redis 大key、热key优化技巧|空间存储优化|调优技巧(一)
写在前面
自从做C端业务后,就不可避免地和缓存打交道,包括本地缓存和redis。这是一个系列文章,本文举一个用户黑名单的例子讲讲我平时用的redis的数据结构和调优技巧,包括大key和热key的优化。
SET 数据结构
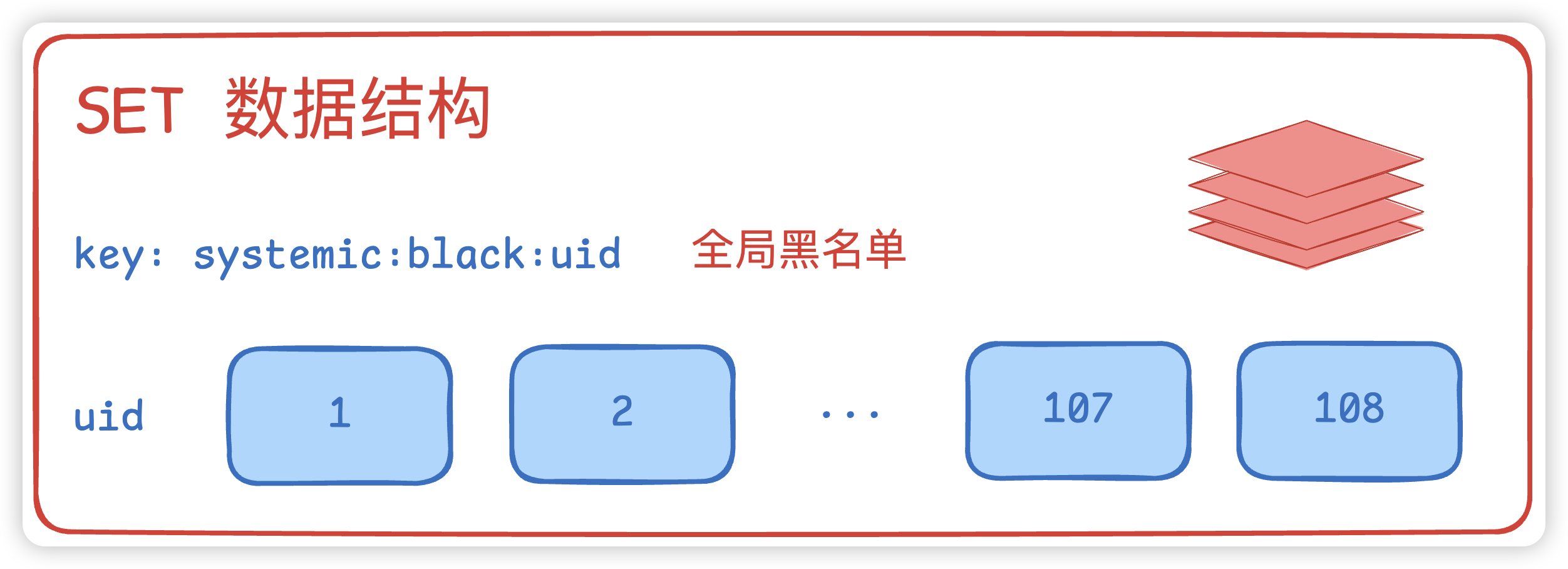
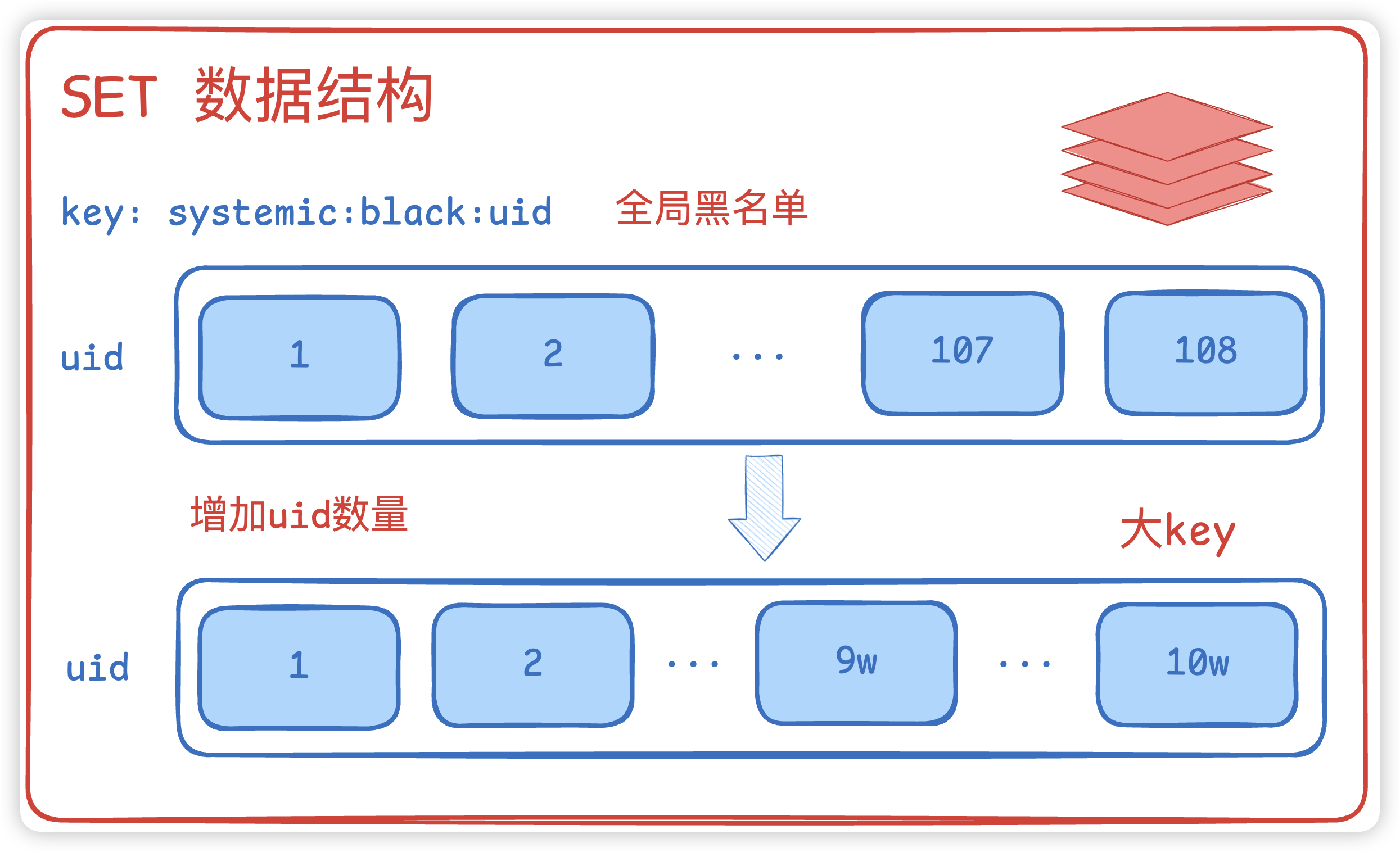
在C端业务中,我们经常会存储一些数据到redis中,比如用户黑名单。相比于LIST数据结构来说,SET 数据结构会更适合,语法操作简单。 假设key为systemic:black:uid,里面存储黑名单的用户uid。
- 去重性 : 自动去除重复元素,保证集合中元素的唯一性。符合要求的用户加入黑名单即可,不需要考虑set中是否已经包含了该用户,
SADD systemic:black:uid 1。 - 高效查找 : O(1) 时间复杂度判断元素是否存在。可以快速查找某个用户是否在这个黑名单中,
SISMEMBER systemic:black:uid 1。
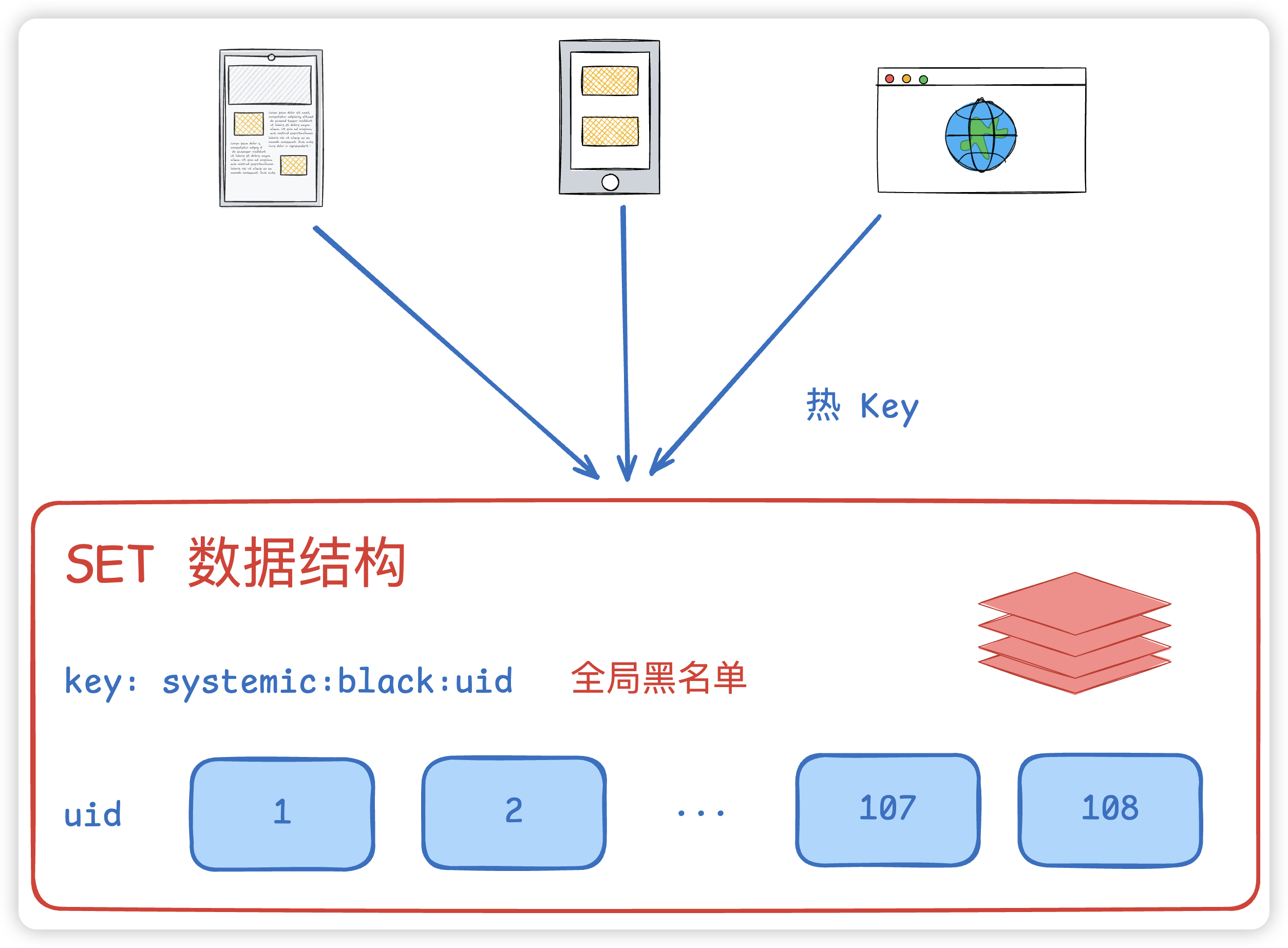
热key
⚠️注意一点,这里是单key并且是全局,这也意味着会有很多请求打到这个key上,此时就会面临热key的问题。
通常来说,我们Redis是一个分布式集群,而在Redis的Cluster 集群模式中,会使用哈希槽(hash slot)的方式来进行数据分片,将整个数据集划分为多个槽,每个槽分配给一个节点。 客户端访问数据时,先计算出数据对应的槽,然后直接连接到该槽所在的节点进行操作。
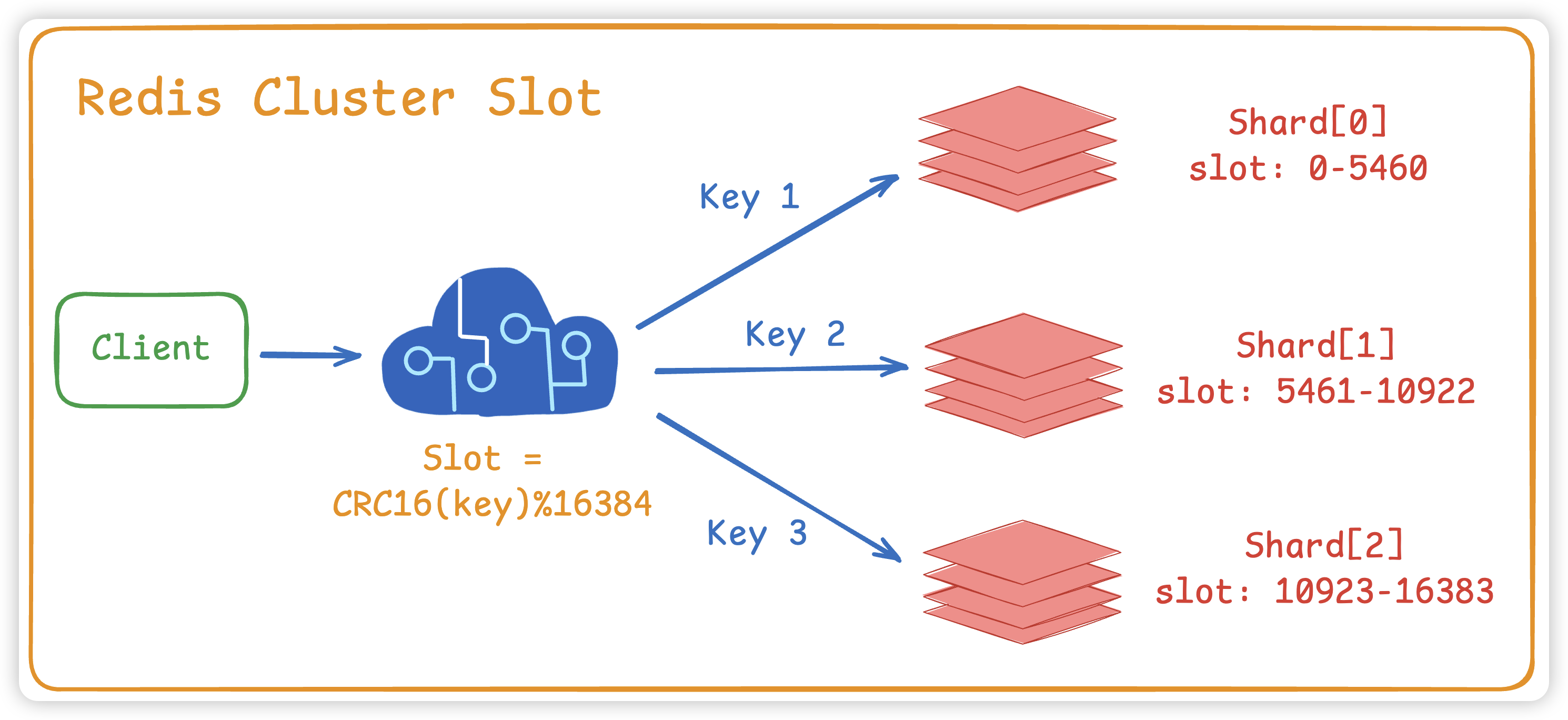
所以我们的数据其实是存在redis集群的某个数据分片中,热key最直观的原因就会导致集群资源利用不均,某个节点CPU、内存、网络打满,而其他节点资源闲置。
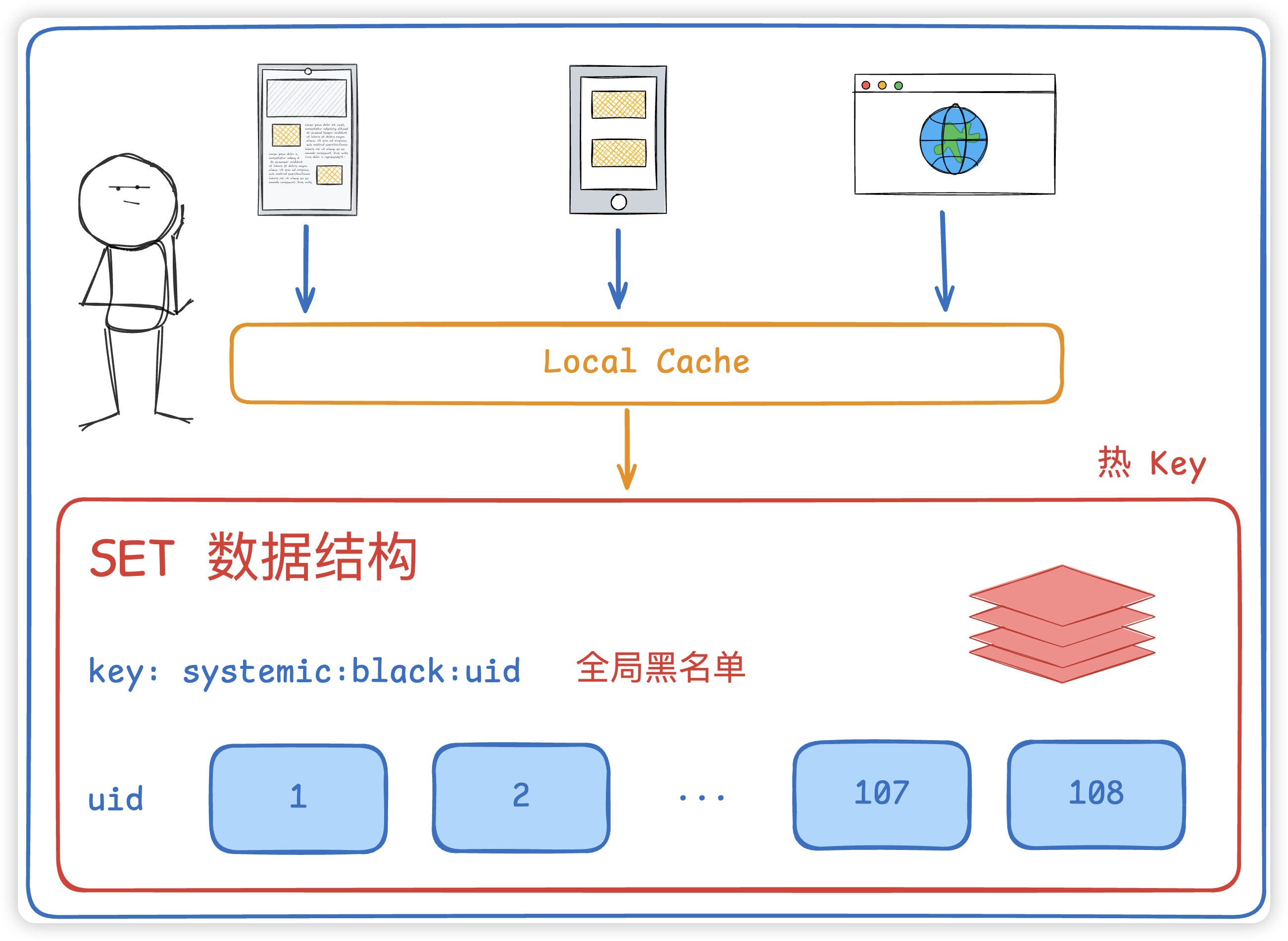
解决思路其实很简单,那就是增加本地缓存,并定时更新本地缓存。
大key
随着业务的发展,用户黑名单数量激增,如果现在需要存储10w的用户黑名单,那么就变成大key 问题了,应该怎么优化呢?
其实也很简单,我们可以做分片存储, 将一个key变成多个key,一个key存储一部分的数据,和上面的slot是类似的思路。
比如我们分 128个key 进行存储,那么10w / 128 = 780,也就是一个key存储大约780个元素,具体的分片规则,可以直接用 uid % 128
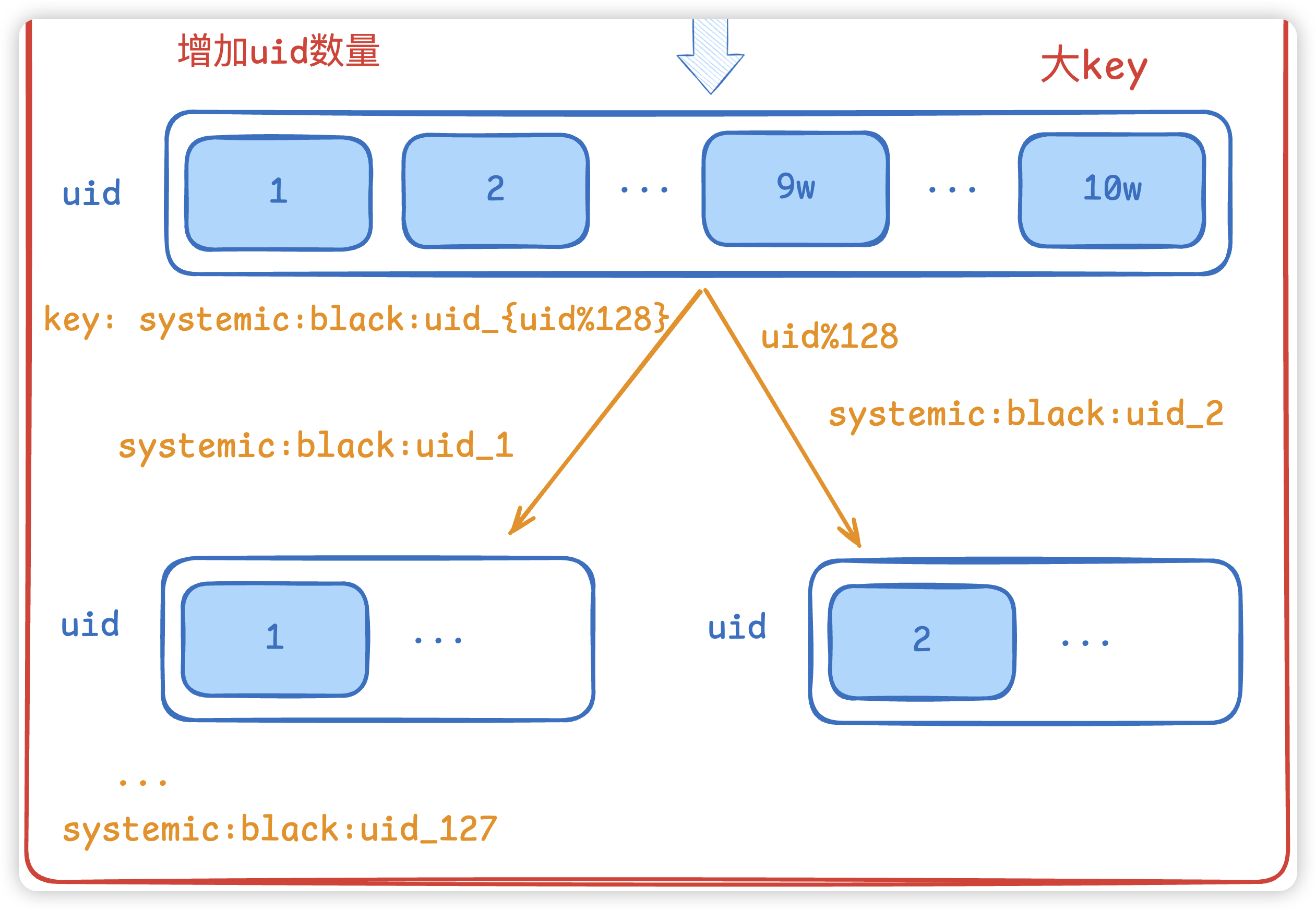
比如:
- uid = 1,对128取余,对应的key就是
systemic:black:uid_1,uid = 1就会放到这个key的value中。 - uid = 2,对128取余,对应的key就是
systemic:black:uid_2,uid = 2就会放到这个key的value中。 - …以此类推
下一篇文章,我们就来讲讲string数据结构的注意点和优化技巧。