黑马JAVA+AI 加强07 Stream流-可变参数
1.Stream流
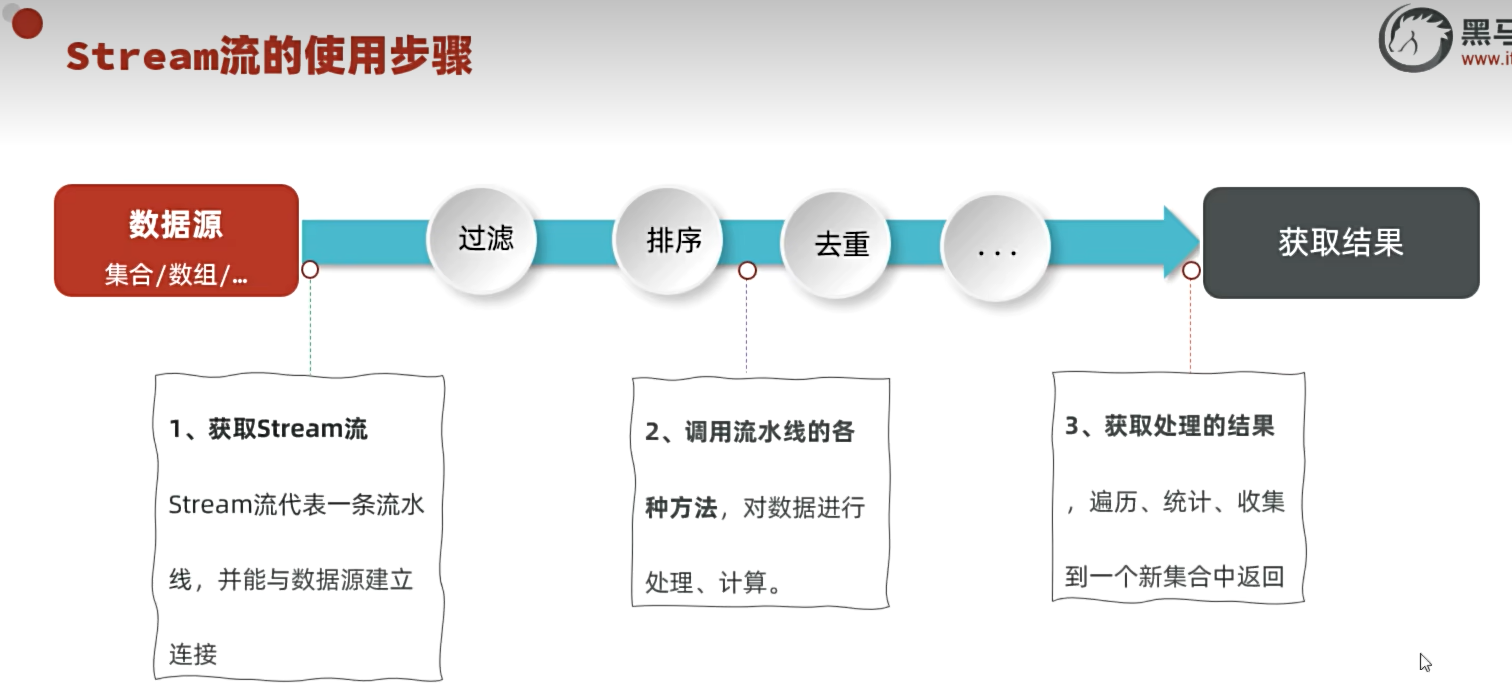
- Stream 流是 Java 8 引入的函数式编程核心特性,用于对集合(或数组)进行高效、声明式的操作(过滤、映射、聚合等)。它的设计目标是简化集合处理代码,同时支持并行处理以提升性能。
核心特点
- 不存储数据:Stream 只是操作数据的 “管道”,不会修改原始集合。
- 一次性使用:一个 Stream 只能遍历一次,再次使用需重新创建。
- 延迟执行:中间操作(如过滤、映射)不会立即执行,直到终端操作(如收集、打印)触发时才会执行,类似 “惰性求值”。
- 支持并行:可通过 parallelStream() 轻松实现并行处理,适合大数据量场景。
代码案例
public class StreamExample {public static void main(String[] args) {// 假设存在一个存储姓名的原始集合List<String> nameList = List.of("张三", "李四", "张三丰", "张伟", "张晓明", "王五");// 1. 传统方式:找出姓张且名字为3个字的人,存入新集合// 创建新集合用于存储结果List<String> newList = new ArrayList<>();// 遍历原始集合中的每个姓名for (String name : nameList) {// 过滤条件:姓名以"张"开头 并且 长度为3if (name.startsWith("张") && name.length() == 3) {// 符合条件的姓名添加到新集合newList.add(name);}}// 打印传统方式的结果System.out.println("传统方式筛选结果:" + newList);// 2. 使用Stream流解决相同问题将每一个对象nameObj进行类似于EXCEL的层层筛选// 步骤解析:// a. nameList.stream():将集合转换为Stream流,开启流操作// b. filter(s -> s.startsWith("张")):第一个过滤中间操作,保留以"张"开头的姓名// c. filter(s -> s.length() == 3):第二个过滤中间操作,保留长度为3的姓名// d. collect(Collectors.toList()):终端操作,将流处理结果收集为List集合List<String> newList2 = nameList.stream().filter(nameObj-> nameObj.startsWith("张")) // 过滤条件1:姓张.filter(nameObj-> nameObj.length() == 3) // 过滤条件2:名字3个字.collect(Collectors.toList()); // 收集结果为新集合// 打印Stream流方式的结果System.out.println("Stream流筛选结果:" + newList2);}
}
2.Stream流-中间方法

案例2
public class StreamDemo {public static void main(String[] args) {List<String> words = Arrays.asList("apple", "banana", "orange", "grape", "watermelon", "pear");// 1. 过滤(filter):保留长度>5的单词List<String> longWords = words.stream().filter(word -> word.length() > 5) // 中间操作:过滤.collect(Collectors.toList()); // 终端操作:收集为ListSystem.out.println("长度>5的单词:" + longWords); // [banana, orange, watermelon]// 2. 映射(map):将单词转为大写List<String> upperWords = words.stream().map(String::toUpperCase) // 中间操作:映射(方法引用简化).collect(Collectors.toList());System.out.println("大写单词:" + upperWords); // [APPLE, BANANA, ORANGE, GRAPE, WATERMELON, PEAR]// 3. 排序(sorted):按长度升序排列List<String> sortedWords = words.stream().sorted((s1, s2) -> s1.length() - s2.length()) // 中间操作:排序.collect(Collectors.toList());System.out.println("按长度排序:" + sortedWords); // [pear, apple, grape, banana, orange, watermelon]// 4. 聚合(count):统计长度<=5的单词数量 聚合还有很多,问AIlong shortWordCount = words.stream().filter(word -> word.length() <= 5).count(); // 终端操作:计数System.out.println("长度<=5的单词数量:" + shortWordCount); // 3(apple、grape、pear)// 5. 遍历(forEach):打印所有单词System.out.print("所有单词:");words.stream().forEach(word -> System.out.print(word + " ")); // 终端操作:遍历// 输出:所有单词:apple banana orange grape watermelon pear }
}
案例3
// 学生类
class Student {private String id;private String name;private int age;public Student(String id, String name, int age) {this.id = id;this.name = name;this.age = age;}// getter方法(Stream操作需要)public String getId() { return id; }public String getName() { return name; }public int getAge() { return age; }@Overridepublic String toString() {return "Student{id='" + id + "', name='" + name + "', age=" + age + "}";}
}public class MapStreamDemo {public static void main(String[] args) {// 初始化一个Map:键为学生ID,值为Student对象Map<String, Student> studentMap = new HashMap<>();studentMap.put("001", new Student("001", "张三", 17));studentMap.put("002", new Student("002", "李四", 19));studentMap.put("003", new Student("003", "王五", 20));studentMap.put("004", new Student("004", "赵六", 18));studentMap.put("005", new Student("005", "孙七", 17));// 1. 从entrySet()获取流(推荐,同时操作键和值)System.out.println("=== 1. 过滤年龄≥18的学生,保留ID和姓名 ===");Map<String, String> adultNameMap = studentMap.entrySet().stream()// 过滤:年龄≥18.filter(entry -> entry.getValue().getAge() >= 18)// 映射:键保留ID,值转换为姓名(大写).collect(Collectors.toMap(Map.Entry::getKey, // 新键:原键(学生ID)entry -> entry.getValue().getName().toUpperCase() // 新值:姓名大写));adultNameMap.forEach((k, v) -> System.out.println(k + " -> " + v));// 2. 从values()获取流(仅操作值)System.out.println("\n=== 2. 提取所有学生的年龄,求平均值 ===");OptionalDouble ageAvg = studentMap.values().stream()// 映射为年龄的IntStream.mapToInt(Student::getAge)// 求平均值.average();ageAvg.ifPresent(avg -> System.out.println("平均年龄:" + avg));// 3. 从keySet()获取流(通过键查值,效率较低,不推荐)System.out.println("\n=== 3. 筛选ID以'00'开头的学生 ===");List<Student> filteredStudents = studentMap.keySet().stream()// 过滤:ID以"00"开头.filter(id -> id.startsWith("00"))// 通过键获取值(学生对象).map(studentMap::get)// 收集为List.collect(Collectors.toList());filteredStudents.forEach(System.out::println);// 4. 分组聚合:按年龄分组,统计每个年龄段的学生数量System.out.println("\n=== 4. 按年龄分组统计人数 ===");Map<Integer, Long> ageCountMap = studentMap.values().stream()// 按年龄分组,值为每个组的人数(计数).collect(Collectors.groupingBy(Student::getAge, // 分组依据:年龄Collectors.counting() // 统计每组数量));ageCountMap.forEach((age, count) -> System.out.println("年龄" + age + ":" + count + "人"));// 5.合并流Stream<String> s1 = Stream.of("张三丰", "张无忌", "张翠山", "张角", "张学良");Stream<Integer> s2 = Stream.of(111, 22, 33, 44);Stream<Object> s3 = Stream.concat(s1, s2);System.out.println(s3.count());}
}
2.Stream流-终结方法

3.可变参数
- 可变参数(varargs)允许方法接收数量不固定的同类型参数,语法为 类型… 参数名,本质是数组的简化写法。以下是常用案例:
public class CollectionUtil {// 向集合中添加任意数量的元素public static <T> void addAll(List<T> list, T... elements) {for (T elem : elements) {list.add(elem);}}public static void main(String[] args) {List<String> fruits = new ArrayList<>();addAll(fruits, "苹果", "香蕉", "橙子"); // 批量添加3个元素System.out.println(fruits); // 输出:[苹果, 香蕉, 橙子]}
}
核心注意点
- 语法规则:可变参数必须写成 类型… 参数名,且必须是方法的最后一个参数(避免歧义)。
- 本质是数组:方法内部可将可变参数当作数组处理(如 numbers.length、for 循环遍历)。
- 参数兼容:调用时可传入单个元素、多个元素或数组,编译器会自动封装为数组。
- 避免重载陷阱:若方法重载时包含可变参数,可能导致调用歧义(如 method(int… a) 和 method(int a, int… b) 需谨慎使用)。
- 可变参数适用于参数数量不确定但类型一致的场景,能简化代码,避免重载多个参数个数不同的方法。