红外与可见光图像融合的跨模态Transformer
Cross-Modal Transformers for Infrared and Visible Image Fusion
红外与可见光图像融合的跨模态Transformer
作者:Seonghyun Park , An Gia Vien , and Chul Lee
发表期刊:IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY
论文地址:https://ieeexplore.ieee.org/document/10163247
摘要 — 图像融合技术旨在通过将具有互补信息的多模态图像进行合并,生成更具信息量的图像。尽管基于学习的方法在融合性能方面取得了显著提升,大多数现有的融合算法仍基于卷积神经网络(CNN),通过堆叠深层网络来获得较大的感受野进行特征提取。然而,源图像中的重要细节和上下文信息可能会在经过一系列卷积层后丢失。
在本文中,我们提出了一种基于跨模态Transformer的融合(CMTFusion)算法,用于红外与可见光图像融合。该方法能够准确地从源图像中提取互补信息,从而捕捉全局交互。具体而言,我们首先提取红外与可见光图像的多尺度特征图;然后,我们构建跨模态Transformer(CMT),通过同时去除空间域和通道域中的冗余信息来保留源图像中的互补信息。为此,我们设计了一种带门控机制的瓶颈结构,将跨域交互集成进去,以考虑源图像的特性。最后,我们利用融合模块在精炼后的特征图中结合空间-通道信息,生成融合结果。
在多个数据集上的实验结果表明,所提出的算法在定量和定性性能上均优于现有的红外与可见光图像融合算法。此外,我们还证明,该算法可用于提升计算机视觉任务的性能,例如目标检测和单目深度估计。
关键词 — 图像融合、Transformer、自注意力机制、红外图像、可见光图像。
一、引言
图像融合是一种技术,用于将由不同传感器或光学设置获取的多幅图像进行组合,从而通过利用互补信息生成更具信息量的图像 [1]。由于其实际应用价值 [1], [2],图像融合已被广泛应用于各种工业领域,例如遥感、医学诊断、安全以及监控系统。
在众多不同模态组合中,红外与可见光图像融合引起了广泛关注,因为它能够在不同波长下提供互补且稳健的场景信息,这些信息还可用于提升计算机视觉任务的性能 [1], [3]。可见光图像(简称可见光图)可以捕捉场景纹理细节,但其质量容易受到天气与光照条件的影响 [4]。相比之下,红外图像捕捉的是物体发出的热辐射,从而克服环境限制,但在纹理与背景细节的表现上较弱。因此,人们已经开发了多种红外与可见光图像融合算法,以结合二者的互补信息 [1], [5]。
红外与可见光图像融合的主要挑战在于:如何有效提取源图像的互补信息,并在融合过程中忠实地加以利用。早期的融合方法采用了数学理论,例如多尺度变换 [6]–[10]、低秩表示 [11], [12]、稀疏表示 [13]–[15] 以及混合模型 [16], [17],以提取源图像的互补信息。这些算法随后根据所提取的特征,使用特定的融合规则生成融合图像 [18]。然而,手工设计的特征可能难以有效保留互补信息,因为它限制了红外与可见光特征的表示能力与刻画力,从而降低融合性能 [19]。
近年来,随着深度学习方法在各种图像处理与计算机视觉任务中的成功,许多红外与可见光图像融合算法开始基于卷积神经网络(CNN)[20]–[34] 或生成对抗网络(GAN)[35]–[41] 进行设计。基于CNN的融合算法通过学习每个源图像的语义特征,展现了强大的特征表示能力,并取得了显著的性能提升。然而,由于深层卷积网络在堆叠以获得大感受野的过程中,源图像的低层信息(例如边缘与线条)可能会丢失 [42]。基于GAN的融合算法则尝试通过对抗学习保留红外与可见光图像的像素值分布,从而生成融合图像。然而,它们无法捕获源图像之间的全局上下文,而且网络容易不稳定,训练困难 [43], [44]。
传统的深度学习融合算法 [20]–[41] 只能够在固定大小窗口内捕获源图像的局部信息,因此在捕捉源图像像素之间的全局交互方面能力有限。受到Transformer在长程依赖建模能力的启发 [45],一些基于Transformer的融合算法 [43], [46]–[51] 已经被开发出来,以利用自注意力机制捕获全局交互。然而,尽管这些方法在融合任务中取得了优异表现,它们通常需要大量计算资源来实现全局交互的处理,因此在高分辨率图像的处理上不够实用。
在本文中,我们提出了一种新的基于跨模态Transformer的红外与可见光图像融合(CMTFusion)算法,以解决传统学习型融合算法的局限性,并通过捕捉全局交互更好地保留源图像中的互补信息。CMTFusion 首先以粗到细的方式提取红外与可见光图像的多尺度特征;随后我们在每一层设计跨模态Transformer(CMT),分别在空间域与通道域去除源图像的冗余信息,以识别它们的互补区域。每个CMT由两个Transformer组成:空间Transformer,用于捕捉源图像在空间域的全局交互;通道Transformer,用于捕捉源图像在通道域的全局上下文。此外,我们设计了带门控机制的瓶颈结构,通过交换源图像的跨模态信息实现跨域交互,从而更好地提取互补信息。最后,一个融合模块将这些精炼的特征进行聚合,生成最终的融合结果。
在多个数据集上的实验结果表明,CMTFusion 在融合性能上优于现有的先进算法 [12], [21]–[29], [38]–[40], [48], [52]。此外,我们证明该算法可以提升计算机视觉任务的表现,例如目标检测与单目深度估计。
综上,我们的贡献如下:
- 我们提出了一种基于跨模态Transformer的红外与可见光图像融合算法,可通过捕捉全局交互有效保留源图像的互补信息;
- 我们开发了新的Transformer模块(CMT),可在空间域与通道域去除源图像的冗余信息,并捕捉其全局交互与上下文;
- 我们设计了带门控机制的瓶颈结构,通过跨域交互交换跨模态信息,以更好地提取互补信息;
- 我们通过实验证明,CMTFusion算法在多种数据集上的表现显著优于现有融合算法,并能提升计算机视觉任务性能。
本文其余部分的结构如下:第二部分回顾相关工作;第三部分介绍所提出的CMTFusion算法;第四部分讨论实验结果;第五部分给出结论。
二、相关工作
A. 基于模型的融合
基于模型的融合方法将图像融合建模为数学问题,通过从每个源图像中提取互补特征,并使用特定的融合策略将这些特征融合,生成融合后的图像。
例如,基于多尺度变换的算法 [6]–[10] 将每个源图像分解为多尺度表示,然后通过多尺度变换的逆变换生成融合图像。基于低秩的算法 [11], [12] 尝试利用低秩表示将源图像分解为基础层与细节层。基于稀疏表示的算法 [13]–[15] 通过学习过完备词典来提升融合图像的有效表达能力。混合模型 [16], [17] 则组合多种基于模型的算法以发挥各自优势,从而进一步提升融合性能。
然而,基于模型的算法往往依赖人工设计的融合策略和数值优化,这会消耗大量的计算资源。
B. 基于学习的融合
随着深度学习在图像处理与计算机视觉领域的成功,基于学习的红外与可见光图像融合算法开始迅速发展,这些方法大体可以分为 基于CNN 和 基于GAN 两类。
基于CNN的融合算法 [20]–[34] 通过卷积神经网络提取特征图,然后融合这些特征生成融合图像。比如在 [25]–[31] 中,红外与可见光特征通过单一网络进行提取与融合,以端到端的方式去除两个源图像的相关性。然而,由于不同模态使用同一个网络模块,难以充分利用源图像的互补信息,从而影响融合结果质量。相比之下,在 [20]–[24], [32]–[34] 中,红外与可见光特征分别独立提取,再通过融合策略进行合并,从而更好地保留每个图像的固有特征。不过,随着网络中的卷积层数量增加,特征提取可能导致源图像细节的丢失,从而产生不均衡的融合图像。
为了解决红外与可见光图像融合中缺乏真实标签用于监督的问题,研究者提出了多种基于GAN的算法 [35]–[41],这些方法通过生成器与判别器之间的对抗学习,学习源图像的像素分布。例如 [35]–[37] 中,使用单一判别器来通过区分融合结果与源图像的差异生成融合图像。然而,单一判别器容易产生偏向某一个源图像的情况,从而导致不理想的伪影。为了解决这一问题,[38]–[41] 引入了双判别器,以保持源图像之间的平衡,并确保融合图像具有高对比度和丰富的纹理。
不过,基于GAN的算法训练困难,而且无法有效捕捉源图像中的长程依赖关系 [43], [44]。
C. 基于Transformer的融合
Transformer在各种计算机视觉任务中取得了巨大成功,主要得益于其在捕捉像素之间 全局交互 方面的卓越能力 [45], [53]。受其成功和优势的启发,研究者开发了多种基于Transformer的图像融合算法 [43], [46]–[51],并提升了融合性能。例如,在 [46], [47] 中,Transformer被用于利用全局注意力特征捕捉源图像之间的全局交互。然而,由于缺乏对邻近像素之间局部相关性的考虑,这些方法可能无法有效保留局部信息 [54]。
为了克服这一限制,[43], [48]–[51] 将CNN与Transformer结合使用,分别提取源图像的局部特征和全局特征,从而更好地保留互补信息。然而,通过自注意力机制捕捉全局交互会导致计算复杂度随图像分辨率呈平方增长。相比之下,本文提出的CMTFusion算法计算高效,同时能够捕捉源图像内部以及跨源图像的局部与全局交互。
近年来,跨模态交互(可实现不同模态信息的交换)已在基于Transformer的多模态计算机视觉任务中得以应用 [55]–[57]。然而,这些方法往往在每个模态中独立提取全局上下文信息 [55],可能无法有效保留关键的差异区域。此外,在 [55] 中,全局交互仅在空间域中通过自注意力实现,而特征图在不同域中包含的信息是不同的。在 [56] 和 [57] 中,卷积层被用于空间与通道注意力,这限制了感受野大小,从而导致有用的全局信息被丢弃。
本文提出的 跨模态Transformer(CMT) 能够同时在空间域和通道域中,通过交换源图像的跨模态信息实现跨域交互,从而有效保留互补特征。
III. 所提出的 CMTFusion 算法
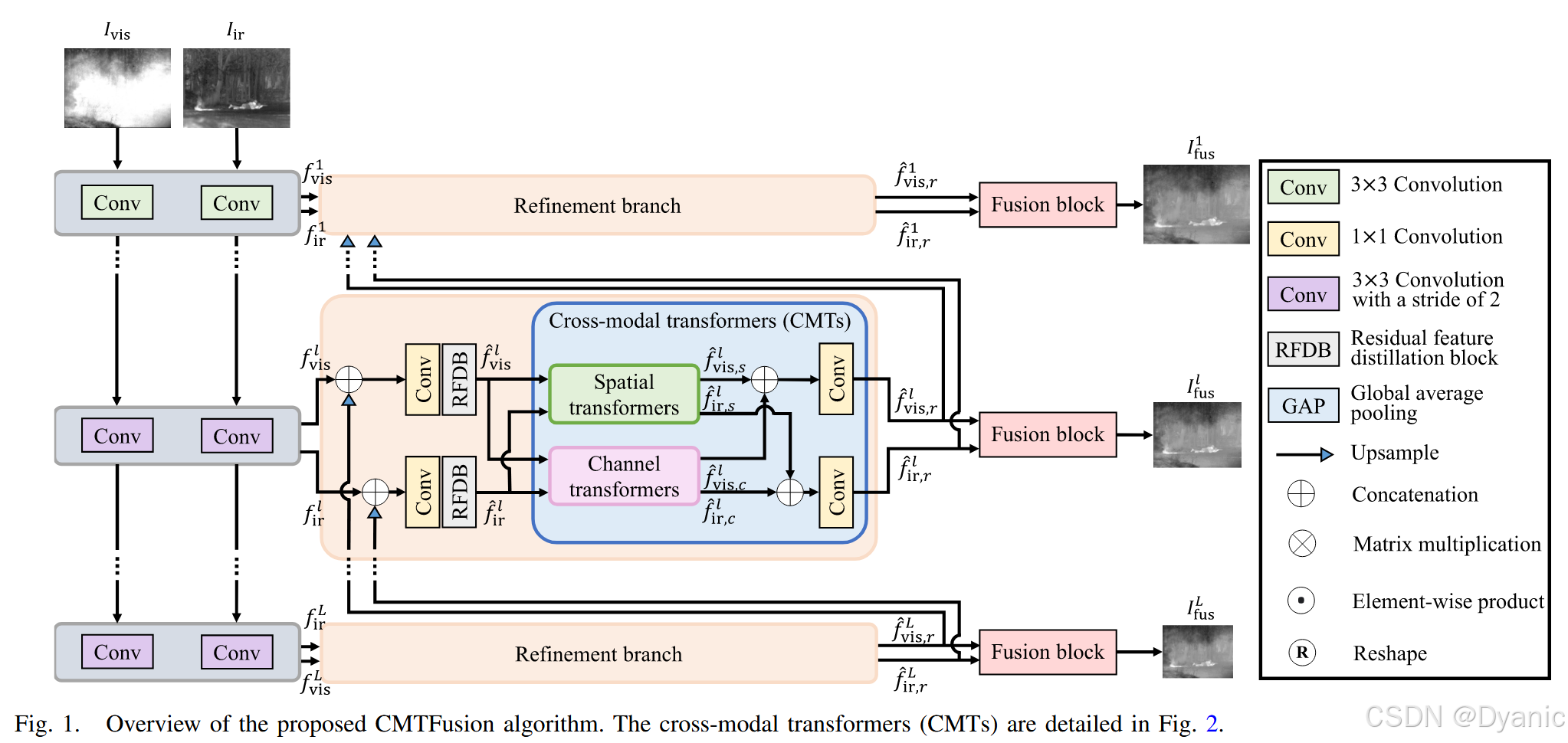
A. 整体架构
图 1 展示了所提出 CMTFusion 算法的概述,该算法以由粗到细的方式融合红外和可见光图像。给定一对红外和可见光图像 {Iir,Ivis}\{I_{ir}, I_{vis}\}{Iir,Ivis},所提出的算法首先通过一系列核大小为 3 × 3、步长为 2 的卷积层提取 L 层特征金字塔 {firl}l=1L\{f^l_{ir}\}^L_{l=1}{firl}l=1L 和{fvisl}l=1L\{f^l_{vis}\}^L_{l=1}{fvisl}l=1L。接下来,第lll 层的一对特征图输入到精炼分支,以捕获源图像的全局信息。具体而言,在精炼分支中,初始特征图firlf^l_{ir}firl和 fvislf^l_{vis}fvisl 首先与前一层(l+1)(l + 1)(l+1)的增强特征进行拼接,然后输入到残差特征蒸馏模块(RFDB)[58],该模块能够学习更具判别性的特征表示,从而获得特征图 f^irl\hat{f}^l_{ir}f^irl 和 f^visl\hat{f}^l_{vis}f^visl。随后,所提出的 CMT 在空间域和通道域均去除这些特征图 f^irl\hat{f}^l_{ir}f^irl 和 f^visl\hat{f}^l_{vis}f^visl 的冗余信息,使它们更加互补。最后,在每一层使用融合模块获得融合图像 IfuslI^l_{fus}Ifusl。接下来,我们将详细描述所提出算法的主要组件。
B. 跨模态 Transformer(CMTs)
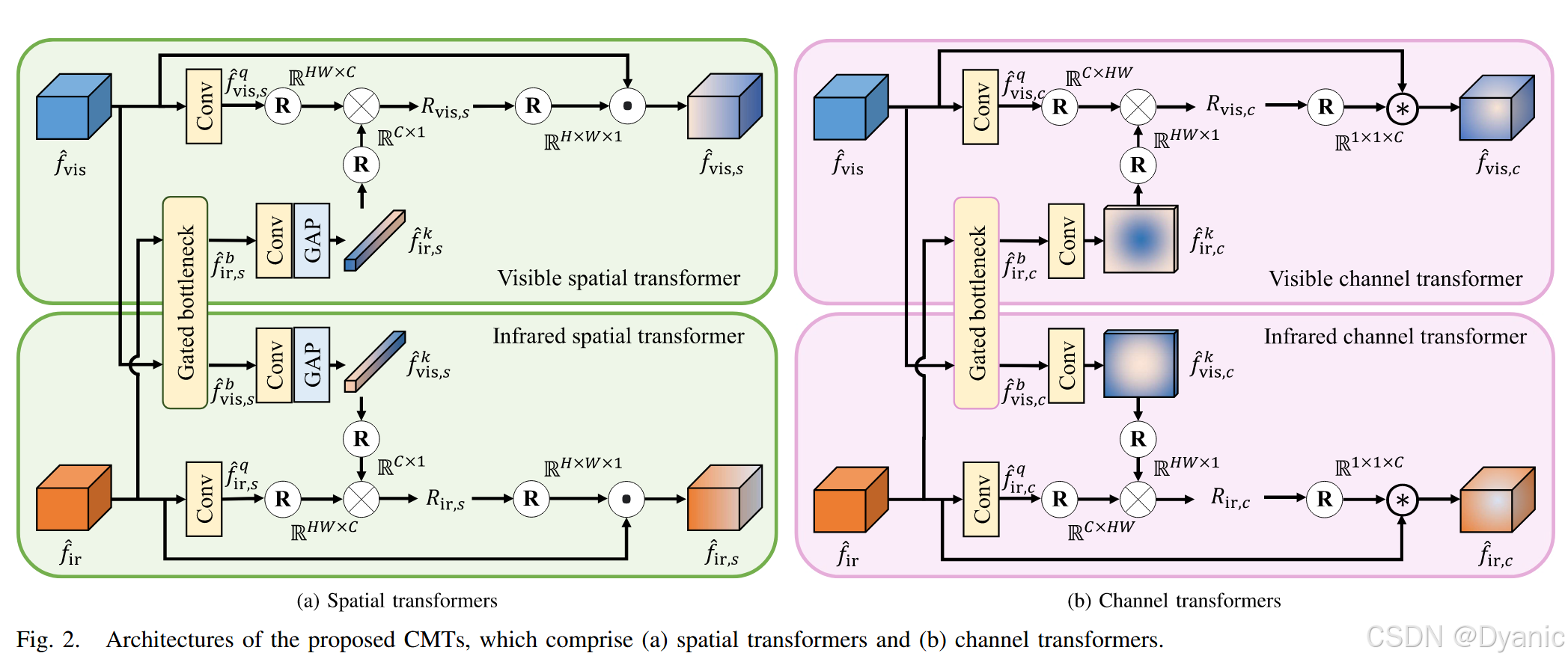
现有基于学习的图像融合算法 [20], [21], [22], [23] 需要堆叠多层深层网络才能获得大的感受野。然而,由于卷积操作限制了局部区域内的交互,它们无法在最终融合图像中捕获来自每个源图像的全局交互。需要注意的是,除了在每个源图像内部的全局交互外,红外和可见光图像之间的全局交互对于提取有意义的互补信息也至关重要 [48], [50]。基于这一观察,一些 Transformer 模块被开发出来,用于估计每个源图像中像素之间的相关性以进行图像融合 [48], [49]。然而,传统的 Transformer 模块可能无法保留跨通道的互补信息,因为它们仅考虑每个像素位置上的空间关系。为了解决这一问题,我们开发了 CMT,通过空间 Transformer 和通道 Transformer(分别如图 2(a) 和 2(b) 所示)在空间域和通道域捕获全局交互,这将在后续详细描述。此外,我们在 CMT 中估计不相关性图(Irrelevance Maps),以确定红外和可见光图像在每个像素位置上的差异程度,从而使网络能够更专注于提取两幅源图像之间有意义的互补信息。
1) 空间 Transformer
我们开发了空间 Transformer,以基于空间域中的不相关关系增强红外和可见光特征之间的互补性。图 2(a) 展示了所提出空间 Transformer 的架构,分别针对可见光图像和红外图像各一个。该对空间 Transformer 接收来自 RFDB 块的 {f^vis,f^ir}\{\hat{f}_{vis}, \hat{f}_{ir}\}{f^vis,f^ir} 输出特征,然后增强它们以获得精炼后的特征图 {f^vis,s,f^ir,s}\{\hat{f}_{vis,s}, \hat{f}_{ir,s}\}{f^vis,s,f^ir,s}。需要注意的是,我们为了简化符号省略了层索引 lll。两个空间 Transformer 的架构是相同的,因此这里只描述可见光空间 Transformer。
所提出的可见光空间 Transformer 首先使用单个 1 × 1 卷积层构造查询特征 f^vis,sq\hat{f}^q_{vis,s}f^vis,sq。需要注意的是,尽管红外与可见光特征图模态不同,它们仍可能包含场景的冗余信息。因此,我们开发了一个门控瓶颈(将在后续部分详细描述),通过跨域交互在 f^vis\hat{f}_{vis}f^vis 和 f^ir\hat{f}_{ir}f^ir 之间交换冗余信息,以更好地从每个特征图中提取互补信息。接下来,关键特征 f^ir,sk\hat{f}^k_{ir,s}f^ir,sk 是通过对门控瓶颈的输出 f^ir,sb\hat{f}^b_{ir,s}f^ir,sb 进行全局平均池化(GAP)和 1 × 1 卷积层获得的。更具体来说,
f^vis,sq=Fconv1×1(f^vis)∈RH×W×C,(1)
\hat{f}^q_{vis,s} = F^{1\times 1}_{conv}(\hat{f}_{vis}) \in \mathbb{R}^{H\times W\times C}, \tag{1}
f^vis,sq=Fconv1×1(f^vis)∈RH×W×C,(1)
f^ir,sk=σ(FGAP(Fconv1×1(f^ir,sb)))∈R1×1×C,(2)
\hat{f}^k_{ir,s} = \sigma(F_{GAP}(F^{1\times 1}_{ conv}(\hat{f}^b_{ir,s}))) \in \mathbb{R}^{1\times 1\times C}, \tag{2}
f^ir,sk=σ(FGAP(Fconv1×1(f^ir,sb)))∈R1×1×C,(2)
其中,Fconv1×1F^{1\times 1}_{conv}Fconv1×1 是 1×11×11×1 卷积函数,FGAPF_{GAP}FGAP 是 GAP 函数,sig(⋅)\text{sig}(\cdot)sig(⋅) 是 Sigmoid 函数。HHH、WWW 和 CCC 分别表示特征图的高度、宽度和通道数。然后,我们将 f^vis,sq\hat{f}^q_{vis,s}f^vis,sq 和 f^ir,sk\hat{f}^k_{ir,s}f^ir,sk 分别重塑成 HW×CHW \times CHW×C 和 C×1C \times 1C×1 矩阵,以估计它们的不相关性图 Rvis,sR_{vis,s}Rvis,s:
Rvis,s=1−sig(f^vis,sq⊗f^ir,sk)∈RHW×1,(3)
R_{vis,s} = 1 - \text{sig}(\hat{f}^q_{vis,s} \otimes \hat{f}^k_{ir,s}) \in \mathbb{R}^{HW\times 1}, \tag{3}
Rvis,s=1−sig(f^vis,sq⊗f^ir,sk)∈RHW×1,(3)
其中,1 是所有元素为 1 的张量,⊗\otimes⊗ 表示矩阵乘法。最后,我们通过在每个通道上元素级相乘 Rvis,sR_{vis,s}Rvis,s 与 f^vis\hat{f}_{vis}f^vis,得到精炼的可见光特征图 f^vis,s\hat{f}_{vis,s}f^vis,s。更具体来说,设 f^vis,s(i)\hat{f}^{(i)}_{vis,s}f^vis,s(i) 和 f^vis(i)\hat{f}^{(i)}_{vis}f^vis(i) 分别表示 f^vis,s\hat{f}_{vis,s}f^vis,s 和 f^vis\hat{f}_{vis}f^vis 的第 iii 个通道,则有:
f^vis,s(i)=Rvis,s⊙f^vis(i),(4)
\hat{f}^{(i)}_{vis,s} = R_{vis,s} \odot \hat{f}^{(i)}_{vis}, \tag{4}
f^vis,s(i)=Rvis,s⊙f^vis(i),(4)
其中 ⊙\odot⊙ 表示元素级乘法。
2) 通道 Transformer
红外和可见光图像之间的互补信息同时包含空间信息和全局上下文,例如强度分布和全局对比度。由于空间 Transformer 仅利用空间域的全局交互,它们可能无法充分保留有意义的场景信息。因此,为了捕获源图像的全局上下文,我们开发了通道 Transformer,通过通道间的互补信息来利用全局交互。图 2(b) 展示了所提出通道 Transformer 的架构,该组件估计通道域中的不相关性图,以表征通道间的特征交互。具体来说,对于可见光图像的查询和关键特征 f^vis,cq\hat{f}^q_{vis,c}f^vis,cq 和 f^ir,ck\hat{f}^k_{ir,c}f^ir,ck 分别为:
f^vis,cq=Fconv1×1(f^vis)∈RH×W×C,(5)
\hat{f}^q_{vis,c} = F^{1\times 1}_{conv}(\hat{f}_{vis}) \in \mathbb{R}^{H\times W\times C}, \tag{5}
f^vis,cq=Fconv1×1(f^vis)∈RH×W×C,(5)
f^ir,ck=sig(Fconv1×1(f^ir,cb))∈RH×W×1,(6)
\hat{f}^k_{ir,c} = \text{sig}(F^{1\times 1}_{conv}(\hat{f}^b_{ir,c})) \in \mathbb{R}^{H\times W\times 1}, \tag{6}
f^ir,ck=sig(Fconv1×1(f^ir,cb))∈RH×W×1,(6)
其中,f^ir,cb\hat{f}^b_{ir,c}f^ir,cb 是门控瓶颈的输出特征图。然后,将 f^vis,cq\hat{f}^q_{vis,c}f^vis,cq 和 f^ir,ck\hat{f}^k_{ir,c}f^ir,ck 分别重塑成 C×HWC \times HWC×HW 和 HW×1HW \times 1HW×1 矩阵。可见光特征f^vis\hat{f}_{vis}f^vis的不相关性图 Rvis,cR_{vis,c}Rvis,c 计算为:
Rvis,c=1−sig(f^vis,cq⊗f^ir,ck)∈RC×1.(7)
R_{vis,c} = 1 - \text{sig}(\hat{f}^q_{vis,c} \otimes \hat{f}^k_{ir,c}) \in \mathbb{R}^{C\times 1}. \tag{7}
Rvis,c=1−sig(f^vis,cq⊗f^ir,ck)∈RC×1.(7)
最后,精炼后的特征图 f^vis,c\hat{f}_{vis,c}f^vis,c 表示为:
f^vis,c=Rvis,c ⊛ f^vis,(8)
\hat{f}_{vis,c} = R_{vis,c} \,\circledast\, \hat{f}_{vis}, \tag{8}
f^vis,c=Rvis,c⊛f^vis,(8)
其中 ⊛\circledast⊛ 表示通道级乘法。
3) 门控瓶颈
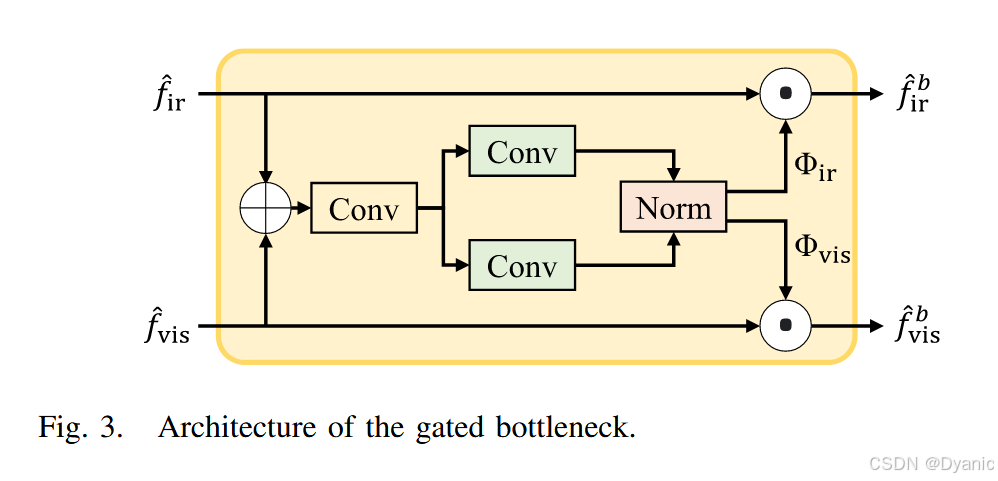
如前所述,所提出的 CMT 将两个特征图 {f^vis,f^ir}\{\hat{f}_{vis}, \hat{f}_{ir}\}{f^vis,f^ir} 作为对应 Transformer 的输入,以挖掘互补信息,不同于标准 Transformer [59] 和传统基于 Transformer 的融合算法 [43], [47], [48] 使用单一特征图作为输入。然而,由于源图像在不同模态中包含冗余信息,独立的 Transformer 可能无法有效地提取场景中的互补信息。因此,基于信息瓶颈能够有效交换跨模态信息 [60], [61] 的观察,我们开发了一个门控瓶颈,通过跨域交互交换源图像之间的冗余信息。图 3 展示了所提出门控瓶颈的架构。门控瓶颈将 f^vis\hat{f}_{vis}f^vis 和 f^ir\hat{f}_{ir}f^ir 作为输入,并分别为可见光和红外特征学习逐元素权重图Φvis\Phi{vis}Φvis 和 Φir\Phi_{ir}Φir,它们的维度均为 RH×W×C\mathbb{R}^{H\times W\times C}RH×W×C,以通过去除冗余来交换信息。更具体来说,Φvis\Phi_{vis}Φvis 和 Φir\Phi_{ir}Φir 的获得方式如下:
Φvis=Fnorm(Fconv3×3(Fconv1×1(f^vis⊕f^ir))),(9)
\Phi_{vis} = F_{norm}(F^{3\times 3}_{conv}(F^{1\times 1}_{conv}(\hat{f}_{vis} \oplus \hat{f}_{ir}))), \tag{9}
Φvis=Fnorm(Fconv3×3(Fconv1×1(f^vis⊕f^ir))),(9)
Φir=Fnorm(Fconv3×3(Fconv1×1(f^vis⊕f^ir))),(10)
\Phi_{ir} = F_{norm}(F^{3\times 3}_{conv}(F^{1\times 1}_{conv}(\hat{f}_{vis} \oplus \hat{f}_{ir}))), \tag{10}
Φir=Fnorm(Fconv3×3(Fconv1×1(f^vis⊕f^ir))),(10)
其中,⊕\oplus⊕ 表示在通道维度上的拼接,FnormF_{norm}Fnorm 表示使特征图同一位置的两个元素之和等于 1 的归一化函数。然后,我们得到门控瓶颈的输出:
f^visb=f^vis⊙Φvis,(11)
\hat{f}^b_{vis} = \hat{f}_{vis} \odot \Phi_{vis}, \tag{11}
f^visb=f^vis⊙Φvis,(11)
f^irb=f^ir⊙Φir.(12)
\hat{f}^b_{ir} = \hat{f}_{ir} \odot \Phi_{ir}. \tag{12}
f^irb=f^ir⊙Φir.(12)
4) 特征精炼
如图 1 所示,所提出的 CMT 分别使用空间 Transformer 和通道 Transformer 独立提取注意特征,以在特征图中获得不同的互补信息。具体而言,提取了两个可见光特征图 {f^vis,s,f^vis,c}\{\hat{f}_{vis,s}, \hat{f}_{vis,c}\}{f^vis,s,f^vis,c} 和两个红外特征图 {f^ir,s,f^ir,c}\{\hat{f}_{ir,s},\hat{f}_{ir,c}\}{f^ir,s,f^ir,c}。我们将它们合并,以传递关键信息,并改善空间-通道注意之间的交互,以进行进一步融合,这里使用单个 1 × 1 卷积层。更具体地,对于可见光和红外特征的两个精炼特征图 f^vis,r\hat{f}_{vis,r}f^vis,r 和 f^ir,r\hat{f}_{ir,r}f^ir,r 分别通过以下方式获得:
f^vis,r=Fconv1×1(f^vis,s⊕f^vis,c),(13)
\hat{f}_{vis,r} = F^{1\times 1}_{conv}(\hat{f}_{vis,s} \oplus \hat{f}_{vis,c}), \tag{13}
f^vis,r=Fconv1×1(f^vis,s⊕f^vis,c),(13)
f^ir,r=Fconv1×1(f^ir,s⊕f^ir,c).(14)
\hat{f}_{ir,r} = F^{1\times 1}_{conv}(\hat{f}_{ir,s} \oplus \hat{f}_{ir,c}). \tag{14}
f^ir,r=Fconv1×1(f^ir,s⊕f^ir,c).(14)
C. 融合模块
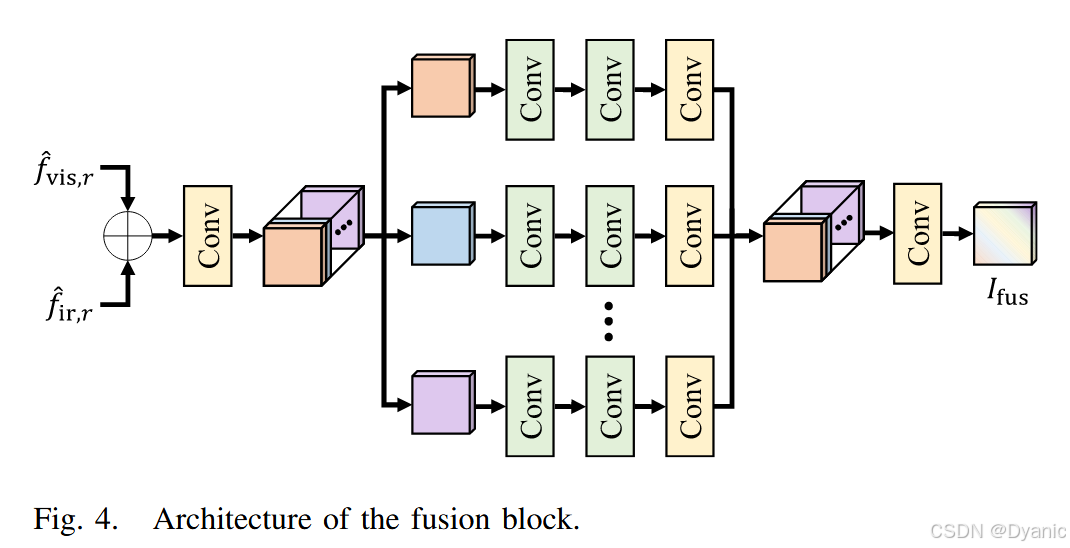
最后,式 (13)–(14) 中的精炼特征 {f^vis,r,f^ir,r}\{\hat{f}_{vis,r}, \hat{f}_{ir,r}\}{f^vis,r,f^ir,r} 被融合以在每层生成融合图像。任何模块,例如卷积 [28] 或残差块 [21],都可以用来融合这些特征。然而,这类直接的融合模块可能难以捕获精炼特征图中的空间与通道信息之间的交互,从而降低融合性能。因此,为了更好地利用精炼特征图中的空间-通道信息进行融合,我们使用图 4 中所示的自融合卷积块(SFC)[62],它可以使用较少参数有效地重建高级信息。不同模块对融合性能的影响将在第 IV-D 节中讨论。
D. 损失函数
我们以端到端方式训练 CMTFusion。为此,我们定义总损失 LtotalL_{total}Ltotal 为数据损失 LdL_dLd、空间损失 LsL_sLs、感知损失 LpL_pLp 和频率损失 LfL_fLf 的组合。具体而言:
Ltotal=Ld+λsLs+λpLp+λfLf,(15)
L_{total} = L_d + \lambda_s L_s + \lambda_p L_p + \lambda_f L_f, \tag{15}
Ltotal=Ld+λsLs+λpLp+λfLf,(15)
其中,超参数 λs,λp,λf\lambda_s, \lambda_p, \lambda_fλs,λp,λf控制四个损失之间的平衡。
我们将数据损失 LdL_dLd 定义为融合图像IfusI_{fus}Ifus 与源图像 IirI_{ir}Iir 和 IvisI_{vis}Ivis之间差异的加权和:
Ld=1L∑l=1Lωir⋅∥∥Ifusl−Iirl∥∥2+ωvis⋅∥∥Ifusl−Ivisl∥∥2,(16)
L_d = \frac{1}{L}\sum_{l=1}^L \omega_{ir}\cdot\|\|I^l_{fus} - I^l_{ir}\|\|_2 + \omega_{vis}\cdot\|\|I^l_{fus} - I^l_{vis}\|\|_2, \tag{16}
Ld=L1l=1∑Lωir⋅∥∥Ifusl−Iirl∥∥2+ωvis⋅∥∥Ifusl−Ivisl∥∥2,(16)
其中,权重ωir\omega_{ir}ωir 和 ωvis\omega_{vis}ωvis 控制源红外和可见光图像对融合结果的相对贡献,L 为金字塔层数。
为了保留源图像的空间特性,我们采用空间一致性损失 [65]:
Ls=1K∑i=1K∑j∈Ω(i)(ωir⋅(∥Ifusi−Ifusj∥1−∥∥Iiri−Iirj∥1)2+ωvis⋅(∥Ifusi−Ifusj∥1−∥Ivisi−Ivisj∥1)2),(17)
L_s = \frac{1}{K} \sum_{i=1}^K \sum_{j\in\Omega (i)} \left( \omega_{ir} \cdot (\|I^i_{fus} - I^j_{fus}\|_1 - \|\|I^i_{ir} - I^j_{ir}\|_1)^2 + \\
\omega_{vis} \cdot (\|I^i_{fus} - I^j_{fus}\|_1 - \|I^i_{vis} - I^j_{vis}\|_1)^2 \right), \tag{17}
Ls=K1i=1∑Kj∈Ω(i)∑(ωir⋅(∥Ifusi−Ifusj∥1−∥∥Iiri−Iirj∥1)2+ωvis⋅(∥Ifusi−Ifusj∥1−∥Ivisi−Ivisj∥1)2),(17)
其中 Ω(i)\Omega(i)Ω(i) 表示 iii 的邻域区域集合,KKK 为区域数量。
我们采用感知损失 [66] 保留融合图像与源图像之间的高级相似度,其表达式如下:
Lp=∑k=2,4,6(ωir⋅∥ϕk(Ifus)−ϕk(Iir)∥1+ωvis⋅∥ϕk(Ifus)−ϕk(Ivis)∥1),(18)
L_p = \sum_{k=2,4,6} \left( \omega_{ir} \cdot \| \phi_k(I_{fus}) - \phi^k(I_{ir}) \|_1 + \\
\omega_{vis} \cdot \| \phi^k(I_{fus}) - \phi^k(I_{vis}) \|_1 \right), \tag{18}
Lp=k=2,4,6∑(ωir⋅∥ϕk(Ifus)−ϕk(Iir)∥1+ωvis⋅∥ϕk(Ifus)−ϕk(Ivis)∥1),(18)
其中ϕk\phi_kϕk表示预训练 VGG-16 网络 [67] 的第kkk 层特征图。
基于学习的算法由于 CNN 的偏差,往往会丢失源图像中的高频信息,导致最终结果中的细节丢失和可见伪影 [68]。因此,为了保留结构与纹理细节的高频信息,我们定义频率损失 LfL_fLf,它衡量融合图像与源图像在频域的差异:
Lf=1HW∑v=0H−1∑u=0W−1(Wir(u,v)⋅∣Ffus(u,v)−Fir(u,v)∣2+Wvis(u,v)⋅∣Ffus(u,v)−Fvis(u,v)∣2),(19)
L_f = \frac{1}{HW}\sum_{v=0}^{H-1}\sum_{u=0}^{W-1} \big( W_{ir}(u,v) \cdot |F_{fus}(u,v) - F_{ir}(u,v)|^2 + W_{vis}(u,v) \cdot |F_{fus}(u,v) - F_{vis}(u,v)|^2 \big), \tag{19}
Lf=HW1v=0∑H−1u=0∑W−1(Wir(u,v)⋅∣Ffus(u,v)−Fir(u,v)∣2+Wvis(u,v)⋅∣Ffus(u,v)−Fvis(u,v)∣2),(19)
其中 Fir,Fvis,FfusF_{ir}, F_{vis}, F_{fus}Fir,Fvis,Ffus 分别是 Iir,Ivis,IfusI_{ir}, I_{vis}, I_{fus}Iir,Ivis,Ifus 的离散傅里叶变换系数。红外和可见光图像的权重 Wir,WvisW_{ir}, W_{vis}Wir,Wvis定义为:
Wir(u,v)=1−G(u−W−12,v−H−12;σir),(20)
W_{ir}(u,v) = 1 - G\left(u - \frac{W-1}{2}, v - \frac{H-1}{2}; \sigma_{ir}\right), \tag{20}
Wir(u,v)=1−G(u−2W−1,v−2H−1;σir),(20)
Wvis(u,v)=1−G(u−W−12,v−H−12;σvis),(21)
W_{vis}(u,v) = 1 - G\left(u - \frac{W-1}{2}, v - \frac{H-1}{2}; \sigma_{vis}\right), \tag{21}
Wvis(u,v)=1−G(u−2W−1,v−2H−1;σvis),(21)
以强调高频分量,其中G(u,v;σ)G(u,v; \sigma)G(u,v;σ)是参数为σ\sigmaσ的二维高斯函数。在本文中,红外与可见光的 σir,σvis\sigma_{ir}, \sigma_{vis}σir,σvis 分别固定为 1 和 2。
IV. 实验结果
A. 实验设置
实现细节:
我们仅使用 KAIST 数据集 [63] 来训练所提出的 CMTFusion 算法,该数据集包含 95,000 对良好对齐的可见光与红外图像。我们随机裁剪 20,000 对尺寸为 256×256256×256256×256的图像块,并将 RGB 颜色转换为灰度。我们使用 Adam 优化器 [69],其参数设定为 β1=0.9β₁ = 0.9β1=0.9、β2=0.999β₂ = 0.999β2=0.999,学习率为 10−410⁻⁴10−4,批量大小为 4,训练 20 轮。式 (15) 中的超参数 λsλₛλs、λpλₚλp和 λfλ_fλf分别固定为 0.8、0.02 和 0.05,以在整体主观质量上达到最佳效果并通过更关注空间信息确保训练稳定,式 (16)–(18) 中的 ωinfω_{inf}ωinf 和 ωvisω_{vis}ωvis 均设为 0.5。
数据集:
尽管严格只使用单一训练数据集,我们仍在多个数据集上评估所提出的 CMTFusion 算法,以检验其泛化能力及有效性。
KAIST [63]:包含使用特殊摄像设备拍摄的分辨率为 640×512640×512640×512 的图像对。我们随机选择 200 对未用于训练的图像对进行测试。
TNO [64]:包含对齐的多光谱夜间图像,涉及不同的军事相关场景。我们使用 [26] 中的测试集,该测试集包括 20 对分辨率在 280×280 至 768×576 范围内的图像对。
RoadScene [28]:包含 221 对分辨率最高为 563×459 的对齐图像对,这些图像使用真实世界相机拍摄,由 Xu 等人 [28] 从 FLIR 数据集¹ 中选取。
M3FD [40]:包含在各种环境、光照、季节和天气条件下拍摄的对齐图像对。我们使用用于测试的独立场景,包括 300 对分辨率最高为 1024×768 的图像对。
用于对比的最新方法:
我们将所提出算法的性能与 15 种最新融合算法进行对比:MDLatLRR [12]、IVFusion [52]、DenseFuse [26]、SEDRFuse [21]、DDcGAN [38]、DRF [22]、UNFusion [25]、RFN-Nest [27]、CSF [23]、GAMFM [39]、U2Fusion [28]、TarDAL [40]、UMFusion [24]、YDTR [48] 和 ReCoNet [29]。所有基于学习的算法 [21]–[40], [48] 均使用 KAIST 数据集及各作者推荐的配置重新训练。源代码和预训练模型将在我们的项目网站²发布。
B. 定量评估
我们使用七个质量指标评估融合性能:总边缘信息 (QAB/F) [70]、离散余弦特征的互信息 (FMIdct) [71]、小波特征的互信息 (FMIw) [71]、多尺度结构相似度 (MS-SSIM) [72]、差分相关性之和 (SCD) [73]、无参考图像空间质量评估器 (BRISQUE) [74] 和自然图像质量评估器 (NIQE) [75]。QAB/F、FMIdct、FMIw、MS-SSIM 和 SCD 的分数是在源图像与融合图像之间计算,然后取平均值。此外,由于缺乏真实值,我们使用两个盲质量度量指标 BRISQUE 和 NIQE。QAB/F、FMIdct、FMIw、MS-SSIM 和 SCD 分数越高表示性能越好,BRISQUE 和 NIQE 分数越低表示性能越好。
表 I 对 KAIST 数据集上的融合性能进行了定量比较。在基于信息论的指标 QAB/F 和 FMIdct 上,CMTFusion 算法获得了最高分,表明所提出的算法能有效保留源图像的互补信息。此外,所提出的 CMTFusion 在基于保真度的指标 MS-SSIM 和 SCD 上超过了所有传统算法,通过保留源图像的结构和精细纹理实现了更优性能。需要注意的是,每个质量指标具有不同的特性,评估图像质量的不同方面 [3],因此难以仅用单一指标比较性能。因此,我们采用基于排名的评估方法 [76] 来进行整体性能评估。具体来说,在表 I 中,对于每个算法,我们确定不同指标的排名,并在最右列给出平均排名。所提出的算法在平均排名方面显著优于传统算法。这些结果证实了所提出的 CMTFusion 通过利用全局交互在保留源图像互补信息方面的优越性。
表 II 展示了在未用于训练的 TNO 数据集上的定量评估结果,其结果趋势与表 I 相似。具体来说,所提出算法的 QAB/F、FMIdct、MS-SSIM 和 SCD 分数依然保持最高,并且有较大优势,证明了算法的优越泛化能力。此外,所提出算法的 BRISQUE 分数显著高于竞争算法,表明 CMTFusion 的融合结果更加自然。
表 III 对 RoadScene 数据集上的融合性能进行了比较。所提出算法的 SCD 分数保持最高,而 QAB/F、FMIdct、MS-SSIM、BRISQUE 和 NIQE 分数与最佳分数相当。注意到结果与表 I 和表 II 的趋势相似。
最后,表 IV 对 M3FD 数据集上的定量性能进行了比较。所提出算法在 QAB/F、MS-SSIM 和 SCD 上取得了最高或第二高的分数,表明所提出算法很好地保留了输入图像的结构和纹理细节。
综上所述,所提出算法在所有数据集的平均排名方面均具有明显优势。这些结果证实 CMTFusion 能够通过有效保留红外与可见光图像的基本互补信息实现最佳整体性能。此外,所提出算法在所有未参与训练的数据集上表现趋势一致,体现了其出色的泛化能力。
C. 定性评估
图 5 比较了各算法在 KAIST 数据集上的融合结果。MDLatLRR、DDcGAN、UNFusion、GANFM、TarDAL 和 ReCoNet(图 5©、(g)、(i)、(l)、(n) 和 (q))生成了可见伪影和噪声,改变了图像的特征,例如第四行中的行人。在图 5(d) 中,IVFusion 过度增强了源图像的对比度,降低了结果的视觉质量。DenseFuse、RFN-Nest 和 CSF(图 5(e)、(j)、(k))生成的低对比度结果使得细节难以识别。SEDRFuse、DRF、U2Fusion、UMFusion 和 YDTR(图 5(f)、(h)、(m)、(o)、§)生成了相对模糊的结果,导致纹理细节丢失,例如第二行中的树。相比之下,所提出的算法(图 5®)能够忠实保留两幅源图像中的纹理细节。
图 6 展示了 TNO 数据集上的融合结果。MDLatLRR、IVFusion、DDcGAN 和 UNFusion(图 6©、(d)、(g)、(i))在结果中产生了严重的视觉伪影,降低了整体图像质量,例如第二行中的人。DenseFuse、SEDRFuse、RFN-Nest、U2Fusion、TarDAL 和 UMFusion(图 6(e)、(f)、(j)、(m)、(n)、(o))的结果伪影较少,但存在模糊现象并丢失了纹理信息,例如第四行中的云。DRF、CSF、GAN-FM、YDTR 和 ReCoNet(图 6(h)、(k)、(l)、§、(q))丢失了源图像中的互补信息,生成的融合图像偏向于红外或可见光图像之一,例如第二行中人后面的灌木。相比之下,所提出的算法(图 6®)有效保留了两幅源图像的互补信息,且没有明显伪影。
图 7 比较了各算法在 RoadScene 数据集上的融合结果。MDLatLRR、IVFusion、DDcGAN、UNFusion、CSF 和 UMFusion(图 7©、(d)、(g)、(i)、(k)、(o))产生了不良伪影和噪声,降低了图像质量。DenseFuse、SEDRFuse、RFN-Nest 和 TarDAL(图 7(e)、(f)、(j)、(n))丢失了纹理信息,生成了模糊的图像,例如第二行的汽车。DRF、GAN-FM、U2Fusion、YDTR 和 ReCoNet(图 7(h)、(l)、(m)、§、(q))未能忠实保留两幅源图像的互补信息,因此融合图像丢失了来自红外或可见光图像的一部分视觉信息,例如第四行的路灯和路标。相比之下,所提出的 CMTFusion 算法(图 7®)能够忠实保留每幅源图像中的精细纹理。
最后,图 8 比较了 M3FD 数据集的融合结果。它们表现出的趋势与图 5–7 相似。具体来说,MDLatLRR、SEDRFuse、DDcGAN、UNFusion、UMFusion 和 ReCoNet(图 8©、(f)、(g)、(i)、(o)、(q))产生了明显伪影,例如第二行的汽车。IVFusion 和 GAN-FM(图 8(d)、(l))过度增强了输入图像的对比度,而 CSF 和 YDTR(图 8(k)、§)对比度较差。DenseFuse、DRF、RFN-Nest、U2Fusion 和 TarDAL(图 8(e)、(h)、(j)、(m)、(n))生成的融合图像细节较少。
D. 模型分析
我们进行了消融实验以验证所提出算法的关键组件的有效性:金字塔层数、CMTs 和融合模块。我们还分析了损失函数各部分对融合性能的影响。所有实验使用 TNO 数据集 [64] 并采用基于排名的评估方法进行定量性能评估。
-
金字塔层数:为了分析所提出网络的层数 L 的影响,我们在不同层数下进行了训练。表 V 对结果进行了定量比较。随着层数 L 的增加,性能提升,因为网络提取了更多有意义的特征。然而,层数过多会降低性能,因为过小的特征图含有较少结构信息,传递到下一层后导致特征信息不足的传播。
-
CMTs:我们分析了所提出 CMTs 中每个组件的有效性,通过不同设置训练所提出网络。表 VI 比较了融合性能。在没有 CMTs 的情况下,所提出算法的融合性能最差,因为互补信息无法充分利用。仅使用通道或空间 Transformer 能够分别通过在对应域中捕获全局交互来提升融合性能。同时使用通道和空间 Transformer 能够更有效地提取互补信息,性能进一步提升。最后,加入门控瓶颈获得了最佳性能,说明门控瓶颈通过跨域交互交换互补信息增强了特征表示能力。
-
融合模块:我们分析了第 III-C 节描述的 SFC 块作为融合模块的有效性,通过使用不同融合块训练所提出网络,例如 1 × 1 卷积层、残差密集块(RDB)[77]、MBConv [78] 和 SFC [62]。表 VII 比较了融合性能。SFC 块在参数量相当的情况下实现了最佳融合性能,表明 SFC 块能够比竞争的特征融合块更有效地重建高级特征。
-
损失函数:我们分析了损失函数各部分的贡献,通过不同组合的损失训练所提出网络。表 VIII 比较了结果。仅使用数据损失 (L_d) 时性能最差;加入空间一致性损失 (L_s) 能够保留源图像的空间特性并提升性能;加入感知损失 (L_p) 能够保留高级上下文从而进一步提升性能;频率损失 (L_f) 能够减轻源图像与融合图像之间的差异;此外,在频率损失中加入权重进一步提升性能,因为它引导网络强调源图像的高频信息,保留结构和纹理细节。最后,使用更深的网络 VGG-19 来计算 (L_p) 会降低融合性能,因为它更关注全局语义而非局部特征。
E. 计算复杂度
表 IX 比较了不同算法在分辨率为 640 × 512 的图像对上所需的网络参数数量、每秒吉级浮点运算次数(GFLOPs)以及平均运行时间,测试在 Nvidia RTX 3090 GPU 上进行。运行时间是对 KAIST 数据集 200 对图像的结果取平均值。所提出的 CMTFusion 在运行时间方面排名第三。然而,运行时间最快的两个算法 DenseFuse 和 RFN-Net 的融合性能如 IV-B 节所述明显低于所提出算法。此外,所提出算法在网络参数数量和 GFLOPs 上表现相近。这些结果表明,所提出算法在性能与复杂度之间提供了优越的权衡,这得益于 CMTs 能有效捕获源图像的全局交互以及其由粗到细的实现方式。
F. 目标检测评估
我们通过将各算法的融合结果应用到目标检测算法中,来评估所提出算法在促进计算机视觉任务方面的有效性。具体而言,我们在 KAIST 和 RoadScene 数据集上使用在 COCO 数据集 [80] 上预训练的 YOLOv4 模型 [79] 进行评估。表 X 定量比较了各融合结果在平均精度均值(mAP)指标上的表现。结果表明,所提出的 CMTFusion 在两个数据集上均实现显著更高的 mAP 值,获得了最佳目标检测性能。具体而言,在 KAIST 和 RoadScene 数据集上,所提出算法相比第二名(DDcGAN 和 U2Fusion)分别提高了 5.39 和 5.96 mAP 值。需要注意的是,只有所提出算法的融合结果在两个数据集上的 mAP 值高于可见光图像。图 9 比较了 KAIST 和 RoadScene 数据集上的目标检测结果。所提出的 CMTFusion(图 9®)的检测精度高于红外图像(图 9(a))和可见光图像(图 9(b))。例如,第一行中在图 9(a) 和图 9(b) 中错误检测的汽车和行人,在图 9® 中被正确检测。同时,所提出算法获得的融合结果在所有目标上均优于其他算法。例如,交通信号灯在图 9® 的第二行中被正确检测,而其他算法未能检测。
G. 单目深度估计评估
我们在另一项计算机视觉任务——单目深度估计上验证所提出算法的有效性。为此,我们在 KAIST 数据集上使用在预训练的 DPT 模型 [81]。图 10 展示了深度估计结果示例。所提出算法(图 10®)在深度图估计方面比传统算法更准确。例如,所提出算法在第二行中准确估计了建筑区域并最忠实地重建了轮廓,而传统算法的结果在这些区域存在错误(除了 UNFusion(图 10(i)))。这表明所提出算法在提升后续计算机视觉性能方面具有巨大潜力。
H. RGB 图像融合
所提出的 CMTFusion 算法开发的初衷是为了与 TNO 数据集 [64] 保持一致而融合单通道的可见光和红外图像。然而,它同样可以用于融合 RGB 通道的可见光和红外图像。图 11 展示了 KAIST、RoadScene 和 M3FD 数据集的融合结果。可以看到,可见光图像的颜色信息在融合结果中被忠实保留,同时保留了输入图像之间的互补信息。
I. 局限性
尽管所提出的 CMTFusion 算法在大多数情况下可以在没有明显伪影的情况下保留两幅源图像的互补信息,但它存在需要在未来解决的局限性。具体来说,如果某个对象在两幅输入图像中均具有显著性,所提出的 CMTs 可能无法准确估计不相关性图,从而在融合图像中去除了输入图像之间的互补信息。图 12 展示了这些失败案例的示例,其中图 12©–12(f) 中的精炼特征丢失了对象的精细纹理信息,例如第二行中的汽车,导致最终结果(图 12(g))中出现可见伪影。
V. 结论
我们提出了一种基于跨模态 Transformer 的融合算法——CMTFusion,用于红外与可见光图像融合,该算法能够通过捕获源图像之间的全局交互来保留互补信息。具体来说,我们首先以由粗到细的方式从每个源图像中提取多尺度特征。本工作的主要贡献是开发了 CMT,它在空间域和通道域去除源图像的冗余信息,通过捕获源图像之间的全局交互与上下文来确定互补区域。最后,所提出的算法将互补特征聚合以获得融合图像。在多个数据集上的实验结果证实,所提出的 CMTFusion 在融合性能方面优于最新算法。此外,实验表明,所提出算法可以用于提升多种计算机视觉任务的性能。一些未来工作的方向包括将 CMTFusion 推广到解决不同的图像融合任务,以及开发更有效的融合方案来促进高级计算机视觉任务。