JavaSE基础——第十二章 集合
本专题主要为观看韩顺平老师《零基础30天学会Java》课程笔记,同时也会阅读其他书籍、学习其他视频课程进行学习笔记总结。如有雷同,不是巧合!
数组的不足:
- 长度开始时必须指定,并且不能修改
- 保存的必须是同一类型元素
- 删除/增加元素比较麻烦
集合的框架体系图:
-
单列集合:
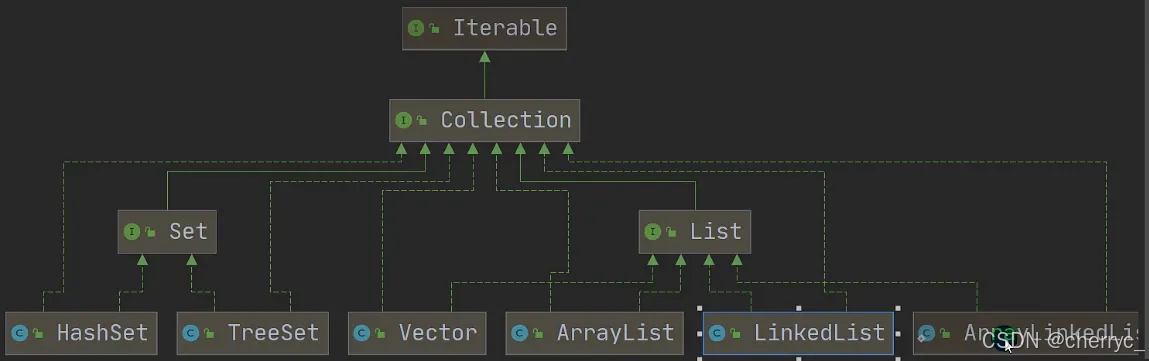
-
双列集合:
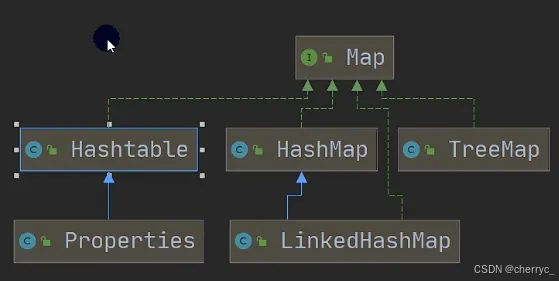
0、集合的选型

一、Collection接口
Collection 接口是 Java 集合框架的根接口,位于 java.util 包中,它定义了所有集合类共有的基本操作和方法。
public interface Collection<E> extends Iterable<E>
(1)概述
Collection 接口代表一组对象,这些对象称为集合的元素。它是最基本的集合接口,其他接口如 List、Set 和 Queue 都继承自 Collection 接口。
主要特点:
- 其实现子类可以存放多个元素,每个元素可以是Object
- 可以包含重复元素(取决于具体实现)
- 可以包含 null 元素(取决于具体实现)
- 元素顺序可能有序(
List)或无序(Set)(取决于具体实现) - 没有直接的实现子类,通过它的子接口实现
(2)常用方法
1. 基本操作方法
// 添加元素
boolean add(E e); // 向集合中添加一个元素
boolean addAll(Collection<? extends E> c); // 添加另一个集合的所有元素// 删除元素
boolean remove(Object o); // 删除指定元素
Object remove(int index); // 删除指定索引的元素
boolean removeAll(Collection<?> c); // 删除与指定集合相同的所有元素
boolean retainAll(Collection<?> c); // 仅保留与指定集合相同的元素
void clear(); // 清空集合
2. 查询方法
// 集合大小和状态
int size(); // 返回集合中元素的数量
boolean isEmpty(); // 判断集合是否为空// 元素检查
boolean contains(Object o); // 判断集合是否包含指定元素
boolean containsAll(Collection<?> c); // 判断集合是否包含指定集合的所有元素
3. 转换方法
// 转换为数组
Object[] toArray(); // 将集合转换为Object数组
<T> T[] toArray(T[] a); // 将集合转换为指定类型的数组// 获取迭代器
Iterator<E> iterator(); // 返回集合的迭代器
4. Java 8 新增的默认方法
// 流操作
default Stream<E> stream(); // 返回顺序流
default Stream<E> parallelStream(); // 返回并行流// 条件删除
default boolean removeIf(Predicate<? super E> filter); // 删除满足条件的元素// 分割迭代器
default Spliterator<E> spliterator(); // 返回分割迭代器
(3)遍历集合元素
1. 使用 Iterator 迭代器
这是最基础的遍历方式,所有 Collection 实现类都支持。
Collection<String> collection = new ArrayList<>();
collection.add("Java");
collection.add("Python");
collection.add("C++");**Iterator<String> iterator = collection.iterator();**
while (iterator.hasNext()) {String element = iterator.next();System.out.println(element);// 可以在遍历时安全删除元素if (element.equals("Python")) {iterator.remove(); // 安全删除当前元素}
}
特点:
-
可以在遍历过程中安全删除元素
-
适用于所有 Collection 实现
-
是 fail-fast 的(如果在迭代过程中集合被修改,会抛出 ConcurrentModificationException)
2. 增强 for 循环 (for-each)
这是最简洁的遍历方式,底层实际使用的是 Iterator。也可以直接在数组上使用。【快捷键:I】
for (Object element : collection) {System.out.println(element);// 注意:不能在 for-each 循环中直接删除元素,会抛出 ConcurrentModificationException// collection.remove(element); // 错误!
}
特点:
- 语法简洁
- 适用于所有实现了 Iterable 接口的集合
- 不能在遍历过程中修改集合(添加/删除元素)
3. 使用 forEach() 方法 (Java 8+)
Java 8 引入了函数式编程风格的遍历方式。
// 使用 Lambda 表达式
collection.forEach(element -> System.out.println(element));// 使用方法引用
**collection.forEach(System.out::println);**
特点:
- 代码简洁
- 支持并行处理
- 不能使用 break/continue 控制流程
- 不能在遍历过程中修改集合
4. 使用 Stream API (Java 8+)
更强大的函数式操作方式。
collection.stream().filter(e -> !e.equals("Python")) // 过滤.map(String::toUpperCase) // 转换.forEach(System.out::println); // 遍历
特点:
- 支持链式操作
- 可以进行过滤、映射等复杂操作
- 支持并行处理(parallelStream())
- 更函数式的编程风格
5. 使用 ListIterator (仅 List 接口)
List 接口特有的双向遍历迭代器。
List<String> list = new ArrayList<>(collection);
ListIterator<String> listIterator = list.listIterator();// 正向遍历
while (listIterator.hasNext()) {System.out.println(listIterator.next());
}// 反向遍历
while (listIterator.**hasPrevious()**) {System.out.println(listIterator.previous());
}
特点:
- 可以双向遍历
- 可以获取元素索引
- 可以在遍历时修改元素(set() 方法)
- 仅适用于 List 实现类
遍历方法选择建议
- 简单遍历:使用 for-each 循环(最简洁)
- 需要修改集合:使用 Iterator
- 函数式操作:使用 forEach() 或 Stream API
- 需要索引或双向遍历:使用 ListIterator(仅 List)
- 大数据量并行处理:使用 parallelStream()
性能比较
一般来说,对于 ArrayList:
- 普通 for 循环(使用索引)最快
- Iterator 和 for-each 性能接近
- forEach() 和 Stream API 稍慢但更灵活
对于 LinkedList:
- Iterator 和 for-each 性能最好
- 避免使用基于索引的普通 for 循环(性能差)
(3)主要子接口
- List 接口 - 有序集合,允许重复元素
- 实现类:ArrayList, LinkedList, Vector
- Set 接口 - 不允许重复元素的集合
- 实现类:HashSet, LinkedHashSet, TreeSet
- Queue 接口 - 队列,通常按FIFO(先进先出)排序
- 实现类:LinkedList, PriorityQueue
(4)使用示例
import java.util.*;public class CollectionExample {public static void main(String[] args) {// 创建集合Collection<String> collection = new ArrayList<>();// 添加元素collection.add("Java");collection.add("Python");collection.add("C++");// 检查集合大小System.out.println("集合大小: " + collection.size()); // 输出: 3// 检查元素是否存在System.out.println("包含Java? " + collection.contains("Java")); // true// 遍历集合for (String language : collection) {System.out.println(language);}// 使用迭代器Iterator<String> iterator = collection.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}// 转换为数组String[] array = collection.toArray(new String[0]);// 删除元素collection.remove("Python");System.out.println("删除后大小: " + collection.size()); // 输出: 2// 清空集合collection.clear();System.out.println("清空后是否为空: " + collection.isEmpty()); // true}
}
二、List接口
List 代表一个有序的集合(也称为序列)。List 允许存储重复元素,并且可以精确控制每个元素的插入位置,通过整数索引(类似于数组的下标)来访问元素。
(1)特点
- 有序性:元素按照插入顺序存储,并保持该顺序
- 可重复:允许存储相同的元素(包括 null)
- 索引访问:可以通过索引(从 0 开始)精确访问元素
- 可变大小:与数组不同,List 的大小可以动态变化
(2)常用实现类
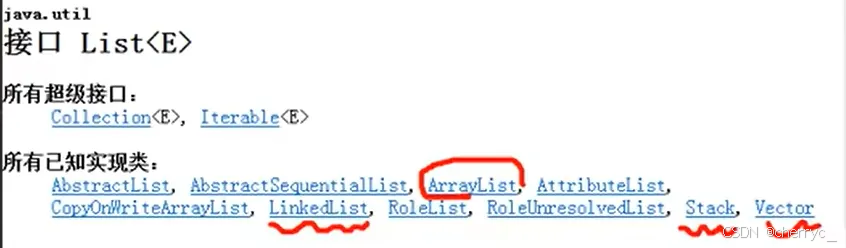
| 实现类 | 特点 |
|---|---|
| ArrayList | 基于动态数组实现,随机访问快,插入删除慢(除非在末尾操作) |
| LinkedList | 基于双向链表实现,插入删除快,随机访问慢 |
| Vector | 线程安全的动态数组实现,性能较差(已被 ArrayList 和 Collections.synchronizedList 取代) |
| Stack | 继承自 Vector,实现后进先出(LIFO)的栈结构 |
| CopyOnWriteArrayList | 线程安全的 List,适用于读多写少的场景(Java 5+) |
(3)核心方法
1. 位置访问操作
E get(int index); // 返回指定位置的元素
E set(int index, E element); // 替换指定位置的元素,返回原元素
2. 搜索操作
int indexOf(Object o); // 返回元素第一次出现的索引
int lastIndexOf(Object o); // 返回元素最后一次出现的索引
3. 列表迭代器
ListIterator<E> listIterator(); // 返回列表迭代器
ListIterator<E> listIterator(int index); // 从指定位置开始的列表迭代器
4. 范围视图操作
List<E> subList(int fromIndex, int toIndex); // 返回子列表视图[)
5. Java 8 新增的默认方法
default void replaceAll(UnaryOperator<E> operator); // 对所有元素应用操作
default void sort(Comparator<? super E> c); // 根据比较器排序
default Spliterator<E> spliterator(); // 创建分割迭代器
代码示例
import java.util.*;public class ListExample {public static void main(String[] args) {List<String> fruits = new ArrayList<>();// 添加元素fruits.add("Apple"); // 添加到末尾fruits.add(0, "Banana"); // 添加到指定位置fruits.addAll(Arrays.asList("Orange", "Grape"));// 访问元素System.out.println(fruits.get(1)); // 输出: Apple// 修改元素fruits.set(2, "Mango"); // 将Orange替换为Mango// 搜索元素System.out.println(fruits.indexOf("Grape")); // 输出: 3// 子列表操作List<String> subList = fruits.subList(1, 3);System.out.println(subList); // 输出: [Apple, Mango]// 排序fruits.sort(String::compareToIgnoreCase);System.out.println(fruits); // 按字母顺序排序// 遍历方式// 1. 普通for循环for (int i = 0; i < fruits.size(); i++) {System.out.println(fruits.get(i));}// 2. 增强for循环for (String fruit : fruits) {System.out.println(fruit);}// 3. 使用迭代器Iterator<String> iterator = fruits.iterator();while (iterator.hasNext()) {System.out.println(iterator.next());}// 4. 使用ListIterator(双向遍历)ListIterator<String> listIterator = fruits.listIterator(fruits.size());while (listIterator.hasPrevious()) {System.out.println(listIterator.previous());}// 5. Java 8 forEachfruits.forEach(System.out::println);}
}
(2)实现类的选择
- ArrayList:
- 默认选择,适用于大多数场景
- 随机访问频繁(get/set 操作多)
- 插入删除主要在列表末尾进行
- LinkedList:
- 频繁在列表中间插入/删除元素
- 需要实现队列或双端队列功能
- 内存使用比 ArrayList 高(每个元素需要额外存储前后节点的引用)
- CopyOnWriteArrayList:
- 多线程环境,读操作远多于写操作
- 迭代过程中不允许修改集合(会创建副本)
- Vector/Stack:
- 遗留代码兼容
- 需要线程安全且不介意性能损失
(3)性能考虑
| 操作 | ArrayList | LinkedList |
|---|---|---|
| get(int) | O(1) | O(n) |
| add(E) | O(1) 分摊 | O(1) |
| add(int, E) | O(n) | O(1) |
| remove(int) | O(n) | O(1) |
| Iterator.remove() | O(n) | O(1) |
(4)线程安全
标准 List 实现(ArrayList、LinkedList)不是线程安全的。如果需要在多线程环境中使用 List,可以考虑:
-
使用
Collections.synchronizedList()包装:List<String> syncList = Collections.synchronizedList(new ArrayList<>()); -
使用
CopyOnWriteArrayList(适合读多写少的场景)
(5)实现类的注意事项
ArrayList
| 特性 | 说明 |
|---|---|
| 有序性 | 元素按插入顺序存储 |
| 可重复 | 允许存储相同元素 |
| 允许 null | 可以存储 null 值 |
| 储存方法 | 由数组实现数据存储 |
| 动态扩容 | 当容量不足时自动扩容(1.5 倍) |
| 快速随机访问 | get(index) 和 set(index, e) 时间复杂度 O(1) |
| 插入/删除较慢 | add(index, e) 和 remove(index) 时间复杂度 O(n)(需要移动元素) |
| 非线程安全 | [基本等同于Vector,除了这一点]多线程环境下需要同步控制 |
| 构造方法 | 说明 |
|---|---|
ArrayList() | 默认构造,初始容量 10 |
ArrayList(int initialCapacity) | 指定初始容量 |
ArrayList(Collection<? extends E> c) | 从另一个集合初始化 |
- 底层数据结构:
- 基于 动态数组(
Object[] elementData) - 初始容量 10(默认),可动态扩容
- 基于 动态数组(
ArrayList<String> list1 = new ArrayList<>(); // 默认容量 10
ArrayList<Integer> list2 = new ArrayList<>(100); // 初始容量 100
ArrayList<String> list3 = new ArrayList<>(Arrays.asList("A", "B", "C")); // 从集合初始化

// transient 是 Java 中的一个关键字,用于修饰类的成员变量,表示该变量不应被序列化(即不会被包含在对象的序列化数据中)【当对象被序列化(例如使用 ObjectOutputStream)时,默认情况下所有非静态、非瞬态(非 transient)的字段都会被序列化】
-
🤯源码分析:
-
无参构造器-创建空数组:


-
add()添加元素-先确定是否扩容,再在末尾添加元素: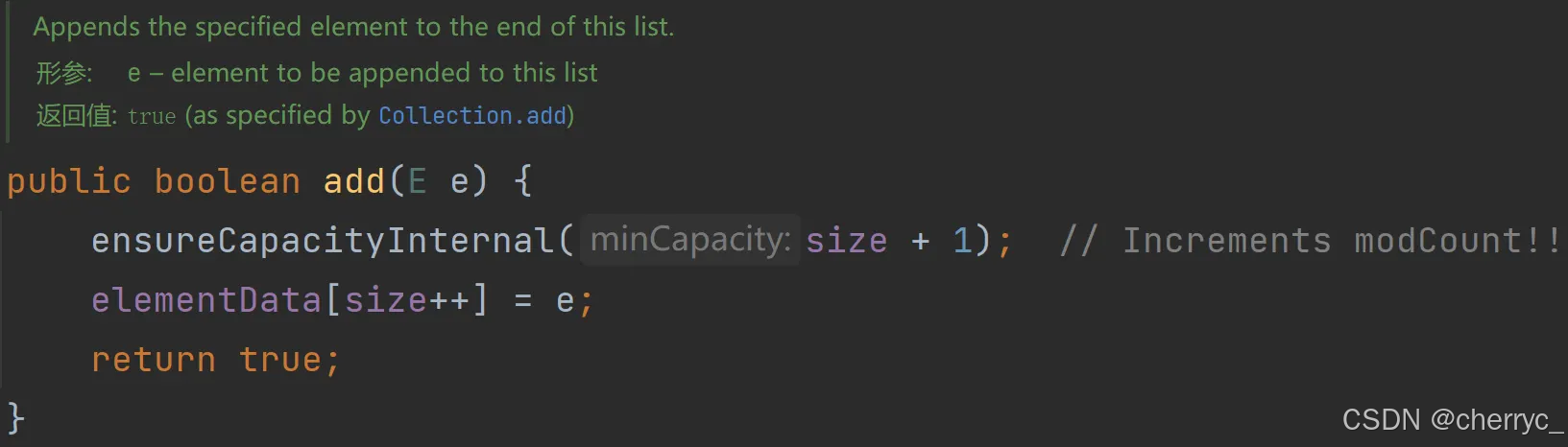
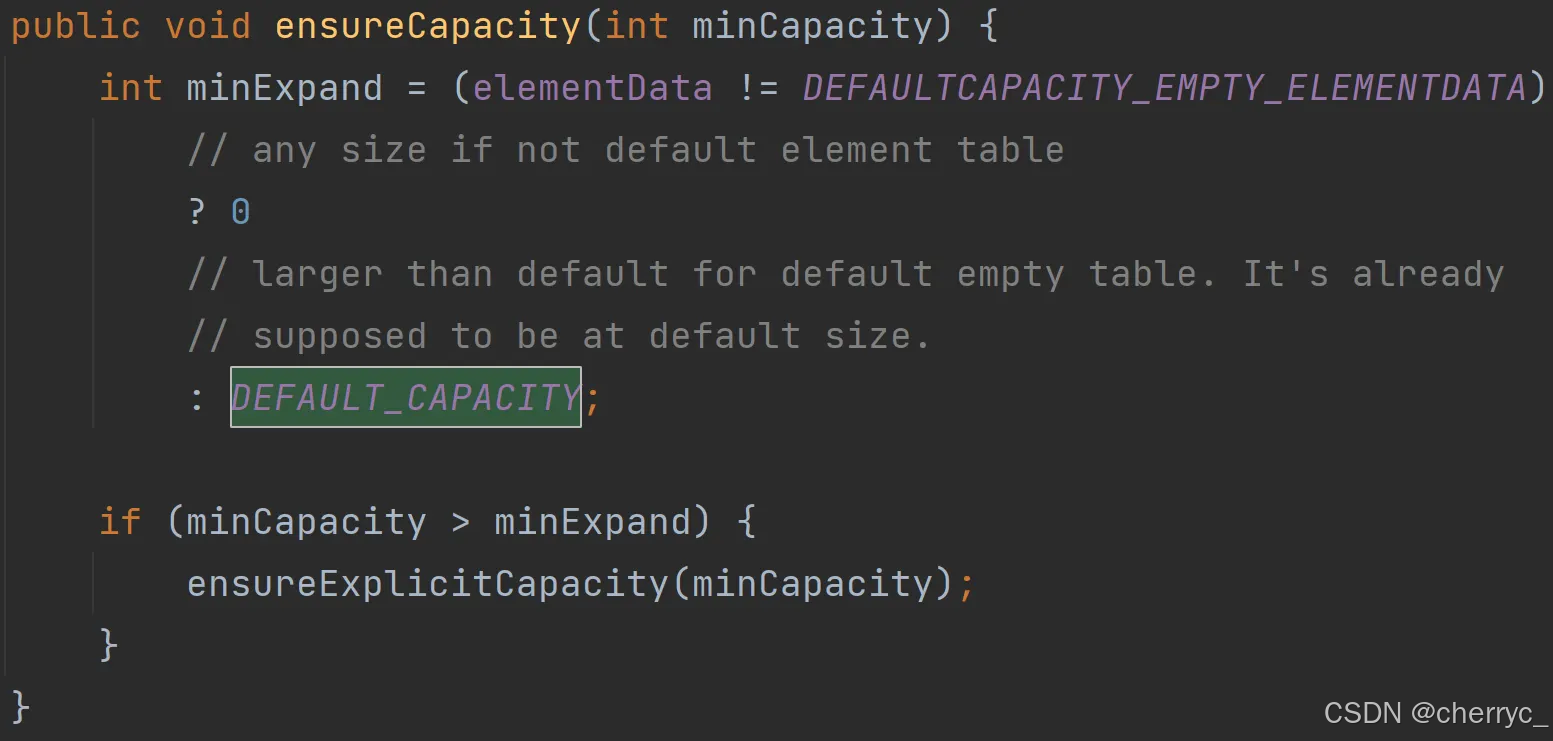

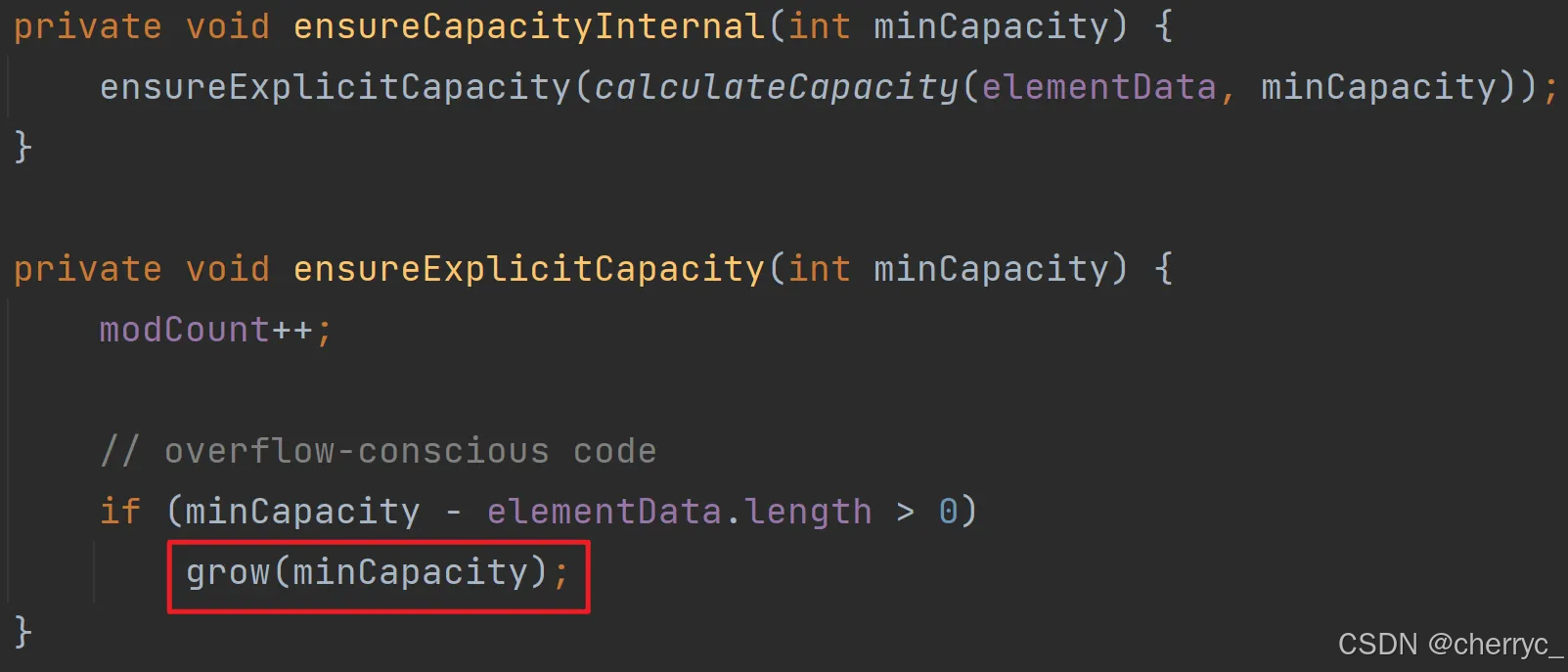
modCount++记录集合被修改的次数;如果elementData大小不够用,就调用grow()扩容;size表示列表中实际存储的元素数量,调用add()、remove()等方法时会自动更新;elementData.length表示数组的物理容量,除非扩容,否则长度不变


容量扩大至1.5倍



确保之前的数据都被复制到新数组
-
有参构造器-初始容量为capacity:

-
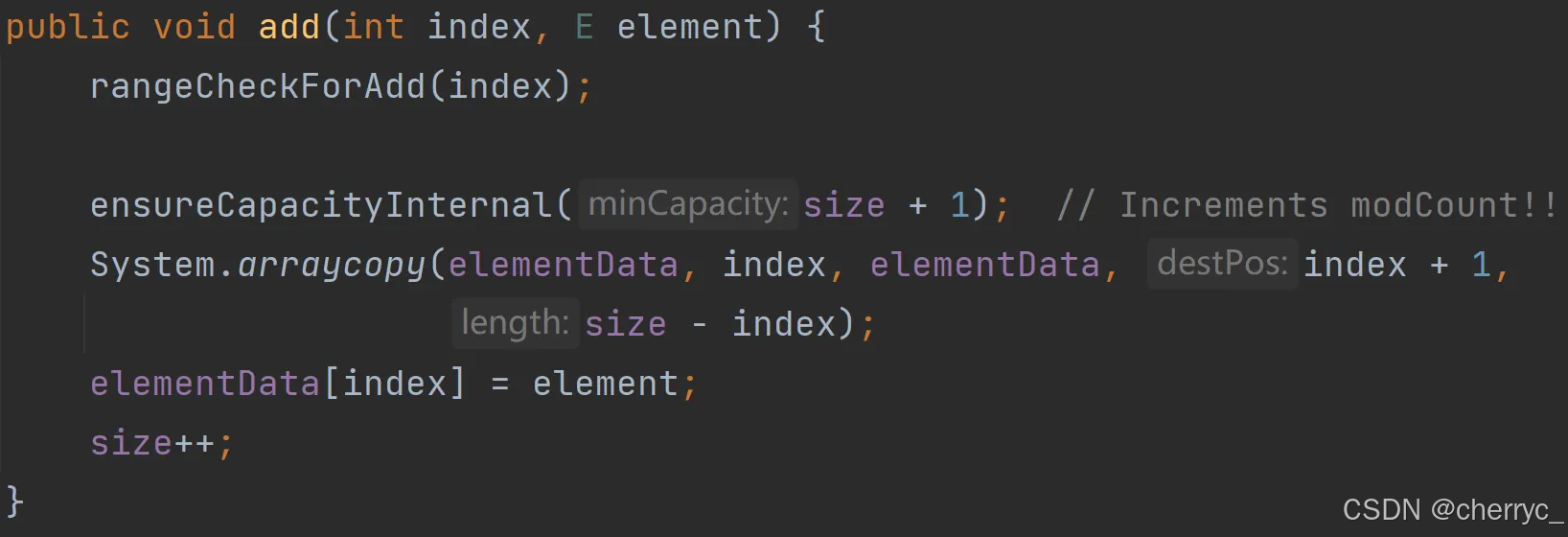
在指定下标添加元素:
-
Vector
与 ArrayList 类似,但所有方法都使用 synchronized 关键字修饰,保证线程安全。
- 底层数据结构:
- 基于 动态数组(Object[] elementData)
- 初始容量 10(默认),可动态扩容
| 特性 | 说明 |
|---|---|
| 线程安全 | 所有方法都使用 synchronized 修饰 |
| 有序性 | 元素按插入顺序存储 |
| 可重复 | 允许存储相同元素 |
| 允许 null | 可以存储 null 值 |
| 动态扩容 | 当容量不足时自动扩容(默认 2 倍) |
| 快速随机访问 | get(index) 和 set(index, e) 时间复杂度 O(1) |
| 插入/删除较慢 | add(index, e) 和 remove(index) 时间复杂度 O(n)(需要移动元素) |
| 构造方法 | 说明 |
|---|---|
Vector() | 默认构造,初始容量 10 |
Vector(int initialCapacity) | 指定初始容量 |
Vector(int initialCapacity, int capacityIncrement) | 指定初始容量和扩容增量 |
Vector(Collection<? extends E> c) | 从另一个集合初始化 |
Vector<String> vec1 = new Vector<>(); // 默认容量 10
Vector<Integer> vec2 = new Vector<>(100); // 初始容量 100
Vector<String> vec3 = new Vector<>(10, 5); // 初始容量 10,每次扩容 +5
Vector<String> vec4 = new Vector<>(Arrays.asList("A", "B", "C")); // 从集合初始化
-
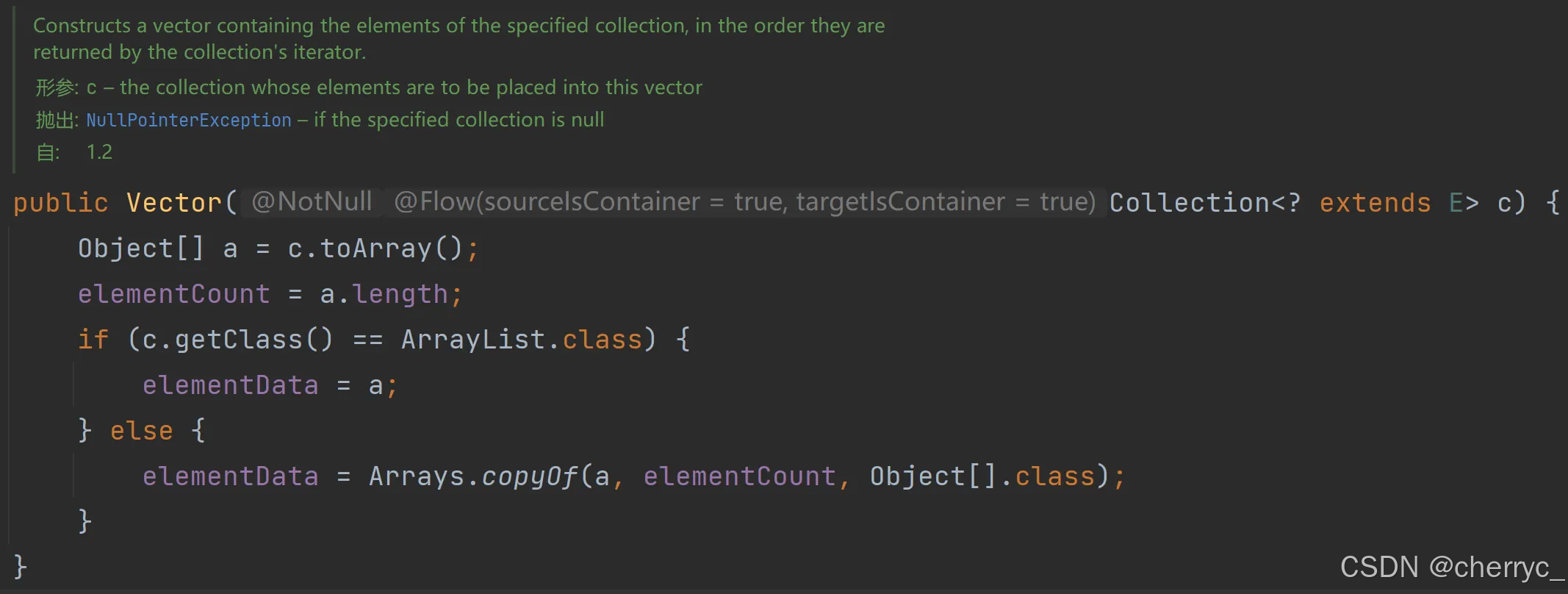
🤯源码分析:
-
构造器:


-
添加元素:



容量扩大至2倍/增加指定大小
-
由于 Vector 的同步机制导致性能较低,现代 Java 开发中更推荐:
-
ArrayList+ 手动同步(如Collections.synchronizedList):List<String> syncList = Collections.synchronizedList(new ArrayList<>()); -
CopyOnWriteArrayList(适合读多写少的并发场景):CopyOnWriteArrayList<String> cowList = new CopyOnWriteArrayList<>();
| 对比项 | Vector | ArrayList |
|---|---|---|
| 线程安全 | 是(所有方法同步) | 否(非线程安全) |
| 扩容机制 | 默认 2 倍(可自定义增量) | 默认 1.5 倍 |
| 性能 | 较慢(同步开销) | 较快(无同步) |
| 迭代器 | Iterator + Enumeration | 仅 Iterator |
| 适用场景 | 多线程环境 | 单线程环境 |
Enumeration<String> en = vec.elements();
while (en.hasMoreElements()) {System.out.println(en.nextElement());
}
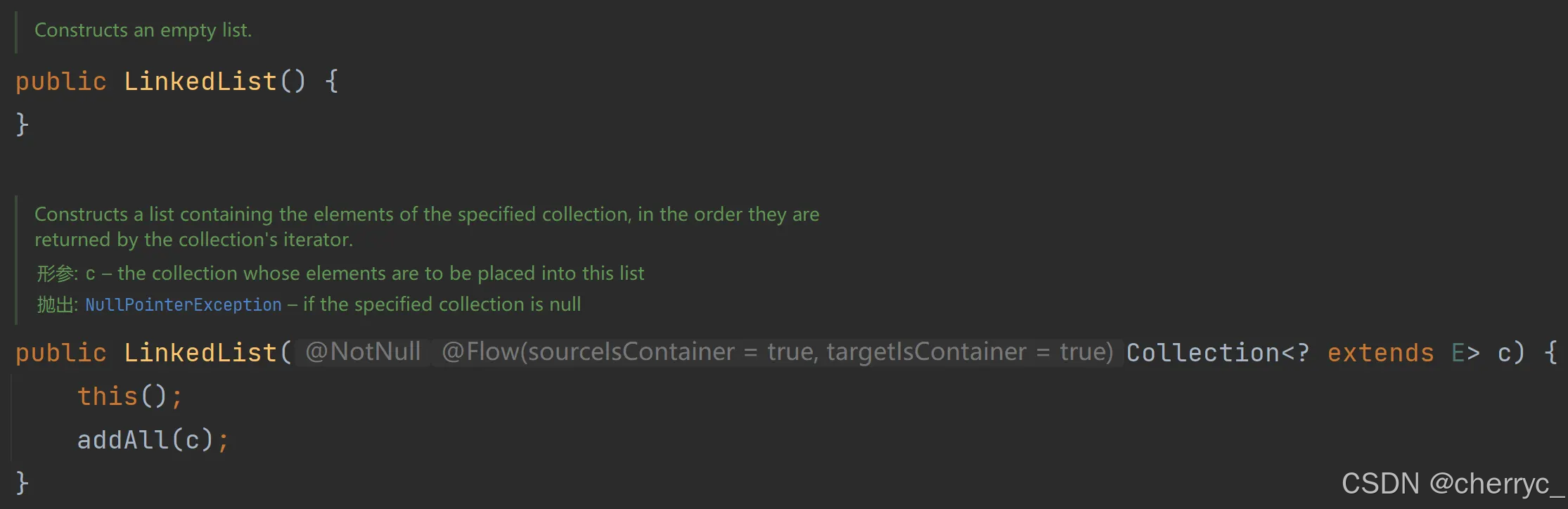
LinkedList
LinkedList 是 Java 集合框架中的一个双向链表实现,它实现了 List 和 Deque(双端队列)接口,适用于频繁插入和删除操作的场景。
- 实现接口:
List<E>(有序、可重复、允许null)Deque<E>(双端队列,支持头部和尾部操作)Cloneable(可克隆)Serializable(可序列化)
- 底层数据结构:
- 基于 双向链表(
Node<E>节点) - 每个节点存储 前驱指针(prev)、数据(item)、后继指针(next)
- 基于 双向链表(
| 特性 | 说明 |
|---|---|
| 双向链表结构 | 每个元素通过 Node 连接,支持双向遍历 |
| 插入/删除高效 | 在头部或尾部插入/删除时间复杂度 O(1) |
| 随机访问较慢 | get(index) 和 set(index, e) 时间复杂度 O(n) |
| 内存占用较高 | 每个元素需要额外存储前后指针 |
| 非线程安全 | 多线程环境下需要同步控制 |
| 构造方法 | 说明 |
|---|---|
LinkedList() | 默认构造,创建空链表 |
LinkedList(Collection<? extends E> c) | 从另一个集合初始化 |
LinkedList<String> list1 = new LinkedList<>(); // 空链表
LinkedList<String> list2 = new LinkedList<>(Arrays.asList("A", "B", "C")); // 从集合初始化
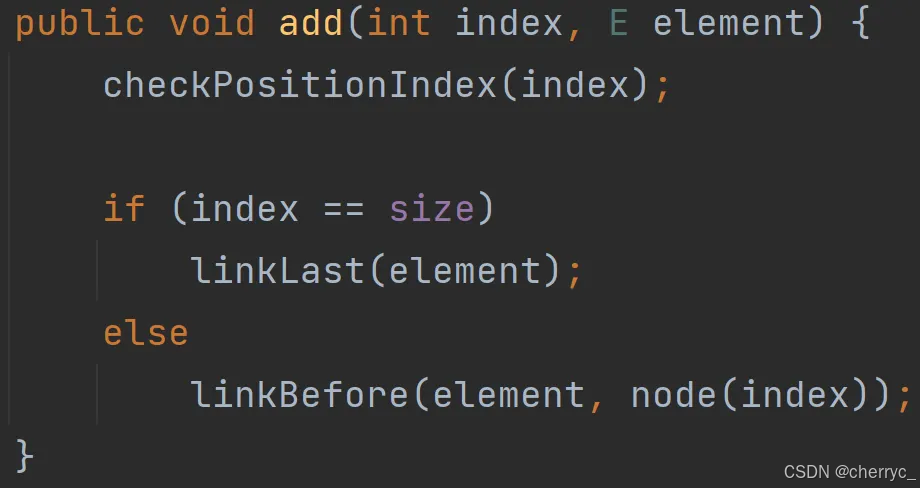
(1) 添加元素
| 方法 | 说明 |
|---|---|
boolean add(E e) | 在链表末尾添加元素 |
void add(int index, E e) | 在指定位置插入元素 |
void addFirst(E e) | 在链表头部插入元素 |
void addLast(E e) | 在链表尾部插入元素 |
boolean offer(E e) | 添加元素到尾部(队列操作) |
boolean offerFirst(E e) | 添加元素到头部 |
boolean offerLast(E e) | 添加元素到尾部 |





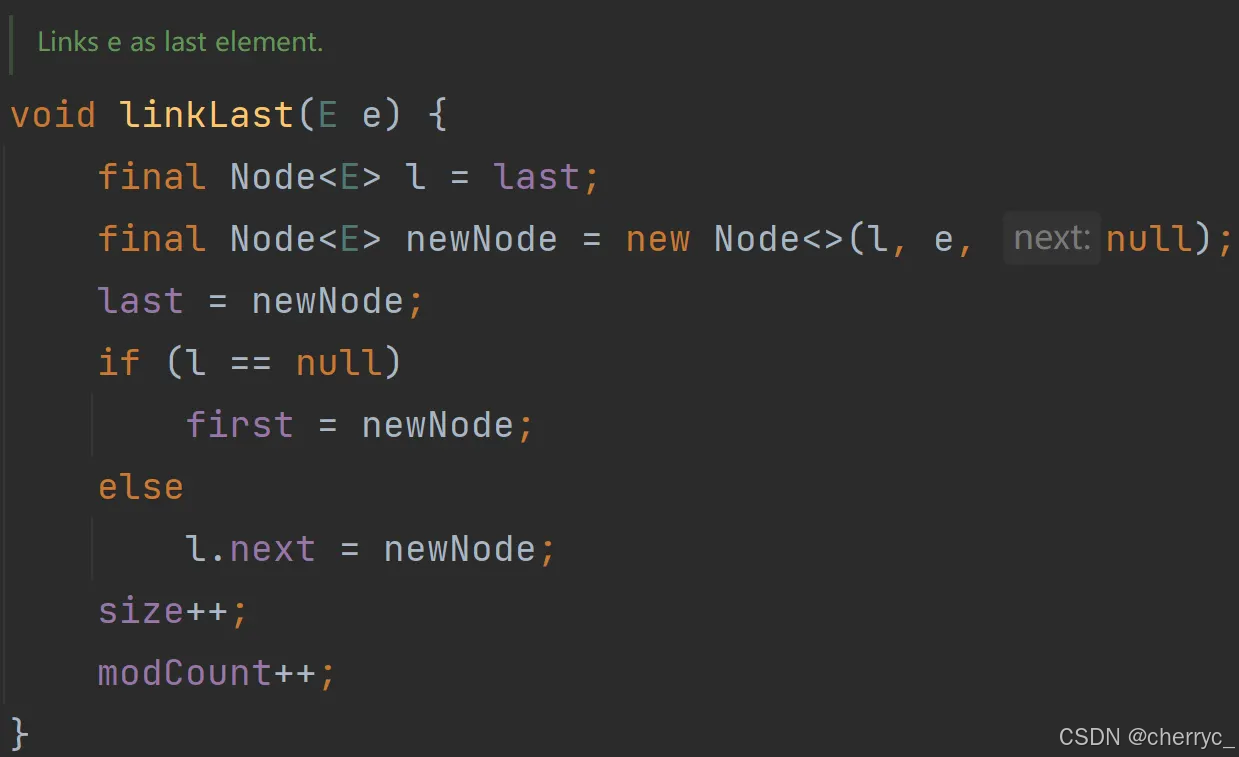



LinkedList<String> list = new LinkedList<>();
list.add("Java"); // ["Java"]
list.addFirst("Python"); // ["Python", "Java"]
list.addLast("C++"); // ["Python", "Java", "C++"]
(2) 删除元素
| 方法 | 说明 |
|---|---|
E remove() | 删除并返回头部元素 |
E remove(int index) | 删除指定位置的元素 |
boolean remove(Object o) | 删除第一个匹配的元素 |
E removeFirst() | 删除并返回头部元素 |
E removeLast() | 删除并返回尾部元素 |
boolean removeFirstOccurrence(Object o) | 删除第一次出现的元素 |
boolean removeLastOccurrence(Object o) | 删除最后一次出现的元素 |
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "A"));
list.remove(); // 删除头部 "A" → ["B", "C", "A"]
list.removeLast(); // 删除尾部 "A" → ["B", "C"]
list.removeFirstOccurrence("B"); // 删除第一个 "B" → ["C"]
-
🤯源码分析:


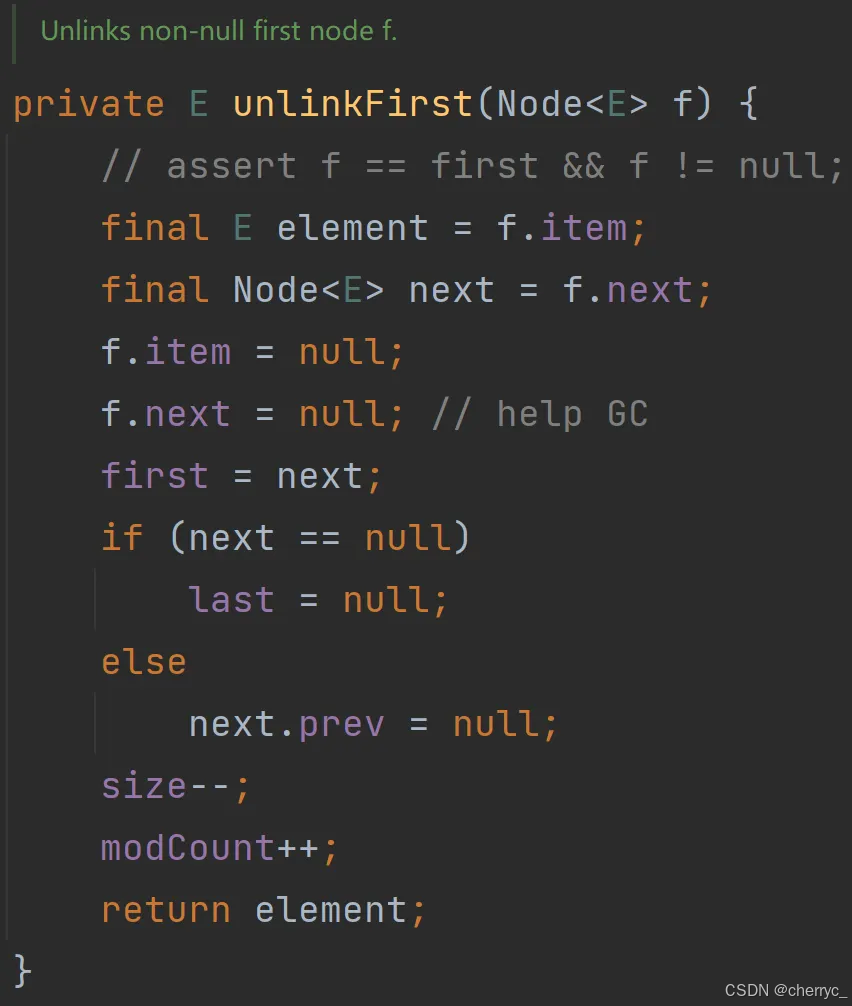
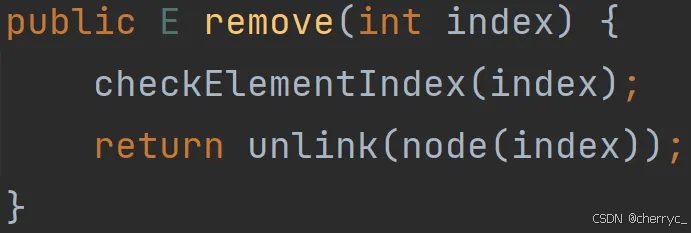

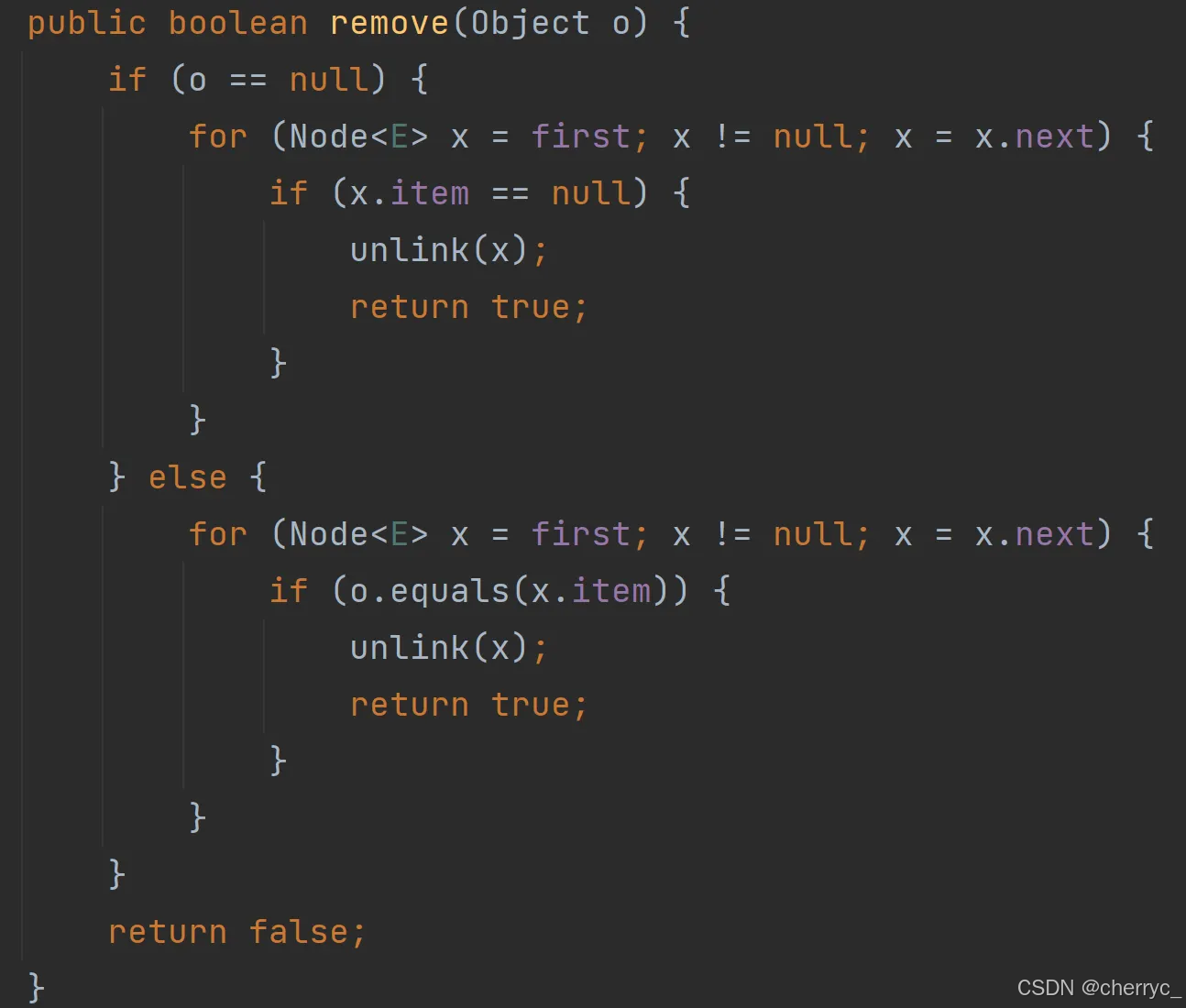
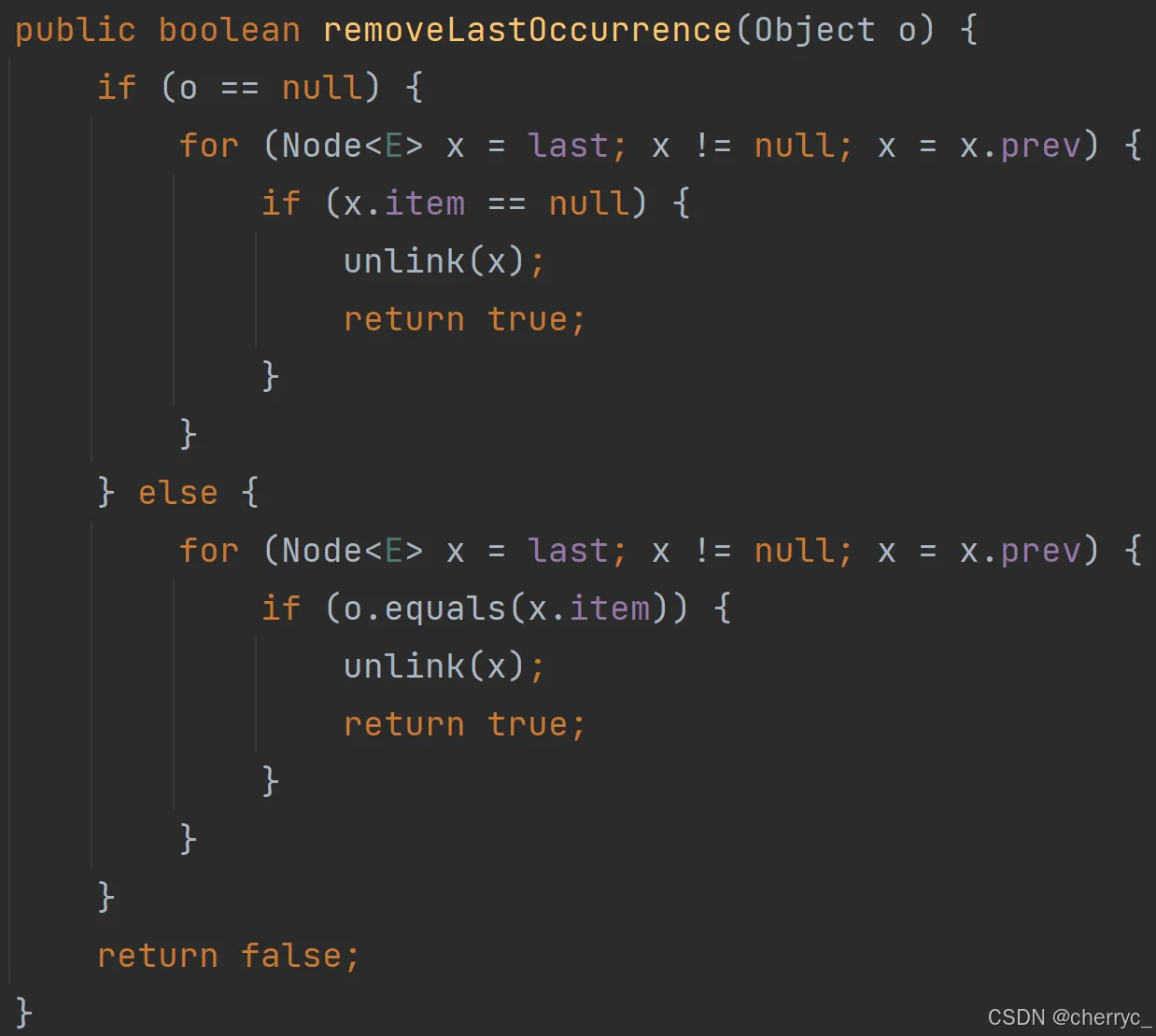
(3) 查询元素
| 方法 | 说明 |
|---|---|
E get(int index) | 获取指定位置的元素 |
E getFirst() | 返回头部元素 |
E getLast() | 返回尾部元素 |
int indexOf(Object o) | 返回元素第一次出现的索引 |
int lastIndexOf(Object o) | 返回元素最后一次出现的索引 |
boolean contains(Object o) | 判断是否包含某个元素 |
-
🤯源码分析:


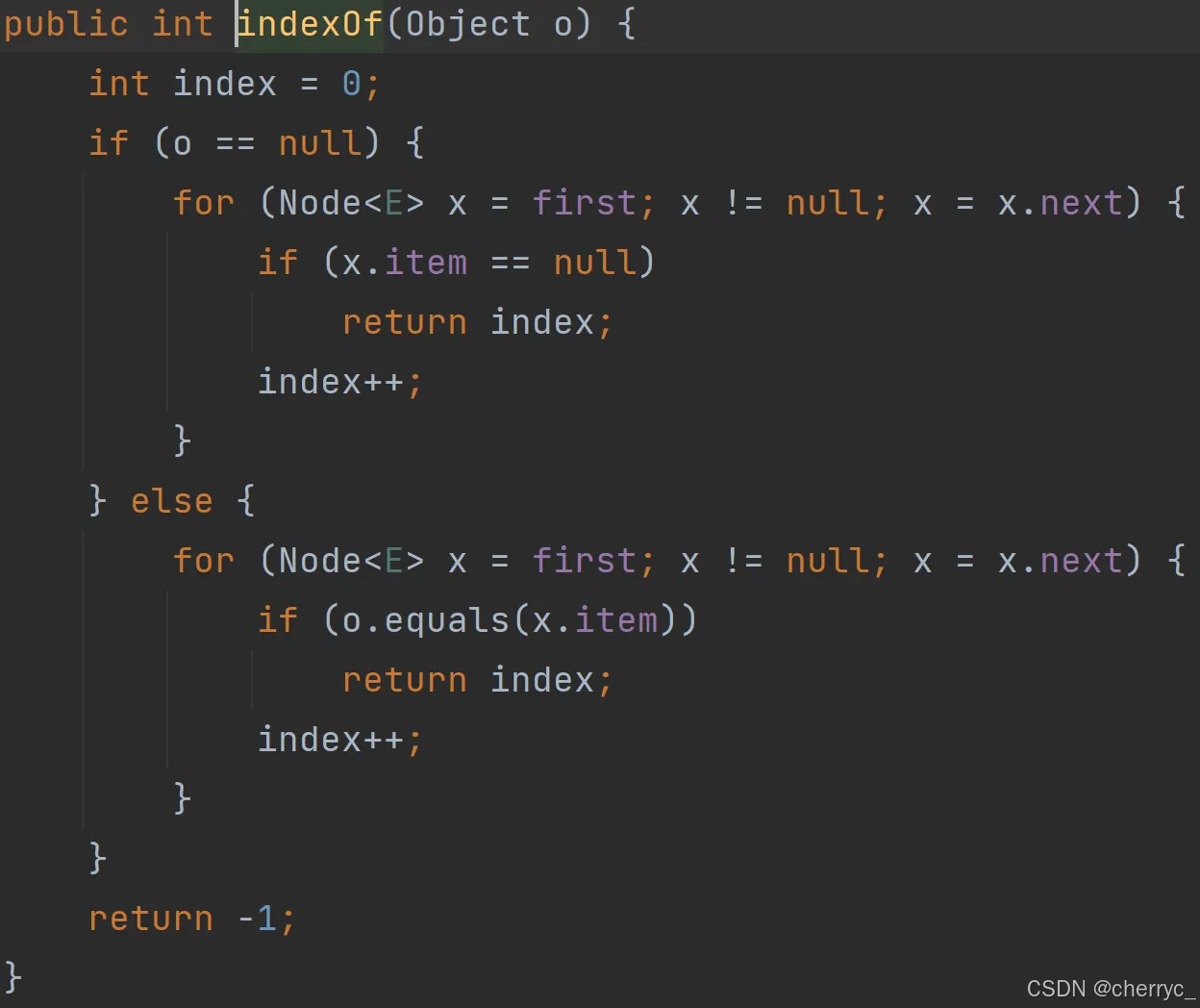
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C", "A"));
System.out.println(list.getFirst()); // "A"
System.out.println(list.get(1)); // "B"
System.out.println(list.lastIndexOf("A")); // 3
(4) 修改元素
| 方法 | 说明 |
|---|---|
E set(int index, E e) | 替换指定位置的元素,返回旧值 |
示例:
LinkedList<String> list = new LinkedList<>(Arrays.asList("A", "B", "C"));
String oldValue = list.set(1, "X"); // ["A", "X", "C"]
System.out.println(oldValue); // "B"
(5) 栈和队列操作
| 方法 | 说明 |
|---|---|
void push(E e) | 压入元素到栈顶(头部) |
E pop() | 弹出栈顶元素(头部) |
E peek() | 查看栈顶元素(不删除) |
E poll() | 取出并删除头部元素(队列操作) |
E pollFirst() | 取出并删除头部元素 |
E pollLast() | 取出并删除尾部元素 |
| 对比项 | LinkedList | ArrayList |
|---|---|---|
| 底层结构 | 双向链表 | 动态数组 |
| 随机访问 | O(n)(慢) | O(1)(快) |
| 头部插入/删除 | O(1)(快) | O(n)(慢) |
| 尾部插入/删除 | O(1)(快) | O(1)(快) |
| 中间插入/删除 | O(n)(需遍历) | O(n)(需移动元素) |
| 内存占用 | 较高(存储指针) | 较低(仅存储数据) |
| 适用场景 | 频繁插入/删除 | 频繁随机访问 |
实际开发中,ArrayList使用的场景更多。
LinkedList 不是线程安全的,多线程环境下需要同步控制:
解决方案:
-
使用
Collections.synchronizedList包装:List<String> syncList = Collections.synchronizedList(new LinkedList<>()) -
使用并发集合(如
ConcurrentLinkedDeque):ConcurrentLinkedDeque<String> concurrentList = new ConcurrentLinkedDeque<>(); -
手动加锁:
synchronized (list) {list.add("item"); }
三、Set接口
用于存储不重复的元素。Set 不保证元素的顺序(除非使用 LinkedHashSet 或 TreeSet),但是取出的顺序始终一致,并且不允许包含重复值(null 值也只能有一个)。
java.lang.Object→ java.util.Collection<E>→ java.util.Set<E>
-
主要实现类:
HashSet(基于哈希表,无序)LinkedHashSet(基于哈希表 + 链表,维护插入顺序)TreeSet(基于红黑树,自然排序或自定义排序)
实现类 底层结构 是否有序 允许 null 时间复杂度(增删查) HashSet哈希表 无序 允许 O(1)(平均) LinkedHashSet哈希表 + 双向链表 维护插入顺序 允许 O(1)(平均) TreeSet红黑树 自然排序或自定义排序 不允许( NullPointerException)O(log n) 
(1)特点
| 特性 | 说明 |
|---|---|
| 元素唯一性 | 不允许重复元素 |
| 允许 null | 最多只能包含一个 null |
无序性(除 LinkedHashSet 和 TreeSet) | 不保证存储顺序(添加和访问数据不一致),并且没有索引 |
| 非线程安全 | 多线程环境下需要同步控制 |
(2)常用方法
Set 接口继承了 Collection 的所有方法,但没有新增方法。遍历时不能使用索引的方式获取【没有get()方法】。
HashSet类
-
实现接口:
Set<E>(元素唯一)Cloneable(可克隆)Serializable(可序列化)
-
底层数据结构:
- 基于
HashMap(哈希表)实现,元素作为HashMap的key存储 HashMap的value统一为PRESENT(一个静态常量对象,作为占位符)
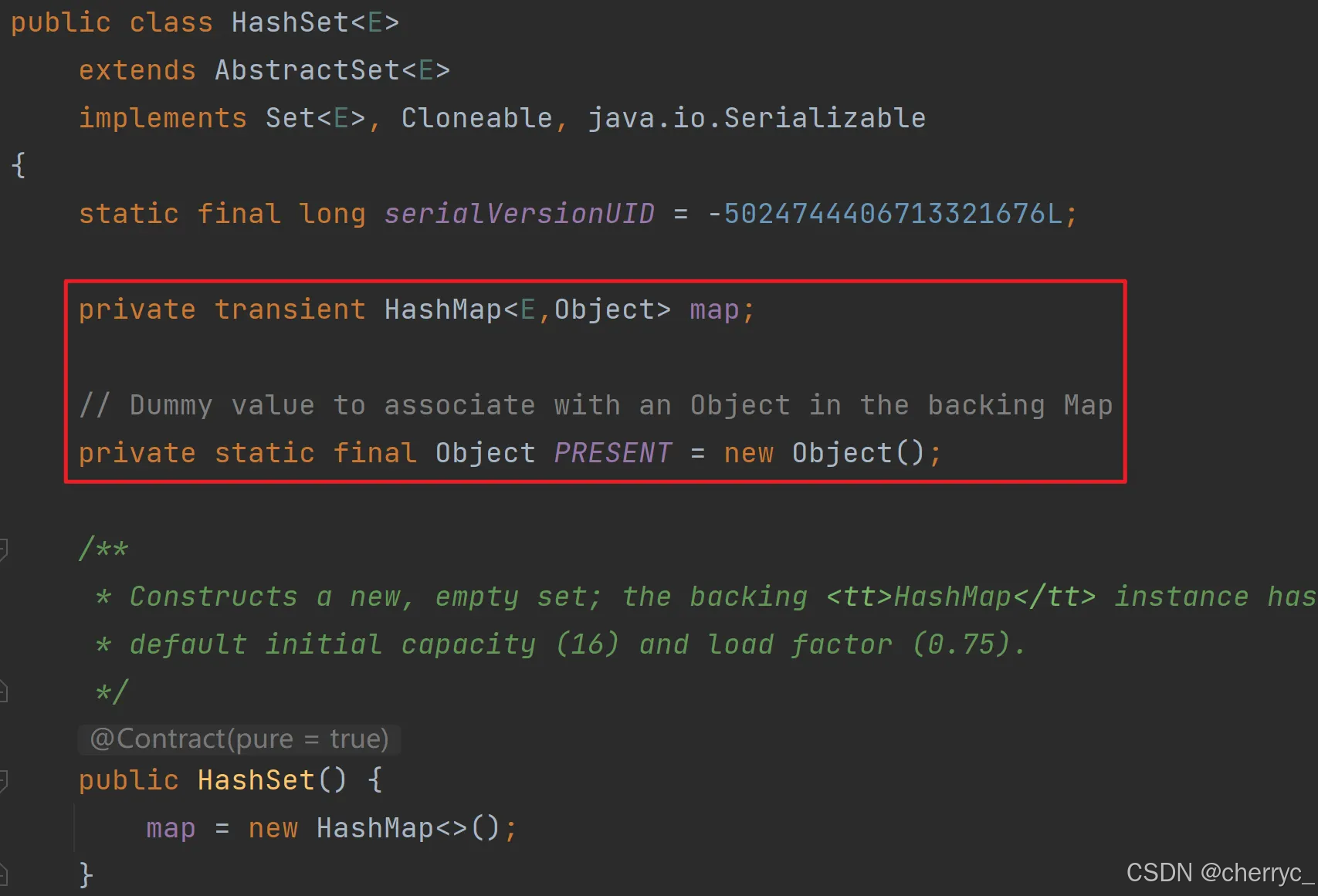
- 基于
| 特性 | 说明 |
|---|---|
| 元素唯一性 | 依赖 hashCode() 和 equals() 方法判断重复 |
| 无序性 | 不保证元素的存储顺序(与插入顺序无关) |
允许 null | 可以存储一个 null 值 |
| 非线程安全 | 多线程环境下需要同步控制 |
| 动态扩容 | 默认初始容量 16,负载因子 0.75 |


equals()方法由程序员定义;如果链表元素个数到8,table大小没有64,就先2倍扩容table,而不是立即树化

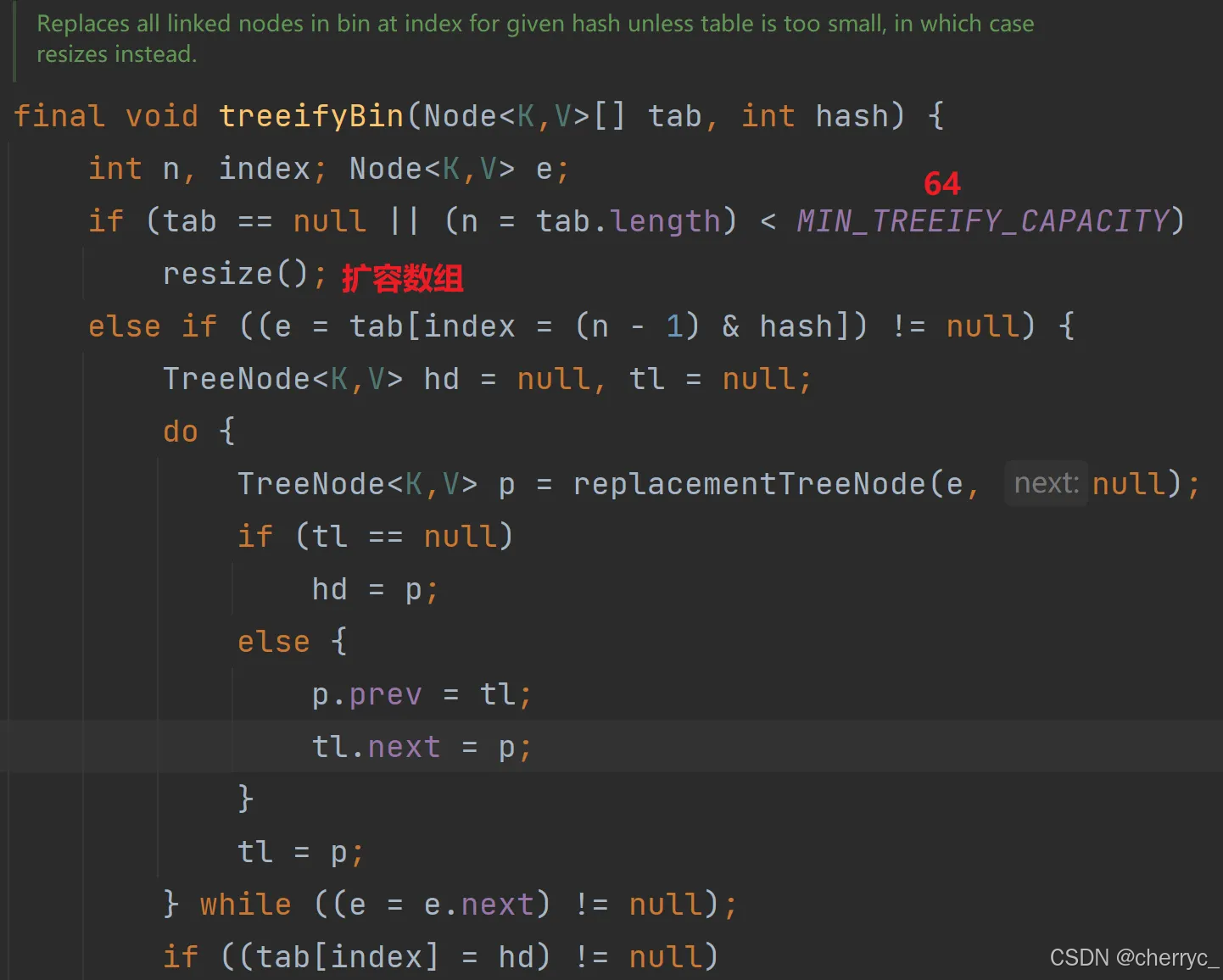
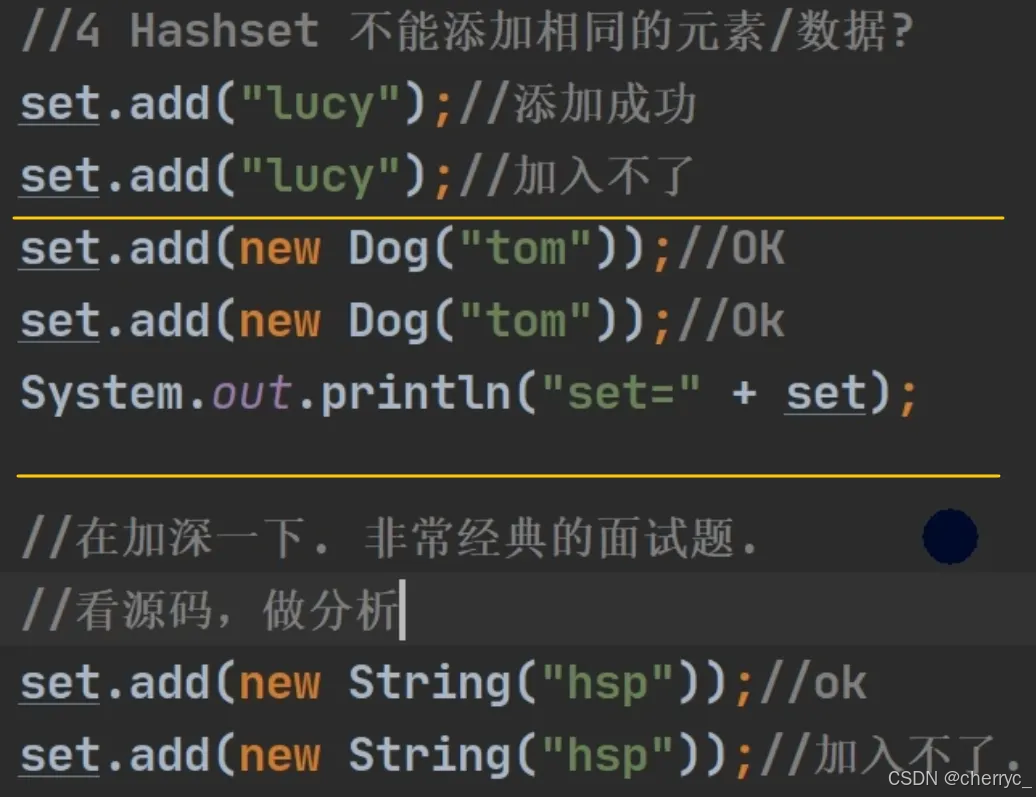
String对象已经重写了equals方法
| 构造方法 | 说明 |
|---|---|
HashSet() | 默认构造(初始容量 16,负载因子 0.75) |
HashSet(int initialCapacity) | 指定初始容量 |
HashSet(int initialCapacity, float loadFactor) | 指定初始容量和负载因子 |
HashSet(Collection<? extends E> c) |
HashSet<String> set1 = new HashSet<>(); // 默认容量 16
HashSet<Integer> set2 = new HashSet<>(100); // 初始容量 100
HashSet<String> set3 = new HashSet<>(16, 0.8f); // 初始容量 16,负载因子 0.8
HashSet<String> set4 = new HashSet<>(Arrays.asList("A", "B", "C")); // 从集合初始化

负载因子=已存储元素数量/哈希表容量。在 Java 的 HashMap 和 HashSet 中,默认负载因子为 0.75。当 元素数量【链表上挂的也算】 > 容量 × 负载因子 时,哈希表会自动扩容(通常容量变为原来的 2 倍)。

HashMap的put()方法如果 e 已存在,返回旧值 PRESENT,否则返回 null;add()方法返回boolean


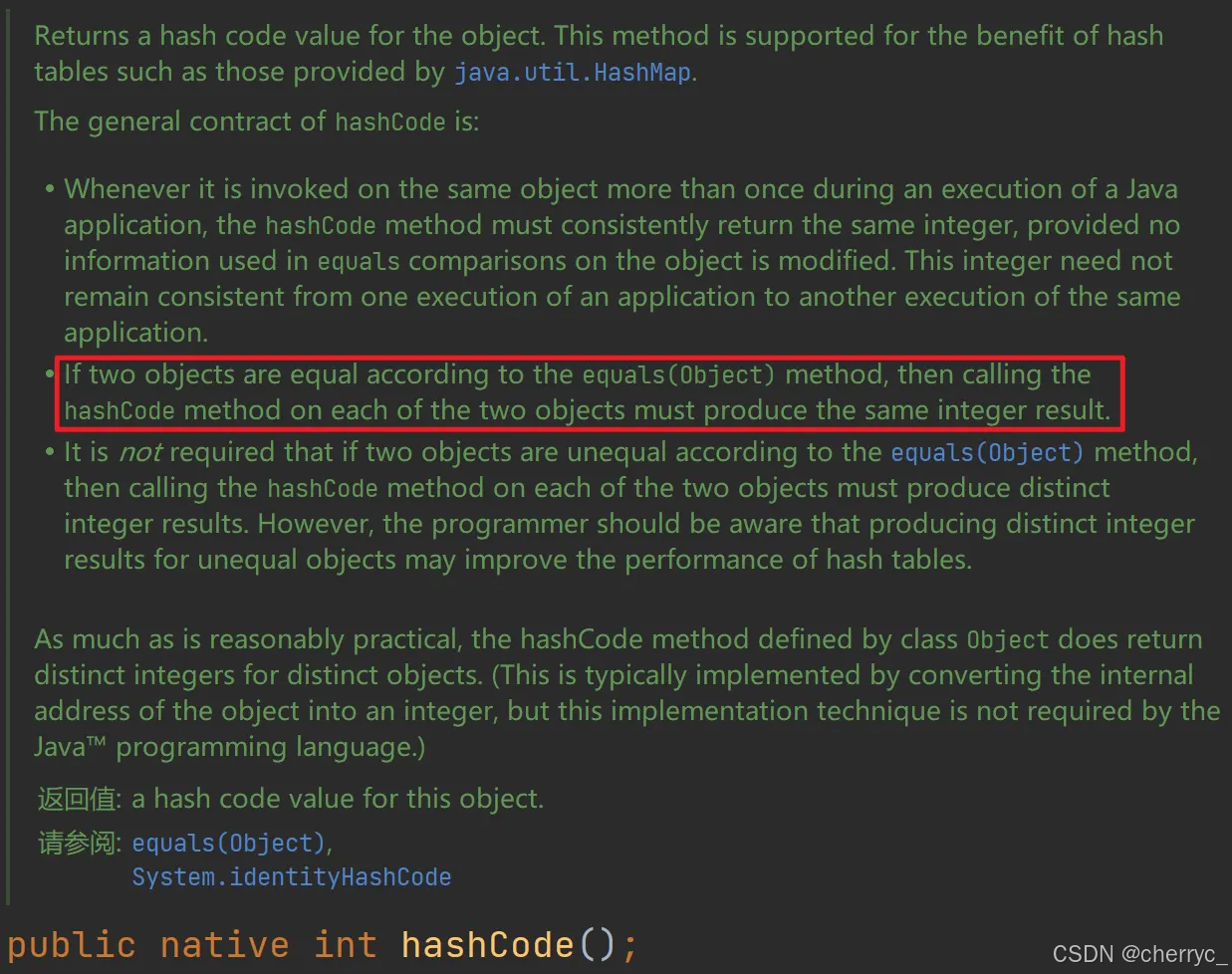
🤯putVal()源码分析⭐⚠【面试必问】
// HashMap方法
// hash: 键 key 的哈希值(经过扰动计算)
// key: 要插入的键
// value: 要插入的值
// onlyIfAbsent: 如果为 true,则仅当键不存在时才插入(不覆盖旧值)
// evict: 用于 LinkedHashMap 的扩展(HashMap 本身不直接使用)
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {Node<K,V>[] tab; Node<K,V> p; int n, i; // 辅助变量// tab: 指向哈希表的数组(table)// p: 临时存储当前桶的头结点// n: 哈希表的长度(容量)// i: 计算出的桶索引if ((tab = table) == null || (n = tab.length) == 0) // table是HashMap的一个字段,存放Node结点// 如果哈希表 table 未初始化或长度为 0,调用 resize() 方法扩容并初始化表n = (tab = resize()).length;if ((p = tab[i = (n - 1) & hash]) == null) // 计算键的桶索引(等价于 hash % n,但效率更高)tab[i] = newNode(hash, key, value, null); // 如果桶为空(p == null),直接创建新节点放入桶中else { // 处理非空桶(哈希冲突)Node<K,V> e; K k;if (p.hash == hash &&// 是同一个对象 或 内容相同[调用自己定义的equals方法]((k = p.key) == key || (key != null && key.equals(k))))e = p; // 如果头结点的键与当前键相同(== 或 equals),记录该节点到 e(后续覆盖值)else if (p instanceof TreeNode) // 如果桶是红黑树结构(TreeNode),调用 putTreeVal 插入节点e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);else { // 处理链表节点// 遍历链表for (int binCount = 0; ; ++binCount) {if ((e = p.next) == null) { // 如果到达链表末尾(e == null),插入新节点p.next = newNode(hash, key, value, null);if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st // 如果链表长度 ≥ TREEIFY_THRESHOLD(默认 8),调用 treeifyBin 转换为红黑树treeifyBin(tab, hash);break;}// 如果找到相同键的节点,退出循环if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))break;p = e;}}// 如果 e 不为空(找到相同键的节点),根据 onlyIfAbsent 决定是否覆盖值if (e != null) { // existing mapping for key // 存在相同键的节点V oldValue = e.value;if (!onlyIfAbsent || oldValue == null)e.value = value; // 覆盖旧值afterNodeAccess(e); // LinkedHashMap 的回调方法return oldValue; // 返回旧值}}++modCount; // 修改计数器(用于快速失败机制)if (++size > threshold) // 没加入一个节点都会增加sizeresize(); // 扩容afterNodeInsertion(evict); // LinkedHashMap 的回调方法return null; // 插入成功,返回 null(无旧值)}
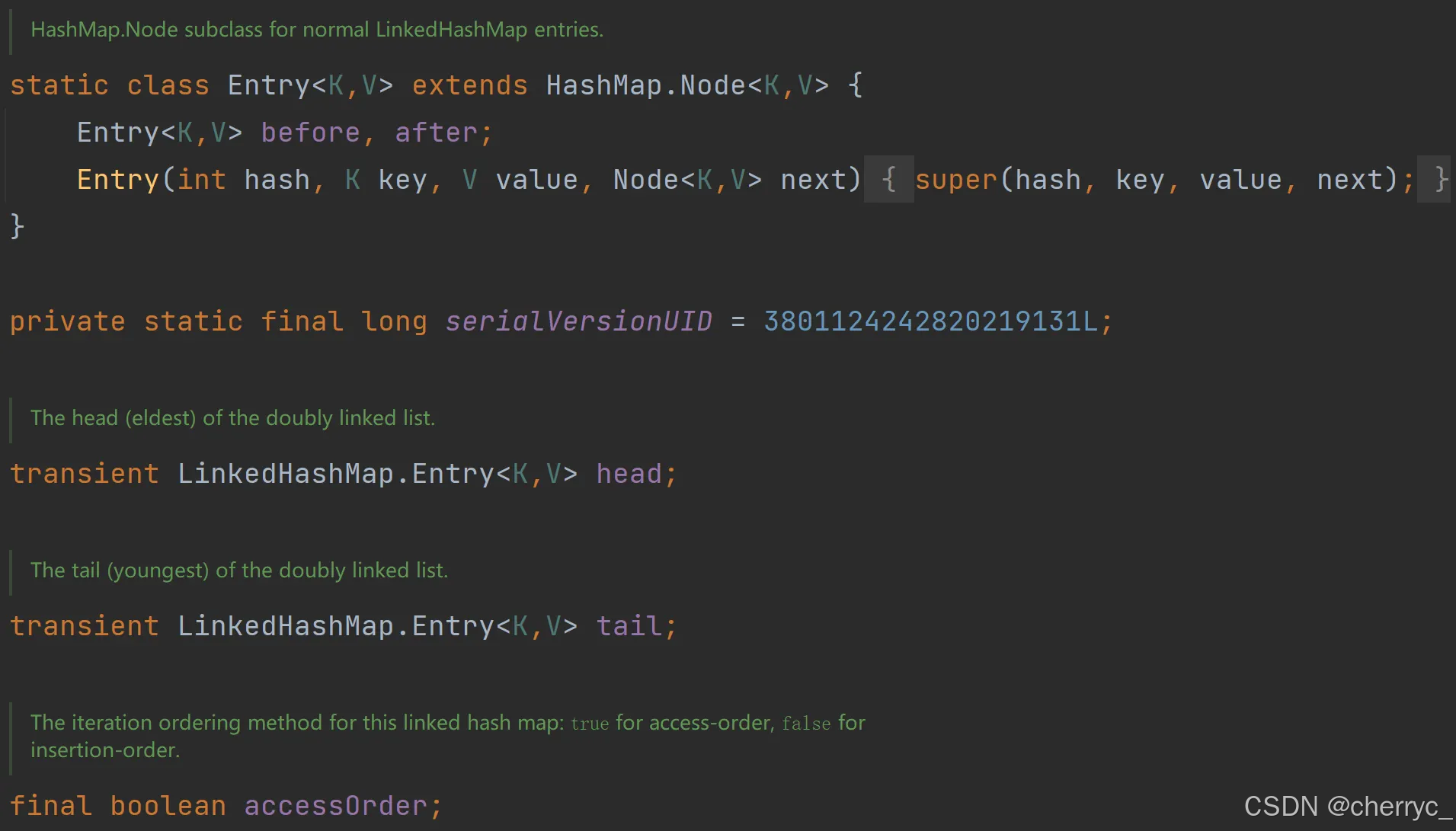
static class Node<K,V> **implements Map.Entry<K,V>** {final int hash;final K key;V value;Node<K,V> next;Node(int hash, K key, V value, Node<K,V> next) {this.hash = hash;this.key = key;this.value = value;this.next = next;}public final K getKey() { return key; }public final V getValue() { return value; }public final String toString() { return key + "=" + value; }public final int hashCode() {return Objects.hashCode(key) ^ Objects.hashCode(value);}public final V setValue(V newValue) {V oldValue = value;value = newValue;return oldValue;}public final boolean equals(Object o) {if (o == this)return true;if (o instanceof Map.Entry) {Map.Entry<?,?> e = (Map.Entry<?,?>)o;if (Objects.equals(key, e.getKey()) &&Objects.equals(value, e.getValue()))return true;}return false;}}
resize()方法用于扩容哈希表(table)并重新分配所有键值对,是 HashMap 动态扩容的核心机制。
final Node<K,V>[] resize() { // 返回一个新的 Node<K,V>[] 数组(扩容后的哈希表)Node<K,V>[] oldTab = table;int oldCap = (oldTab == null) ? 0 : oldTab.length; // 当前容量;可能为 null,表示首次初始化int oldThr = threshold; // 当前扩容阈值int newCap, newThr = 0; // 新容量、新阈值(初始为0)if (oldCap > 0) { // 非首次初始化if (oldCap >= MAXIMUM_CAPACITY) { // 已达最大容量(2^30)threshold = Integer.MAX_VALUE; // 不再扩容return oldTab; // 直接返回原表(无法再扩容)}else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY) // **容量翻倍;初始容量>=16**newThr = oldThr << 1; // double threshold // 阈值翻倍}// 如果当前容量 = 0(首次初始化)else if (oldThr > 0) // initial capacity was placed in thresholdnewCap = oldThr; // 构造时指定了初始容量,设置容量// HashMap 构造时如果指定了 initialCapacity,会计算 threshold(初始阈值)else { // zero initial threshold signifies using defaults// 无参构造,使用默认值newCap = DEFAULT_INITIAL_CAPACITY; // 16newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 16 * 0.75 = 12}// 计算新的阈值if (newThr == 0) {float ft = (float)newCap * loadFactor;newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?(int)ft : Integer.MAX_VALUE);}// 创建新哈希表threshold = newThr; // 更新全局阈值@SuppressWarnings({"rawtypes","unchecked"})Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; // 创建新数组table = newTab; // // 更新全局 table// 迁移旧数据到新表if (oldTab != null) {for (int j = 0; j < oldCap; ++j) { // 遍历旧表,处理非空桶Node<K,V> e;if ((e = oldTab[j]) != null) { // 当前桶不为空oldTab[j] = null; // 清空旧桶(帮助GC)if (e.next == null) // 只有一个节点newTab[e.hash & (newCap - 1)] = e; // 直接计算新位置,放入新表else if (e instanceof TreeNode). // 红黑树节点((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 拆分红黑树(可能退化为链表)else { // preserve order 链表节点// 由于容量翻倍(newCap = oldCap << 1),节点的新位置只有两种可能:// 原位置 j((e.hash & oldCap) == 0)// 新位置 j + oldCap((e.hash & oldCap) != 0)Node<K,V> loHead = null, loTail = null; // 低位链表(留在原位置)Node<K,V> hiHead = null, hiTail = null; // 高位链表(移动到 j + oldCapNode<K,V> next;do {next = e.next;if ((e.hash & oldCap) == 0) { // 判断是否留在原位置if (loTail == null)loHead = e;elseloTail.next = e;loTail = e;}else { // 需要移动到新位置if (hiTail == null)hiHead = e;elsehiTail.next = e;hiTail = e;}} while ((e = next) != null);if (loTail != null) { // 低位链表放回原索引 jloTail.next = null;newTab[j] = loHead;}if (hiTail != null) { // 高位链表放到 j + oldCaphiTail.next = null;newTab[j + oldCap] = hiHead;}}}}}return newTab; // 返回扩容后的新哈希表}


-
💻例题:添加3个Employee对象,年龄和生日相同时不添加【注意重写equals()和hashCode()方法】
import java.util.Objects; import java.util.Set; import java.util.HashSet;public class Main {public static void main(String[] args) {Set<Employee> employees = new HashSet<>();employees.add(new Employee("张三", 2800, new MyDate(1990, 8, 30)));employees.add(new Employee("里斯", 2800, new MyDate(1990, 8, 30)));employees.add(new Employee("张三", 2800, new MyDate(1990, 8, 30)));System.out.println(employees);} }class Employee {private String name;private int sal;private MyDate birthday;public Employee(String name, int sal, MyDate birthday) {this.name = name;this.sal = sal;this.birthday = birthday;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;Employee employee = (Employee) o;return sal == employee.sal && Objects.equals(name, employee.name) && Objects.equals(birthday, employee.birthday);}@Overridepublic int hashCode() {return Objects.hash(name, sal, birthday);}@Overridepublic String toString() {return "Employee{" +"name='" + name + '\\'' +", sal=" + sal +", birthday=" + birthday +'}';} }class MyDate {private int year;private int month;private int day;public MyDate(int year, int month, int day) {this.year = year;this.month = month;this.day = day;}public int getYear() {return year;}public int getMonth() {return month;}public int getDay() {return day;}public void setYear(int year) {this.year = year;}public void setMonth(int month) {this.month = month;}public void setDay(int day) {this.day = day;}@Overridepublic boolean equals(Object o) {if (this == o) return true;if (o == null || getClass() != o.getClass()) return false;MyDate myDate = (MyDate) o;return year == myDate.year && month == myDate.month && day == myDate.day;}@Overridepublic int hashCode() {return Objects.hash(year, month, day);} }

HashSet 不是线程安全的,多线程环境下需要同步:
解决方案:
-
使用
Collections.synchronizedSet:Set<String> syncSet = Collections.synchronizedSet(new HashSet<>()); -
使用
ConcurrentHashMap.newKeySet()(Java 8+):Set<String> concurrentSet = ConcurrentHashMap.newKeySet(); -
使用
CopyOnWriteArraySet(读多写少场景):Set<String> cowSet = new CopyOnWriteArraySet<>();
-
💻例题

两个
Person对象,只要它们的id和name相同,那么equals()返回true,且hashCode()的值也相同。- 修改
p1.name时,p1对象本身没变,在HashSet中的存储位置是根据它原先的hashCode()(基于"AA") 确定的;但是 它的新hash值发生变化 set.remove(p1)执行时:-
根据
p1当前的hashCode()(基于"CC") 去查找对应的哈希桶
-
但是
p1存储位置和计算出的位置不同,所以找不到元素 -
所以
remove(p1)失败,p1仍然在set中 -
输出[Person{id=1001, name='CC'}, Person{id=1002, name='BB'}]
-
- 添加新的对象
p3(1001, "CC"),计算的hash值对应的位置为空,添加成功 - 添加新的对象
p4(1001, "AA"),计算的hash值和初次添加p1的值相同,但是由于内容不同,equals结果不是true,所以会挂在p1后面,添加成功

- 修改
TreeSet类
TreeSet 基于 红黑树(Red-Black Tree) 实现,能够对元素进行自然排序或自定义排序。它保证元素唯一且有序,但不允许 null 值(会抛出 NullPointerException)。
-
继承关系:
java.lang.Object→ java.util.AbstractCollection<E>→ java.util.AbstractSet<E>→ java.util.TreeSet<E> -
实现接口:
Set<E>(元素唯一)NavigableSet<E>(支持导航方法,如ceiling(),floor())SortedSet<E>(支持排序)Cloneable(可克隆)Serializable(可序列化)
-
底层数据结构:
- 红黑树(自平衡二叉搜索树),保证元素有序且操作高效(
O(log n))。
- 红黑树(自平衡二叉搜索树),保证元素有序且操作高效(
| 特性 | 说明 |
|---|---|
| 元素唯一性 | 不允许重复元素(依赖 compareTo() 或 Comparator) |
| 排序能力 | 默认按自然顺序(Comparable)或自定义 Comparator 排序 |
不允许 null | 会抛出 NullPointerException |
| 非线程安全 | 多线程环境下需要同步控制 |
| 高效操作 | 查找、插入、删除的时间复杂度为 O(log n) |
| 构造方法 | 说明 |
|---|---|
TreeSet() | 默认构造,按自然顺序排序(元素需实现 Comparable;如果也没有传入Comparator接口的匿名内部类,则会报ClassCastException异常) |
TreeSet(Comparator<? super E> comparator) | 指定自定义排序规则 |
TreeSet(Collection<? extends E> c) | 从另一个集合初始化,按自然顺序排序 |
TreeSet(SortedSet<E> s) | 从另一个 SortedSet 初始化,继承其排序规则 |
示例:
// 1. 自然排序(元素需实现 Comparable)
TreeSet<String> set1 = new TreeSet<>();
set1.add("Java");
set1.add("Python");
set1.add("C++");
System.out.println(set1); // 输出 [C++, Java, Python](字典序)// 2. 自定义排序(按字符串长度)
TreeSet<String> set2 = new TreeSet<>((a, b) -> a.length() - b.length());
set2.add("Java");
set2.add("Python");
set2.add("C");
System.out.println(set2); // 输出 [C, Java, Python](按长度排序)// 3. 从集合初始化
TreeSet<Integer> set3 = new TreeSet<>(Arrays.asList(3, 1, 2));
System.out.println(set3); // 输出 [1, 2, 3](自然排序)
常用方法
(1) 添加元素
| 方法 | 说明 |
|---|---|
boolean add(E e) | 添加元素,如果已存在则返回 false |
(2) 删除元素
| 方法 | 说明 |
|---|---|
boolean remove(Object o) | 删除指定元素 |
void clear() | 清空集合 |
(3) 查询元素
| 方法 | 说明 |
|---|---|
boolean contains(Object o) | 判断是否包含某个元素 |
E first() | 返回第一个(最小)元素 |
E last() | 返回最后一个(最大)元素 |
int size() | 返回集合大小 |
示例:
TreeSet<Integer> nums = new TreeSet<>(Arrays.asList(3, 1, 2));
System.out.println(nums.first()); // 1
System.out.println(nums.last()); // 3
(4) 范围查询(NavigableSet 方法)
| 方法 | 说明 |
|---|---|
SortedSet<E> headSet(E toElement) | 返回小于 toElement 的子集 |
SortedSet<E> tailSet(E fromElement) | 返回大于等于 fromElement 的子集 |
SortedSet<E> subSet(E fromElement, E toElement) | 返回 [fromElement, toElement) 的子集 |
E ceiling(E e) | 返回大于等于 e 的最小元素 |
E floor(E e) | 返回小于等于 e 的最大元素 |
示例:
TreeSet<Integer> nums = new TreeSet<>(Arrays.asList(1, 3, 5, 7, 9));
System.out.println(nums.headSet(5)); // [1, 3]
System.out.println(nums.tailSet(5)); // [5, 7, 9]
System.out.println(nums.subSet(3, 7)); // [3, 5]
System.out.println(nums.ceiling(4)); // 5
System.out.println(nums.floor(4)); // 3
(5) 遍历方式(按排序顺序)
① 增强 for 循环
for (String item : set) {System.out.println(item); // 按排序顺序输出
}
② Iterator 迭代器
Iterator<String> it = set.iterator();
while (it.hasNext()) {System.out.println(it.next());
}
③ 降序遍历(descendingIterator)
Iterator<String> descIt = set.descendingIterator();
while (descIt.hasNext()) {System.out.println(descIt.next()); // 从大到小输出
}
④ Java 8 forEach + Lambda
set.forEach(System.out::println);
排序规则
(1) 自然排序(Comparable)
- 元素必须实现
Comparable接口,重写compareTo()方法。 - 示例:
String、Integer等已实现Comparable。
class Student implements Comparable<Student> {String name;int age;@Overridepublic int compareTo(Student other) {return this.age - other.age; // 按年龄排序}
}TreeSet<Student> students = new TreeSet<>();
students.add(new Student("Alice", 20));
students.add(new Student("Bob", 18));
// 输出顺序:Bob(18) → Alice(20)
(2) 自定义排序(Comparator)
- 通过构造方法传入
Comparator,覆盖自然排序规则。 - 示例:按字符串长度排序。
TreeSet<String> set = new TreeSet<>((a, b) -> a.length() - b.length());
set.add("Java");
set.add("Python");
set.add("C");
// 输出顺序:C → Java → Python
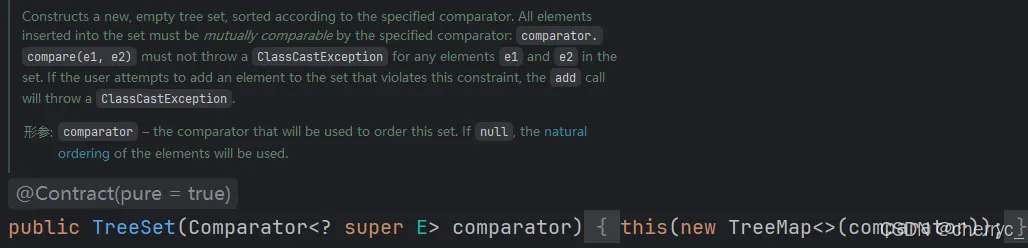
构造器把传入的比较器对象,赋值给TreeMap的属性this.comparator


-
🤯
add()方法调试: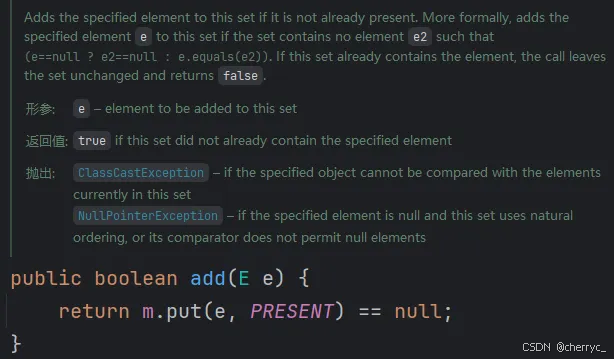
TreeSet方法
如果
comparator的compare方法值为0,则不会加入新元素(因为TreeMap中替换的是value,即PRESENT占位符)// TreeMap方法 public V put(K key, V value) {Entry<K,V> t = root;if (t == null) {**compare(key, key); // type (and possibly null) check,主要用于检测是否为空**root = new Entry<>(key, value, null);size = 1;modCount++;return null;}int cmp;Entry<K,V> parent;// split comparator and comparable pathsComparator<? super K> cpr = comparator;if (cpr != null) {do {parent = t;**cmp = cpr.compare(key, t.key);**if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;else**return t.setValue(value); // 替换的是value,不是key**} while (t != null);}else {if (key == null)throw new NullPointerException();@SuppressWarnings("unchecked")Comparable<? super K> k = (Comparable<? super K>) key;do {parent = t;cmp = k.compareTo(t.key);if (cmp < 0)t = t.left;else if (cmp > 0)t = t.right;elsereturn t.setValue(value);} while (t != null);}Entry<K,V> e = new Entry<>(key, value, parent);if (cmp < 0)parent.left = e;elseparent.right = e;fixAfterInsertion(e);size++;modCount++;return null; }final int compare(Object k1, Object k2) {return comparator==null ? ((Comparable<? super K>)k1).compareTo((K)k2): comparator.compare((K)k1, (K)k2); }

LinkedHashSet类
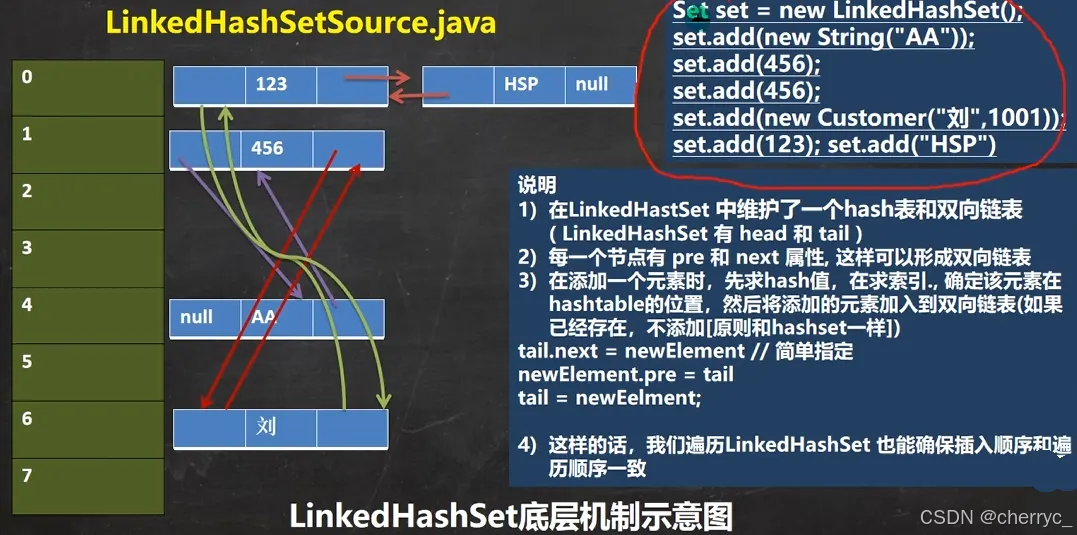
LinkedHashSet 继承自 HashSet,并实现了 Set 接口。LinkedHashSet 的主要特点是维护元素的插入顺序,同时具备 HashSet 的去重能力。

-
继承关系:
java.lang.Object→ java.util.AbstractCollection<E>→ java.util.AbstractSet<E>→ java.util.HashSet<E>→ java.util.LinkedHashSet<E> -
实现接口:
Set<E>(元素唯一)Cloneable(可克隆)Serializable(可序列化)
-
底层数据结构:
-
哈希表(
LinkedHashMap,时HashMap的子类):用于快速查找和去重。 -
双向链表:维护元素的插入顺序。

多态
-
| 特性 | 说明 |
|---|---|
| 元素唯一性 | 不允许重复元素(依赖 hashCode() 和 equals()) |
| 维护插入顺序 | 遍历顺序与元素添加顺序一致 |
允许 null | 可以存储一个 null 值 |
| 非线程安全 | 多线程环境下需要同步控制 |
| 动态扩容 | 默认初始容量 16,负载因子 0.75 |
| 构造方法 | 说明 |
|---|---|
LinkedHashSet() | 默认构造(容量 16,负载因子 0.75) |
LinkedHashSet(int initialCapacity) | 指定初始容量 |
LinkedHashSet(int initialCapacity, float loadFactor) | 指定初始容量和负载因子 |
LinkedHashSet(Collection<? extends E> c) | 从另一个集合初始化 |
示例:
LinkedHashSet<String> set1 = new LinkedHashSet<>(); // 默认容量 16
LinkedHashSet<Integer> set2 = new LinkedHashSet<>(100); // 初始容量 100
LinkedHashSet<String> set3 = new LinkedHashSet<>(Arrays.asList("A", "B", "C")); // 从集合初始化
常用方法:
LinkedHashSet 的方法与 HashSet 完全一致,但遍历顺序不同。
(1) 添加元素
LinkedHashSet<String> set = new LinkedHashSet<>();
set.add("Java"); // ["Java"]
set.add("Python"); // ["Java", "Python"]
set.add("C++"); // ["Java", "Python", "C++"]
set.add("Java"); // 重复元素,不添加 → ["Java", "Python", "C++"]
(2) 删除元素
set.remove("Python"); // ["Java", "C++"]
set.clear(); // []
(3) 查询元素
System.out.println(set.contains("Java")); // true
System.out.println(set.size()); // 2
底层实现
LinkedHashSet 继承自 HashSet,但内部使用 LinkedHashMap 存储数据:
// LinkedHashSet 的源码片段
public LinkedHashSet() {super(16, 0.75f, true); // 调用 HashSet 的特定构造方法
}// HashSet 中的构造方法
HashSet(int initialCapacity, float loadFactor, boolean dummy) {map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
LinkedHashMap:在HashMap的基础上,额外维护了一个双向链表,记录元素的插入顺序。
LinkedHashSet vs. HashSet vs. TreeSet
| 对比项 | LinkedHashSet | HashSet | TreeSet |
|---|---|---|---|
| 底层结构 | 哈希表 + 双向链表 | 哈希表 | 红黑树 |
| 顺序性 | 插入顺序 | 无序 | 自然排序/自定义排序 |
null 支持 | 允许一个 null | 允许一个 null | 不允许 null |
| 时间复杂度 | O(1)(查找/插入/删除) | O(1) | O(log n) |
| 适用场景 | 需要维护插入顺序的去重集合 | 快速去重,不关心顺序 | 需要排序的去重集合 |
四、Map接口
Map 用于存储**键值对(Key-Value)**数据。它表示一组映射关系,其中每个 Key 对应一个 Value,并且 Key 不允许重复(Value 可以重复)。
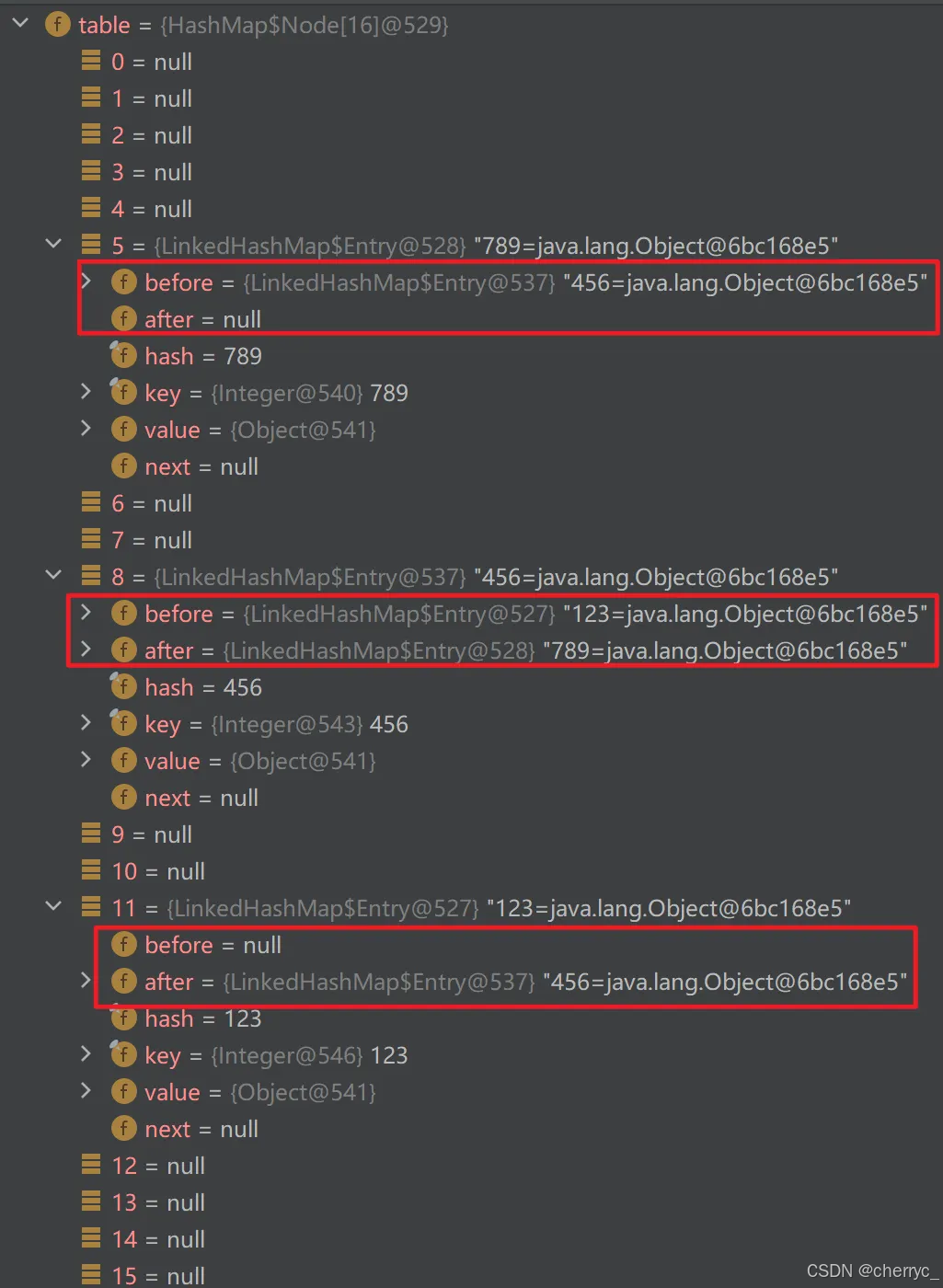
JDK8中Map特点👇[其他版本可能不同]


Node存放在table中,为了方便遍历【因为Map.Entry提供了getKey和getValue方法】,使用entrySet存放Node类型-向上转型【Node实现了Entry接口】


-
继承关系:
Map是一个独立的接口,不继承Collection,但它是集合框架的一部分。 -
核心特性:
特性 说明 键唯一性 每个 Key只能映射一个Value允许 null可以有一个 nullKey 和多个nullValue无序性(除 LinkedHashMap和TreeMap)不保证存储顺序 非线程安全 多线程环境下需要同步控制 -
主要实现类:
实现类 底层结构 是否有序 允许 null时间复杂度 HashMap哈希表 无序 Key/Value 均可为 nullO(1) LinkedHashMap哈希表 + 双向链表 维护插入/访问顺序 Key/Value 均可为 nullO(1) TreeMap红黑树 Key 自然排序或自定义排序 Key 不能为 nullO(log n) Hashtable哈希表 无序 Key/Value 均不能为 nullO(1) ConcurrentHashMap分段锁 + 哈希表 无序 Key/Value 均不能为 nullO(1)
(1)常用方法
1.添加/修改元素
| 方法 | 说明 |
|---|---|
V put(K key, V value) | 添加键值对,如果 Key 已存在则替换旧值;key和Value类型为Object |
void putAll(Map<? extends K, ? extends V> m) | 添加另一个 Map 的所有键值对 |
示例:
Map<String, Integer> map = new HashMap<>();
map.put("Java", 1); // {"Java":1}
map.put("Python", 2); // {"Java":1, "Python":2}
map.put("Java", 3); // 替换旧值 → {"Java":3, "Python":2}
2.删除元素
| 方法 | 说明 |
|---|---|
V remove(Object key) | 删除指定 Key 的键值对,返回被删除的 Value |
void clear() | 清空所有键值对 |
示例:
Map<String, Integer> map = new HashMap<>();
map.put("A", 1);
map.put("B", 2);
map.remove("A"); // 删除 "A" → {"B":2}
map.clear(); // 清空 → {}
3.查询元素
| 方法 | 说明 |
|---|---|
V get(Object key) | 获取指定 Key 对应的 Value |
boolean containsKey(Object key) | 判断是否包含某个 Key |
boolean containsValue(Object value) | 判断是否包含某个 Value |
boolean isEmpty() | 判断 Map 是否为空 |
int size() | 返回键值对数量 |
示例:
Map<String, Integer> map = new HashMap<>();
map.put("Java", 1); // int->Integer
System.out.println(map.get("Java")); // 1
System.out.println(map.containsKey("Go")); // false
4.遍历方式
① 遍历所有 Key(keySet())
增强for循环👇/迭代器
for (String key : map.keySet()) { // SetSystem.out.println(key + ": " + map.get(key));
}
Iterator iterator = map.keySet().iterator();
while (iterator.hasNext()) {Object key = iterator.next();Object value = map.get(key);System.out.println(value);
}
② 遍历所有 Value(values())
增强for循环👇/迭代器
for (Integer value : map.values()) { // CollectionSystem.out.println(value);
}
③ 遍历所有键值对(entrySet())
增强for循环👇/迭代器
for (Map.Entry<String, Integer> entry : map.entrySet()) { // SetSystem.out.println(entry.getKey() + ": " + entry.getValue());
}
Iterator it = map.entrySet().iterator();
while (it.hasNext()) {
// System.out.println(it.next().getClass()); // 运行类型为 NodeMap.Entry entry = (Map.Entry) it.next();// 编译类型为Object,运行类型为Node,也有get方法,但是Node的修饰符是default,没有办法转换System.out.println(entry.getKey() + " : " + entry.getValue());
}
④ Java 8 forEach + Lambda
map.forEach((key, value) -> System.out.println(key + ": " + value));
(2)Map.Entry 接口
Map.Entry 是 Map 的内部接口,表示一个键值对条目。常用方法:
| 方法 | 说明 |
|---|---|
K getKey() | 获取当前条目的 Key |
V getValue() | 获取当前条目的 Value |
V setValue(V value) | 修改当前条目的 Value |
示例:
Map<String, Integer> map = new HashMap<>();
map.put("Java", 1);
for (Map.Entry<String, Integer> entry : map.entrySet()) {entry.setValue(entry.getValue() + 10); // 修改 Value
}
(3)线程安全问题
HashMap、TreeMap、LinkedHashMap 不是线程安全的。解决方案:
-
使用
Collections.synchronizedMap:Map<String, Integer> syncMap = Collections.synchronizedMap(new HashMap<>()); -
使用
ConcurrentHashMap(推荐):Map<String, Integer> concurrentMap = new ConcurrentHashMap<>(); -
使用
Hashtable(已过时,性能差):Map<String, Integer> table = new Hashtable<>();
(4)实现类的选择
| 场景 | 推荐实现类 |
|---|---|
| 需要快速查找、去重 | HashMap |
| 需要维护插入/访问顺序 | LinkedHashMap |
| 需要 Key 排序 | TreeMap |
| 多线程高并发 | ConcurrentHashMap |
| 遗留代码兼容 | Hashtable |
HashMap类
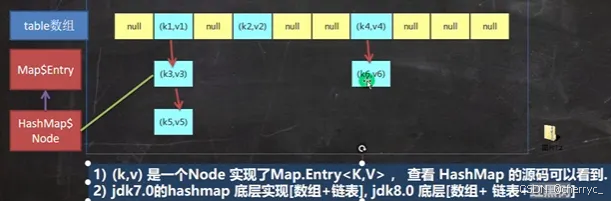
HashMap基于哈希表实现,不保证映射的顺序,提供高效的键值对存储和查询(平均时间复杂度 O(1))。它允许 null 键和 null 值,但非线程安全。
-
继承关系:
java.lang.Object→ java.util.AbstractMap<K,V>→ java.util.HashMap<K,V> -
实现接口:
Map<K,V>(键值对存储)Cloneable(可克隆)Serializable(可序列化)

-
底层数据结构(JDK 8+):
- 数组 + 链表 + 红黑树(当链表长度 ≥8 时,链表转为红黑树)。
- 每个桶(bucket)存储一个链表或红黑树节点(
Node<K,V>)。
| 特性 | 说明 |
|---|---|
| 键唯一性 | 依赖 hashCode() 和 equals() 判断 Key 是否重复 |
允许 null | 可以有一个 null Key 和多个 null Value |
| 无序性 | 不保证键值对的存储顺序 |
| 动态扩容 | 默认初始容量 16,负载因子 0.75 |
| 非线程安全 | 多线程环境下需手动同步 |
| 构造方法 | 说明 |
|---|---|
HashMap() | 默认构造(容量 16,负载因子 0.75) |
HashMap(int initialCapacity) | 指定初始容量 |
HashMap(int initialCapacity, float loadFactor) | 指定初始容量和负载因子 |
HashMap(Map<? extends K, ? extends V> m) | 从另一个 Map 初始化 |
示例:
HashMap<String, Integer> map1 = new HashMap<>(); // 默认容量 16
HashMap<String, Integer> map2 = new HashMap<>(32); // 初始容量 32
HashMap<String, Integer> map3 = new HashMap<>(16, 0.8f); // 容量 16,负载因子 0.8
HashMap<String, Integer> map4 = new HashMap<>(map1); // 从另一个 Map 初始化

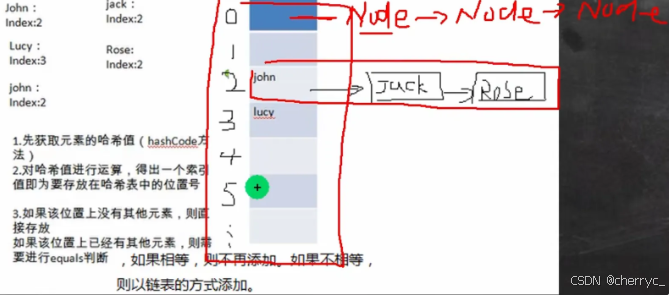
当HashCode()值都相同,equals()不等时,添加到第9个,table桶的数量从16扩容到32;添加到第10个,扩容到64;添加到第11个,进行树化:

底层原理
1.哈希函数
-
hashCode():计算Key的哈希值。 -
扰动函数:JDK 8 使用以下方法减少哈希冲突:
static final int hash(Object key) {int h;return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);// 将 h 的二进制表示向右移动 16 位,左边补 0// 将原始的 h 与 h >>> 16 进行按位异或 }
2.存储结构
- 数组(table):存储桶(bucket),每个桶对应一个哈希值。
- 链表/红黑树:
- 哈希冲突时,元素以链表形式存储(
Node<K,V>)。 - 当链表长度 ≥8 且数组长度 ≥64 时,链表转为红黑树(
TreeNode<K,V>)。
- 哈希冲突时,元素以链表形式存储(
3.扩容机制

- 触发条件:当
元素数量 > 容量 × 负载因子(默认16 × 0.75 = 12)。 - 扩容操作:
- 新容量 = 旧容量 × 2(如
16 → 32)。 - 重新计算所有键值对的哈希并分配到新桶中(
rehash)。
- 新容量 = 旧容量 × 2(如
性能优化
(1) 减少哈希冲突
-
重写
hashCode()和equals():确保两个方法逻辑一致。@Override public int hashCode() {return Objects.hash(name, age); // 使用相同字段计算哈希 }@Override public boolean equals(Object o) {// 比较所有关键字段 }
(2) 预分配容量
// 预知存储 1000 个元素,避免扩容
HashMap<String, Integer> map = new HashMap<>(1000, 0.75f);
Hashtable类
Hashtable 是 Java 早期提供的线程安全的哈希表实现,用于存储键值对(Key-Value)。它继承自 Dictionary 类并实现了 Map 接口,但已被 HashMap 和 ConcurrentHashMap 取代,现代开发中不建议使用。
-
继承关系:

java.lang.Object→ java.util.Dictionary<K,V>→ java.util.Hashtable<K,V> -
实现接口:
Map<K,V>(键值对存储)Cloneable(可克隆)Serializable(可序列化)
-
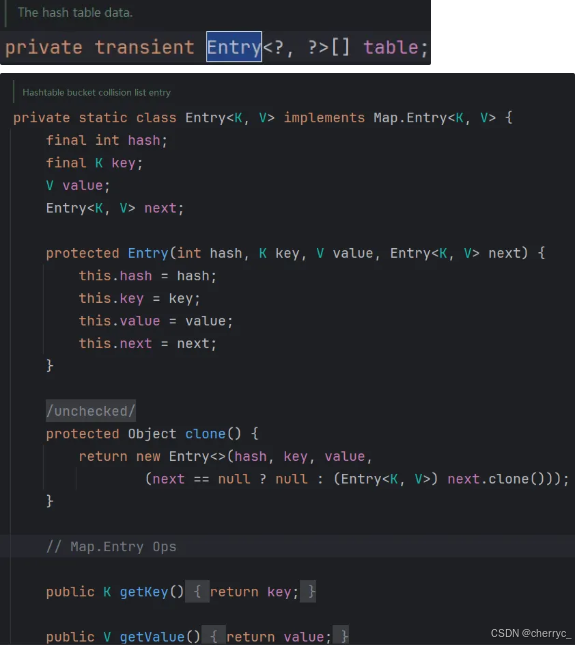
底层数据结构:
- 哈希表(数组
Hashtable$Entry[]+ 链表),通过synchronized关键字实现线程安全。
- 哈希表(数组
| 特性 | 说明 |
|---|---|
| 线程安全 | 所有方法用 synchronized 修饰,性能较低 |
| 键值唯一性 | Key 不允许重复(依赖 hashCode() 和 equals()) |
不允许 null | Key 和 Value 均不能为 null(会抛出 NullPointerException) |
| 无序性 | 不保证键值对的存储顺序 |
| 动态扩容 | 默认初始容量 11,负载因子 0.75,临界值为8【当元素个数为8时,下一次扩容为23:int newCapacity = (oldCapacity << 1) + 1;,阈值为17】 |
| 构造方法 | 说明 |
|---|---|
Hashtable() | 默认构造(容量 11,负载因子 0.75) |
Hashtable(int initialCapacity) | 指定初始容量 |
Hashtable(int initialCapacity, float loadFactor) | 指定初始容量和负载因子 |
Hashtable(Map<? extends K, ? extends V> t) | 从另一个 Map 初始化 |
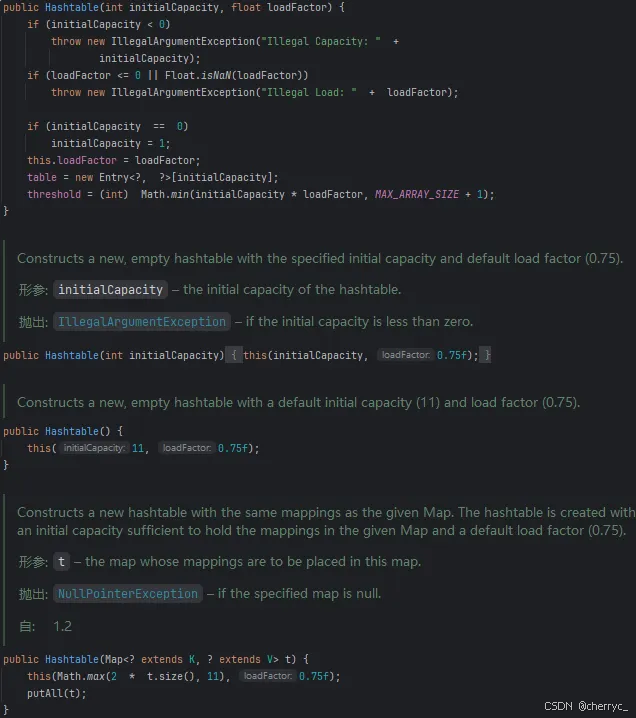
示例:
Hashtable<String, Integer> table1 = new Hashtable<>(); // 默认容量 11
Hashtable<String, Integer> table2 = new Hashtable<>(16); // 初始容量 16
Hashtable<String, Integer> table3 = new Hashtable<>(16, 0.8f); // 容量 16,负载因子 0.8
Hashtable<String, Integer> table4 = new Hashtable<>(map); // 从另一个 Map 初始化
-
🤯
put()源码:public synchronized V put(K key, V value) {// Make sure the value is not nullif (value == null) {throw new NullPointerException();}// Makes sure the key is not already in the hashtable.Entry<?,?> tab[] = table;int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;@SuppressWarnings("unchecked")Entry<K,V> entry = (Entry<K,V>)tab[index];for(; entry != null ; entry = entry.next) {if ((entry.hash == hash) && entry.key.equals(key)) {V old = entry.value;entry.value = value; // 替代原值return old;}}**addEntry(hash, key, value, index);**return null;}private void addEntry(int hash, K key, V value, int index) {modCount++;Entry<?,?> tab[] = table;if (count >= threshold) {// Rehash the table if the threshold is exceeded**rehash();**tab = table;hash = key.hashCode();index = (hash & 0x7FFFFFFF) % tab.length;}// Creates the new entry.@SuppressWarnings("unchecked")Entry<K,V> e = (Entry<K,V>) tab[index];tab[index] = new Entry<>(hash, key, value, e);count++;}protected void rehash() {int oldCapacity = table.length;Entry<?,?>[] oldMap = table;// overflow-conscious code**int newCapacity = (oldCapacity << 1) + 1;**if (newCapacity - MAX_ARRAY_SIZE > 0) { // private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;if (oldCapacity == MAX_ARRAY_SIZE)// Keep running with MAX_ARRAY_SIZE bucketsreturn;newCapacity = MAX_ARRAY_SIZE;}Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];modCount++;threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);table = newMap;for (int i = oldCapacity ; i-- > 0 ;) {for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {Entry<K,V> e = old;old = old.next;int index = (e.hash & 0x7FFFFFFF) % newCapacity;e.next = (Entry<K,V>)newMap[index];newMap[index] = e;}}}
(1)遍历方式
① 遍历所有 Key(keys() 或 keySet())
// 使用 Enumeration(旧版方式)
Enumeration<String> keys = table.keys();
while (keys.hasMoreElements()) {String key = keys.nextElement();System.out.println(key + ": " + table.get(key));
}// 使用 keySet()(推荐)
for (String key : table.keySet()) {System.out.println(key + ": " + table.get(key));
}
② 遍历所有 Value(elements() 或 values())
// 使用 Enumeration
Enumeration<Integer> values = table.elements();
while (values.hasMoreElements()) {System.out.println(values.nextElement());
}// 使用 values()
for (Integer value : table.values()) {System.out.println(value);
}
③ 遍历键值对(entrySet())
for (Map.Entry<String, Integer> entry : table.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue());
}
(2)线程安全实现
Hashtable 通过 synchronized 修饰所有方法实现线程安全,但性能较低,效率较低:
public synchronized V put(K key, V value) { ... }
public synchronized V get(Object key) { ... }
public synchronized V remove(Object key) { ... }
问题:
- 锁粒度大:整个表加锁,并发度低
- 过时设计:现代 Java 推荐使用
ConcurrentHashMap
| 对比项 | Hashtable | HashMap | ConcurrentHashMap |
|---|---|---|---|
| 线程安全 | 是(方法同步) | 否 | 是(分段锁/CAS) |
null 支持 | 不允许 | 允许 | 不允许 |
| 性能 | 低(全局锁) | 高 | 中等(分段锁优化) |
| 初始容量 | 11 | 16 | 16 |
| 推荐场景 | 遗留代码兼容 | 单线程环境 | 高并发环境 |
(3) 为什么 Hashtable 被淘汰?
- 性能差:全局锁导致并发效率低。
- 功能局限:不支持
null键值,缺乏现代Map的高级方法(如computeIfAbsent)。 - 替代方案:
- 单线程 →
HashMap - 多线程 →
ConcurrentHashMap
- 单线程 →
Properties类
Properties 是 Java 中用于管理键值对配置文件的特殊类,继承自 Hashtable<Object, Object>,专门用于处理 .properties 文件(如数据库配置、系统参数等)。它支持从文件/流中加载配置,并提供了便捷的读写方法。
-
继承关系:
java.lang.Object→ java.util.Dictionary<K,V>→ java.util.Hashtable<Object,Object>→ java.util.Properties -
核心功能:
- 管理键值对格式的配置(如
key=value)。 - 支持从
.properties文件或输入流中加载配置。 - 支持将配置保存到文件或输出流。
- 支持 Unicode 转义字符(如
\\\\u4e2d表示中文“中”)。
- 管理键值对格式的配置(如
| 特性 | 说明 |
|---|---|
| 键值对存储 | 键和值均为 String 类型 |
| 继承自 Hashtable | 线程安全(方法用 synchronized 修饰) |
| 支持文件IO | 可通过 load() 和 store() 读写文件 |
| 支持默认值 | 可通过构造方法传入默认 Properties 对象 |
| 编码规范 | 默认使用 ISO-8859-1(Latin-1)编码,但支持 Unicode 转义 |
不允许 null | Key 和 Value 均不能为 null(会抛出 NullPointerException) |
| 构造方法 | 说明 |
|---|---|
Properties() | 创建空 Properties 对象 |
Properties(Properties defaults) | 指定默认 Properties(查询时若 key 不存在,返回默认值) |
示例:
Properties props = new Properties(); // 空配置
Properties defaults = new Properties();
defaults.setProperty("user", "guest"); // 默认值
Properties propsWithDefaults = new Properties(defaults);
(1)额外常用方法
(1) 设置/获取属性
| 方法 | 说明 |
|---|---|
String getProperty(String key) | 获取属性值(若 key 不存在,返回 null 或默认值) |
String getProperty(String key, String defaultValue) | 获取属性值,若 key 不存在则返回 defaultValue |
Object setProperty(String key, String value) | 设置属性(键值均为 String) |
示例:
props.setProperty("db.url", "jdbc:mysql://localhost:3306/test");
props.setProperty("db.user", "admin");String url = props.getProperty("db.url"); // "jdbc:mysql://localhost:3306/test"
String password = props.getProperty("db.password", "123456"); // 默认值 "123456"
(2) 从文件/流加载配置
| 方法 | 说明 |
|---|---|
void load(InputStream in) | 从输入流加载配置(.properties 文件) |
void load(Reader reader) | 从字符流加载配置(支持指定编码) |
示例(加载 config.properties 文件):
try (InputStream input = new FileInputStream("config.properties")) {props.load(input); // 加载文件
} catch (IOException e) {e.printStackTrace();
}
(3) 保存配置到文件/流
| 方法 | 说明 |
|---|---|
void store(OutputStream out, String comments) | 保存到输出流(comments 为文件头注释) |
void store(Writer writer, String comments) | 保存到字符流(支持指定编码) |
示例(保存到文件):
try (OutputStream output = new FileOutputStream("config.properties")) {props.store(output, "Database Configuration"); // 保存并添加注释
} catch (IOException e) {e.printStackTrace();
}
(4) 遍历属性
| 方法 | 说明 |
|---|---|
Enumeration<?> propertyNames() | 返回所有键的枚举 |
Set<String> stringPropertyNames() | 返回所有键的集合(推荐) |
示例:
for (String key : props.stringPropertyNames()) {String value = props.getProperty(key);System.out.println(key + " = " + value);
}
(2)Properties 文件格式
.properties 文件示例:
# 数据库配置(注释以 # 或 ! 开头)
db.url = jdbc:mysql://localhost:3306/test
db.user = admin
db.password = 123456# 支持 Unicode 转义
message = \\\\u4e2d\\\\u6587 # 表示 "中文
语法规则:
-
键值对用
=或:分隔(如key=value或key:value)。 -
支持
#或!开头的注释。 -
值中的空格会自动保留(如
key = hello world)。 -
支持多行值(用
\\\\续行):multi.line = This is a \\\\long value.
TreeMap类
TreeMap 是 Java 集合框架中的一个 基于红黑树(Red-Black Tree) 的 Map 实现类,它保证键值对按照 键(Key)的自然顺序 或 自定义比较器(Comparator) 排序,并提供高效的查找、插入和删除操作(时间复杂度 O(log n))。
-
继承关系:
java.lang.Object→ java.util.AbstractMap<K,V>→ java.util.TreeMap<K,V> -
实现接口:
Map<K,V>(键值对存储)NavigableMap<K,V>(支持导航方法,如ceilingKey(),floorKey())SortedMap<K,V>(支持排序)Cloneable(可克隆)Serializable(可序列化)
-
底层数据结构:
- 红黑树(自平衡二叉搜索树),保证键有序且操作高效。
| 特性 | 说明 |
|---|---|
| 键排序 | 默认按自然顺序(Comparable)或自定义 Comparator 排序 |
| 键唯一性 | 不允许重复 Key(依赖 compareTo() 或 Comparator) |
不允许 null Key | 会抛出 NullPointerException(除非自定义 Comparator 支持 null) |
| 高效操作 | 查找、插入、删除的时间复杂度为 O(log n) |
| 非线程安全 | 多线程环境下需要同步控制 |
| 构造方法 | 说明 |
|---|---|
TreeMap() | 默认构造,按 Key 的自然顺序排序(需实现 Comparable) |
TreeMap(Comparator<? super K> comparator) | 指定自定义排序规则 |
TreeMap(Map<? extends K, ? extends V> m) | 从另一个 Map 初始化,按 Key 的自然顺序排序 |
TreeMap(SortedMap<K, ? extends V> m) | 从另一个 SortedMap 初始化,继承其排序规则 |
示例:
// 1. 自然排序(Key 需实现 Comparable)
TreeMap<String, Integer> map1 = new TreeMap<>();
map1.put("Java", 1);
map1.put("Python", 2);
System.out.println(map1); // 输出 {Java=1, Python=2}(字典序)// 2. 自定义排序(按 Key 长度)
TreeMap<String, Integer> map2 = new TreeMap<>((a, b) -> a.length() - b.length());
map2.put("C++", 3);
map2.put("Go", 4);
System.out.println(map2); // 输出 {Go=4, C++=3}(按长度排序)// 3. 从 Map 初始化
Map<String, Integer> hashMap = new HashMap<>();
hashMap.put("Ruby", 5);
TreeMap<String, Integer> map3 = new TreeMap<>(hashMap); // 按自然顺序排序
(1) 范围查询(NavigableMap 方法)
| 方法 | 说明 |
|---|---|
SortedMap<K,V> headMap(K toKey) | 返回 Key 小于 toKey 的子集 |
SortedMap<K,V> tailMap(K fromKey) | 返回 Key 大于等于 fromKey 的子集 |
SortedMap<K,V> subMap(K fromKey, K toKey) | 返回 [fromKey, toKey) 的子集 |
K ceilingKey(K key) | 返回大于等于 key 的最小 Key |
K floorKey(K key) | 返回小于等于 key 的最大 Key |
示例:
TreeMap<Integer, String> map = new TreeMap<>();
map.put(1, "Java");
map.put(3, "Python");
map.put(5, "C++");
System.out.println(map.headMap(3)); // {1=Java}
System.out.println(map.tailMap(3)); // {3=Python, 5=C++}
System.out.println(map.ceilingKey(2)); // 3
System.out.println(map.floorKey(4)); // 3
(2)遍历方式(按 Key 排序顺序)
① 遍历所有 Key(keySet())
for (String key : map.keySet()) {System.out.println(key + ": " + map.get(key));
}
② 遍历所有 Value(values())
for (Integer value : map.values()) {System.out.println(value);
}
③ 遍历键值对(entrySet(),推荐)
for (Map.Entry<String, Integer> entry : map.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue());
}
④ 降序遍历(descendingMap())
for (Map.Entry<String, Integer> entry : map.descendingMap().entrySet()) {System.out.println(entry.getKey()); // 从大到小输出
}
(3)排序规则
(1) 自然排序(Comparable)
Key必须实现Comparable接口,重写compareTo()方法。- 示例:
String、Integer等已实现Comparable。
class Student implements Comparable<Student> {String name;int age;@Overridepublic int compareTo(Student other) {return this.age - other.age; // 按年龄排序}
}TreeMap<Student, String> map = new TreeMap<>();
map.put(new Student("Alice", 20), "A");
map.put(new Student("Bob", 18), "B");
// 输出顺序:Bob(18) → Alice(20)
(2) 自定义排序(Comparator)
- 通过构造方法传入
Comparator,覆盖自然排序规则。 - 示例:按
Key的长度排序。
TreeMap<String, Integer> map = new TreeMap<>((a, b) -> a.length() - b.length());
map.put("C++", 3);
map.put("Go", 4);
// 输出顺序:Go → C++
(4)线程安全问题
TreeMap 不是线程安全的,多线程环境下需要同步控制:
解决方案:
-
使用
Collections.synchronizedSortedMap:SortedMap<String, Integer> syncMap = Collections.synchronizedSortedMap(new TreeMap<>()); -
手动加锁:
synchronized (map) {map.put("Java", 1); } -
使用并发集合(如
ConcurrentSkipListMap):NavigableMap<String, Integer> concurrentMap = new ConcurrentSkipListMap<>();
TreeMap vs. HashMap vs. LinkedHashMap
| 对比项 | TreeMap | HashMap | LinkedHashMap |
|---|---|---|---|
| 底层结构 | 红黑树 | 哈希表 | 哈希表 + 双向链表 |
| 顺序性 | Key 排序 | 无序 | 插入顺序/访问顺序 |
null Key | 不允许 | 允许 | 允许 |
| 时间复杂度 | O(log n) | O(1) | O(1) |
| 适用场景 | 需要排序的键值对 | 快速查找,不关心顺序 | 需要维护插入/访问顺序 |
六、Collections工具类
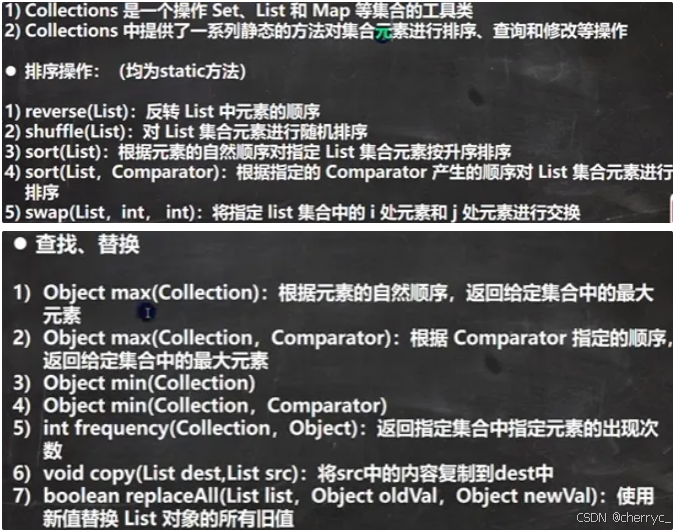
Collections 是 Java 集合框架中的一个工具类,提供了一系列静态方法用于操作或返回集合(如 List、Set、Map)。它包含排序、查找、同步控制、不可变集合等实用功能,是处理集合的瑞士军刀。
- 所属包:
java.util.Collections - 构造函数:
Collections()【private】 - 核心功能:
- 排序(
sort、reverse) - 查找(
binarySearch、max、min) - 同步控制(
synchronizedXXX) - 不可变集合(
unmodifiableXXX) - 其他工具方法(
shuffle、fill、copy等)
- 排序(
(1)常用方法分类详解
1 排序操作
| 方法 | 说明 |
|---|---|
void sort(List<T> list) | 对 List 按自然顺序升序排序 |
void sort(List<T> list, Comparator<? super T> c) | 按自定义 Comparator 排序 |
void reverse(List<?> list) | 反转 List 中元素的顺序 |
void shuffle(List<?> list) | 随机打乱 List(洗牌算法) |
示例:
List<Integer> numbers = Arrays.asList(3, 1, 4, 2);Collections.sort(numbers); // [1, 2, 3, 4]
Collections.reverse(numbers); // [4, 3, 2, 1]
Collections.shuffle(numbers); // 随机打乱,如 [2, 4, 1, 3]
2 查找操作
| 方法 | 说明 |
|---|---|
int binarySearch(List<? extends Comparable<? super T>> list, T key) | 二分查找(需先排序) |
T max(Collection<? extends T> coll) | 返回集合中的最大值(自然顺序) |
T min(Collection<? extends T> coll) | 返回集合中的最小值(自然顺序) |
int frequency(Collection<?> c, Object o) | 返回元素在集合中的出现次数 |
示例:
List<Integer> sortedList = Arrays.asList(1, 2, 3, 4);int index = Collections.binarySearch(sortedList, 3); // 2
int max = Collections.max(sortedList); // 4
int freq = Collections.frequency(sortedList, 2); // 1
3 同步控制(线程安全包装)
| 方法 | 说明 |
|---|---|
List<T> synchronizedList(List<T> list) | 返回线程安全的 List |
Set<T> synchronizedSet(Set<T> s) | 返回线程安全的 Set |
Map<K,V> synchronizedMap(Map<K,V> m) | 返回线程安全的 Map |
示例:
List<String> unsafeList = new ArrayList<>();
List<String> safeList = Collections.synchronizedList(unsafeList);// 多线程操作 safeList 是安全的
synchronized (safeList) { // 仍需手动同步遍历操作for (String item : safeList) {System.out.println(item);}
}
4 不可变集合(只读包装)
| 方法 | 说明 |
|---|---|
List<T> unmodifiableList(List<? extends T> list) | 返回不可修改的 List |
Set<T> unmodifiableSet(Set<? extends T> s) | 返回不可修改的 Set |
Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m) | 返回不可修改的 Map |
示例:
List<String> mutableList = new ArrayList<>(Arrays.asList("A", "B"));
List<String> unmodifiableList = Collections.unmodifiableList(mutableList);unmodifiableList.add("C"); // 抛出 UnsupportedOperationException
5 其他实用方法
| 方法 | 说明 |
|---|---|
void copy(List<? super T> dest, List<? extends T> src) | 将 src 复制到 dest,需要注意不能越界 |
void fill(List<? super T> list, T obj) | 用 obj 填充 List 的所有元素 |
boolean replaceAll(List<T> list, T oldVal, T newVal) | 替换所有匹配元素 |
void swap(List<?> list, int i, int j) | 交换 List 中两个位置的元素 |
示例:
List<String> src = Arrays.asList("A", "B", "C");
List<String> dest = new ArrayList<>(src.size());Collections.copy(dest, src); // dest = ["A", "B", "C"]
Collections.fill(dest, "X"); // dest = ["X", "X", "X"]
Collections.swap(dest, 0, 2); // dest = ["X", "X", "X"] → ["X", "X", "X"](交换无效,因为元素相同)
(2)实际应用场景
1 排序与查找
List<Student> students = Arrays.asList(new Student("Alice", 90),new Student("Bob", 80)
);// 按分数降序排序
Collections.sort(students, (s1, s2) -> s2.getScore() - s1.getScore());// 查找分数为 80 的学生
int index = Collections.binarySearch(students,new Student("", 80),(s1, s2) -> s1.getScore() - s2.getScore()
);
2 线程安全集合
Map<String, Integer> unsafeMap = new HashMap<>();
Map<String, Integer> safeMap = Collections.synchronizedMap(unsafeMap);// 多线程操作 safeMap
synchronized (safeMap) {for (Map.Entry<String, Integer> entry : safeMap.entrySet()) {System.out.println(entry.getKey() + ": " + entry.getValue());}
}
3 不可变配置
Map<String, String> config = new HashMap<>();
config.put("host", "localhost");
config.put("port", "8080");Map<String, String> unmodifiableConfig = Collections.unmodifiableMap(config);
unmodifiableConfig.put("timeout", "30"); // 抛出 UnsupportedOperationException
(3)注意事项
-
同步集合的遍历仍需手动加锁:
synchronized (safeList) {for (Object item : safeList) { ... } } -
不可变集合是视图:底层原集合修改会影响不可变视图。
List<String> original = new ArrayList<>(); original.add("A"); List<String> unmodifiable = Collections.unmodifiableList(original); original.add("B"); // unmodifiable 也会变为 ["A", "B"] -
binarySearch需先排序:否则结果未定义。