长沙企业网站建设收费施工企业管理制度
本文基于实际经验,针对 python 环境下本地 html 文件的读取、解析,特别是编码查看、报错等问题进行了梳理和总结。
前言
python 环境下,本地 html 文件的读取,最常用的是其内置文件操作函数 open()。
open() 函数基础语法格式如下:
open(filename[,mode[,encoding]])参数说明:
filename:必须参数,要创建或打开文件的文件名或者文件路径。
mode:可选参数,用以指定文件打开模式。默认为'r'-只读模式,常见有'w'-写入、'a'-追加、'b'-二进制等。
encoding:可选参数,用以指定编码格式。
重点注意事项:使用 open() 函数打开文件时,如果没有明确指定编码方式,默认情况下使用的编码格式则依赖于本机操作系统及 python 版本。这也是后续读取本地 html 文件编码报错的核心原因之一。
本地 html 读取及编码导致报错的解决方法
(一)本地 html 文件编码查看方法
在了解 open() 函数的基础用法后,以下将用2个示例文件演示如何正确读取本地 html 文件。
示例1:test.html,已知编码为 utf-8。
示例2:Document.html,已知编码为 windows-1252。
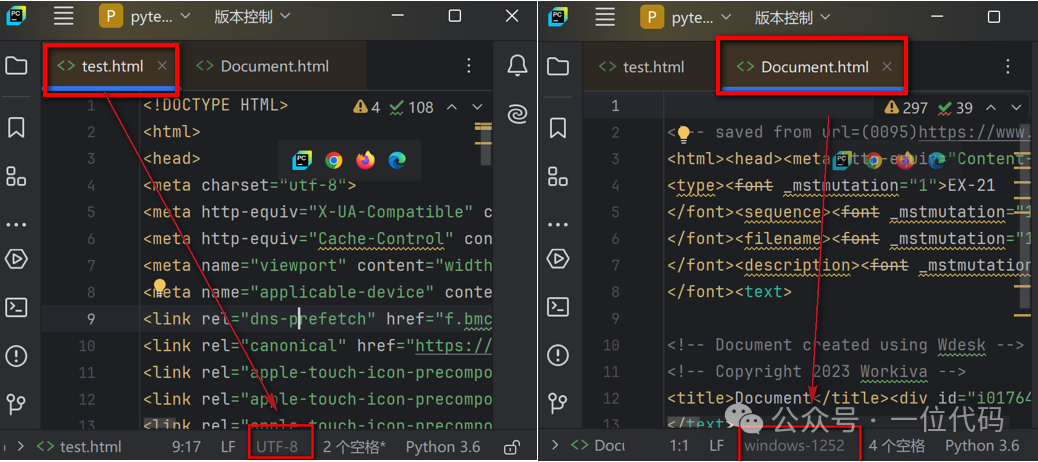
查看本地 html 文件编码的方式较多,比如可以使用 Notepad++、PyCharm直接打开 html 文件,其右下角就会直接显示编码。
如示例文件:test.html(utf-8)、Document.html(windows-1252),使用PyCharm查看编码结果如下图:
(二)本地 html 读取方法及常见报错解决方案
错误示例1:不指定编码,直接读取 html 文件(test.html)导致读取失败。
# 本地html文件完整路径
file_path = r'C:\Users\Administrator\Desktop\test.html'
# 读取html文件,未指定编码格式
with open(file_path) as f:res = f.read()print("返回结果类型:",type(res))print("返回结果为:",res)执行后,报错为:UnicodeDecodeError: 'gbk' codec can't decode byte 0xae in position 875: illegal multibyte sequence
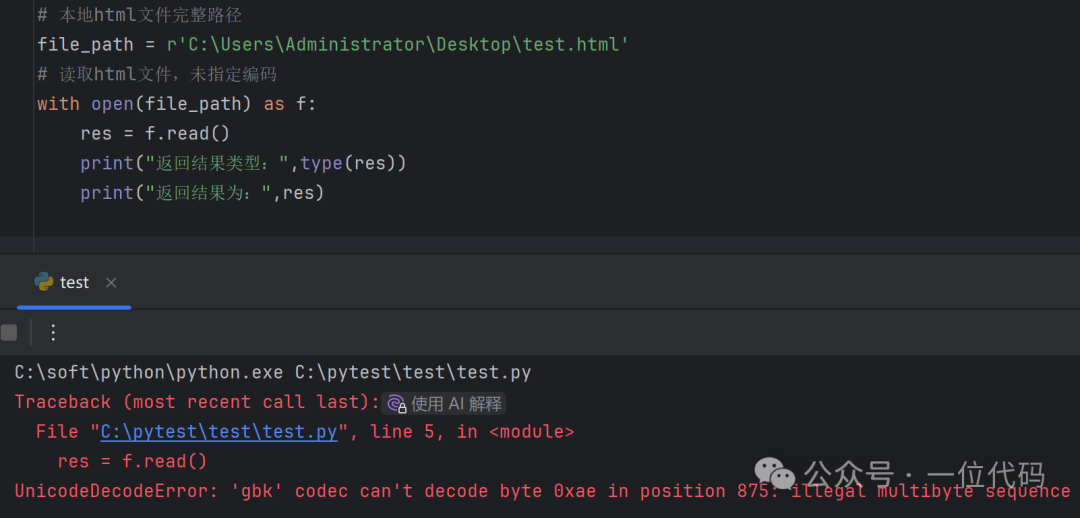
原因:前文在简述 open() 函数用法时提到,如果不指定文件打开编码 encoding 参数,默认情况下使用的编码格式则依赖于本机操作系统及 python 版本。从报错提示看,本文作者使用的环境下,默认编码为 gbk,所以在打开以 utf-8 编码的 test.html 时,出现报错。
解决办法有二(重点)
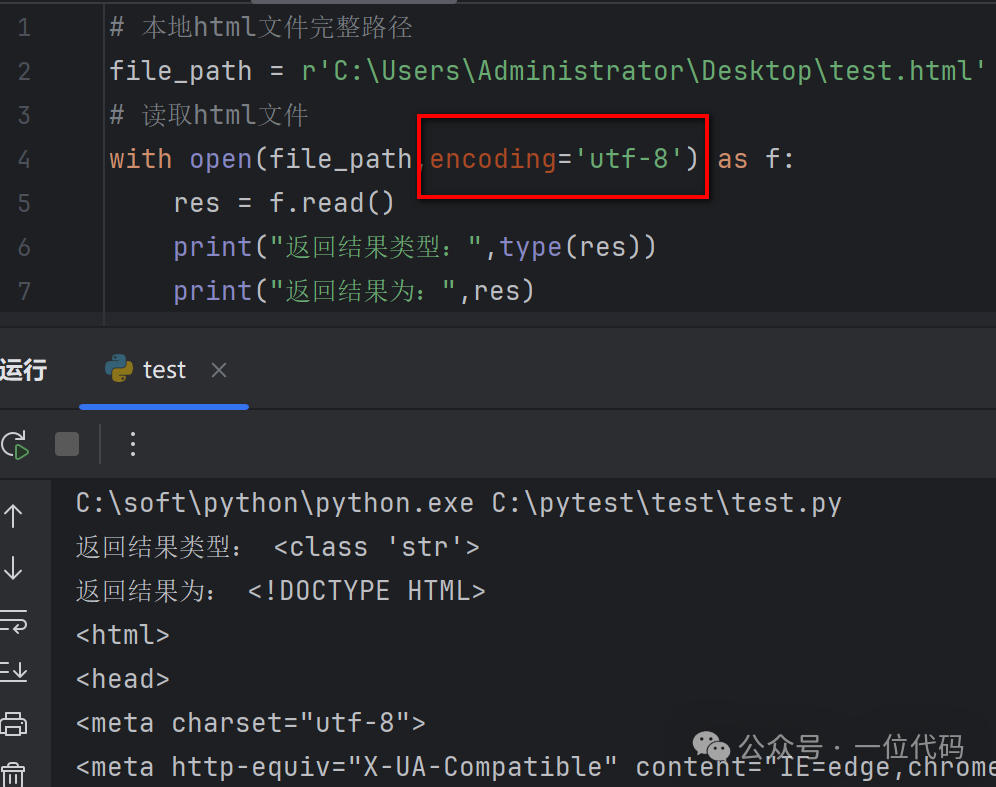
一是:指定正确的编码,以上即是使用 test.html 本身的 utf-8 编码去打开它。
# 本地html文件完整路径
file_path = r'C:\Users\Administrator\Desktop\test.html'
# 读取html文件
with open(file_path,encoding='utf-8') as f: res = f.read() print("返回结果类型:",type(res)) print("返回结果为:",res)执行后,test.html成功读取,如下图:
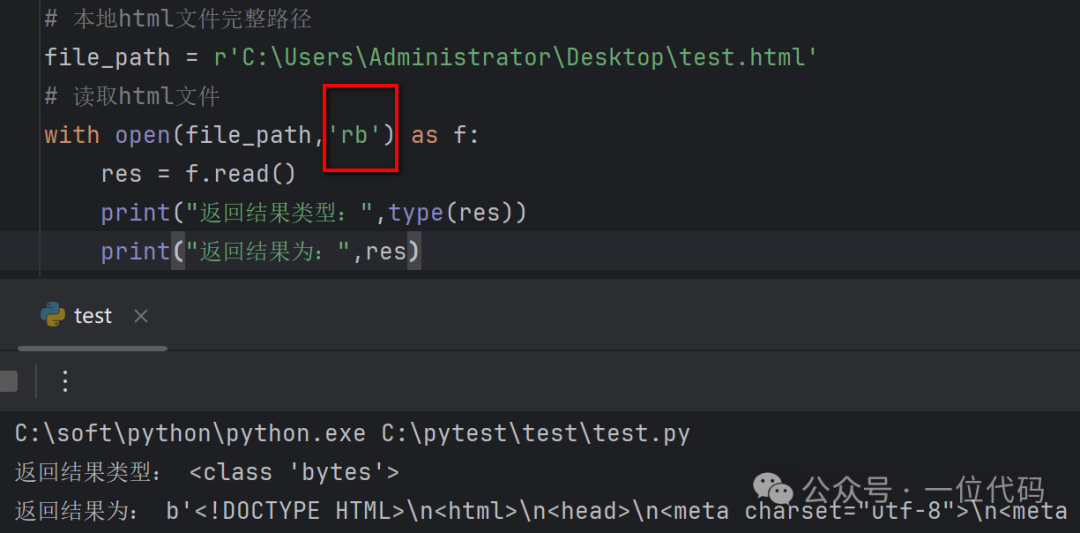
二是:抛开本地 html 文件编码格式不管,直接采用 open() 函数的二进制文件读取模式 'rb',打开本地 html 文件。
如,直接以二进制模式打开 test.html(utf-8),读取成功如下图:
又如,直接以二进制模式打开 Document.html(windows-1252),读取成功如下图。
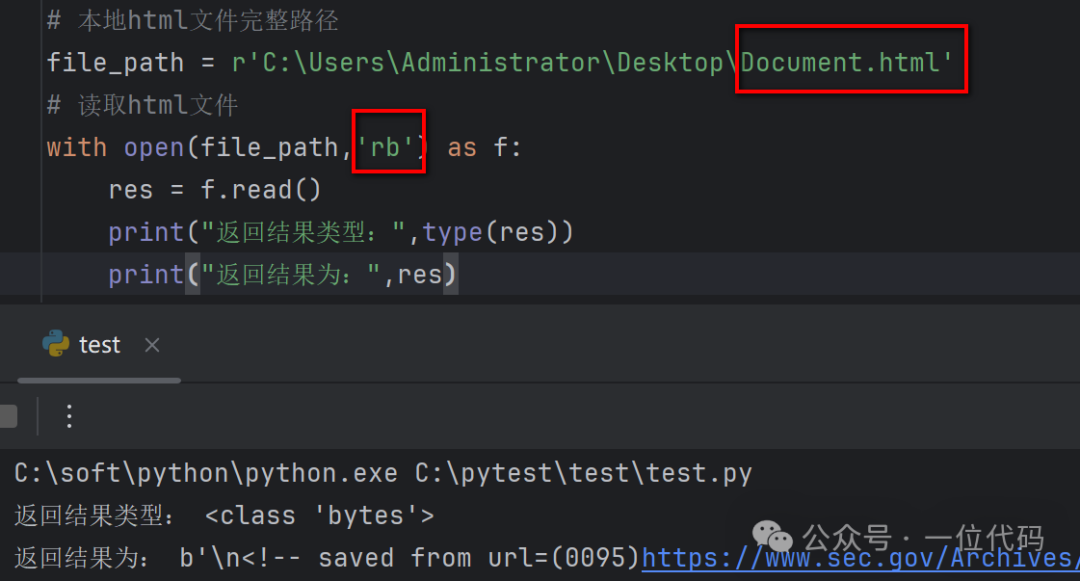
从以上两个例子可知,不论本地 html 文件为何种编码格式,都可以直接采用二进制模式打开。好处就是,在批量处理时,不必先去查看每一个 html 文件的编码;坏处就是,返回值是二进制格式,在解析提取时需要解码。
注:使用 decode() 将返回的二进制格式结果转为字符串方法如下。
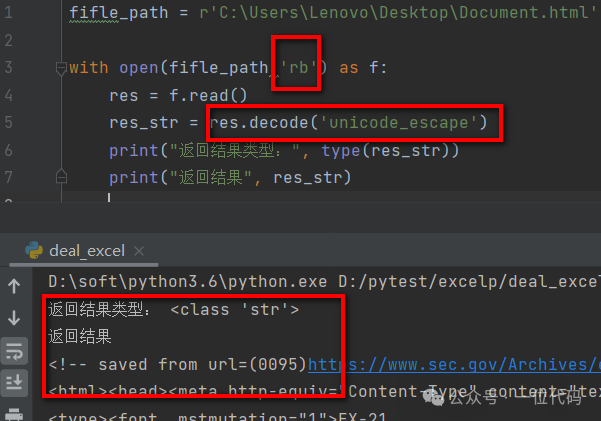
读取后的 html 解析方式
从本地读取 html 后的解析方式,跟爬虫解析网页的方式一样,可以采用 xpath、正则表达式等去解析所需要的内容。
以上就是基于 python 环境下读取本地 html 文件的方式,其中着重对读取时的编码问题进行了阐述,可供参考。
-end-