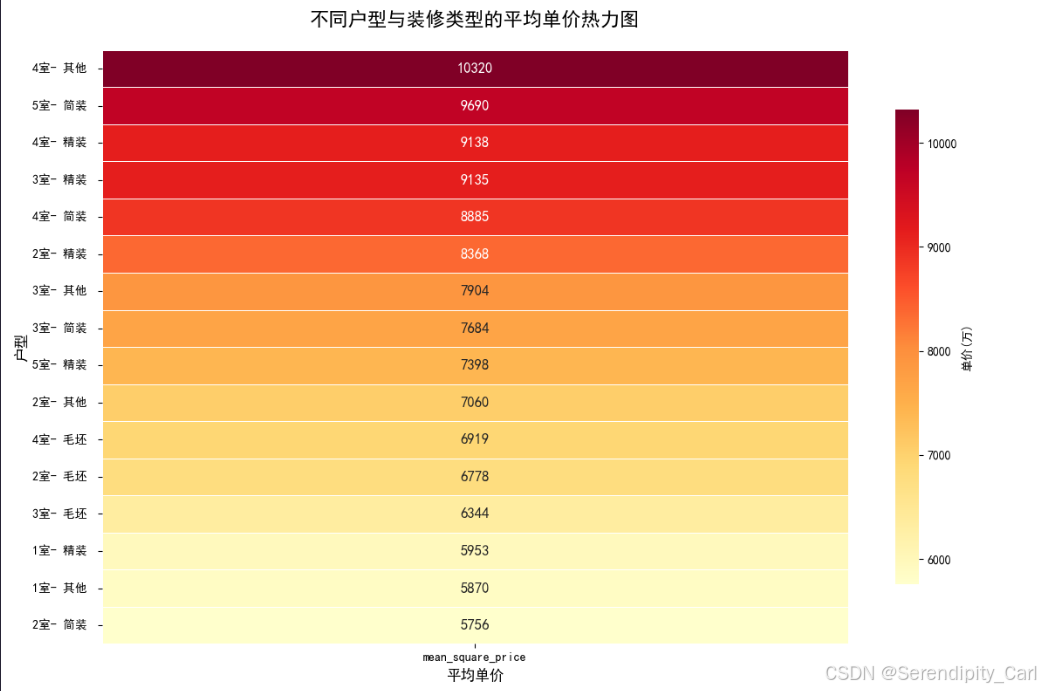
探索不同户型(rooms)与装修类型(house_type)组合的平均单价
分析思路:
1. 提取户型中的房间数(如"3室1厅" → 3室)
2. 按"房间数"和"装修类型"分组计算平均单价
3. 用热力图展示不同组合的价格差异
# 导包 起别名
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import rcParams
import seaborn as sns# 设置显示的字体为自带的黑体
rcParams['font.family'] = 'SimHei'# 读取excel数据
df = pd.read_excel('cleaned_lianjia.xlsx')# 处理数据 使用字符串中的提取匹配的数据
df['room'] = df['rooms'].str.extract(r'(\d+.*)\d+')# 将多余的字符去掉 使用字符串中的替换方法
df['square_price'] = df['square_price'].str.replace('元/平', '')
df['square_price'] = df['square_price'].str.replace(',', '').astype(int)# 分组聚合 按照房间和类型分组 计算平均的单价 然后按照高到低重新排列
room_analysis = df.groupby(['room', 'house_type']).agg({'square_price': 'mean',
}).rename(columns={'square_price': 'mean_square_price'}).sort_values(by=['mean_square_price'], ascending=False)# 创建画布
plt.figure(figsize=(12, 8))
# 里面的参数上个文章讲了
sns.heatmap(room_analysis[['mean_square_price']], annot=True, annot_kws={'fontsize': 12, 'weight': 'bold'}, fmt='.0f',cmap='YlOrRd', linewidths=0.5, cbar_kws={'label': '单价(万)', 'shrink': 0.8})# 设置标题 字体大小 粗细 间距 x y 标签
plt.title('不同户型与装修类型的平均单价热力图', fontsize=16, fontweight='bold', pad=20)
plt.xlabel('平均单价', fontsize=12)
plt.ylabel('户型', fontsize=12)
# 自动调整布局
plt.tight_layout()# 展示图表
plt.show()
本次的案例分析就到此结束啦 谢谢大家的观看 你的点赞和关注是我更新的最大动力
如果感兴趣的话可以看看我之前的博客