wordpress博客站点wordpress连数据库很慢
文章:ECIR 2025会议
一、动机
背景:利用LLMs强大的能力,将一个查询(query)和一组候选段落作为输入,整体考虑这些段落的相关性,并对它们进行排序。
先前的研究基础上进行扩展 [14,15],这些研究使用 RankGPT 作为教师模型,将排序结果蒸馏到 listwise 学生重排序模型中。其中一个代表性模型是 RankZephyr [15],它在排序效果上缩小了与 GPT-4 的差距,甚至在某些情况下超过了这个闭源的教师模型。
大型语言模型(LLMs)推动了listwise重排序研究的发展,并取得了令人印象深刻的最先进成果。然而,这些模型庞大的参数数量和有限的上下文长度限制了其在重排序任务中的效率。
二、解决方法
LiT5模型架构:
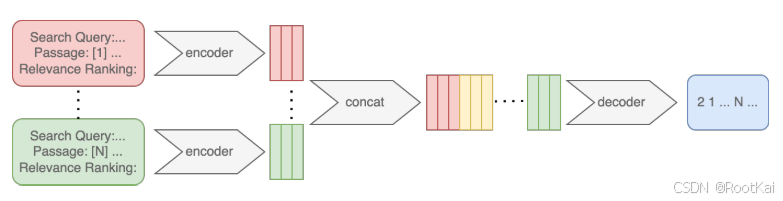
模型遵循 FiD 架构,编码器会将每个段落与查询(query)逐对分别编码。对于每个查询–段落对,输入提示(prompt)的格式如下:
-
以 Search Query: 开头,接着是查询内容;
-
然后是 Passage:,后面带有一个唯一的编号(例如 [1]、[2]);
-
最后是该段落的文本;
-
提示的结尾是 Relevance Ranking:,用于引导模型生成排序结果。
解码器随后会对所有段落的编码表示进行处理,根据与查询的相关性,生成一个按编号排序的结果(从最相关到最不相关),例如:“3 1 2 ...”。
LiT5 模型的设计和创新,它通过采用 RankZephyr 作为教师模型,利用 FiD 架构 和 蒸馏技术,有效地训练了一个能够处理更多段落(最多100个段落)的高效排序模型,突破了传统模型在处理段落数量上的限制,并且能够节省计算成本。
三、训练模型
数据集:
MS MARCO v1 passage ranking 数据集中随机抽取了 20K 个查询,对于每个查询,我们从 MS MARCO v1 和 v2 数据集中各自检索了 100 个段落。
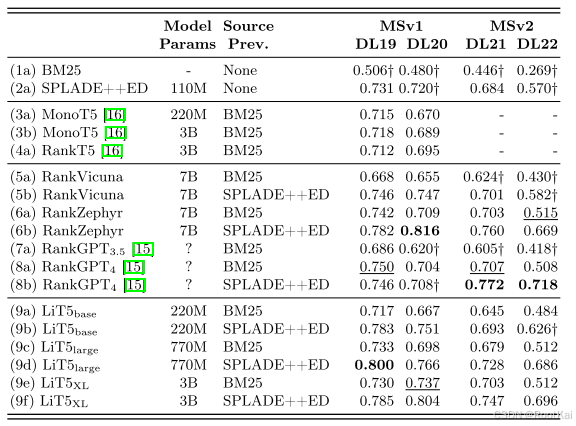
实验结果: