cuda矩阵转置算子(共享内存)
cpu版本
即为按行遍历行列互换
// 主机上的矩阵转置函数,用于验证结果
void cpuTranspose(const float *input, float *output, int n)
{
for (int row = 0; row < n; ++row)
{
for (int col = 0; col < n; ++col)
{
output[col * n + row] = input[row * n + col];
}
}
}
gpu未优化版本
每个线程单独处理一个元素
__global__ void transpose(float *input, float *output, int n)
{
int row = blockDim.y * blockIdx.y + threadIdx.y;
int col = blockDim.x * blockIdx.x + threadIdx.x;
if (row < n && col < n)
{
output[col * n + row] = input[row * n + col];
}
}
gpu共享内存
对齐访问:对齐访问顾名思义即当设备内存事务的第一个地址是用于事务服务的缓存粒度的偶数倍时(32字节的二级 缓存或128字节的一级缓存),就会出现对齐内存访问。运行非对齐的加载会造成带宽浪 费。
如下图为对齐访问的情况,假设带宽为128B,则只需要加载一次内存
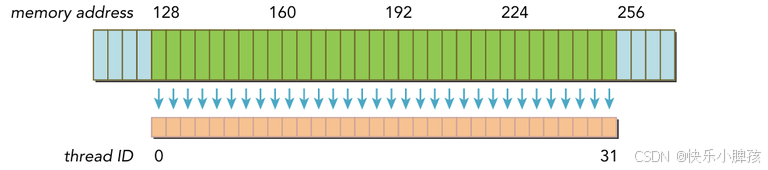
下面是非对齐的情况,访问的地址是分散的,那么至少需要3次访存
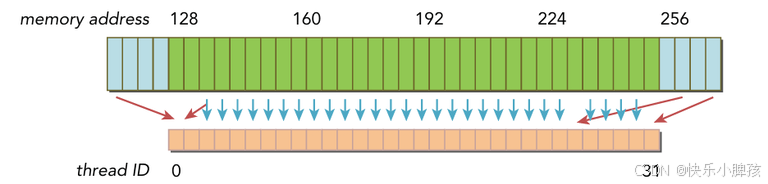 合并访问,如果一个warp中的所有线程访问的是一片连续的内存,那么就会合并访问,反之则反,直接上图。
合并访问,如果一个warp中的所有线程访问的是一片连续的内存,那么就会合并访问,反之则反,直接上图。
假设一个线程访问4B的数据,下图warp中所有线程访问的地址是连续的,则为合并访问,没有浪费带宽,总线占用率为100%

另外一种情况为虽然按线程id顺序访问的内存地址不是有顺序的,但是总的额访问的内存仍然是一块连续的地址,那么总线占用率还是100%

下面回到我们的矩阵转置中,在实际的矩阵存储中是一维的,如下图所示
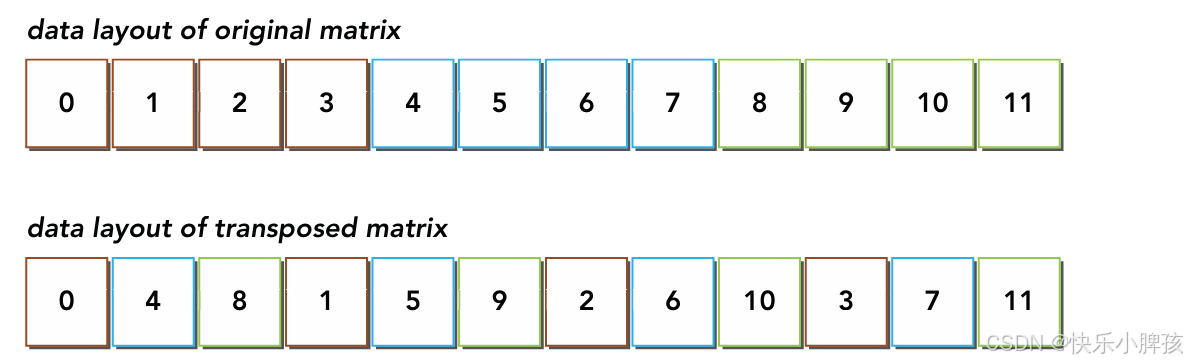
在我们按行读取的时候,属于我们的合并访问,因为访问的地址是连续的,但是我们转置后,按列存储到一维数组的时候时,地址是分散的,则就是非合并访问了,需要访存多次。
或者我们按行去写,这个时候写地址是连续的,是合并访问的,但是读的时候需要按列读,地址不连续,则读不是合并访问了。所以无论我们按行还是按列读都无法避免合并访问。
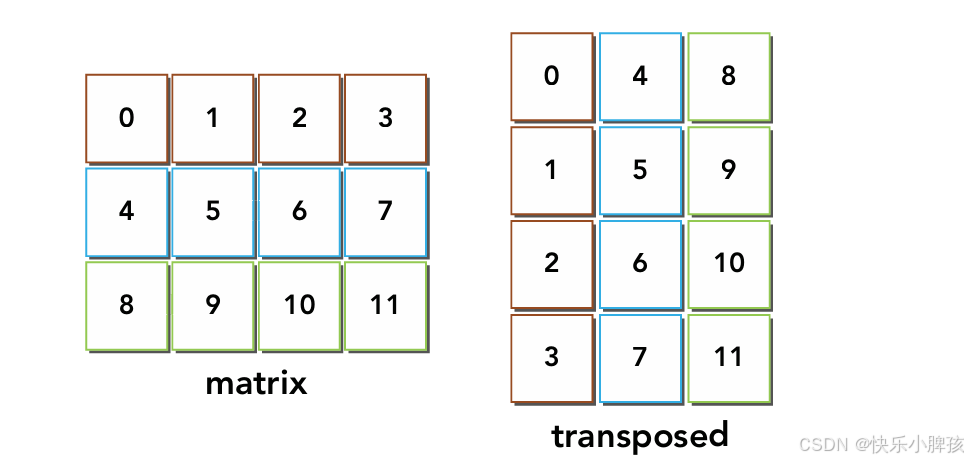
那么有没有什么办法能够使得按行读数据,按行写数据呢,那么引入中间一小块内存就能做到,我们知道共享内存在一个block内对于所有线程是可见的,而我们可以申请一小块共享内存,这一块地址是连续的,这个时候,如下图所示,在一个block处理矩阵中一小块元素的时候,我们就能将原本地址不连续的元素,重新排布到在共享内存上面,就变得地址连续了。
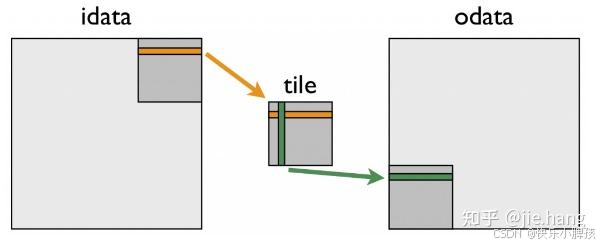
那么我们再将共享内存的数据,按照转置,写入到结果矩阵中,此时读数据按行读,写数据也是按行写,那么读写都是合并访问,而共享内存中地址是连续的,读共享内存的数据也是合并访问,虽然我们每个线程由刚开始读入(行,列)的数据到共享内存中,到从共享内存中读取(列,行)的数据按行输出到矩阵中,访问的元素在逻辑顺序上变了,但是还是处于共享内存的这一片连续的内存中,是不是就是前面说过的这一种合并访问情况

代码:
__global__ void transposeShared(float *input, float *output, int N)
{
// 每个线程块都有一个 BLOCK_SIZE ✕ BLOCK_SIZE 的共享内存数组,用于存储其内部处理的数据
__shared__ int sharedMemory [blocksize] [blocksize];
// global index
int indexX = threadIdx.x + blockIdx.x * blockDim.x;
int indexY = threadIdx.y + blockIdx.y * blockDim.y;
// transposed global memory index
int tindexX = threadIdx.x + blockIdx.y * blockDim.x;
int tindexY = threadIdx.y + blockIdx.x * blockDim.y;
// local index
int localIndexX = threadIdx.x;
int localIndexY = threadIdx.y;
int index = indexY * N + indexX;
int transposedIndex = tindexY * N + tindexX;
// reading from global memory in coalesed manner and performing tanspose in shared memory
sharedMemory[localIndexX][localIndexY] = input[index];
__syncthreads();
// writing into global memory in coalesed fashion via transposed data in shared memory
output[transposedIndex] = sharedMemory[localIndexY][localIndexX];
}
时间消耗
cpu
Time taken: 16.800961 ms
普通cuda
Time taken: 0.522752 ms
共享内存cuda
Time taken: 0.395680 ms
汇总代码如下:
#include <iostream>
#include <cuda_runtime.h>
#define blocksize 32
#define BSIZEX 32
#define BSIZEY 32
__global__ void transpose(float *input, float *output, int n)
{
int row = blockDim.y * blockIdx.y + threadIdx.y;
int col = blockDim.x * blockIdx.x + threadIdx.x;
if (row < n && col < n)
{
output[col * n + row] = input[row * n + col];
}
}
__global__ void transposeShared(float *input, float *output, int N)
{
// 每个线程块都有一个 BLOCK_SIZE ✕ BLOCK_SIZE 的共享内存数组,用于存储其内部处理的数据
__shared__ int sharedMemory [blocksize] [blocksize];
// global index
int indexX = threadIdx.x + blockIdx.x * blockDim.x;
int indexY = threadIdx.y + blockIdx.y * blockDim.y;
// transposed global memory index
int tindexX = threadIdx.x + blockIdx.y * blockDim.x;
int tindexY = threadIdx.y + blockIdx.x * blockDim.y;
// local index
int localIndexX = threadIdx.x;
int localIndexY = threadIdx.y;
int index = indexY * N + indexX;
int transposedIndex = tindexY * N + tindexX;
// reading from global memory in coalesed manner and performing tanspose in shared memory
sharedMemory[localIndexX][localIndexY] = input[index];
__syncthreads();
// writing into global memory in coalesed fashion via transposed data in shared memory
output[transposedIndex] = sharedMemory[localIndexY][localIndexX];
}
// 主机上的矩阵转置函数,用于验证结果
void cpuTranspose(const float *input, float *output, int n)
{
for (int row = 0; row < n; ++row)
{
for (int col = 0; col < n; ++col)
{
output[col * n + row] = input[row * n + col];
}
}
}
int main()
{
float *A, *B, *outputcpu;
int n = 1024;
size_t size = n * n * sizeof(float);
A = (float *)malloc(size);
B = (float *)malloc(size);
outputcpu = (float *)malloc(size);
for (int i = 0; i < n * n; i++)
{
A[i] = i + 1;
}
float *input, *output;
cudaMalloc((void **)&input, size);
cudaMalloc((void **)&output, size);
cudaMemcpy(input, A, size, cudaMemcpyHostToDevice);
// 定义CUDA事件
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
dim3 blockDim(BSIZEX, BSIZEY);
dim3 gridDim((n + BSIZEX - 1) / BSIZEX, (n + BSIZEY - 1) / BSIZEY);
// 记录开始时间
cudaEventRecord(start);
transposeShared<<<gridDim, blockDim>>>(input, output, n);
// 记录结束时间
cudaEventRecord(stop);
// 等待直到事件完成
cudaEventSynchronize(stop);
// 计算耗时
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
printf("Time taken: %f ms\n", milliseconds);
// 清理事件
cudaEventDestroy(start);
cudaEventDestroy(stop);
cudaMemcpy(B, output, size, cudaMemcpyDeviceToHost);
cpuTranspose(A, outputcpu, n);
for (int i = 0; i < n * n; ++i)
{
if (fabs(outputcpu[i] - B[i]) > 1e-5)
{
printf("result error!");
break;
}
}
free(A);
free(B);
free(outputcpu);
cudaFree(input);
cudaFree(output);
return 0;
}
参考文献:
https://deployment.gitbook.io/love/whitepaper/cuda/global_memory
https://zhuanlan.zhihu.com/p/568769940