模型推理如何利用非前缀缓存
背景知识
大模型推理阶段
transformer
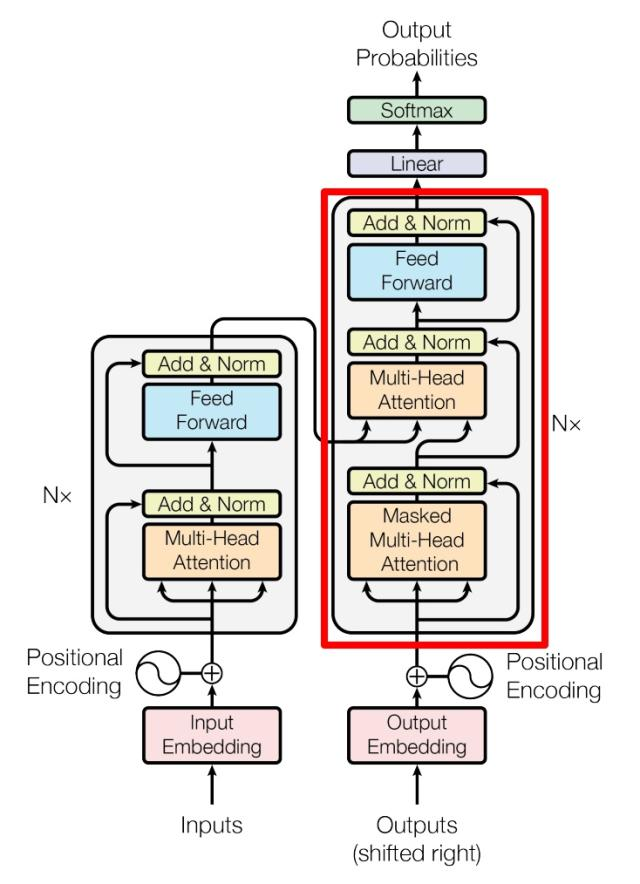
先看下transformer架构图,来了解到大模型推理在该架构的大概定位
![[图片]](https://i-blog.csdnimg.cn/direct/4753ef3f3db1464eb3543ca70c64d857.png)
该图的左侧,我们可以这样来理解他的作用:为了让模型能够更好的了解prompt(即对于模型来说,prompt的语义怎么能更好的表示)
该图的右侧,就是模型推理阶段,该阶段每次产生token的类型是自回归生成的,即模型生成一个token会基于输入prompt的tokens 和 已生成的tokens来推理出一个新的token
由此我们知道了,该transformer架构图的右侧,是大模型推理阶段
推理流程
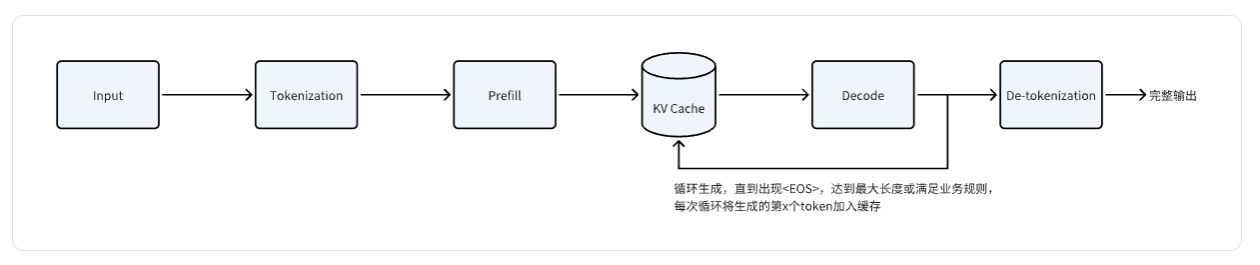
- Input:用户输入的prompt(文本)
- Tokenization:将文本转换为模型可处理的token
- Prefill:一次性处理所有输入token,计算每个token KV,并存入KV Cache中(注意:这一步利用GPU并行性来加速计算过程)
- KV Cache:空间换时间的思想,通过缓存每个token的kv(transformer注意力机制的中间结果),来避免重复计算,从而节省时间
- Decode:逐一生成新的token,每次用当前的tokens(历史tokens + 已生成)来预测下一个token,同时将新的token的kv加入缓存中(供下一轮用),一直循环,直到满足停止条件(生成 或 达到长度限制)
- De-tokenization:将生成的token序列转换为人类可读的文本
至此,我们知道了模型推理的大概流程。此外,由于我们的主题是和KV Cache有关的,所以在这里我们需要先详细了解一下KV Cache(由于KV Cache是用于加速自注意力机制的计算,所以会结合自注意力机制计算来讲)
自注意力机制 & KV Cache & 前缀缓存
自注意力机制
在注意力机制计算之前,我们要先得到该token的q、k、v
![[图片]](https://i-blog.csdnimg.cn/direct/6a9505c5080c4504bdff1ba7792ceb9a.png)
以上的
- X代表该token经过位置编码后的词嵌入向量
- W_Q、W_K、W_V,是模型在训练过程中学到的参数矩阵,它们决定了如何通过X得到QKV
- Q、K、V:
- Q代表:代表当前 token 在“提问”时所关注的信息,它会去匹配所有历史 token 的 Key,寻找与自己最相关的内容。可以理解为:“我现在在想什么?我需要哪些上下文来帮助我?”
- K代表:代表每个已生成 token 对自身内容的“摘要”或“索引”。
- V代表:代表每个 token 所承载的实际语义信息,当 Query 找到匹配的 Key 后,就会从对应的 Value 中提取内容,作为最终输出的一部分。可以理解为:“我不仅告诉你‘我在’,还告诉你‘我是什么意思’。”
至此,我们知道了一个token的Q、K、V三个矩阵是如何得到的,接下来,我们来看,这三个矩阵是如何在自注意力机制中发挥自身作用的。
![[图片]](https://i-blog.csdnimg.cn/direct/67e50ad1623b4f4fab7de9732d2c891e.png)
上图是自注意力机制的计算的主要逻辑:
我们从Score这行开始看(对于score之前行,就是得到每个token的Q、K、V):
q1 . k1、q2 . k2:这个就是该token的q,需要 去和所有历史token的k做匹配,得到该token与历史token的相似度,也可以这样理解。首先,Q 代表当前 token 在当前上下文中的“信息需求”,然后它通过匹配历史 token 的 Key,来决定从对应的 Value 中提取多少语义内容,从而完成上下文感知的表示更新。
Divide by (d_k) ^1/2:缩放点积,避免softmax梯度接近0
softmax函数:
![[图片]](https://i-blog.csdnimg.cn/direct/e070223b9dec4ee39276ce91b39298e7.png)
当输入x_i时候,todo
softmax(归一化):将每个token的相似度,变成概率
softmax*value:有了概率列表,就对历史token的v,加权求和
z:这个就是我们的注意力的结果啦,注意它是一个融合了上下文信息的新表示
此处,小插曲,为什么要用点积计算呢?(todo)
KV Cache
至此,我们知道了一个token的qkv是如何产生的,也知道了qkv在自注意力机制中发挥了重要作用,经过自注意力机制的计算,使每个token都有一个融合上下文信息的新的表示,现在我们来思考一下,以上步骤有可优化之处吗?
我们通过详细看下注意力机制计算的公式找出优化点:
当模型生成第一个“遥”字时,input=“”, ""是起始字符。Attention的计算如下:
![[图片]](https://i-blog.csdnimg.cn/direct/517283bb76994ba5b1941327163a042b.png)
Attention的计算公式如下:
![[图片]](https://i-blog.csdnimg.cn/direct/b1b9497558614e1bbf14fcbb1ca32e94.png)
当模型生成第二个“遥”字时,input=“遥”, Attention的计算如下:
![[图片]](https://i-blog.csdnimg.cn/direct/c532485047794d0daf5022f1acda408c.png)
Attention的计算公式如下:

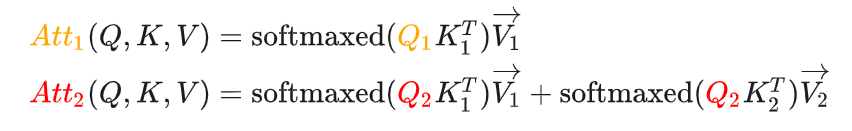
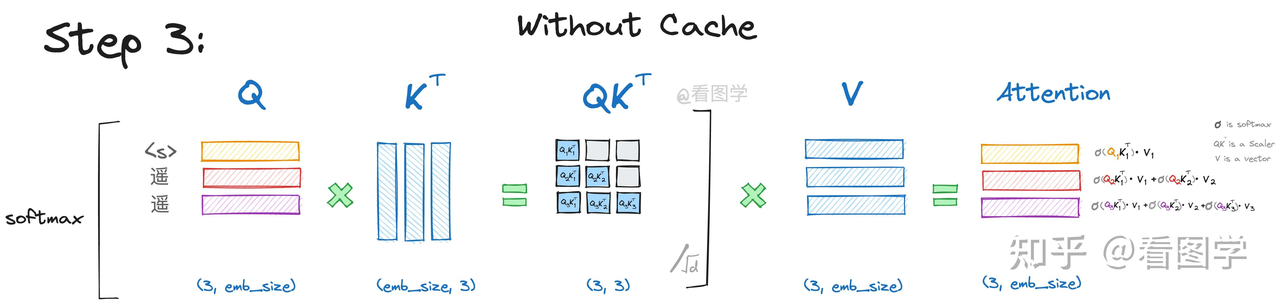
当模型生成第三个“领”字时,input="遥遥"Attention的计算如下:
Attention的计算公式如下:
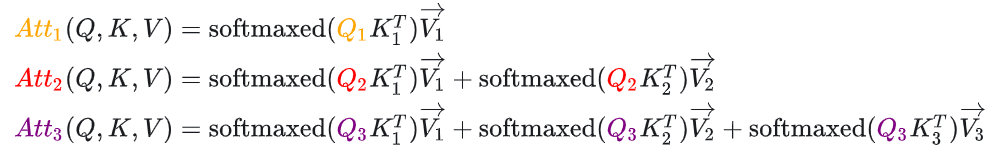
我们发现,当生成一个新toke时,历史token的k,v也是要参与的,那么我们想要用历史token的k、v,每次用它们时候都要算出来吗?所以我们可以用空间换时间的思想,将历史token的k、v存起来,我们需要用的时候直接取就行,这样一来,矩阵相乘的次数就少了,那么整体推理时间也会降低,那么这就是KV Cache
因此,我们可以选择缓存历史token的kv,如下图:
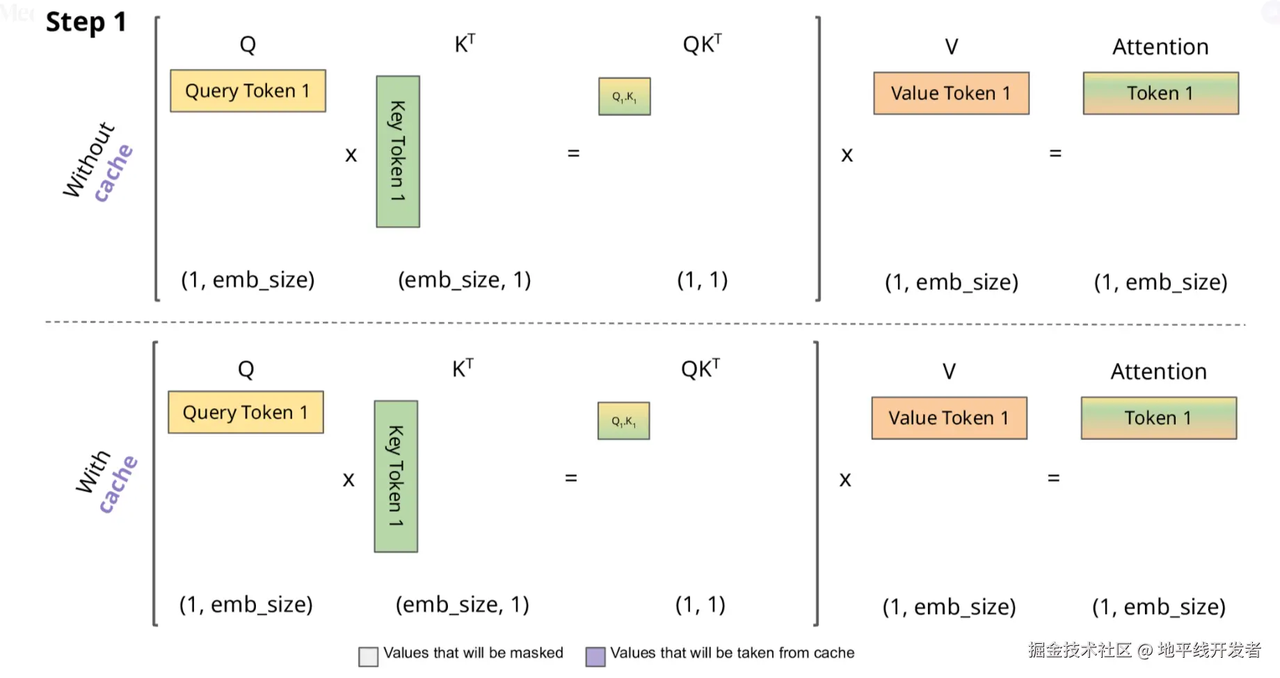
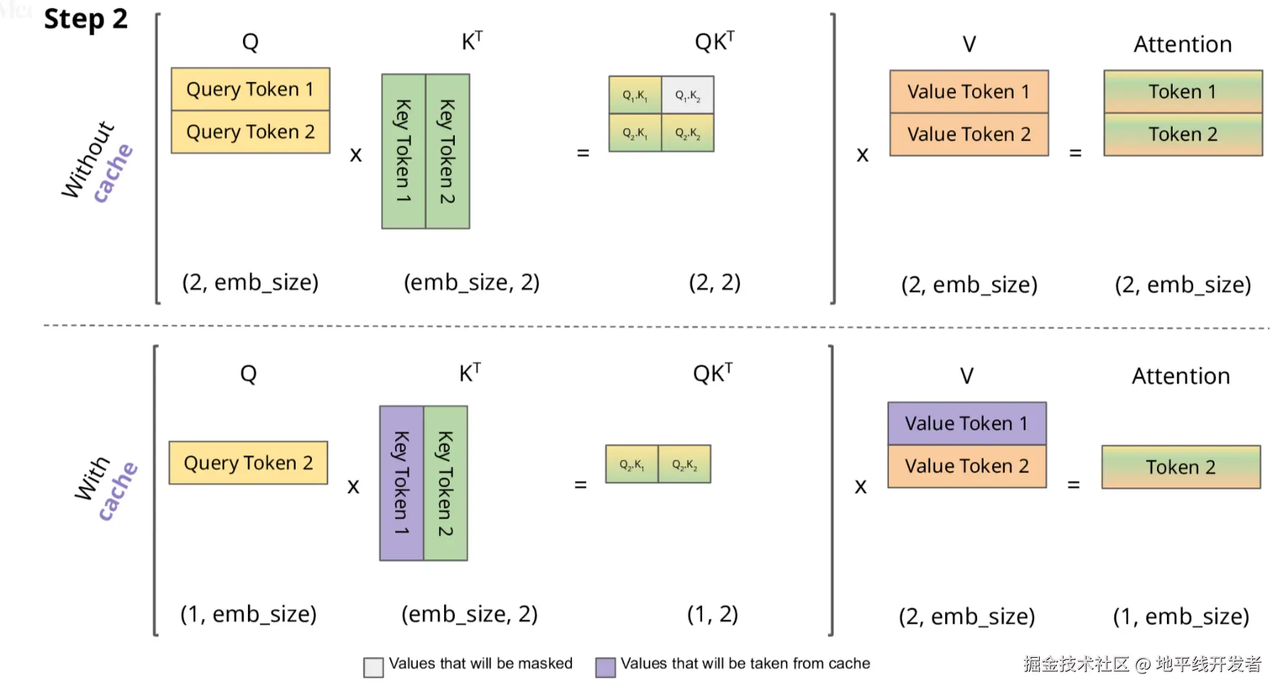
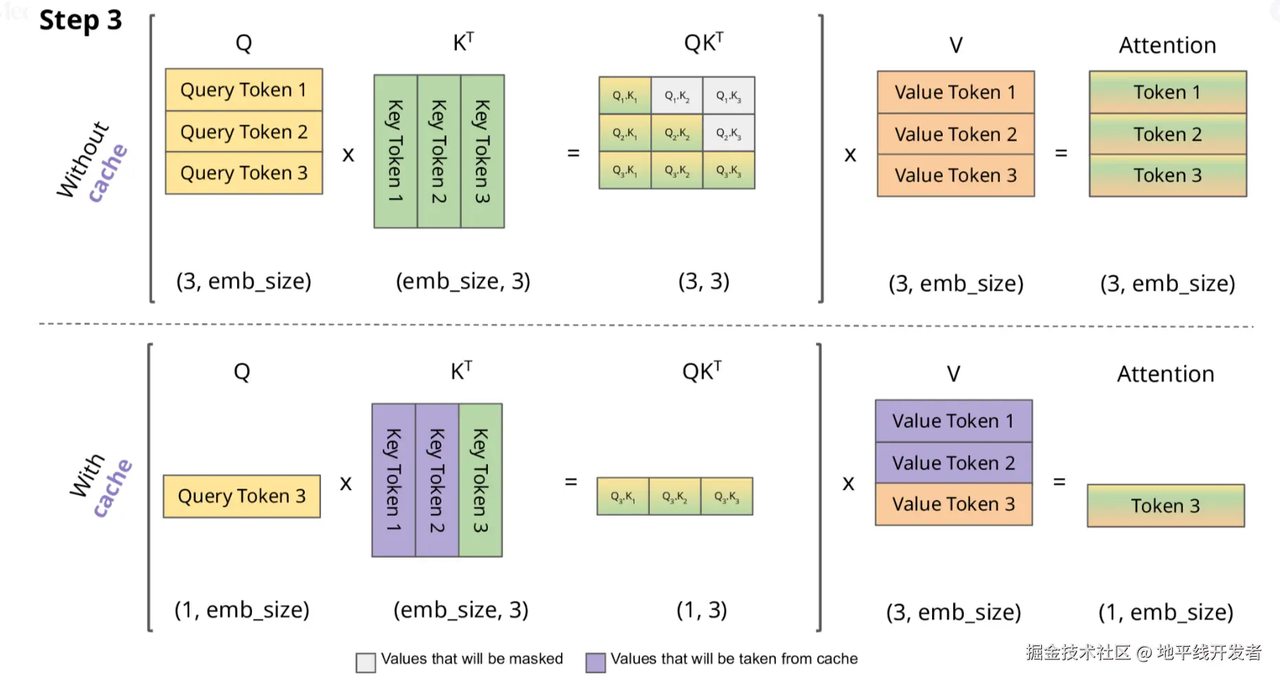
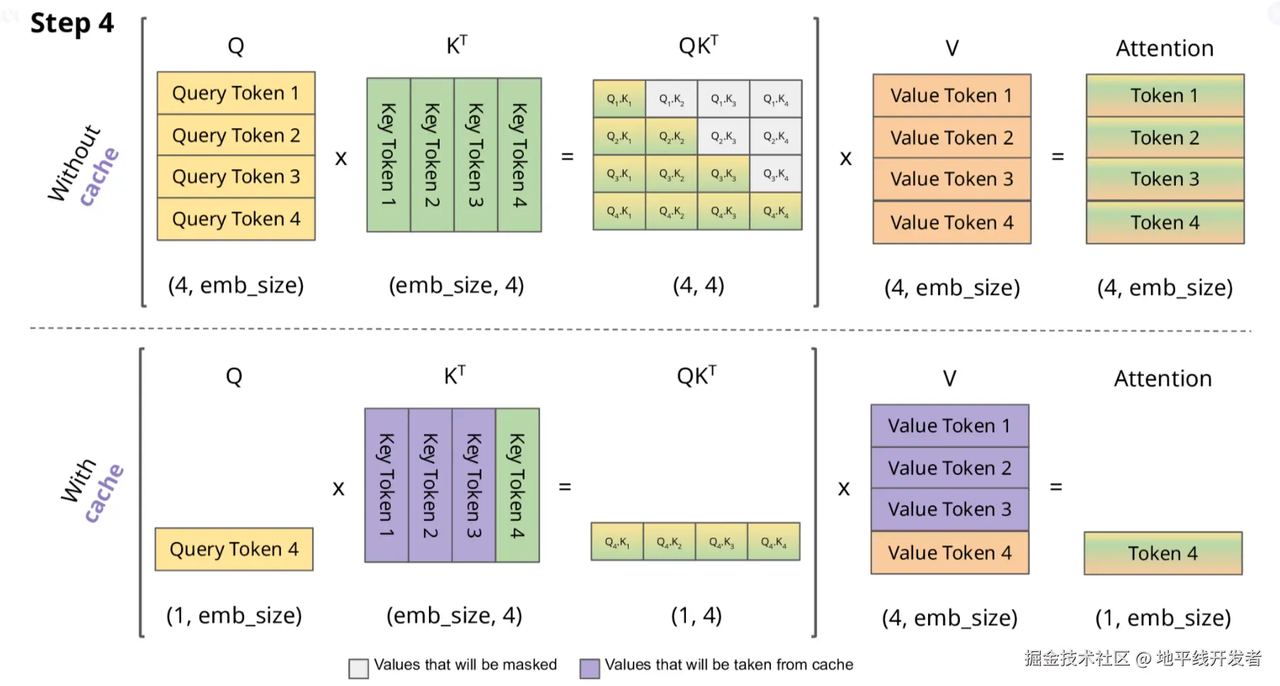
至此,我们知道了一个token的qkv是如何产生的,也知道了各token的qkv通过参与自注意力机制的计算,使每个token都有一个融合上下文信息的新的表示,以及加速注意力机制计算的KV Cache
前缀缓存
为避免重复计算token的kv,所以在 prefill 阶段主要作用就是给迭代的生成阶段准备 KV Cache。但这些 KV Cache 仅仅是为单次生成式请求服务的,那很自然的一种想法就是,KV Cache 能不能跨请求复用?
在某些场景下,多次请求的 Prompt 可能会共享同一个前缀(Prefix),比如system prompt,这种情况下,请求的前缀的 KV Cache 计算的结果是相同的,所以可以被缓存起来,给下一个请求复用。
但 KV Cache 跟其它服务缓存不一样的地方是,它太大了,以至于(目前)很难通过 Redis/Memcache 这种分布式缓存服务存取。比如对 13B LLM 模型来说,在 FP16 精度下单 token 的 KV Cache 大约是 1MB,假设要缓存的前缀有 500 个 token(大约800多个汉字),那就是 500MB。一般来说,我们不会每次请求去从分布式系统里读取/传输 500MB 的缓存,甚至都不会每次请求从内存往显存中拷贝 500MB 的缓存,所以大部分情况下,prefix cache 都会放在显存里。
这也就意味着,如果你想命中 prefix cache,必须把相同 prefix 的请求发到同一张 GPU卡上才行。
具体实现
以sglang中的实现介绍
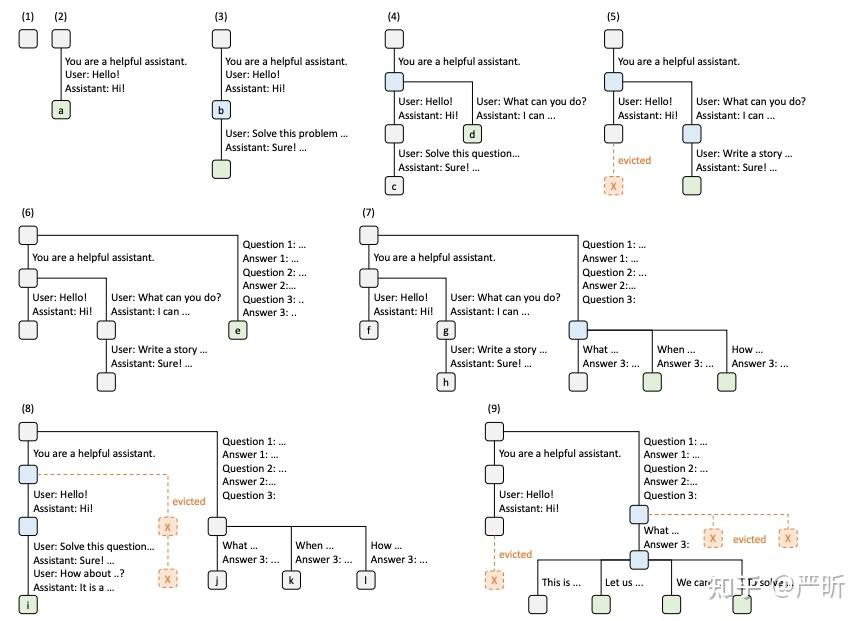
- 在每次请求结束后,这次请求里的KV Cache不直接丢弃,而是借由RadixAttention算法将KV Cache仍然保留在GPU的显存中。RadixAttention算法还将序列token到KV Cache的映射关系,保存在RadixTree这种数据结构中。
- 当一个新的请求到来的时候,SGLang的调度器通过RadixTree做前缀匹配,查找新的请求是否命中缓存。如果命中了缓存,SGLang的调度器会复用KV Cache来完成这次请求。
- 由于GPU的显存是非常有限的,缓存在内存中的KV Cache不能永久被保留,需要设计相应的逐出策略。RadixAttention引入的逐出策略是LRU(least recently used)
此时,我们知道了用前缀缓存可以加速推理,那非前缀可以吗?我们先来分析一下:
第一层 KV 的生成公式
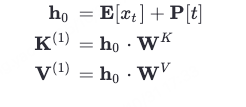
h是词嵌入 + 位置编码;k是该token的k,v是该token的v
注意:这一步是纯局部的,每个 token 独立计算自己的 QKV,不与其他 token 交互,因此,第一层的 K 和 V 完全由 (token ID, 位置 t) 决定。
自注意力机制计算
自注意力机制大概过程:当前 token 的 q 会 与所有已生成 token(包括自己)的 k 矩阵相乘计算,再经过softmax得到多个系数,再用这些系数对所有已生成的v加权求和,最终得到注意力分数。
自注意力机制是 Transformer 的核心,但单层自注意力只能捕捉 “扁平的关联”,无法处理语言中的复杂依赖。
- 每一层都对前一层的输出进行非线性变换 + 上下文整合
- 信息被逐步提炼:
- Layer 1: 词性、局部语法
- Layer 5: 句法结构、依存关系
- Layer 10: 语义角色、意图理解
- Layer 20+: 世界知识、逻辑推理
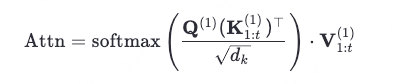
第一层的自注意力机制计算后,得到h1(可以理解为 对于第二层来说,未变化成k、v的一个矩阵)。
第二层的自注意力机制的k 和 v是有h1 分别和 w_k 和 w_v矩阵得来,但此时的kv是已经有上下文信息的了!
第三层,类推…
所以,即使两个徐请求中,即使相同(词嵌入 + 位置编码都相同)的token也不能利用kv cache,因为会有注意力缺失问题。
那么我们有办法利用非前缀缓存吗?来看Cache blend技术
CacheBlend
…todo