黑马商城day7-消息可靠性
1.修改业务
1.1.抽取共享的MQ配置
将MQ配置抽取到Nacos中管理,微服务中直接使用共享配置。
1.抽取共享配置。在nacos控制台新建一个共享配置shared-rabbitMQ.yaml:
spring:rabbitmq:host: 192.168.150.128 # 你的虚拟机IPport: 5672 # 端口virtual-host: /hmall # 虚拟主机username: hmall # 用户名password: 123 # 密码2.拉取共享配置。引入依赖;新建bootstrap.yaml;修改application.yaml
引入依赖:
<!--nacos配置管理--><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><!--读取bootstrap文件--><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-bootstrap</artifactId></dependency>新建bootstrap.yaml:
spring:application:name: cart-service # 服务名称profiles:active: devcloud:nacos:server-addr: 192.168.150.101:8848 # nacos地址config:file-extension: yaml # 文件后缀名shared-configs: # 共享配置- dataId: shared-jdbc.yaml # 共享mybatis配置- dataId: shared-log.yaml # 共享日志配置- dataId: shared-swagger.yaml # 共享日志配置- dataId: shared-rabbitMQ.yaml # 共享MQ配置修改application.yaml
server:port: 8082
feign:okhttp:enabled: true # 开启OKHttp连接池支持
hm:swagger:title: 购物车服务接口文档package: com.hmall.cart.controllerdb:database: hm-cart1.2.改造下单功能
改造下单功能,将基于OpenFeign的清理购物车同步调用,改为基于RabbitMQ的异步通知:
定义topic类型交换机,命名为
trade.topic定义消息队列,命名为
cart.clear.queue将
cart.clear.queue与trade.topic绑定,BindingKey为order.create下单成功时不再调用清理购物车接口,而是发送一条消息到
trade.topic,发送消息的RoutingKey为order.create,消息内容是下单的具体商品、当前登录用户信息购物车服务监听
cart.clear.queue队列,接收到消息后清理指定用户的购物车中的指定商品
1.定义消息监听器:
@Component
@RequiredArgsConstructor
public class ItemsDeleteListener {private final ICartService cartService;@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "cart.order.success.queue"),exchange = @Exchange(name = "trade.topic",type = "topic"),key ="order.create"))public void itemsDelete(@Payload Set<Long> itemIds){cartService.removeByItemIds(itemIds);}
}2.编写发送消息代码:
// 3.清理购物车商品try {rabbitTemplate.convertAndSend("trade.topic","order.create",itemIds);} catch (Exception e) {log.error("发送清理购物车通知失败",e);}3.测试,发现清除失败,观察控制台发现,userId缺失。
分析原因:之前是通过OpenFeign调用,请求头包含了用户信息。但是现在使用MQ来监听,消息只包含参数,不包含用户信息。
1.3.登录信息传递优化
修改MQConfig,新增两个功能:
1.在消息发送之前,从当前线程中获取用户信息,存入消息头中。
- 作用:封装了向 RabbitMQ 发送消息的逻辑,是生产者发送消息的核心工具类。
- 核心增强:
- 通过
setBeforePublishPostProcessors在消息发送前,自动将当前登录用户的userId存入消息头(X-USER-INFO),实现跨服务的用户上下文传递(例如:订单服务发送消息到购物车服务时,购物车服务需要知道是哪个用户的订单)。
- 通过
2.在消息被消费之前,拦截消息,并从消息头中获取用户信息存入当前线程中,再执行消费功能。
- 作用:创建并配置消费消息的容器(
MessageListenerContainer),负责监听队列、接收消息、调用消费方法(如@RabbitListener注解的方法)。 - 核心增强:
- 通过
setAdviceChain添加拦截器,在消费方法执行前,从消息头(X-USER-INFO)中解析出userId并注入到UserContext(当前线程上下文),让消费方法能直接获取用户信息。 - 消费完成后(无论成功 / 失败),通过
finally块清除UserContext中的用户信息,避免线程池复用(消费端通常用线程池处理消息)导致的用户信息串用问题。
- 通过
要注意:两次都需要重新设置JSON消息转换器。
@Configuration
@Slf4j
public class MQConfig {@Beanpublic MessageConverter messageConverter(){return new Jackson2JsonMessageConverter();}@Beanpublic RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory,MessageConverter messageConverter){RabbitTemplate rabbitTemplate = new RabbitTemplate(connectionFactory);rabbitTemplate.setMessageConverter(messageConverter);rabbitTemplate.setBeforePublishPostProcessors(message -> {//1.从当前线程中取用户信息Long userId = UserContext.getUser();if(userId != null){try {// 2. 将userId转为JSON字符串(避免Java原生序列化的兼容性问题)ObjectMapper objectMapper = new ObjectMapper();String userJson = objectMapper.writeValueAsString(userId);// 3. 将JSON字符串存入消息头(自定义键X-USER-INFO)message.getMessageProperties().setHeader("X-USER-INFO", userJson);} catch (JsonProcessingException e) {// 异常处理:如日志记录(不影响消息发送,仅用户信息传递失败)log.error("序列化用户信息失败", e);}}// 4. 返回处理后的消息(继续发送流程)return message;});return rabbitTemplate;}@Beanpublic SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(ConnectionFactory connectionFactory,MessageConverter messageConverter) {SimpleRabbitListenerContainerFactory factory = new SimpleRabbitListenerContainerFactory();factory.setConnectionFactory(connectionFactory);factory.setMessageConverter(messageConverter);// 配置消费拦截器(AOP环绕通知)factory.setAdviceChain(new MethodInterceptor() {@Overridepublic Object invoke(MethodInvocation invocation) throws Throwable {// 1. 从方法参数中提取MQ消息对象(Message)Message message = extractMessageFromInvocation(invocation);// 2. 从消息头获取用户信息并注入UserContextif (message != null) {String userJson = message.getMessageProperties().getHeader("X-USER-INFO");if (userJson != null) {try {ObjectMapper objectMapper = new ObjectMapper();Long userId = objectMapper.readValue(userJson, Long.class);UserContext.setUser(userId); // 注入上下文} catch (JsonProcessingException e) {log.error("反序列化用户信息失败", e);}}}try {// 3. 执行实际的消费业务逻辑(如@RabbitListener方法)return invocation.proceed();} finally {// 4. 无论消费成功/失败,都清除线程上下文(关键!避免线程池复用)UserContext.removeUser();}}// 辅助方法:从方法参数中提取Message对象private Message extractMessageFromInvocation(MethodInvocation invocation) {for (Object arg : invocation.getArguments()) {if (arg instanceof Message) {return (Message) arg;}}return null;}});return factory;}
}
这个配置类实现了 RabbitMQ 消息传递的 “序列化统一” 和 “用户上下文传递” 两大核心功能,流程如下:
消息发送阶段:
- 生产者通过
RabbitTemplate发送消息时,Jackson2JsonMessageConverter将消息对象序列化为 JSON。 - 发送前,处理器自动从
UserContext取userId,序列化后存入消息头X-USER-INFO。
- 生产者通过
消息消费阶段:
- 消费容器通过
SimpleRabbitListenerContainerFactory创建,使用相同的Jackson2JsonMessageConverter将 JSON 消息反序列化为 Java 对象。 - 消费方法执行前,拦截器从消息头解析
userId并注入UserContext,供业务逻辑使用。 - 消费完成后,拦截器清除
UserContext,避免线程复用导致的问题。
- 消费容器通过
2.可靠性分析
在昨天的练习作业中,我们改造了余额支付功能,在支付成功后利用RabbitMQ通知交易服务,更新业务订单状态为已支付。
但是大家思考一下,如果这里MQ通知失败,支付服务中支付流水显示支付成功,而交易服务中的订单状态却显示未支付,数据出现了不一致。
此时前端发送请求查询支付状态时,肯定是查询交易服务状态,会发现业务订单未支付,而用户自己知道已经支付成功,这就导致用户体验不一致。
因此,这里我们必须尽可能确保MQ消息的可靠性,即:消息应该至少被消费者处理1次
那么问题来了:
我们该如何确保MQ消息的可靠性?
如果真的发送失败,有没有其它的兜底方案?
首先,我们一起分析一下消息丢失的可能性有哪些。
消息从发送者发送消息,到消费者处理消息,需要经过的流程是这样的: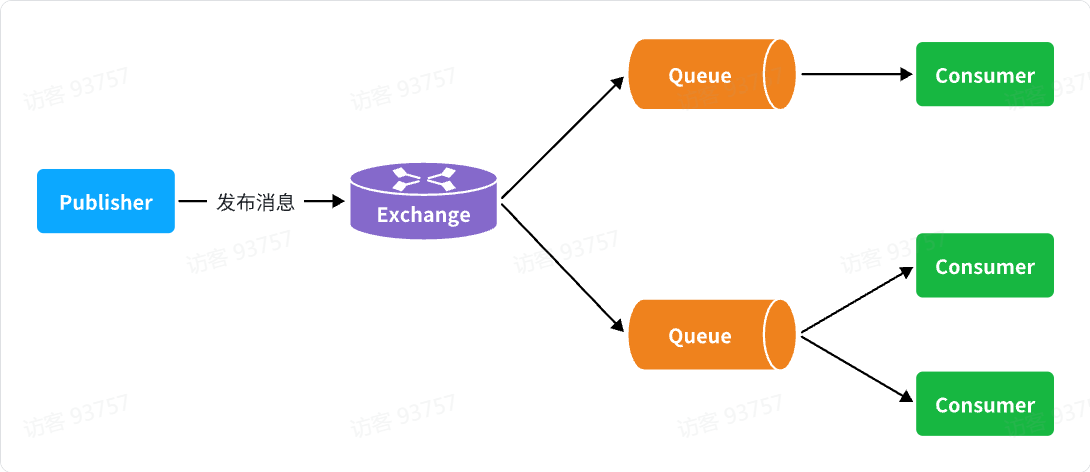
消息从生产者到消费者的每一步都可能导致消息丢失:
发送消息时丢失:
生产者发送消息时连接MQ失败
生产者发送消息到达MQ后未找到
Exchange生产者发送消息到达MQ的
Exchange后,未找到合适的Queue消息到达MQ后,处理消息的进程发生异常
MQ导致消息丢失:
消息到达MQ,保存到队列后,尚未消费就突然宕机
消费者处理消息时:
消息接收后尚未处理突然宕机
消息接收后处理过程中抛出异常
综上,我们要解决消息丢失问题,保证MQ的可靠性,就必须从3个方面入手:
确保生产者一定把消息发送到MQ
确保MQ不会将消息弄丢
确保消费者一定要处理消息
3.生产者的可靠性
3.1.生产者重连机制
有的时候由于网络波动,可能会出现发送者连接MQ失败的情况。通过配置我们可以开启连接失败后的重连机制:
spring:rabbitmq:connection-timeout: 1s # 设置MQ的连接超时时间template:retry:enabled: true # 开启超时重试机制initial-interval: 1000ms # 失败后的初始等待时间multiplier: 1 # 失败后下次的等待时长倍数,下次等待时长 = initial-interval * multipliermax-attempts: 3 # 最大重试次数在docker停止mq,启动测试类发送消息,发现控制台显示重连三次:

注意:当网络不稳定的时候,利用重试机制可以有效提高消息发送的成功率。不过SpringAMQP提供的重试机制是阻塞式的重试,也就是说多次重试等待的过程中,当前线程是被阻塞的,会影响业务性能。
如果对于业务性能有要求,建议禁用重试机制。如果一定要使用,请合理配置等待时长和重试次数,当然也可以考虑使用异步线程来执行发送消息的代码。
3.2.生产者确认
SpringAMQP提供了Publisher Confirm和Publisher Return两种确认机制。开启确机制认后,当发送者发送消息给MQ后,MQ会返回确认结果给发送者。返回的结果有以下几种情况:
- 消息投递到了MQ,但是路由失败。此时会通过PublisherReturn返回路由异常原因,然后返回ACK,告知投递成功
- 临时消息投递到了MQ,并且入队成功,返回ACK,告知投递成功
- 持久消息投递到了MQ,并且入队完成持久化,返回ACK ,告知投递成功
- 其它情况都会返回NACK,告知投递失败
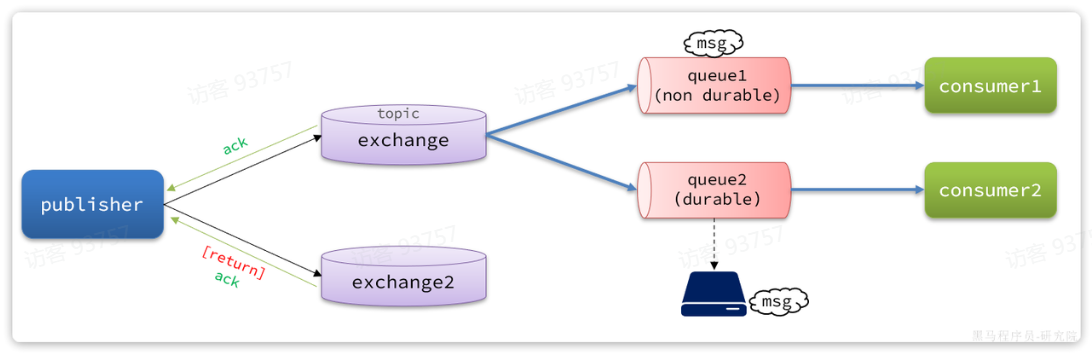
实现:
1.在publisher这个微服务的application.yml中添加配置:
spring:rabbitmq:publisher-confirm-type: correlated # 开启publisher confirm机制,并设置confirm类型publisher-returns: true # 开启publisher return机制配置说明:
这里publisher-confirm-type有三种模式可选:
- none:关闭confirm机制
- simple:同步阻塞等待MQ的回执消息
- correlated:MQ异步回调方式返回回执消息
2.发消息前,路由失败执行。每个RabbitTemplate只能配置一个ReturnCallback,因此需要在项目启动过程中配置:
@Slf4j
@AllArgsConstructor
@Configuration
public class MqConfig {private final RabbitTemplate rabbitTemplate;@PostConstructpublic void init(){rabbitTemplate.setReturnsCallback(new RabbitTemplate.ReturnsCallback() {@Overridepublic void returnedMessage(ReturnedMessage returned) {log.error("触发return callback,");log.debug("exchange: {}", returned.getExchange());log.debug("routingKey: {}", returned.getRoutingKey());log.debug("message: {}", returned.getMessage());log.debug("replyCode: {}", returned.getReplyCode());log.debug("replyText: {}", returned.getReplyText());}});}
}@PostConstruct 是 Java 标准库(javax.annotation.PostConstruct)中的一个注解,用于标记对象创建后需要立即执行的初始化方法。它的核心作用是在依赖注入完成后,执行一些初始化逻辑。
执行时机:当一个类被 Spring 容器实例化(创建对象),并且所有依赖注入(如
@Autowired、@Resource或构造函数注入的依赖)完成后,被@PostConstruct标记的方法会自动执行。执行顺序:构造方法 → 依赖注入 → @PostConstruct 方法。MQConfig类通过@RequiredArgsConstructor注入了RabbitTemplate实例(依赖注入完成)。@PostConstruct标记的init()方法会在RabbitTemplate注入后自动执行,为其设置ReturnsCallback(用于处理消息路由失败的场景)。
这样做的好处是:确保在使用 RabbitTemplate 之前,回调逻辑已经初始化完成,避免因回调未设置导致的消息处理异常。
3.发消息时,根据MQ结果执行回调函数。每次发送消息都要指定,指定消息ID、消息ConfirmCallback:
由于每个消息发送时的处理逻辑不一定相同,因此ConfirmCallback需要在每次发消息时定义。具体来说,是在调用RabbitTemplate中的convertAndSend方法时,多传递一个参数: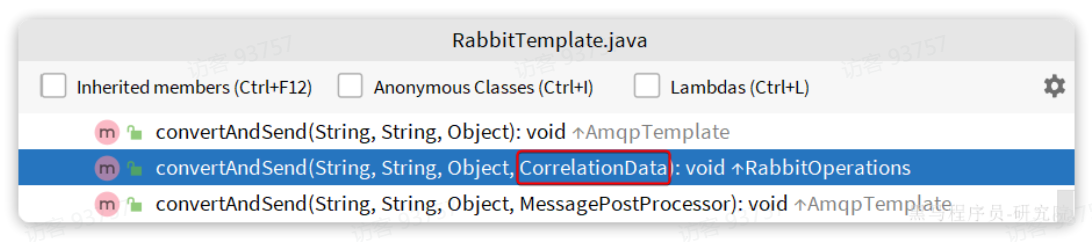
这里的CorrelationData中包含两个核心的东西:
id:消息的唯一标示,MQ对不同的消息的回执以此做判断,避免混淆SettableListenableFuture:回执结果的Future对象
将来MQ的回执就会通过这个Future来返回,我们可以提前给CorrelationData中的Future添加回调函数来处理消息回执:
@Testpublic void testConfirmCallback() throws InterruptedException {//1.创建correlationData,需要指定唯一的idCorrelationData cd =new CorrelationData(UUID.randomUUID().toString());cd.getFuture().addCallback(new ListenableFutureCallback<CorrelationData.Confirm>() {@Override//Future内部出现异常,但几乎不会,只需简单记录日志即可public void onFailure(Throwable ex) {log.error("send message fail", ex);}@Overridepublic void onSuccess(CorrelationData.Confirm result) {if(result.isAck()){ // result.isAck(),boolean类型,true代表ack回执,false 代表 nack回执log.debug("发送消息成功,收到 ack!");}else{ // result.getReason(),String类型,返回nack时的异常描述log.error("发送消息失败,收到 nack, reason : {}", result.getReason());}}});//2.准备消息交换器和信息String exchangeName = "hmall.direct";//交换器名String message = "hello,red";//消息rabbitTemplate.convertAndSend(exchangeName,"red22",message,cd);Thread.sleep(2000);}测试结果:
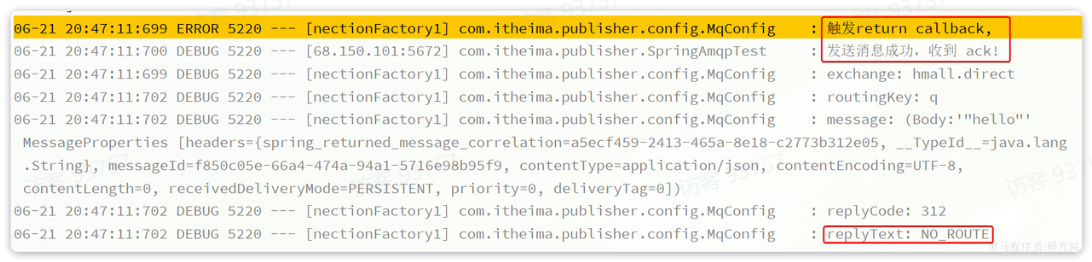
可以看到,由于传递的RoutingKey是错误的,路由失败后,触发了return callback,同时也收到了ack。
当我们修改为正确的RoutingKey以后,就不会触发return callback了,只收到ack。
而如果连交换机都是错误的,则只会收到nack。
确认回调关注 “消息是否到达服务器”,ReturnsCallback 关注 “到达服务器后是否路由成功”。
注意:
开启生产者确认比较消耗MQ性能,一般不建议开启。而且大家思考一下触发确认的几种情况:
路由失败:一般是因为RoutingKey错误导致,往往是编程导致
交换机名称错误:同样是编程错误导致
MQ内部故障:这种需要处理,但概率往往较低。因此只有对消息可靠性要求非常高的业务才需要开启,而且仅仅需要开启ConfirmCallback处理nack就可以了。
4.MQ的可靠性
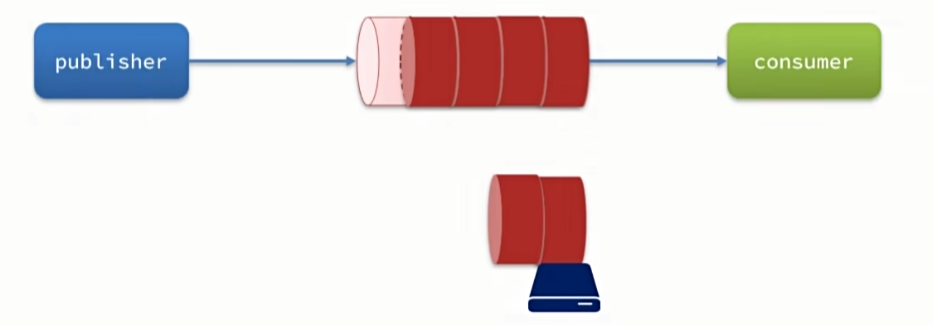
消息到达MQ以后,如果MQ不能及时保存,也会导致消息丢失,所以MQ的可靠性也非常重要。
在默认情况下,RabbitMQ会将接收到的信息保存在内存中以降低消息收发的延迟。这样会导致两个问题:
- 一旦MQ宕机,内存中的消息会丢失
- 内存空间有限,当消费者故障或处理过慢时,会导致消息积压,引发MQ阻塞
4.1.数据持久化
为了提升性能,默认情况下MQ的数据都是在内存存储的临时数据,重启后就会消失。为了保证数据的可靠性,必须配置数据持久化,包括:
交换机持久化
队列持久化
消息持久化
实现:
1.交换机和队列,不管是使用控制台还是程序去创建,都默认是持久的: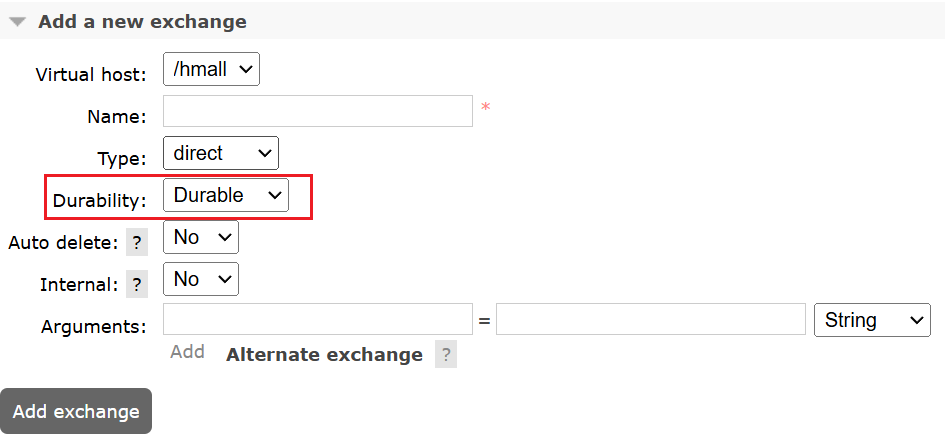
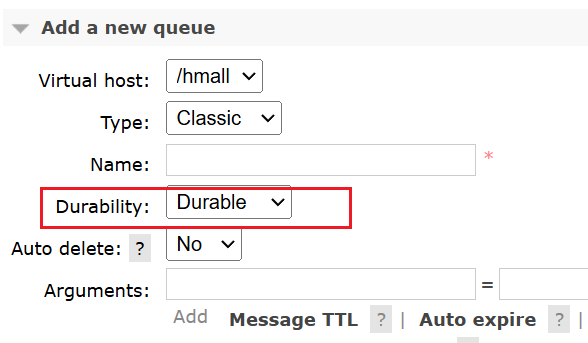
2.SpringAMQP发送消息,默认消息也是持久化的。
@Testpublic void testSimpleQueue2(){Message message = MessageBuilder.withBody("hello,SpringAMQP".getBytes(StandardCharsets.UTF_8)).setDeliveryMode(MessageDeliveryMode.PERSISTENT).build();String queueName = "simple.queue";//队列名for (int i = 0; i < 1000000; i++) {rabbitTemplate.convertAndSend(queueName,message);}}这里我们通过向队列发送1000000条持久化/临时的消息,观察控制台,来检验两者的发送效率。
临时消息:在将数据写到磁盘时,消息速率会先降到零,写完后再速率才会上来。测试耗时38s
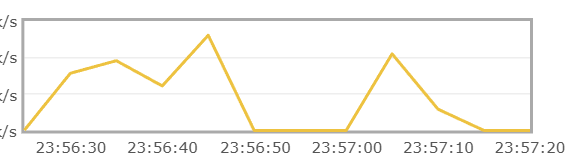

持久消息:消息速率基本保持在很高,同时测试时间也只有20s,而且在mq重启后消息依旧能保存。
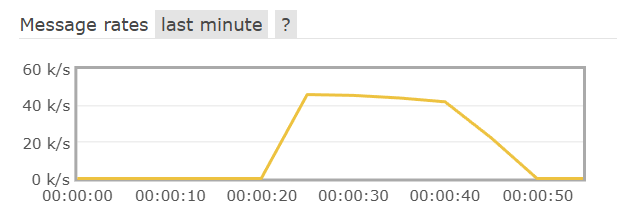
说明:在开启持久化机制以后,如果同时还开启了生产者确认,那么MQ会在消息持久化以后才发送ACK回执,进一步确保消息的可靠性。
不过出于性能考虑,为了减少IO次数,发送到MQ的消息并不是逐条持久化到数据库的,而是每隔一段时间批量持久化。一般间隔在100毫秒左右,这就会导致ACK有一定的延迟,因此建议生产者确认全部采用异步方式。
4.2.LazyQueue
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queue的概念,也就是惰性队列。
惰性队列的特征如下:
- 接收到消息后直接存入磁盘,不再存储到内存
- 消费者要消费消息时才会从磁盘中读取并加载到内存(可以提前缓存部分消息到内存,最多2048条)
在3.12版本后,所有队列都是Lazy Queue模式,无法更改。
在 RabbitMQ 中,Lazy Queue(惰性队列) 是一种特殊的队列类型,其核心设计是优先将消息存储在磁盘上,而非内存中,仅在消费者需要时才加载到内存。这种设计在处理大量消息或长时间未消费的消息时,有显著优势。
一、Lazy Queue 的核心好处
大幅降低内存占用,避免 OOM(内存溢出)
- 普通队列(默认)会将消息优先保存在内存中,当消息量巨大(如百万级)且消费速度慢时,内存会被快速占满,可能导致 RabbitMQ 崩溃或被操作系统杀死。
- Lazy Queue 会直接将消息写入磁盘,仅在消费者请求时才加载部分消息到内存,内存占用始终保持在较低水平,从根本上避免了大量消息导致的内存压力。
提高消息持久化的效率
- 普通队列的持久化消息需要先存内存,再异步刷盘(可能因内存满导致刷盘延迟)。
- Lazy Queue 的消息天生存储在磁盘,无需额外的内存到磁盘的同步开销,持久化过程更高效,尤其适合大量持久化消息的场景。
减少节点重启后的恢复时间
- 普通队列重启时,需要将磁盘上的持久化消息重新加载到内存,消息量越大,恢复时间越长(可能几分钟到几小时)。
- Lazy Queue 重启后无需加载全部消息到内存,仅在消费时按需加载,因此恢复速度极快,几乎不受消息量影响。
更适合 “消息堆积” 场景
- 对于非实时消费的场景(如日志收集、数据备份),消息可能长时间堆积在队列中。
- 普通队列堆积大量消息会导致内存膨胀,而 Lazy Queue 即使堆积千万级消息,也能保持稳定的内存占用。
二、使用 Lazy Queue 的原因(解决传统队列的痛点)
传统队列(默认配置)在处理大量消息时存在以下痛点,而 Lazy Queue 正是为解决这些问题而设计:
内存瓶颈限制消息量普通队列依赖内存存储消息,当消息量超过内存容量时,会触发 RabbitMQ 的 “内存告警” 机制,此时 RabbitMQ 会阻塞生产者发送消息,甚至强制将内存消息刷盘(可能导致性能骤降)。Lazy Queue 彻底摆脱了内存容量的限制,支持存储海量消息。
持久化消息的性能损耗普通队列的持久化消息需要经历 “内存暂存→异步刷盘” 的过程,当消息量激增时,刷盘操作可能跟不上消息写入速度,导致内存中堆积大量待刷盘消息,进一步加剧内存压力。Lazy Queue 直接写入磁盘,省去了内存暂存环节,减少了 I/O 阻塞。
节点恢复慢,可用性低普通队列重启时,必须将所有持久化消息从磁盘加载到内存才能提供服务,消息量越大,恢复时间越长,期间队列无法处理请求,可用性降低。Lazy Queue 重启后立即可用,消息按需加载,几乎不影响服务恢复速度。
三、适用场景与注意事项
适用场景:
- 消息量大且消费速度慢(如日志、监控数据);
- 消息需要长期存储(如归档数据);
- 对内存占用敏感,避免 OOM 的场景。
注意事项:
- 消费延迟略高:消息从磁盘加载到内存需要时间,因此实时性要求极高的场景(如秒杀订单)不适合;
- 依赖磁盘性能:Lazy Queue 对磁盘 I/O 性能更敏感,建议使用 SSD 提升效率;
- 配置方式:需显式声明为 Lazy Queue(通过队列参数
x-queue-mode: lazy),默认队列不是 Lazy 模式。
总结
Lazy Queue 通过 “磁盘优先存储” 的设计,解决了传统队列在大量消息场景下的内存瓶颈、持久化效率低、恢复慢等问题,是处理海量消息、非实时消费场景的最佳选择。其核心价值在于平衡消息存储量与系统稳定性,让 RabbitMQ 能更可靠地应对高消息量场景。
1.控制台:在添加队列的时候,添加x-queue-mod=lazy参数即可设置队列为Lazy模式: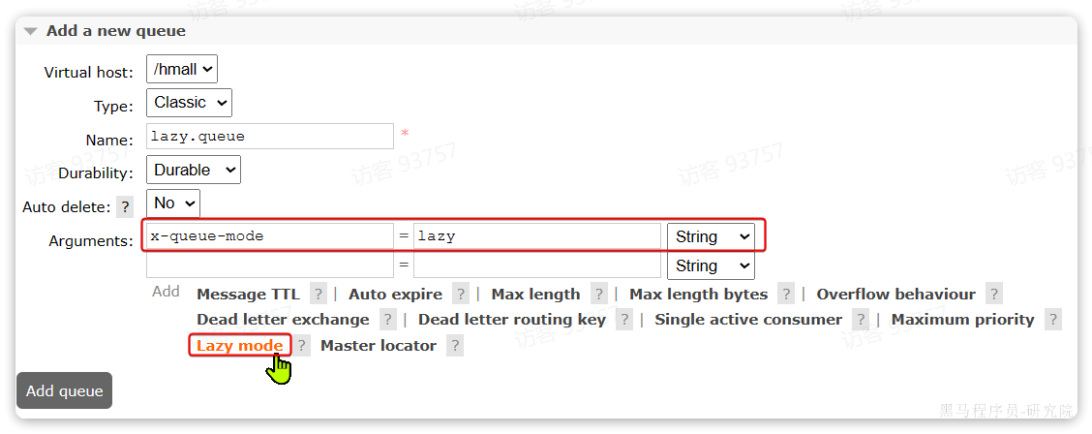
2.代码:在利用SpringAMQP声明队列的时候,添加x-queue-mod=lazy参数也可设置队列为Lazy模式:
@Bean
public Queue lazyQueue(){return QueueBuilder.durable("lazy.queue").lazy() // 开启Lazy模式.build();
}当然,我们也可以基于注解来声明队列并设置为Lazy模式:
@RabbitListener(queuesToDeclare = @Queue(name = "lazy.queue",durable = "true",arguments = @Argument(name = "x-queue-mode", value = "lazy")
))
public void listenLazyQueue(String msg){log.info("接收到 lazy.queue的消息:{}", msg);
}3.对于已经存在的队列,也可以配置为lazy模式,但是要通过设置policy实现。
可以基于命令行设置policy:
rabbitmqctl set_policy Lazy "^lazy-queue$" '{"queue-mode":"lazy"}' --apply-to queues 命令解读:
rabbitmqctl:RabbitMQ的命令行工具set_policy:添加一个策略Lazy:策略名称,可以自定义"^lazy-queue$":用正则表达式匹配队列的名字'{"queue-mode":"lazy"}':设置队列模式为lazy模式--apply-to queues:策略的作用对象,是所有的队列
当然,也可以在控制台配置policy,进入在控制台的Admin页面,点击Policies,即可添加配置: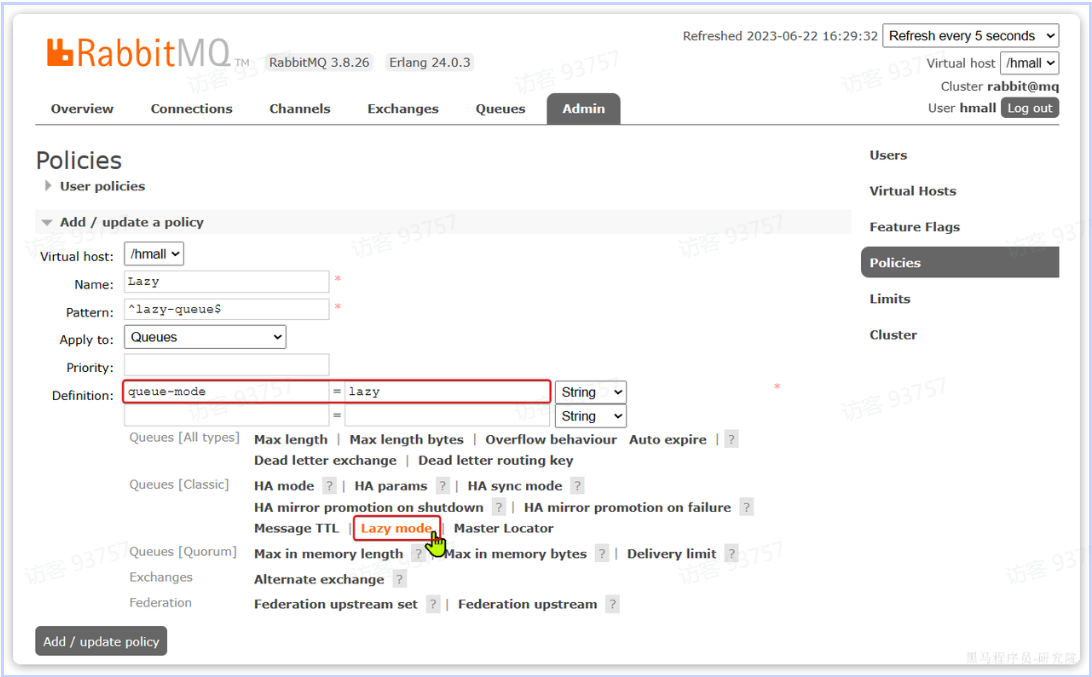
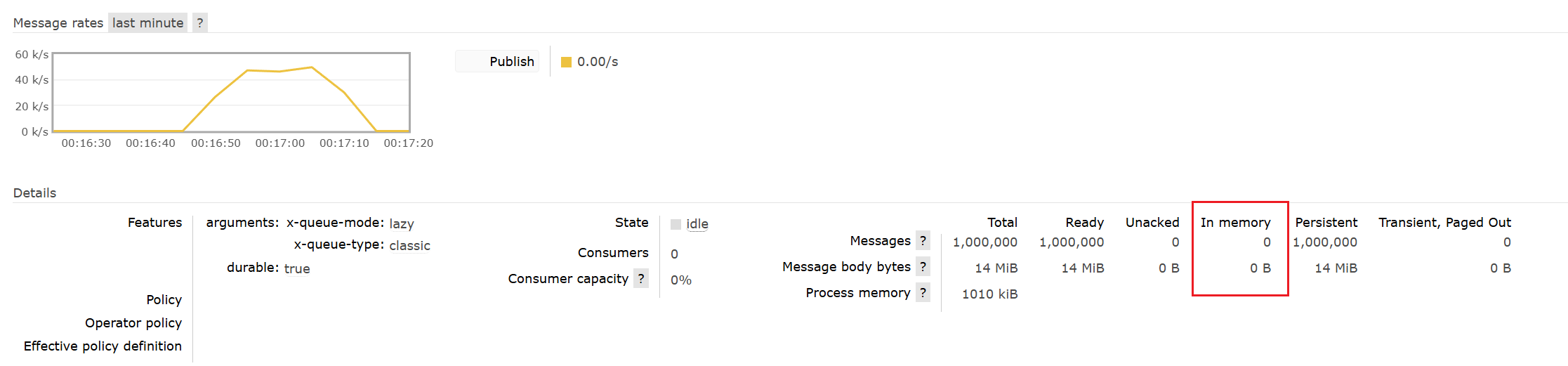
测试:观察到内存根本没有消息,直接存入磁盘。
5.消费者的可靠性
当RabbitMQ向消费者投递消息以后,需要知道消费者的处理状态如何。因为消息投递给消费者并不代表就一定被正确消费了,可能出现的故障有很多,比如:
消息投递的过程中出现了网络故障
消费者接收到消息后突然宕机
消费者接收到消息后,因处理不当导致异常
...
一旦发生上述情况,消息也会丢失。因此,RabbitMQ必须知道消费者的处理状态,一旦消息处理失败才能重新投递消息。
但问题来了:RabbitMQ如何得知消费者的处理状态呢?
5.1.消费者确认机制
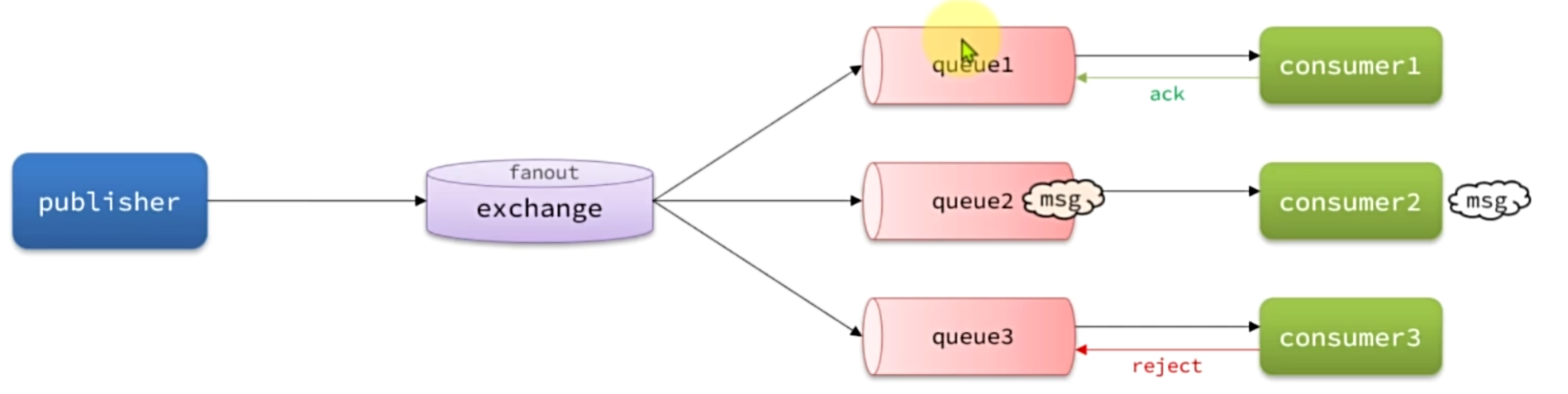
消费者确认机制(Consumer Acknowledgement)是为了确认消费者是否成功处理消息。当消费者处理消息结束后,应该向RabbitMQ发送一个回执,告知RabbitMQ自己消息处理状态:
- ack:成功处理消息,RabbitMQ从队列中删除该消息
- nack:消息处理失败,RabbitMQ需要再次投递消息
- reject:消息处理失败并拒绝该消息,RabbitMQ从队列中删除该消息
SpringAMQP已经实现了消息确认功能。并允许我们通过配置文件选择ACK处理方式,有三种方式:
- none:不处理。即消息投递给消费者后立刻ack,消息会立刻从MQ删除。非常不安全,不建议使用
- manual:手动模式。需要自己在业务代码中调用api,发送ack或reject,存在业务入侵,但更灵活
- auto:自动模式。SpringAMQP利用AOP对我们的消息处理逻辑做了环绕增强,当业务正常执行时则自动返回ack. 当业务出现异常时,根据异常判断返回不同结果:
- 如果是业务异常,会自动返回nack
- 如果是消息处理或校验异常,自动返回reject
spring:rabbitmq:listener:simple:acknowledge-mode: auto
1.当为none时,测试发送一条消息:

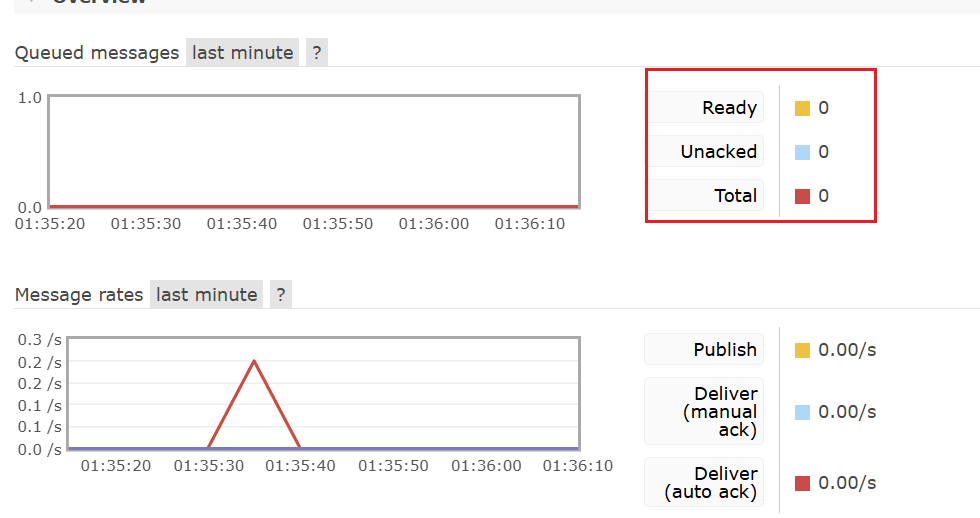
发现当抛出异常后,消息已经被清除,但是整个方法并未结束。
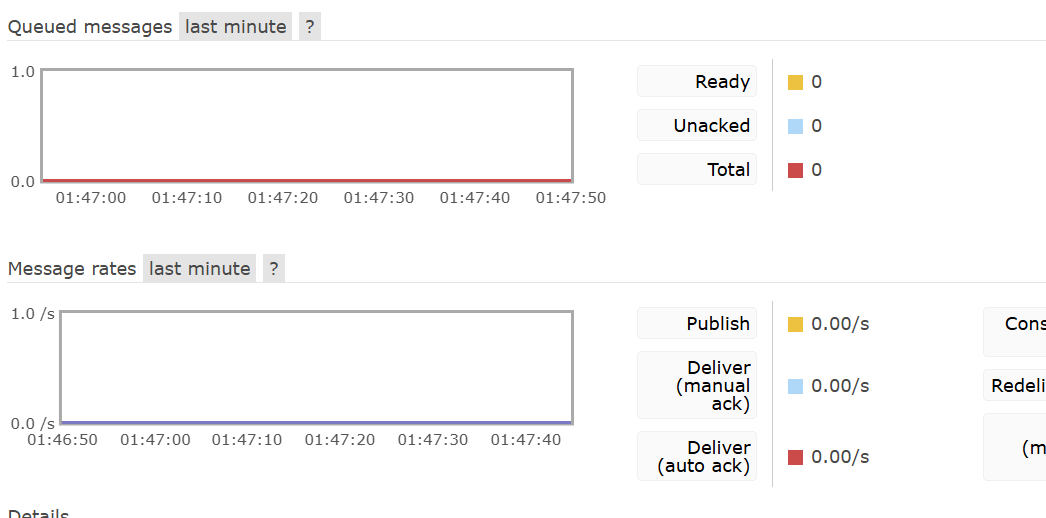
2.当为auto时: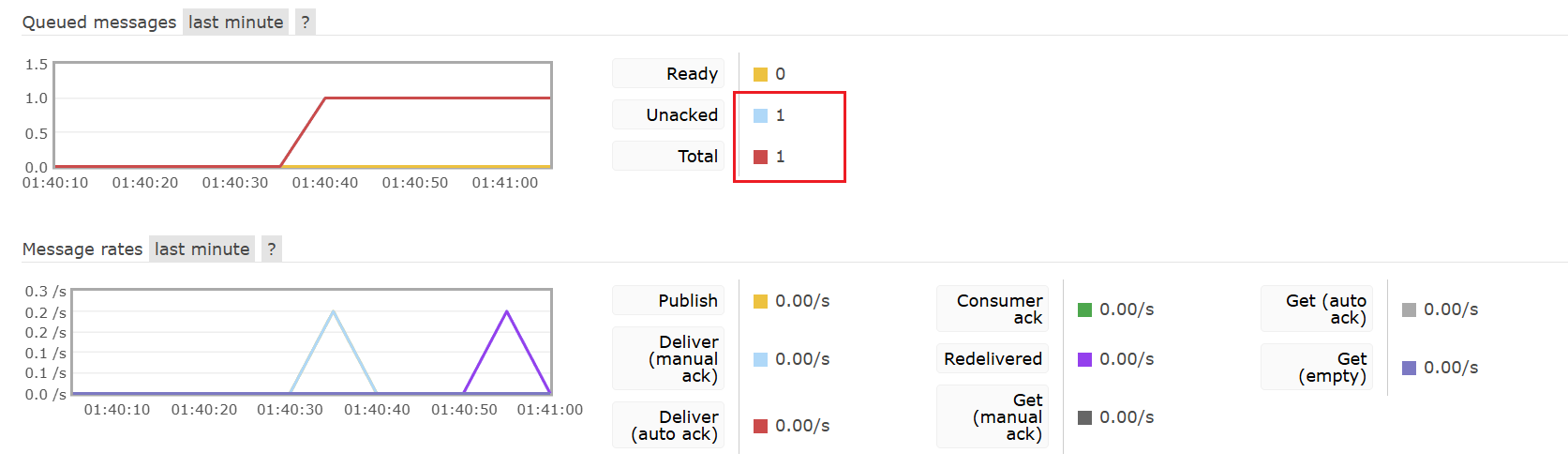
发现当抛出异常后,会存进Unacked中。放行程序,又会停止在断点处,说明消息MQ尝试再次发送消息。
当修改异常为MessageConversionException,放行程序,发现并未再次发送消息。观察控制台:
消息被拒绝,不会再次尝试。
5.2.失败重试机制
当消费者出现异常后,消息会不断requeue(重入队)到队列,再重新发送给消费者。如果消费者再次执行依然出错,消息会再次requeue到队列,再次投递,直到消息处理成功为止。
极端情况就是消费者一直无法执行成功,那么消息requeue就会无限循环,导致mq的消息处理飙升,带来不必要的压力:
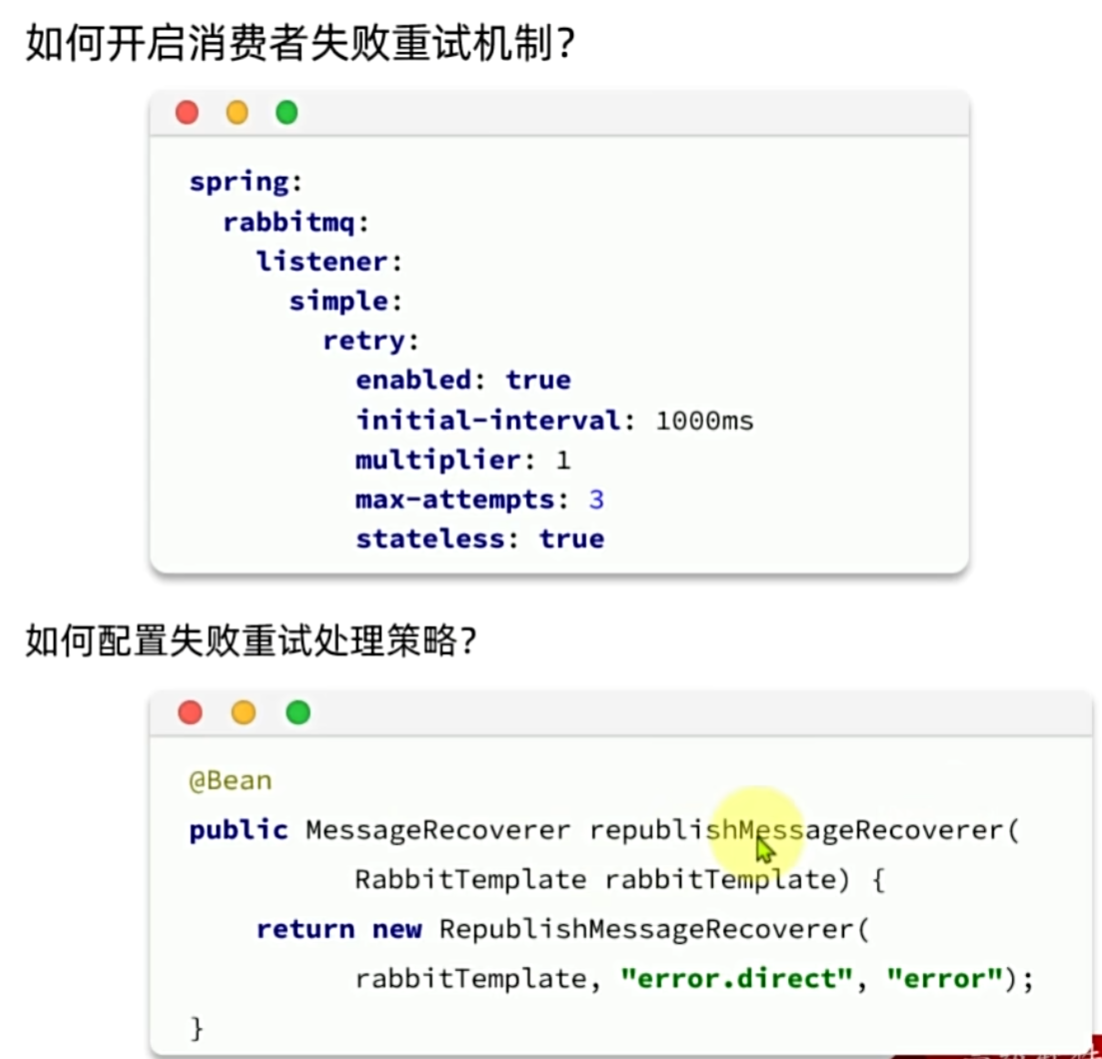
SpringAMQP提供了消费者失败重试机制,在消费者出现异常时利用本地重试,而不是无限的requeue到mq。我们可以通过在application.yaml文件中添加配置来开启重试机制:
spring:rabbitmq:listener:simple:retry:enabled: true # 开启消费者失败重试initial-interval: 1000ms # 初识的失败等待时长为1秒multiplier: 1 # 失败的等待时长倍数,下次等待时长 = multiplier * last-intervalmax-attempts: 3 # 最大重试次数stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false再次测试,观察消费者控制台:

在本地重试三次,重试次数耗尽。
观察MQ控制台,Redelivered为0,证明重试是在本地发生的,而不是MQ重新投递,同时消息也被清除。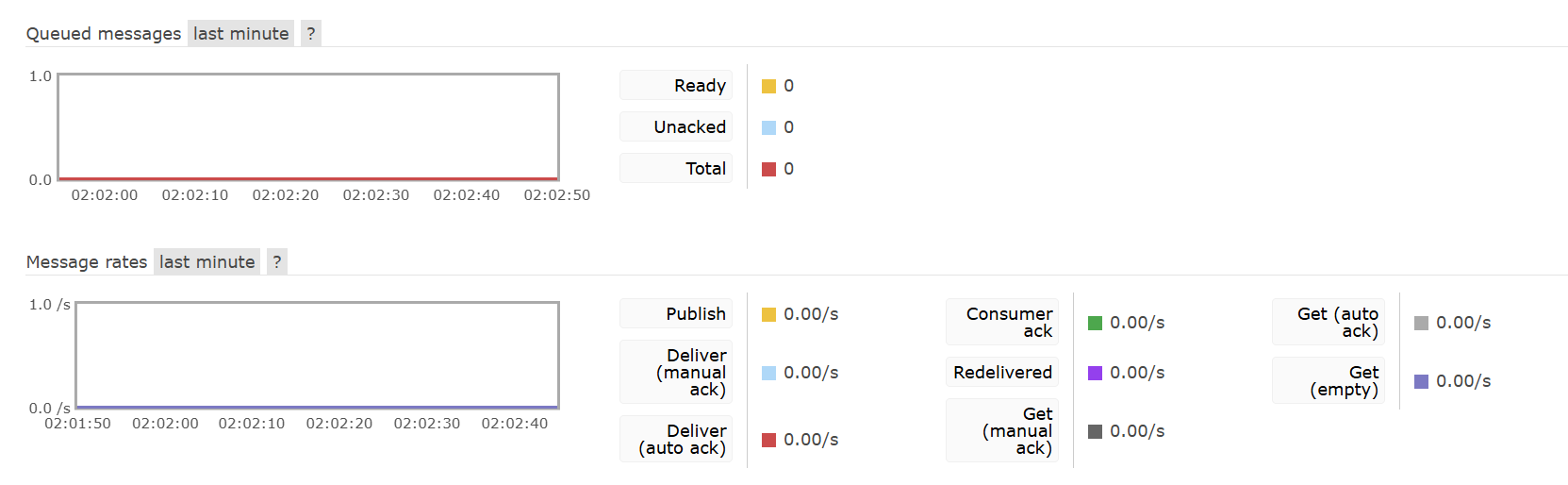
在开启重试模式后,重试次数耗尽,如果消息依然失败,则需要有MessageRecoverer接口来处理,它包含三种不同的实现:
- RejectAndDontRequeueRecoverer:重试耗尽后,直接reject,丢弃消息。默认就是这种方式
- ImmediateRequeueMessageRecoverer:重试耗尽后,返回nack,消息重新入队
- RepublishMessageRecoverer:重试耗尽后,将失败消息投递到指定的交换机

修改重试机制:
将失败处理策略改为RepublishMessageRecoverer:
- 首先,定义接收失败消息的交换机、队列及其绑定关系,此处略:
- 然后,定义RepublishMessageRecoverer:
@Bean
public MessageRecoverer republishMessageRecoverer(RabbitTemplate rabbitTemplate){return new RepublishMessageRecoverer(rabbitTemplate, "error.direct", "error");
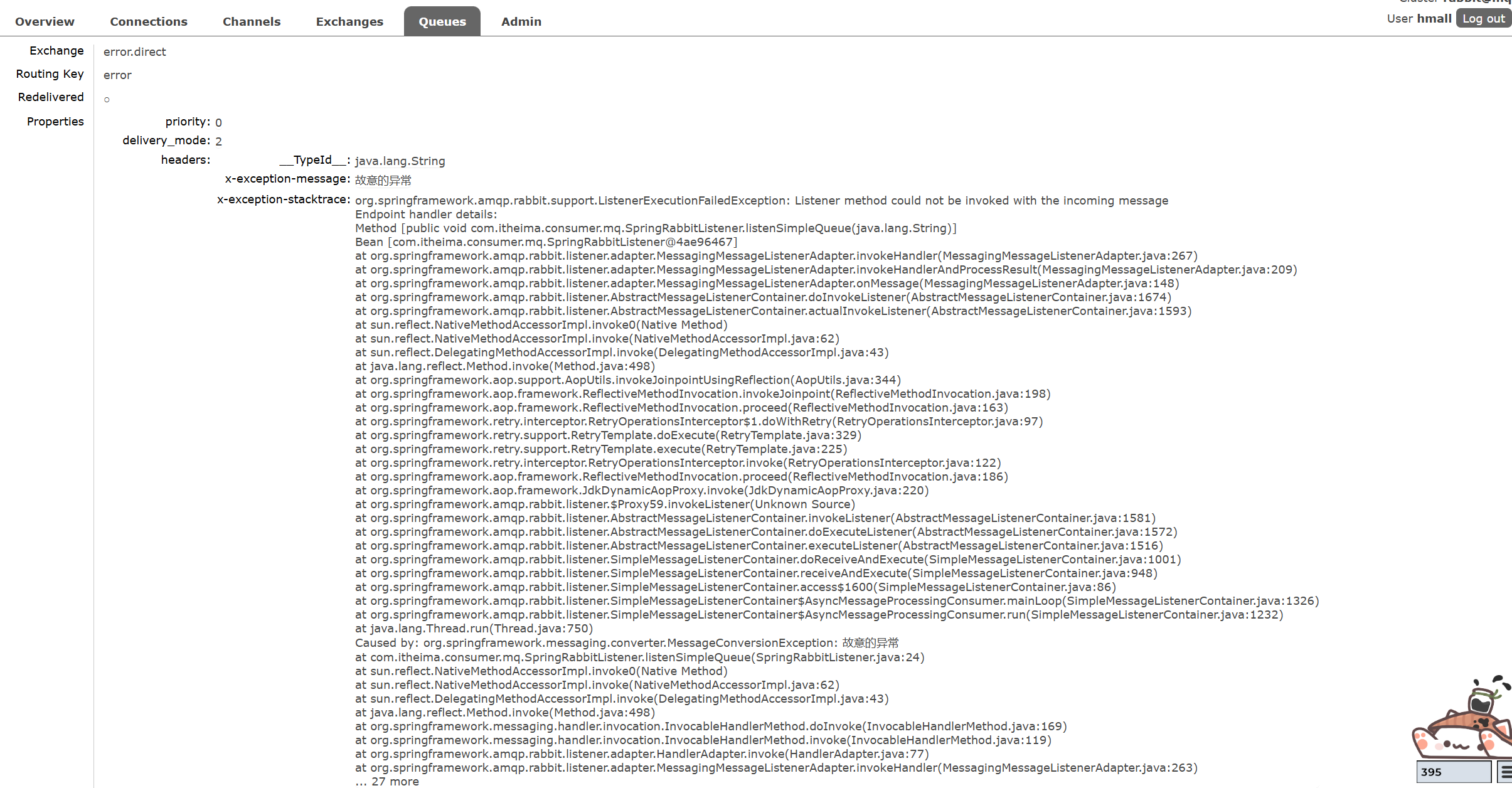
}重新测试,观察消费者控制台发现:重新发送三次失败,向指定的交换机发送消息和routingKey。

MQ控制台获取错误消息:
总结:
5.3.业务幂等性
当业务被处理完成向MQ发送ACK时,发生了网络异常导致ACK没有发送成功,在重新连接后,MQ会再次推送消息,业务会被二次处理,这是不对的。
何为幂等性?
幂等是一个数学概念,用函数表达式来描述是这样的:f(x) = f(f(x)),例如求绝对值函数。
在程序开发中,则是指同一个业务,执行一次或多次对业务状态的影响是一致的。例如:
根据id删除数据
查询数据
新增数据
但数据的更新往往不是幂等的,如果重复执行可能造成不一样的后果。比如:
取消订单,恢复库存的业务。如果多次恢复就会出现库存重复增加的情况
退款业务。重复退款对商家而言会有经济损失。
所以,我们要尽可能避免业务被重复执行。
然而在实际业务场景中,由于意外经常会出现业务被重复执行的情况,例如:
页面卡顿时频繁刷新导致表单重复提交
服务间调用的重试
MQ消息的重复投递
我们在用户支付成功后会发送MQ消息到交易服务,修改订单状态为已支付,就可能出现消息重复投递的情况。如果消费者不做判断,很有可能导致消息被消费多次,出现业务故障。
举例:
假如用户刚刚支付完成,并且投递消息到交易服务,交易服务更改订单为已支付状态。
由于某种原因,例如网络故障导致生产者没有得到确认,隔了一段时间后重新投递给交易服务。
但是,在新投递的消息被消费之前,用户选择了退款,将订单状态改为了已退款状态。
退款完成后,新投递的消息才被消费,那么订单状态会被再次改为已支付。业务异常。
因此,我们必须想办法保证消息处理的幂等性。这里给出两种方案:
唯一消息ID
业务状态判断
5.3.1.唯一消息ID
给每个消息都设置一个唯一id,利用id区分是否是重复消息:
- 每一条消息都生成一个唯一的id,与消息一起投递给消费者。
- 消费者接收到消息后处理自己的业务,业务处理成功后将消息ID保存到数据库
- 如果下次又收到相同消息,去数据库查询判断是否存在,存在则为重复消息放弃处理。
我们该如何给消息添加唯一ID呢?
其实很简单,SpringAMQP的MessageConverter自带了MessageID的功能,我们只要开启这个功能即可。
以Jackson的消息转换器为例:
@Bean
public MessageConverter messageConverter(){// 1.定义消息转换器Jackson2JsonMessageConverter jjmc = new Jackson2JsonMessageConverter();// 2.配置自动创建消息id,用于识别不同消息,也可以在业务中基于ID判断是否是重复消息jjmc.setCreateMessageIds(true);return jjmc;
}1.修改配置类,发送消息,观察MQ控制台获取消息:发现存在message_id。
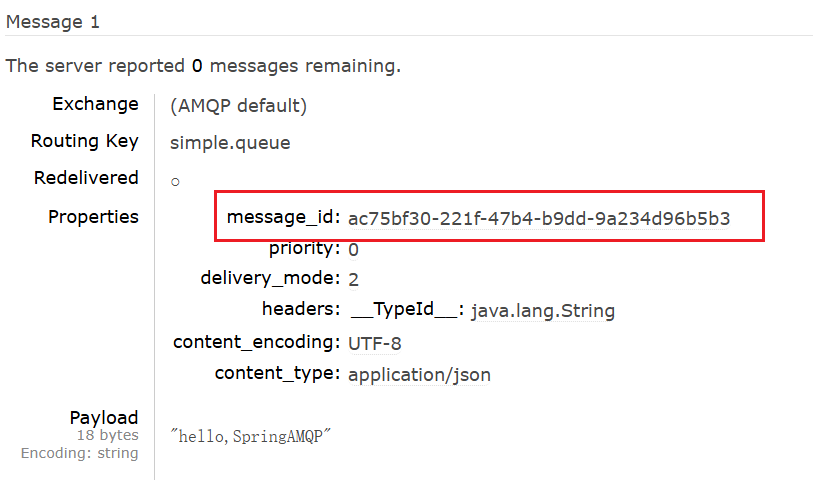
2.消费者如何获得message_id?监听对象修改为Message,从Message对象中获取:
@RabbitListener(queues = "simple.queue")public void listenSimpleQueue(Message message){log.info("监听到simple.queue的消息ID:【{}】", message.getMessageProperties().getMessageId());log.info("监听到simple.queue的消息:【{}】",new String(message.getBody()));//字节转字符串//throw new MessageConversionException("故意的异常");}
但是这种方案存在数据库读写操作,不仅会有业务侵入,而且会导致业务效率下降,一般不采用。
5.3.2.业务判断
结合业务逻辑,基于业务本身做判断。以我们的余额支付业务为例: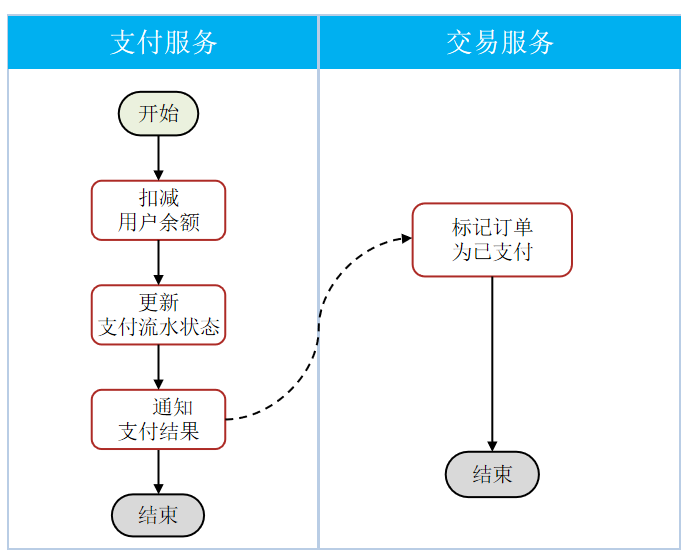
如果消息重发,加一层判断:
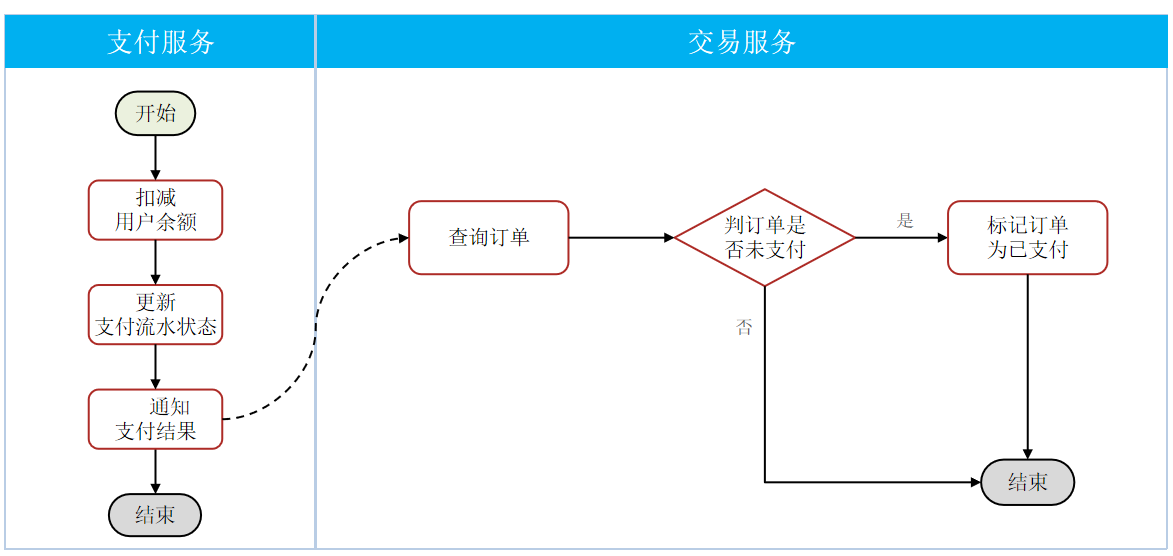
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "trade.pay.success.queue",durable = "true"),exchange = @Exchange(name = "pay.direct",type = "direct"),key = "pay.success"))public void listenPaySuccess(Long orderId){//1.查询订单Order order = orderService.getById(orderId);//2.判断订单状态是否为未支付(未支付才需要修改订单状态)if (order == null || order.getStatus() != 1){//不做处理return;}//3.标记订单状态为已支付orderService.markOrderPaySuccess(orderId);}5.3.3.总结
如何保证支付服务与交易服务之间的订单状态一致性?
- 首先,支付服务会正在用户支付成功以后利用MQ消息异步通知交易服务,完成订单状态同步。
- 其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消费者确认、消费者失败重试等策略,确保消息投递和处理的可靠性。同时也开启了MQ的持久化,避免因服务宕机导致消息丢失。
- 最后,我们还在交易服务更新订单状态时做了业务幂等判断,避免因消息重复消费导致订单状态异常。
如果交易服务消息处理失败,有没有什么兜底方案?
- 我们可以在交易服务设置定时任务,定期查询订单支付状态。这样即便MQ通知失败,还可以利用定时任务作为兜底方案,确保订单支付状态的最终一致性。
6.延迟消息
延迟消息:发送者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才收到消息。
延迟任务:设置在一定时间之后才执行的任务
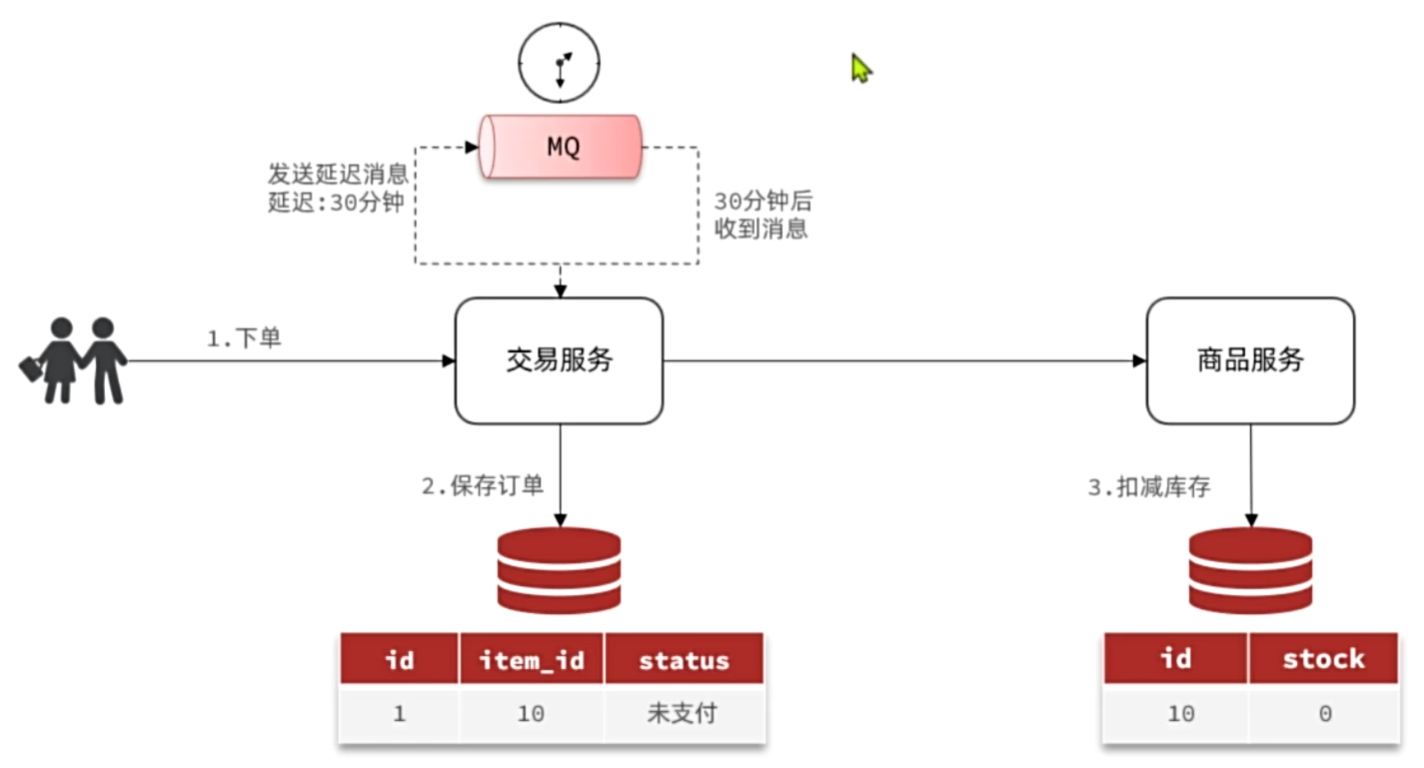
在RabbitMQ中实现延迟消息也有两种方案:
死信交换机+TTL
延迟消息插件
6.1死信交换机和延迟消息
6.1.1.死信交换机
什么是死信?
当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter):
消费者使用
basic.reject或basic.nack声明消费失败,并且消息的requeue参数设置为false消息是一个过期消息,超时无人消费(达到队列或消息本身设置的过期时间)
要投递的队列消息满了,无法投递,最早的消息可能成为死信
如果一个队列中的消息已经成为死信,并且这个队列通过dead-letter-exchange属性指定了一个交换机,那么队列中的死信就会投递到这个交换机中,而这个交换机就称为死信交换机(Dead Letter Exchange)。而此时加入有队列与死信交换机绑定,则最终死信就会被投递到这个队列中。
利用过期消息会成为死信和死信交换机机制,可以去实现延迟消息功能。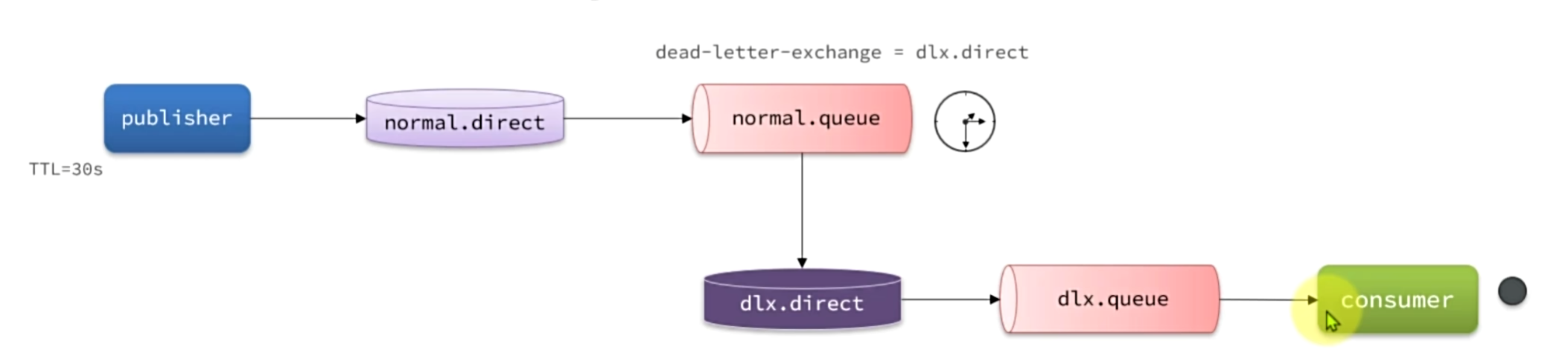
定义一个没有绑定消费者的队列,当消息到达队列由于没有消费者必然会过期成为死信,然后将死信发送给死信交换机,最后发送给消费者,这样就可以实现延迟消息功能。
注意:两组消息队列的bindingKey要保持一致。
死信交换机有什么作用呢?
收集那些因处理失败而被拒绝的消息
收集那些因队列满了而被拒绝的消息
收集因TTL(有效期)到期的消息
6.1.2.实现延迟消息
1.设置死信交换机、死信队列并编写监听程序:
//死信消息队列@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "dlx.queue",durable = "true"),exchange = @Exchange(name = "dlx.direct", type = ExchangeTypes.DIRECT),key = {"hi"}))public void listenDlxQueue(String msg){System.out.println("消费者接收到dlx.queue的消息:【" + msg + "】");}2.设置没有绑定监听器的消息队列:
@Configuration
public class NormalConfiguration {@Beanpublic DirectExchange directExchange(){return ExchangeBuilder.directExchange("normal.direct").build();}@Beanpublic Queue normalQueue(){return QueueBuilder.durable("normal.queue").deadLetterExchange("dlx.direct").build();}@Beanpublic Binding NormalQueueBinding(Queue normalQueue,DirectExchange directExchange){return BindingBuilder.bind(normalQueue).to(directExchange).with("hi");//后续通过.with()去指定bindingKey}
}3.通过消息后置处理器,当消息被消息转换器转换为Message对象后,为Message对象添加过期时间。
@Testpublic void testSendDelayMessaga(){String exchangeName = "normal.direct";//交换机名String message = "hello,hi";//消息//通过消息的后置处理器,当消息被消息转换器转换位Message对象后进行处理rabbitTemplate.convertAndSend(exchangeName, "hi", message, new MessagePostProcessor() {@Overridepublic Message postProcessMessage(Message message) throws AmqpException {//设置Message过期时间message.getMessageProperties().setExpiration("10000");return message;}});}注:当定义了消息转换器后不能再直接向MQ发送Message对象,因为Message对象会跳过消息转换器,导致消费者和生产者适用的不是同一个消息转换器,消费者那边会出现异常。
4.观察MQ控制台和idea控制台:
![]()
符合预期。
6.2.DelayExchange插件
基于死信队列虽然可以实现延迟消息,但是太麻烦了。因此RabbitMQ社区提供了一个延迟消息插件来实现相同的效果。
官方文档说明:
https://blog.rabbitmq.com/posts/2015/04/scheduling-messages-with-rabbitmq
这个插件可以将普通交换机改造为支持延迟消息功能的交换机,当消息投递到交换机后可以暂存一定时间,到期后再投递到队列。
6.2.1.安装插件
1.插件下载地址:
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
由于我们安装的MQ是3.8版本,因此这里下载3.8.17版本:
2.因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。
docker volume inspect mq-plugins结果如下:
[{"CreatedAt": "2024-06-19T09:22:59+08:00","Driver": "local","Labels": null,"Mountpoint": "/var/lib/docker/volumes/mq-plugins/_data","Name": "mq-plugins","Options": null,"Scope": "local"}
]插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。
接下来执行命令,安装插件:
docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange运行结果如下:
6.2.2.声明交换机
1.基于注解方式:
@RabbitListener(bindings = @QueueBinding(value = @Queue(name = "delay.queue", durable = "true"),exchange = @Exchange(name = "delay.direct", delayed = "true"),key = "delay"
))
public void listenDelayMessage(String msg){log.info("接收到delay.queue的延迟消息:{}", msg);
}2.基于@Bean的方式:
@Slf4j
@Configuration
public class DelayExchangeConfig {@Beanpublic DirectExchange delayExchange(){return ExchangeBuilder.directExchange("delay.direct") // 指定交换机类型和名称.delayed() // 设置delay的属性为true.durable(true) // 持久化.build();}@Beanpublic Queue delayedQueue(){return new Queue("delay.queue");}@Beanpublic Binding delayQueueBinding(){return BindingBuilder.bind(delayedQueue()).to(delayExchange()).with("delay");}
}两者都是通过将delay设置为true实现消息延迟。
3.发送消息时,必须通过x-delay属性设定延迟时间:
@Test
void testPublisherDelayMessage() {// 1.创建消息String message = "hello, delayed message";// 2.发送消息,利用消息后置处理器添加消息头rabbitTemplate.convertAndSend("delay.direct", "delay", message, new MessagePostProcessor() {@Overridepublic Message postProcessMessage(Message message) throws AmqpException {// 添加延迟消息属性message.getMessageProperties().setDelay(5000);return message;}});
}测试:

注意:由于延迟消息底层是有一个时钟在计时,如果同时有大量延迟消息存在,会导致CPU压力过高,所以要避免延迟消息扎堆,并发量高的项目尽量将延迟消息时间设置在1min内,并发量不高的项目尽量在30min以内。
6.3.取消超时订单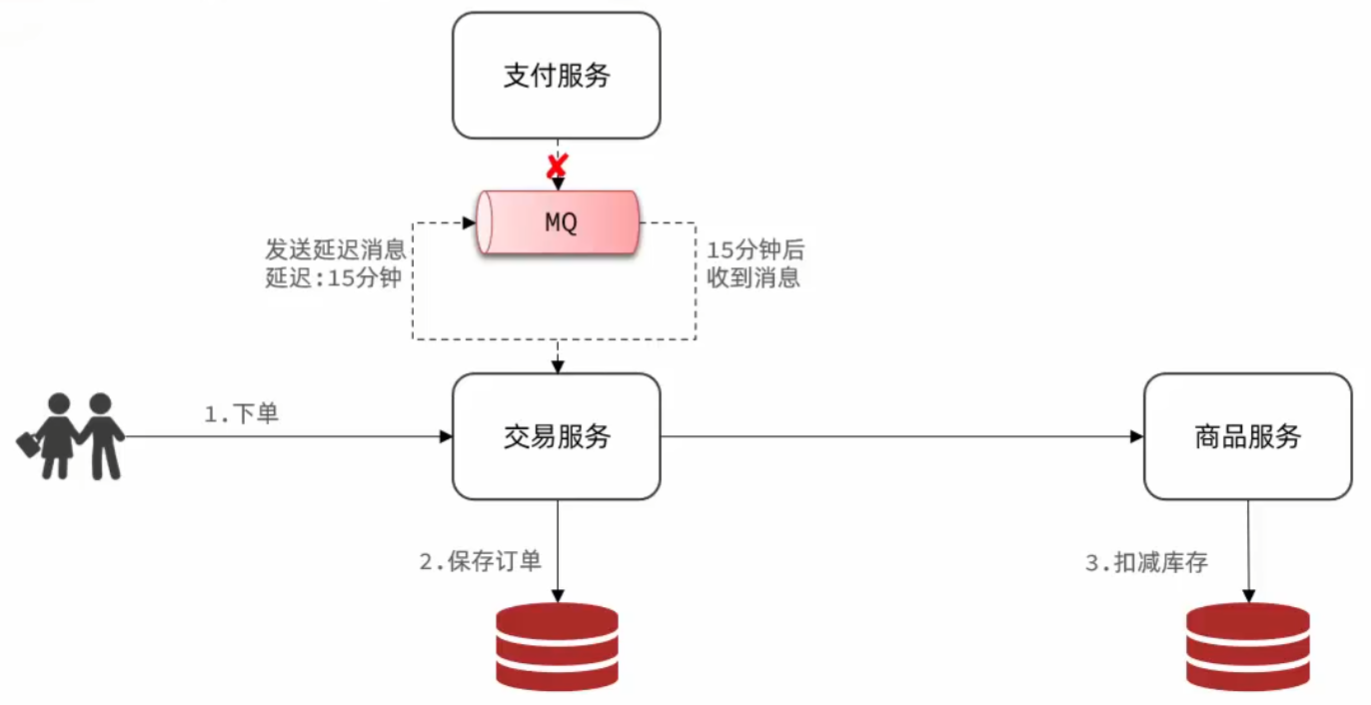
用户下单完成后,发送15分钟延迟消息,在15分钟后接收消息,检查支付状态:
- 已支付:更新订单状态为已支付
- 未支付:更新订单状态为关闭订单,恢复商品库存
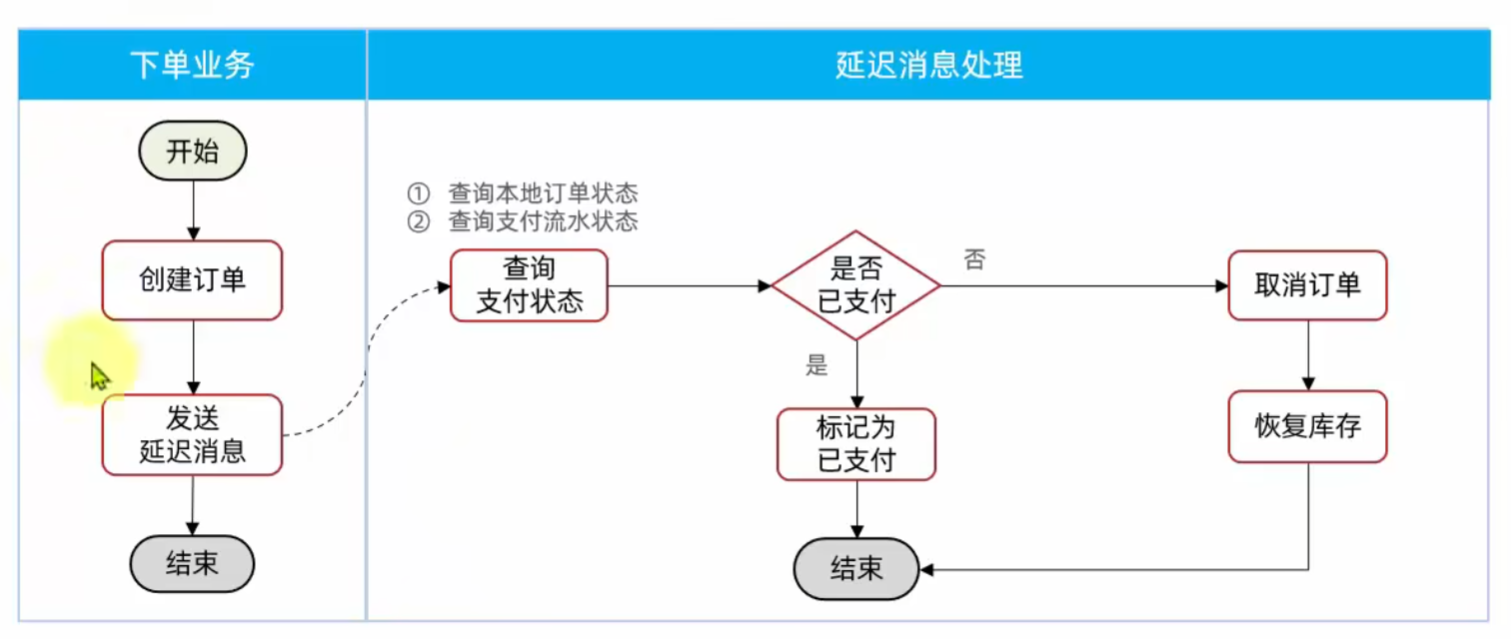
实现:定义延迟消息队列;设置监听器,查询支付流水,根据支付流水执行下一步。
1.定义延迟消息队列:
常量类定义消息队列名称
public interface MQConstants {String DELAY_EXCHANGE_NAME = "trade.delay.direct";//Ctrl+Shift+u,全大/小写String DELY_QUEUE_NAME = "trade.delay.order.queue";String DELY_ORDER_KEY = "delay.order.query";
}定义消息队列和消息监听器逻辑:
@Component
@RequiredArgsConstructor
@Slf4j
public class OrderDelayMessageListener {private final IOrderService orderService;private final PayClient payClient;@RabbitListener(bindings = @QueueBinding(value = @Queue(name = MQConstants.DELY_QUEUE_NAME),exchange = @Exchange(name = MQConstants.DELAY_EXCHANGE_NAME,delayed = "true",type = "direct"),key = MQConstants.DELY_ORDER_KEY))public void listenOrderDelayMessage(Long orderId){//1.查询本地订单状态Order order = orderService.getById(orderId);//2.检测订单状态,判断是否已支付if (order == null || order.getStatus()!=1){return;}//3.未支付,需要查询支付流水PayOrderDTO payOrder = payClient.queryPayOrderByBizOrderNo(orderId);//4.判断是否支付if (payOrder != null && payOrder.getStatus() == 3){//4.1.已支付,标记订单状态为已支付orderService.markOrderPaySuccess(orderId);}else {//4.2.未支付,取消订单,回复库存orderService.cancelOrder(orderId);}}
}
2.在原有业务基础上增加发送延迟消息功能:
//5.发送延迟消息,检测订单支付状态rabbitTemplate.convertAndSend(MQConstants.DELAY_EXCHANGE_NAME,MQConstants.DELY_ORDER_KEY,order.getId(),message -> {message.getMessageProperties().setDelay(30000);return message;});测试发现,即使把支付服务部分发送消息的代码注释掉,交易服务也能正常更新订单状态。
7.练习部分
7.1.取消订单
在处理超时未支付订单时,如果发现订单确实超时未支付,最终需要关闭该订单。
关闭订单需要完成两件事情:
将订单状态修改为已关闭
恢复订单中已经扣除的库存
1.定义取消订单方法:
@Overridepublic void cancelOrder(Long orderId) {//1.标记订单为已关闭Order order = new Order();order.setId(orderId);order.setStatus(5);updateById(order);//2.标记支付订单取消payClient.PayOrderStatusCancel(orderId);//3.恢复库存//3.1.获取订单商品id+numList<OrderDetail> orderDetails = detailService.lambdaQuery().eq(OrderDetail::getOrderId, orderId).list();Map<Long,Integer> itemNumMap = orderDetails.stream().collect(Collectors.toMap(OrderDetail::getItemId,OrderDetail::getNum));//3.2.回复库存itemClient.rebackStock(itemNumMap);}通过Fegin分别调用支付服务更新支付订单状态、调用商品服务恢复库存。
支付服务:
@ApiOperation("取消支付订单")@PutMapping("/biz/cancel/{orderId}")public void PayOrderStatusCancel(@PathVariable("orderId")Long orderId){payOrderService.lambdaUpdate().eq(PayOrder::getBizOrderNo,orderId).set(PayOrder::getPayOverTime, LocalDateTime.now()).set(PayOrder::getUpdateTime,LocalDateTime.now()).set(PayOrder::getIsDelete,false).set(PayOrder::getUpdater, UserContext.getUser()).set(PayOrder::getStatus,2).update();}商品服务:
@PostMapping("/stock/reback")public void rebackStock(@RequestBody Map<Long,Integer> itemNumMap){itemService.rebackStock(itemNumMap);}
@Overridepublic void rebackStock(Map<Long, Integer> itemNumMap) {if (itemNumMap.isEmpty()) {return;}// 转换为 List<Map>,适配 XML 中的参数List<Map<String, Object>> items = itemNumMap.entrySet().stream().map(entry -> {Map<String, Object> map = new HashMap<>();map.put("itemId", entry.getKey());map.put("num", entry.getValue());return map;}).collect(Collectors.toList());// 调用批量更新itemMapper.batchRecoverStock(items);}
<update id="batchRecoverStock"><foreach collection="items" separator=";" item="item">UPDATE itemSET stock = stock + #{item.num}WHERE id = #{item.itemId}</foreach></update>7.2.抽取MQ工具
MQ在企业开发中的常见应用我们就学习完毕了,除了收发消息以外,消息可靠性的处理、生产者确认、消费者确认、延迟消息等等编码还是相对比较复杂的。
因此,我们需要将这些常用的操作封装为工具,方便在项目中使用。
7.2.1.抽取共享配置
首先,我们需要在nacos中抽取RabbitMQ的共享配置,命名为shared-mq.yaml: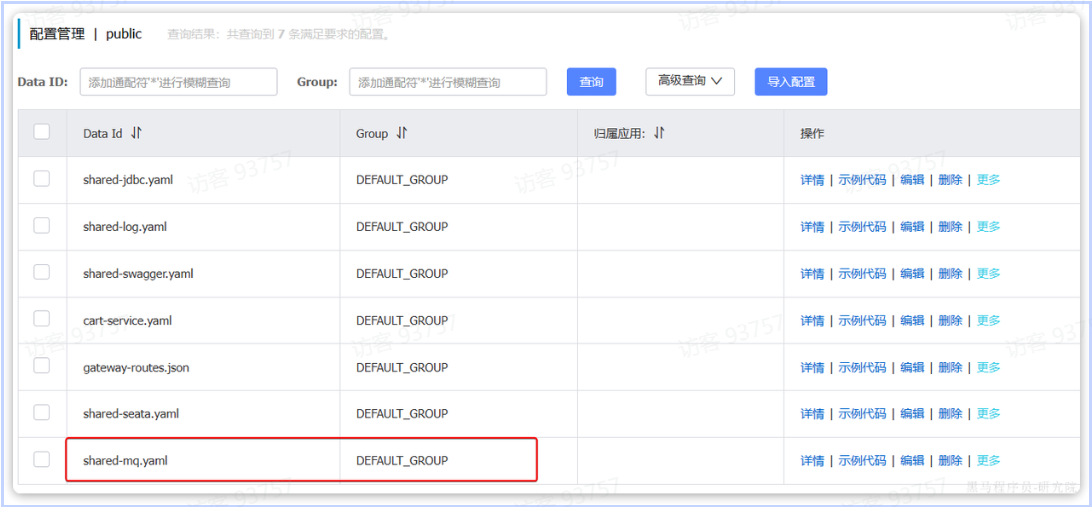 其中只包含mq的基础共享配置,内容如下:
其中只包含mq的基础共享配置,内容如下:
spring:rabbitmq:host: ${hm.mq.host:192.168.150.101} # 主机名port: ${hm.mq.port:5672} # 端口virtual-host: ${hm.mq.vhost:/hmall} # 虚拟主机username: ${hm.mq.un:hmall} # 用户名password: ${hm.mq.pw:123} # 密码7.2.2.引入依赖
在hm-common模块引入要用到的一些依赖,主要包括amqp、jackson。但是不要引入starter,因为我们希望可以让用户按需引入。
依赖如下:·
<!--AMQP依赖-->
<dependency><groupId>org.springframework.amqp</groupId><artifactId>spring-amqp</artifactId><scope>provided</scope>
</dependency>
<!--Spring整合Rabbit依赖-->
<dependency><groupId>org.springframework.amqp</groupId><artifactId>spring-rabbit</artifactId><scope>provided</scope>
</dependency>
<!--json处理-->
<dependency><groupId>com.fasterxml.jackson.dataformat</groupId><artifactId>jackson-dataformat-xml</artifactId><scope>provided</scope>
</dependency>注意:依赖的scope要选择provided,这样依赖仅仅是用作项目编译时不报错,真正运行时需要使用者自行引入依赖。
7.2.3.封装工具
在hm-common模块的com.hmall.common.utils包下新建一个RabbitMqHelper类:
@Slf4j
@RequiredArgsConstructor
public class RabbitMqHelper {private final RabbitTemplate rabbitTemplate;public void sendMessage(String exchange, String routingKey, Object msg){log.debug("准备发送消息,exchange:{}, routingKey:{}, msg:{}", exchange, routingKey, msg);rabbitTemplate.convertAndSend(exchange, routingKey, msg);}public void sendDelayMessage(String exchange, String routingKey, Object msg, int delay){rabbitTemplate.convertAndSend(exchange, routingKey, msg, message -> {message.getMessageProperties().setDelay(delay);return message;});}public void sendMessageWithConfirm(String exchange, String routingKey, Object msg, int maxRetries){log.debug("准备发送消息,exchange:{}, routingKey:{}, msg:{}", exchange, routingKey, msg);CorrelationData cd = new CorrelationData(UUID.randomUUID().toString(true));cd.getFuture().addCallback(new ListenableFutureCallback<>() {int retryCount;@Overridepublic void onFailure(Throwable ex) {log.error("处理ack回执失败", ex);}@Overridepublic void onSuccess(CorrelationData.Confirm result) {if (result != null && !result.isAck()) {log.debug("消息发送失败,收到nack,已重试次数:{}", retryCount);if(retryCount >= maxRetries){log.error("消息发送重试次数耗尽,发送失败");return;}CorrelationData cd = new CorrelationData(UUID.randomUUID().toString(true));cd.getFuture().addCallback(this);rabbitTemplate.convertAndSend(exchange, routingKey, msg, cd);retryCount++;}}});rabbitTemplate.convertAndSend(exchange, routingKey, msg, cd);}
}7.2.4.自动装配
最后,我们在hm-common模块的包下定义一个配置类: 将
将RabbitMqHelper注册为Bean:
@Configuration
@ConditionalOnClass(value = {MessageConverter.class, RabbitTemplate.class})
public class MqConfig {@Bean@ConditionalOnBean(ObjectMapper.class)public MessageConverter messageConverter(ObjectMapper mapper){// 1.定义消息转换器Jackson2JsonMessageConverter jackson2JsonMessageConverter = new Jackson2JsonMessageConverter(mapper);// 2.配置自动创建消息id,用于识别不同消息jackson2JsonMessageConverter.setCreateMessageIds(true);return jackson2JsonMessageConverter;}@Beanpublic RabbitMqHelper rabbitMqHelper(RabbitTemplate rabbitTemplate){return new RabbitMqHelper(rabbitTemplate);}
}注意:
由于hm-common模块的包名为com.hmall.common,与其它微服务的包名不一致,因此无法通过扫描包使配置生效。
为了让我们的配置生效,我们需要在项目的classpath下的META-INF/spring.factories文件中声明这个配置类:
内容如下:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.hmall.common.config.MyBatisConfig,\com.hmall.common.config.MqConfig,\com.hmall.common.config.MvcConfig至此,RabbitMQ的工具类和自动装配就完成了。