Linux进程信号(Ⅱ)
目录
1. 信号产生方式
1. 键盘产生
2. kill命令产生
3. 系统调用函数
3.1 kill
3.2 raise
3.3 abort
3.4 使用系统调用函数
4. 软件条件
4.1 alarm函数
4.2 pause函数
4.3 模拟OS工作过程
5.异常
2. Core & Term
2.1 ulimit命令
1. 信号产生方式
1. 键盘产生
在 Linux系统中,用户可以通过键盘输入特定的组合键,向当前前台进程发送信号。这些信号通常用于中断、终止或挂起进程。
常见组合键及其对应信号:
Ctrl + C → 发送 SIGINT(信号编号 2),通常用于中断进程。
Ctrl + \ → 发送 SIGQUIT(信号编号 3),通常用于退出进程并生成核心转储(core dump)。
Ctrl + Z → 发送 SIGTSTP(信号编号 20),用于挂起进程(放入后台)。
注意:这些信号可以被进程捕获、忽略或执行默认操作。
2. kill命令产生
kill命令是用户空间中用于向指定进程发送信号的常用工具,其基本语法:
kill -信号编号 进程PID
例如:kill -9 1234 //向 PID 为 1234 的进程发送 SIGKILL(9)信号
前面的文章中我们已经使用过很多次了,它的用法也很简单,所以我就不多赘述了
3. 系统调用函数
3.1 kill
kill函数是kill命令底层调用的函数,向指定进程发送指定信号,具体用法也和kill命令相似:
#include <sys/types.h>
#include <signal.h>int kill(pid_t pid, int sig);
3.2 raise
rise()向当前进程发送指定信号sig,具体语法:
#include <signal.h>
int raise(int sig);
3.3 abort
abort()用于使当前进程异常终止,并产生 SIGABRT 信号(编号 6)。该信号默认行为是终止进程并生成核心转储。
#include <stdlib.h>
void abort(void);
3.4 使用系统调用函数
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
#include<sys/wait.h>
#include<signal.h>void handler(int signo)
{printf("进程%d捕捉到了%d号信号\n",getpid(),signo);
}int main()
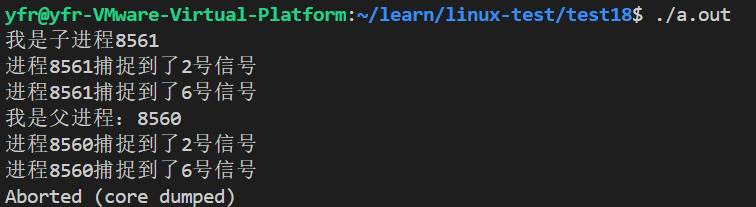
{signal(2,handler);signal(3,handler);signal(6,handler);pid_t id = fork();if(id == 0){printf("我是进程%d\n",getpid());kill(getpid(),2);abort();}waitpid(id,NULL,0);printf("我是父进程:%d\n",getpid());raise(2);abort();return 0;
}运行结果:
4. 软件条件
这类信号并非由用户直接触发,而是由程序运行时的某种软件状态或条件自动触发。底层操作系统监控这些条件,并在条件满足时自动向进程发送相应的信号。
常见例子:
当进程向已经关闭写端的管道进行写操作时,内核会向该进程发送 SIGPIPE 信号(编号13);
由 alarm() 函数设置的定时器超时后,内核会向进程发送 SIGALRM 信号(编号14)。
4.1 alarm函数
基本语法:
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
该函数的作用是告诉该进程过seconds秒后向进程发送一个SIGALRM信号(编号14)。
alarm调用只执行一次,以最新的闹钟为准,第二次设置闹钟的新时间,会取消上一个闹钟,并返回上一个闹钟的剩余时间
我们浅浅的使用一下
#include<stdio.h>
#include<unistd.h>int main()
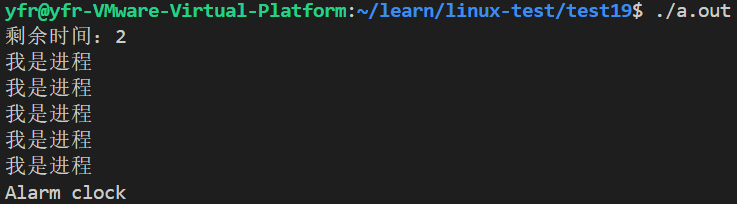
{alarm(3);sleep(1);int n = alarm(5);printf("剩余时间:%d\n",n);while(1){printf("我是进程\n");sleep(1);}return 0;
}运行结果:
那么OS就要把不同这些alarm管理起来。对闹钟alarm的管理方案:“ 先描述,再组织 ”——设置一个关于闹钟的结构体
struct alarm
{
uint64_t timeout;//时钟到期时间戳(绝对时间),当前时间戳+时钟时间
uint32_t id;//闹钟唯一标识符
task_struct *pcb;//使用这个alarm的进程
//......
}
将这些结构体以timeout为键值用一个最小堆组织起来,堆顶的闹钟,永远是所有闹钟中 timeout 最小的那个,即最早要超时的那个。
▶那么如何判断alarm是否超时呢?
操作系统通过检测堆顶的timeout和当前时间戳的大小判断是否超时。如果超时,则弹出堆顶并通知对应进程,然后循环检查下一个,直到没有闹钟超时为止。
下面我们来通过alarm设置一个案例来感受内核操作和IO操作的效率:
#include<stdio.h>
#include<stdlib.h>
#include<signal.h>
#include<unistd.h>long long cnt = 0;void handler(int signo)
{printf("捕捉到%d信号,当前计数器:%lld\n",signo,cnt);exit(0);
}
int main()
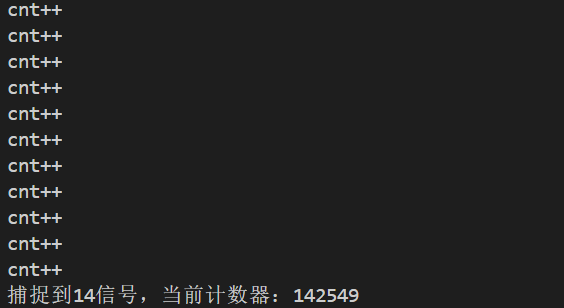
{signal(SIGALRM,handler);alarm(1);while(1){cnt++;//内存操作printf("cnt++\n");//IO操作}return 0;
}有IO操作时的运行结果:
屏蔽掉printf时的运行结果:

我们可以通过这两个数据非常清楚的感受到IO操作的效率之低。
4.2 pause函数
功能:挂起调用进程,直到收到一个信号。
#include<unistd.h>
int pause();
#include<stdio.h>
#include<signal.h>
#include<unistd.h>void handler(int signo)
{printf("捕捉到了信号%d\n",signo);alarm(1);
}int main()
{signal(SIGALRM,handler);alarm(1);while(1){pause();//等待信号}return 0;
}这段代码利用pause函数和alarm函数做到了不用sleep也能实现每秒打印一次的效果。
4.3 模拟OS工作过程
下面我们写一段代码来模拟OS是如何因为中断而调度起来的:
#include<iostream>
#include<functional>
#include<vector>
#include<signal.h>
#include<unistd.h>using func_t = std::function<void()>;
std::vector<func_t> cb;void FlushDisk()
{std::cout<<"我是刷盘操作"<<std::endl;
}
void Sched()
{std::cout<<"我是进程调度操作"<<std::endl;
}void handler(int signo)
{for(auto f:cb){f();//执行任务}std::cout<<"捕捉到了一个信号:"<<signo<<std::endl;alarm(1);
}int main()
{cb.push_back(FlushDisk);cb.push_back(Sched);signal(SIGALRM,handler);alarm(1);while(1){pause();//等待信号}return 0;
}代码执行结果:每秒执行一次FlushDisk和Sched任务
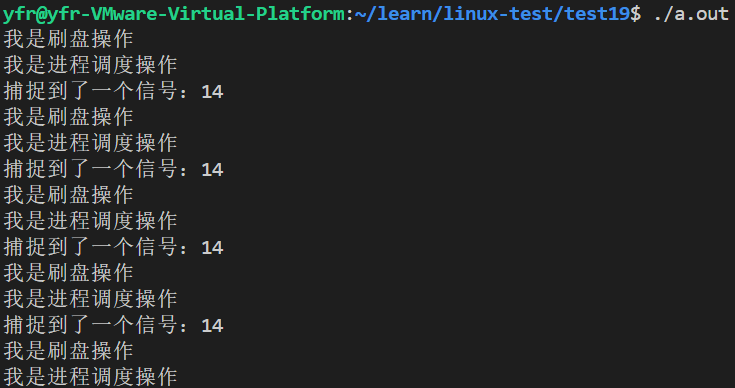
主循环通过 pause() 等待“中断”发生,而由 alarm 定时触发的 SIGALRM 信号则模拟了硬件定时器中断;当信号抵达时,操作系统(main)被“唤醒”并执行中断处理程序(handler),该处理程序会依次执行预先注册在任务队列 cb 中的各个内核任务(如 FlushDisk、Sched),从而模拟了操作系统因中断而调度执行关键任务的工作流程。
5.异常
大家应该都遇到过除0或者野指针这种情况,此时编译程序会崩溃
▶那么为什么出现这种异常会导致程序崩溃呢?
用一段比较官方的话来说就是:当程序执行除零、访问野指针等这类非法操作时,会触发CPU级别的硬件异常,操作系统接收到这些异常后,会向违反规则的进程发送相应的信号(如SIGFPE用于算术错误,SIGSEGV用于内存访问违规),而默认的信号处理行为就是终止进程并生成核心转储,因此程序表现为崩溃。
这段话里面有两个点需要解释一下:一个是CPU级别的硬件异常,另一个是核心转储。
CPU是一个非常死板、只会按规矩办事的机器,当我们让它进行除零或者访问野指针这种违规操作时,它按照它的办事手册无法执行,就会马上告诉操作系统说:“这个事我办不了”,并告诉操作系统是因为出现了什么样的错误导致它办不了这个事。当CPU说它办不了的时候,它会立即中断当前正在执行的程序流,并切换到操作系统内核模式。这个过程类似于一个最高优先级的硬件中断,也就是CPU级别的硬件异常。
当操作系统在接收到上述CPU异常报告、并决定要终止该违规程序时,会为该程序立马生成一个Core文件来记录该程序在崩溃瞬间的完整状态,包括内存镜像(当时所有变量、堆、栈的数据)、寄存器状态(包括程序计数器(PC/EIP),它指向了导致崩溃的那条指令)、线程信息和内存管理单元(MMU)状态等。生成Core文件这个动作就是核心转储。
2. Core & Term
我们查信号表的时候就看到了这两种中断方式:Core和Term
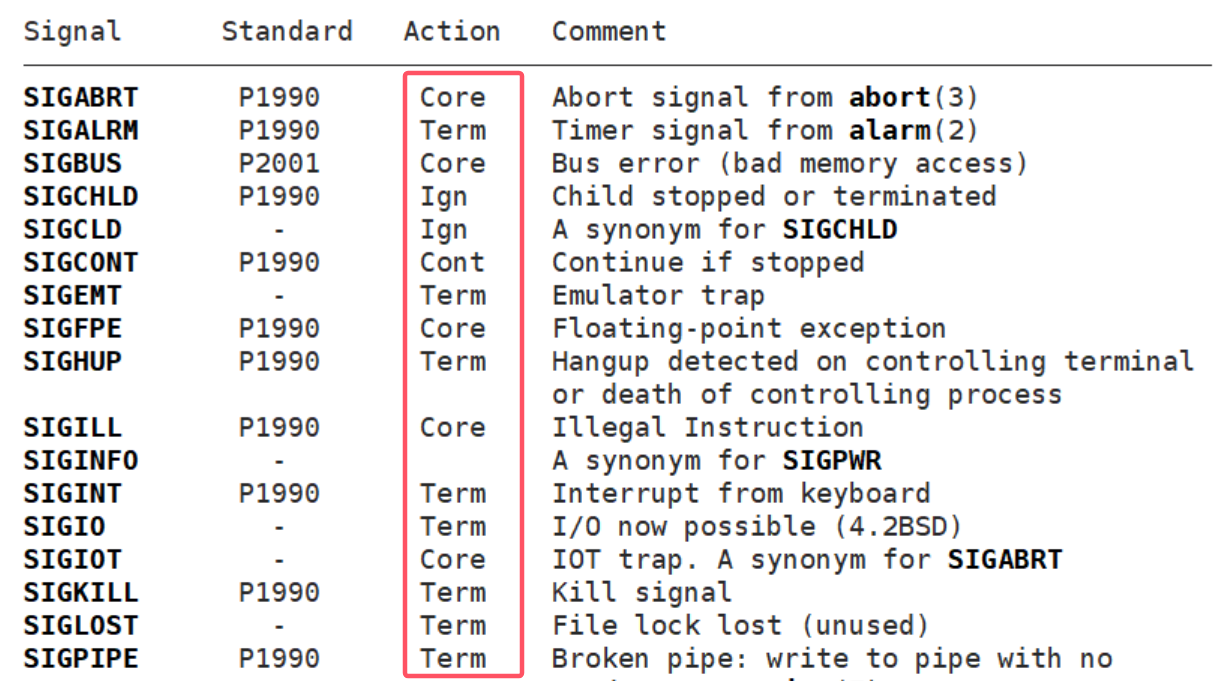
▶这两种中断方式有什么区别呢?
先说结论:
Core:core dump标志位为1,需要追踪异常,会生成core文件
Term:core dump标志位为0,用户主动退出,不需要追踪异常,
当程序正常退出时,我们只需要存储退出状态即可;当程序异常退出时,我们存储了退出状态以及退出信号(信号告诉的是我们出了什么异常),这还有一个core dump标志位,干什么的呢?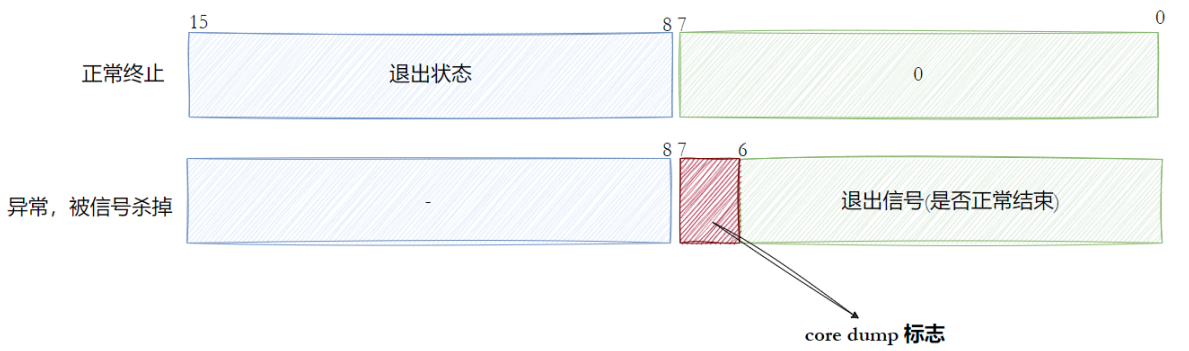
程序退出,有可能就是单纯的发送了退出信号,没有别的原因,用户主动杀掉进程(9,2号信号);有的时候我们是因为程序出错了导致的异常退出,程序因自身bug出错导致退出,这个时候我们通过信号可以知道出了什么错,但我们还想知道出错的位置在哪里,即追踪错误。
这个core dump标志位就是表示是否存在核心转储,即是否生成了core文件,由此判断我们是否需要追踪错误。如果需要,那么我们可以根据core文件来找到程序出错的位置。
我们之所以从来没见过core文件,这是因为core转储默认在云服务器上是被禁用的。那么我们要怎么才能看到core文件呢?
2.1 ulimit命令
ulimit 是一个用于显示和限制用户进程资源使用情况的 Shell 内建命令。它主要用于控制一个 Shell 及其启动的进程 所能使用的系统资源。
ulimit -a #显示当前所有的资源限制
ulimit -c [数值] #设置核心转储文件的最大大小
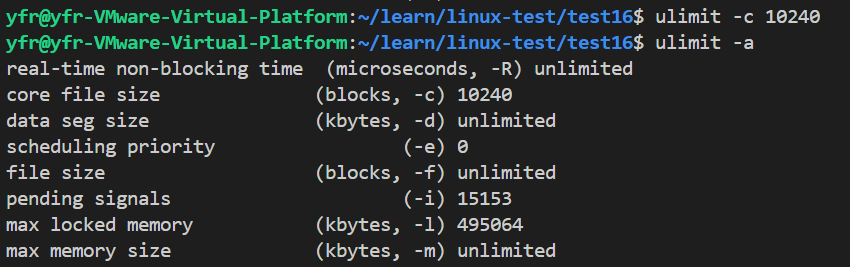
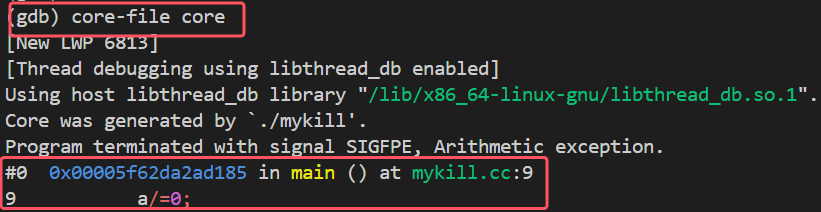
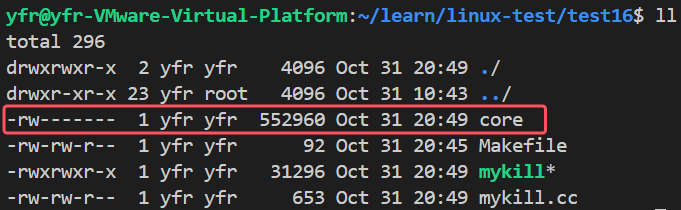
我们写一段有错误的代码,现在我们再次运行有错误的文件,就能看到core文件了。
▶为什么云服务器往往把core禁掉?
恶意用户可能故意制造崩溃来获取系统信息,防止通过分析 core 文件发现软件漏洞
云服务器禁用core dump主要是为了防止单个程序崩溃时生成巨大的内存转储文件瞬间占满磁盘空间,影响同一物理机上其他租户的服务稳定性。
▶那么我们是怎么通过core文件来调试找出错误位置的呢?
打开gdb,输入core-file core就可以定位到出错位置