kafka kraft 模式简介
一、背景
Zookeeper 提供了配置服务、分布式同步、命名服务、Leader 选举和集群管理等功能,很多大数据组件都依赖 Zookeeper 来构建,Apache Kafka 也不例外。但是随着 Kafka 功能的演进和应用场景越来越多,也暴露出了许多基于 Zookeeper 的问题:
- 基于 Zookeeper 的协作模式,使得 Kafka 的集群一致性维护越来越复杂;
- 受到 Zookeeper 性能的限制,使得 Kafka 无法支撑更大的集群规模;
- 并且 Zookeeper 自身带来的运维复杂性和产品稳定性,也同样将复杂度和风险负担传递到 Kafka 运维人员;
因此作为 Zookeeper 的替代,Kafka 3.3.1 提供了 KRaft 元数据管理组件,下图分别是 Zookeeper 模式和 KRaft 模式的 Kafka 部署架构图:
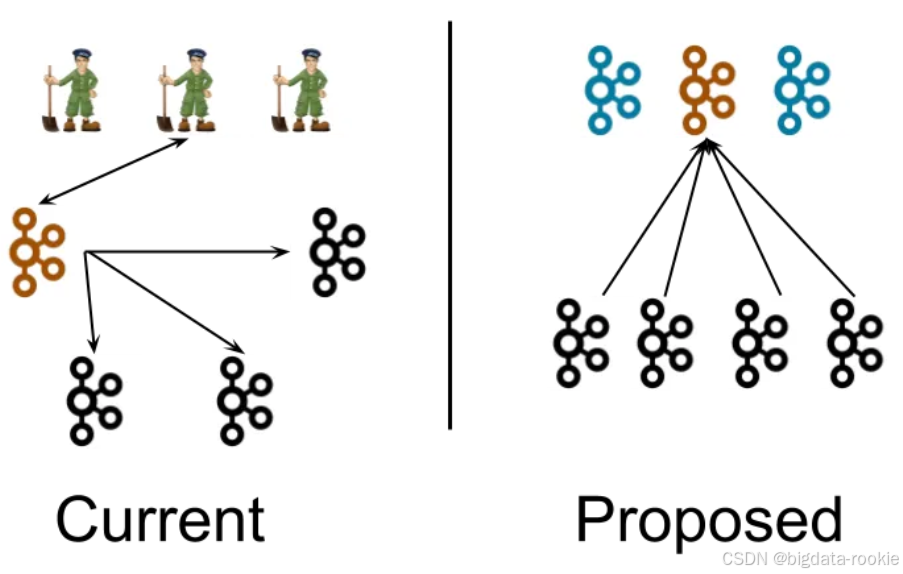
在 KRaft 模式下:
- 运维部署:3 个 Controller 节点;0~N 个 Broker 节点。Kafka 节点可以同时承担 Controller 和 Broker 两个角色,因此一套最小生产集群只需要 3 个节点。在测试环境更可以只以 1 节点模式就轻量地拉起一个 Kafka 集群。
- 通信协调:Controller 节点底层通过 Raft 协议达成一致,Controller 的内存状态通过 #replay Raft Log 来构建,因此 Controller 之间的内存状态都是一致的;Broker 通过订阅 KRaft Log 来维护和 Controller 一致的内存状态,并通过事件驱动的方式执行 Partition Reassignment 之类的操作来实现集群最终一致性协调。整个集群的状态维护和一致性协调都是基于 KRaft 中的事件。
二、KRaft 的核心原理
KRaft 模式利用 Raft 共识算法来管理集群元数据。Raft 是一种分布式一致性算法,通过选举 Leader 和日志复制机制确保集群状态的一致性。
2.1 角色划分
- Controller 节点:所有的 Controller 节点共同组成一个 Raft 仲裁组。
- Broker 节点:负责存储和传输数据。
2.2 Raft仲裁组
- Raft 组中会选举出一个 Active Controller(Leader),其他 Controller 作为 Follower。
- 所有元数据的变更都必须由 Active Controller 发起,并复制到 Follower Controller,达成多数派确认后才会提交。这确保了元数据的一致性。
2.3 元数据日志
- KRaft 模式将集群的元数据变化作为一种特殊的 内部日志(_cluster_metadata)进行存储和复制。
- 这个日志记录了所有元数据的变更历史,类似于 Zookeeper 的 ZNode。通过重发这个日志,任何节点都可以重建出完整的元数据状态。
2.4 工作流程
- 当一个管理员创建一个新主题时,请求会发送到某个 Broker。
- 该 Broker 将请求转发给 Active Controller。
- Active Controller 将“创建主题”这个操作作为一条记录追加到元数据日志中。
- 一旦这条记录被 Reft 仲裁组中的多数派确认并提交,Active Controller 就会更新其内存中的元数据缓存,并将更新通知给所有相关的 Broker。
- 所有 Broker 随后更新自己的元数据缓存,新主题就创建成功了。