DeepGEMM 论文和实现浅析(二)
官方测试代码
DeepGEMM 官方自带 test_jit.py 测试动态编译
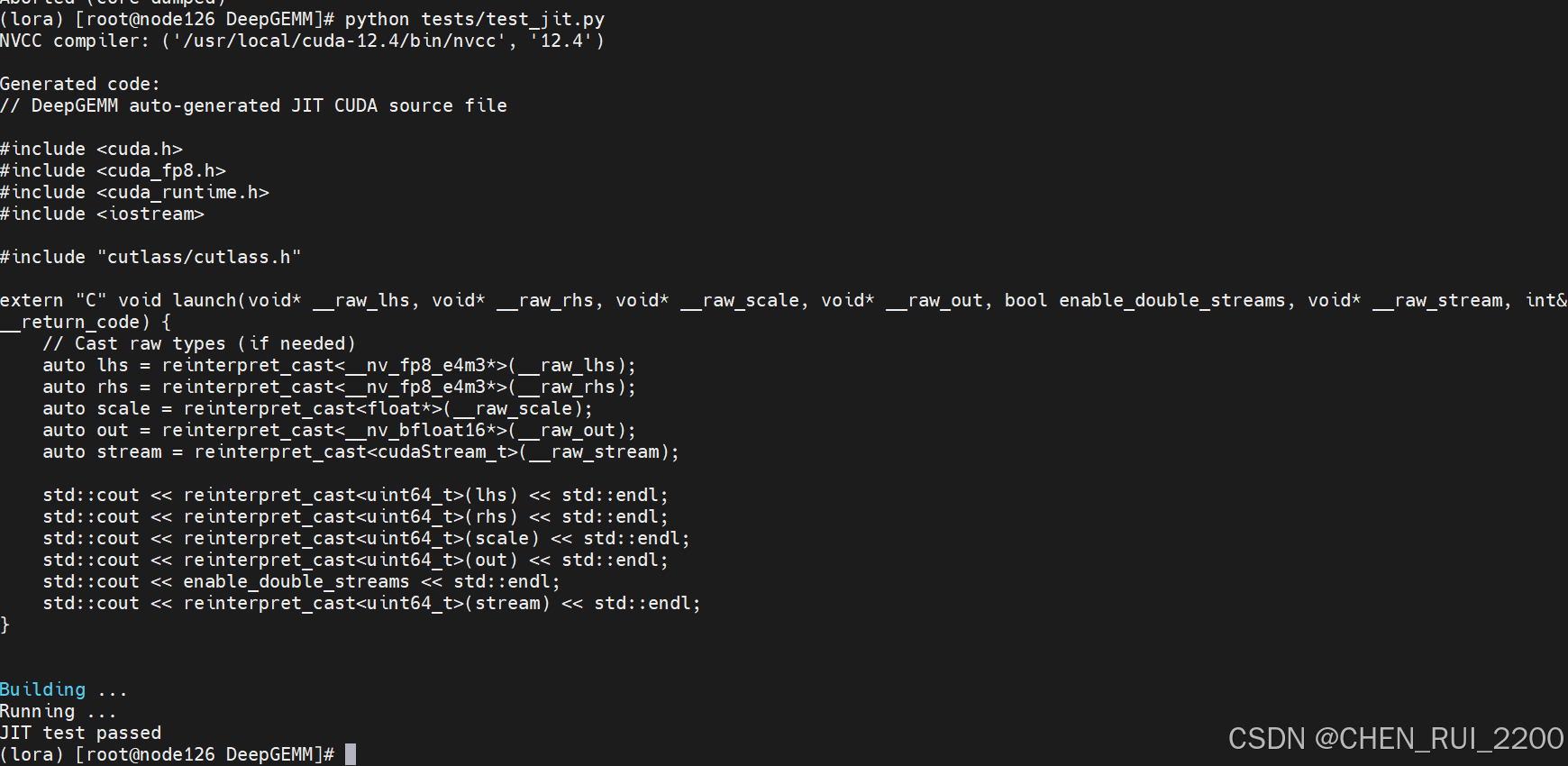
test_core.py 主要用于验证其 FP8 (8-bit floating-point) 矩阵乘法 (GEMM, General Matrix Multiply) 的正确性和性能。代码包含三个主要的测试函数,分别测试普通 GEMM、分组连续 GEMM 和分组掩码 GEMM 的功能
1. 核心功能与辅助函数
per_token_cast_to_fp8 和 per_block_cast_to_fp8
def per_token_cast_to_fp8(x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
assert x.dim() == 2 and x.size(1) % 128 == 0
m, n = x.shape
x_view = x.view(m, -1, 128)
x_amax = x_view.abs().float().amax(dim=2).view(m, -1).clamp(1e-4)
return (x_view * (448.0 / x_amax.unsqueeze(2))).to(torch.float8_e4m3fn).view(m, n), (x_amax / 448.0).view(m, -1)
def per_block_cast_to_fp8(x: torch.Tensor) -> Tuple[torch.Tensor, torch.Tensor]:
assert x.dim() == 2
m, n = x.shape
x_padded = torch.zeros((ceil_div(m, 128) * 128, ceil_div(n, 128) * 128), dtype=x.dtype, device=x.device)
x_padded[:m, :n] = x
x_view = x_padded.view(-1, 128, x_padded.size(1) // 128, 128)
x_amax = x_view.abs().float().amax(dim=(1, 3), keepdim=True).clamp(1e-4)
x_scaled = (x_view * (448.0 / x_amax)).to(torch.float8_e4m3fn)
return x_scaled.view_as(x_padded)[:m, :n].contiguous(), (x_amax / 448.0).view(x_view.size(0), x_view.size(2))
这两个函数将输入张量从 bfloat16 转换为 float8_e4m3fn (FP8 格式,4-bit 指数,3-bit 尾数,无 NaN)。FP8 是一种低精度浮点格式,用于加速计算并减少内存使用。
- per_token_cast_to_fp8:
- 输入张量维度为 (m, n),要求 n 是 128 的倍数。
- 将张量按每 128 个元素分块,计算每块的最大绝对值 (x_amax),并根据此值进行缩放后转换为 FP8。
- 返回转换后的 FP8 张量和缩放因子 (x_amax / 448.0)。
- 缩放因子 448.0 是 FP8 格式的最大值,用于归一化。
- per_block_cast_to_fp8:
- 输入张量维度为 (m, n),无需特定对齐要求。
- 将张量填充到 128 的倍数,按 (128, 128) 块计算最大绝对值并转换。
- 返回裁剪到原始大小的 FP8 张量和缩放因子。
construct 和 construct_grouped
这两个函数用于生成测试数据:
- construct:
- 生成随机输入矩阵 x (m × k) 和 y (n × k),计算参考输出 ref_out = x @ y.t()。
- 将 x 和 y 转换为 FP8 格式,返回 FP8 输入、输出张量和参考结果。
- construct_grouped:
- 为分组 GEMM 生成数据,输入维度为 (num_groups, m, k) 和 (num_groups, n, k)。
- 根据是否掩码 (is_masked) 处理维度合并,并返回 FP8 格式的输入和输出。
2. 测试函数
test_gemm
def test_gemm() -> None:
print('Testing GEMM:')
for m in (64, 128, 4096):
for k, n in [(7168, 2112), (1536, 24576), (512, 32768), (16384, 7168), (7168, 4096), (2048, 7168)]:
x_fp8, y_fp8, out, ref_out = construct(m, k, n)
deep_gemm.gemm_fp8_fp8_bf16_nt(x_fp8, y_fp8, out)
diff = calc_diff(out, ref_out)
assert diff < 0.001, f'{m=}, {k=}, {n=}, {diff:.5f}'
# noinspection PyShadowingNames
def test_func():
# Construct new tensors every time to avoid L2 cache acceleration
x_fp8, y_fp8, out, ref_out = construct(m, k, n)
deep_gemm.gemm_fp8_fp8_bf16_nt(x_fp8, y_fp8, out)
t = bench_kineto(test_func, 'fp8_gemm', suppress_kineto_output=True)
print(f' > Performance (m={m:5}, n={n:5}, k={k:5}): {t * 1e6:4.0f} us | '
f'throughput: {2 * m * n * k / t / 1e12:4.0f} TFLOPS, '
f'{(m * k + k * n + m * n * 2) / 1e9 / t:4.0f} GB/s')
pass测试普通的 FP8 GEMM 操作:
- 测试流程:
- 遍历多种矩阵尺寸 (m, k, n)。
- 使用 construct 生成测试数据,调用 deep_gemm.gemm_fp8_fp8_bf16_nt 执行矩阵乘法。
- 使用 calc_diff 计算输出与参考结果的差异,断言误差小于 0.001。
- 使用 bench_kineto 测量性能,输出执行时间、计算吞吐量 (TFLOPS) 和内存带宽 (GB/s)。
- 关键点:
- 输入为 FP8 格式,输出为 bfloat16。
- 每次测试重新生成数据,避免缓存影响性能测量。
test_m_grouped_gemm_contiguous
def test_m_grouped_gemm_contiguous() -> None:
print('Testing grouped contiguous GEMM:')
for num_groups, m, k, n in ((4, 8192, 7168, 4096), (4, 8192, 2048, 7168), (8, 4096, 7168, 4096), (8, 4096, 2048, 7168)):
# TODO: make a stronger test
x_fp8, y_fp8, out, ref_out = construct_grouped(num_groups, m, k, n, is_masked=False)
m_indices = torch.arange(0, num_groups, device='cuda', dtype=torch.int)
m_indices = m_indices.unsqueeze(-1).expand(num_groups, m).contiguous().view(-1)
deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_contiguous(x_fp8, y_fp8, out, m_indices)
diff = calc_diff(out, ref_out)
assert diff < 0.001, f'm={m * num_groups}, {k=}, {n=}, {diff:.5f}'
# noinspection PyShadowingNames
def test_func():
# Construct new tensors every time to avoid L2 cache acceleration
x_fp8, y_fp8, out, ref_out = construct_grouped(num_groups, m, k, n, is_masked=False)
m_indices = torch.arange(0, num_groups, device='cuda', dtype=torch.int)
m_indices = m_indices.unsqueeze(-1).expand(num_groups, m).contiguous().view(-1)
deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_contiguous(x_fp8, y_fp8, out, m_indices)
t = bench_kineto(test_func, 'fp8_gemm', suppress_kineto_output=True)
print(f' > Performance ({num_groups=}, m_per_group={m:4}, n={n:4}, k={k:4}): {t * 1e6:4.0f} us | '
f'throughput: {2 * num_groups * m * n * k / t / 1e12:4.0f} TFLOPS, '
f'{(num_groups * (m * k + k * n + m * n * 2)) / 1e9 / t:4.0f} GB/s')
pass测试分组连续 GEMM:
- 测试流程:
- 测试多个分组配置 (num_groups, m, k, n)。
- 使用 construct_grouped 生成数据(无掩码),调用 deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_contiguous。
- 生成连续的组索引 m_indices,验证结果正确性并测量性能。
- 关键点:
- 分组维度与 m 维度合并为单一维度,适合连续内存访问。
- 性能指标考虑所有组的总计算量。
test_m_grouped_gemm_masked
测试分组掩码 GEMM:
- 测试流程:
- 测试多种 (num_groups, m, k, n) 配置。
- 使用 construct_grouped 生成数据(有掩码),随机选择每组的掩码大小 masked_m。
- 调用 deep_gemm.m_grouped_gemm_fp8_fp8_bf16_nt_masked,验证每组掩码部分的正确性。
- 性能测试使用固定掩码(全 m)测量。
- 关键点:
- 掩码允许每组处理不同数量的行 (masked_m),模拟动态形状。
- 性能测量假设最坏情况(全用 m)。
3. 性能测量与指标
- bench_kineto:
- 使用 Kineto 工具测量函数执行时间,返回平均时间 (秒)。
- 吞吐量计算公式:2 * m * n * k / t / 1e12 (TFLOPS),表示每秒浮点运算次数。
- 带宽计算公式:(m * k + k * n + m * n * 2) / 1e9 / t (GB/s),考虑输入和输出数据的总字节数。
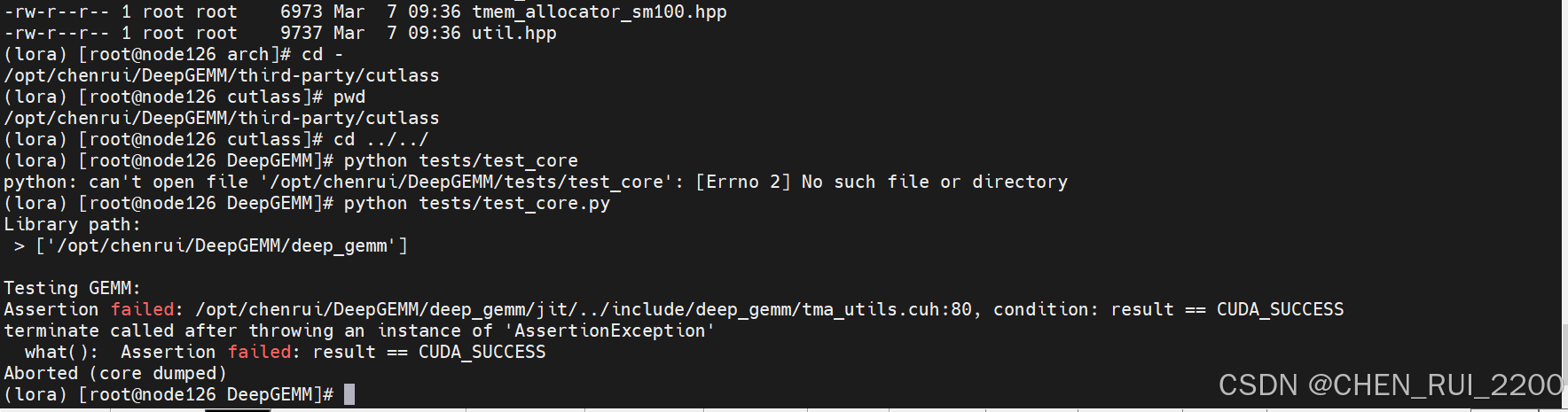
运行出现错误
Testing GEMM:
Assertion failed: /opt/chenrui/DeepGEMM/deep_gemm/jit/../include/deep_gemm/tma_utils.cuh:80, condition: result == CUDA_SUCCESS
terminate called after throwing an instance of 'AssertionException'
what(): Assertion failed: result == CUDA_SUCCESS
Aborted (core dumped)
40/50 显卡不支持问题根源
主要原因是GPU 是 NVIDIA GeForce RTX 4090。这是一个基于 Ada Lovelace 架构的 GPU(SM 8.9),支持 CUDA 12.4,但 不支持 TMA (Tensor Memory Access),因为 TMA 是专为 NVIDIA Hopper 架构(如 H100)设计的特性。之前报错的原因正是由于 deep_gemm 代码尝试调用 TMA 相关的功能(例如 get_col_major_tma_aligned_tensor),而 RTX 4090 不支持这些操作,导致 result != CUDA_SUCCESS 的断言失败。
- TMA 不支持:tma_utils.cuh 中的代码依赖 TMA,而 RTX 4090(Ada Lovelace)不支持此功能。看了下 issue里确实有人在做40/50 显卡的适配工作。

看到有人在做的尝试
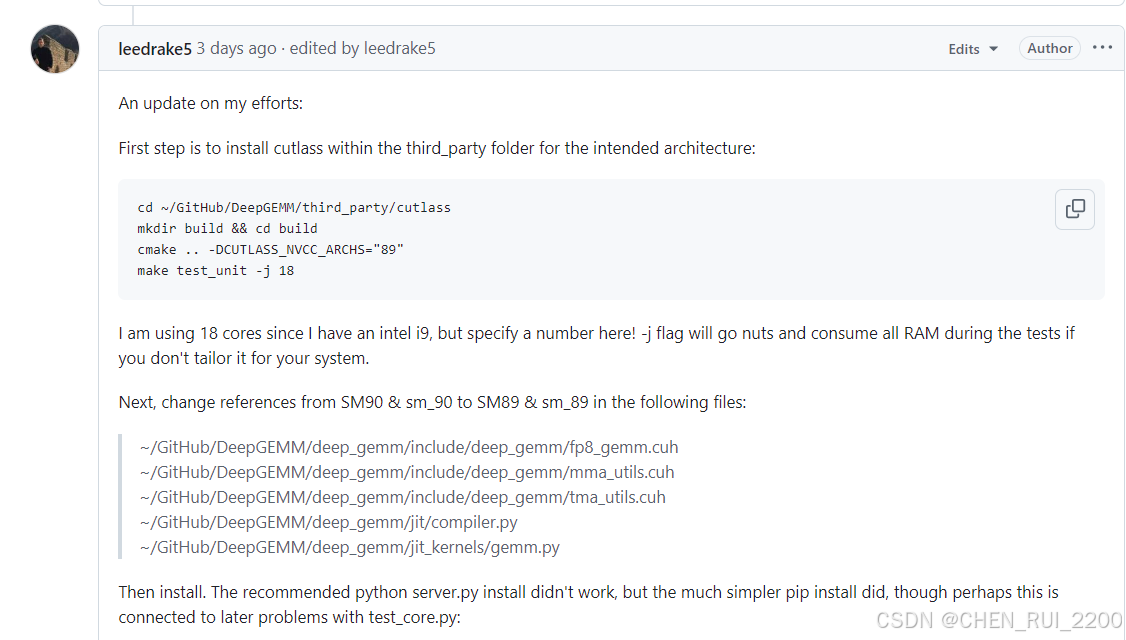
- cd ~/GitHub/DeepGEMM/third_party/cutlass:
- 进入 DeepGEMM 项目中集成的 CUTLASS 子模块目录。CUTLASS 是 DeepGEMM 的底层依赖,提供高效的 GEMM(矩阵乘法)实现。
- mkdir build && cd build:
- 创建一个 build 目录并进入,用于存放编译生成的中间文件和目标文件。这是 CMake 的常见做法,避免污染源代码目录。
- cmake .. -DCUTLASS_NVCC_ARCHS="89":
- 目的:配置 CUTLASS 的构建过程,指定目标 GPU 架构为 SM 8.9(RTX 4090 的计算能力)。
- -DCUTLASS_NVCC_ARCHS="89":
- 89 表示 CUDA 计算能力 8.9,这是 RTX 4090 的架构。
- CUTLASS 使用模板生成针对特定 GPU 架构优化的内核,指定正确的架构可以确保生成的代码充分利用 RTX 4090 的硬件特性(如 FP8 支持、Tensor Core 等)。
- 如果不指定,默认可能针对其他架构(如 Hopper SM 9.0),导致性能下降或不兼容。
- make test_unit -j 18:
- 目的:编译 CUTLASS 的单元测试并验证其功能。
- test_unit:构建并运行 CUTLASS 的单元测试目标,确保库在指定架构上的正确性。
- -j 18:并行编译,使用 18 个线程加速构建(适合多核 CPU,例如 18 核或更多)。
- 解决 TMA 不支持问题:
- 如前所述,RTX 4090(Ada Lovelace, SM 8.9)不支持 Hopper 架构(SM 9.0)的 TMA 特性。
- 默认的 DeepGEMM 可能针对 Hopper 编译,包含 TMA 调用(例如 tma_utils.cuh),导致之前的错误。
- 通过将 CUTLASS 配置为 SM 8.9,可以避免生成依赖 TMA 的代码,改为使用 RTX 4090 支持的常规内存访问和计算路径。
# 执行
cd third-party/cutlass
# 创建目录
mkdir build && cd build
# 编译
cmake .. \
-DCUTLASS_NVCC_ARCHS="89" \
-DCMAKE_CUDA_COMPILER=/usr/local/cuda-12.4/bin/nvcc \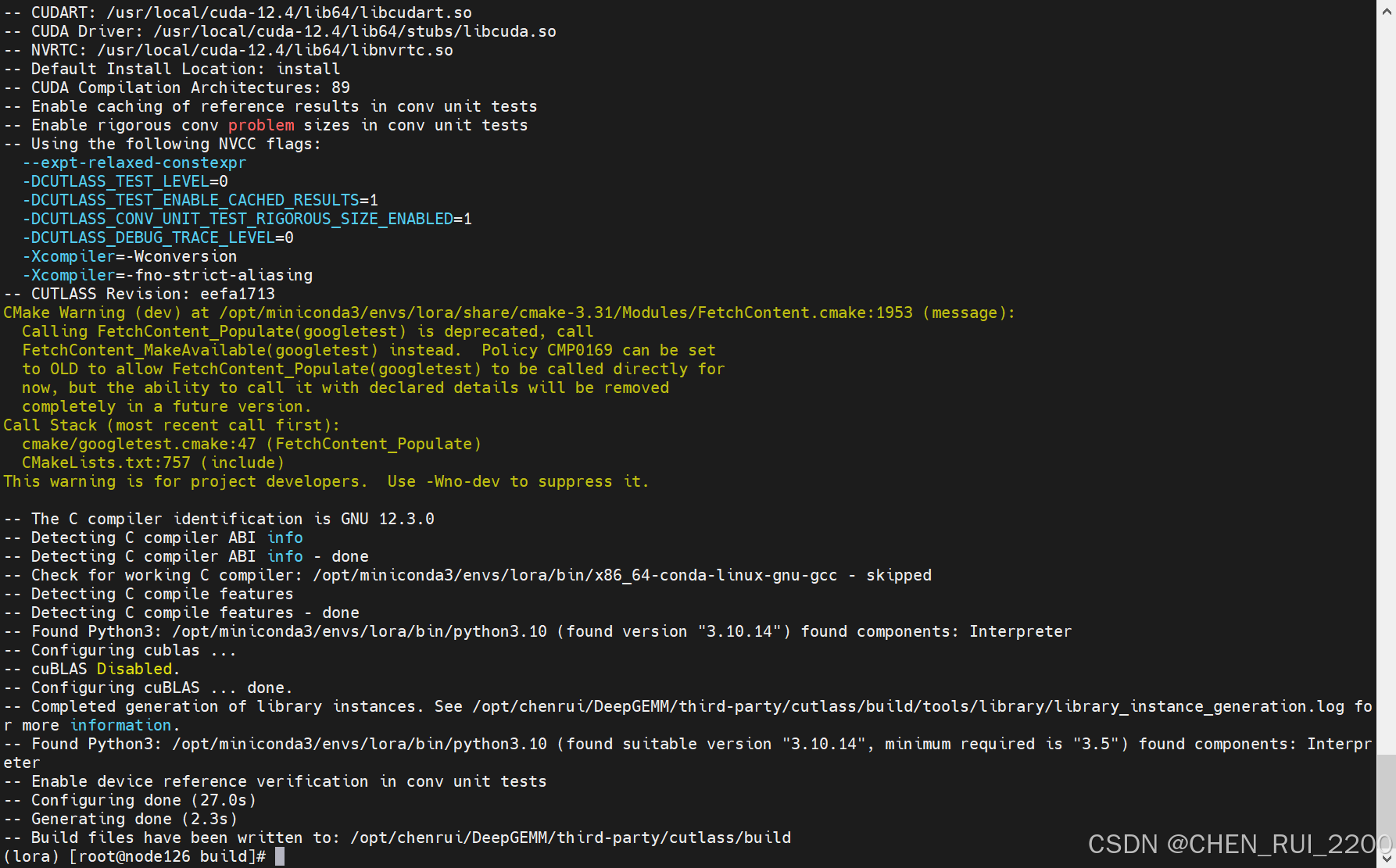
编译成功
下载是全局把#include <cute/arch/cluster_sm90.hpp>
替换为#include <cute/arch/cluster_sm89.hpp>
更新后测试test_jit.py 成功
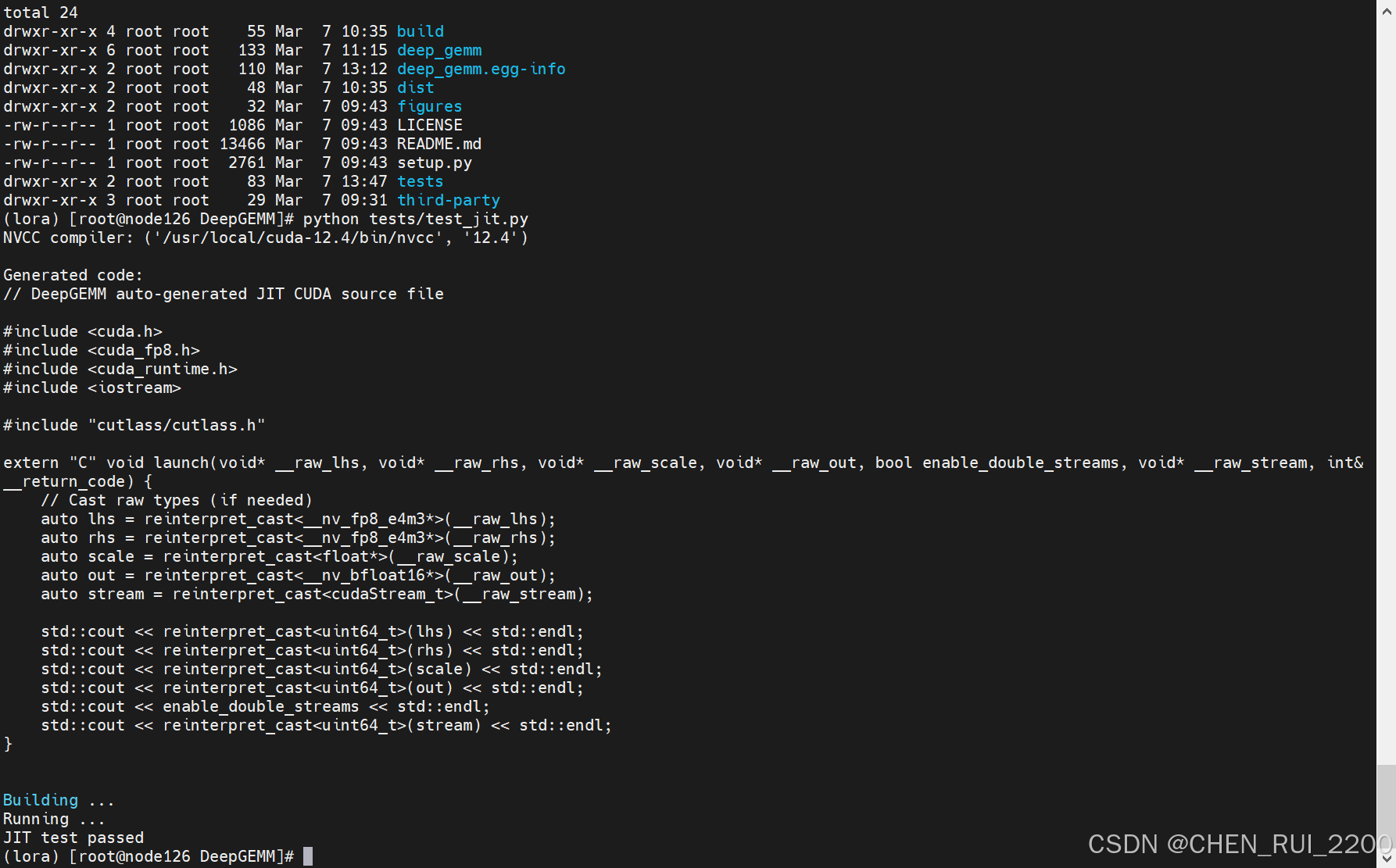
测试test_core.py
看起来 CUTLASS 并没有编译类似于 cluster_sm90.hpp 的 cluster_sm89.hpp 文件,可能是因为这些 GPU 不是为了作为服务器的工作马。因此,cluster 可能无法正常工作。但有可能将测试文件拆分,看看它是否能在单个 GPU 上运行。接下来会对此进行尝试。目前看来只有 JIT 仍然能够工作。
我现在的希望是重新编译他们的 CUTLASS 版本以支持 sm_89,并且这些文件只需要被编译。
让子弹飞一会儿吧,看看有没有哪个大佬搞出来