【MySQL】第四章:数据类型

一、数据类型分类
下面是一张关于MySQL数据类型的分类及其说明的表格,其中标红的数据类型是后续讲解的解释说明的重点。

分类相同的数据类型之间用法类似,掌握了一个,其他的也能触类旁通,本文的重点在于讲解那些标红的类型。为了更好地说明这一点,我们可以拿数值类型中的整数类型作为例子。在整数类型的分类里,总共有5种不同的数据类型:分别是tinyint、smallint、mediumint、int以及bigint。这五种类型的差别仅仅体现在它们各自占用的存储空间大小(以字节为单位)和能够表示的数据范围上,除此之外,在使用方法上并无二致。因此,一旦你熟悉了其中一种类型的使用方法,那么对于其他几种类型也会运用自如。这种学习方法可以让你更加高效地掌握MySQL中不同类型数据的使用技巧。
二、数值类型
1、准备工作
本节将学习 MySQL 数据类型及其应用,为了更好的演示每种数据类型的具体用途。
此处会创建一个名为 data_type 的数据库,这个数据库专门用于存放本节所涉及到的各个表结构和示例数据。
-- 创建数据库
create database if not exists data_type;
-- 进入数据库
use data_type;
2、数值类型分类
| 分类 | 类型 |
|---|---|
| 整数类型 | tinyint、smallint、mediumint、int、bigint |
| 浮点数类型 | float、double、decimal |
| 布尔类型 | bool |
| 位类型 | bit(M) |
3、整数类型详细信息
| 类型 | 字节 | 符号 | 最小值 | 最大值 |
|---|---|---|---|---|
| TINYINT | 1 | 有(默认) | -128 | 127 |
| 无 | 0 | 255 | ||
| SMALLINT | 2 | 有(默认) | -32,768 | 32,767 |
| 无 | 0 | 65535 | ||
| MEDIUMINT | 3 | 有(默认) | -8,388,608 | 8,388,607 |
| 无 | 0 | 16,777,215 | ||
| INT | 4 | 有(默认) | -2,147,483,648 | 2,147,483,647 |
| 无 | 0 | 4,294,967,295 | ||
| BIGINT | 8 | 有(默认) | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,808 |
| 无 | 0 | 18,446,744,073,709,551,615 |
下面将以几个案例,逐步引入并讲解我们的知识点:
案例一:创建t1表并查看表结构的详细信息
-- 创建表t1
create table if not exists t1(
n1 tinyint,
n2 smallint,
n3 mediumint,
n4 int,
n5 bigint
);
-- 查看表t1
desc t1;
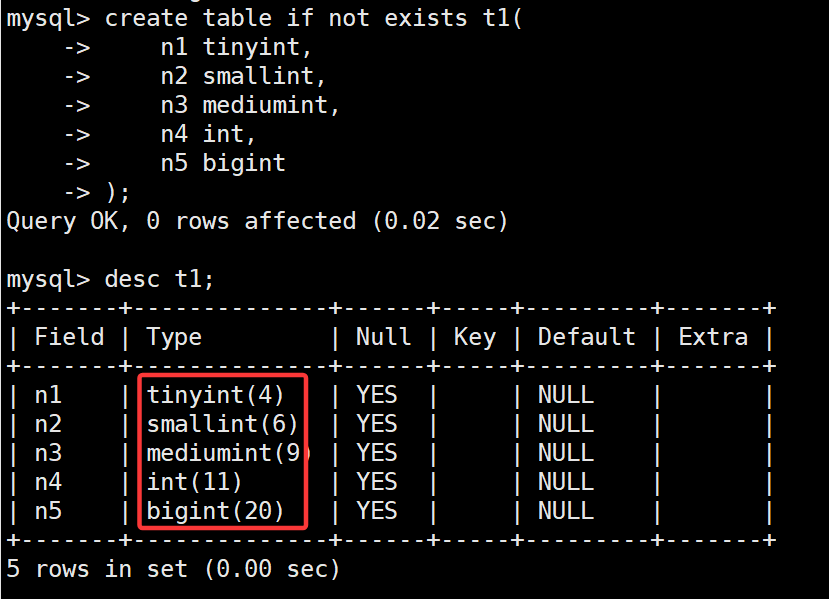
内容说明:在 desc t1; 语句执行结果中,我们能够看到 Type 中显示出来的各个数据类型后面都会跟着 (数字) 这么一个东西,其实括号中的数字表示该类型的数据默认的显示宽度,这部分内容涉及字段级别约束条件中的zerofill修饰符,属于是表的约束中的一部分,后续会详细介绍,这里不是本节的重点。
案例二:signed 修饰符的省略与数据范围
signed 表示有符号数,具有正负数属性
我们当前的表 t1 及其字段属性内容:
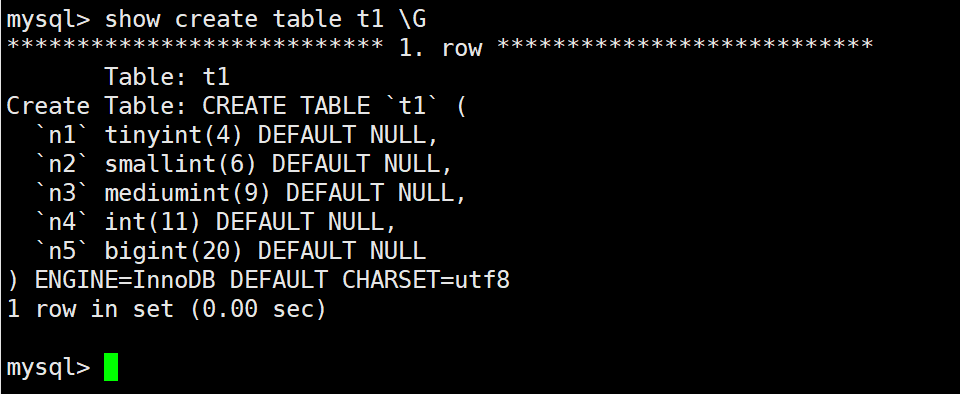
我们下面要往该表中,分别插入 n1 tinyint 的不同的数值,观察其表现
insert into t1 (n1) values (-128); # 插入 -128
insert into t1 (n1) values (-1); # 插入 -1
insert into t1 (n1) values (0); # 插入 0
insert into t1 (n1) values (1); # 插入 1
insert into t1 (n1) values (127); # 插入 127
insert into t1 (n1) values (128); # 插入 128,失败
insert into t1 (n1) values (-129); # 插入 -129,失败
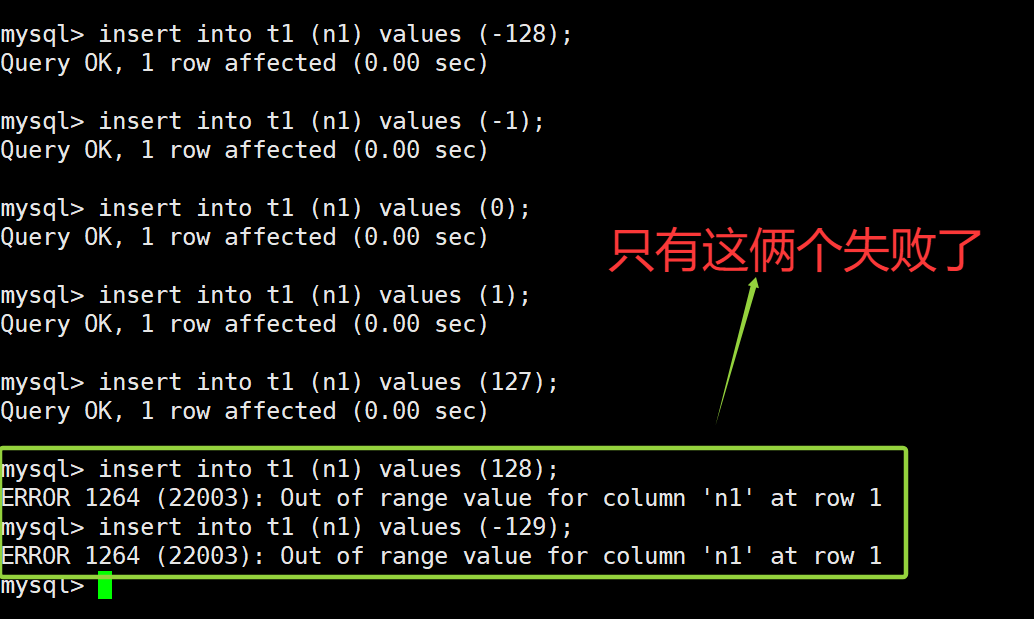
案例二说明:
-
MySQL定义了 signed 和 unsigned 修饰符,它们适用于除了 bool 和 bit(M) 之外的其余数值类型,用于指定字段是否允许存储负数(这个其实和我们的 C/C++ 中的 signed 和 unsigned 修饰符一致)
-
MySQL会默认将数值类型字段设置为有符号,例如
n1 tinyint等同于n1 tinyint signed(和语言中的设计一致)。 -
insert into t1 (n1) values (128);:这表示向n1字段(列)插入一个数字128。关于插入语句的具体语法将在后续文章中详细介绍,此处只需了解这是在插入数据即可。 -
MySQL规定了每个整数类型字段所能存储的数据范围(可以查看上面的整数类型表格),这个范围取决于该类型字段所占存储空间的大小(单位是字节)。例如:
tinyint signed的范围是 -128 到 127。tinyint unsigned的范围是 0 到 255。
一旦数据大小超过类型规定的范围,MySQL会拦截数据的插入,并报越界错误。
-
在 C/C++ 或 Java 中,我们也会遇到将大数据存储到小空间的情况。然而,C/C++ 编译器通常不会报错,而是通过数据截断或隐式类型提升等手段来处理。这种设计是为了满足应用开发的不同需求。而 MySQL 的主要职责是对数据进行安全、可靠的管理,严格的数据类型和数据范围检测确保了数据库中存储的数据一定是安全、可靠的。
-
尝试初步理解“约束”这一概念。“MySQL的数据类型”或者说“MySQL对数据类型和数据范围的严格检测”本身就是一种约束。它要求MySQL的使用者每次都要尽可能地执行正确的插入操作。因此,什么是约束?约束就是通过不断加条件让数据变得可预期、完整的过程。
案例三:unsigned修饰符的使用
我们创建一个表 t2:表中的类型和前面的表 t1一致,不同的是表 t2 中的所有类型都使用 unsigned修饰
-- 创建一个表 t2
CREATE TABLE if not exists `t2` (
n1 tinyint(4) unsigned DEFAULT NULL,
n2 smallint(6) unsigned DEFAULT NULL,
n3 mediumint(9) unsigned DEFAULT NULL,
n4 int(11) unsigned DEFAULT NULL,
n5 bigint(20) unsigned DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
向表中插入不同大小的数据:类似案例 2 一样的测试方法
insert into t2 (n1) values (0);
insert into t2 (n1) values (255);
insert into t2 (n1) values (256);
insert into t2 (n1) values (-1);
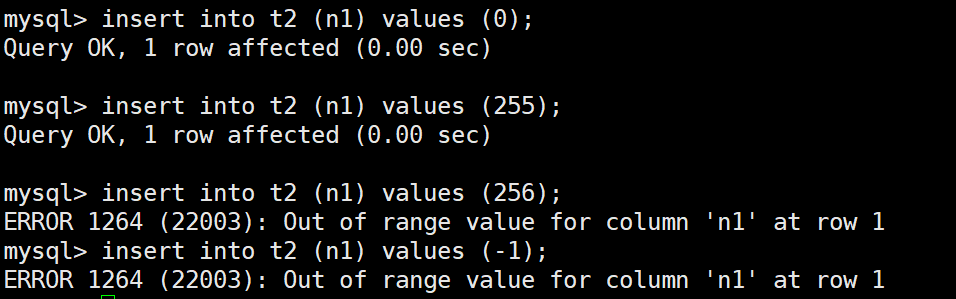
可以发现,插入数据 256 和 -1 时,就被阻止了
案例三的说明如下:
-
signed 修饰符和 unsigned 修饰符的区别:
- 这两种修饰符的主要区别在于数据的取值范围不同。其余特性基本一致。
signed类型可以存储负数,而unsigned类型只能存储非负数(即正数和零)。- 直白点说,理解
unsigned,就和编程语言中学的那样,就是无符号的意思,将原本负数范围的部分加到正数范围中
-
关于 unsigned 修饰符的观点:
- 有些说:我们应该尽量不使用
unsigned,理由是如果int类型无法存放的数据,int unsigned同样可能无法存放,因此建议直接将类型提升为bigint。 - 答:然而,这种说法并不完全正确。是否使用
unsigned完全取决于具体的应用场景。例如,在定义年龄、商品库存、ID等字段时,由于这些数据天然不会出现负数,因此更适合使用unsigned修饰符。
- 有些说:我们应该尽量不使用
-
MySQL 提供多种数据类型的原因:
- MySQL 设计时在“提供应用场景”和“节省资源”之间进行了权衡。
- 以年龄为例,使用
tinyint类型(消耗1个字节)已经足够满足需求,完全没有必要浪费7个额外字节来使用bigint类型。 - 因此,MySQL 提供了多种数据类型,以便开发者根据实际需求选择最合适的类型,从而在保证功能的同时优化资源利用。
4、浮点数
float[(M, D)] [unsigned] M--指定浮点数长度,D--小数位数,占用空间4个字节
double[(M, D)] [unsigned] M--指定浮点数长度,D--小数位数,占用空间8个字节
decimal(M, D) [unsigned] M--指定浮点数长度,D--小数位数,占用空间不定
浮点数类型一共有三个,分别是 float、double、decimal(M, D)。
其中,float 和 double 这两个类型的差别仅在于可存储的数据范围和数据的精度,所以只会针对性地了解其中的一个,这里选择的是 float。
因此,下面内容分成两部分,第一部分是关于 float 的介绍,第二部分是关于 decimal(M, D) 类型的介绍。
float
cloumn_name float[(M, D)] [unsigned]
- [(M, D)]:可选项,
- M 用于指定浮点数的总位数(总位数 = 整数部分 + 小数部分)。
- D 用于表示小数点后的位数。
- [unsigned]:可选项,不写默认浮点数是有符号的。
- float 类型所占据的存储空间大小是4个字节。
案例一:signed 浮点数的边界与超过规定数位的了解
-- 新建表 t3
create table if not exists t3(
id int,
salary float(4, 2)
);
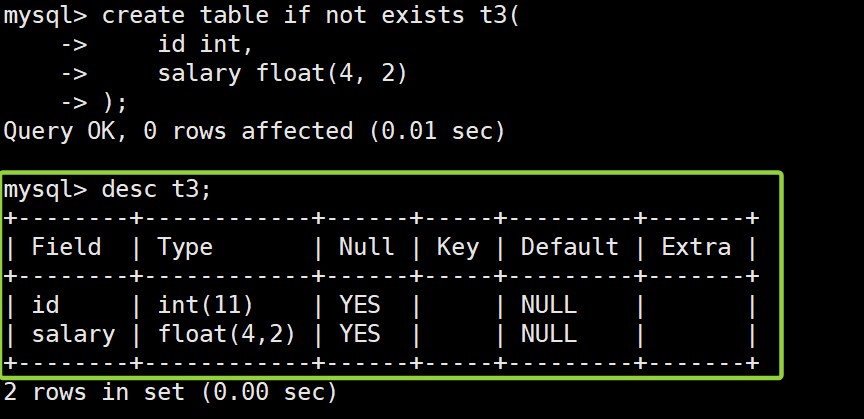
有了前面一节的整数类型的讲解,我们可以基本知道,本章节讲解这些数据类型,基本都是采用输入不同的数值,来设置该数据类型的上下边界、约束条件以及其他特性,下面测试浮点数以及其他数据类型我们都如此:
insert into t3 (id, salary) values (1, -99.99); -- 下边界
insert into t3 (id, salary) values (2, 99.99); -- 上边界
insert into t3 (id, salary) values (3, -10.1); -- 小数点部分不足2位会补零
insert into t3 (id, salary) values (4, -100.00);
insert into t3 (id, salary) values (4, -100.0);
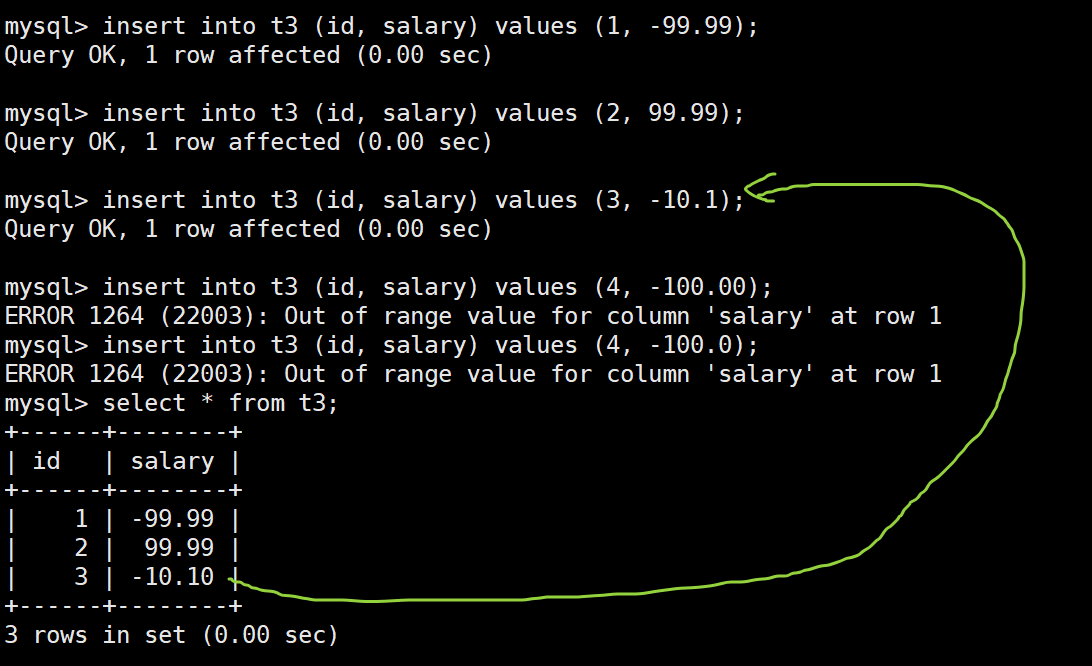
可以发现,前两项插入属于正常范围内插入,第三项不仅成功插入而且系统帮你自动补位,后面几个插入失败
案例一的说明:
salary float(4, 2)字段定义的时候没有使用unsigned修饰符修饰,说明该字段能够存储负数。- 存储范围与位数规定:
float(4, 2)表示字段的总位数为4位,其中2位用于小数部分。因此,整数部分最多允许2位。因此,该字段可以存储的范围是 -99.99 到 99.99。任何超出这个范围的值(例如 -100.00 或 100.00)都会触发“Out of range”错误。这就是为什么尝试插入 -100.00 和 100.00 时,MySQL 会报错。 - 补位机制: 在小数部分不满足精度要求时(如 -10.1 只有 1 位小数),MySQL 会自动在小数部分补零以满足
float(4, 2)的格式要求。插入时,即使提供的浮点数不精确到 2 位小数,MySQL 也会确保输出格式符合定义。
案例二:浮点数插入时的四舍五入
在案例一中,我们认识到了缺位就补位机制,如果位数超了呢?
insert into t3 (id, salary) values (4, -10.999);
insert into t3 (id, salary) values (4, 10.999);
select * from t3;
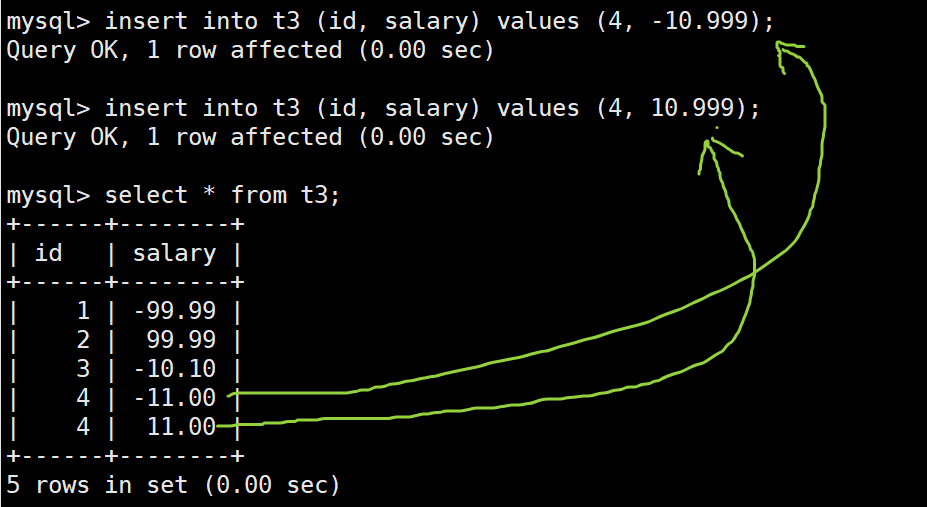
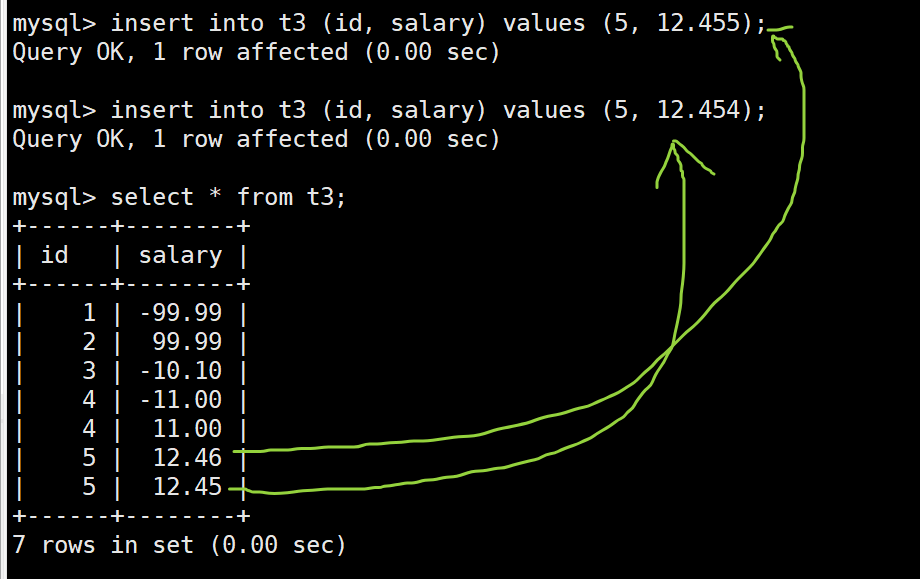
insert into t3 (id, salary) values (5, 12.455);
insert into t3 (id, salary) values (5, 12.454);
select * from t3;
insert into t3 (id, salary) values (6, 99.999);
select * from t3;

案例二说明如下:
-
四舍五入规则:当插入的浮点数小数位数超过定义的小数位数时(如2位),MySQL会自动对值进行四舍五入来调整浮点数的值,以符合定义的精度。例如:
- -10.999 被四舍五入为 -11.00(因为 .999 超过 2 位小数,因此对其四舍五入调整为 2 位小数)
- 10.999 被四舍五入为 11.00 (同上)
- 12.455 被四舍五入为 12.46 (同上)
- 12.454 被四舍五入为 12.45(同上)
-
四舍五入可能导致的边界问题:当四舍五入后值超出定义的范围,仍会引发“Out of range”错误。例如,如果插入 99.995,四舍五入后变为 100.00,将超出 float(4, 2) 的范围,从而导致插入失败。
案例三:无符号的浮点数的插入以及边界的了解
-- 新建表t4 : unsigned修饰字段
create table if not exists t4(
id int,
salary float(4, 2) unsigned
);
-- 查看表t4
desc t4;
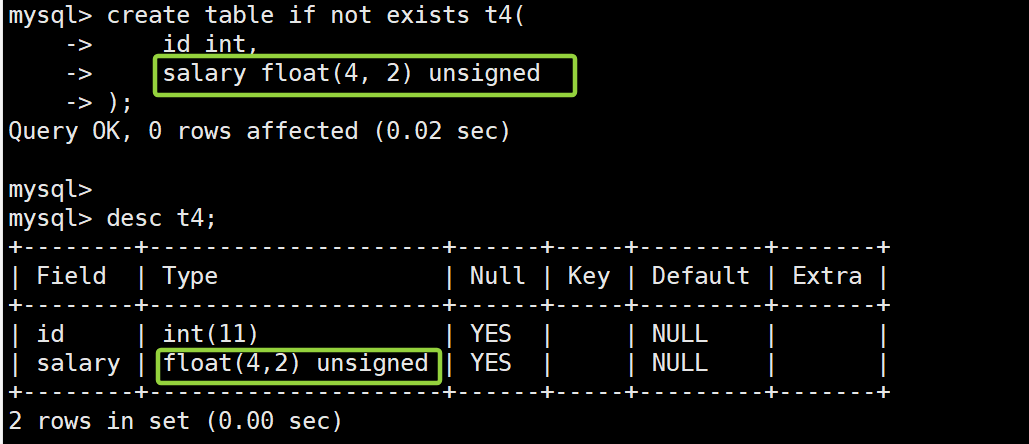
测试数据及其查询结果:
insert into t4 (id, salary) values (1, 0); -- 测试数值 0
insert into t4 (id, salary) values (2, 99.99);
insert into t4 (id, salary) values (3, 99.994);
insert into t4 (id, salary) values (3, 99.996);
insert into t4 (id, salary) values (3, -0.0001); -- 测试负数
insert into t4 (id, salary) values (3, 100); -- 测试三位整数
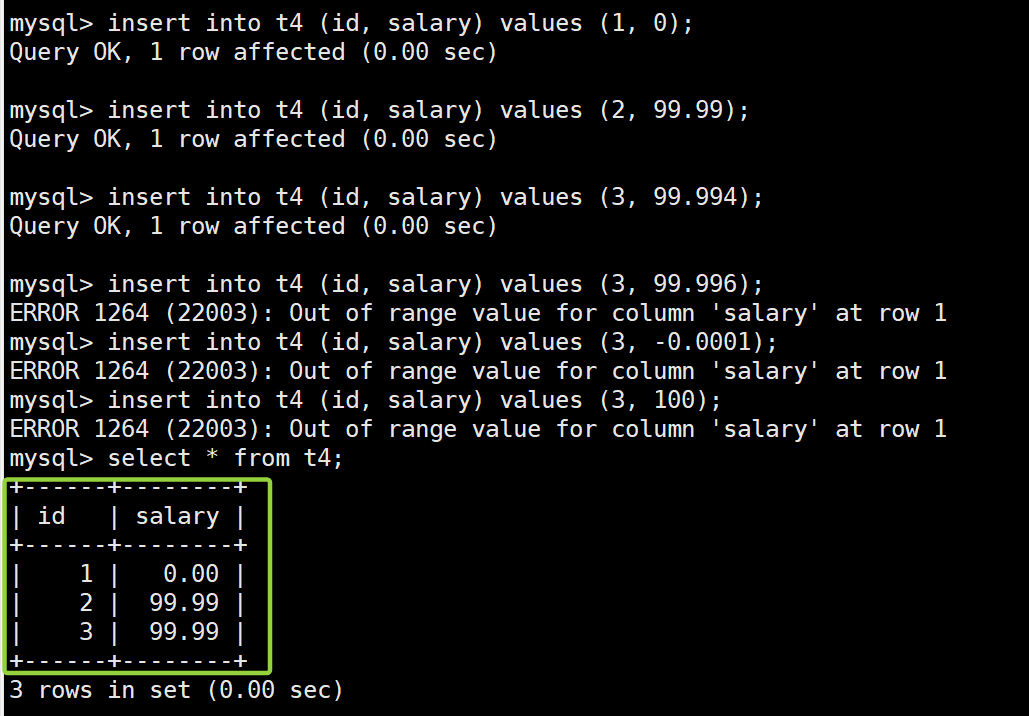
案例三的说明如下:
-
无符号浮点数的取值范围:
在定义了
float(4, 2) unsigned后,salary字段只能存储非负数,其取值范围是 [0.00, 99.99]。和整数类似,移除符号限制后,负数的支持被取消,但与整数不同的是,无符号浮点数不会扩大数值上限。例如,float(4, 2)的有符号范围为 [-99.99, 99.99],无符号后范围变为 [0.00, 99.99],上限依旧没有变化。 -
边界处理:
- 0 是合法的最小值,因此
insert into t4 (id, salary) values (1, 0);成功。 - 99.99 是最大合法值,因此
insert into t4 (id, salary) values (2, 99.99);成功。 - 插入负值(如 -0.0001)会立即触发“Out of range”错误,因为无符号字段不允许负数。
- 0 是合法的最小值,因此
-
四舍五入的处理:
float(4, 2)在插入 99.994 时,MySQL 自动四舍五入为 99.99,结果符合精度要求,并不会超出范围。但 99.996 则会被视为 100.00,超出上限,从而触发“Out of range”错误。这说明无符号浮点数也是符合四舍五入规则的。
案例四:float 的精度损失
在此案例中,t5 表的设计用于测试 MySQL 中浮点数类型 float 的精度损失情况。表结构定义如下:
- 字段
s1:为浮点类型float,用于测试当整数部分过大时可能造成的精度损失。 - 字段
s2:定义为float(10,8),用于测试当小数部分位数过多时的精度损失。 - 值得注意的是 字段
s1定义的类型float并没有显示的指定数位
create table if not exists t5(
id int,
s1 float comment '用于测试整数部分过大时造成的精度损失',
s2 float(10, 8) comment '用于测试小数部分位数过多时的精度损失'
);
测试数据及其查询结果:
insert into t5 (id, s1, s2) values (1, 2.12345, 2.12345);
insert into t5 (id, s1, s2) values (2, 123456789, 1.23456789);
insert into t5 (id, s1, s2) values (3, 123456789, 12.3456789);
select * from t5;
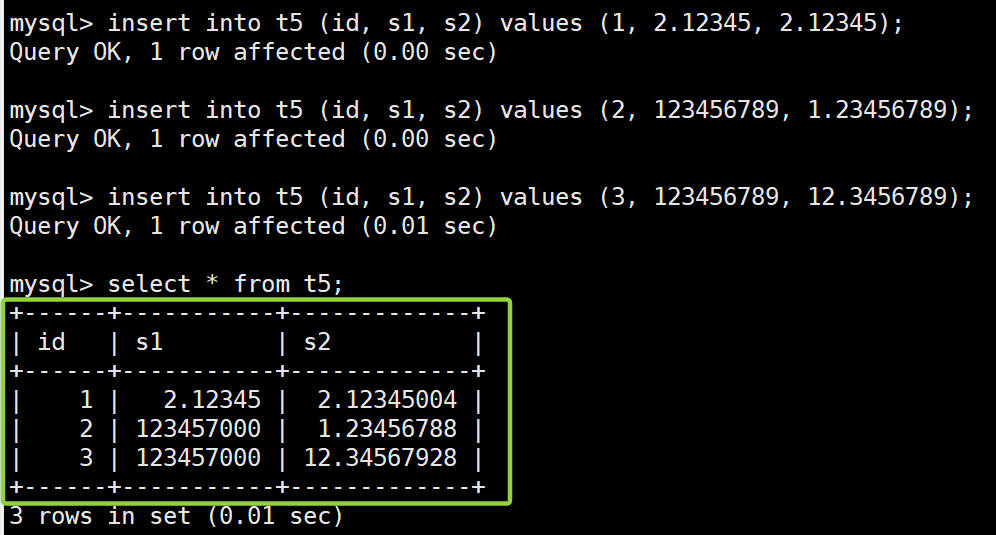
案例 4 说明:
-
字段 s1:测试整数部分较大时的精度损失
- 插入 s1 的值为 123456789,但在查询结果中,s1 显示为 123457000。
- 这表明,当浮点数的整数部分位数较大时,float 类型会由于精度限制对数值进行近似存储,从而出现数据损失。这是由于 float 类型采用 IEEE 754 标准的单精度浮点表示,无法精确表示非常大的整数,从而导致存储时的数据变动。
-
字段 s2:测试小数部分位数过多时的精度损失
- 插入 s2 的值为 2.12345,查询显示 2.12345004;插入 1.23456789 显示为 1.23456788,插入 12.3456789 显示为 12.34567928。这些结果说明,当小数部分的位数超过 float 的精度限制时,MySQL 会近似存储这些数据,而非精确存储。
- 即使字段定义了 float(10, 8),也无法完全保证八位小数精度,因为 float 类型的底层存储结构限制了数值的精确度。
-
以上测试结果中,大概体现了 float 类型能大概只能保证 7 位(从左往右)的精度,如果对数字的精度要求较高时不应该使用 float 类型。
decimal(M, D)
使用语法:
column_name decimal(M, D) [unsigned]
-
M:
- 名称:精度。
- 含义:数字的总位数(包括小数点左右两侧的所有数字)。
- 取值范围:[1~65],缺省值为10。
-
D:
- 名称:标度。
- 含义:小数点右侧数字的位数。
- 取值范围:[0, 30],缺省值为0。注意:MySQL要求 D <= M。
-
[unsigned]:可选项,类型修饰符,使用之后只能该列不能存储负数。
-
不写或写零即为缺省: 字段定义时,
decimal、decimal(0)、decimal(0, 0)三种写法都会被MySQL认为M、D缺省。 -
举例:decimal(4, 2) 表示该列可以存储小数有2位,总共有4位的浮点数,如12.34。
-
简单来说,
decimal(M, D)就是不会精度损失的float
案例一:缺省定义
-- 新建表 t8
create table if not exists t8 (
d1 decimal,
d2 decimal(0),
d3 decimal(0, 0)
);
-- 查看t8
desc t8;
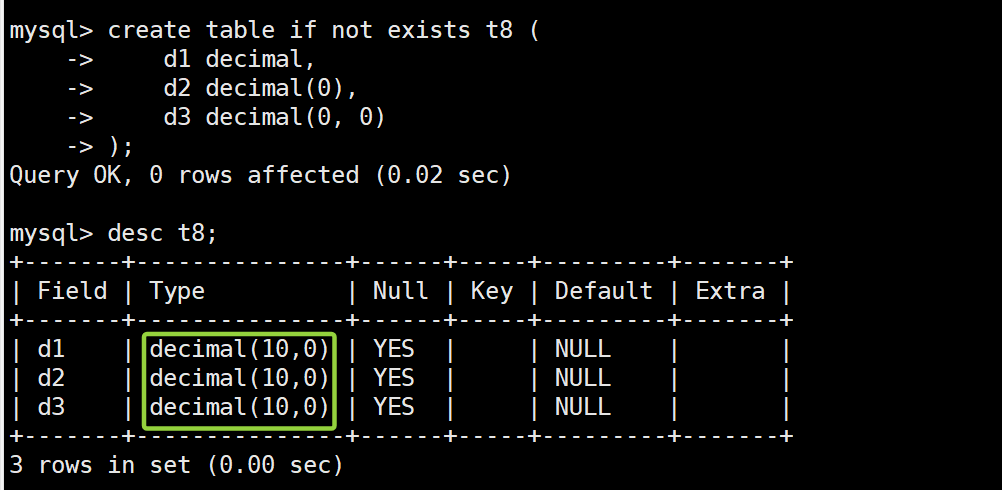
-
不写或写零即为缺省: 字段定义时,
decimal、decimal(0)、decimal(0, 0)三种写法都会被MySQL认为M、D缺省。 -
缺省整数位为 10,小数位为 0
案例二:越界定义
-- M最大值是65
create table if not exists t8 ( d1 decimal(66, 30) );
ERROR 1426 (42000): Too-big precision 66 specified for 'd1'. Maximum is 65.
-- D最大值是30
mysql> create table if not exists t8 ( d1 decimal(65, 31) );
ERROR 1425 (42000): Too big scale 31 specified for column 'd1'. Maximum is 30.
-- M最小值为1,D最小值为0
mysql> create table if not exists t8 (
-> d1 decimal(1, 0),
-> d2 decimal(65, 30)
-> );
Query OK, 0 rows affected (0.02 sec)
<br>
mysql> desc t8;
+-------+----------------+------+-----+---------+-------+
| Field | Type | NULL | Key | Default | Extra |
+-------+----------------+------+-----+---------+-------+
| d1 | decimal(1,0) | YES | | NULL | |
| d2 | decimal(65,30) | YES | | NULL | |
+-------+----------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
- 只有当M、D(精度、标度)取值正确,表的创建SQL才能正常执行。
decimal和float的差别就在于decimal能够精确存储数值。
create table if not exists t8(
f float(10, 8),
d decimal(10, 8)
);
desc t8;
+-------+---------------+------+-----+---------+-------+
| Field | Type | NULL | Key | Default | Extra |
+-------+---------------+------+-----+---------+-------+
| f | float(10,8) | YES | | NULL | |
| d | decimal(10,8) | YES | | NULL | |
+-------+---------------+------+-----+---------+-------+
插入测试数据:
insert into t8 values (23.12345612, 23.12345612);
select * from t8;
+-------------+-------------+
| f | d |
+-------------+-------------+
| 23.12345695 | 23.12345612 |
+-------------+-------------+
-
字段
f,插入值是23.12345612,查询值是23.12345695,存在误差。 -
字段
d,插入值是23.12345612,查询值是23.12345612,不存在误差。
5、BIT(M)类型
语法
以下是关于bit类型的语法:
column_name bit[(M)]
-
位类型
-
M:
- 名称:位宽或者位长度。
- 含义:可用的比特位数(结合存储空间理解)。
- 取值范围:[1, 64],缺省值为1。
-
存储空间:[M / 8] 字节(向上取整)。
举例,当 M==1 时,字段所占存储空间是1个字节,但是只会使用1个比特位。
字段的定义
-- M不能为0
mysql> create table if not exists t( id int, online bit(0) );
ERROR 3013 (HY000): Invalid size for column 'online'.
-- M的最大值为64
mysql> create table if not exists t( id int, online bit(65) );
ERROR 1439 (42000): Display width out of range for column 'online' (max = 64)
mysql> create table if not exists t (
-> id int comment '当前用户的标识符',
-> online bit(1) comment '当前用户是否在线'
-> );
Query OK, 0 rows affected (0.02 sec)
mysql> desc t;
+--------+---------+------+-----+---------+-------+
| Field | Type | NULL | Key | Default | Extra |
+--------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| online | bit(1) | YES | | NULL | |
+--------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
插入数据
mysql> insert into t (id, online) values (1, 0);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t (id, online) values (2, 1);
Query OK, 1 row affected (0.00 sec)
mysql> insert into t (id, online) values (3, 2);
ERROR 1406 (22001): Data too long for column 'online' at row 1
- 字段定义时,指定可用比特位数为1,那么只能存储1个比特位的数据。
- 0 的二进制为
0,1的二进制位1,这两个能够正常插入。 - 2 的二进制为
10,需要使用两个比特位,但可用比特位为1,插入失败。
查询数据
我们刚刚成功插入了 values (1, 0) 和 values (2, 1),现在将 t 表数据查询出来看看:
mysql> select * from t;
+------+--------+
| id | online |
+------+--------+
| 1 | |
| 2 | |
+------+--------+
2 rows in set (0.00 sec)
mysql> alter table t modify column online bit(8);
Query OK, 2 rows affected (0.04 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> desc t;
+--------+---------+------+-----+---------+-------+
| Field | Type | NULL | Key | Default | Extra |
+--------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| online | bit(8) | YES | | NULL | |
+--------+---------+------+-----+---------+-------+
2 rows in set (0.00 sec)
mysql> insert into t (id, online) values (65, 65);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t;
+------+--------+
| id | online |
+------+--------+
| 1 | |
| 2 | |
| 65 | A |
+------+--------+
3 rows in set (0.00 sec)
-
现象:查询 t 表数据的时候发现 online 列什么也看不到。
-
原因:bit(M) 类型数据显示的时候默认按照数字对应的 ASCII 字符进行显示,数字 0、1 对应的 ASCII 字符都是不可打印不可显示的字符。
-
验证步骤如下:
-
修改 online 列的数据类型为 bit(8)。
-
在 id 列和 online 列分别插入数据 65。
-
再次查询时发现有一行数据中,id 列值为 65,online 列值为 A。
-
查询 ASCII 表发现,字符 A 的 ASCII 码值就是 65。
-
通过以上验证步骤,可以确认当 online 列的数据类型为 bit(M) 时,默认会按照 ASCII 字符显示。由于数字 0 和 1 对应的 ASCII 字符是不可打印的,所以在查询时无法看到任何内容。而当将 online 列的数据类型修改为 bit(8),并插入数据 65 后,查询结果显示为字符 A,这是因为 65 对应的 ASCII 字符正是 A。
bit(M) 十进制显示
我们可以指定选择该字段,以十进制的形式显示出来
select id, hex(online) from t3;
bit(M) 类型不支持存储负数
mysql> alter table t modify column online bit(63);
Query OK, 3 rows affected (0.03 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into t (id, online) values (-1, -1);
ERROR 1406 (22001): Data too long for column 'online' at row 1
--------------------------------------------------------------------
mysql> alter table t modify column online bit(64);
Query OK, 3 rows affected (0.03 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> insert into t (id, online) values (-1, -1);
Query OK, 1 row affected (0.00 sec)
--------------------------------------------------------------------
mysql> select * from t;
+------+----------+
| id | online |
+------+----------+
| 1 | |
| 2 | |
| 65 | A |
| -1 | ÿÿÿÿÿÿÿÿ |
+------+----------+
4 rows in set (0.00 sec)
--------------------------------------------------------------------
mysql> insert into t (id, online) values (255, 255);
Query OK, 1 row affected (0.00 sec)
mysql> select * from t;
+------+----------+
| id | online |
+------+----------+
| 1 | |
| 2 | |
| 65 | A |
| -1 | ÿÿÿÿÿÿÿÿ |
| 255 | ÿ |
+------+----------+
5 rows in set (0.00 sec)
在MySQL中,bit(M) 被设计存储无符号二进制数据的类型,即它没有负数的概念。
-
负数的处理机制:
- 当遇到负数时,MySQL会将其转换成64位二进制补码。例如,-1会被转换成全为1的64位二进制数:
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111。
- 当遇到负数时,MySQL会将其转换成64位二进制补码。例如,-1会被转换成全为1的64位二进制数:
-
BIT 类型的显示问题:
- 由于
BIT类型不直接转换为十进制或 ASCII 字符串,MySQL 会尝试将全为1的二进制位解释为字符。 - 在这种情况下,8位全为1的二进制数(即
11111111)对应的十进制值是255,而 255 在ASCII表中对应的是不可打印字符 “ÿ” 。 - 因此,当一个
BIT类型字段存储了全为1的二进制数时,MySQL会显示为 “yyyyyyyy” 。
- 由于
三、字符串类型
1、定长字符串类型 char
语法
column_name char(L)
说明:
- 作用是定义固定长度的字符串。
L是可以存储的字符串的长度,单位是字符。L的最大值是 255- 和C/C++中的 char 不一样,MySQL的 char 的单位是 字符,最大为 255个字符!!!
要点说明
长度单位是字符
1、定义一张名为 t8 的表结构,其中 name 字段类型为 char(2),最多可以存储 2 个字符。
mysql> create table if not exists t8 (
-> id int,
-> name char(2)
-> );
Query OK, 0 rows affected (0.01 sec)
2、插入英文字符。
-- 一个字符插入成功
mysql> insert into t8 (id, name) values (1, 'a');
Query OK, 1 row affected (0.00 sec)
-- 两个字符插入成功
mysql> insert into t8 (id, name) values (1, 'ab');
Query OK, 1 row affected (0.00 sec)
-- 三个字符插入失败
mysql> insert into t8 (id, name) values (1, 'abc');
ERROR 1406 (22001): Data too long for column 'name' at row 1
3、插入中文字符。
-- 一个中文字符插入成功
mysql> insert into t8 (id, name) values (1, '中');
Query OK, 1 row affected (0.00 sec)
-- 两个中文字符插入成功
mysql> insert into t8 (id, name) values (1, '中国');
Query OK, 1 row affected (0.00 sec)
-- 三个中文字符插入失败
mysql> insert into t8 (id, name) values (1, '中国的');
ERROR 1406 (22001): Data too long for column 'name' at row 1
对于中文字符:
- UTF-8 的中文一个字占 3 个字节
- GBK 的中文一个字占 2 个字节
总结:
- MySQL 对字符一视同仁,不管是英文字符还是中文字符,无论存储该字符具体需要消耗多少存储空间,都统一当成一个字符来看待。
- 当插入的字符串的字符个数超过预设的字符长度时,插入操作会被拦截。
预设字符长度不能超过 255
定义一张名为 t9 的表结构,其中,name 字段的类型为 char(256)。
mysql> create table if not exists t9 (
-> id int,
-> name char(256)
-> );
ERROR 1074 (42000): Column length too big for column 'name' (max = 255);
use BLOB or TEXT instead
SQL 语句执行失败,MySQL 提示 char 类型字符长度最大值为 255,当长度超过最大值时,表结构创建失败。
另外,MySQL 提示,想要使用更大的字符长度,请用 BLOB 或者 TEXT 类型。
在MySQL中,
BLOB和TEXT类型主要用于存储大量的数据。它们之间的主要区别在于存储的数据类型不同:BLOB用于二进制数据(如图片、音频文件等),而TEXT用于存储文本数据(如文章、评论等)。
2、变长字符串类型 varchar
变长的意思是具体使用长度不固定,你用多少,我给你多少,上限是 len,我们设置的 varchar(len),其实表示上限!len = 10,此次你只用 5,系统就给你分配 5 的空间,而不会分配满 10 给你
语法
column_name varchar(L)
说明:
- 作用是定义长度可变的字符串。
L是可以存储的字符串的字符长度的最大预设值,单位是字符。varchar(L)类型的最大字节长度为 65535 字节。
要点介绍
长度单位是字符
1、定义一张名为 t9 的表结构,其中 name 字段的类型为 varchar(2),最多存储 2 个字符。
mysql> create table if not exists t9 (
-> id int,
-> name varchar(2)
-> );
Query OK, 0 rows affected (0.02 sec)
2、插入英文字符。
-- 一个字符插入成功
mysql> insert into t9 (id, name) values (1, 'a');
Query OK, 1 row affected (0.01 sec)
-- 两个字符插入成功
mysql> insert into t9 (id, name) values (1, 'ab');
Query OK, 1 row affected (0.00 sec)
-- 三个字符插入失败
mysql> insert into t9 (id, name) values (1, 'abc');
ERROR 1406 (22001): Data too long for column 'name' at row 1
3、插入中文字符。
-- 一个字符插入成功
mysql> insert into t9 (id, name) values (1, '中');
Query OK, 1 row affected (0.00 sec)
-- 两个字符插入成功
mysql> insert into t9 (id, name) values (1, '中国');
Query OK, 1 row affected (0.00 sec)
-- 三个字符插入失败
mysql> insert into t9 (id, name) values (1, '中国人');
ERROR 1406 (22001): Data too long for column 'name' at row 1
总结:这一部分和 char(L) 在使用上没有区别。
字符长度与编码
这里建立一个共识:
- 我们把一个字符串中有多少个字符称为“字符长度”。
- 该字符串存储在计算机当中占据了多少个字节,称为“字节长度”。
MySQL规定,varchar 类型的最大字节长度为 65535 字节。然而,在这 65535 字节中,有1到3个字节会被用来记录字符串的实际字节长度,具体使用多少取决于字符串的字节长度。
因此,实际上可用于存储字符串的有效字节长度是 65532 字节(即 65535 - 3)。
此外,一个字符所占的字节数受表结构编码的影响,导致字符串的字符长度上限与编码紧密相关:
- 在
utf8编码中,一个字符占用3个字节,所以最大字符长度为 65532 / 3 = 21844。 - 在
gbk编码中,一个字符占用2个字节,因此最大字符长度为 65532 / 2 = 32766。
你可以简单理解:字节长度就是一个容器的空间大小,字符数就是你放入多个字符,而每个字符所占据的空间大小随着编码变化而变化,允许的最多字符数,就看空间能装下多少个字符,另外要注意的是有 1 到 3 个字节需要用于记录 varchar 类型此次实际使用的字节数,使用 varchar 时,我们可以直接设置稍微大一点,大点不用担心,因为实际用多少就给多少
接下来尝试对字符长度与编码的关系进行验证:
- 创建
t_utf8设置字符编码为utf8,字符长度设置为 100000。
当字符集为utf8并且预设字符长度超过 21845(65525 / 3)时,报错并提示最大可用字符长度为21845。
mysql> create table if not exists t_utf ( name varchar(100000) ) charset=utf8;
ERROR 1074 (42000): Column length too big for column 'name' (max = 21845);
use BLOB or TEXT instead
当字符集为utf8并且预设字符长度等于 21845(65525 / 3)时,报错提示字节长度超过65535。
mysql> create table if not exists t_utf ( name varchar(21845) ) charset=utf8;
ERROR 1118 (42000): Row size too large.
The maximum row size for the used table type, not counting BLOBs, is 65535.
This includes storage overhead, check the manual.
You have to change some columns to TEXT or BLOBs
回到开始提到的,“有3个字节用于记录字符串字节长度”。
当 L 值为 21845 时,实际花费(65535 + 3)个字节超过规定的 65535。
所以实际上,当字符集为utf8时,最大字符长度只能为21844。
mysql> create table if not exists t_utf ( name varchar(21844) ) charset=utf8;
Query OK, 0 rows affected (0.02 sec)
- 创建
t_gbk设置字符编码为gbk,字符长度设置为 100000。
当字符集为gbk并且预设字符长度超过 32767(65525 / 2)时,报错并提示最大可用字符长度为32767。
mysql> create table if not exists t_gbk ( name varchar(100000) ) charset=gbk;
ERROR 1074 (42000): Column length too big for column 'name' (max = 32767);
use BLOB or TEXT instead
当字符集为gbk并且预设字符长度等于 32767(65525 / 2)时,报错提示字节长度超过65535。
mysql> create table if not exists t_gbk ( name varchar(32767) ) charset=gbk;
ERROR 1118 (42000): Row size too large.
The maximum row size for the used table type, not counting BLOBs, is 65535.
This includes storage overhead, check the manual.
You have to change some columns to TEXT or BLOBs
当字符长度设置为32766,SQL 语句执行成功。
mysql> create table if not exists t_gbk ( name varchar(32766) ) charset=gbk;
Query OK, 0 rows affected (0.01 sec)
总结:varchar 类型的字符长度上限等于“(65535-3)/ 一个字符占据的字节数”,设置长度时只需要注意。另外,使用 varchar 时,我们可以直接设置稍微大一点,大点不用担心,因为实际用多少就给多少
3、char 和 varchar 区别

char类型
- 不管字符串实际的字符长度是多少,都会消耗固定字节长度的存储空间来存储字符串。
- 好处是存储长度是固定值,存储时效率相较更高一点。
- 坏处是可能会浪费大量存储空间。
varchar类型:
- 先计算实际消耗的字节长度,然后给字符串分配合适的存储空间。
- 好处是会节省存储空间。
- 坏处是在插入和更新数据时可能涉及额外的存储计算开销。

4、char 和 varchar 的选择
-
如果数据确定长度都一样,就使用定长(
char),比如:身份证、手机号、md5。 -
如果数据长度有变化,就使用变长(
varchar),比如:名字、地址,但是要保证最长的数据能存进去。 -
定长的磁盘空间比较浪费,但是效率高。
-
变长的磁盘空间比较节省,但是效率低。
-
定长的意义是,直接开辟好对应的空间。
-
变长的意义是,在不超过自定义范围的情况下,用多少,开辟多少。
四、日期和时间类型
这里先来建立一个共识:
- “年月日” 定义为 “日期(date)”
- “时分秒” 定义为 “时间(time)”
以上就是 MySQL 对于时间的划分,目的是能够针对性地处理日期和时间相关的数据。
另外,以下的日期时间类型的数据插入,都需要用单引号引起来的 字符格式,否则插入失败
1、日期相关类型
-
date
- 大小:3字节。
- 用途:表示日期(年月日)。
- 格式:‘YYYY-MM-DD’(例如 ‘2025-01-10’)。
- 范围:从 ‘1000-01-01’ 到 ‘9999-12-31’。
- 特点:适用于仅需要存储日期、不需要时间信息的场景,如生日、注册日期、评论日期等。
-
year
- 大小:1字节。
- 用途:表示年份。
- 格式:‘YYYY’(例如 ‘2025’)。
- 范围:从 ‘1901’ 到 ‘2155’。
- 特点:存储单独的年份,适合处理年份维度的数据,如财年、学年等。
2、时间相关类型
- time
- 大小:3字节。
- 用途:表示一天中的时间点或时间间隔。
- 格式:‘HH:MM:SS’(例如 ‘15:30:00’)。
- 范围:从 ‘-838:59:59’ 到 ‘838:59:59’。
- 特点:可用于存储时间点,也可以表示时长,例如航班时长、工时记录等。
3、日期与时间的结合类型
-
datetime
- 大小:8字节。
- 用途:表示日期和时间(精确到秒)。
- 格式:‘YYYY-MM-DD HH:MM:SS’(例如 ‘2025-01-10 15:30:00’)。
- 范围:从 ‘1000-01-01 00:00:00’ 到 ‘9999-12-31 23:59:59’。
- 特点:与时区无关,适用于不需要与时区转换的时间记录。
-
timestamp
- 大小:4字节。
- 用途:表示时间戳(日期和时间,带时区)。
- 格式:与 DATETIME 相同,即 ‘YYYY-MM-DD HH:MM:SS’。
- 范围:从 ‘1970-01-01 00:00:01’ 到 ‘2038-01-19 03:14:07’。
- 特点:
- 与时区相关:存储时会转换为 UTC,查询时会根据会话的时区设置转换回本地时间。
- 通常用于记录事件发生的具体时间点,如日志记录。
- 会自动更新,无需用户管理
4、案例
创建名为 t10 的表结构,SQL 语句如下:
create table if not exists t10 (
t1 year,
t2 date,
t3 time,
t4 datetime,
t5 timestamp
);
查看表结构信息。
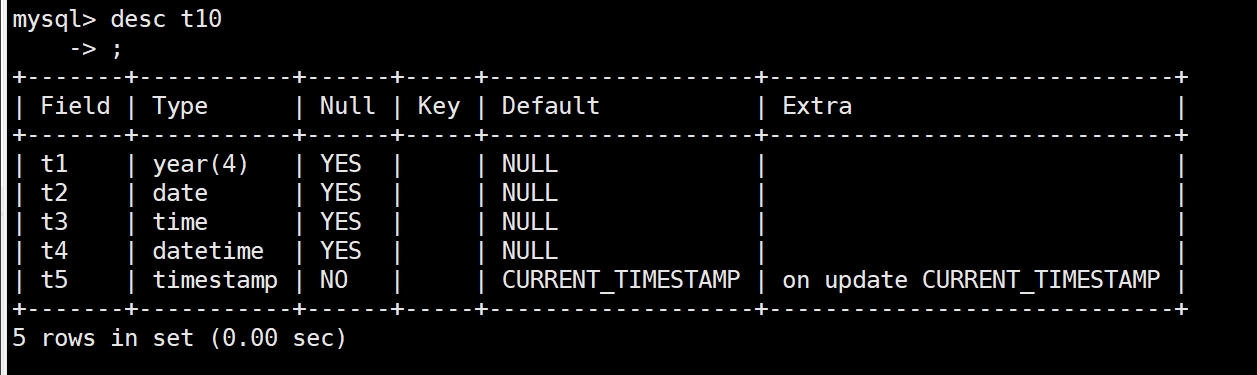
前四列指定插入数据,第五个没有插入数据
mysql> insert into t10 (t1, t2, t3, t4)
-> values (2025, 2025-1-10, 00:00:01, 2025-1-10 00:00:01);
由于插入的数据不是字符串格式,插入失败。
ERROR 1064 (42000): You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version for the right syntax
to use near ':00:01, 2025-1-10 00:00:01)' at line 1
将数据修改为字符串格式,插入成功。
mysql> insert into t10 (t1, t2, t3, t4)
-> values ('2025', '2025-1-10', '00:00:01', '2025-1-10 00:00:01');
Query OK, 1 row affected (0.00 sec)
在使用上可以认为:日期、时间相关类型就是一个特定长度、特定格式的字符串而已。
执行查询SQL语句,查询表格内容发现,t5 字段明明没有手动插入,却已经被填入了一个数据。
这就是 timestamp 类型的特点:当该行记录被修改或者新增时,由 MySQL 自动填充。
mysql> select * from t10;
+------+------------+----------+---------------------+---------------------+
| t1 | t2 | t3 | t4 | t5 |
+------+------------+----------+---------------------+---------------------+
| 2025 | 2025-01-10 | 00:00:01 | 2025-01-10 00:00:01 | 2025-01-10 15:16:41 |
+------+------------+----------+---------------------+---------------------+
1 row in set (0.00 sec)
5、几个日期时间类型对比
date 用于只记录日期,如记录某人的生日
datetime 就负责记录固定的时间,不会随着其他数据的变化而变化
timestamp 记录时间戳,会自动更新
五、枚举类型 enum
简单认知:枚举类型 enum 就是单选题,列举的众多元素,只能选择一个
1、语法
create table table_name (
column_name enum('选项值1', '选项值2', '选项值3', ...)
);
2、要点说明
选项值只能是字符串。
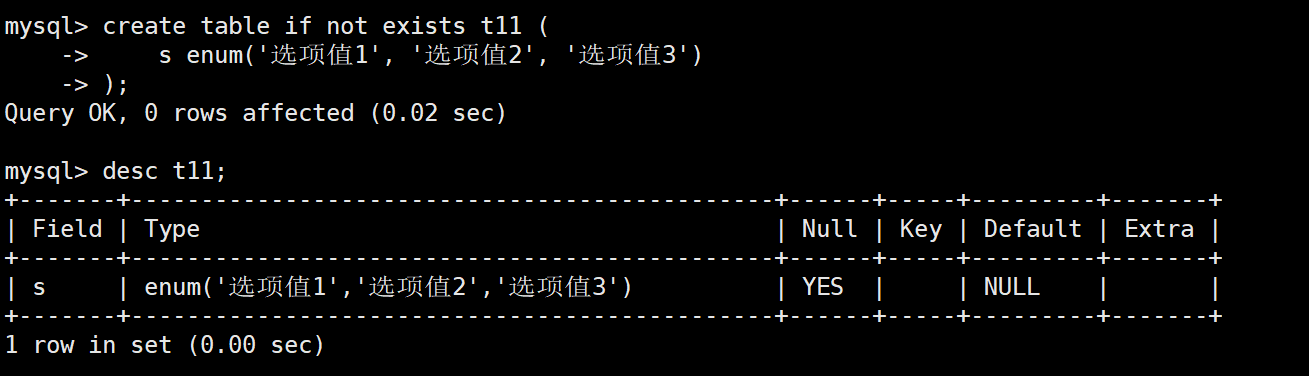
创建表结构 t11,字段 s 的类型是 enum,枚举值不是字符串,表结构创建失败。
mysql> create table if not exists t11 (
-> s enum(1, 2, 3)
->);
ERROR 1064 (42000): You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version for the right syntax
to use near '1, 2, 3) )' at line 1
创建表结构 t11,字段 s 的类型是 enum,枚举值是字符串,表结构创建成功。
-- 新建表 t11
create table if not exists t11 (
s enum('选项值1', '选项值2', '选项值3')
);
-- 查看表 t11
desc t11;
不能插入非选项值
前面我们定义好了 enum 类型:enum('选项值1', '选项值2', '选项值3'),现在向表 t11 的字段 s 插入数据 '不是选项值'。
insert into t11 (s) values ('不是选项值');
SQL语句执行失败。
ERROR 1265 (01000): Data truncated for column 's' at row 1
插入选项值或者选项值索引
这里解释一下什么是选项值索引。
在定义表结构时,MySQL 会将 enum 类型字段的选项值(枚举值)用一个类似于顺序表之类的结构存储起来。
然后按照定义时,从左到右的顺序依次分配一个索引值,索引值从1开始65535个。
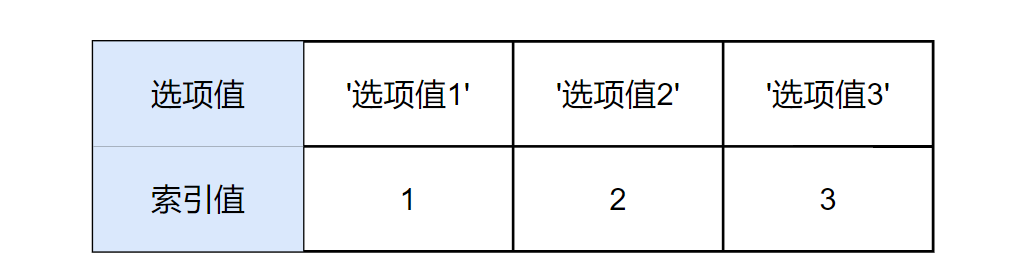
插入选项值索引。
mysql> insert into t11 (s) values (0); -- 插入 0 失败,因为从 1 开始
ERROR 1265 (01000): Data truncated for column 's' at row 1
mysql> insert into t11 (s) values (1); -- 插入 1 成功
Query OK, 1 row affected (0.00 sec)
mysql> insert into t11 (s) values (2); -- 插入 2 成功
Query OK, 1 row affected (0.00 sec)
mysql> insert into t11 (s) values (3); -- 插入 3 成功
Query OK, 1 row affected (0.01 sec)
mysql> insert into t11 (s) values (4); -- 插入 4 失败,因为没有第四个选项值
ERROR 1265 (01000): Data truncated for column 's' at row 1
mysql> select * from t11;
+------------+
| s |
+------------+
| 选项值1 |
| 选项值2 |
| 选项值3 |
+------------+
6 rows in set (0.00 sec)
插入选项值本身。
mysql> insert into t11 (s) values ('选项值1');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t11 (s) values ('选项值2');
Query OK, 1 row affected (0.01 sec)
mysql> insert into t11 (s) values ('选项值3');
Query OK, 1 row affected (0.01 sec)
mysql> select * from t11;
+------------+
| s |
+------------+
| 选项值1 |
| 选项值2 |
| 选项值3 |
| 选项值1 |
| 选项值2 |
| 选项值3 |
+------------+
6 rows in set (0.00 sec)
对比看到:无论是插入选项值索引还是插入选项值本身,都是一致的效果。
实际上,在 MySQL 中,ENUM 类型字段虽然表面上存储的是字符串值,但其底层实际上存储的是对应字符串枚举值的索引值(以 1 为起始的整数索引)。在插入和查询时,MySQL 会自动在字符串值和索引值之间进行转换。
换言之,当你插入数据时,无论插入的是字符串还是索引值,MySQL 都选项值对应的索引值。
说明:不建议在添加枚举值的时候采用数字索引的方式,因为不利于阅读。
索引为 0 的值表空串
索引为0的值表示空串,和NULL不同

3、条件查询
enum 类型可以直接使用 = 运算符进行条件查询。
mysql> select * from t11 where s = '选项值1';
+------------+
| s |
+------------+
| 选项值1 |
| 选项值1 |
+------------+
2 rows in set (0.00 sec)
六、集合类型 set
简单认知:集合类型 set 就是多选题,列举的众多元素,可以选择多个
1、语法
create table table_name (
column_name set('选项值1', '选项值2', '选项值3', ...)
);
2、要点说明
选项值只能是字符串。
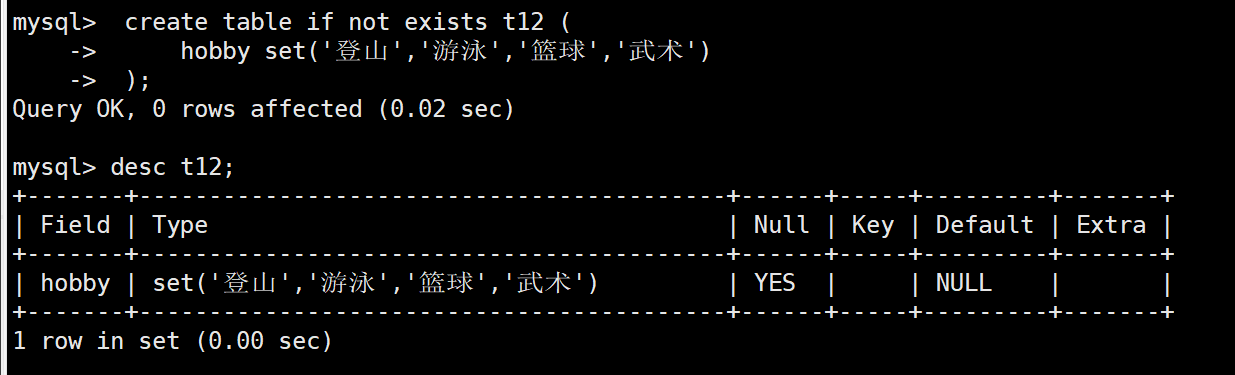
创建表 t12 字段 hobby 类型为 set,选项值不是字符串,表结构创建失败。
create table if not exists t12 ( hobby set(1, 2, 3, 4, 5) );
创建表 t12 字段 hobby 类型为 set,选项值是字符串,表结构创建成功。
create table if not exists t12 (
hobby set('登山','游泳','篮球','武术')
);
desc t12;
不能插入非选项值
向 t12 插入定义时不存在的 '羽毛球'。(这点就和 enum 是一样的)
mysql> insert into t12 values ('羽毛球');
SQL语句执行失败。
ERROR 1265 (01000): Data truncated for column 'hobby' at row 1
可以插入多个选项值
set 的特点是相比 enum 可以同时插入多个选项值。
插入时,字符串格式:'选项值1,选项值2,...',选项值之间用 , 分割。
mysql> insert into t12 values('登山,武术');
Query OK, 1 row affected (0.00 sec)
mysql> select * from t12;
+---------------+
| hobby |
+---------------+
| 登山,武术 |
+---------------+
1 row in set (0.00 sec)
使用索引值替换字符串插入
与 ENUM 类型不同,set 类型在 MySQL 中使用的是位图存储。对于 set 类型,每个可能的值都会分配一个唯一的二进制位,字段的存储值是所有选定值对应的二进制位的按位“或”操作结果。
说明:这里仅仅用于讲解,但不建议在添加集合值的时候采用数字的方式,因为不利于阅读。
以 t12 为例:
create table if not exists t12 (
hobby set('登山','游泳','篮球','武术')
);
MySQL 会按照定义的顺序从左往右依次给每个枚举值分配一个比特位:
'登山'-> 第1位(值:1,二进制:0001)'游泳'-> 第2位(值:2,二进制:0010)'篮球'-> 第3位(值:4,二进制:0100)'武术'-> 第4位(值:8,二进制:1000)
| 插入值 | 二进制表示 | 十进制索引值 |
|---|---|---|
'登山' | 0001 | 1 |
'游泳' | 0010 | 2 |
'登山,游泳' | 0011 | 3 |
'篮球' | 0100 | 4 |
'登山,篮球' | 0101 | 5 |
'游泳,篮球' | 0110 | 6 |
'登山,游泳,篮球' | 0111 | 7 |
mysql> insert into t12 values(1); -- 插入一个选项值
Query OK, 1 row affected (0.01 sec)
mysql> select * from t12;
+---------------+
| hobby |
+---------------+
| 登山,武术 |
| 登山 | -- 新插入的
+---------------+
2 rows in set (0.00 sec)
mysql> insert into t12 values(7); -- 插入三个选项值
Query OK, 1 row affected (0.00 sec)
mysql> select * from t12;
+----------------------+
| hobby |
+----------------------+
| 登山,武术 |
| 登山 |
| 登山,游泳,篮球 | -- 新插入的
+----------------------+
3 rows in set (0.00 sec)
可以发现 set 类似通过一种位图机制,实现多个元素传参
find_in_set 查询
这是 t12 表目前存储的内容。
mysql> select * from t12;
+----------------------+
| hobby |
+----------------------+
| 登山,武术 |
| 登山 |
| 登山,游泳,篮球 |
+----------------------+
3 rows in set (0.00 sec)
需求:想要查询所有包含【登山】爱好的记录(行)。
但是发现使用 = 运算符进行条件查询【选项值本身】就只能找到【爱好仅为登山】的记录(行),默认是一种严格匹配。
mysql> select * from t12 where hobby = '登山';
+--------+
| hobby |
+--------+
| 登山 |
+--------+
1 row in set (0.00 sec)
这时候就可以使用 find_in_set 内置函数进行查询,这种是非严格匹配
find_in_set(substring, string)的作用
- 如果
substring在string中,则返回下标。 - 如果不在,返回0。
string用逗号分隔的字符串。- 一个
find_in_set函数不能同时查找多个元素,如 a 和 b ,是否在集合 {a, b, c}
SQL 语句修改如下:
mysql> select * from t12 where find_in_set('登山', hobby);
+----------------------+
| hobby |
+----------------------+
| 登山,武术 |
| 登山 |
| 登山,游泳,篮球 |
+----------------------+
3 rows in set (0.00 sec)
说明:where 在语言中类似一种条件判断 if,后面可以跟表达式,若该表达式为true,则返回结果
既然 where 在语言中类似一种条件判断 if,我们也可以在 where 后面跟上多个表达式,要求多个表达式同时满足,只需在多个表达式之间加上 and,这个在语言中类似 &&,如下:
需求:查询爱好包含【登山】和【篮球】的记录(行)。
SQL 语句如下:
mysql> select * from t12 where find_in_set('登山', hobby) and find_in_set('篮球', hobby);
+----------------------+
| hobby |
+----------------------+
| 登山,游泳,篮球 |
+----------------------+
1 row in set (0.00 sec)
注:本文大部分内容借鉴于博客【https://blog.csdn.net/ljh1257/article/details/145066867】,我的本篇博客主要是对这篇博客进行结构逻辑优化,并且添加一些补充内容与运行图片展示。