【完整源码+数据集+部署教程】【制造业&传送带】几何形状检测系统源码&数据集全套:改进yolo11-DGCST
背景意义
随着计算机视觉技术的快速发展,物体检测已成为人工智能领域的重要研究方向之一。尤其是在工业自动化、智能监控、无人驾驶等应用场景中,准确、快速地识别和分类物体的能力显得尤为重要。YOLO(You Only Look Once)系列模型因其高效的实时检测能力而受到广泛关注。近年来,YOLOv11作为该系列的最新版本,通过改进网络结构和算法,进一步提升了检测精度和速度。然而,针对特定几何形状的检测任务,现有模型在特征提取和分类精度上仍存在一定的局限性。
本研究旨在基于改进的YOLOv11模型,构建一个专门针对几何形状的检测系统。我们所使用的数据集包含3400张图像,涵盖了四种基本几何形状:圆形(Circulo)、正方形(Quadrado)、矩形(Retangulo)和三角形(Triangulo)。该数据集的单一类别设置,使得模型能够集中学习几何形状的特征,从而提高检测的准确性和效率。此外,几何形状的简单性和多样性为模型的训练提供了良好的基础,能够有效避免复杂背景对检测结果的干扰。
通过对YOLOv11模型的改进,我们期望在几何形状检测任务中实现更高的准确率和更快的处理速度。这不仅能够为相关领域的应用提供技术支持,还将推动物体检测技术在特定场景下的深入研究。随着几何形状检测系统的成功实现,我们相信其在教育、建筑、制造等行业的潜在应用将极大地促进相关领域的智能化进程,具有重要的理论价值和实际意义。
图片效果
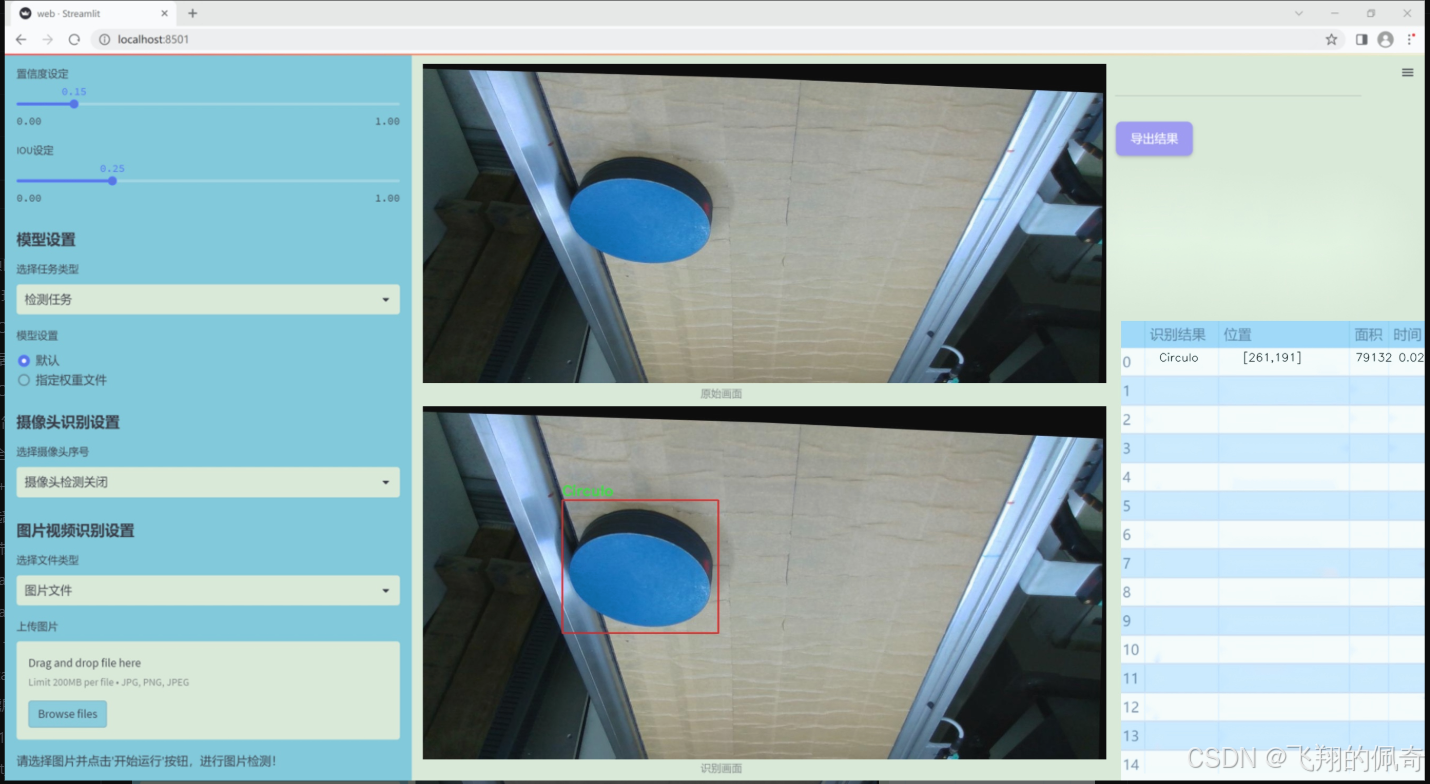
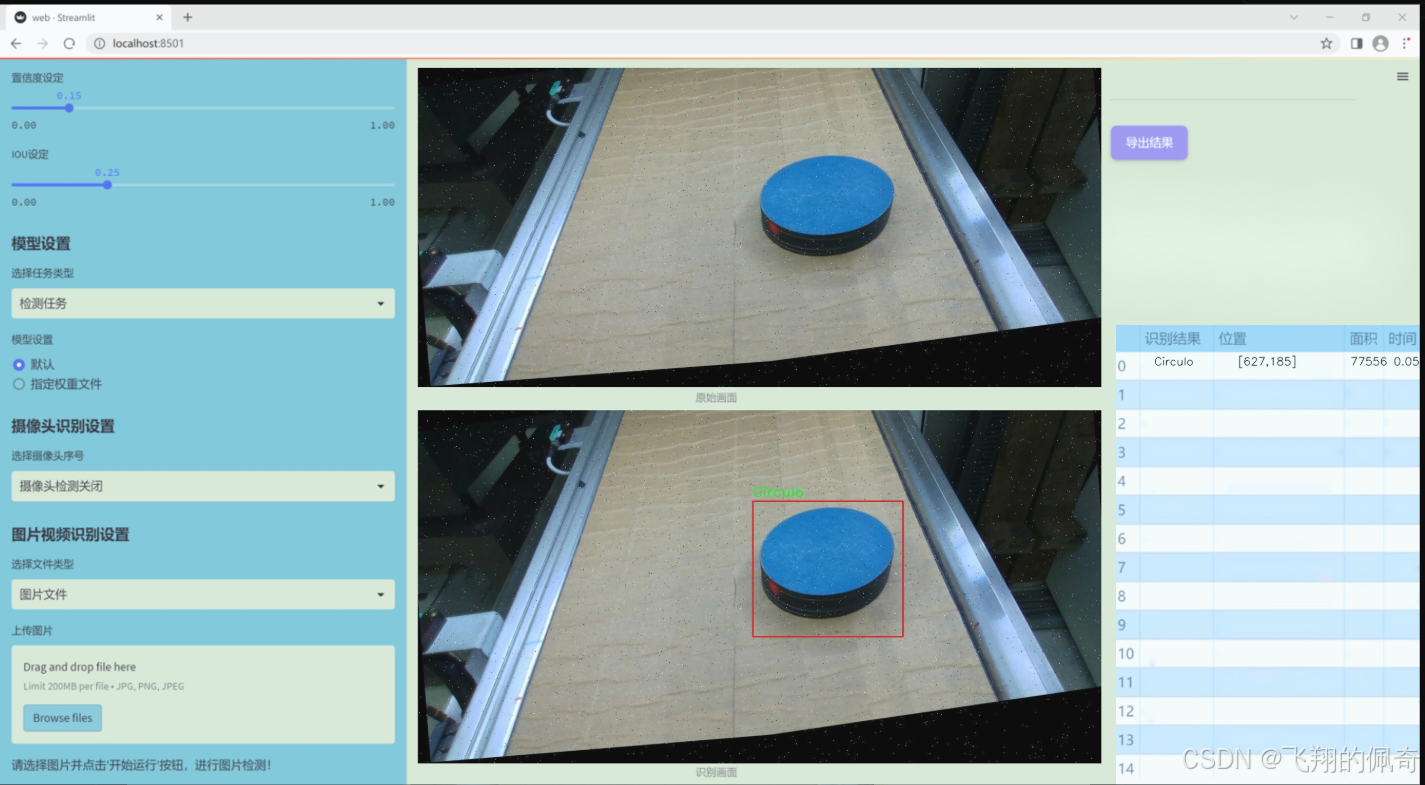
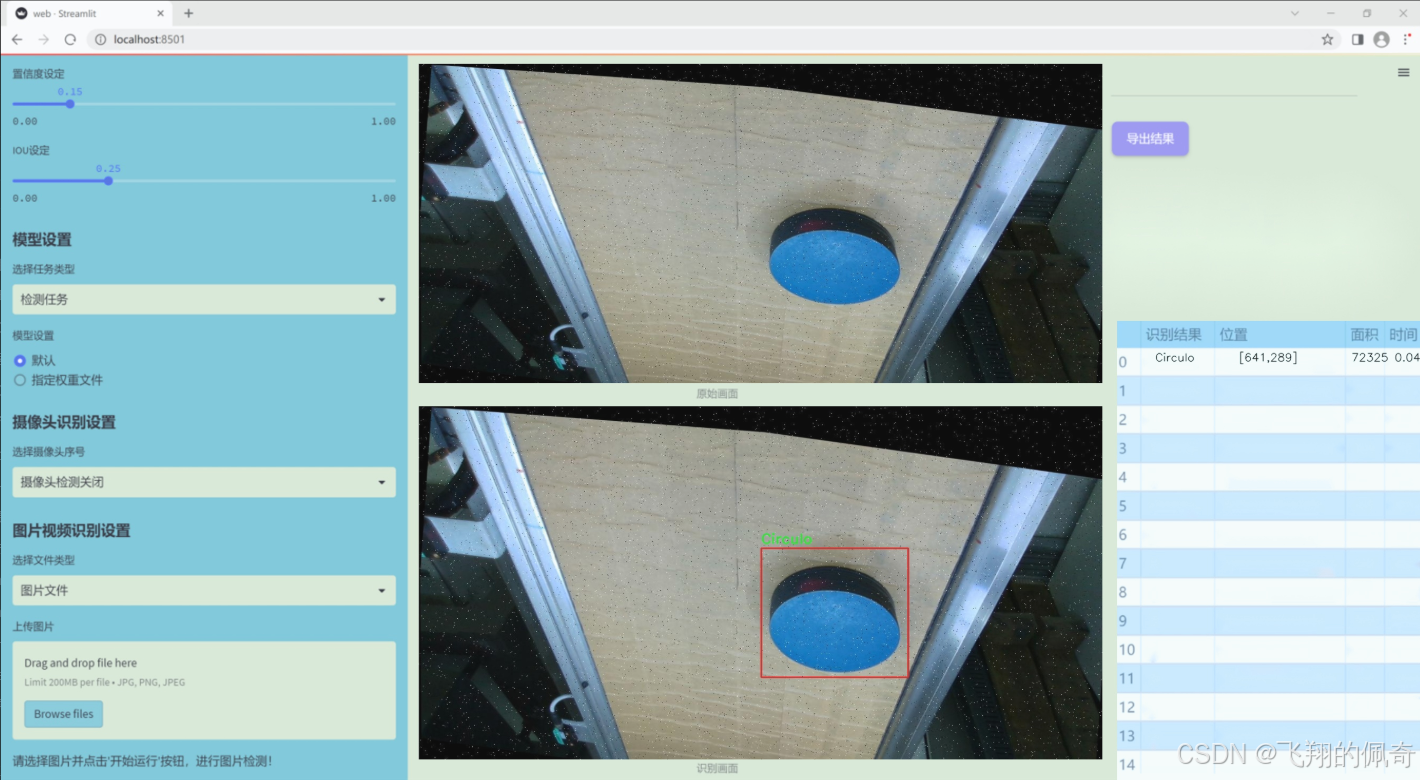
数据集信息
本项目所使用的数据集名为“aline”,旨在为改进YOLOv11的几何形状检测系统提供高质量的训练数据。该数据集包含三种几何形状类别,分别为“Circulo”(圆形)、“Quadrado”(正方形)和“Retangulo”(矩形),总类别数量为三。这些类别的选择不仅涵盖了基本的几何形状,也为算法的训练提供了多样性和挑战性,使得模型能够更好地识别和区分不同形状。
“aline”数据集的构建过程经过精心设计,确保了数据的多样性和代表性。每种几何形状在数据集中都有大量的样本,以便模型能够学习到形状的不同特征和变体。数据集中包含了各种角度、大小和背景的图像,这些因素都是影响形状识别准确性的关键。通过这种方式,数据集不仅提供了理想的训练条件,还能有效地提高模型在实际应用中的鲁棒性。
此外,数据集中的图像经过标注,确保每个样本的几何形状都被准确地框定和分类。这种精确的标注对于训练深度学习模型至关重要,因为它直接影响到模型的学习效果和最终的检测性能。通过使用“aline”数据集,研究人员能够在YOLOv11的基础上进行改进,提升其在几何形状检测任务中的表现。
总之,“aline”数据集为本项目提供了一个坚实的基础,支持了YOLOv11模型在几何形状检测领域的进一步研究与发展。通过对该数据集的深入分析和应用,期望能够推动形状识别技术的进步,并为相关领域的应用提供更为准确和高效的解决方案。





核心代码
以下是对代码中最核心部分的分析和详细注释:
import torch
import torch.nn.functional as F
def selective_scan_easy(us, dts, As, Bs, Cs, Ds, delta_bias=None, delta_softplus=False, return_last_state=False, chunksize=64):
“”"
选择性扫描函数,进行序列数据的处理。
参数:
us: 输入数据,形状为 (B, G * D, L)
dts: 时间增量,形状为 (B, G * D, L)
As: 权重矩阵,形状为 (G * D, N)
Bs: 权重矩阵,形状为 (B, G, N, L)
Cs: 权重矩阵,形状为 (B, G, N, L)
Ds: 可选的偏置项,形状为 (G * D)
delta_bias: 可选的偏置增量,形状为 (G * D)
delta_softplus: 是否使用softplus激活函数
return_last_state: 是否返回最后的状态
chunksize: 每次处理的序列长度
"""def selective_scan_chunk(us, dts, As, Bs, Cs, hprefix):"""处理单个块的选择性扫描。参数:us: 输入数据块,形状为 (L, B, G, D)dts: 时间增量块,形状为 (L, B, G, D)As: 权重矩阵,形状为 (G, D, N)Bs: 权重矩阵,形状为 (L, B, G, N)Cs: 权重矩阵,形状为 (L, B, G, N)hprefix: 前一个状态,形状为 (B, G, D, N)返回:ys: 输出结果,形状为 (L, B, G, D)hs: 状态,形状为 (L, B, G, D, N)"""ts = dts.cumsum(dim=0) # 计算时间增量的累积和Ats = torch.einsum("gdn,lbgd->lbgdn", As, ts).exp() # 计算A的指数scale = 1 # 缩放因子rAts = Ats / scale # 归一化duts = dts * us # 计算增量dtBus = torch.einsum("lbgd,lbgn->lbgdn", duts, Bs) # 计算B的增量hs_tmp = rAts * (dtBus / rAts).cumsum(dim=0) # 计算状态hs = hs_tmp + Ats * hprefix.unsqueeze(0) # 更新状态ys = torch.einsum("lbgn,lbgdn->lbgd", Cs, hs) # 计算输出return ys, hs# 数据类型设置
dtype = torch.float32
inp_dtype = us.dtype # 输入数据类型
has_D = Ds is not None # 检查Ds是否存在
if chunksize < 1:chunksize = Bs.shape[-1] # 设置块大小# 处理输入数据
dts = dts.to(dtype)
if delta_bias is not None:dts = dts + delta_bias.view(1, -1, 1).to(dtype) # 添加偏置
if delta_softplus:dts = F.softplus(dts) # 应用softplus激活函数# 调整输入数据的形状
Bs = Bs.unsqueeze(1) if len(Bs.shape) == 3 else Bs
Cs = Cs.unsqueeze(1) if len(Cs.shape) == 3 else Cs
B, G, N, L = Bs.shape
us = us.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
dts = dts.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
As = As.view(G, -1, N).to(dtype)
Bs = Bs.permute(3, 0, 1, 2).to(dtype)
Cs = Cs.permute(3, 0, 1, 2).to(dtype)
Ds = Ds.view(G, -1).to(dtype) if has_D else None
D = As.shape[1] # 获取状态维度oys = [] # 输出结果列表
hprefix = us.new_zeros((B, G, D, N), dtype=dtype) # 初始化前一个状态
for i in range(0, L, chunksize):ys, hs = selective_scan_chunk(us[i:i + chunksize], dts[i:i + chunksize], As, Bs[i:i + chunksize], Cs[i:i + chunksize], hprefix, )oys.append(ys) # 添加输出结果hprefix = hs[-1] # 更新前一个状态oys = torch.cat(oys, dim=0) # 合并输出结果
if has_D:oys = oys + Ds * us # 添加偏置项
oys = oys.permute(1, 2, 3, 0).view(B, -1, L) # 调整输出形状return oys.to(inp_dtype) if not return_last_state else (oys.to(inp_dtype), hprefix.view(B, G * D, N).float())
代码核心部分说明:
函数定义:selective_scan_easy 是一个选择性扫描的核心函数,处理输入数据和时间增量,并计算输出。
内部函数:selective_scan_chunk 是一个处理单个数据块的函数,计算状态和输出。
输入处理:对输入数据进行形状调整和类型转换,确保后续计算的正确性。
循环处理:通过循环处理每个数据块,逐步更新状态和输出结果。
返回值:根据参数选择返回输出结果或最后状态。
这段代码实现了一个复杂的序列处理逻辑,使用了张量运算和自动微分功能,适合用于深度学习模型中的序列数据处理。
这个文件 test_selective_scan_easy.py 是一个用于测试选择性扫描(Selective Scan)算法的实现。该算法主要用于处理序列数据,常见于时间序列分析和递归神经网络等领域。代码中包含了多个函数和类的定义,以及一些测试用例,以下是对代码的逐步分析和说明。
首先,文件引入了一些必要的库,包括 math、functools、torch、torch.nn.functional、pytest 和 einops。这些库提供了数学运算、函数式编程、深度学习操作、测试框架和张量重排等功能。
接下来,定义了一个名为 selective_scan_easy 的函数,它实现了选择性扫描的核心逻辑。该函数接受多个参数,包括输入张量 us 和 dts,以及权重矩阵 As、Bs、Cs 和 Ds。函数内部定义了一个嵌套函数 selective_scan_chunk,用于处理输入数据的一个块(chunk)。这个嵌套函数通过对输入数据进行累积和变换,计算出输出张量 ys 和隐藏状态 hs。
在 selective_scan_easy 函数中,首先对输入数据进行类型转换和形状调整,以确保它们符合预期的格式。然后,使用循环将输入数据分块处理,调用 selective_scan_chunk 函数,并将结果存储在列表中。最后,将所有块的结果拼接在一起,返回最终的输出。
随后,定义了一个名为 SelectiveScanEasy 的类,它继承自 torch.autograd.Function,用于实现自定义的前向和反向传播。该类的 forward 方法实现了选择性扫描的前向计算,backward 方法实现了反向传播的梯度计算。通过使用 torch.cuda.amp.custom_fwd 和 torch.cuda.amp.custom_bwd 装饰器,确保在混合精度训练时的性能优化。
在 selective_scan_easy_fwdbwd 函数中,封装了对 SelectiveScanEasy 类的调用,以便在需要时可以方便地进行前向和反向传播的计算。
接下来,定义了多个版本的选择性扫描函数,如 selective_scan_easyv2 和 selective_scan_easyv3,这些版本可能在实现细节上有所不同,旨在优化性能或适应不同的使用场景。
文件的最后部分包含了一个名为 test_selective_scan 的测试函数,它使用 pytest 框架进行单元测试。通过参数化的方式,测试函数可以验证不同输入条件下选择性扫描函数的正确性和性能。测试过程中,首先生成随机输入数据,然后调用选择性扫描函数和参考实现,比较它们的输出和梯度,确保它们在数值上足够接近。
总体而言,这个文件实现了选择性扫描算法的核心逻辑,并通过测试确保其正确性和性能。选择性扫描在处理序列数据时非常有用,尤其是在需要高效计算累积和的场景中。
10.2 afpn.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
from …modules.conv import Conv
定义基本的卷积块
class BasicBlock(nn.Module):
def init(self, filter_in, filter_out):
super(BasicBlock, self).init()
# 定义两个卷积层
self.conv1 = Conv(filter_in, filter_out, 3) # 第一个卷积层
self.conv2 = Conv(filter_out, filter_out, 3, act=False) # 第二个卷积层,不使用激活函数
def forward(self, x):residual = x # 保存输入以便后续残差连接out = self.conv1(x) # 通过第一个卷积层out = self.conv2(out) # 通过第二个卷积层out += residual # 添加残差return self.conv1.act(out) # 返回激活后的输出
定义上采样模块
class Upsample(nn.Module):
def init(self, in_channels, out_channels, scale_factor=2):
super(Upsample, self).init()
# 定义上采样的卷积层和上采样操作
self.upsample = nn.Sequential(
Conv(in_channels, out_channels, 1), # 1x1卷积
nn.Upsample(scale_factor=scale_factor, mode=‘bilinear’) # 双线性插值上采样
)
def forward(self, x):return self.upsample(x) # 直接返回上采样结果
定义下采样模块(2倍)
class Downsample_x2(nn.Module):
def init(self, in_channels, out_channels):
super(Downsample_x2, self).init()
# 定义2倍下采样的卷积层
self.downsample = Conv(in_channels, out_channels, 2, 2, 0)
def forward(self, x):return self.downsample(x) # 直接返回下采样结果
定义自适应特征融合模块(ASFF)
class ASFF_2(nn.Module):
def init(self, inter_dim=512):
super(ASFF_2, self).init()
self.inter_dim = inter_dim
compress_c = 8 # 压缩通道数
# 定义权重卷积层self.weight_level_1 = Conv(self.inter_dim, compress_c, 1)self.weight_level_2 = Conv(self.inter_dim, compress_c, 1)self.weight_levels = nn.Conv2d(compress_c * 2, 2, kernel_size=1, stride=1, padding=0)self.conv = Conv(self.inter_dim, self.inter_dim, 3) # 融合后的卷积层def forward(self, input1, input2):# 计算每个输入的权重level_1_weight_v = self.weight_level_1(input1)level_2_weight_v = self.weight_level_2(input2)# 合并权重并计算softmaxlevels_weight_v = torch.cat((level_1_weight_v, level_2_weight_v), 1)levels_weight = self.weight_levels(levels_weight_v)levels_weight = F.softmax(levels_weight, dim=1)# 进行特征融合fused_out_reduced = input1 * levels_weight[:, 0:1, :, :] + \input2 * levels_weight[:, 1:2, :, :]out = self.conv(fused_out_reduced) # 通过卷积层return out # 返回融合后的输出
定义特征金字塔网络(AFPN)
class AFPN_P345(nn.Module):
def init(self, in_channels=[256, 512, 1024], out_channels=256, factor=4):
super(AFPN_P345, self).init()
# 定义输入通道到输出通道的卷积层
self.conv0 = Conv(in_channels[0], in_channels[0] // factor, 1)
self.conv1 = Conv(in_channels[1], in_channels[1] // factor, 1)
self.conv2 = Conv(in_channels[2], in_channels[2] // factor, 1)
# 定义特征块self.body = BlockBody_P345([in_channels[0] // factor, in_channels[1] // factor, in_channels[2] // factor])# 定义输出卷积层self.conv00 = Conv(in_channels[0] // factor, out_channels, 1)self.conv11 = Conv(in_channels[1] // factor, out_channels, 1)self.conv22 = Conv(in_channels[2] // factor, out_channels, 1)def forward(self, x):x0, x1, x2 = x # 拆分输入x0 = self.conv0(x0) # 通过卷积层x1 = self.conv1(x1)x2 = self.conv2(x2)out0, out1, out2 = self.body([x0, x1, x2]) # 通过特征块out0 = self.conv00(out0) # 输出卷积out1 = self.conv11(out1)out2 = self.conv22(out2)return [out0, out1, out2] # 返回输出
代码说明:
BasicBlock:定义了一个基本的卷积块,包含两个卷积层和残差连接。
Upsample 和 Downsample:定义了上采样和下采样的模块,分别使用卷积和插值方法。
ASFF_2:实现了自适应特征融合的功能,计算输入特征的权重并进行融合。
AFPN_P345:构建了特征金字塔网络的基础结构,负责输入特征的处理和输出特征的生成。
以上是核心代码的简化和注释,旨在帮助理解其基本结构和功能。
这个程序文件 afpn.py 实现了一个用于图像处理的深度学习模型,主要包括了不同的网络结构和模块,尤其是自适应特征金字塔网络(AFPN)。该文件使用了 PyTorch 框架,定义了一系列的类和方法来构建网络。
首先,文件引入了一些必要的库和模块,包括 torch 和 torch.nn,以及自定义的卷积和块模块。接着,定义了一些基本的网络块,如 BasicBlock、Upsample、Downsample_x2、Downsample_x4、Downsample_x8 等,这些模块负责特征图的卷积、上采样和下采样操作。
BasicBlock 类是一个基本的残差块,包含两个卷积层和一个残差连接。Upsample 和 Downsample 类则实现了特征图的上采样和下采样,分别使用了不同的卷积和插值方法。
接下来,定义了多个自适应特征融合模块(ASFF),如 ASFF_2、ASFF_3 和 ASFF_4,这些模块通过计算输入特征图的权重并进行加权融合,以实现不同尺度特征的有效结合。每个 ASFF 模块都包含多个卷积层和一个 softmax 操作,用于生成融合后的特征图。
然后,BlockBody_P345 和 BlockBody_P2345 类实现了特定的网络结构,这些结构通过组合多个基本块和 ASFF 模块来处理不同尺度的特征图。BlockBody_P345_Custom 和 BlockBody_P2345_Custom 类则允许用户自定义块类型,以便在不同的应用场景中使用。
AFPN_P345 和 AFPN_P2345 类是网络的主要实现,分别处理三个和四个输入通道的特征图。它们通过一系列卷积层和自定义的块体来处理输入特征,并最终输出经过处理的特征图。这些类在初始化时还包括了权重初始化的操作,以确保网络在训练开始时具有良好的性能。
最后,AFPN_P345_Custom 和 AFPN_P2345_Custom 类提供了进一步的自定义选项,允许用户选择不同的块类型来构建网络。
整体而言,这个程序文件实现了一个灵活且可扩展的深度学习模型,适用于图像分割、目标检测等任务,通过自适应特征融合技术来提高模型的性能。
10.3 kan_conv.py
以下是保留的核心代码部分,并添加了详细的中文注释:
import torch
import torch.nn as nn
class KANConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, input_dim, output_dim, spline_order, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, grid_size=5, base_activation=nn.GELU, grid_range=[-1, 1], dropout=0.0):
super(KANConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.spline_order = spline_order # 样条阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组数self.ndim = ndim # 维度self.grid_size = grid_size # 网格大小self.base_activation = base_activation() # 基础激活函数self.grid_range = grid_range # 网格范围# 初始化dropout层self.dropout = Noneif dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查分组参数的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 初始化基础卷积层self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 初始化样条卷积层self.spline_conv = nn.ModuleList([conv_class((grid_size + spline_order) * input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 初始化层归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 初始化PReLU激活函数self.prelus = nn.ModuleList([nn.PReLU() for _ in range(groups)])# 生成网格h = (self.grid_range[1] - self.grid_range[0]) / grid_sizeself.grid = torch.linspace(self.grid_range[0] - h * spline_order,self.grid_range[1] + h * spline_order,grid_size + 2 * spline_order + 1,dtype=torch.float32)# 使用Kaiming均匀分布初始化卷积层权重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')for conv_layer in self.spline_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')def forward_kan(self, x, group_index):# 处理输入并进行基础卷积base_output = self.base_conv[group_index](self.base_activation(x))x_uns = x.unsqueeze(-1) # 扩展维度以进行样条操作target = x.shape[1:] + self.grid.shape # 计算目标形状grid = self.grid.view(*list([1 for _ in range(self.ndim + 1)] + [-1, ])).expand(target).contiguous().to(x.device)# 计算样条基bases = ((x_uns >= grid[..., :-1]) & (x_uns < grid[..., 1:])).to(x.dtype)# 计算多阶样条基for k in range(1, self.spline_order + 1):left_intervals = grid[..., :-(k + 1)]right_intervals = grid[..., k:-1]delta = torch.where(right_intervals == left_intervals, torch.ones_like(right_intervals),right_intervals - left_intervals)bases = ((x_uns - left_intervals) / delta * bases[..., :-1]) + \((grid[..., k + 1:] - x_uns) / (grid[..., k + 1:] - grid[..., 1:(-k)]) * bases[..., 1:])bases = bases.contiguous()bases = bases.moveaxis(-1, 2).flatten(1, 2) # 调整基的形状spline_output = self.spline_conv[group_index](bases) # 进行样条卷积x = self.prelus[group_index](self.layer_norm[group_index](base_output + spline_output)) # 归一化和激活if self.dropout is not None:x = self.dropout(x) # 应用dropoutreturn xdef forward(self, x):# 将输入按组分割split_x = torch.split(x, self.inputdim // self.groups, dim=1)output = []for group_ind, _x in enumerate(split_x):y = self.forward_kan(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone())y = torch.cat(output, dim=1) # 合并输出return y
代码说明
KANConvNDLayer类:这是一个自定义的卷积层,支持多维卷积(1D、2D、3D),并结合了样条基的卷积操作。
初始化方法:设置卷积层、归一化层、激活函数和dropout等参数,并进行相应的初始化。
forward_kan方法:实现了具体的前向传播逻辑,包括基础卷积、样条基的计算、样条卷积和激活。
forward方法:将输入数据按组分割,分别进行前向传播,然后合并输出。
这个程序文件定义了一个名为 KANConvNDLayer 的神经网络层,主要用于实现一种新的卷积操作,支持多维输入(如1D、2D、3D)。该层的设计灵感来源于样条插值,结合了卷积操作和归一化层,旨在提高模型的表达能力和训练效果。
在 KANConvNDLayer 的构造函数中,首先初始化了一些参数,包括输入和输出维度、样条的阶数、卷积核大小、步幅、填充、扩张率、分组数等。通过这些参数,用户可以灵活地配置卷积层的行为。构造函数还会检查分组数是否为正整数,并确保输入和输出维度可以被分组数整除,以保证每个组的输入和输出维度一致。
接下来,构造函数创建了基础卷积层和样条卷积层的模块列表。基础卷积层使用传入的卷积类(如 nn.Conv1d、nn.Conv2d 或 nn.Conv3d)构建,而样条卷积层则根据样条的阶数和网格大小构建。每个组都有自己的归一化层和激活函数(使用 PReLU 激活函数)。
程序还定义了一个网格,用于样条计算。网格的范围和大小由用户指定,并根据样条的阶数进行扩展。权重初始化使用 Kaiming 均匀分布,以便在训练开始时获得更好的性能。
forward_kan 方法实现了前向传播的核心逻辑。首先对输入进行基础激活,然后通过基础卷积层进行线性变换。接着,计算样条基函数,并通过样条卷积层进行处理。最后,经过归一化和激活函数处理后,输出结果。如果设置了 dropout,则在输出前应用 dropout。
forward 方法负责处理输入数据的分组,将输入张量按照组的数量进行切分,并对每个组调用 forward_kan 方法进行处理,最后将所有组的输出拼接在一起。
此外,程序还定义了三个子类 KANConv1DLayer、KANConv2DLayer 和 KANConv3DLayer,分别用于处理一维、二维和三维数据。这些子类通过调用父类的构造函数,传入相应的卷积类和归一化类,简化了多维卷积层的创建过程。
整体来看,这个程序文件提供了一种灵活且强大的卷积层实现,适用于多种类型的输入数据,能够有效地结合卷积和样条插值的优点。
10.4 kaln_conv.py
以下是代码中最核心的部分,并附上详细的中文注释:
from functools import lru_cache
import torch
import torch.nn as nn
from torch.nn.functional import conv3d, conv2d, conv1d
class KALNConvNDLayer(nn.Module):
def init(self, conv_class, norm_class, conv_w_fun, input_dim, output_dim, degree, kernel_size,
groups=1, padding=0, stride=1, dilation=1, dropout: float = 0.0,
ndim: int = 2):
super(KALNConvNDLayer, self).init()
# 初始化参数self.inputdim = input_dim # 输入维度self.outdim = output_dim # 输出维度self.degree = degree # 多项式的阶数self.kernel_size = kernel_size # 卷积核大小self.padding = padding # 填充self.stride = stride # 步幅self.dilation = dilation # 膨胀self.groups = groups # 分组卷积的组数self.base_activation = nn.SiLU() # 基础激活函数self.conv_w_fun = conv_w_fun # 卷积权重函数self.ndim = ndim # 数据的维度(1D, 2D, 3D)self.dropout = None # Dropout层初始化为None# 如果dropout大于0,则根据维度选择相应的Dropout层if dropout > 0:if ndim == 1:self.dropout = nn.Dropout1d(p=dropout)elif ndim == 2:self.dropout = nn.Dropout2d(p=dropout)elif ndim == 3:self.dropout = nn.Dropout3d(p=dropout)# 检查分组卷积的有效性if groups <= 0:raise ValueError('groups must be a positive integer')if input_dim % groups != 0:raise ValueError('input_dim must be divisible by groups')if output_dim % groups != 0:raise ValueError('output_dim must be divisible by groups')# 创建分组卷积层self.base_conv = nn.ModuleList([conv_class(input_dim // groups,output_dim // groups,kernel_size,stride,padding,dilation,groups=1,bias=False) for _ in range(groups)])# 创建分组归一化层self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])# 多项式权重的形状poly_shape = (groups, output_dim // groups, (input_dim // groups) * (degree + 1)) + tuple(kernel_size for _ in range(ndim))# 初始化多项式权重self.poly_weights = nn.Parameter(torch.randn(*poly_shape))# 使用Kaiming均匀分布初始化卷积层的权重for conv_layer in self.base_conv:nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')nn.init.kaiming_uniform_(self.poly_weights, nonlinearity='linear')@lru_cache(maxsize=128) # 使用LRU缓存以避免重复计算Legendre多项式
def compute_legendre_polynomials(self, x, order):# 计算Legendre多项式P0 = x.new_ones(x.shape) # P0 = 1if order == 0:return P0.unsqueeze(-1)P1 = x # P1 = xlegendre_polys = [P0, P1]# 使用递推关系计算更高阶的多项式for n in range(1, order):Pn = ((2.0 * n + 1.0) * x * legendre_polys[-1] - n * legendre_polys[-2]) / (n + 1.0)legendre_polys.append(Pn)return torch.concatenate(legendre_polys, dim=1)def forward_kal(self, x, group_index):# 前向传播过程base_output = self.base_conv[group_index](x) # 基础卷积输出# 将输入x归一化到[-1, 1]范围x_normalized = 2 * (x - x.min()) / (x.max() - x.min()) - 1 if x.shape[0] > 0 else x# 如果有Dropout,则应用Dropoutif self.dropout is not None:x_normalized = self.dropout(x_normalized)# 计算归一化后的x的Legendre多项式legendre_basis = self.compute_legendre_polynomials(x_normalized, self.degree)# 使用多项式权重进行卷积运算poly_output = self.conv_w_fun(legendre_basis, self.poly_weights[group_index],stride=self.stride, dilation=self.dilation,padding=self.padding, groups=1)# 合并基础输出和多项式输出,进行归一化和激活x = base_output + poly_outputif isinstance(self.layer_norm[group_index], nn.LayerNorm):orig_shape = x.shapex = self.layer_norm[group_index](x.view(orig_shape[0], -1)).view(orig_shape)else:x = self.layer_norm[group_index](x)x = self.base_activation(x)return xdef forward(self, x):# 前向传播,处理输入xsplit_x = torch.split(x, self.inputdim // self.groups, dim=1) # 按组分割输入output = []for group_ind, _x in enumerate(split_x):y = self.forward_kal(_x.clone(), group_ind) # 对每个组进行前向传播output.append(y.clone())y = torch.cat(output, dim=1) # 合并所有组的输出return y
代码核心部分说明:
KALNConvNDLayer:这是一个通用的卷积层类,支持任意维度的卷积(1D, 2D, 3D)。它使用Legendre多项式进行特征变换,并通过分组卷积来处理输入数据。
构造函数:初始化卷积层、归一化层和多项式权重,并进行必要的参数检查。
compute_legendre_polynomials:计算Legendre多项式,使用LRU缓存来提高效率。
forward_kal:实现前向传播逻辑,计算基础卷积输出和多项式输出,并进行归一化和激活。
forward:处理输入数据,按组进行分割和处理,最终合并输出。
该代码实现了一个灵活的卷积层,可以用于多种深度学习任务,尤其是在处理具有多维特征的数据时。
这个程序文件定义了一个名为 KALNConvNDLayer 的神经网络层,旨在实现一种基于 Legendre 多项式的卷积操作。该层支持多维卷积(1D、2D 和 3D),并通过多项式权重来增强卷积的表达能力。以下是对代码的详细说明。
首先,文件导入了必要的库,包括 torch 和 torch.nn,以及 functools 中的 lru_cache,后者用于缓存计算结果以提高性能。接着,定义了 KALNConvNDLayer 类,它继承自 nn.Module,并在初始化方法中接收多个参数,包括卷积类型、归一化类型、输入和输出维度、卷积核大小、分组数、填充、步幅、扩张、丢弃率等。
在初始化过程中,程序会进行一些基本的参数检查,例如确保分组数是正整数,并且输入和输出维度能够被分组数整除。接着,程序创建了一个包含多个卷积层和归一化层的模块列表,具体数量由分组数决定。每个卷积层的输入和输出通道数都是输入维度和输出维度除以分组数。随后,程序还初始化了一个多项式权重参数,用于存储多项式的系数。
compute_legendre_polynomials 方法用于计算 Legendre 多项式,使用递归关系生成指定阶数的多项式,并利用 lru_cache 来缓存计算结果,以避免重复计算。这个方法的输入是一个张量和多项式的阶数,输出是计算得到的多项式。
forward_kal 方法是该层的核心计算部分。它首先对输入进行卷积操作,然后将输入归一化到 [-1, 1] 的范围,以便进行稳定的 Legendre 多项式计算。接着,调用 compute_legendre_polynomials 方法计算多项式基,并通过多项式权重进行线性变换。最后,将卷积输出和多项式输出相加,并进行归一化和激活操作。
forward 方法则是对输入进行分组处理,并调用 forward_kal 方法对每个分组进行计算,最后将所有分组的输出拼接在一起,形成最终的输出。
此外,文件还定义了三个具体的卷积层类:KALNConv3DLayer、KALNConv2DLayer 和 KALNConv1DLayer,分别用于处理三维、二维和一维卷积。这些类通过调用 KALNConvNDLayer 的构造函数,传入相应的卷积和归一化类型来实现。
整体来看,这个程序文件实现了一种灵活且强大的卷积层,能够通过多项式的方式增强卷积的表达能力,并且支持多种维度的输入数据。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻