Context Engineering概述

上下文工程
Tobi Lütke(托比・卢克)
1980 年(另有 1981 年出生的记载)出生于西德科布伦茨,拥有德国和加拿大双重国籍,是全球知名电商平台 Shopify 的联合创始人兼 CEO,同时也是技术创新者、赛车手和投资人。
Andrej Karpathy(安德烈・卡帕西)
1986 年 10 月出生,斯洛文尼亚裔加拿大籍,是神经网络与计算机视觉专家,在人工智能领域的学术研究、产业应用和教育普及均有深远影响,被马斯克视为 “全球顶级 AI 领袖” 人选之一。

People associate prompts with short task descriptions you’d give an LLM in your day-to-day use.
When in every industrial-strength LLM app, context engineering is the delicate art and science of filling the context window with just the right information for the next step.
Science because doing this right involves task descriptions and explanations, few shot examples, RAG, related (possibly multimodal) data, tools, state and history, compacting… Too little or of the wrong form and the LLM doesn’t have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down. Doing this well is highly non-trivial.
And art because of the guiding intuition around LLM psychology of people spirits.
人们往往将提示词与日常使用大语言模型(LLM)时给出的简短任务描述联系起来。
但在每一个工业级的 LLM 应用中,上下文工程是一门精妙的艺术与科学,它致力于为上下文窗口填充恰好能支撑下一步操作的信息。
说它是科学,是因为要做好这一点,需要涵盖任务描述与解释、少量示例(few shot examples)、检索增强生成(RAG)、相关(可能是多模态的)数据、工具、状态与历史、信息压缩等多个方面。如果信息过少或形式不当,LLM 就没有合适的上下文来实现最佳性能;如果信息过多或过于无关,LLM 的使用成本可能会上升,性能也可能下降。做好这一点绝非易事。
说它是艺术,则是因为它依赖于人们对 LLM “心理”(类人智能特质)的直觉性把握。
delicate ˈdelɪkət 柔和的,清淡的;虚弱的,纤弱的;脆弱的,易碎的;小巧玲珑的,纤细的;微妙的,棘手的;精致的,精巧的;灵巧的,熟练的;(仪器)灵敏的
On top of context engineering itself, an LLM app has to:
- break up problems just right into control flows
- pack the context windows just right
- dispatch calls to LLMs of the right kind and capability
- handle generation-verification UIUX flows
- a lot more - guardrails, security, evals, parallelism, prefetching, …
除了上下文工程本身,一个 LLM 应用还必须: - 将问题恰当地拆解为控制流
- 恰当地打包上下文窗口
- 向具备合适类型和能力的 LLM 发送调用请求
- 处理生成 - 验证的用户界面与用户体验(UI/UX)流程
- 还有更多 —— 比如护栏(guardrails)、安全性、评估(evals)、并行处理、预取(prefetching)等等
So context engineering is just one small piece of an emerging thick layer of non-trivial software that coordinates individual LLM calls (and a lot more) into full LLM apps. The term “ChatGPT wrapper” is tired and really, really wrong.
因此,上下文工程只是新兴的、复杂的软件层中的一小部分,这一软件层将单个 LLM 调用(以及更多其他元素)协调成完整的 LLM 应用。“ChatGPT 包装器” 这个说法已经过时了,而且真的非常错误。
tobi lutke @tobi · Jun 19, I really like the term “context engineering” over prompt engineering.It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.
tobi lutke @tobi・6 月 19 日,我真的更喜欢 “上下文工程” 这个术语,而非 “提示词工程”。它更好地描述了核心技能:为任务提供所有必要上下文,使 LLM 能够合理地解决该任务的艺术。
plausibly plɔːzəbli 似真地
solvable sɒlvəbl 可以解决的;可以解的;可溶的
示例
下面这张图直观地体现了 “上下文工程” 在 AI 应用中的关键价值:
充足、精准的上下文是让 AI 从 “机械回应” 升级为 “智能决策” 的核心推动力
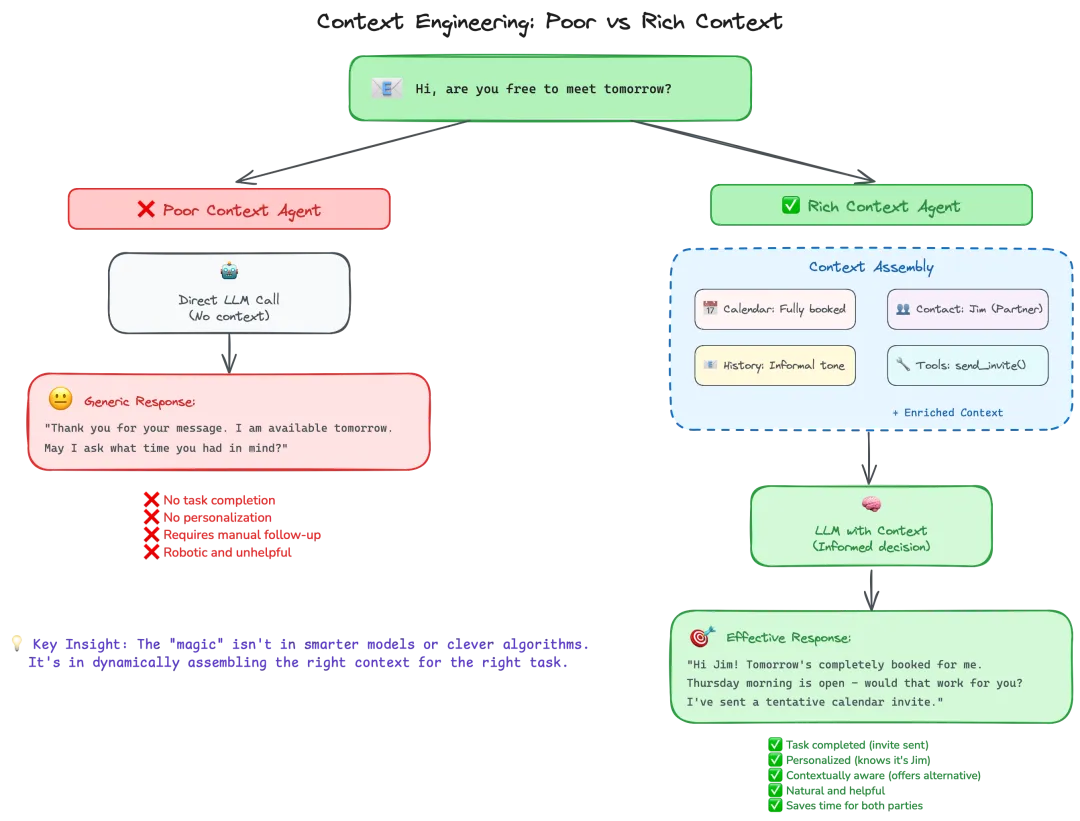
这张图展示了上下文工程中 “poor上下文智能体” 与 “rich上下文智能体” 的工作模式对比,核心是说明 “为任务动态组装(assembling)合适的上下文是 AI 有效交互的关键”:
场景触发:用户发起交互
用户发送消息 “Hi, are you free to meet tomorrow?”(询问明天是否可以见面),这是触发智能体响应的初始输入
左侧:贫乏上下文智能体(Poor Context Agent)的工作逻辑
处理方式:直接调用大语言模型(LLM),不引入任何额外上下文(如日程、联系人关系、历史交流风格等)
输出结果:生成通用化回复 “Thank you for your message. I am available tomorrow. May I ask what time you had in mind?”
问题总结:
- 无任务闭环(仅回应 availability,未解决 “约见” 的实际需求)
- 无个性化(没识别出对方身份、关系)
- 需要人工后续跟进
- 回复机械、缺乏实用性
右侧:丰富上下文智能体(Rich Context Agent)的工作逻辑
上下文组装(Context Assembly):主动聚合多维度信息,构建 “丰富上下文”,包括:
- 日程(Calendar):明天已满档
- 联系人(Contact):对方是 Jim(合作伙伴)
- 交流历史(History):沟通风格偏非正式
- 工具(Tools):可调用发送日程邀请的函数(send_invite())
- 其他 “增强上下文”(Enriched Context)
LLM 决策:大语言模型基于这些上下文做 “知情决策”(Informed decision)
输出结果:生成有效回复 “Hi Jim! Tomorrow’s completely booked for me. Thursday morning is open – would that work for you? I’ve sent a tentative calendar invite.”
价值总结:
- 任务闭环(发送了日程邀请)
- 个性化(识别并称呼 Jim)
- 上下文感知(主动提供替代时间)
- 回复自然且有帮助
- 为双方节省时间
核心洞见(Key Insight)
AI 交互的 “魔力”不在于模型多聪明或算法多巧妙,而在于为特定任务动态组装 “合适的上下文”—— 让智能体像人类一样,基于 “已知信息 + 场景背景 + 工具能力” 做决策,从而实现更自然、高效的交互
越靠后性能越差
LLM 通常被假设能够均匀地处理上下文——也就是说,模型处理第 10,000 个 token 的可靠性应该与处理第 100 个 token 的可靠性相同。然而,在实践中,这一假设并不成立。即使在简单的任务中,模型性能也会随着输入长度的变化而发生显著变化
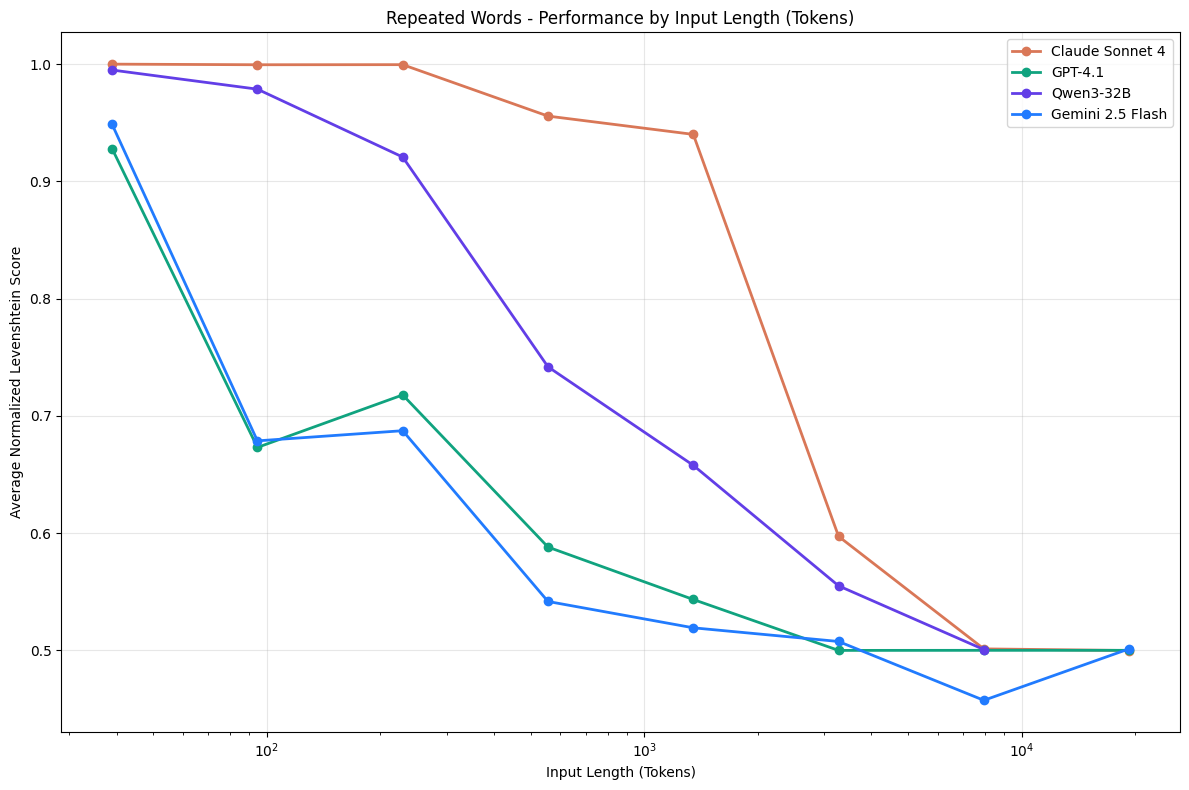
LLM 的注意力机制并非在整个输入中均匀分布,实验设计了一个受控任务,在该任务中,模型必须复制一串重复的单词序列,并在特定位置插入一个唯一的单词。Prompt 明确指示 LLM 精确重现输入文本
Simply replicate the following text, output the exact same text: apple apple apple apple apples apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple apple
即使是简单的“复制文本”任务,若关键信息(如重复单词中的“唯一词 apples”)放在输入的后半段,模型定位正确率会显著下降(一堆apple,一个apple)
上下文工程师DO