Milvus:标量字段-字符串、数字、数组与结构数组(七)

一、字符串字段 (VARCHAR)
1.1 概念解析
VARCHAR字段是Milvus中用于存储可变长度字符串数据的标量字段类型。
核心特性:
- 可变长度:存储长度可变的字符串
- 最大长度限制:支持1到65,535字节
- 空值支持:可配置允许空值
- 默认值:支持设置默认字符串值
- 高效存储:只存储实际字符串内容
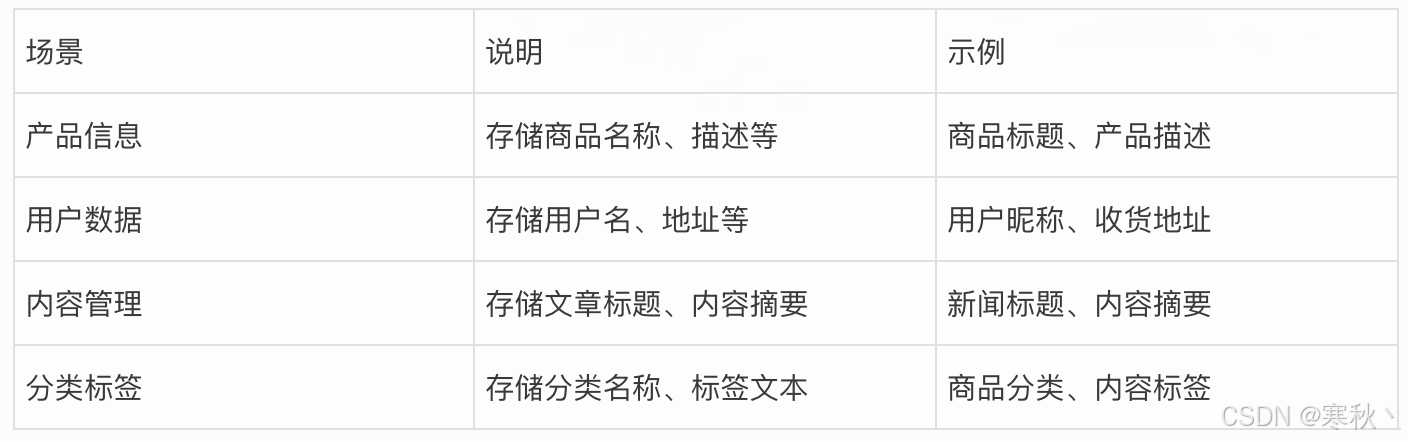
1.2 应用场景
1.3 完整代码示例
from pymilvus import MilvusClient, DataTypedef create_varchar_collection():"""创建包含VARCHAR字段的Collection完整示例"""client = MilvusClient(uri="http://localhost:19530")# 清理现有Collectionif client.has_collection("varchar_demo"):client.drop_collection("varchar_demo")# 创建Schemaschema = client.create_schema(auto_id=False,enable_dynamic_fields=True,)# 添加VARCHAR字段 - 产品名称,最大100字符,允许空值,默认"Unknown"schema.add_field(field_name="product_name", datatype=DataType.VARCHAR, max_length=100, nullable=True, default_value="Unknown")# 添加VARCHAR字段 - 产品描述,最大500字符,允许空值,无默认值schema.add_field(field_name="description", datatype=DataType.VARCHAR, max_length=500, nullable=True)# 添加主键和向量字段schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=128)# 配置索引index_params = client.prepare_index_params()# 为VARCHAR字段创建索引(可选)index_params.add_index(field_name="product_name",index_type="AUTOINDEX",index_name="product_name_idx")# 为向量字段创建索引index_params.add_index(field_name="embedding",index_type="IVF_FLAT",metric_type="COSINE",params={"nlist": 1024})# 创建Collectionclient.create_collection(collection_name="varchar_demo",schema=schema,index_params=index_params)print("✅ VARCHAR字段Collection创建成功")return clientdef insert_varchar_data(client):"""插入VARCHAR字段数据示例"""data = [{"product_name": "智能手机X1","description": "最新款智能手机,配备顶级摄像头","pk": 1,"embedding": [0.1] * 128},{"product_name": "笔记本电脑Pro","description": None, # 描述为空"pk": 2, "embedding": [0.2] * 128},{"product_name": None, # 产品名称为空,使用默认值"Unknown""description": "高性能游戏笔记本","pk": 3,"embedding": [0.3] * 128},{# product_name字段缺失,使用默认值"Unknown""description": "便携式蓝牙音箱","pk": 4,"embedding": [0.4] * 128}]result = client.insert(collection_name="varchar_demo",data=data)print(f"✅ 插入 {len(result['ids'])} 条VARCHAR数据")return resultdef query_varchar_examples(client):"""VARCHAR字段查询示例"""print("\n🔍 VARCHAR字段查询示例:")# 1. 精确匹配查询print("1. 精确匹配查询 - product_name = '智能手机X1'")results = client.query(collection_name="varchar_demo",filter="product_name == '智能手机X1'",output_fields=["pk", "product_name", "description"])for item in results:print(f" ID: {item['pk']}, 产品: {item['product_name']}")# 2. 空值查询print("\n2. 空值查询 - description is null")results = client.query(collection_name="varchar_demo",filter="description is null", output_fields=["pk", "product_name", "description"])for item in results:print(f" ID: {item['pk']}, 产品: {item['product_name']}, 描述: {item['description']}")# 3. 默认值查询print("\n3. 默认值查询 - product_name == 'Unknown'")results = client.query(collection_name="varchar_demo", filter="product_name == 'Unknown'",output_fields=["pk", "product_name", "description"])for item in results:print(f" ID: {item['pk']}, 产品: {item['product_name']}, 描述: {item['description']}")# 4. 向量搜索 + VARCHAR过滤print("\n4. 向量搜索 + VARCHAR过滤")search_results = client.search(collection_name="varchar_demo",data=[[0.15] * 128], # 查询向量anns_field="embedding",search_params={"params": {"nprobe": 10}},limit=3,output_fields=["pk", "product_name"],filter="product_name != 'Unknown'" # 过滤掉默认值)for hits in search_results:for hit in hits:print(f" ID: {hit['id']}, 距离: {hit['distance']:.4f}, 产品: {hit['entity']['product_name']}")# 执行示例
varchar_client = create_varchar_collection()
insert_varchar_data(varchar_client)
query_varchar_examples(varchar_client)二、数字字段
2.1 概念解析
数字字段用于存储数值数据,包括整数和浮点数。
支持的数字类型:
类型 | 描述 | 范围 | 适用场景 |
BOOL | 布尔值 | true/false | 状态标志、开关 |
INT8 | 8位整数 | -128 到 127 | 小范围计数 |
INT16 | 16位整数 | -32,768 到 32,767 | 中等范围数据 |
INT32 | 32位整数 | -2³¹ 到 2³¹-1 | 一般整数数据 |
INT64 | 64位整数 | -2⁶³ 到 2⁶³-1 | 大范围数据、时间戳 |
FLOAT | 32位浮点数 | 单精度 | 一般精度数据 |
DOUBLE | 64位浮点数 | 双精度 | 高精度数据 |
2.2 应用场景
场景 | 数据类型 | 示例 |
用户信息 | INT32/INT64 | 年龄、用户ID |
商品数据 | FLOAT/DOUBLE | 价格、评分 |
状态标记 | BOOL | 是否可用、是否推荐 |
时间数据 | INT64 | 时间戳、创建时间 |
统计指标 | INT32/FLOAT | 销量、点击率 |
2.3 完整代码示例
def create_numeric_collection():"""创建包含数字字段的Collection"""client = MilvusClient(uri="http://localhost:19530")if client.has_collection("numeric_demo"):client.drop_collection("numeric_demo")schema = client.create_schema(auto_id=False,enable_dynamic_fields=True,)# 添加各种数字字段schema.add_field(field_name="user_id", datatype=DataType.INT64, is_primary=True)schema.add_field(field_name="age", datatype=DataType.INT32, nullable=True, default_value=18)schema.add_field(field_name="price", datatype=DataType.FLOAT, nullable=True)schema.add_field(field_name="rating", datatype=DataType.DOUBLE, nullable=True, default_value=0.0)schema.add_field(field_name="is_premium", datatype=DataType.BOOL, nullable=True, default_value=False)schema.add_field(field_name="click_count", datatype=DataType.INT16, nullable=True, default_value=0)schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=64)# 配置索引index_params = client.prepare_index_params()# 为数字字段创建索引(可选)index_params.add_index(field_name="age",index_type="AUTOINDEX",index_name="age_idx")index_params.add_index(field_name="price", index_type="AUTOINDEX",index_name="price_idx")# 向量字段索引index_params.add_index(field_name="embedding",index_type="IVF_FLAT",metric_type="L2",params={"nlist": 256})client.create_collection(collection_name="numeric_demo",schema=schema,index_params=index_params)print("✅ 数字字段Collection创建成功")return clientdef insert_numeric_data(client):"""插入数字字段数据示例"""data = [{"user_id": 1001,"age": 25,"price": 299.99,"rating": 4.5,"is_premium": True,"click_count": 150,"embedding": [0.1] * 64},{"user_id": 1002,"age": None, # 年龄为空,使用默认值18"price": 199.50,"rating": 3.8,"is_premium": False,"click_count": 75,"embedding": [0.2] * 64},{"user_id": 1003,"age": 35,"price": None, # 价格为空"rating": None, # 评分为空,使用默认值0.0"is_premium": True,"click_count": 200,"embedding": [0.3] * 64},{"user_id": 1004,"age": 22,"price": 599.99,"rating": 4.9,"is_premium": None, # 会员状态为空,使用默认值False"click_count": None, # 点击数为空,使用默认值0"embedding": [0.4] * 64}]result = client.insert(collection_name="numeric_demo",data=data)print(f"✅ 插入 {len(result['ids'])} 条数字字段数据")return resultdef query_numeric_examples(client):"""数字字段查询示例"""print("\n🔍 数字字段查询示例:")# 1. 范围查询print("1. 范围查询 - age between 20 and 30")results = client.query(collection_name="numeric_demo",filter="age >= 20 and age <= 30",output_fields=["user_id", "age", "price"])for item in results:print(f" 用户ID: {item['user_id']}, 年龄: {item['age']}, 价格: {item['price']}")# 2. 空值查询print("\n2. 空值查询 - price is null")results = client.query(collection_name="numeric_demo",filter="price is null",output_fields=["user_id", "price", "rating"])for item in results:print(f" 用户ID: {item['user_id']}, 价格: {item['price']}, 评分: {item['rating']}")# 3. 布尔值查询print("\n3. 布尔值查询 - is_premium == true")results = client.query(collection_name="numeric_demo", filter="is_premium == true",output_fields=["user_id", "is_premium", "rating"])for item in results:print(f" 用户ID: {item['user_id']}, 会员: {item['is_premium']}, 评分: {item['rating']}")# 4. 多条件组合查询print("\n4. 多条件组合查询 - rating > 4.0 and price < 300")results = client.query(collection_name="numeric_demo",filter="rating > 4.0 and price < 300",output_fields=["user_id", "rating", "price"])for item in results:print(f" 用户ID: {item['user_id']}, 评分: {item['rating']}, 价格: {item['price']}")# 5. 向量搜索 + 数字过滤print("\n5. 向量搜索 + 数字过滤")search_results = client.search(collection_name="numeric_demo",data=[[0.15] * 64],anns_field="embedding", search_params={"params": {"nprobe": 10}},limit=3,output_fields=["user_id", "age", "price"],filter="age > 20 and price > 100" # 数字字段过滤)for hits in search_results:for hit in hits:print(f" 用户ID: {hit['entity']['user_id']}, 年龄: {hit['entity']['age']}, 价格: {hit['entity']['price']}")# 执行示例
numeric_client = create_numeric_collection()
insert_numeric_data(numeric_client)
query_numeric_examples(numeric_client)三、数组字段 (ARRAY)
3.1 概念解析
ARRAY字段用于存储相同数据类型元素的有序集合。
核心特性:
- 同质元素:所有元素必须是相同数据类型
- 固定容量:最大容量1-4096个元素
- 有序存储:保持元素的插入顺序
- 空值支持:整个数组可以为空
- 元素访问:支持通过索引访问特定元素
限制说明:
- ❌ 不支持默认值
- ❌ 元素类型不能是JSON
- ✅ 支持空值(nullable=True)
- ✅ VARCHAR元素需要指定max_length
3.2 应用场景

3.3 完整代码示例
def create_array_collection():"""创建包含ARRAY字段的Collection"""client = MilvusClient(uri="http://localhost:19530")if client.has_collection("array_demo"):client.drop_collection("array_demo")schema = client.create_schema(auto_id=False,enable_dynamic_fields=True,)# 添加ARRAY字段 - 字符串数组schema.add_field(field_name="tags", datatype=DataType.ARRAY, element_type=DataType.VARCHAR,max_capacity=10, # 最大10个标签max_length=50, # 每个标签最大50字符nullable=True)# 添加ARRAY字段 - 整数数组schema.add_field(field_name="ratings",datatype=DataType.ARRAY,element_type=DataType.INT64, max_capacity=5, # 最大5个评分nullable=True)# 添加ARRAY字段 - 浮点数数组schema.add_field(field_name="features",datatype=DataType.ARRAY,element_type=DataType.FLOAT,max_capacity=8, # 最大8个特征nullable=True)# 主键和向量字段schema.add_field(field_name="pk", datatype=DataType.INT64, is_primary=True)schema.add_field(field_name="embedding", datatype=DataType.FLOAT_VECTOR, dim=32)# 配置索引index_params = client.prepare_index_params()# 为ARRAY字段创建索引(可选)index_params.add_index(field_name="tags",index_type="AUTOINDEX", index_name="tags_idx")# 向量字段索引index_params.add_index(field_name="embedding",index_type="IVF_FLAT",metric_type="COSINE",params={"nlist": 128})client.create_collection(collection_name="array_demo",schema=schema,index_params=index_params)print("✅ ARRAY字段Collection创建成功")return clientdef insert_array_data(client):"""插入ARRAY字段数据示例"""data = [{"pk": 1,"tags": ["科技", "智能手机", "5G", "摄影"],"ratings": [5, 4, 5, 4],"features": [0.8, 0.6, 0.9, 0.7, 0.5],"embedding": [0.1] * 32},{"pk": 2, "tags": ["文学", "小说", "经典"],"ratings": [5, 5, 4, 3],"features": [0.3, 0.7, 0.2, 0.8, 0.4],"embedding": [0.2] * 32},{"pk": 3,"tags": None, # 整个tags数组为空"ratings": [4, 3],"features": [0.6, 0.4, 0.5, 0.3],"embedding": [0.3] * 32},{"pk": 4,"tags": ["美食", "烹饪", "食谱"],"ratings": None, # 整个ratings数组为空"features": [0.9, 0.8, 0.7],"embedding": [0.4] * 32},{"pk": 5,# tags字段完全缺失"ratings": [5, 5, 5, 4, 5],"features": [0.5, 0.6, 0.7, 0.8, 0.9, 1.0],"embedding": [0.5] * 32}]result = client.insert(collection_name="array_demo",data=data)print(f"✅ 插入 {len(result['ids'])} 条ARRAY字段数据")return resultdef query_array_examples(client):"""ARRAY字段查询示例"""print("\n🔍 ARRAY字段查询示例:")# 1. 空数组查询print("1. 空数组查询 - tags is not null")results = client.query(collection_name="array_demo",filter="tags is not null",output_fields=["pk", "tags"])for item in results:print(f" ID: {item['pk']}, 标签: {item['tags']}")# 2. 数组元素索引查询print("\n2. 数组元素索引查询 - ratings[0] > 4")results = client.query(collection_name="array_demo",filter="ratings[0] > 4", # 第一个评分大于4output_fields=["pk", "ratings"])for item in results:print(f" ID: {item['pk']}, 评分: {item['ratings']}")# 3. 数组包含查询print("\n3. 数组包含查询 - array_contains(tags, '科技')")results = client.query(collection_name="array_demo",filter="array_contains(tags, '科技')",output_fields=["pk", "tags"])for item in results:print(f" ID: {item['pk']}, 标签: {item['tags']}")# 4. 数组长度查询print("\n4. 数组长度查询 - array_length(ratings) >= 3")results = client.query(collection_name="array_demo",filter="array_length(ratings) >= 3",output_fields=["pk", "ratings", "array_length(ratings) as rating_count"])for item in results:print(f" ID: {item['pk']}, 评分: {item['ratings']}, 数量: {item['rating_count']}")# 5. 向量搜索 + 数组过滤print("\n5. 向量搜索 + 数组过滤")search_results = client.search(collection_name="array_demo",data=[[0.15] * 32],anns_field="embedding",search_params={"params": {"nprobe": 10}},limit=3,output_fields=["pk", "tags", "ratings"],filter="array_contains(tags, '科技') and array_length(ratings) > 2")for hits in search_results:for hit in hits:print(f" ID: {hit['entity']['pk']}, 标签: {hit['entity']['tags']}")# 执行示例
array_client = create_array_collection()
insert_array_data(array_client)
query_array_examples(array_client)四、结构体数组 (Array of Structs)
4.1 概念解析
结构体数组是Milvus 2.6.4+引入的高级功能,允许在数组中存储结构化的数据。
核心特性:
- 结构化数据:每个结构体包含多个字段
- 统一Schema:所有结构体共享相同的字段定义
- 向量支持:结构体内可以包含向量字段
- 复杂查询:支持对结构体字段的复杂操作
重要限制:
- ❌ 不能作为集合的顶级字段
- ❌ 不支持默认值
- ❌ 结构体字段不能为空
- ❌ 不支持标量字段过滤
- ✅ 仅支持HNSW索引类型
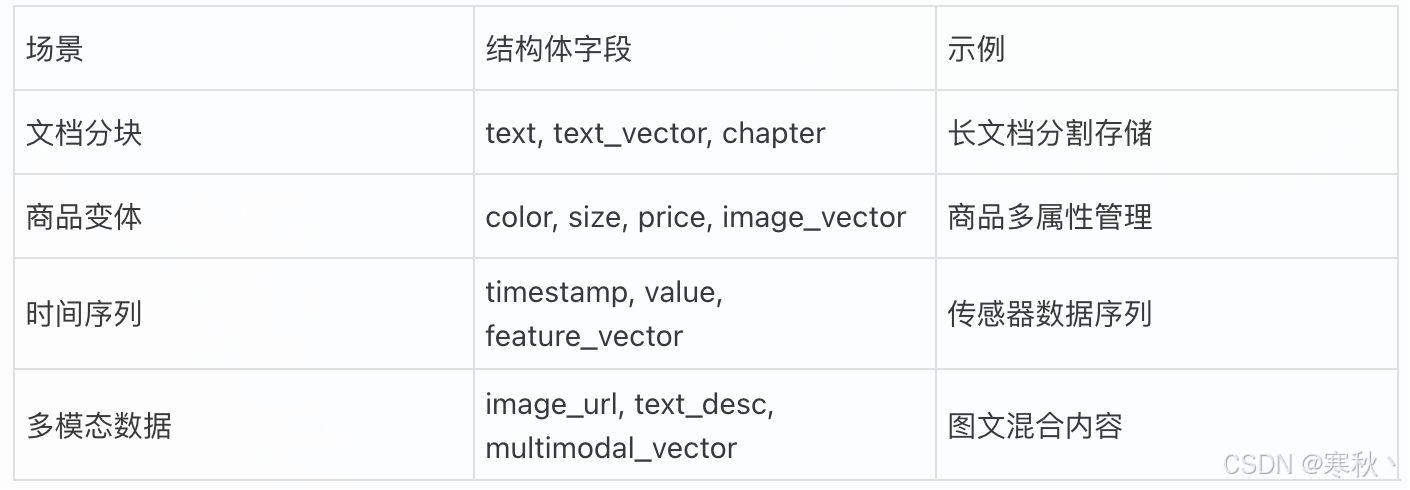
4.2 应用场景
4.3 完整代码示例
def create_struct_array_collection():"""创建包含结构体数组的Collection"""client = MilvusClient(uri="http://localhost:19530")if client.has_collection("struct_array_demo"):client.drop_collection("struct_array_demo")# 创建主Schemaschema = client.create_schema()# 添加主键字段schema.add_field(field_name="doc_id", datatype=DataType.INT64, is_primary=True, auto_id=True)# 添加文档级字段schema.add_field(field_name="doc_title", datatype=DataType.VARCHAR, max_length=200)schema.add_field(field_name="doc_author", datatype=DataType.VARCHAR, max_length=100)schema.add_field(field_name="doc_vector", datatype=DataType.FLOAT_VECTOR, dim=128)# 创建结构体Schemastruct_schema = client.create_struct_field_schema()# 添加结构体字段struct_schema.add_field("chunk_text", DataType.VARCHAR, max_length=1000 # 文本块内容)struct_schema.add_field("chunk_vector", DataType.FLOAT_VECTOR, dim=128, # 文本块向量mmap_enabled=True # 启用内存映射优化)struct_schema.add_field("chunk_type", DataType.VARCHAR, max_length=50 # 块类型:标题、段落、列表等)struct_schema.add_field("word_count", DataType.INT32 # 字数统计)# 添加结构体数组字段schema.add_field(field_name="chunks",datatype=DataType.ARRAY,element_type=DataType.STRUCT,struct_schema=struct_schema,max_capacity=50 # 最多50个文本块)# 配置索引参数index_params = client.prepare_index_params()# 为文档级向量字段创建索引index_params.add_index(field_name="doc_vector",index_type="IVF_FLAT",metric_type="COSINE",params={"nlist": 256})# 为结构体数组中的向量字段创建索引index_params.add_index(field_name="chunks[chunk_vector]", # 注意语法:字段名[结构体字段名]index_type="HNSW", # 结构体数组向量必须使用HNSWmetric_type="MAX_SIM_COSINE", # 专用度量类型params={"M": 16, # HNSW参数"efConstruction": 200})# 创建Collectionclient.create_collection(collection_name="struct_array_demo",schema=schema,index_params=index_params)print("✅ 结构体数组Collection创建成功")return clientdef insert_struct_array_data(client):"""插入结构体数组数据示例"""data = [{"doc_title": "人工智能发展历程","doc_author": "科技作者A","doc_vector": [0.1] * 128,"chunks": [{"chunk_text": "人工智能的概念最早可以追溯到20世纪50年代","chunk_vector": [0.11] * 128,"chunk_type": "引言","word_count": 15},{"chunk_text": "图灵测试是衡量机器智能的重要标准","chunk_vector": [0.12] * 128, "chunk_type": "正文","word_count": 12},{"chunk_text": "深度学习的发展推动了人工智能的新浪潮","chunk_vector": [0.13] * 128,"chunk_type": "结论","word_count": 10}]},{"doc_title": "机器学习算法综述", "doc_author": "数据科学家B","doc_vector": [0.2] * 128,"chunks": [{"chunk_text": "监督学习需要标注数据进行训练","chunk_vector": [0.21] * 128,"chunk_type": "分类","word_count": 8},{"chunk_text": "无监督学习可以发现数据中的隐藏模式","chunk_vector": [0.22] * 128,"chunk_type": "聚类", "word_count": 9}]}]result = client.insert(collection_name="struct_array_demo",data=data)print(f"✅ 插入 {len(result['ids'])} 条结构体数组数据")print(f"生成的文档ID: {result['ids']}")return resultdef search_struct_array_examples(client):"""结构体数组搜索示例"""from pymilvus import EmbeddingListprint("\n🔍 结构体数组搜索示例:")# 1. 文档级向量搜索print("1. 文档级向量搜索")doc_results = client.search(collection_name="struct_array_demo",data=[[0.15] * 128], # 文档级查询向量anns_field="doc_vector",search_params={"params": {"nprobe": 10}},limit=2,output_fields=["doc_title", "doc_author"])for hits in doc_results:for hit in hits:print(f" 文档标题: {hit['entity']['doc_title']}, 作者: {hit['entity']['doc_author']}")# 2. 结构体数组向量搜索 - 单个EmbeddingListprint("\n2. 结构体数组向量搜索 - 单个查询")embedding_list1 = EmbeddingList()embedding_list1.add([0.115] * 128) # 添加一个查询向量chunk_results1 = client.search(collection_name="struct_array_demo",data=[embedding_list1], # 使用EmbeddingList包装anns_field="chunks[chunk_vector]", # 指定结构体数组中的向量字段search_params={"metric_type": "MAX_SIM_COSINE"},limit=3,output_fields=["doc_title", "chunks[chunk_text]", "chunks[chunk_type]"])print(" 单个查询结果:")for hits in chunk_results1:for hit in hits:print(f" 文档: {hit['entity']['doc_title']}")if 'chunks' in hit['entity']:for chunk in hit['entity']['chunks']:print(f" 文本块: {chunk['chunk_text'][:30]}...")# 3. 结构体数组向量搜索 - 多个EmbeddingListprint("\n3. 结构体数组向量搜索 - 多个查询")embedding_list2 = EmbeddingList()embedding_list2.add([0.125] * 128) # 第一个查询向量embedding_list2.add([0.135] * 128) # 第二个查询向量embedding_list3 = EmbeddingList() embedding_list3.add([0.145] * 128) # 第三个查询向量chunk_results2 = client.search(collection_name="struct_array_demo",data=[embedding_list2, embedding_list3], # 多个EmbeddingListanns_field="chunks[chunk_vector]",search_params={"metric_type": "MAX_SIM_COSINE"},limit=2,output_fields=["doc_title", "chunks[chunk_text]"])print(" 多个查询结果:")for i, hits in enumerate(chunk_results2):print(f" 查询{i+1}结果:")for hit in hits:print(f" 文档: {hit['entity']['doc_title']}, 距离: {hit['distance']:.4f}")# 执行示例
struct_client = create_struct_array_collection()
insert_struct_array_data(struct_client)
search_struct_array_examples(struct_client)五、字段类型选择指南
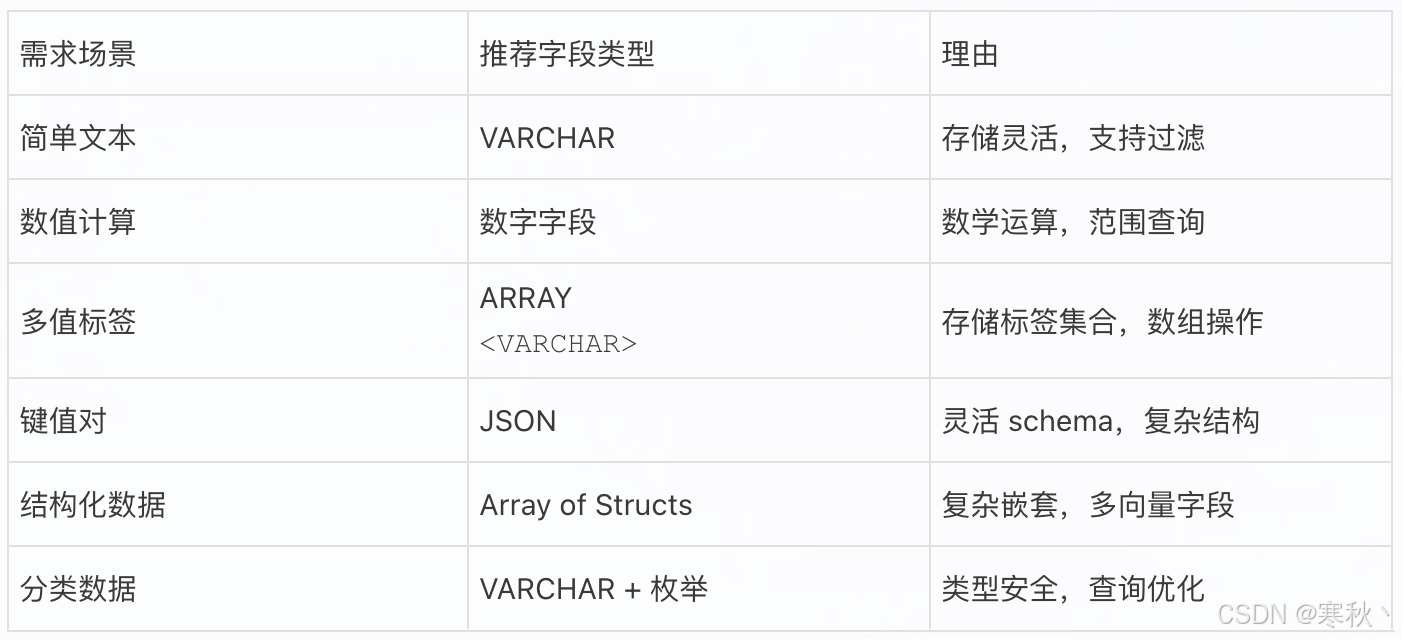
5.1 选择策略总结
5.2 性能优化建议
VARCHAR字段:
- 合理设置max_length,避免过度分配
- 对频繁查询的字段创建索引
- 使用LIKE操作时考虑NGRAM索引
数字字段:
- 选择合适的数据类型范围
- 对范围查询字段创建索引
- 考虑数据精度需求
ARRAY字段:
- 合理设置max_capacity
- 对数组操作频繁的字段创建索引
- 使用数组函数优化查询
结构体数组:
- 合理设计结构体Schema
- 为向量字段启用mmap优化
- 使用专用索引类型