【Day 83】虚拟化-openstack
一、云的简介
云是基于大量虚拟化资源池构建的计算模式,其核心底层技术是虚拟化—— 通过软件抽象硬件资源(如 CPU、内存、存储、网络),实现资源的动态分配与高效利用,打破物理硬件的边界限制。
1、优势
-
按需自助服务:用户无需人工干预,可通过自助平台自主申请、配置和管理所需资源,满足即时业务需求。
-
广泛的网络接入:资源服务可通过标准网络协议(如 HTTP/HTTPS、TCP/IP)访问,支持各类终端设备(电脑、手机、服务器),不受地理位置限制。
-
弹性伸缩:资源可根据业务负载动态调整(如业务高峰期自动扩容 CPU / 内存,低谷期自动缩容),避免资源浪费,同时保障服务稳定性。
-
资源池化:将多个物理节点的同类资源(如计算、存储)整合为统一 “资源池”,隐藏底层硬件差异(如服务器型号、存储介质),用户仅需关注资源使用,无需了解硬件细节。
-
成本优化:降低 IT 投入与运维成本:云计算通过 “资源共享 + 按需付费” 模式,从硬件采购、运维管理、能耗支出等多维度帮助用户控制成本,尤其适合中小企业和初创团队
-
高可用性与容灾能力:保障业务持续运行.云计算通过分布式架构和冗余设计,大幅提升资源的可用性,降低硬件故障或自然灾害对业务的影响,解决传统 IT 架构 “单点故障” 的痛点
-
快速部署与迭代:加速业务创新。云计算打破传统 IT 架构 “采购 - 部署 - 上线” 的漫长周期,支持资源和应用的快速创建与更新,帮助用户更快响应市场需求,提升创新效率
2、缺点与潜在风险
-
依赖网络连接:网络中断即服务中断。云计算的所有资源(如虚拟机、存储、应用)均通过网络访问,网络连接的稳定性直接决定服务可用性,这是云计算最基础的依赖瓶颈:
-
数据安全与隐私风险:数据控制权转移。使用云计算时,用户数据(如业务数据、用户隐私数据)需存储在云服务商的服务器中,数据控制权从 “用户自有” 转移为 “服务商托管”,带来多重安全隐患:
-
供应商锁定:迁移成本高,难以切换。云计算的技术架构、API 接口、服务模型具有较强的 “供应商特异性”,用户一旦深度使用某家云服务商的服务,后续切换到其他服务商将面临极高的迁移成本,形成 “供应商锁定”
-
长期成本可能高于自建:“按需付费” 的隐性成本。云计算的 “按需付费” 模式看似灵活,但长期使用(尤其是业务规模稳定、资源需求固定的场景)下,总成本可能高于传统自建 IT 架构,存在 “隐性成本陷阱”
-
服务可用性依赖服务商:无法完全掌控。云计算的服务可用性由云服务商的基础设施、运维能力决定,用户无法直接干预,若服务商出现故障,用户业务将被动受影响
-
技术复杂度与学习成本:需适配云原生架构。云计算并非 “开箱即用”,尤其是企业级应用迁移到云时,需适配 “云原生” 技术架构(如容器化、微服务、无服务器计算),对技术团队的能力要求高,学习成本显著
3、类型
(1)根据提供的服务范围
- 公有云:由第三方服务商(如 AWS、阿里云、华为云)搭建和运营,资源对公众开放,多租户共享。优势是零硬件投入、按需付费,适合初创企业、中小团队或临时业务需求。
- 私有云:仅为单个组织(如企业、政府部门)服务,部署在组织内部数据中心,资源独享。优势是安全性高、可定制化强,适合对数据隐私和合规性要求严格的场景(如金融、医疗)。
- 混合云:结合公有云和私有云的架构,可将核心业务(如用户数据、财务系统)部署在私有云,非核心业务(如临时算力需求、海量数据存储)部署在公有云,通过专用网络实现资源互通,兼顾安全性和灵活性。
(2)根据提供服务不同
- IaaS(Infrastructure as a Service,基础设施即服务):提供底层 IT 基础设施资源,包括计算(虚拟机、物理机、服务器)、存储(云硬盘、对象存储)、网络(虚拟网络、负载均衡)。用户可像使用物理硬件一样配置和管理这些资源,无需关注硬件维护。OpenStack 是典型的 IaaS 层开源平台。
- PaaS(Platform as a Service,平台即服务):在 IaaS 基础上提供开发、测试、部署所需的 “平台环境”,包括操作系统、编程语言运行时(如 Java、Python)、数据库、中间件(如分布式缓存),用户可直接在平台上开发和运行应用,无需搭建底层环境。例如 Google App Engine、阿里云 PaaS 平台。
- SaaS(Software as a Service,软件即服务):直接提供现成的软件应用,用户通过浏览器或客户端即可使用,无需安装、部署和维护软件及底层基础设施。例如 Office 365、钉钉、 Salesforce 客户关系管理软件。
- FaaS(函数即服务):无服务器架构,用户仅写代码函数,按执行次数 / 时长计费,适用于轻量任务(如图片压缩、API 响应);
- CaaS(容器即服务):以容器为单位提供部署、编排服务,比虚拟机轻量,适配微服务架构;
- DaaS(桌面即服务):云端提供桌面环境,用户远程访问,适用于企业标准化办公、远程协作;
- BaaS(后端即服务):提供现成后端功能(如用户认证、消息推送),简化 APP / 小程序开发;
- MaaS(监控即服务):提供云资源、应用的监控与告警,无需自建监控系统;
- NaaS(网络即服务):封装 VPN、CDN、防火墙等网络资源,按需快速部署,适配跨地域连接、资源加速。
二、OpenStack 核心组件
(一)综合介绍
OpenStack 是一套开源的云基础设施管理平台,为构建和管理公有云、私有云、混合云提供统一框架。它通过多个独立组件协同工作,实现计算、存储、网络等物理硬件资源的虚拟化,形成可灵活调度的逻辑资源池,并对其进行自动化管理。
- 计算资源:整合多台服务器的 CPU、内存等硬件,通过虚拟化技术(如 KVM、Xen)将物理服务器拆分为多个虚拟机(VM),再通过 Nova 组件统一调度这些虚拟机,实现 “按需分配计算能力”。
- 存储资源:整合服务器本地硬盘、外置存储阵列(如 SAN、NAS)等硬件,通过 Cinder(块存储)、Swift(对象存储)等组件,将物理存储抽象为 “块设备”“对象存储空间” 等形式,供虚拟机或应用直接使用。
- 网络资源:整合物理交换机、路由器、网卡等硬件,通过 Neutron 组件将物理网络资源抽象为 “虚拟网络”“子网”“安全组” 等逻辑网络对象,实现虚拟机之间、虚拟机与外部网络灵活通信。
其官方安装指南可参考:https://docs.openstack.org/install-guide/
- OpenStack 版本自项目启动(2010 年),始终遵循按“字母顺序排序 ->地名 / 实体名称“的规则命名。
- OpenStack 本身更像一个 “基础框架”,直接拿来用的情况很少,大多需要二次开发或封装后再使用。
1、核心组件
- 核心资源管理组件(计算、存储、网络):Nova(计算)→Glance(镜像,支撑计算)→Neutron(网络)→Cinder(块存储)→Swift(对象存储);
- 扩展资源组件(补充核心资源场景):Ironic(裸金属,扩展计算)→Zun(容器,扩展计算);
- 支撑服务组件(保障资源可用与易用):Keystone(认证,基础支撑)→Heat(编排,自动化支撑)→Ceilometer(计量,监控计费支撑)→Dashboard(可视化,操作支撑)。调整后可让用户更清晰地理解 “资源是核心,支撑服务为资源服务” 的架构逻辑。
- OpenStack Docs: 2025.2 Services and Libraries
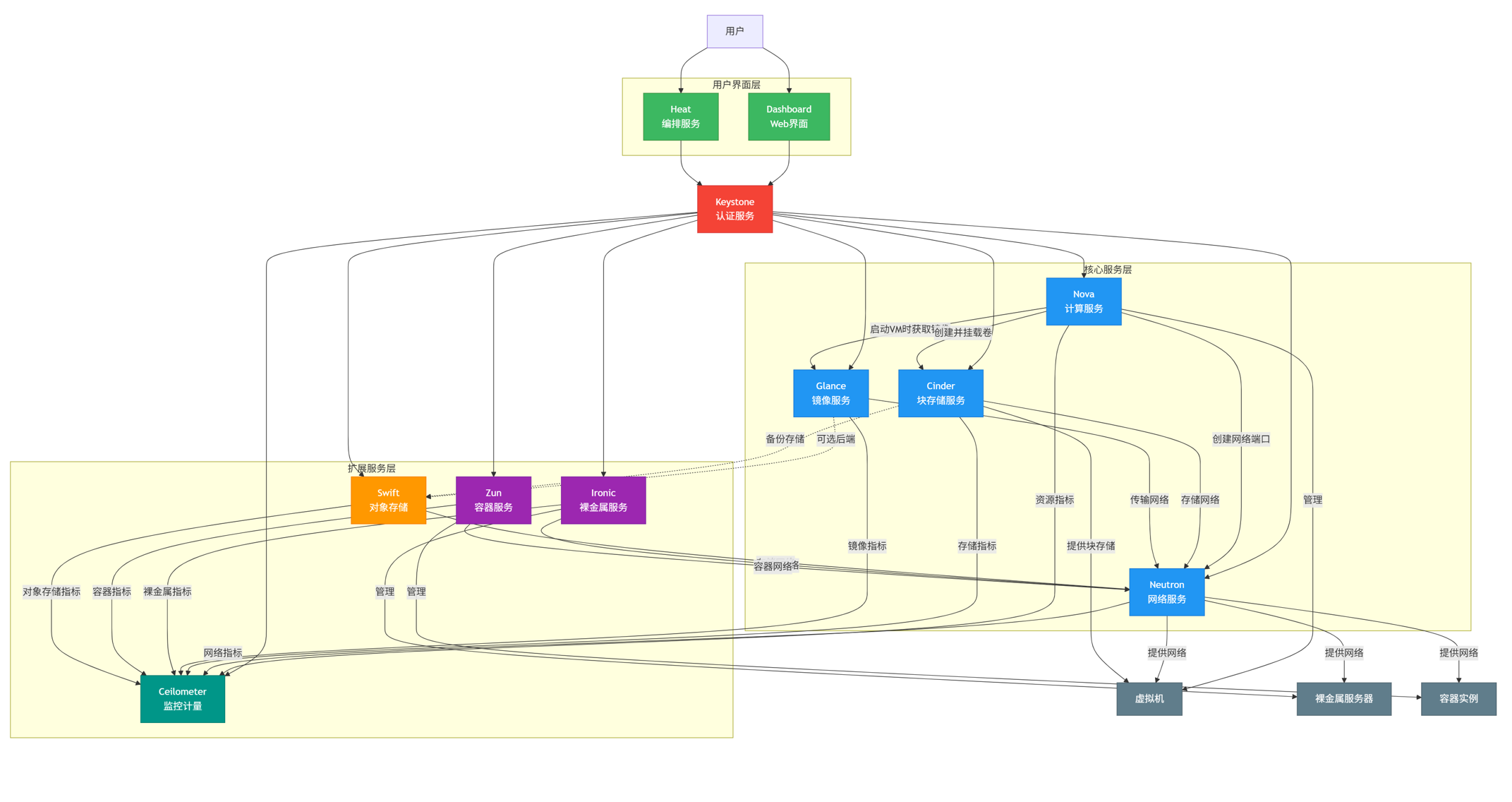
2、OpenStack基础架构
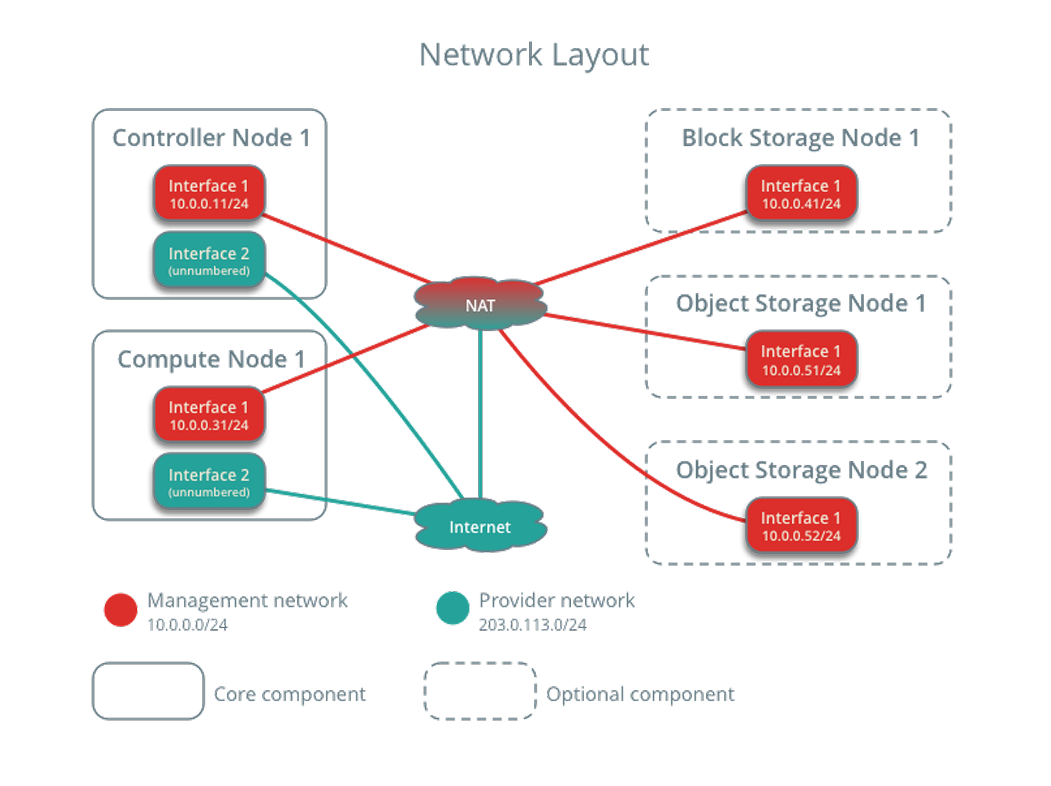
(1)Controller控制节点:
-
数据库:通常使用 MySQL 或 MariaDB,存储 OpenStack 各组件的元数据(如虚拟机配置、用户信息、网络拓扑等),是各组件协同工作的 “数据中心”。
-
MQ 消息队列:通常用 RabbitMQ、Qpid 等,作为各组件间的通信枢纽。OpenStack 组件多为分布式架构,通过消息队列异步传递指令(如创建虚拟机、挂载存储),实现松耦合协作。
-
Redis:常用作缓存服务,提升频繁访问数据的读取速度(如令牌缓存、会话管理),也可用于部分组件的状态存储(如负载均衡组件 Octavia 的健康检查状态)。
-
此外,控制节点通常还包含认证服务(Keystone)、镜像服务(Glance)、网络服务(Neutron 服务器端)等核心组件,是云平台的控制核心。
(2)Compute计算节点:
-
KVM 虚拟机(hypervisor):KVM(Kernel-based Virtual Machine)是 Linux 内核中的虚拟化模块,负责硬件资源(CPU、内存、I/O)的虚拟化,允许在物理机上同时运行多个独立的虚拟机。
-
Nova 组件:OpenStack 的计算服务,运行在计算节点上的是 Nova Compute 服务,负责与 KVM 交互,执行虚拟机的生命周期管理(创建、启动、停止、迁移等),并接受控制节点的调度指令。
(3)Block Storage 节点:
-
Cinder 组件:OpenStack 的块存储服务,运行在块存储节点上的是 Cinder Volume 服务。它通过管理底层存储设备(如本地磁盘、SAN、NAS 等),为虚拟机提供可持久化的 “虚拟磁盘”(卷),支持卷的创建、挂载、快照、备份等操作(类似 AWS 的 EBS)。
(4)Object节点:
-
Swift 组件:OpenStack 的对象存储服务,用于存储非结构化数据(如图片、视频、日志、备份文件等),采用分布式架构,通过冗余存储保证数据可靠性,支持无限扩展(横向增加节点即可)。
(5)网络节点(Network Node)
-
L3 代理(L3 Agent):管理虚拟路由器(Virtual Router),实现不同子网间的路由转发,以及 NAT 功能(SNAT/DNAT)。
-
SNAT(源地址转换):虚拟机访问 Internet 时,将私有 IP 转换为网络节点的公网 IP,实现出口流量的地址转换。
-
DNAT(目的地址转换):外部请求访问虚拟机时,将公网 IP 和端口映射到虚拟机的私有 IP 和端口(如公网 IP:8080 → 虚拟机私有 IP:80)。
-
-
DHCP 代理(DHCP Agent):为虚拟机分配私有 IP 地址、子网掩码、网关等网络配置。
-
元数据代理(Metadata Agent):为虚拟机提供元数据服务(如获取临时密码、实例 ID 等)。
-
负载均衡与防火墙:若部署负载均衡服务(Octavia)或防火墙服务(Neutron FWaaS),相关代理也可能运行在网络节点,负责流量分发和安全策略控制。
(6)其他节点:监控节点、UI节点、镜像节点、身份认证节点、容器节点等
(二)单独介绍
1、Nova 组件
计算服务 — nova 32.0.1.dev14 文档
Nova is the OpenStack project that provides a way to provision compute instances (aka virtual servers). Nova supports creating virtual machines, baremetal servers (through the use of ironic), and has limited support for system containers. Nova runs as a set of daemons on top of existing Linux servers to provide that service.
Nova 是 OpenStack 项目的计算服务组件。负责云服务器(虚拟机 / 实例)的全生命周期管理,提供计算实例(又称虚拟服务器)的部署能力,包括实例的创建、启动、暂停、重启、删除、规格调整等操作,是实现 “计算资源池化” 的核心。Nova 支持创建虚拟机和裸金属服务器(通过集成 Ironic 组件实现),同时对系统容器也具备有限的支持能力。Nova 以一组守护进程的形式,运行在现有 Linux 服务器之上,从而提供上述计算服务
- OpenStack:开源的云计算管理平台,由多个核心项目组成,Nova 是其中负责 “计算资源管理” 的核心组件,类似 AWS 的 EC2 服务。
- baremetal servers:裸金属服务器,指不依赖虚拟化技术、直接使用物理硬件的服务器,适合对性能和稳定性要求极高的场景(如高性能计算、核心数据库)。
- Ironic:OpenStack 的一个子项目,专门用于裸金属服务器的部署、管理和运维,Nova 通过调用 Ironic 的接口实现对裸金属资源的调度。
- daemons:守护进程,指在操作系统后台持续运行、用于提供特定服务的进程,Nova 的功能正是通过这类后台进程持续提供的。
它需要以下额外的 OpenStack 服务才能实现基本功能:
- Keystone(密钥石):为所有 OpenStack 服务提供身份标识与认证功能。
- Glance(镜像服务):提供计算镜像仓库。所有计算实例都从 Glance 存储的镜像启动。
- Neutron(网络服务):负责配置虚拟或物理网络,供计算实例在启动时连接。
- Placement(资源放置服务):负责跟踪云环境中可用的资源库存,并在创建虚拟机时协助选择将使用哪些资源提供者。
Nova 核心进程
计算服务概述 — nova 32.0.1.dev14 文档
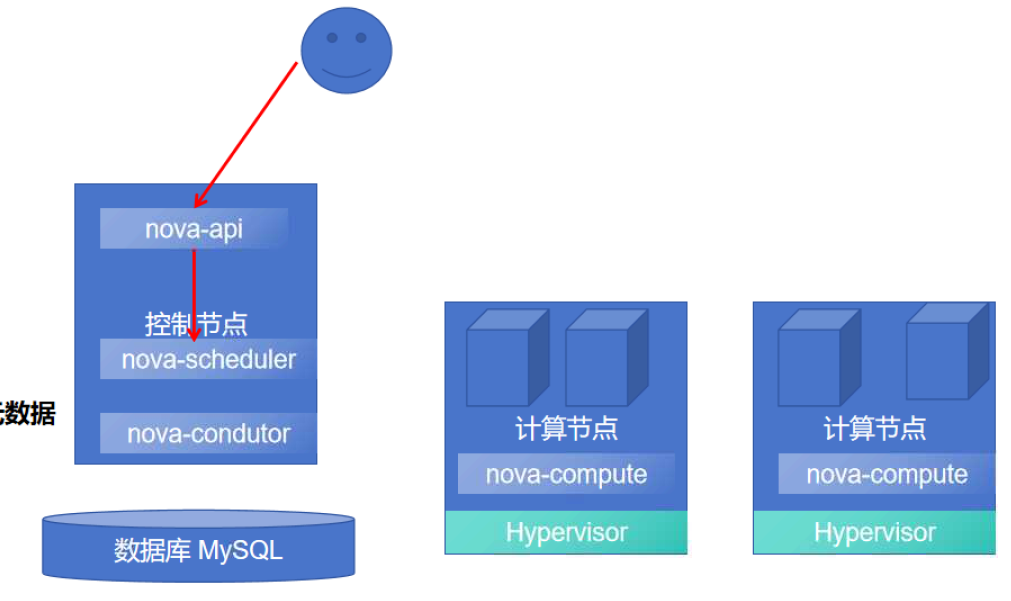
(1)nova-api:
-
nova-api-wsgi service:Accepts and responds to end user compute API calls. The service supports the OpenStack Compute API. It enforces some policies and initiates most orchestration activities, such as running an instance.
-
Nova 服务的 “前端接口网关”,接收并响应终端用户及其他组件的计算服务 API 调用,核心功能包括:
-
支持 OpenStack 计算服务 API 规范,接收各类计算资源操作请求(如创建实例、查询实例状态、终止实例等);
-
执行基础策略校验(如请求是否符合系统全局规则),并触发后续编排流程(如实例创建的调度、资源分配等);
-
作为用户 / 其他组件与 Nova 内部服务的交互入口,通过 REST API 提供标准化接口,同时进行请求参数验证、身份权限检查(依赖 Keystone),确保操作的合法性与安全性。
-
(2)nova-scheduler:
-
nova-scheduler service:Takes a virtual machine instance request from the queue and determines on which compute server host it runs.
-
Nova 的 “资源调度核心”,负责从请求队列中接收虚拟机实例创建请求,并决策该实例应运行在哪个计算节点上。
-
作为 Nova 的 “调度器”,其核心逻辑是根据预设策略(如计算节点的资源利用率),从集群中的多个计算节点中筛选出 “最优节点”。
-
例如,当用户请求创建 1 台 2 核 4G 的实例时,scheduler 会先过滤出剩余 CPU、内存资源满足需求的节点,再依据策略(如 “最小负载优先”“资源利用率均衡” 等)最终确定实例部署的目标节点,确保资源高效分配与集群负载均衡。
(3)nova-compute:
-
nova-compute service:A worker daemon that creates and terminates virtual machine instances through hypervisor APIs. For example:
-
libvirt for KVM or QEMU
-
VMwareAPI for VMware
-
-
Processing is fairly complex. Basically, the daemon accepts actions from the queue and performs a series of system commands such as launching a KVM instance and updating its state in the database.
-
运行在每个计算节点上的 “实例执行 daemon 进程”,核心功能是通过调用底层虚拟化技术(Hypervisor)的 API,完成虚拟机实例的创建、终止等生命周期操作。
-
其支持的 Hypervisor 包括:通过 libvirt 接口对接 KVM 或 QEMU,通过 VMwareAPI 对接 VMware 虚拟化平台等。
-
-
具体处理流程较为复杂:该进程从消息队列中接收操作指令(如创建实例),执行一系列系统级操作(例如,为 KVM 实例生成包含 CPU、内存、磁盘等参数的 XML 配置文件,通过 libvirt 工具与 KVM 交互完成实例启动),并同步更新实例状态至数据库.
(4)nova-novnc:
-
nova-novncproxy daemon:Provides a proxy for accessing running instances through a VNC connection. Supports browser-based novnc clients.
-
Nova 提供的 VNC 连接代理服务,核心功能是为用户访问运行中的实例提供 VNC 协议转发能力,尤其支持基于浏览器的 noVNC 客户端(无需安装额外 VNC 工具)。
-
其工作机制为:接收用户通过 Web 界面发起的远程连接请求,将请求安全转发至目标实例的 VNC 服务端,实现用户对实例桌面的交互式操作。通过代理转发,既简化了用户接入流程(无需直接暴露实例的 VNC 端口),又增强了连接的安全性(可集成认证与权限校验)。
(5)nova-conductor:
- nova-conductor module:Mediates interactions between the service and the database. It eliminates direct accesses to the cloud database made by the service. The module scales horizontally. However, do not deploy it on nodes where the service runs. For more information, see the section in the Configuration Options.nova-computenova-computenova-conductornova-computeconductor
-
Nova 架构中的 “数据库交互中间层”,核心作用是作为 nova-compute 服务与数据库之间的中介,统一处理两者的交互请求,读取云服务器的相关元数据信息,分担部分业务逻辑处理。
-
其核心价值体现在:
- 消除 nova-compute 节点对数据库的直接访问,避免因计算节点暴露数据库连接信息带来的安全风险;
- 集中处理实例状态更新、资源信息同步等数据库操作(尤其支持批量处理),减轻数据库的并发访问压力;
- 承担部分非 Hypervisor 依赖的业务逻辑(如实例规格验证、资源配额检查),降低 nova-compute 节点的负载;
- 支持水平扩展(通过部署多个 conductor 实例分担负载),但需注意:不可与 nova-compute 服务部署在同一节点,以确保架构隔离性与稳定性。
2、Glance 组件
Glance Utility Programs — glance 31.1.0.dev15 documentation
Glance 是 OpenStack 的镜像服务组件,负责虚拟机镜像的全生命周期管理,包括镜像的上传、查询、更新、删除,以及为 Nova 提供实例创建所需的镜像文件(如操作系统镜像、预装应用镜像)。
Glance 核心进程
- glance-api:Glance 的 “前端接口”,接收用户的镜像操作请求(如上传镜像、查询镜像列表、下载镜像),并将请求转发到后端的存储服务或 glance-registry,同时处理镜像格式验证、权限检查等逻辑。
- glance-registry:Glance 的 “元数据管理中心”,负责存储和管理镜像的元数据信息(如镜像名称、大小、格式、创建时间、所属租户),不存储镜像本身。当用户查询镜像信息时,glance-api 会从 glance-registry 中获取元数据,将 “镜像文件的存储位置” 返回给客户端,客户端根据
glance-api返回的存储位置,直接与存储后端(如 Ceph、Swift、本地磁盘、S3、HTTP)交互,下载或读取镜像文件。(用户或 Nova),同时支持多种镜像格式(如 QCOW2、RAW、VHD,其中 QCOW2 为 OpenStack 默认镜像格式) - 但随着 OpenStack 架构的简化,社区决定将元数据管理功能合并到
glance-api中,以减少组件间依赖。在 OpenStack Newton 版本(2016 年) 中,glance-registry 被正式从 Glance 代码库中移除,不再作为官方支持的组件。其元数据管理功能被合并到 glance-api 中,通过 glance-api 直接操作数据库实现,使 Glance 架构更简洁。 - 存储后端支持:Glance 不直接存储镜像文件,而是通过插件式架构支持多种存储方式,包括:
- 本地文件系统(适合测试环境);
- 对象存储(如 Swift、AWS S3,适合海量镜像存储);
- 块存储(如 Cinder,适合高性能镜像访问);
- 共享文件系统(如 NFS、GlusterFS,适合多节点共享镜像)。
3、Neutron 组件
欢迎来到 Neutron 的文档!— Neutron 27.1.0.dev77 文档
Neutron 是 OpenStack 的网络服务组件,为云环境提供灵活、可扩展、可编程的网络资源(虚拟网络、子网、路由器、防火墙、负载均衡)的创建与管理,确保 Nova(计算)、Cinder(块存储)、Glance(镜像)等资源之间及资源与外部网络的连接性。
(1)Neutron 核心进程
OpenStack Networking — Neutron 27.0.1.dev18 documentation
- neutron-server:
- neutron-server Accepts and routes API requests to the appropriate OpenStack Networking plug-in for action
- Neutron 的 “前端接口”,接收用户的网络操作请求(如创建虚拟网络、配置路由器、绑定端口),通过 REST API 提供标准化接口,并将请求路由到对应的 “网络插件”(如 Open vSwitch 插件、Linux Bridge 插件)或 “服务插件”(如防火墙插件、负载均衡插件)处理。
网络插件与其代理进程
Neutron 采用 “中心 - 代理” 架构,除 neutron-server 外,还需在计算节点、网络节点上运行代理进程,实现网络数据转发:
Agents and Services — Neutron 27.0.2.dev3 documentation
- L2Agent(二层接入插件 / 代理)
- neutron-openvswitch-agent:基于 Open vSwitch(OVS)实现的 L2 代理,负责实例的网络连接、流量转发(如 VLAN、VXLAN 封装)。
- neutron-linuxbridge-agent:基于 Linux 网桥实现虚拟网络,轻量简单但功能较少,适合测试或低负载场景。
- 部署位置:计算节点(必须部署,负责本地虚拟机的网络接入)和网络节点(可选,辅助处理跨节点流量)。
- L3Agent(三层路由插件 / 代理)
- neutron-l3-agent:唯一实现 L3 功能的代理进程,通过控制 Linux 内核路由表或 OVS 流表实现路由转发。
- 部署位置:通常仅部署在网络节点,部分场景下也可部署在计算节点(简化架构)。
- dhcp-agent(DHCP 插件 / 代理)
- neutron-dhcp-agent:运行在网络节点,为虚拟子网提供 DHCP 服务,自动为实例分配 IP 地址、子网掩码、网关等网络参数。
- 部署位置:通常在网络节点,也可分布式部署在多个节点提高可用性。
- iptables/firewalld(安全组插件)
- 不是独立的代理进程,而是 L2 代理(如 openvswitch-agent、linuxbridge-agent)的内置功能:通过调用 iptables(或 firewalld)工具在计算节点上配置防火墙规则,直接作用于虚拟机的虚拟网卡。
(2)核心网络虚拟化技术
Neutron 依赖多种网络虚拟化技术实现灵活的网络隔离与扩展:
- Open vSwitch(OVS):开源的多层虚拟交换机,支持 VLAN、VXLAN、GRE 等隧道技术,可实现跨物理节点的虚拟网络连接,是 Neutron 最常用的网络虚拟化方案。
- Linux Bridge:Linux 内核自带的虚拟网桥功能,支持基本的二层转发和 VLAN 隔离,部署简单但功能不如 OVS 丰富,适合小规模或测试环境。
- VXLAN 技术:一种基于 UDP 的 overlay 隧道技术,通过在原始以太网帧上封装 VXLAN 头部(含 24 位 VNI 标识),突破传统 VLAN 仅支持 4096 个隔离网络的限制,可实现多达 1600 万个虚拟网络,同时支持实例跨物理子网迁移(隧道封装可穿透三层网络)。
- 软件定义网络(SDN):核心是 “控制平面与数据平面分离”—— 控制平面(如 Neutron-server、SDN 控制器)负责网络策略配置(如路由规则、访问控制),数据平面(如 OVS、Linux Bridge)负责实际流量转发,实现网络的动态配置与自动化管理。改网络规则不用去一个个调设备,直接在控制平面改配置,所有数据平面设备自动同步,实现网络的自动化和动态调整。SDN 在 Neutron 中的应用包括:
- 软 SDN:控制平面和数据平面都用软件实现。比如用 Neutron 自己的控制器,配合 OVS 虚拟交换机,所有网络功能都在服务器的软件里跑。灵活、成本低,适合大多数通用场景
- 硬 SDN:控制平面(如SDN 控制器)直接对接物理硬件交换机(如 Cisco、H3C 设备),通过 OpenFlow 协议控制硬件转发。适合对性能要求极高的场景如金融核心业务
5、Cinder 组件
Cinder 是 OpenStack 的块存储服务组件,负责为云服务器(Nova 实例)提供 “持久化、可扩展、高可用” 的块级存储服务(即 “卷”),类似物理机的硬盘,但通过软件定义的方式实现了存储资源的灵活调度与生命周期管理——支持卷的创建、挂载、卸载、备份、快照等操作,数据在实例删除后仍可保留(需手动删除卷)。
Cinder 核心进程
Introduction to the Block Storage service — cinder 27.0.1.dev4 documentation
Cinder 核心进程围绕 “请求处理 - 调度 - 执行” 流程设计,同时依赖底层存储技术实现卷的创建:
-
- cinder-api:Cinder 的 “前端入口”,接收用户的卷操作请求(如创建卷、挂载卷到实例、删除卷),进行请求验证和权限检查后,将请求转发到 cinder-scheduler 或 cinder-volume。
- cinder-scheduler:Cinder 的 “存储调度器”,根据预设策略(如卷大小需求、存储类型、可用空间、性能指标)从多个存储节点(cinder-volume 节点)中选择合适的存储节点创建卷。例如,当用户需要创建 100GB 的 SSD 卷时,scheduler 会筛选出支持 SSD 类型且剩余空间足够的存储节点。
- cinder-volume:运行在存储节点上的 “执行器”,通过调用底层存储驱动(如 LVM 驱动、iSCSI 驱动、硬件存储阵列驱动)创建、删除卷,或执行卷的快照、备份操作。每个存储节点对应一个 cinder-volume 进程,管理该节点上的存储资源。
- cinder-backup:负责卷的备份服务,将 Cinder 卷的数据备份到外部存储(如 Swift 对象存储、S3 兼容存储),支持备份的创建、恢复和删除,避免卷数据因硬件故障丢失。
- 涉及核心技术:
- LVM(逻辑卷管理):默认的本地存储方案,通过将物理磁盘划分为逻辑卷组,动态创建 / 调整逻辑卷(即 Cinder 卷),适合小规模部署;
- iSCSI/SCSI:用于实现块存储的网络共享,将后端存储(如 SAN 设备、LVM 卷组)通过 iSCSI 协议暴露为网络块设备,供计算节点挂载使用,支持大规模分布式部署。
| 存储类型 | 核心协议 / 技术 | 数据组织形式 | 典型场景 | 核心区 |
|---|---|---|---|---|
| 块存储 | iSCSI、NVMeoF、LVM | 无固定结构,按 “块”(Block)寻址 | 虚拟机系统盘、数据库(MySQL、MongoDB) | 最接近物理硬盘,适合低延迟、随机读写场景 |
| 文件存储 | NFS、SMB/CIFS | 树状存储(目录树结构:/a/b/file) | 多虚拟机共享静态资源(图片、视频)、日志存储 | 依赖目录树,适合多用户共享、按文件名访问 |
| 对象存储 | S3 API、Swift API | URL 存储(扁平结构:Bucket+Key) | 海量非结构化数据(图片、音视频)、静态网站 | 无目录树,按唯一 URL 寻址,适合海量数据存储 |
| 协议 | 传输底层 | 特点 | 适用场景 |
|---|---|---|---|
| iSCSI | 以太网(TCP/IP) | - 基于通用以太网,成本低(无需专用硬件);- 兼容性强(几乎所有服务器 / 操作系统都支持);- 性能中等(延迟约 1-10ms)。 | 中小规模云环境、通用块存储(如虚拟机非高性能数据盘)。 |
| FC(光纤通道) | 专用光纤网络 | - 需专用 FC 交换机和 HBA 卡,成本高;- 性能强(延迟约 0.1-1ms),适合高 IO 场景;- 兼容性差(依赖专用硬件)。 | 传统企业级 SAN、高性能数据库(如 Oracle RAC)。 |
| NVMeoF | 以太网(RDMA)/ 光纤 | - 基于 NVMe 协议,专为 SSD 优化;- 低延迟(约 0.01-0.1ms)、超高带宽;- 需支持 RDMA 的网卡和交换机。 | 云环境中的高性能块存储(如 AWS EBS io2、阿里云 ESSD)。 |
6、Swift 组件
Swift 是 OpenStack 的对象存储服务组件,专门用于存储 “非结构化数据”(如镜像文件、备份数据、日志文件、静态网页资源),采用分布式架构,支持海量数据的持久化存储(通过多副本机制)和高可用访问(无单点故障)。
7、Ironic(裸金属)组件
Ironic 是 OpenStack 的裸金属服务组件,专门用于管理物理服务器(裸金属机),将物理机视为 “可像虚拟机一样调度的资源”,实现物理机的自动化部署、启动、关闭与全生命周期管理。
核心功能:
- 裸金属服务器全生命周期管理:支持物理机注册与发现(通过 PXE 或 IPMI 纳入管理,自动获取硬件信息)、部署与启动(基于镜像安装操作系统,支持本地磁盘或网络启动)、维护与回收(电源控制、硬件检测,实例释放后自动清理磁盘);
- 与 OpenStack 生态深度集成:复用 Keystone(认证)、Neutron(网络)、Glance(镜像)等组件,物理机使用 Neutron 网络资源,从 Glance 获取镜像;支持与 Heat 协同,实现 “虚拟机 + 物理机” 混合架构的自动化部署;
- 灵活的驱动机制:支持多种硬件厂商驱动(如 Dell、HPE、华为),通过 IPMI、Redfish 等协议与物理机交互,适配不同品牌和型号的服务器。
8、Zun 组件
Zun 是 OpenStack 中专注于容器管理的服务组件,旨在为 OpenStack 生态提供轻量级、原生的容器编排与生命周期管理能力,支持 Docker 等容器引擎,实现容器与 OpenStack 现有计算、网络、存储资源的无缝集成。
核心功能:
- 容器生命周期管理:支持容器的创建、启动、停止、重启、删除等基础操作,可指定容器镜像(如从 Docker Hub 或私有镜像仓库拉取)、资源限制(如 CPU、内存配额)、网络配置(如接入 Neutron 虚拟网络);
- 与 OpenStack 生态深度集成:复用 Keystone 进行身份认证,使用 Neutron 提供网络连接(容器可接入虚拟网络,获取与 Nova 实例一致的网络能力),支持挂载 Cinder 块存储卷或 Swift 对象存储,实现容器数据持久化;
- 容器编排简化:提供基本的容器编排能力,支持创建容器组(Pod 类似概念),可定义多个容器的关联关系(如共享网络、存储),满足简单微服务架构的部署需求;
- 轻量灵活:无需依赖外部容器编排平台(如 Kubernetes),部署和使用门槛低,适合在 OpenStack 环境中快速引入容器技术,实现虚拟机与容器的统一管理。
9、Keystone 组件
Keystone 是 OpenStack 的身份认证与授权服务组件,相当于 OpenStack 云平台的 “统一身份网关”,负责管理用户、租户(Project)、角色、权限,确保只有授权用户才能访问指定资源。
- 核心功能:
- 身份认证(Authentication):验证用户身份,支持多种认证方式(如密码认证、令牌(Token)认证、OAuth 认证、LDAP 集成);
- 授权(Authorization):基于 “角色 - 权限” 模型(RBAC)分配权限 —— 租户是资源的隔离单元(如一个租户下的实例仅该租户用户可见),角色是权限的集合(如 “管理员” 角色拥有所有操作权限,“普通用户” 角色仅能管理自己创建的实例);
- 服务目录(Service Catalog):存储 OpenStack 各组件(如 Nova、Glance、Neutron)的服务端点(API 地址),用户通过 Keystone 获取服务目录后,可直接访问对应组件的 API。
- 核心流程:用户登录时,向 Keystone 提交身份信息(如用户名 + 密码),Keystone 验证通过后返回一个临时 Token 和服务目录;用户后续访问其他组件时,需在请求头中携带该 Token,组件会向 Keystone 验证 Token 的有效性和用户权限,验证通过才处理请求。
10、Dashboard(Horizon)
Dashboard 是 OpenStack 的Web 可视化管理界面(官方名称为 Horizon),为用户和管理员提供直观的图形化操作界面,无需通过命令行或 API 手动操作,降低 OpenStack 的使用门槛。
- 核心功能:
- 用户视角:支持创建 / 管理实例、卷、网络、镜像,查看资源使用情况,远程连接实例,下载镜像等;
- 管理员视角:支持管理用户、租户、角色,配置全局参数(如默认实例规格、镜像类型),监控各节点(控制器、计算、存储节点)的运行状态,查看系统日志等;
- 集成性:与 OpenStack 所有核心组件无缝集成,界面操作会自动转化为对应组件的 API 请求,确保操作与命令行 / API 操作的一致性;
- 定制化:支持通过插件扩展功能(如添加自定义资源类型、集成第三方服务),也可自定义界面风格(如企业 Logo、配色方案)。
11、Heat 组件
Heat 是 OpenStack 的编排服务组件,负责基于 “模板(Template)” 自动化部署和管理云资源栈(Stack)—— 用户无需手动逐一创建实例、网络、卷等资源,只需编写一个模板定义资源依赖关系和配置参数,Heat 会按模板自动创建、配置和关联所有资源,实现 “一键部署” 复杂应用(如一个包含 Web 服务器、数据库服务器、负载均衡的应用集群)。
- 核心功能:
- 模板支持:采用 YAML 格式的 Heat Orchestration Template(HOT)或 AWS CloudFormation 兼容模板,支持定义资源类型(如 Nova::Server、Neutron::Net、Cinder::Volume)、资源依赖(如先创建网络再创建实例)、参数(如实例规格、镜像 ID 可动态传入)、输出(如实例的 IP 地址);
- 栈生命周期管理:支持栈的创建、更新、删除、暂停、恢复,更新栈时可自动处理资源的增量变更(如修改实例规格、添加新卷);
- 自动伸缩与容错:结合 Ceilometer 计量数据,支持基于策略的自动伸缩(如 CPU 使用率过高时自动增加实例数量),同时支持资源故障自动恢复(如实例宕机时自动重建)。
12、Ceilometer 组件
Ceilometer 是 OpenStack 的计量与监控服务组件,负责采集、存储和分析 OpenStack 各组件的资源使用数据(如实例的 CPU 使用率、内存占用、网络流量、卷的存储容量),为计费、资源监控、弹性伸缩提供数据支撑。
- 核心功能:
- 数据采集:通过 “代理(Agent)” 采集各组件的计量数据(如 nova-agent 采集实例数据、neutron-agent 采集网络数据),支持定时采集或事件触发采集;
- 数据存储:将采集到的计量数据存储到后端数据库(如 MongoDB、MySQL)或时间序列数据库(如 InfluxDB),适合海量时序数据的存储与查询;
- 数据分析与告警:支持基于计量数据设置阈值告警(如 CPU 使用率超过 90% 时触发告警),同时为计费系统提供数据接口(如按实例运行时长、网络流量计费)。