【MySQL】数据库基础
目录
连接MySQL服务器
什么是数据库
SQL分类
库的操作
创建数据库
系统编码
查看数据库编码集
查看数据库校验集
查看数据库支持的字符集
修改数据库
删除数据库
确认当前是在哪个数据库
备份和恢复
查看当前有谁在使用数据库
表操作
创建表
查看表结构
编辑
修改表
修改表名
新增列
修改列属性
删除列
数据类型
数值类型
BIT类型
小数类型
decimal
字符串类类型
char类型
varchar类型
char和varchar比较
日期和时间类型
枚举类型
enum
set
连接MySQL服务器
mysql -h 127.0.0.1 -P 3306 -u root -p- -h:指明登录部署了mysql服务的主机
- -P:指明我们要访问的端口号
- -u:指明登录用户
- -p:指明需要输入密码
什么是数据库
问题抛出:存储数据使用文件就可以了,为什么还需要使用数据库?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
一般的文件确实已经提供了数据的存储功能,但是文件没有提供非常好的数据管理能力,数据库的本质就是对数据内容存储的一套解决方案,得到字段或者要求,返回结果即可。
- mysql是数据库服务的客户端
- mysqld是数据库服务的服务器端
mysql是一套提供数据存取服务的网络程序,本质是基于C(mysql)S(mysqld)模式的一种网络服务。
数据库一般指的是,在磁盘或内存中存储的特定结构组织的数据。
SQL分类
1、DDL:数据定义语言,用来维护存储数据的结构,代表指令:create、drop、alter
2、DML:数据操纵语言,用来对数据进行操作,代表指令:insert、delete、update。
- DML中又单独分了一个DQL:数据查询语言,代表指令select
3、DCL:数据控制语言,主要负责权限管理和事务,代表指令:grant、revoke、commit
库的操作
创建数据库
CREATE DATABASE IF NOT EXISTS db_name;
系统编码
创建数据库的时候,有两个编码集:
- 数据库编码集 --- 数据库未来存储数据采用的编码集。
- 数据库校验集 --- 数据库进行字段比较使用的编码,本质上也是一种读取数据库中数据采用的编码格式。
数据库无论对数据做任何操作,都必须保证操作和编码必须是编码一致的。
查看数据库编码集
show variables like 'character_set_database';可以看到,目前我们数据库的编码集是utf8的。
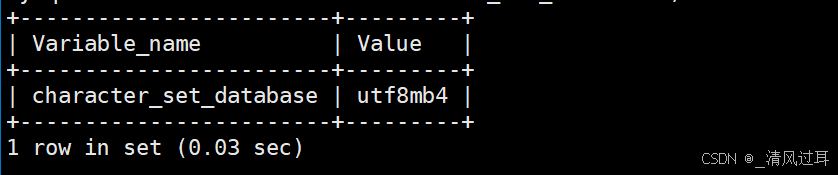
查看数据库校验集
show variables like 'collation_database'结果如下:
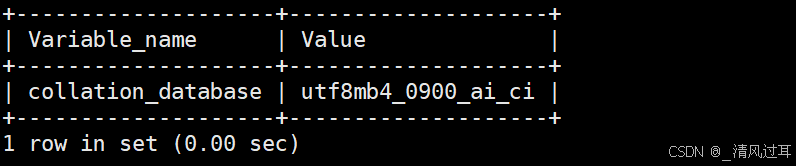
查看数据库支持的字符集
show charset;这里只展示部分结果:
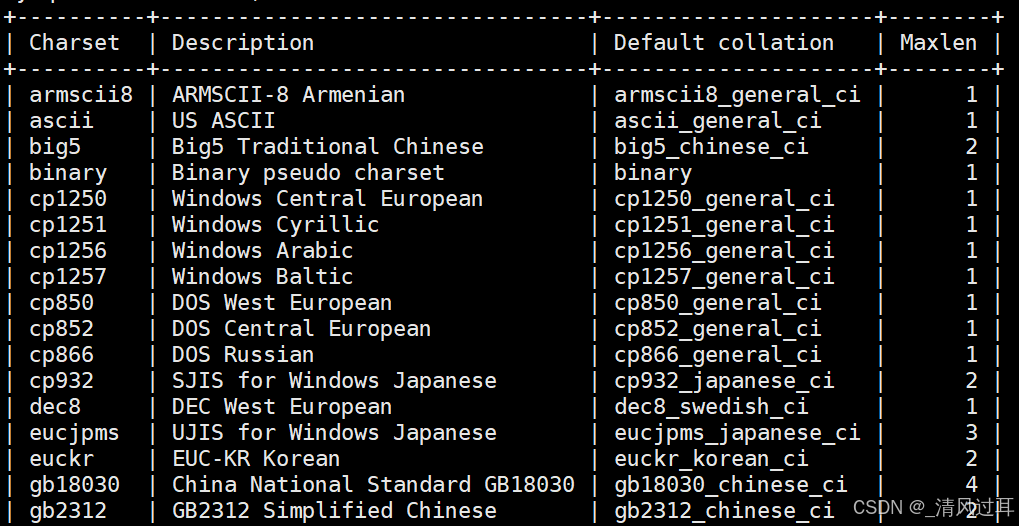 当我们在创建数据库时没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则:utf8_general_ci
当我们在创建数据库时没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则:utf8_general_ci
- 创建一个使用utf8字符集的名为'db2'的数据库
#第一种方法
create database db2 charset=utf8;
#第二种方法
create database db2 charset set utf8;- 创建一个使用utf字符集,并带校对规则的'db3'数据库。
create database db3 charset=utf8 collate utf8_general_ci;utf8_general_ci校验集不区分大小写。
修改数据库
修改数据库的编码集和校验集
alter database test1 charset=gbk collate gbk_chinese_ci;删除数据库
DROP DATABASE IF EXISTS db_name;确认当前是在哪个数据库
SELECT DATABASE();备份和恢复
备份
mysqldump -P3306 -u root -p -B 数据库名 > 数据库备份存储的文件路径;如果备份的是张表
mysqldump -P3306 -u root -p -B 数据库名 表名1 表名2 > 数据库备份存储的文件路径;还原
source 文件路径名(.sql结尾的文件);查看当前有谁在使用数据库
show processlist;表操作
创建表
语法:
CREATE TABLE table_name(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校验规则 engine 存储引擎;
说明:
- field 表示列名
- datatype 表示列的类型
- character set 字符集,如果没有指定字符集,则以所在数据库的字符集为准
- collate 校验规则,如果没有指定校验规则,则以所在数据库的校验规则为准
查看表结构
desc 表名 ;
结果如下:

修改表
修改表名
alter table 原表名 rename to 新表名;
- to可省略。
新增列
alter table 表名 add 新增列名 类型 comment '备注' after 列名(新增列名放到哪一列的后面);
修改列属性
第一种方法:
alter table 表名 modify 列名 新改的类型;
- modify会把对应的列名原本的属性全部覆盖
第二种方法:
alter table 表名 change column 原来的列名 新的列名 新列的属性
删除列
alter table 表名 drop 列名;
- 删除列需要谨慎,对应的列数据也会被删除。
数据类型
数值类型
| 类型 | 字节 | 最小值 | 最大值 |
| 带符号的/无符号的 | 带符号的/无符号的 | ||
| TINYINT | 1 | -128 | 127 |
| TINYINT UNSIGNED | 0 | 255 | |
| SMALLINT | 2 | -32768 | 32767 |
| 0 | 65535 | ||
| MEDIUMINT | 3 | -8388608 | 83688607 |
| 0 | 16777215 | ||
| INT | 4 | -2147483648 | 2147483647 |
| 0 | 4294967295 | ||
| BIGINT | 8 | -9223372036854775808 | 9223372036854775807 |
| 0 | 18446744073709551615 |
BIT类型
语法:
bit [(M)] :位字段类型,M表示每个值的位数,范围从1到64,如果M被忽略,默认为1。
小数类型
语法:
float [(m,d)] [unsigned]:
- M指定显示的长度(包含小数位数,整数部分长度=M-d)
- d指定小数位数
- 占用空间4个字节
- float(4,2)范围是-99.99~99.99,如果指定unsigned,直接将[-99.99,0]变成非法数据,不进行扩展。
- 如果不指定(m,d),直接使用float,当精度到达一定长度(正常是7位)或整体长度过长时,会损失精度。
当多出的位数是小数部分的话, 会进行四舍五入,比如
float (4,2); 90.976 插入可以成功,会四舍五入称90.98,在-99.99~99.99范围内,会进行四舍五入。
但是当99.996时四舍五入会变成100.00超出指定长度,导致插入失败。
decimal
语法:
decimal (m,d) [unsigned]
- 定点数m指定长度
- d表示小数点后的位数
- 有效规避float的精度损失
- decimal整数最大位数m为65,支持最大位数d是30,如果d省略,默认0,m省略,默认10
字符串类类型
char类型
语法:
char(L):固定长度的字符串,L是可以存储的长度,单位为字符,最大长度值可以为255
varchar类型
语法:
varchar(L):可变长度字符串,L表示字符长度,最大长度65535个字节
- varchar(len),len值和表的编码密切相关,len是指定最大分配的大小,在len范围内,用多少给多少。而char是固定大小,你指定多少,就给多少。
- varchar长度可以指定0到65535之间的值,但是有1-3字节用于记录数据大小(也就是varchar有效数据长度),所以实际有效字节数是65532。
- 使用utf8编码时,varchar(n)的参数n最大值65532/3=21844(因为utf8一个字符占3个字节)。
- 使用gbk编码时,varchar(n)的参数n最大值65532/2=32766(因为gbk一个字符占2个)。
char和varchar比较
| 实际存储 | char(4) | varchar(4) | char占用字节 | varchar占用字节 |
| abcd | abcd | abcd | 4*3=12 | 4*3+1=13(+多少取决于字符长度,这里只有12,用1字节表示即可) |
| A | A | A | 4*3=12 | 1*3+1=4 |
- 如果确定长度一样,就是用定长(char),比如身份证号。
- 如果数据长度有变化,就使用变长,比如:名字。
- 定长的磁盘空间比较浪费,但是效率高。
- 边长的磁盘空间比较节省,但是效率低。
日期和时间类型
- date:日期'yyyy-mm-dd',占用三字节。
- datetime:时间日期格式 'yyyy-mm-dd HH:ii:ss' 表示范围从1000到9999,占用八字节。
- timestamp:时间戳,从1970年开始, 'yyyy-mm-dd HH:ii:ss'格式与datetime一致,占用四字节。
第一种和第二种需要程序员自己以字符串的形式输入数据,timestamp会自动更新。
枚举类型
enum
enum:枚举,“单选”类型。
语法:
enum('选项1','选项2','选项3',...)
- 插入值时,除了直接插入选项值以外,也可以直接插入选项值下标(从1开始)
set
set:集合,“多选”类型。
语法:
set('选项1','选项2','选项3',...)
- 插入方式:insert into 表名 values ('选项1,选项2,选项3')
- 也可以不使用选项值,传入相应比特位为1的数字(比如传入3,011第一个爱好和第二个爱好被选择),也就是用位图的方式,0表示空串不会显示NULL,1表示对应选项1
- enum和set可以为空,不插入值,显示为NULL
如果要查找set类型中包含某种选项的数据,使用find_in_set函数
示例:
select * from votes where find_in_set('羽毛球',hobby);
- votes为表名
- hobby为set集合类型的字段
- 查询爱好有羽毛球