缓存异常:缓存穿透、缓存击穿、缓存雪崩
文章目录
- 一、缓存异常问题与解决
- 1.1 缓存穿透
- 1.2 缓存击穿
- 1.3 缓存雪崩
- 二、缓存方案的局限
一、缓存异常问题与解决
在高并发系统中,缓存(如 Redis)承担着“抗高并发、减轻数据库压力”的核心作用。但在实际业务中,缓存机制并非完美,常见的异常问题包括缓存穿透、缓存击穿和缓存雪崩。这三种问题本质上都是由于缓存失效或未命中导致大量请求直接访问数据库,从而引发数据库压力骤增。
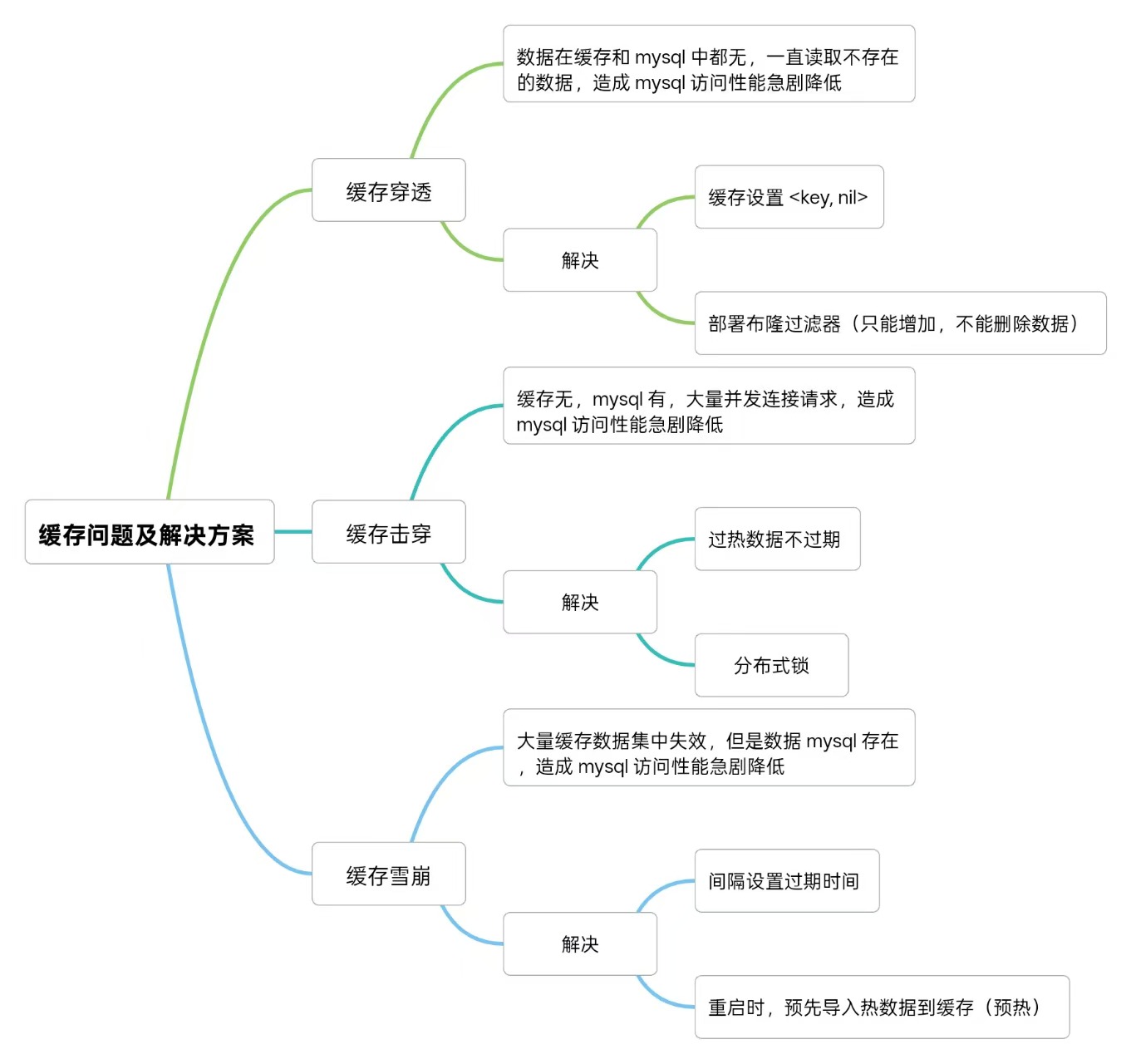
1.1 缓存穿透
缓存穿透指的是——请求的数据在缓存和数据库中都不存在。此时每次请求都会“穿透”缓存,直接打到数据库;若请求量巨大,会导致数据库 QPS(每秒查询数)激增,甚至被压垮。
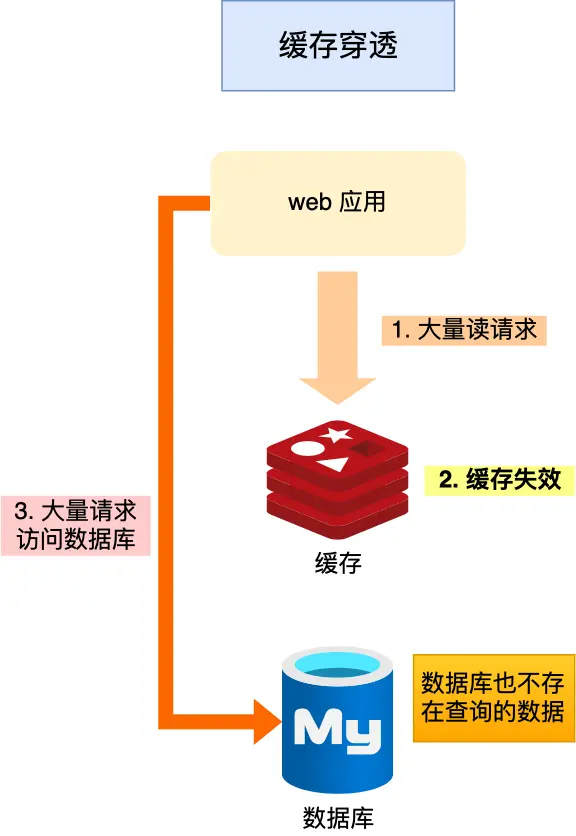
图:小林coding
解决方案主要有两种思路:
① 缓存空值:当数据库查询结果为空时,也将 <key, nil> 写入缓存,并设置一个较短的过期时间(例如 5 分钟)。这样后续相同的无效请求会被缓存层直接拦截,而不会再次访问数据库。
注意:应避免缓存中积累大量无意义的空值,可设置短期过期或使用定期清理机制。
② 布隆过滤器(Bloom Filter):在缓存层前增加一层布隆过滤器,用于快速判断某个 key 是否可能存在。
- 若布隆过滤器判断该 key 一定不存在,则直接拒绝请求;
- 若判断可能存在,再走“缓存 -> 数据库”流程。
这种方式能有效拦截大部分无效请求,但需要注意:布隆过滤器是只能新增、无法删除的结构,适合数据删除较少的业务场景。
1.2 缓存击穿
缓存击穿是指——某个热点数据(高频访问的 key)在某一时刻突然失效,而数据库中该数据仍然存在。此时,成百上千个请求同时访问这个 key,全部穿透到数据库,引发瞬时访问洪峰,严重时可能造成数据库宕机。
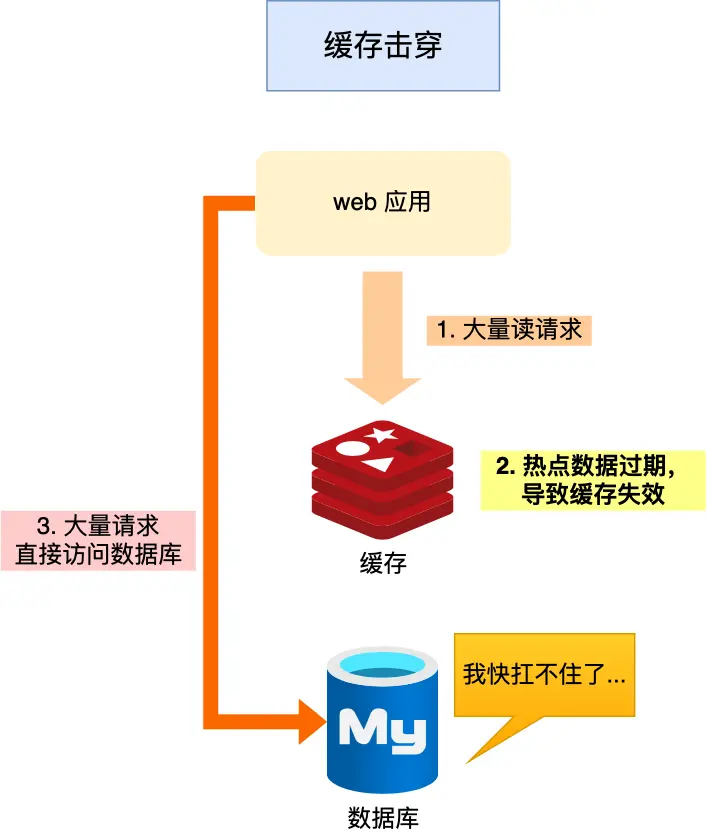
图:小林coding
常见解决方案:
① 过热数据永不过期:
对业务中访问频率极高的热点数据(例如首页爆款商品信息、热门榜单),可以将其缓存设置为“永不过期”,并通过主动刷新或后台异步更新机制保持数据的新鲜度,从根源上避免击穿。
② 分布式锁机制:
当某个 key 缓存失效时,通过分布式锁(如 Redis 的 SETNX)保证只有一个线程去查询数据库并回写缓存。
其他线程等待该线程完成缓存更新后,再从缓存读取数据。
这种方式能有效防止同一时刻多个线程同时访问数据库,保护后端系统稳定性。
1.3 缓存雪崩
缓存雪崩的概念是——在同一时间内,大量缓存数据集中失效或缓存服务不可用,导致所有请求都涌向数据库,形成“雪崩效应”,可能使数据库直接被打垮,甚至引发服务整体不可用。
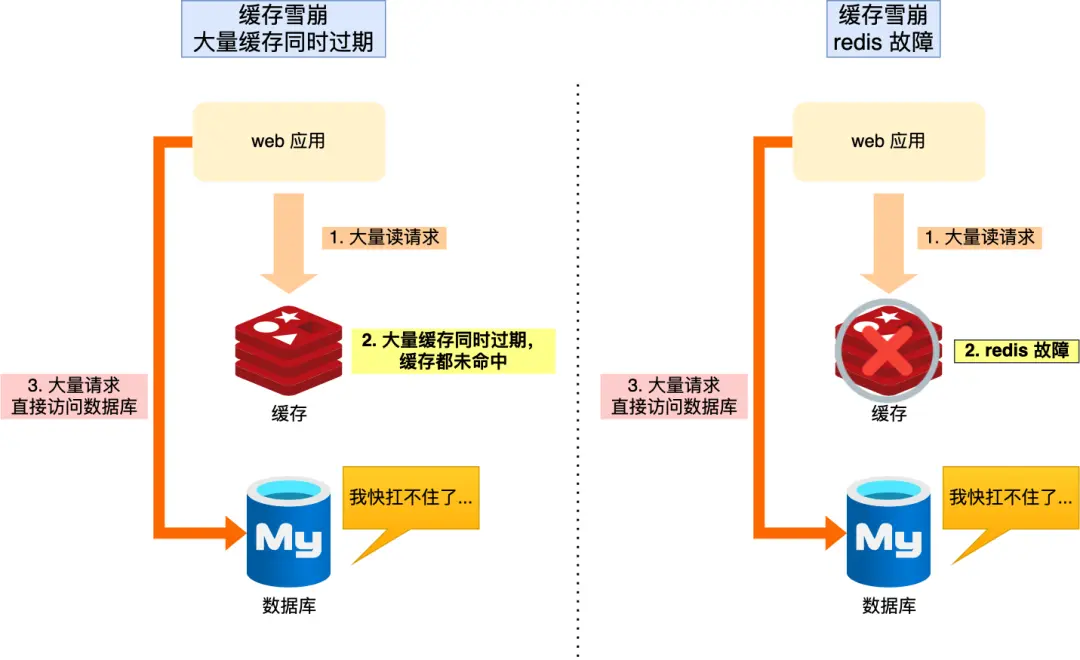
图:小林coding
常见应对方案:
① 提高缓存系统的高可用性:
如果因 Redis 宕机导致缓存层不可用,可通过哨兵模式或 Cluster 集群模式提高可用性。
- 哨兵模式可以自动监控主从节点并完成故障转移;
- Cluster 模式则通过多主多从架构实现数据分片与冗余,保证单节点故障不影响整体服务。
② 错开缓存过期时间:
如果大量 key 设置了相同的过期时间,就可能在某一时刻集中失效。
解决办法是在设置过期时间时加入随机偏移量(例如基础时间 + 随机 0~10 分钟),从而分散失效时间,避免集体“雪崩”。
③ 缓存预热机制:
当系统重启或 Redis 发生大规模数据丢失时,可以提前将“热数据”加载进缓存,确保系统上线时缓存中已包含核心数据,减少冷启动阶段对数据库的冲击。
- 如果重启时间较短,可依赖 Redis 的 持久化机制(RDB / AOF) 进行恢复;
- 如果重启时间较长,则可提前导出热数据文件,启动后再导入 Redis。
二、缓存方案的局限
尽管缓存机制能显著提升系统性能,但在实际应用中也存在一些明显的局限性,主要集中在事务处理能力不足与数据一致性风险两个方面。
首先,多语句事务支持有限。
关系型数据库的事务要求所有操作在同一条连接中执行,以保证原子性。而缓存与数据库属于两个独立系统,通常无法保证多语句事务全部在同一连接内执行,从而破坏事务的原子性,导致“部分更新”或“部分提交”的异常情况。
其次,Redis 事务不支持回滚。
虽然 Redis 提供了 MULTI / EXEC 事务命令,但如果事务中某条命令执行失败,Redis 不会像 MySQL 一样自动回滚,之前的操作依然会生效。这种“无回滚机制”使得 Redis 在事务一致性上存在天然缺陷。
最后,Redis 与 MySQL 的数据一致性难以完全保障。
缓存层与数据库层分别存储不同副本的数据,在高并发场景中若处理不当,可能出现“缓存与数据库内容不一致”的情况。例如写 MySQL 成功但写 Redis 失败、或缓存过期时间未及时更新等,都会造成数据不一致问题。
因此在设计中通常需要配合延迟双删、消息队列异步同步、订阅通知机制等方式来缓解这一问题。