GPT-0: Attention+Transformer+可视化
本文介绍GPT组件: Attention+Transformer,及其可视化
原文 《Visualizing Attention in Transformer-Based Language Representation Models》, 2019
- link:https://arxiv.org/pdf/1904.02679
- code: https://github.com/jessevig/bertviz, 《Visualize Attention in NLP Models》
1.Attention原文
原文核心就1个公式和2个图
1.1 公式
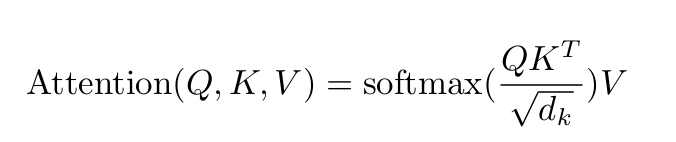
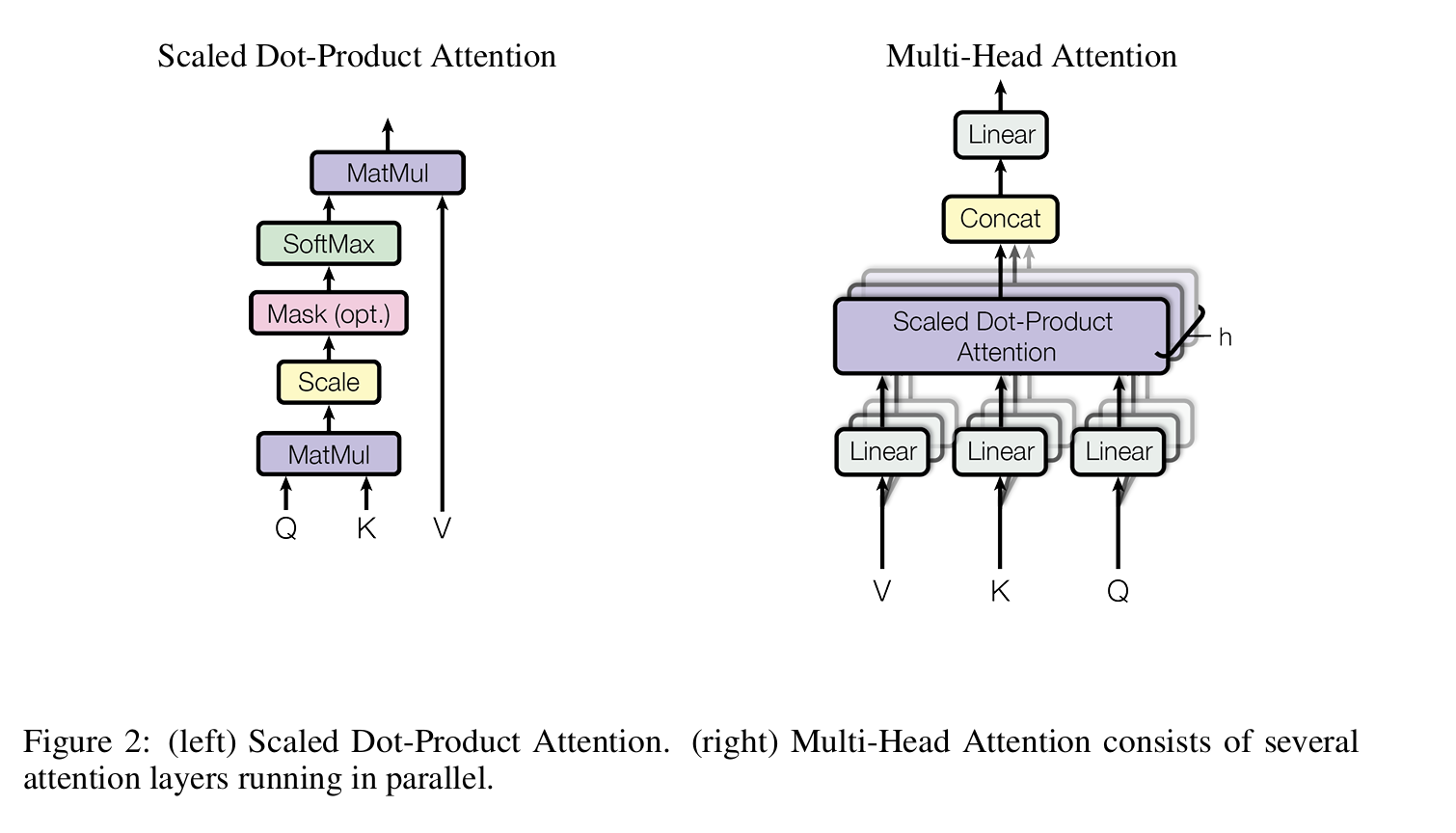
1.2 多头注意力
图2展示attention的计算方法,即点积,输出标量,即注意力值(得分)
以及多头注意力的结构:
1.3 Transformer结构
图1以自编码器(auto-encoder)的方式展示Transformer结构。
左边是解码器(decoder),右边是编码器(encoder)。
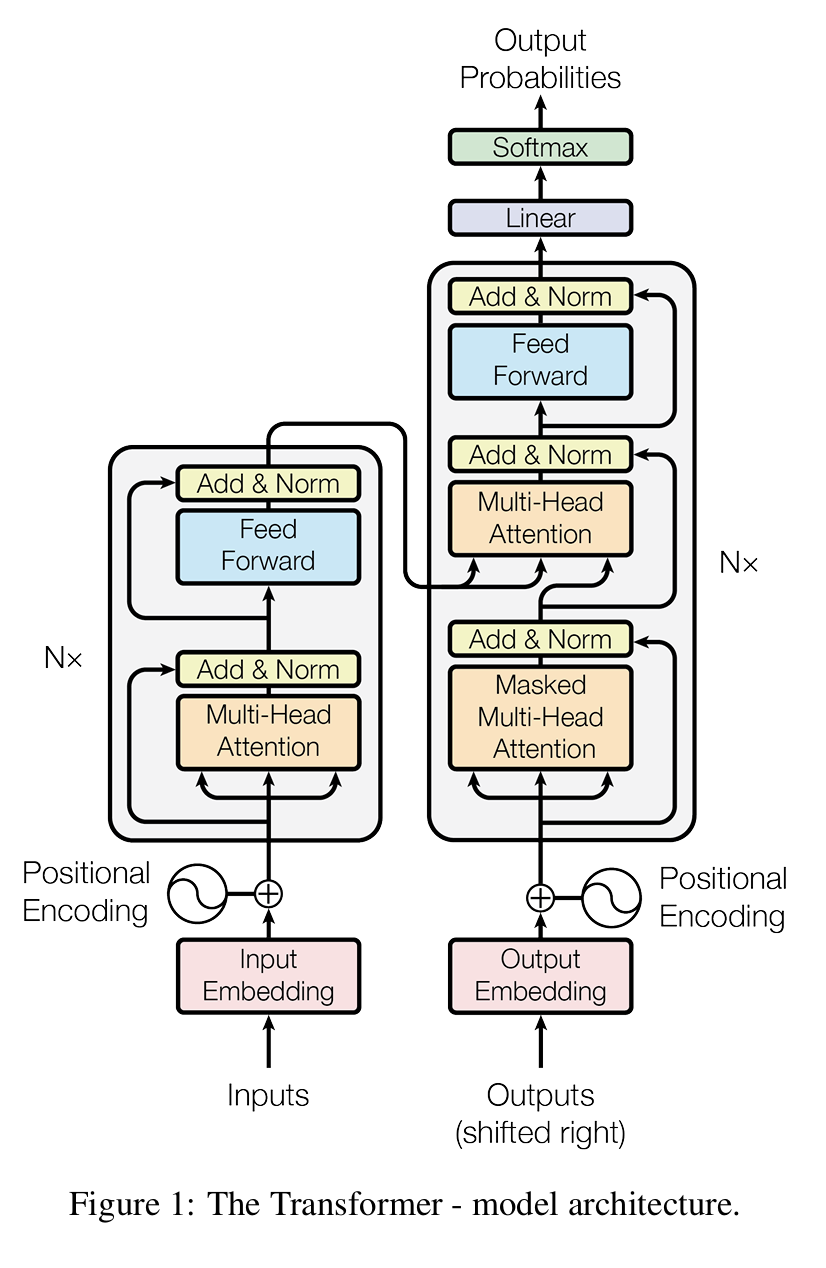
当前大模型更多不用自编码器,仅用解码器部分(decoder-only)
另外Feed-Forward Network (FFN)通常是普通的全链接网络:线性层+激活函数
2.Attention可视化
| 层级 | 学到的主要信息 | 注意力特征 |
|---|---|---|
| 低层(1–4) | 表层语言特征:字形、位置、词序 | 强位置依赖,捕捉局部顺序关系 |
| 中层(5–8) | 句法结构、词类依赖(POS patterns) | 出现明确句法或搭配规律,如介词↔宾语 |
| 高层(9–12) | 语义与实体层次规律 | 关注跨词组或概念性关联(缩写、命名实体等) |
2.1 图1-多头注意力可视化(GPT-2 Attention Head View)
Attention 可视化是解释大模型内部机制的关键手段。
图1展示GPT2的 多头注意力(attention heads)在文本处理时“注意力”关系的内部工作方式
图1输入的文本是:“The quick, brown fox jumps over the lazy”,模型还未看到“dog”这个词(它只看到到 lazy)。
| 图1 | 内容 | 含义 |
|---|---|---|
| 左图 | 第四层橘色head 注意力分布 | 显示此 head 学到的语法/语义依赖 |
| 中图 | 第一层蓝色head 注意力分布 | 显示此 head 学到的语法/语义依赖 |
| 右图 | 中图同一个 head, 但选定“lazy”词 | 展示形容词-名词修饰关系 |
-
每一个不同颜色小格区分不同的 attention head。
-
线条粗细表示注意力强度(score 大→粗/深)。
-
左侧(横轴)表示 token在看谁(query),右侧 (纵轴)是关注的目标词(key)。

总结- 每个 head 学习一种“关系模式”或“依赖模式”
- 有的 head 专注于 句法结构(如主语-动词配对);
- 有的 head 专注于 语义一致性(如形容词-名词);
- 有的 head 专注于 上下文衔接(如句首与句尾联系)。
2.1.1 左图(Left Figure)
第4层 橘色 attention head 注意力可视化。
例如,第 5 个 token(例如 “jumps”)时,模型对 “fox” 有很高的注意力权重,就说明这个 head 认为“jumps”应该参考“fox”的信息。
2.1.2 中图(Center Figure)
第一层蓝色 attention head 的注意力可视化。
例如:
- “fox” → “brown” 可能线条较粗,表示该 head 把“fox”的意义与“brown”联系起来。
- “lazy” → “the” 可能线条较细或无连接。
2.1.3 右图(Right Figure)
与中图相同的层 / head,但固定选中了 token “lazy”。
展示该 head 在处理“lazy”这个词时,注意力主要集中在什么地方。
可以观察到,“lazy”这个词会强烈地指向 “the”(定冠词),表明模型学会了 形容词-名词短语(adjective phrase) 的语法结构规律。
即“形容词通常修饰紧随其后的名词”。
不同层的 heads 学到不同层次的信息:
- 底层 head 更多是局部依赖(如词法、短距离语法);
- 高层 head 更多是全局语义(如句意、上下文衔接)。
- 每个 head 形成了特定的功能化角色(functional specialization);
2.2 图2 BERT 的 Attention Head View
输入:Sentence A: “The cat sat on the mat.” ;Sentence B: “The cat lay on the rug.”
BERT 的encoder-only 可以同时看前后文(双向 attention),处理句子对任务。
| 部分 | 内容 | 说明 |
|---|---|---|
| 左图 | 第0层蓝色 head | 表现 句内 attention pattern:比如“cat”→“the”,或“sat”→“cat”,代表句法结构内部关系。 |
| 中图 | 第十层蓝色head | 表现 句间 attention pattern:部分词(如“cat”)在 Sentence A 与 Sentence B 中建立语义对齐关系,表示模型识别出两个句子的语义相似性。 |
| 右图 | 相同的层/head,但开启 “Sentence A → Sentence B filter” | 只显示 Sentence A 中词对 Sentence B 中词的注意力连接,清晰地看到跨句对齐关系(例如“cat”↔“cat”,“mat”↔“rug”)。 |
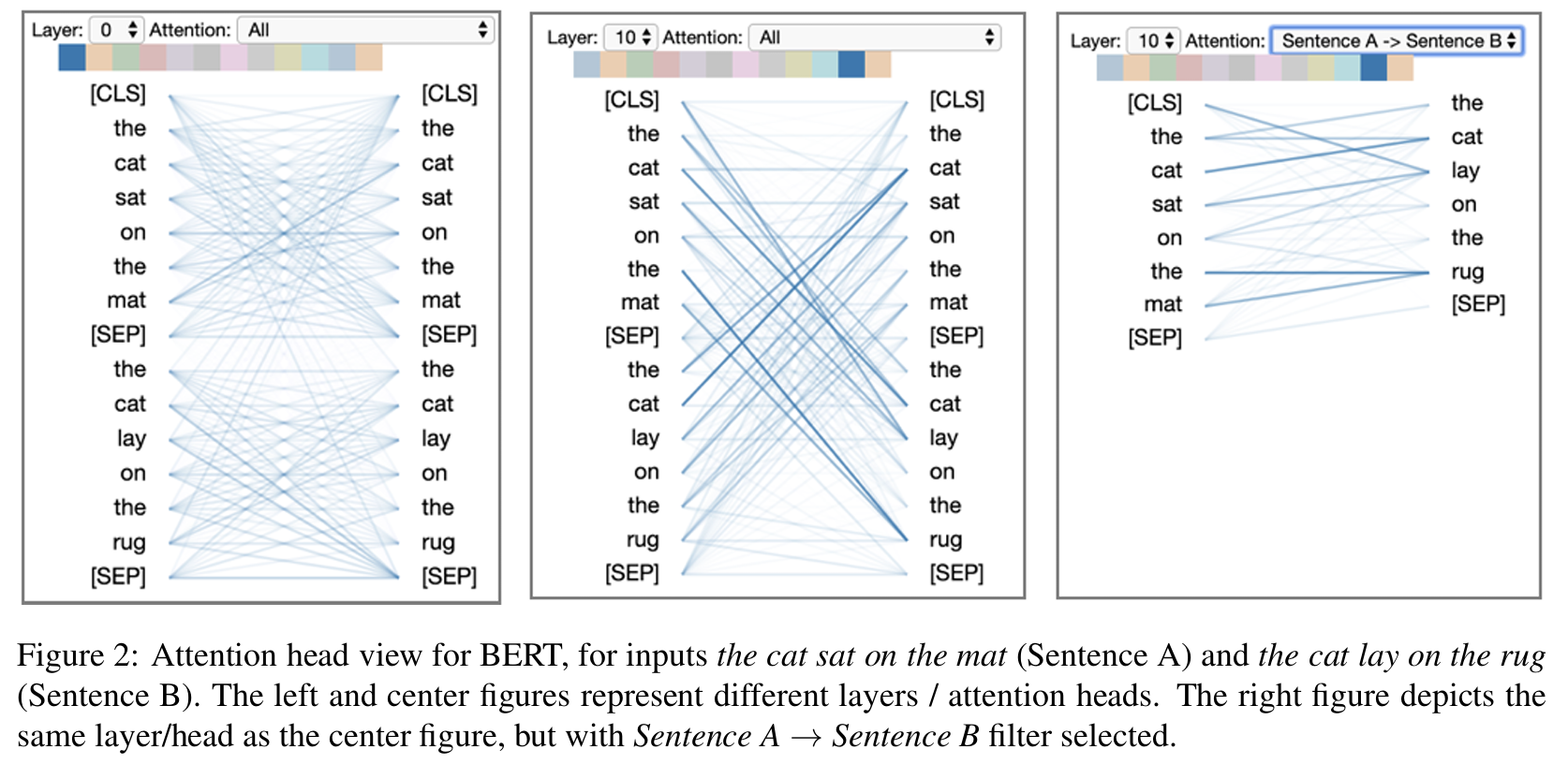
总结
- Head 的“独立性”:各 head 参数独立,因此能学习互补模式(句法、词汇、对齐、语义等)。
- 功能特化:有的 head 学到 punctuation、named entity、subject-verb pair 等特定语言规律。
| 对比项 | GPT-2 (Fig. 1) | BERT (Fig. 2) |
|---|---|---|
| 架构 | Decoder-only | Encoder-only |
| Attention方向 | 单向(仅看前文) | 双向(看前后文) |
| 输入 | 单句文本 | 句对输入 |
| Head功能 | 顺序预测、局部依赖 | 句内关系、句间语义对齐 |
| 可视化过滤 | 可按词过滤 | 可按词或句对过滤 |
2.3 图3 词汇模式-lexical pattern
“Lexical” 在语言学中指与具体单词(word forms)及其用法相关的语言现象。
不同于 “syntactic pattern(句法模式)” 那种抽象的结构规则(如主谓宾顺序),
lexical pattern 关注:
- 词与词之间的具体搭配;
- 某类词(如介词、缩略词、专有名词)的行为规律;
- 词形或词汇层面的相似性。
Transformer 的注意力机制不只是机械地关注相邻词,而是能自动学习到:
- 某些词是列表的一部分;
- 某些词有语义配对;
- 某些符号(如括号、引号)标记结构边界。
Figure 3 通过选取第 3、8、10 层的注意力头,展示了 GPT-2 如何在不同网络深度逐步从局部词汇依附 → 结构化列表关系 → 语义映射。
这些层级差异正是“lexical patterns”跨层演化的体现,也说明 Transformer 内部具备某种语言结构的自组织分化。
具体层数/Head的注意力如下:

- 空注意力
右图中,常看到许多线指向句子第一个 token。 即模型在没有强注意力目标时,会默认分配一点权重给起始 token(即“空注意力”)。
因此,指向第一个词的注意力常被视为 “null attention”,不代表真实语言依赖。
- 总结
| 图 | 层号 | 模式类型 | 说明 | 所处语言层次 |
|---|---|---|---|---|
| 左图 | Layer 8 | List items pattern(列表项模式) | 模型在中层学会识别文本中带有序列结构的规律(如分号或编号项),表明这一层的 head 能抓到“局部语法+格式”特征。 | 中层结构级特征 |
| 中图 | Layer 3 | Prepositions(介词模式) | 第 3 层相对较浅,注意力集中于局部词组(介词→宾语),属于典型的词类依附关系。 | 低层词汇句法特征 |
| 右图 | Layer 10 | Acronyms(缩略词模式) | 第 10 层较高,模型注意力跨越较大范围,将“NASA”与“National Aeronautics and Space Administration”等词关联,代表了语义层或命名层级的映射。 | 高层语义特征 |
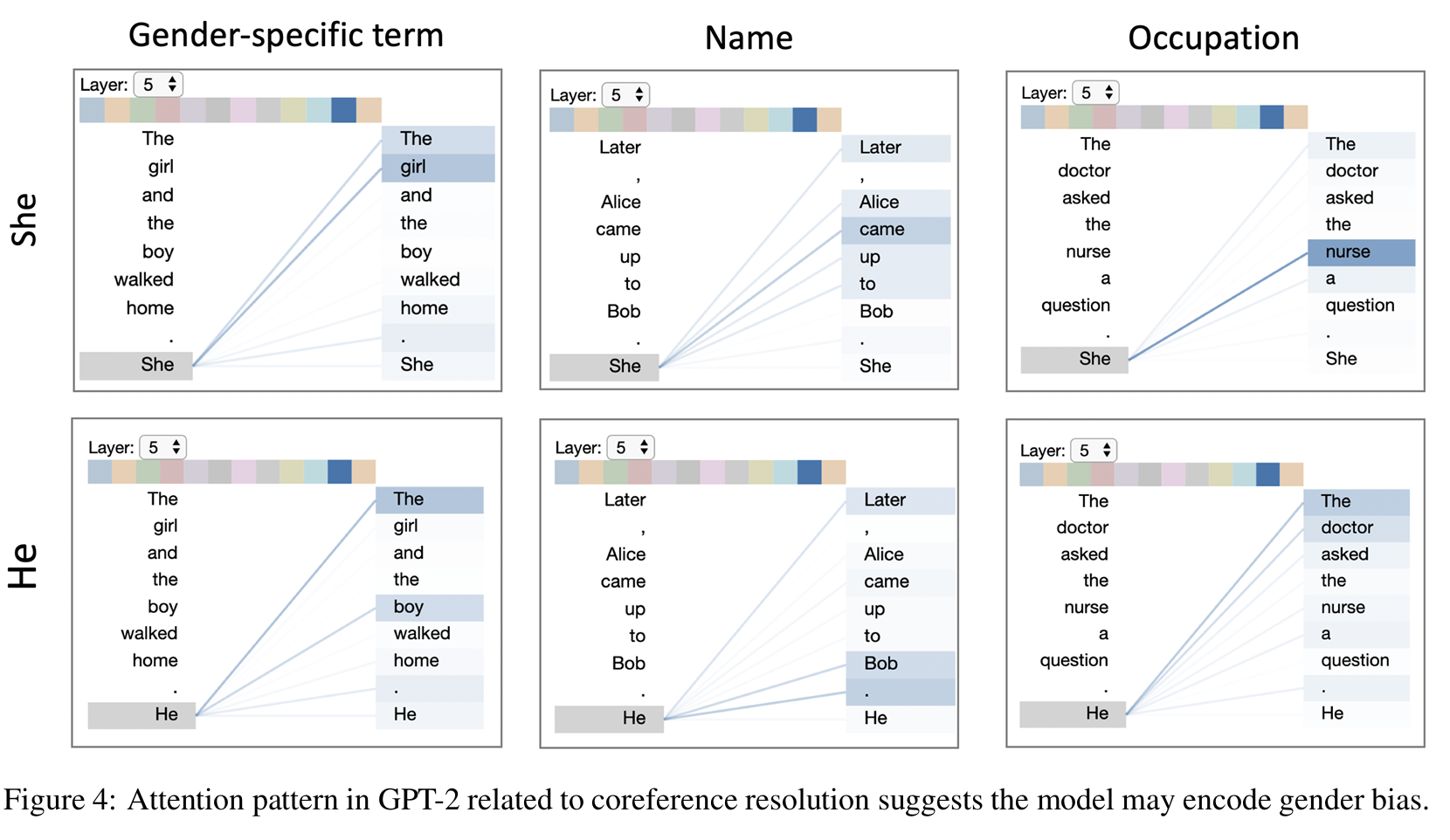
2.4 图4 指代消解 (coreference resolution)
在第五层, 指代消解 对 she和he在性别,名字,职业的注意力
2.5 图5 概览层与头的分布
输入 The quick, brown fox jumps over the lazy
这里包括0-5层的layers和heads(还有6-11的layers与heads)
- 行(rows) → 不同的 Transformer 层(layer)
- 列(columns) → 每层中的不同 注意力头(head)
- 每个格子(thumbnail) → 一个小型的注意力模式图,显示该 head 的总体“形状”或“倾向”
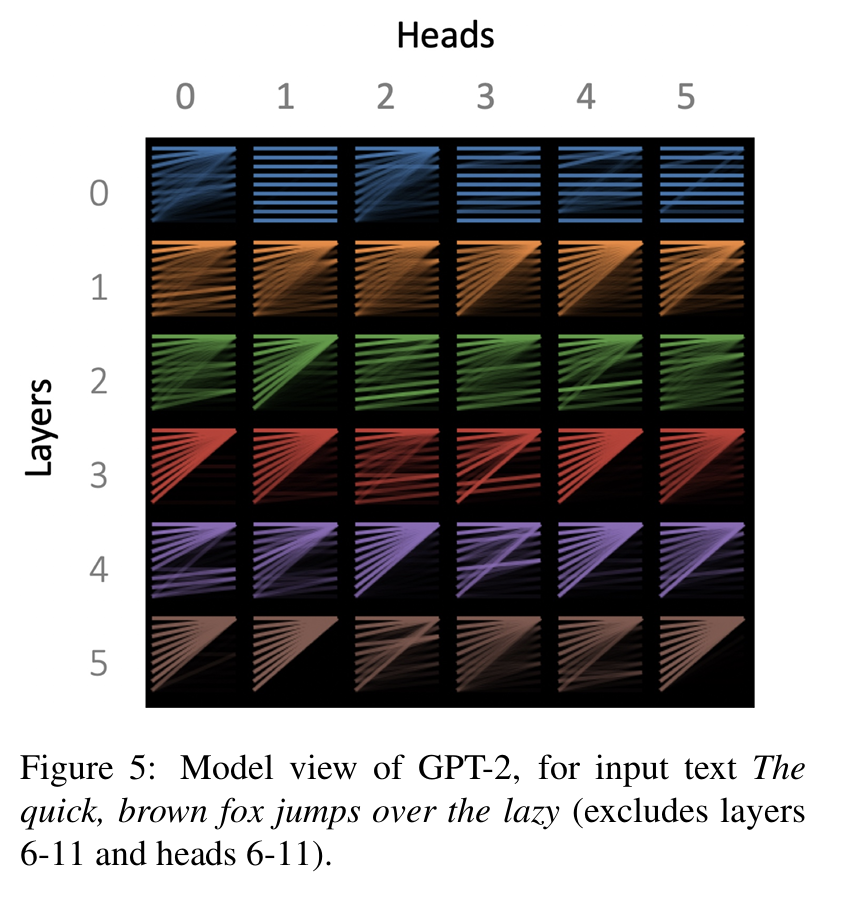
- 初始层(Layer 0–2)
主要是 位置驱动(position-based)模式- Layer 0, Head 1:注意力集中在同一个 token(自我注意 self token)
- Layer 2, Head 2:每个词主要关注前一个词(previous token)
这说明潜层的注意力更偏向 句法结构与序列依赖(syntax/position patterns),
例如语言的顺序规则(如“形容词→名词”、“主语→谓语”)。
-
中层(Layer 3-5)
模式更多样化、语义化(虽然部分层在图中未展示),attention heads 开始关注:- 主谓搭配(subject–verb)
- 语义相似词
- 段落主语、上下文主干等更高级语义关系
这些往往对应模型理解上下文与语义一致性的能力。
-
现象提示:
- 某些注意力头可能是在特定语境下才激活(例如需要特定语义结构时)。
- 当输入文本没有触发该语义模式时,head 就“闲置”,其注意力退化成“全指向第一个 token”。
因此作者提出,或许模型可以显式设计一个 “null token” 或 “padding attention sink”,专门接收这种“空注意力(null attention)”。
这样做的潜在好处:
- 提高模型可解释性(区分真实语义关注 vs 空关注)
- 结构更清晰(减少混淆第一个词与空注意力)
不过这是个可解释性优化的启示,不一定带来性能收益。
2.6 图6 神经元(Neuron View )
这是Transformer 中“Query–Key–Dot Product–Softmax”的全过程。
GPT-2 的多头注意力机制参数如下:
| 参数 | 含义 | 维度(GPT-2 small) | 备注 |
|---|---|---|---|
| ( d_{\text{model}} ) | Transformer 层的隐藏维度 | 768 | 每个 token 的向量表示长度 |
| ( h ) | 注意力头数量 | 12 | 多头并行计算 |
| ( d_k = d_v ) | 每个 head 的维度 | 64 | ( 768 / 12 = 64 ) |
在每一层的 self-attention 中:
- Query, Key, Value 都是 [sequence_len,64](针对单个 head)
- 多个 head 拼接后回到 [sequence_len,768]
Neuron View 展示第8层第6Head 的 q/k/v(每个 64 维),在一个 attention head 内部的细节。
选中一个 token (这里是最后一个标点)的 Query (64) → 与每个 token 的 Key (64) 逐元素相乘 → 求点积 → Softmax 得到注意力分布:

蓝=正值,橙=负值;代表该 token 的“关注特征”方向 |
- 数据视角
| 阶段 | 张量维度 | 说明 |
|---|---|---|
| 输入嵌入 ( X ) | [8, 768] | 每个词是一个 768 维向量 |
| 线性映射到 Q, K, V | [8, 12, 64] | 每个 head 拿到自己的一份 64 维表示 |
| 选中一个 head | [8, 64] | 只看单个 head |
| Query = 当前 token | [64] | 选中的 token |
| Key = 所有 token | [8, 64] | 所有 token 的 keys |
| q · kᵗ → scores | [8] | 每个 token 的注意力打分 |
| Softmax(scores) | [8] | 归一化权重 |
| 加权求和 ( \sum \alpha_i v_i ) | [64] | 输出该 head 的结果向量 |
- 计算视角
| 视图列 | 数学表达式 | 维度 | 含义 |
|---|---|---|---|
| ① Query q | ( q_i = x_i W_Q ) | [64] | 当前选中 token(例如 “,”)的 query 向量 |
| ② Key k | ( k_j = x_j W_K ) | [64] per token | 序列中每个 token 的 key 向量 |
| ③ q ⊙ k | element-wise product | [64] | q 与 k 的逐元素乘积(每个 neuron 的匹配贡献) |
| ④ q·k | ( \sum_{m=1}^{64} q_m k_m ) | scalar per token | q ⊙ k 的求和,得到未缩放打分 |
| ⑤ Softmax | ( \text{softmax}\big(\frac{q·k}{\sqrt{64}}\big) ) | [sequence_len] | 归一化注意力权重(最终各 token 被关注程度-总注意力打分) |
| ⑥ (隐含的) Value v | ( v_j = x_j W_V ) | [64] per token | 注意力加权后用于生成输出的值向量(在图中未展示) |
2.7 图7 距离与注意力
图7中蓝色箭头指出一些神经元的注意力值(以last token 为例):
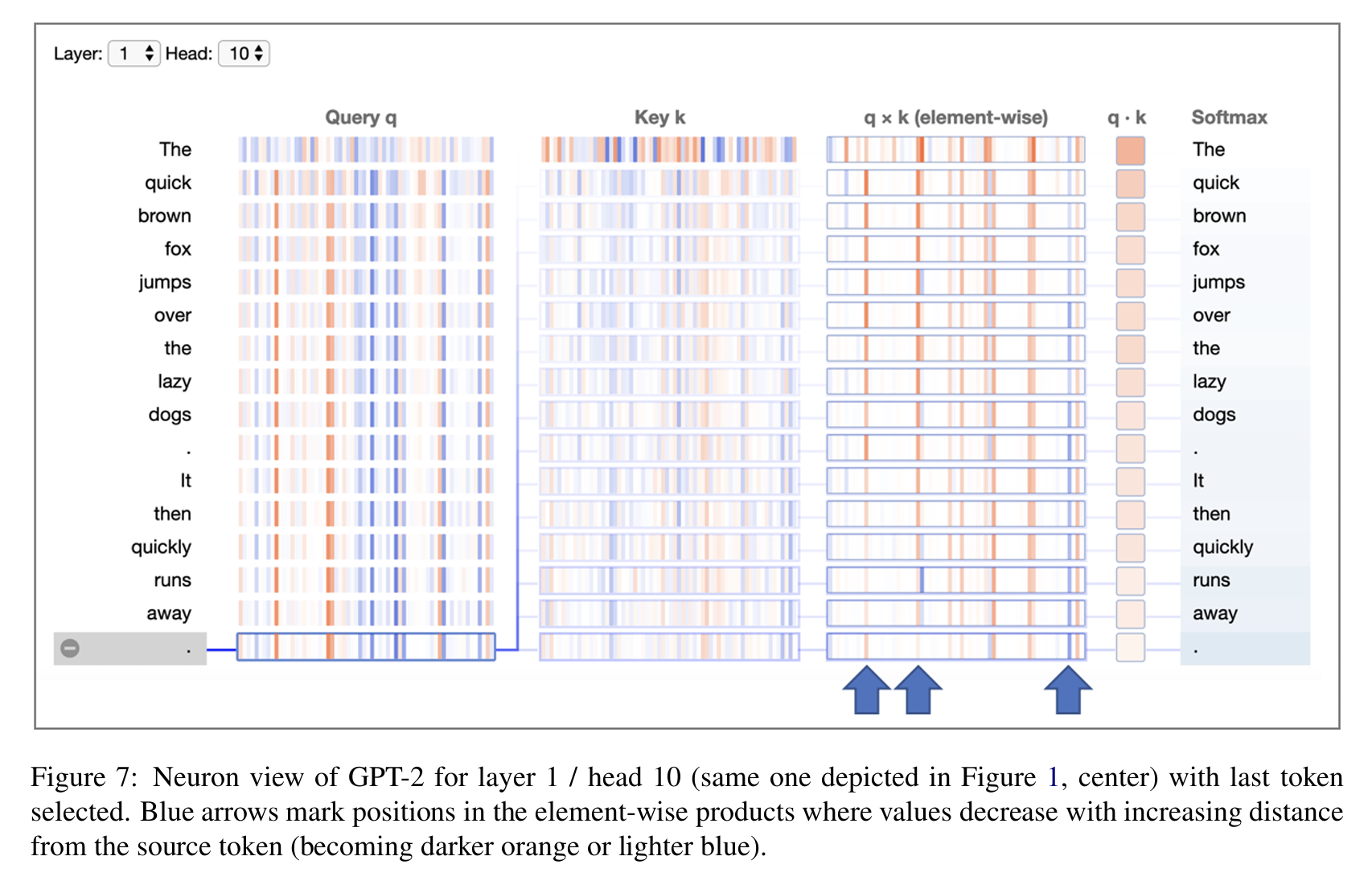
规律如下:
-
离last token 越远,q⊙k 的值越低;在可视化中表现为:颜色逐渐变深橙或浅蓝;说明这个头编码了“距离衰减”的机制。
-
所有的 query 向量几乎一样(除了第一个 token)。说明这个头的注意力对 输入文本内容(词义)几乎不敏感。
-
这个头的计算分布值,体现出其不关心单词意义,它对各个token的注意力值仅关注其相对位置。
Ref
- 《attention is all your need》 https://arxiv.org/pdf/1706.03762