Hybrid OCR-LLM框架用于在大量复杂密集企业级文档信息提取
在文档解析过程中,你是否遇到过表单、证书或报告之类的大量结构相似内容文档?
今天的文章提供了一些想法和见解。
在这里插入图片描述
为什么内容密集型文档仍深陷低效泥潭?
让我们从一个简单的定义开始。当我们说“文本密集型”文档时,指的是像保险单、政府表格、财务报表和身份记录这类文件。这些文档的难点不在于含义多变,而在于它们具有高度重复性、结构固定,并且需要批量处理。

图1:文本密集型任务的文档示例:(a)保险索赔;(b)政府表格;(c)财务报告。[来源]。
那么瓶颈是什么呢?计算效率低、错误传播、系统脆弱性、格式变化的适应性问题以及LLMs的高延迟和生成式模型的解码开销。
大多数通用大型语言模型逐token生成文本。这对于写作或回答问题来说没什么问题。但当任务是提取大量几乎可以直接复制的结构化信息时,这种方法就变得极其低效。它速度慢、成本高,而且颇具讽刺意味的是,会给本应具有确定性的内容引入不必要的错误。
现在再加上现实的限制:业务工作流通常要求亚秒级的延迟和接近零的错误率。在生产流程中,即使是微小的错误也会引发重大问题。
归根结底:与其试图让一个模型做所有事情,我们不如将文档结构视为一种性能资产。当文档看起来相似时,这种相似性并非局限——而是一种机会。通过识别和利用结构模式,我们可以设计出更智能、更快速的系统,不必在每个页面上都浪费时间做重复工作。
引入混合OCR-LLM:两阶段、三模式提取
为解决这一问题,论文提出了一个混合框架,该框架清晰地分离了文档智能中的两个核心步骤:读取和理解。
这个想法很简单。首先,专注于从文档中提取清晰、结构化的文本。然后,专注于理解这些文本。每个步骤都使用最适合该任务的工具,而不是强迫一个模型完成所有工作。
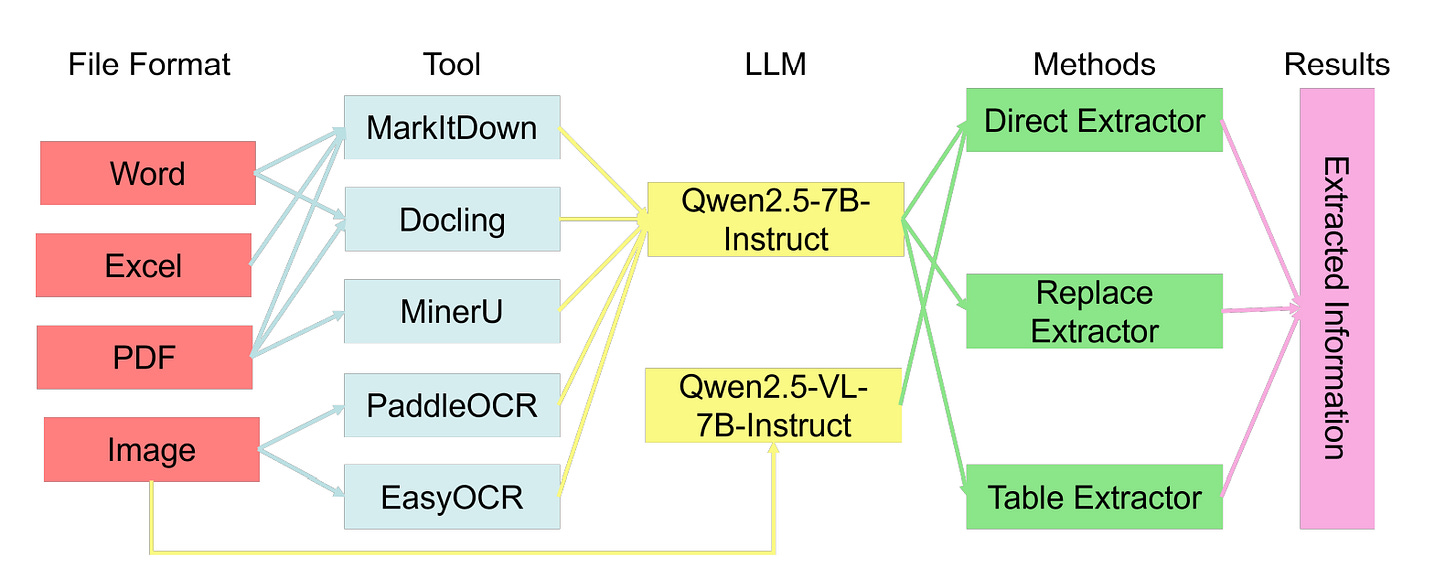
图2:提取框架包括文本提取和基于LLMs的信息提取两个主要组件。文本提取工具包括MarkItDown、Docling、MinerU、PaddleOCR和EasyOCR,分别用于处理Markdown、Word、Excel、PDF和图像文件。提取的文本传递给LLMs进行特定任务的信息提取[来源]。
第一阶段:文本获取
根据文件类型的不同,会使用不同的解析或光学字符识别工具——MarkItDown、Docling、MinerU、PaddleOCR、EasyOCR——来提取内容。这里的目标不仅仅是提取文字,尽可能保留布局和位置信息也很重要。这些上下文往往承载着重要的含义,尤其是在表格、表单和官方文件中。
选择合适的解析工具
并非所有格式都是一样的,不同的工具各有其优势。
- Docling 非常适合保持阅读顺序和层次结构。这对于那些对布局敏感的任务特别有用,比如解析表格或理解文档章节。
- MinerU(RAG基建之PDF解析的“流水线”魔法之旅)专注于复杂PDF的像素级布局恢复。当视觉结构与文本本身同等重要时,它的表现尤为出色。
- MarkItDown(PDF与Markdown的量子纠缠:一场由VLM导演的文档界奇幻秀)可处理常见的办公文件格式并保留语义标记,这有助于维持逻辑结构。
- PaddleOCR和EasyOCR用于基于图像的文档。PaddleOCR在多语言场景中表现更佳,并且在将文本映射到空间位置方面做得更为一致。
所有这些选择都遵循一个关键原则:结构的准确性比原始文本的准确性更重要。特别是对于表格密集型的工作流程,保持布局至关重要。否则,后续的表格提取往往会失败。
第二阶段:目标提取
提取策略:设计了三种互补的提取策略:直接提取、替换提取和表格提取。
在三种提取模式中选择
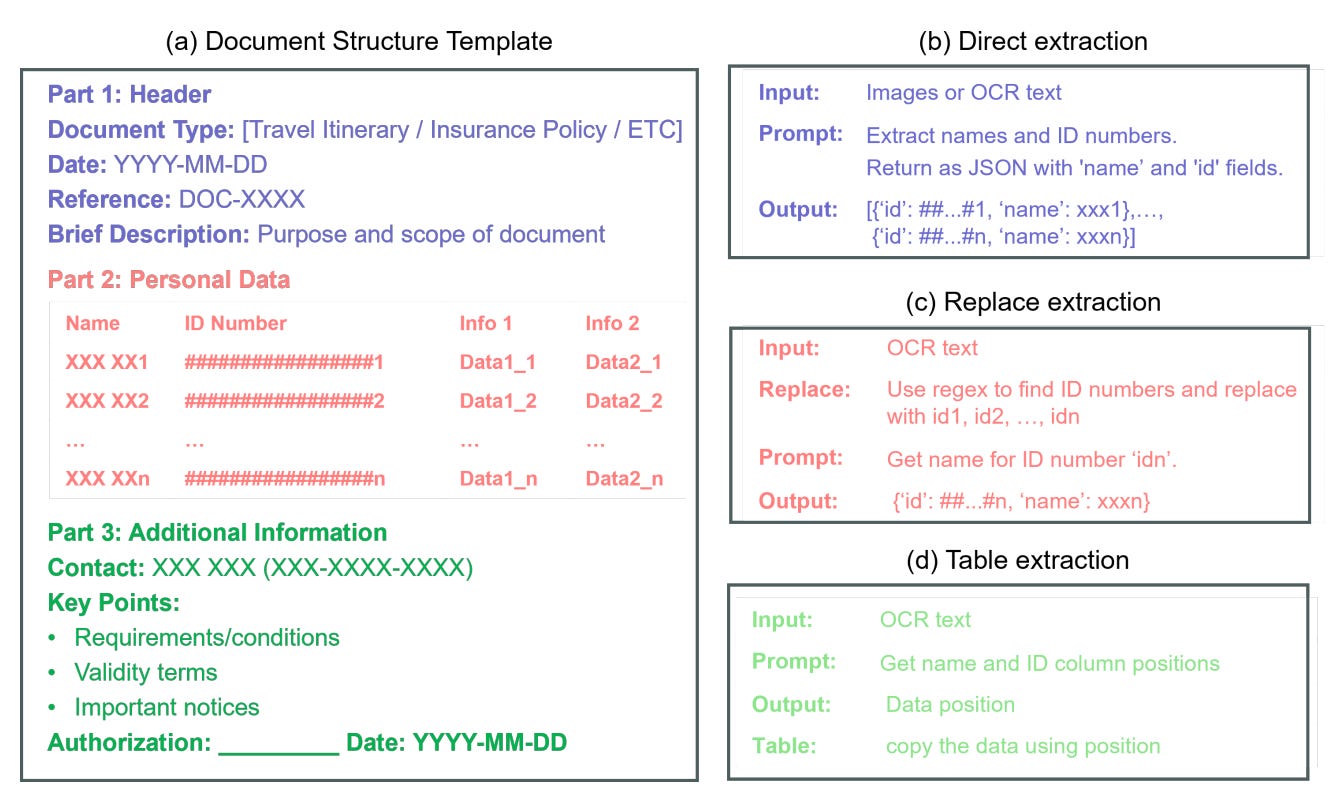
图3:文本密集型任务的提取方法:(a)文档结构模板;(b)直接提取;(c)替换提取;(d)表格提取。[来源]。
-
•直接提取:将原始文本传递给LLMs进行端到端的信息提取。是最灵活的。它在各种格式中都能很好地工作,但通常会受到大模型推理速度的限制。
-
•替换提取:首先用唯一占位符替换结构化元素,然后LLMs根据占位符检索关联字段。对于具有重复字段或模板的文档来说是可靠的。然而,当上下文被剥离时,它在处理一些微妙的关联(如将姓名与身份证号关联)时可能会遇到困难。
-
•表格提取:当结构可预测时,表格的效率最高,结合LLM的结构识别和基于规则的解析,LLM识别表格区域和目标单元格坐标,规则解析器提取内容。在表格提取方法中,LLM和基于规则的解析器协同工作的方式如下:
- 1.LLM的结构识别:LLM(如Qwen2.5-7B)首先识别文档中的表格区域和目标单元格的坐标。LLM通过训练数据学习到的上下文信息,能够准确地定位表格结构和单元格位置。
- 2.基于规则的解析:一旦LLM识别出表格区域和单元格坐标,基于规则的解析器(如Docling的表格提取方法)会提取这些单元格中的内容。这种方法利用预定义的规则和模式来解析表格数据,确保提取的准确性和一致性。
这种协同工作的优势包括:
- •减少生成成本:通过限制LLM的输出仅为位置元数据,大大减少了模型的生成成本。LLM只需生成表格的坐标信息,而不是整个文档的内容。
- •最小化错误传播:基于规则的解析器在提取过程中不会引入额外的错误,从而减少了错误传播的可能性。LLM的输出经过规则解析器的进一步验证和提取,确保了数据的准确性。
- •高效处理:表格提取方法通过结合LLM的结构识别和基于规则的解析,实现了高效的文档处理。LLM的快速识别和规则解析器的精确提取相结合,使得整个提取过程既快速又准确。
模型选择
文本类任务使用Qwen2.5-7B,图文结合场景使用Qwen2.5-VL-7B。这些模型在准确性、效率和指令遵循稳定性之间为我们提供了良好的平衡。
为什么选择70亿参数模型?
70亿参数规模的模型达到了一个理想平衡点:它们足够轻量,可在单GPU上部署,同时在生成结构化输出方面仍表现稳健。这些模型在文本和多模态输入上都能保持一致性,这使得评估和维护工作变得容易得多。
评估
该实验使用了400份合成的中国身份证件,涵盖四种格式:PNG、DOCX、XLSX和PDF。实验在直接、替换和表格三种提取模式下测试了16种不同的OCR-LLM组合,每种格式最多有100个样本。总共评估了约2500个测试案例。
评估跟踪了标准指标,如精确率、召回率、F1分数和处理延迟(细分为光学字符识别和大语言模型组件)。它还报告了成功率和每种格式的准确率。
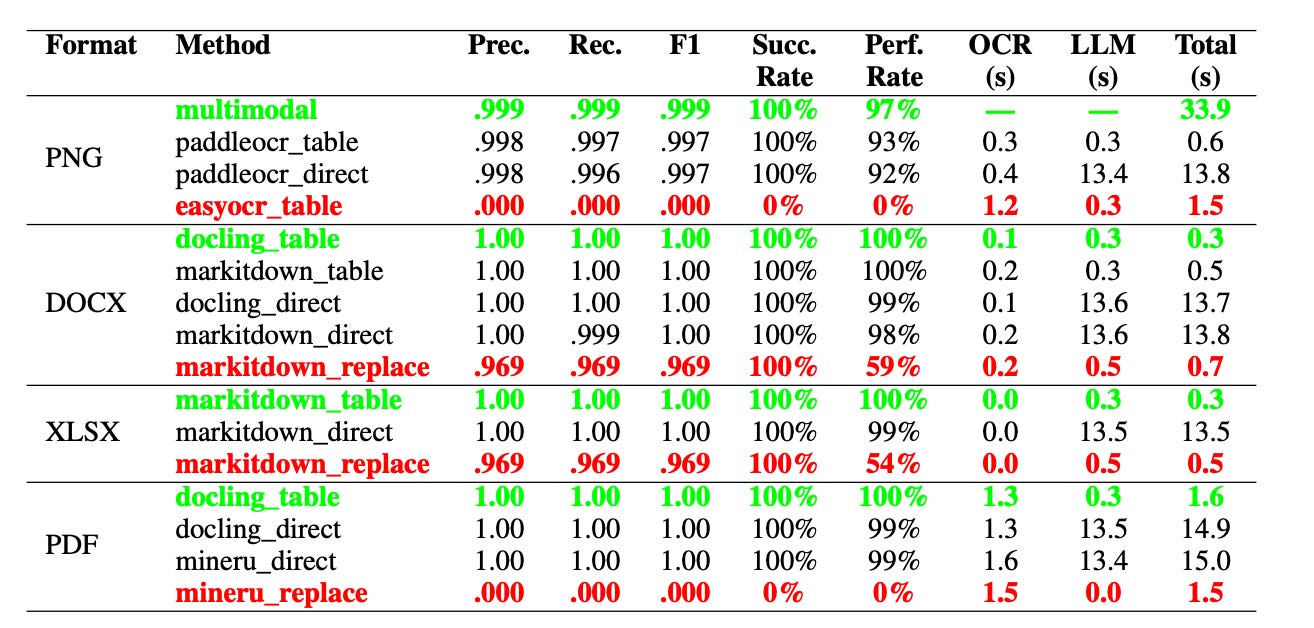
图4:比较性能指标,按文档格式显示最佳(绿色)和最差(红色)提取方法。多模态方法使用Qwen2.5-VL-7B,而所有其他方法使用Qwen2.5-7B。Prec.=精确率,Rec.=召回率,Succ. Rate=成功率(成功提取的百分比),Perf. Rate=完美率(达到1.0的完美F1分数的百分比)。OCR时间表示字符识别开销;LLM时间表示推理延迟。[来源]。
在DOCX和XLSX等结构化格式上,表格模式的结果堪称完美:F1分数为1.0,延迟在0.3至0.5秒之间,成功率达100%。另一方面,替换模式在这些格式上的表现最差,F1分数约为0.969,完美提取率下降,DOCX为59%,XLSX为54%,这主要是因为大语言模型偶尔会将名称与其对应的身份证号码匹配错误。
对于基于图像的文档(PNG),一个多模态模型基线的F1分数达到0.999,但每个样本需要约33.9秒。当使用PaddleOCR作为上游工具时,表格模式保持了接近0.997的F1分数,同时将延迟降至约0.6秒,比多模态基线快了54倍。相比之下,EasyOCR与表格模式结合则完全失败,F1分数为0.000,因为EasyOCR的处理过程无法保留文本的空间布局,导致大语言模型无法定位表格单元格。
PDF结果显示出类似的模式。docling_table组合的F1值达到1.0,总延迟约为1.6秒。同时,mineru_replace完全失败,F1值和成功率均降至零,这凸显了方法与文档格式不匹配的风险。
总体而言,直接模式的推理时间始终最长,约为13-15秒,因为它严重依赖大语言模型。相比之下,Table模式在PNG/Office格式上的速度提升达到41-54倍;对于PDF格式,速度提升约为9-10倍。
评估得出的总体结论是,不存在“一刀切”的解决方案。最佳策略与文档格式有着内在联系,这证明了一个具有适应性且能识别格式的框架的必要性,该框架能将任务分配给最高效的方法——例如,对结构化文件采用基于表格的提取方式,而将多模态模型作为处理模糊图像的可靠备用方案。
思考
混合OCR-LLM并非将结构冗余视为问题,而是将其当作提升性能的手段。大语言模型扮演定位器的角色,而实际的内容提取则由确定性解析器负责。这是一个罕见的实用配置案例,专为文本密集型文档设计,并且与低延迟、高稳定性的生产目标高度契合。
不过,该流程严重依赖于稳定的布局模式以及OCR层提供的精确空间保真度。页面边距的任何变动、新字段的添加、印章与文本的重叠,甚至OCR引擎的更换,都可能导致系统突然失效。正如EasyOCR与表格模式结合的案例所示,其性能可能会从近乎完美骤降至完全无法使用。
参考文献:面向企业级文档信息抽取混合OCR-LLM框架。