网站维护提醒php文件荣耀手机官网入口
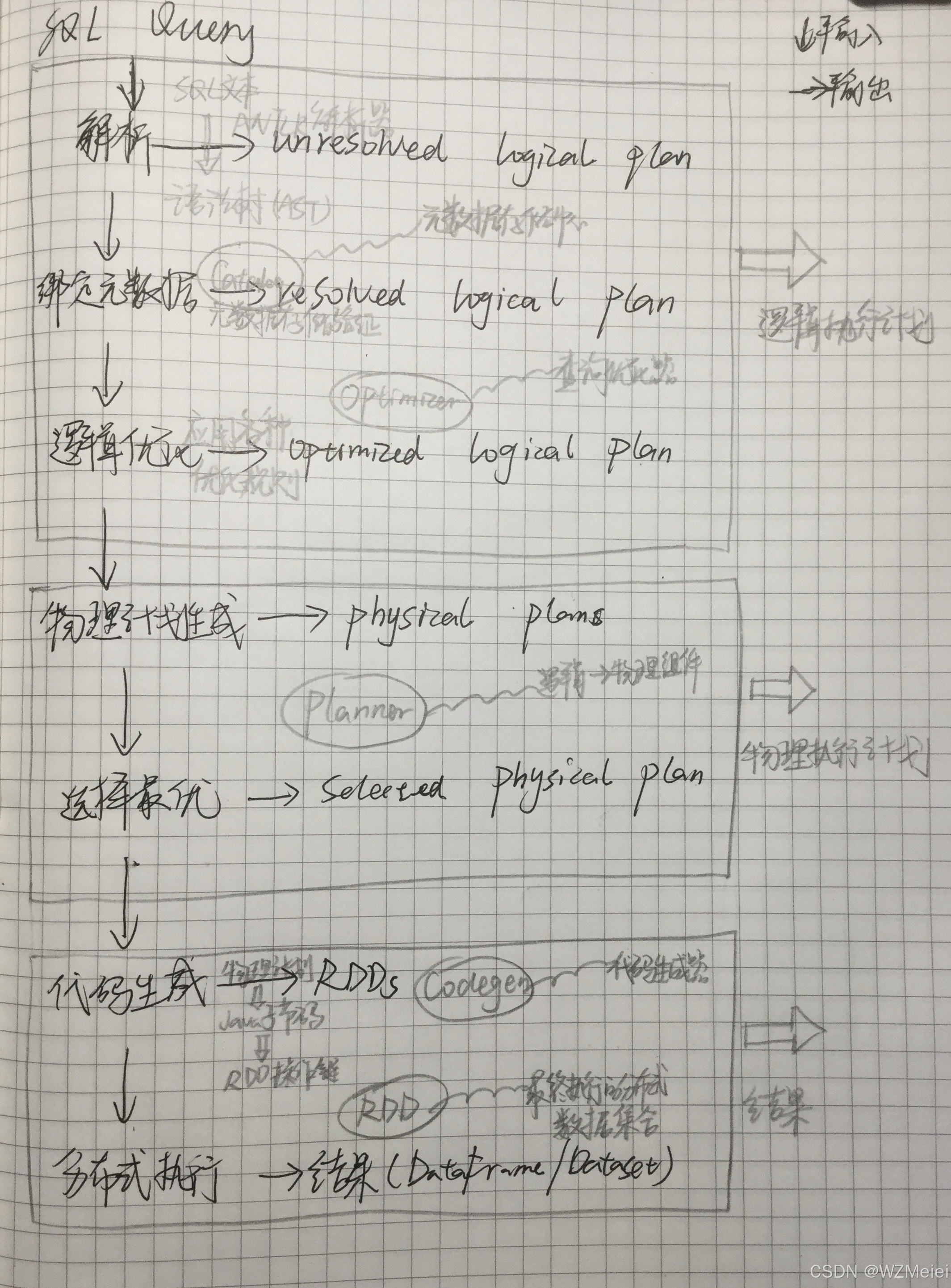
1. 整体架构概览
Spark SQL的运行过程可以想象成一个"SQL查询的加工流水线",从原始SQL语句开始,经过多个阶段的处理和优化,最终变成分布式计算任务执行。主要流程如下:
SQL Query → 解析 → 逻辑计划 → 优化 → 物理计划 → 执行 → 结果
2. 详细阶段解析
阶段1:SQL解析(Unresolved Logical Plan)
-
输入:用户提交的SQL查询语句
-
处理:Spark使用ANTLR等解析器将SQL文本转换为语法树(AST)
-
输出:生成"未解析的逻辑计划"(Unresolved Logical Plan)
-
这时计划是初步的,还不知道表在哪、字段类型是什么
-
类似"我要找某个表里的某些数据",但具体细节还不明确
-
阶段2:元数据绑定与验证(Resolved Logical Plan)
-
输入:未解析的逻辑计划
-
处理:
-
查询Catalog(元数据存储)获取数据库、表、列等信息
-
验证表是否存在、字段是否存在、类型是否匹配
-
-
输出:生成"已解析的逻辑计划"(Resolved Logical Plan)
-
现在知道具体从哪个表的哪个字段获取数据了
-
阶段3:逻辑优化(Optimized Logical Plan)
-
输入:已解析的逻辑计划
-
处理:应用各种优化规则:
-
列剪裁:只选择需要的列,减少数据传输
-
谓词下推:尽早过滤数据,减少处理量
-
常量折叠:提前计算常量表达式
-
分区剪裁:只扫描需要的分区
-
-
输出:生成"优化后的逻辑计划"
-
这时计划已经更高效,但还不知道具体如何执行
-
阶段4:物理计划生成(Physical Plan)
-
输入:优化后的逻辑计划
-
处理:
-
将逻辑操作转换为物理操作(如join用哪种算法)
-
生成多个可能的物理执行方案
-
基于成本模型选择最佳方案
-
-
输出:生成"物理执行计划"
-
现在知道具体如何执行了,但还不是可执行代码
-
阶段5:代码生成与执行(Selected Physical Plan → RDDs)
-
输入:物理执行计划
-
处理:
-
代码生成:将物理计划转换为Java字节码(避免解释执行开销)
-
转换为RDD:生成Spark底层执行的RDD操作链
-
分布式执行:在集群上并行执行
-
-
输出:计算结果(通常返回DataFrame/Dataset)
3. 关键组件说明
-
Catalog:元数据存储中心,记录所有数据库、表、函数等信息
-
Optimizer:查询优化器,包含数百种优化规则
-
Planner:将逻辑计划转换为物理计划的组件
-
Codegen:代码生成器,提升执行效率
-
RDD:最终执行的分布式数据集合
4. 举例说明
假设执行一个简单查询:
SELECT name FROM users WHERE age > 30-
解析:识别出这是从users表查询name列,条件是age>30
-
绑定:检查users表是否存在,是否有name和age列
-
优化:决定先过滤age>30再取name列(谓词下推)
-
物理计划:选择全表扫描或索引扫描(如果有索引)
-
执行:生成代码在集群上并行扫描和过滤数据
5. 为什么这样设计?
这种分层架构的好处:
-
灵活性:可以支持多种查询语言(SQL/DataFrame API)
-
可扩展:容易添加新的优化规则或数据源
-
高效性:通过优化和代码生成提高性能
-
统一性:最终都转换为RDD执行,复用Spark核心引擎
接下来用番茄炒蛋例子更为详细的解释 Spark SQL 运行架构
Spark SQL 运行流程:厨房做菜版
想象你要做一道菜(执行一个SQL查询),Spark SQL就是你的智能厨房系统,帮你高效完成这道菜。步骤如下:
1. 点菜:接收你的SQL查询
-
你:“我要番茄炒蛋!”(相当于输入SQL:
SELECT * FROM 番茄表 WHERE 菜名='炒蛋') -
厨房:先听懂你的要求(检查语法对不对,比如有没有把“番茄”写成“蕃茄”)。
2. 检查食材:绑定元数据
-
厨房:打开冰箱(Catalog,存储所有食材信息),检查有没有“番茄”和“鸡蛋”。
-
如果冰箱里没有番茄,直接告诉你:“没番茄,做不了!”(报错:表或列不存在)。
-
如果有,确认番茄和鸡蛋的位置(比如在冰箱第二层)。
-
3. 优化菜谱:找到最快的做法
-
智能助手(Catalyst优化器):帮你想怎么省时间:
-
列剪裁:你只要番茄和蛋,其他食材(比如洋葱)直接忽略。
-
谓词下推:先挑出熟透的番茄(提前过滤
WHERE 番茄.状态='熟'),再切块。 -
常量替换:你说“加一勺盐”,助手直接换成“5克盐”。
-
4. 准备工具:生成物理计划
-
厨房:决定用炒锅还是平底锅(选择物理操作,比如用
BroadcastHashJoin快速翻炒)。-
可能试几种方法(生成多个候选计划),最后选最快的那个。
-
5. 开始炒菜:生成代码并执行
-
自动炒菜机(代码生成器):把步骤写成机器指令(字节码),避免手动操作慢。
-
执行:机器开火、倒油、下锅(转换成RDD操作,分布式执行)。
6. 上菜:返回结果
-
结果:一盘番茄炒蛋(DataFrame/Dataset),你可以直接吃,或者再做其他菜(继续处理数据)。
关键角色解释
-
Catalog(冰箱):存了所有食材(表、列)的位置和状态。
-
优化器(智能助手):帮你省时间、省材料。
-
物理计划(工具选择):用炒锅还是微波炉?选最高效的工具。
-
RDD(流水线):厨房里的多个厨师同时切菜、炒菜(分布式计算)。
为什么需要这些步骤?
-
提前检查食材:避免炒到一半发现没鸡蛋!
-
优化步骤:让你最快吃上菜,不浪费时间。
-
分布式执行:多个厨师一起干活,比一个人快得多!
一句话总结
Spark SQL就像智能厨房:听懂你的要求 → 检查食材 → 优化步骤 → 开火炒菜 → 上菜,中间全是自动化的“黑科技”帮你省时省力!
Spark SQL 运行架构图