CLIP个人理解
作为学习CLIP的笔记,方便理解与复习。
1.CLIP是什么?
CLIP(Contrastive Language–Image Pre-training)是由OpenAI在2021年提出的一种革命性的多模态人工智能模型,它的核心思想是将自然语言理解和计算机视觉联系起来。
简单来说,CLIP是一个能够理解图片和文字之间关系的模型,它将图像和文本映射到同一个多模态嵌入空间,从而可以直接比较它们的相似度。
在训练CLIP时,它的输入是海量的严格对应的(图像,文本)对,举个简单的例子:
| 图像 | 文本描述 |
|---|---|
| [一张猫的图片] | “a photo of a cat” |
| [一张狗的图片] | “a photo of a dog” |
| [一辆卡车的图片] | “a photo of a truck” |
其中,每一行都代表一个(图像,文本)对,也对应一个训练数据。
它的最终输出是两个张量,以上面提到的三个训练数据为例,输出可能如下:
# 概念性代码
import torch# 假设 embed_dim (嵌入维度) 为 512# 图像嵌入张量
image_embeds = torch.tensor([# 这代表第一张图片(猫)在空间中对应的向量[0.12, -0.05, 0.88, 0.01, ..., -0.23, 0.45],# 这代表第二张图片(狗)在空间中对应的向量[0.09, -0.01, 0.91, -0.03, ..., -0.19, 0.41]# 这代表第三张图片(卡车)在空间中对应的向量[-0.46, 0.63, 0.11, 0.34, ..., 0.76, -0.56]
])
# image_embeds.shape 为 torch.Size([3, 512])
# 每个向量包含512个浮点数# 文本嵌入张量
text_embeds = torch.tensor([# 这代表第一个文本 "a photo of a cat" 在空间中对应的向量[0.11, -0.04, 0.87, 0.02, ..., -0.22, 0.44],# 这代表第二个文本 "a photo of a dog" 在空间中对应的向量[0.08, 0.00, 0.90, -0.01, ..., -0.18, 0.40],# 这代表第三个文本 "a photo of a truck" 在空间中对应的向量[-0.45, 0.62, 0.10, 0.33, ..., 0.75, -0.55]
])
# text_embeds.shape 为 torch.Size([3, 512])
# 每个向量包含512个浮点数其中,每个向量,都代表着训练数据中的图像(或文本)在这个多模态嵌入空间中的投影。
简单一点来说,CLIP的作用就是将每一个图像和文本都用一个这个嵌入空间中的向量表示了出来。
在实际使用训练好的CLIP模型时,得益于CLIP的“双塔”结构,CLIP可以单独对图像(或文本)进行推理(输出嵌入空间中的向量表示),而不强求输入的图像和文本有严格的对应关系。
PS:CLIP输出的向量的理解
个人理解,这个向量类似于一个“概念”,比如一张图,图上有“一条狗”,这是概念,一句话,话里提到了“一条狗”,这也是概念,而这个向量表示的就是这个“概念”,图和文本表示的概念越接近,这个图和文本对应的向量也就越相似。
在绝对理想的情况下,如果一串文本能够把一张图里面的内容完全表示出来,那么这个文本和这张图对应的向量就应该完全一样。
但是实际情况下,文本不可能和图像完全对应,文本可能描述有一条狗,图中可能还有一只猫,文本添加叙述了一只猫,图中可能还有一辆卡车,文本接着描述了一辆卡车,图中狗的动作、猫的毛色、卡车的载重量等等,这些都是图中存储信息和概念,用简单的文本叙述是不可能将图像描述完全的,所以上面给的例子之中,对应的图和文本,两者向量也只是相似,但不完全相同(虽然本来就是编的向量,但是道理还是这么个道理)。
2.CLIP的主要结构
根据个人对CLIP的理解,CLIP的架构可以按照以下图像表示:
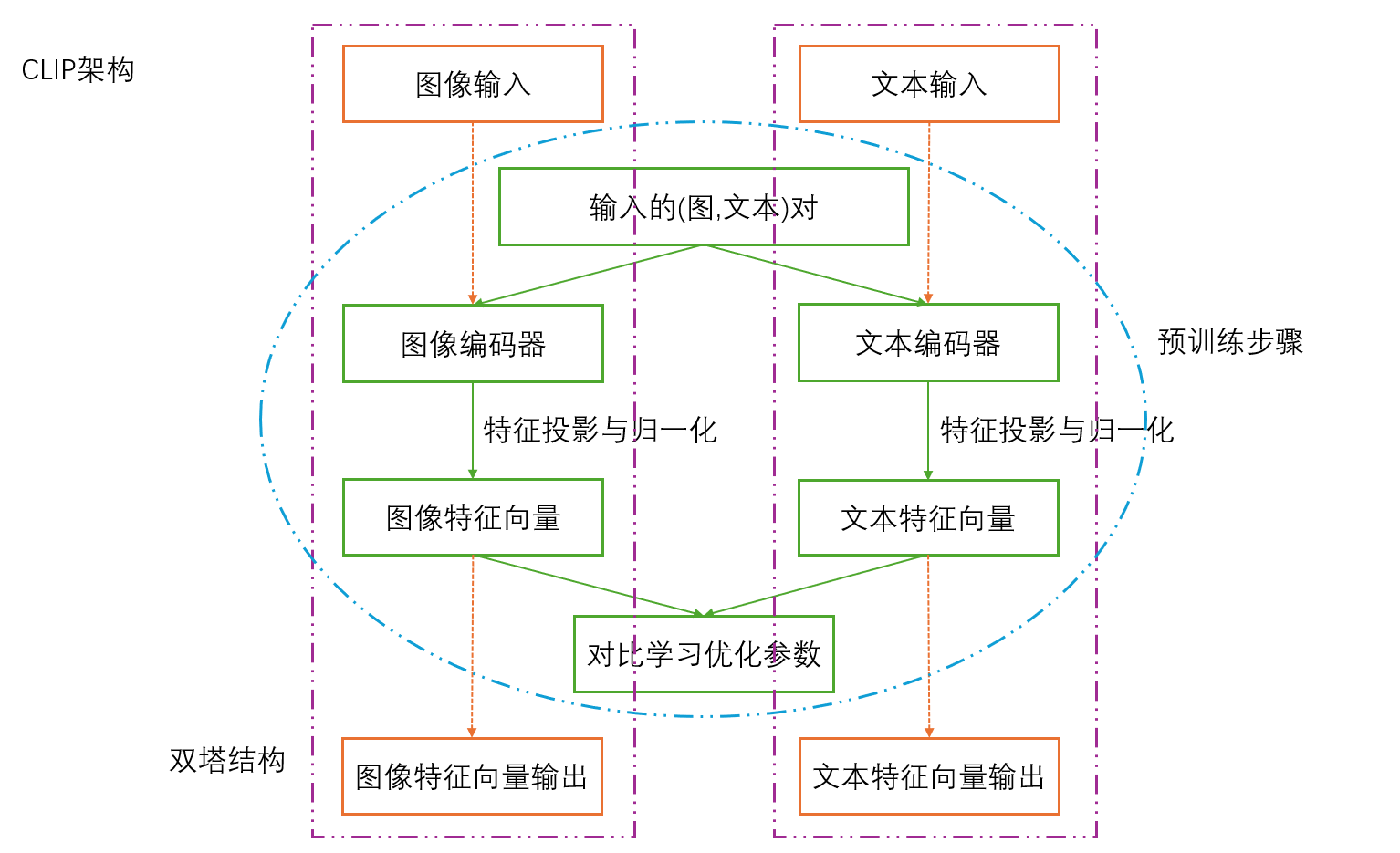
大概可以理解为CLIP包含两个模型,一个处理图像,一个处理文本,两个模型同时训练,但是训练好的模型可以分开使用。
①CLIP的预训练
1)输入
CLIP 的输入是大规模、从互联网收集的(图像,文本)对,例如 WebImageText 数据集,包含约 4 亿个 (图像,文本)对,它们一一对应,其中,图像是任意自然图像,文本则是与图像对应的自然语言描述、标题或标签。
在训练时,每次会抽取一个批次的(图像,文本)对,假设批次大小为 N,则得到 N 个正样本对:
2)编码器
图像和文本分别通过两个独立的编码器进行特征提取。
图像编码器会将前文样本对中的像素数据转换为一个代表图像的抽象视觉特征的高维特征向量,其可选择的架构包括ResNet和Vision Transformer(ViT),一般而言会选用ViT,性能相对更好(如常用的CLIP预训练模型ViT-B/32 和 ViT-L/14)。
文本编码器会将前文样本对中的文本数据转换为一个代表文本的抽象语义特征的高维特征向量,其架构基于Transformer的模型,具体是采用GPT-2的结构(仅使用解码器,带有因果注意力掩码),人话讲就是Transformer架构的一个特定变体。
需要注意的是,这两个编码器的输出虽然也是高维特征向量,但是和前文提到的CLIP输出的向量并不在同一个空间,而是分别在各自的视觉空间和语义学空间,三个空间的关系如下图所示:
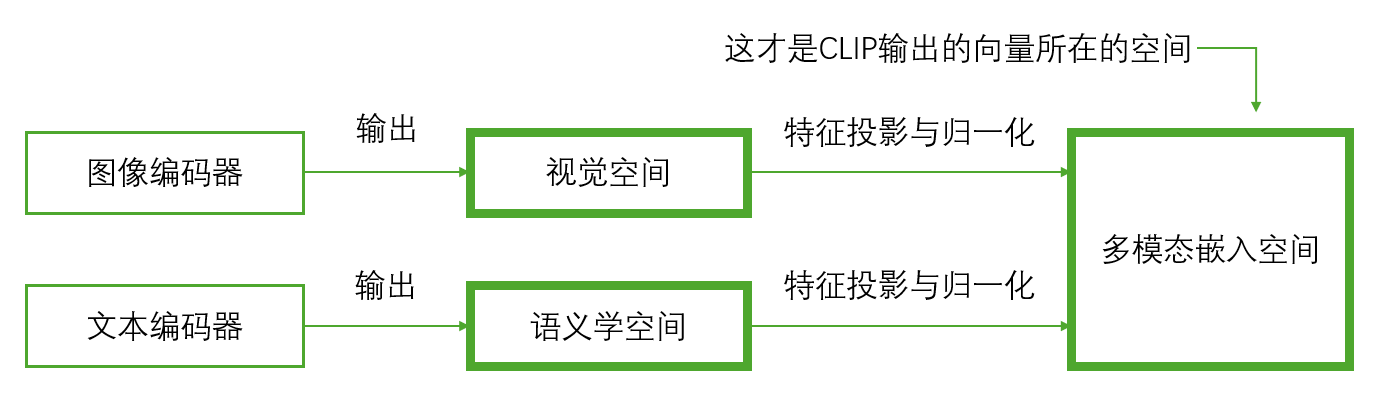
可以理解为,视觉空间里面的向量是通过视觉上的不同分辨的(也就是图片的特点),向量越相似,看起来就越像(图片信息越相似),而语义学空间里面的向量是通过语言表达的内容分辨的(也就是文本的特点),向量越相似,内容越接近(文本含义越相似),这两个空间里的向量是没有关系的,也就是说视觉空间里表示一条狗的向量,在语义学空间里可能表示一只猫,也可能表示一辆卡车,更大概率两者都不是。而多模态嵌入空间的目的,就是通过不同的特征投影与归一化,将这两个空间里的向量投影进来形成新的向量,解决两个空间里图像、文本对应不上的问题。
3)特征投影与归一化
这一步是将两个模态的特征对齐到同一个可比的空间的关键。
- 线性投影
将图像和文本编码器输出的高维向量分别通过一个独立的线性层(全连接层)映射到一个维度更低、共享的多模态嵌入空间中。 - L2归一化
对投影后的图像和文本向量分别进行 L2 归一化。这使得所有向量的模长都变为 1,其目的是将向量限制在单位球面上,防止梯度爆炸,同时让两个向量的点积就等于它们的余弦相似度,范围落到 [-1, 1] 之间。
经过此步骤,我们得到了:
- 归一化的图像特征向量集合:
- 归一化的文本特征向量集合:
它们位于同一个向量空间,可以直接进行相似度比较,方便下一步的对比学习。
4)对比学习
这也解释了为什么CLIP的两个模块要一起训练,它通过一个对称的对比损失函数来同时优化两个编码器。
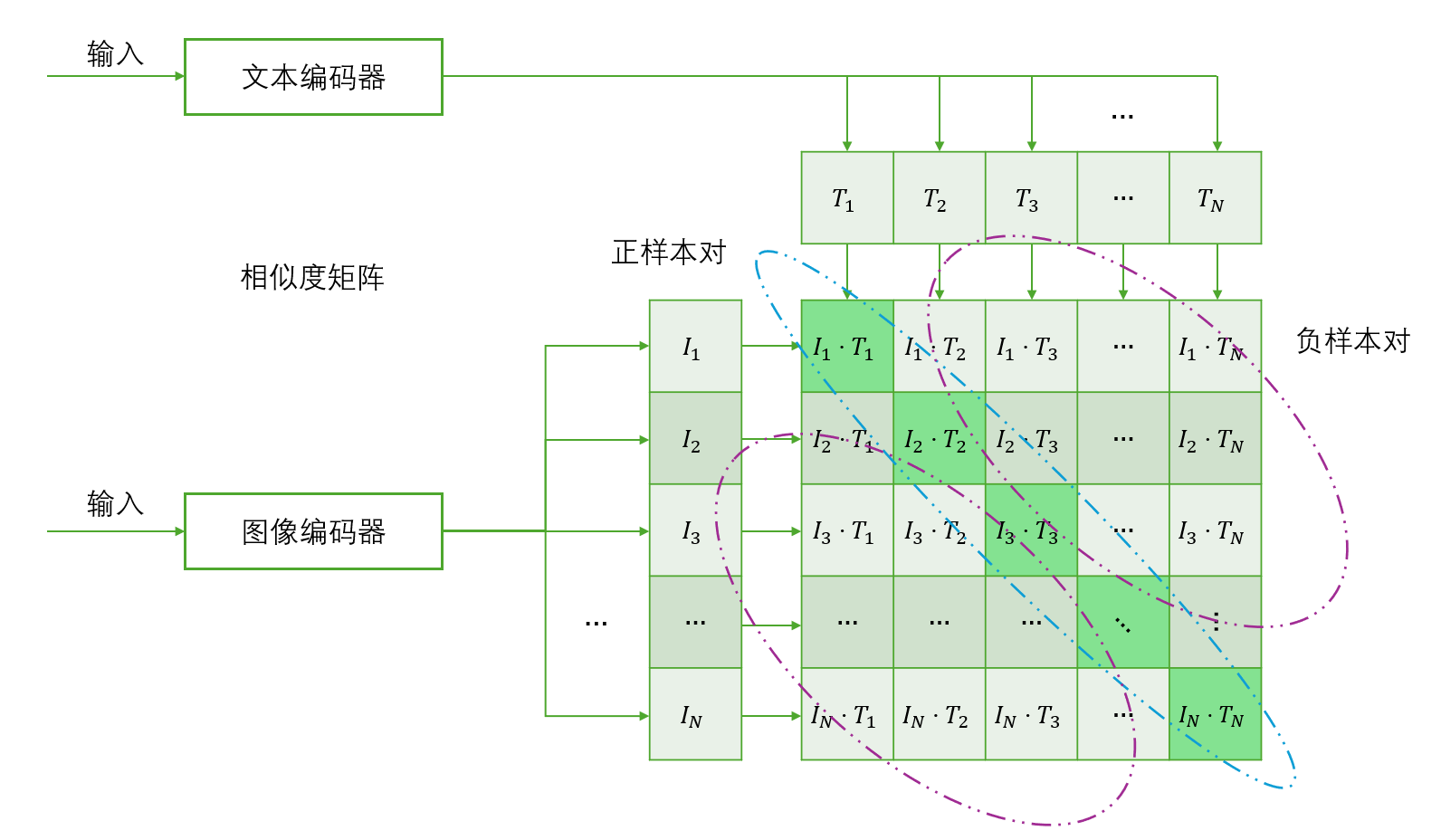
对比学习分为相似度矩阵的计算和对称对比损失的计算两步。
在计算相似度矩阵的过程中,会先计算一个的矩阵
,其中每个元素
是图像
和文本
的归一化向量的点积:
其中,对角线元素 是正确的正样本对(也就是图片和文本内容相对应)的相似度,非对角线元素
都是错误的负样本对(也就是图片和文本内容不对应)的相似度。
相似度矩阵如下图所示:
接下来就是计算对称对比损失,其损失函数从两个角度进行计算:
- 图像到文本的损失:对于每一张图片
,将其视为一个多分类问题,目标是让它与正确文本
的相似度
远高于与所有其他文本
的相似度。这通过计算每一行的交叉熵损失实现。
- 文本到图像的损失:对于每一段文本
,同样将其视为一个多分类问题,目标是让它与正确图片
的相似度
远高于与所有其他图片
的相似度。这通过计算每一列的交叉熵损失实现。
最终损失:将这两个损失取平均(或相加),作为模型的总损失,通过最小化这个损失,模型被驱动着:
- 拉近:正确配对的图像和文本向量
- 推远:所有错误配对的图像和文本向量
这个过程不断重复,直到模型收敛,最终得到一个能够深刻理解图像和文本语义关联的双塔模型。
②CLIP的使用
大部分情况下,我们会把一个已经在大规模数据集(如WebImageText,包含4亿个图像-文本对)上完成了对比学习训练过程的CLIP常作为一个特征提取器使用,而不考虑它是如何训练的。
下面是简单的代码使用例子:
import torch
import clip
from PIL import Imagedevice = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)# 图像输入
image = preprocess(Image.open("image.jpg")).unsqueeze(0).to(device)
# 文本输入
text = clip.tokenize(["your text description"]).to(device)with torch.no_grad():# 只获取特征向量image_embedding = model.encode_image(image)text_embedding = model.encode_text(text)print("图像嵌入向量:", image_embedding.shape)
print("文本嵌入向量:", text_embedding.shape)clip库内置了图像和文本的预处理函数preprocess和clip.tokenize,所以预处理也不需要自己考虑,直接丢进去就可以用,再通过model.encode_image和model.encode_text函数就可以得到图像和文本对应的嵌入向量了。
至于为什么图像处理函数preprocess是和模型绑定的,而clip.tokenize是直接在clip包里面的,个人理解是preprocess会因为不同CLIP变体而对图像进行不同的处理方式,而clip.tokenize对文本的处理方式各个CLIP变体之间都一样,所以并不绑定模型。(比如大多数CLIP变体模型使用的图像输入是224px的,而ViT-L/14@336px需要336px,所以两者的preprocess不同,需要绑定模型才能正确使用)
3.总结
1. 核心思想
CLIP是一个将图像和文本映射到同一向量空间的多模态模型。它的核心思想是通过对比学习,让语义相关的图像和文本在共享空间中靠近,语义不相关的则远离。这使得模型能够理解两种模态之间的深层联系,实现跨模态的语义理解。
2. 训练方法
CLIP采用双编码器架构,通过对比损失进行训练。图像编码器(如ViT)和文本编码器(如Transformer)分别处理各自模态的输入,然后将特征投影到共享空间并进行归一化。训练时计算所有图文对的相似度矩阵,并用对称交叉熵损失同时优化两个编码器,确保正确的配对获得更高相似度。
3. 应用方式
训练完成的CLIP主要作为特征提取器使用。得益于其“双塔”结构,图像和文本编码器可以独立进行推理,输出归一化的嵌入向量。这些向量可直接计算余弦相似度,用于图像分类、图文检索等各种任务。