选对模型、搭好架构:企业如何构建高精准RAG知识库
一、引言
在当今企业数字化转型的浪潮中,大型语言模型(LLM)技术的快速发展为企业知识管理和智能交互带来了前所未有的机遇。检索增强生成(Retrieval-Augmented Generation, RAG)技术作为连接企业知识库与大语言模型的桥梁,能够有效解决LLM知识时效性差、幻觉问题和领域知识不足等局限。而在RAG系统中,Embedding嵌入模型的选择直接决定了检索的准确性,也间接影响了大模型输出的可信度。
本文将为企业技术团队提供全面的RAG知识库搭建参考,重点探讨Embedding模型的选型策略,并结合Spring AI等主流技术栈,提供从概念到实践的完整解决方案。
二、基础知识
2.1 RAG技术概述
检索增强生成(RAG)是一种结合了检索和生成的技术,通过在生成前检索相关外部知识,增强LLM的输出质量和准确性。RAG技术主要解决了LLM的以下局限性:
- 知识时效性问题:LLM训练数据存在时间窗口限制,无法获取最新信息
- 幻觉问题:模型可能生成看似合理但事实上不准确的内容
- 领域知识不足:通用LLM在特定专业领域的知识深度有限
- 可解释性差:难以追溯模型回答的知识来源
2.2 为什么需要嵌入模型
计算机本质上只能处理数字运算,无法直接理解自然语言、文字、图片、音频等非数值形式的数据。因此,我们需要通过"向量化"操作,将这些数据转化为计算机可以理解和处理的数值形式,即映射为数学上的向量表示。这一过程通常借助嵌入模型(Embedding Model)来实现,它可以有效地捕捉数据中的语义信息和内在结构。
嵌入模型的作用在于,它不仅能够将离散的数据(如单词、图像片段或音频片段)转换为连续的低维向量,还能在向量空间中保留数据之间的语义关系。例如,在自然语言处理中,嵌入模型可以生成词向量,使得语义相似的单词在向量空间中距离更近。这种高效的表示方式使计算机能够基于这些向量进行复杂的计算与分析,从而更好地理解与处理文本、图像或声音等复杂数据。
通过嵌入模型的向量化操作,计算机不仅可以高效地处理大规模数据,还能在各种任务中(如分类、检索、生成等)展现出更强的性能和泛化能力。
三、Embedding模型原理与评测
3.1 嵌入模型工作原理
Embedding模型通常基于预训练的语言模型架构(如Transformer),通过以下步骤将文本转换为向量:
- 文本预处理:对输入文本进行分词、清理和规范化处理
- 特征提取:通过多层神经网络提取文本的语义特征
- 向量生成:将高维特征压缩到固定维度的向量空间
- 相似度计算:使用余弦相似度等度量方法计算向量间的语义关联度
3.2 嵌入模型评测标准
要判断一个嵌入模型的好坏,必须有一套明确的标准。通常使用MTEB和C-MTEB进行基准测试。
3.2.1 MTEB
Huggingface的MTEB(Massive Multilingual Text Embedding Benchmark)评测标准是业界比较公认的标准,可以作为参考。它涵盖了8个嵌入任务,共58个数据集和112种语言,是目前迄今为止最全面的文本嵌入基准。
- 排行榜:https://huggingface.co/spaces/mteb/leaderboard
- GitHub地址:https://github.com/embeddings-benchmark/mteb
3.2.2 C-MTEB
C-MTEB是当前最全面的中文语义向量评测基准,涵盖6大类评测任务(检索、排序、句子相似度、推理、分类、聚类)和35个数据集。
- C-MTEB论文:https://arxiv.org/abs/2309.07597
- 代码和排行榜:https://github.com/FlagOpen/FlagEmbedding/tree/master/research/C_MTEB
四、主流Embedding模型特性对比
4.1 模型概览
企业在搭建RAG知识库时,常用的Embedding模型包括:bge、m3e、nomic-embed-text、BCEmbedding(网易有道)等。以下是这些模型的详细特性对比:
| 模型名称 | 开发者 | 向量维度 | 多语言支持 | 特点 | 适用场景 |
|---|---|---|---|---|---|
| BGE-M3 | 北京智源人工智能研究院(BAAI) | 1024/2048/3072 | 支持100+语言 | 多功能、多粒度、混合检索能力 | 企业级多语言知识库、复杂语义检索 |
| BGE-Base | 北京智源人工智能研究院(BAAI) | 768 | 支持多语言 | 平衡性能和效率 | 一般企业应用、中等规模知识库 |
| M3E | 智谱AI | 768 | 优化中文 | 中文语义理解优秀 | 中文为主的企业知识库 |
| nomic-embed-text | Nomic AI | 768 | 多语言 | 开源可商用、语义理解强 | 注重合规性的企业应用 |
| BCEmbedding | 网易有道 | 768 | 优化中文 | 稳定性好、中文场景优化 | 中文企业应用、客服知识库 |
4.2 BGE系列模型详解
BGE(BAAI General Embedding)系列模型由北京智源人工智能研究院开发,是当前性能最优秀的开源嵌入模型之一。
4.2.1 BGE-M3
BGE-M3是BGE系列的最新版本,可以说是当前文本转向量模型中的佼佼者。
主要特点:
- 支持混合检索(密集向量+稀疏向量)
- 多粒度嵌入(词、句子、段落级)
- 多语言支持(100+种语言)
- 长文本处理能力强
- 开源权重及完整技术栈(微调、知识蒸馏等)
性能优势:
- 在MTEB和C-MTEB评测中表现优异
- 对完全相同查询的相似度计算准确(相比早期版本)
- 语义理解能力强,检索准确率高
4.2.2 BGE-Base
BGE-Base是BGE系列的基础版本,提供了良好的性能和效率平衡。
主要特点:
- 768维向量表示
- 适合中等规模知识库应用
- 推理速度较快,资源消耗适中
4.3 M3E模型详解
M3E(Moka Massive Mixed Embedding)是由智谱AI开发的中文优化嵌入模型。
主要特点:
- 专为中文场景优化
- 768维向量表示
- 中文语义理解能力强
- 开源可商用
4.4 nomic-embed-text模型详解
nomic-embed-text是由Nomic AI开发的开源嵌入模型。
主要特点:
- 完全开源可商用
- 768维向量表示
- 多语言支持
- 语义理解能力强
4.5 BCEmbedding模型详解
BCEmbedding是由网易有道开发的企业级嵌入模型。
主要特点:
- 中文场景优化
- 768维向量表示
- 企业级稳定性保障
- 技术支持完善
五、企业RAG知识库架构设计
5.1 系统架构概述
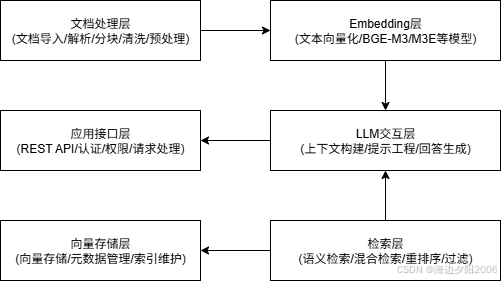
系统分层说明:
- 文档处理层:负责文档的导入、解析、分块等预处理工作
- Embedding层:使用选定的嵌入模型将文本转换为向量
- 向量存储层:存储文档向量和元数据,支持高效检索
- 检索层:实现语义检索、混合检索等功能
- LLM交互层:与大语言模型交互,生成回答
- 应用接口层:提供API接口供业务系统调用
5.2 系统核心组件
企业级RAG知识库系统的典型架构包括以下核心组件:
5.2.1 文档处理层
核心功能 :负责企业各类文档的全生命周期处理
主要组件 :
- 文档导入器:支持PDF、Word、Excel、TXT等多种格式
- 文档解析器:提取结构化和非结构化内容
- 文本分块器:智能分块策略(段落、语义、混合)
- 文本清洗器:去噪、格式标准化
- 元数据提取器:提取文档属性、元信息
5.2.2 Embedding层
核心功能 :将文本转换为向量表示
主要组件 :
- EmbeddingClient:Spring AI抽象接口
- 模型适配器:支持BGE-M3、M3E、nomic-embed-text、BCEmbedding
- 批量处理引擎:提高向量化效率
- 向量缓存:减少重复计算
- 质量评估器:向量质量监测
5.2.3 向量存储层
核心功能:高效存储和管理向量数据
主要组件:
- 向量数据库:PostgreSQL+pgvector或专业向量数据库
- 索引管理器:HNSW、IVFFlat等索引类型管理
- 元数据存储:文档元数据管理
- 数据分区管理器:冷热数据分离
- 备份恢复组件:数据安全保障
5.2.4 检索层
核心功能:精准高效地检索相关文档
主要组件:
- 语义检索引擎:基于向量相似度
- 混合检索引擎:结合关键词和语义检索
- 重排序模型:优化检索结果质量
- 过滤器:基于元数据的筛选
- 相关性评估器:检索结果质量监控
5.2.5 LLM交互层
核心功能:与大语言模型交互生成回答
主要组件:
- 上下文构建器:优化上下文组织
- 提示工程师:动态提示模板管理
- LLM客户端:支持多种大语言模型
- 回答生成器:多轮对话管理
- 引用生成器:溯源信息管理
5.2.6 应用接口层
核心功能:提供标准化API接口
主要组件 :
- REST API接口:标准化请求响应
- 认证授权:JWT、OAuth2等安全机制
- 流量控制:限流、熔断、降级
- 日志监控:请求日志、性能指标
- 文档管理API:知识库维护接口
5.3 核心组件选择
5.3.1 向量数据库选择
企业在选择向量数据库时,需要考虑以下因素:
- 性能:查询速度、吞吐量、并发支持
- 扩展性:水平扩展能力、数据量增长支持
- 功能:过滤条件、混合检索、索引类型
- 集成性:与现有系统的集成便捷性
- 运维复杂度:部署、监控、维护难度
- 成本:许可费用、资源消耗
常用向量数据库对比:
| 向量数据库 | 类型 | 主要特点 | 适用场景 |
|---|---|---|---|
| PostgreSQL+pgvector | 关系型+向量扩展 | 无缝集成、事务支持、成熟生态 | 已有PostgreSQL部署、需要关系型功能 |
| Pinecone | 托管服务 | 易用性高、性能优秀、全托管 | 快速上线、减少运维成本 |
| Milvus | 开源分布式 | 高扩展性、多模态支持、丰富索引 | 大规模向量数据、需要定制化部署 |
| Qdrant | 开源 | 过滤能力强、支持有效负载存储 | 需要复杂过滤条件的场景 |
| Weaviate | 开源 | GraphQL接口、自动分类 | 语义搜索、知识图谱构建 |
5.3.2 文档处理组件
企业知识库通常需要处理多种格式的文档,包括PDF、Word、Excel、PPT、Markdown、HTML等。常用的文档处理组件包括:
- Apache Tika:强大的文档解析工具,支持多种格式
- Apache PDFBox:专注于PDF文档处理
- Poi:Microsoft Office文档处理
- Unstructured:AI驱动的文档解析,支持复杂布局理解
5.3.3 文件存储方案
对于企业级应用,需要考虑可靠的文件存储方案:
- 本地文件系统:简单直接,但扩展受限
- 对象存储:如AWS S3、阿里云OSS、MinIO等,适合大规模文件存储
- 分布式文件系统:如HDFS,适合超大规模数据
六、Spring AI实战应用
6.1 Spring AI概述
Spring AI是Spring生态系统中用于人工智能应用开发的框架,提供了与各种AI模型和服务的集成能力,包括Embedding、LLM、向量存储等。使用Spring AI可以快速构建企业级RAG应用。
6.2 Spring AI + PostgreSQL + pgvector集成
6.2.1 环境准备
1. 安装PostgreSQL和pgvector扩展
# 安装PostgreSQL
sudo apt-get install postgresql# 安装pgvector扩展
sudo apt-get install postgresql-14-pgvector2. 启用pgvector扩展
CREATE EXTENSION IF NOT EXISTS vector;6.2.2 项目依赖配置
在pom.xml中添加Spring AI相关依赖:
<dependencies><!-- Spring Boot基础 --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency> <!-- PostgreSQL驱动 --><dependency><groupId>org.postgresql</groupId><artifactId>postgresql</artifactId></dependency> <!-- Spring Data JPA --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-jpa</artifactId></dependency> <!-- Spring AI Core --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-core</artifactId><version>0.8.1</version></dependency> <!-- Spring AI Embedding支持 --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai</artifactId><version>0.8.1</version></dependency> <!-- Spring AI Vector Store --><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-pgvector-store</artifactId><version>0.8.1</version></dependency>
</dependencies>6.2.3 配置文件设置
在application.properties中配置数据库和AI模型信息:
# 数据库配置
spring.datasource.url=jdbc:postgresql://localhost:5432/rag_knowledge_base
spring.datasource.username=postgres
spring.datasource.password=password
spring.jpa.hibernate.ddl-auto=update# OpenAI API配置(如需使用OpenAI的Embedding服务)
spring.ai.openai.api-key=your-api-key# 自定义Embedding模型配置(如使用本地部署的模型)
spring.ai.embedding.model=text-embedding-ada-002
spring.ai.embedding.dimensions=15366.2.4 实体类定义
创建用于存储文档向量的实体类:
import jakarta.persistence.*;
import org.springframework.ai.document.Document;@Entity
@Table(name = "document_embeddings")
public class DocumentEntity { @Id@GeneratedValue(strategy = GenerationType.UUID)private String id; private String content; @Column(name = "vector", columnDefinition = "vector(1536)")private float[] vector; @Column(columnDefinition = "jsonb")private String metadata; // getter和setter方法 public static DocumentEntity fromDocument(Document document, float[] embedding) {DocumentEntity entity = new DocumentEntity();entity.setId(document.getId());entity.setContent(document.getContent());entity.setVector(embedding);entity.setMetadata(new bjectMapper().writeValueAsString(document.getMetadata()));return entity;} public Document toDocument() {Document document = new Document(content, new HashMap<>());document.setId(id);try {document.setMetadata(new ObjectMapper().readValue(metadata, Map.class));} catch (JsonProcessingException e) {// 处理异常}return document;}
}6.2.5 Repository接口
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;import java.util.List;public interface DocumentRepository extends JpaRepository<DocumentEntity, String> {@Query(value = "SELECT d.*, d.vector <=> :embedding AS similarity " +"FROM document_embeddings d " +"ORDER BY similarity ASC " +"LIMIT :limit", nativeQuery = true)List<DocumentEntity> findSimilarDocuments(@Param("embedding") float[] embedding, @Param("limit") int limit);
}6.2.6 服务层实现
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.List;
import java.util.stream.Collectors;@Service
public class RAGService { @Autowiredprivate EmbeddingClient embeddingClient; @Autowiredprivate VectorStore vectorStore; // 添加文档到知识库public void addDocument(Document document) {vectorStore.add(List.of(document));}// 批量添加文档public void addDocuments(List<Document> documents) {vectorStore.add(documents);} // 相似文档检索public List<Document> retrieveSimilarDocuments(String query, int topK) {return vectorStore.similaritySearch(query, topK);} // 检索增强生成public String ragGenerate(String query, int topK) {// 1. 检索相似文档List<Document> similarDocs = retrieveSimilarDocuments(query, topK); // 2. 构建增强提示StringBuilder prompt = new StringBuilder();prompt.append("请基于以下信息回答问题:\n\n"); for (Document doc : similarDocs) {prompt.append(doc.getContent()).append("\n\n");} prompt.append("问题:").append(query); // 3. 调用LLM生成回答// 这里需要集成具体的LLM服务return llmService.generate(prompt.toString());}
}6.2.7 控制器实现
import org.springframework.ai.document.Document;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import java.util.List;@RestController
@RequestMapping("/api/rag")
public class RAGController { @Autowiredprivate RAGService ragService; @Autowiredprivate DocumentProcessor documentProcessor; // 添加文档@PostMapping("/documents")public ResponseEntity<String> addDocument(@RequestBody String content) {Document document = new Document(content);ragService.addDocument(document);return ResponseEntity.ok("文档添加成功");}// 上传文件@PostMapping("/upload")public ResponseEntity<String> uploadFile(@RequestParam("file") MultipartFile file) {try {List<Document> documents = documentProcessor.processFile(file);ragService.addDocuments(documents);return ResponseEntity.ok("文件处理成功,添加了 " + documents.size() + " 个文档片段");} catch (Exception e) {return ResponseEntity.badRequest().body("文件处理失败:" + e.getMessage());}} // 检索问答@GetMapping("/query")public ResponseEntity<String> query(@RequestParam String question,@RequestParam(defaultValue = "3") int topK) {String answer = ragService.ragGenerate(question, topK);return ResponseEntity.ok(answer);}
}6.3 自定义Embedding模型集成
企业在实际应用中,可能需要集成自定义的Embedding模型(如BGE-M3、M3E等开源模型),可以通过实现EmbeddingClient接口来实现:
import org.springframework.ai.embedding.EmbeddingClient;
import org.springframework.ai.embedding.EmbeddingResponse;
import org.springframework.stereotype.Component;import java.util.List;
import java.util.concurrent.CompletableFuture;@Component
public class CustomEmbeddingClient implements EmbeddingClient { private final EmbeddingModelClient modelClient; public CustomEmbeddingClient(EmbeddingModelClient modelClient) {this.modelClient = modelClient;} @Overridepublic List<Double> embed(String text) {return modelClient.encode(text);}@Overridepublic List<List<Double>> embed(List<String> texts) {return texts.stream().map(this::embed).collect(Collectors.toList());} @Overridepublic EmbeddingResponse call(EmbeddingRequest request) {List<List<Double>> embeddings = embed(request.getInputs());// 构建并返回响应return new EmbeddingResponse(/* ... */);}
}七、性能调优与最佳实践
7.1 文档分块优化
文档分块是RAG系统性能的关键因素之一:
1. 分块大小选择:
- 通用知识文档:500-1000 tokens
- 技术文档:300-500 tokens
- 长文本:可采用递归分块法
2. 重叠度设置:
- 推荐重叠度:20%-30%
- 目的:避免语义割裂,保持上下文连贯性
3. 分块策略:
- 基于段落的分块(保留自然语义单元)
- 基于语义的分块(使用NLP技术识别语义边界)
- 混合分块(结合规则和语义分析)
7.2 Embedding模型优化
1. 模型选择建议:
- 中文场景:优先考虑BGE-M3、M3E
- 多语言场景:BGE-M3、nomic-embed-text
- 企业级稳定性要求:BCEmbedding
2. 模型部署优化:
- 使用ONNX、TensorRT等加速框架
- 批量处理请求提高吞吐量
- 缓存常用查询的嵌入结果
3. 向量维度选择:
- 权衡检索精度和存储成本
- 一般推荐:768-1536维
- 高精度要求:2048-3072维
7.3 检索策略优化
1. 混合检索:
- 结合关键词检索(BM25)和语义检索
- 利用BGE-M3等模型的稀疏编码能力
2. 重排序机制:
- 初步检索扩大范围
- 使用精排模型重新排序
3. 检索参数调优:
- 相似度阈值:0.7-0.85(根据场景调整)
- 检索数量:3-10(根据上下文窗口大小调整)
7.4 数据库优化
1. PostgreSQL+pgvector优化:
- 创建适当的索引:HNSW、IVFFlat等
- 设置合适的索引参数(如IVF分区数)
- 优化查询语句和缓存配置
2. 分区策略:
- 按时间、部门等维度分区
- 冷热数据分离存储
3. 资源配置:
- 增加共享缓冲区大小
- 优化工作内存配置
- 配置适当的维护窗口
八、功能扩展点
8.1 多模态支持
企业知识库可以扩展到支持图片、音频、视频等多模态内容:
1. 图片理解:
- 使用CLIP等模型进行图文嵌入
- 支持以文搜图、以图搜图
2. 多模态检索:
- 统一的多模态向量空间
- 跨模态语义理解
8.2 知识图谱集成
将知识图谱与RAG系统结合,提升推理和关联能力:
1. 实体关系提取:
- 从文档中提取实体和关系
- 构建领域知识图谱
2. 图检索增强:
- 结合图数据库查询
- 支持复杂逻辑推理
8.3 增量学习与更新机制
实现知识库的自动更新和模型的持续优化:
1. 增量索引更新:
- 新文档实时加入索引
- 历史文档定期重新处理
2. 用户反馈优化:
- 收集检索结果反馈
- 优化模型和检索参数
九、与AI Agent、MCP的结合应用
9.1 Agent辅助的RAG系统
将RAG技术与智能体(Agent)结合,可以实现更高级的知识应用:
1. 专业领域Agent:
- 构建特定领域的知识Agent
- Agent利用RAG获取最新领域知识
2. 任务型Agent:
- Agent分解复杂任务
- 针对子任务使用RAG检索相关知识
3. 实现示例:
public class KnowledgeAgent {private final RAGService ragService;private final TaskPlanner taskPlanner; public String processTask(String taskDescription) {// 1. 任务分解List<SubTask> subTasks = taskPlanner.decompose(taskDescription); // 2. 针对每个子任务检索知识并执行List<String> results = new ArrayList<>();for (SubTask subTask : subTasks) {String relevantKnowledge = ragService.ragGenerate(subTask.getQuery(), 5);results.add(subTask.execute(relevantKnowledge));} // 3. 整合结果return taskPlanner.integrateResults(results);}
}9.2 MCP(多智能体协作平台)应用
在MCP架构中,RAG系统可以作为知识服务的核心组件:
1. 智能体知识共享:
- 构建中心化知识库
- 多智能体共享知识资源
2. 协作推理增强:
- 智能体间通过RAG共享推理依据
- 基于共同知识进行协作决策
3. 分布式知识管理:
- 各领域知识库独立维护
- MCP协调跨知识库检索
十、总结与展望
企业RAG知识库的搭建是一个系统工程,涉及多方面的技术选择和架构设计。Embedding模型作为检索准确性的关键决定因素,需要根据企业的具体场景需求进行合理选型。BGE-M3作为当前性能领先的开源模型,在多数场景下是较好的选择;对于中文优化场景,可以考虑M3E;对于注重稳定性和技术支持的企业,可以考虑BCEmbedding等商业解决方案。
随着技术的不断发展,我们可以预见:
- 多模态RAG将成为主流,支持更丰富的知识表达形式
- 自适应检索技术将进一步提高检索的准确性和效率
- 领域特化模型将在垂直领域发挥更大价值
- 端到端优化将使RAG系统的整体性能得到质的飞跃
企业在实施RAG项目时,应当从业务需求出发,结合技术可行性,制定合理的实施路径,逐步构建起高效、准确、可扩展的企业知识服务体系。
参考文献
1. MTEB: Massive Multilingual Text Embedding Benchmark
2. C-MTEB: A Comprehensive Multilingual Text Embedding Benchmark for Chinese.
3. BGE: BAAI General Embedding.
4. Spring AI Reference Documentation.
5. pgvector: Open-source vector similarity search for PostgreSQL.