AI 图像生成技术发展时间脉络:从 GAN 到多模态大模型的知名模型概略解析
以下是按时间顺序排列的图像生成模型及介绍:
-
生成对抗网络(GAN,2014年)
2014年由伊恩·古德费洛等人提出,通过生成器与判别器相互对抗的训练框架,为AI生成图像奠定技术根基,是图像生成领域的开创性模型。

-
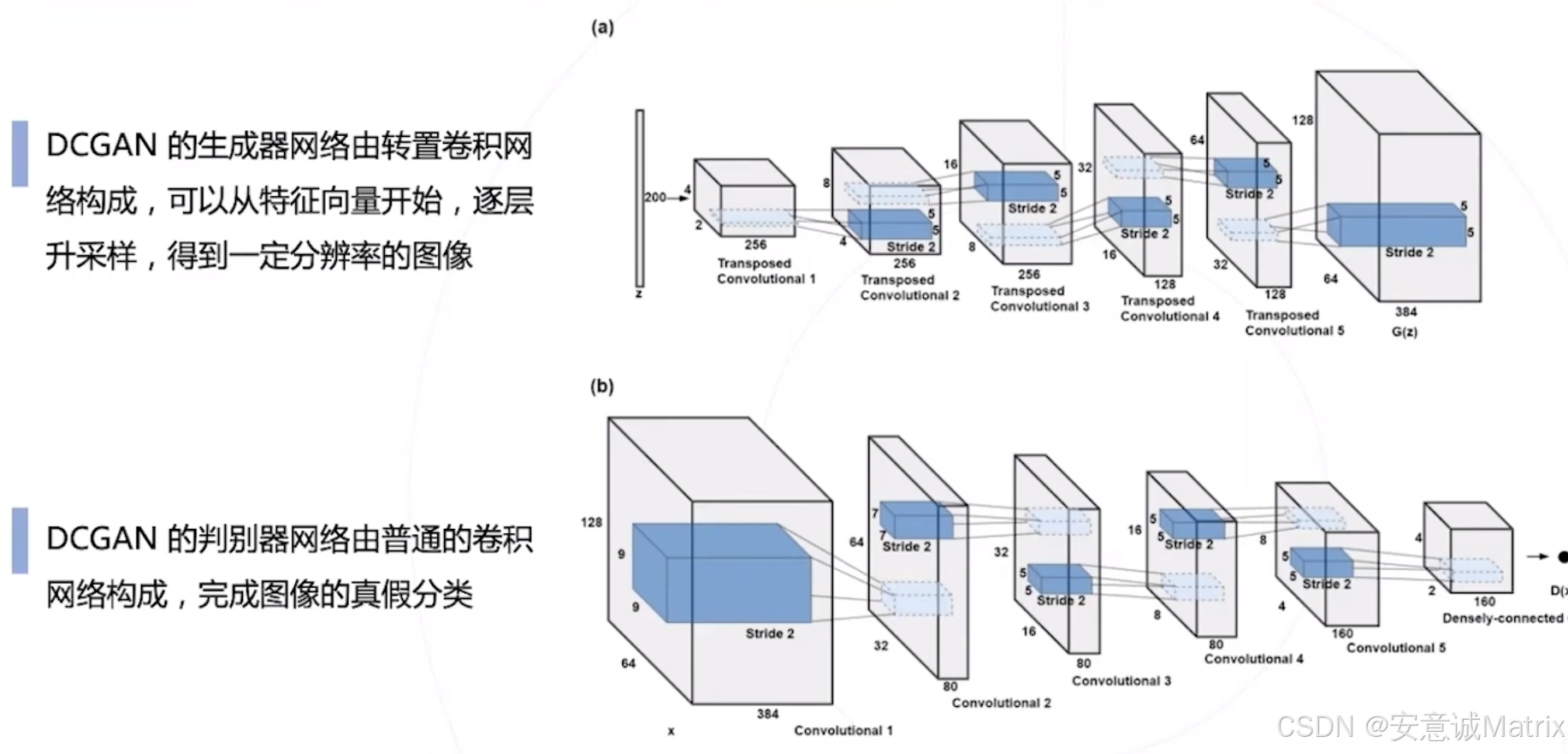
DCGAN(2016年)
首次将卷积神经网络引入GAN架构,提升生成图像质量与训练稳定性,其转置卷积、Batch Normalization等设计范式成为后续GAN模型的通用标准。
-
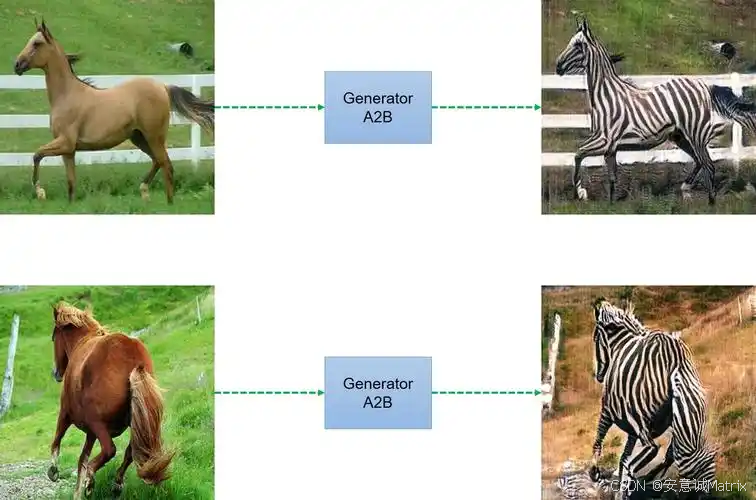
CycleGAN(2017年)
无需成对数据即可实现跨域图像转换(如“马→斑马”“照片→油画”),通过循环一致性损失保证转换可逆性,在风格迁移、多领域图像转换中应用广泛。
-
StyleGAN(2018年)
引入“样式混合”“截断技巧”,实现对生成图像特征(发型、肤色等)的精细控制,生成的人脸图像高度逼真,为后续StyleGAN系列奠定基础。 -
StyleGAN2(2019年)
通过“非饱和损失”“路径长度正则化”解决GAN“模式崩溃”问题,生成图像细节更丰富,是高分辨率人脸生成的标杆模型。

-
DALL·E(OpenAI,2021年1月)
OpenAI推出的早期文本-图像生成模型,可根据趣味文本描述(如“牛油果穿西装办公”)生成对应图像,开启多模态图像生成新方向。

-
GLIDE(2021年)
OpenAI开发的文本引导扩散模型,实现高质量文本到图像生成,其“无分类器引导”技术被Stable Diffusion等后续模型沿用,是DALL·E 2的核心组成部分。 -
StyleGAN3(2021年)
消除生成图像伪影,支持1024×1024高分辨率生成,在艺术创作、工业设计(虚拟角色、产品原型)等领域应用广泛。 -
MidJourney(2022年3月)
闭源商业模型,以艺术风格生成著称,生成图像在创意性、色彩表现上极具特色,是设计师、艺术家群体的主流创作工具。 -
文心一格(2022年8月)
百度推出的中文原生文本-图像生成模型,支持中文提示词(如“水墨江南水乡”),在中文语境的创意生成、商业设计中优势明显。 -
Stable Diffusion(2022年8月)
开源扩散模型,凭借强大的社区生态和自定义能力,成为文本-图像生成领域的主流模型,支持风格、分辨率的高度定制。 -
Imagen(2022年)
Google的文本-图像扩散模型,结合大规模语言模型T5-XXL和多阶段超分辨率网络,对复杂文本的理解与图像生成质量行业顶尖。 -
DALL·E 2(2022年)
OpenAI第二代文本-图像模型,结合CLIP实现图文语义精准对齐,支持“图像编辑”功能(如“给场景添加独角兽”),生成创意性进一步突破。 -
通义万相(2023年4月)
阿里云推出的文本-图像生成模型,支持中文提示词,在电商商品图、营销素材等商业场景应用广泛,具备风格迁移、多图联动功能。 -
PLAYGROUND V2(2023年12月)
擅长生成电影级、艺术装置类复杂场景,在创意性和视觉叙事性上表现突出,受创意从业者关注。 -
豆包大模型(2024年5月)
字节跳动推出的多模态大模型,具备文本-图像-知识联动生成能力,可结合文本、知识背景生成兼具创意与信息性的图像。 -
Stable Diffusion 3(2024年)
Stability AI第三代开源模型,基于“多模态扩散Transformer”架构,提升对复杂提示词的理解能力,支持多分辨率生成和中文语义优化。 -
MidJourney V6(2024年)
新增“风格参考”(上传图片模仿风格)和4K分辨率输出功能,在艺术风格精细度、场景逻辑一致性上进一步突破。 -
混元DiT(2024年)
腾讯推出的中文原生扩散模型,支持中英文混合提示和中国元素生成(如“古诗词山水画卷”),全面开源且具备多轮对话优化图像的能力。 -
Gemini Pro 1.5(2024年)
Google多模态大模型,支持文本、图像、视频联合处理,可根据长文本、视频片段生成逻辑连贯的图像/视频内容,向动态内容生成延伸。 -
Sora(2024年)
OpenAI推出的视频生成模型,能根据文本描述生成长达60秒的连贯动态视频(如“松鼠在赛博朋克城市滑板”),标志生成技术向动态内容跨越。 -
FLUX(2024年8月)
2024年8月推出的模型,在图像生成的技术创新性和创意表现上有显著突破,引发行业关注。 -
Fooocus(2025年)
基于Stable Diffusion优化的开源工具,支持一键生成高质量图像,仅需4GB显存即可运行,大幅降低AI图像生成的硬件门槛。 -
Step1X-Edit(2025年)
开源多模态模型,支持“图像+指令”联合输入实现像素级编辑(如“替换背景天空为夕阳”),指令跟随精度达闭源模型的92%。