论文学习_LLM4Decompile: Decompiling Binary Code with Large Language Models
标题: LLM4Decompile: Decompiling Binary Code with Large Language Models (Hanzhuo Tan,2024)
作者: Hanzhuo Tan, Qi Luo, Jing Li, Yuqun Zhang
期刊: Arxiv
摘要
反编译旨在将二进制代码转换为高级源代码,但传统工具如Ghidra往往生成可读性和可执行性较差的结果。受大语言模型(LLM)技术进展的启发,我们提出LLM4Decompile——首个且规模最大的开源LLM系列(1.3B至33B),专门用于二进制代码反编译任务。我们优化了LLM训练流程,并推出LLM4Decompile-End模型以实现直接二进制反编译。实验表明,该模型在HumanEval和ExeBench基准测试中的可重执行率显著超越GPT-4o和Ghidra超过100%。此外,我们改进了标准代码优化方法,微调出LLM4DecompileRef模型,能够有效优化Ghidra的反编译结果,在LLM4Decompile-End基础上进一步实现16.2%的性能提升。LLM4Decompile系列模型展现了LLM彻底改变二进制代码反编译领域的潜力,在提升代码可读性与可执行性方面取得突破性进展,同时能与传统工具形成互补以实现最优效果。
首个反编译大模型LLM4Decompile,并微调出反编译优化模型LLM4DecompileRef。
引言
反编译是将机器代码或二进制代码转换为高级编程语言的逆向过程,其在漏洞识别、恶意软件研究以及遗留软件迁移等逆向工程任务中具有重要作用。由于编译过程中存在信息丢失问题(尤其是变量名称等细节信息以及循环和条件判断等基础结构),反编译面临显著挑战。为应对这些挑战,目前已开发出多种反编译工具,其中Ghidra和IDA Pro最为常用。尽管这些工具能够将二进制代码还原为高级伪代码,但其输出结果通常缺乏可读性与可重执行性,而这对于遗留软件迁移和安全插装等应用场景至关重要。
现有反编译器虽然可以将二进制转换为伪代码,但存在可读性和可重执行性问题。
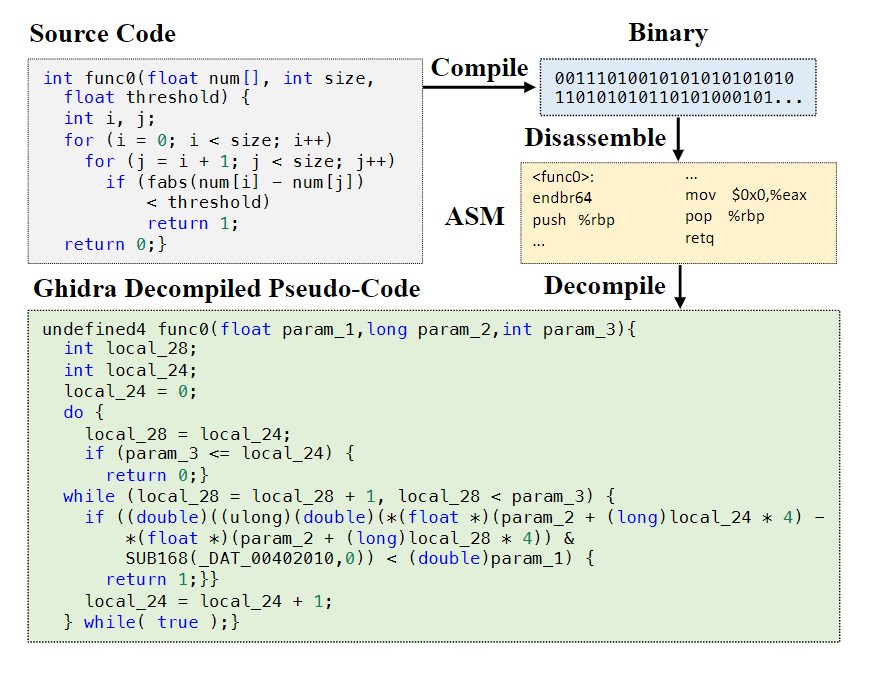
上图展示了从C语言源代码到二进制文件、汇编代码(ASM)以及Ghidra反编译伪代码的转换过程。该伪代码中,原有的嵌套for循环结构被替换为缺乏直观性的do-while循环嵌套while循环的组合形式。此外,类似num[i]的数组索引被反编译为复杂的指针运算表达式*(float *)(param_2 + (long)local_24 * 4)。反编译结果还存在语法错误,例如函数返回类型被转换为未定义类型undefined4。总体而言,传统反编译工具往往会丧失高级语言特有的语法明晰性,且无法保证语法正确性,即使对资深开发者而言也为其重构算法逻辑带来显著挑战。
LLMs的最新进展显著改善了代码反编译流程。目前基于LLM的反编译主要存在两种方法——优化反编译(Refined-Decompile)和端到端反编译(End2end-Decompile)。其中,优化反编译通过提示LLM对传统反编译工具的输出结果进行优化修正。然而,由于LLM主要针对高级编程语言进行优化,其在处理二进制数据时可能效果欠佳。端到端反编译则通过微调LLM来实现直接对二进制文件进行反编译。但此前开源领域对该方法的应用受限于仅使用约2亿参数的小型模型和有限的训练语料库。相比之下,研究表明采用更庞大数据集训练的较大模型能显著提升性能表现。
研究动机:研究表明采用更庞大数据集训练的较大模型能显著提升性能表现。
为克服现有研究的局限性,我们提出LLM4Decompile——首个且规模最大的开源大语言模型系列,其参数量覆盖1.3B至33B,专门针对二进制代码反编译任务进行训练。据我们所知,尚无研究在此深度上探索基于LLM的反编译能力提升,或引入如此大规模的大语言模型。基于端到端反编译方法,我们引入三个关键步骤:数据增强、数据清洗和两阶段训练,以优化大语言模型训练流程,并推出LLM4Decompile-End模型实现直接二进制反编译。具体而言,我们的LLM4Decompile-End-6.7B模型在HumanEval数据集上实现45.4%的成功反编译率,在ExeBench数据集上达到18.0%,远超Ghidra和GPT-4o超过100%的性能表现。
此外,我们通过分析Ghidra反编译流程的效率,改进优化反编译策略,通过增强和筛选数据来微调LLM4Decompile-Ref模型,该模型擅长优化Ghidra的输出结果。实验表明增强型优化反编译方法具有更高的性能上限,相较LLM4Decompile-End模型实现16.2%的提升。同时,我们评估了模型在软件保护常用混淆条件下被潜在滥用的风险。研究发现无论是我们的方法还是Ghidra,均无法有效反编译混淆后的代码,这缓解了关于未经授权使用该技术进行知识产权侵权的担忧。
相关工作
将可执行二进制文件还原为源代码形式的实践(即反编译)已历经数十年研究。传统反编译方法依赖于分析程序的控制流与数据流,并采用模式匹配技术,例如Hex-Rays Ida Pro和Ghidra等工具所示。这些系统试图在程序控制流图中识别对应于条件语句或循环等标准编程结构的模式。然而,此类反编译过程的输出结果往往只是汇编代码的类源代码表示形式,包括将变量直接映射为寄存器、使用goto语句及其他底层操作,而非还原原始高级语言结构。这种输出虽然功能上常与原始代码相似,但可读性差且通常不可重新执行。受神经机器翻译的启发,研究人员将反编译重新定义为一种翻译任务,即将机器级指令转换为可读的源代码。该领域的早期尝试使用循环神经网络进行反编译,并辅以纠错技术来提升输出质量。
受大语言模型成功实践的推动,研究人员已采用LLM进行反编译,主要形成两种技术路径——优化反编译与端到端反编译。其中,优化反编译通过提示LLM优化传统工具(如Ghidra或IDA Pro)的输出结果。例如,DeGPT通过降低24.4%认知负荷显著提升Ghidra输出可读性,而DecGPT通过将错误信息融入优化流程,使IDA Pro输出的可重执行率提高至75%以上。然而这类方法普遍忽视了一个关键事实:LLM主要针对高级编程语言设计,其处理二进制文件的有效性尚未得到充分验证。另一方面,端到端反编译通过微调LLM直接实现二进制文件反编译。早期开源模型BTC及近期开发的Slade均采用约2亿参数量的语言模型进行反编译微调。虽未开源,Nova则开发了十亿参数规模的二进制LLM并进行反编译微调。这导致该领域最大的开源模型参数量仍局限在2亿级别。而现有研究证明,采用更广泛数据集训练的大规模模型能显著提升性能表现。
因此,我们的目标是推出首个且最全面的开源大模型反编译系列LLM4Decompile,旨在系统性提升大语言模型的反编译能力。我们首先优化端到端反编译方法,训练出LLM4Decompile-End模型,验证其直接反编译二进制文件的有效性;随后改进优化反编译框架,将大模型与Ghidra深度融合,增强传统工具以实现最优效能。
研究内容
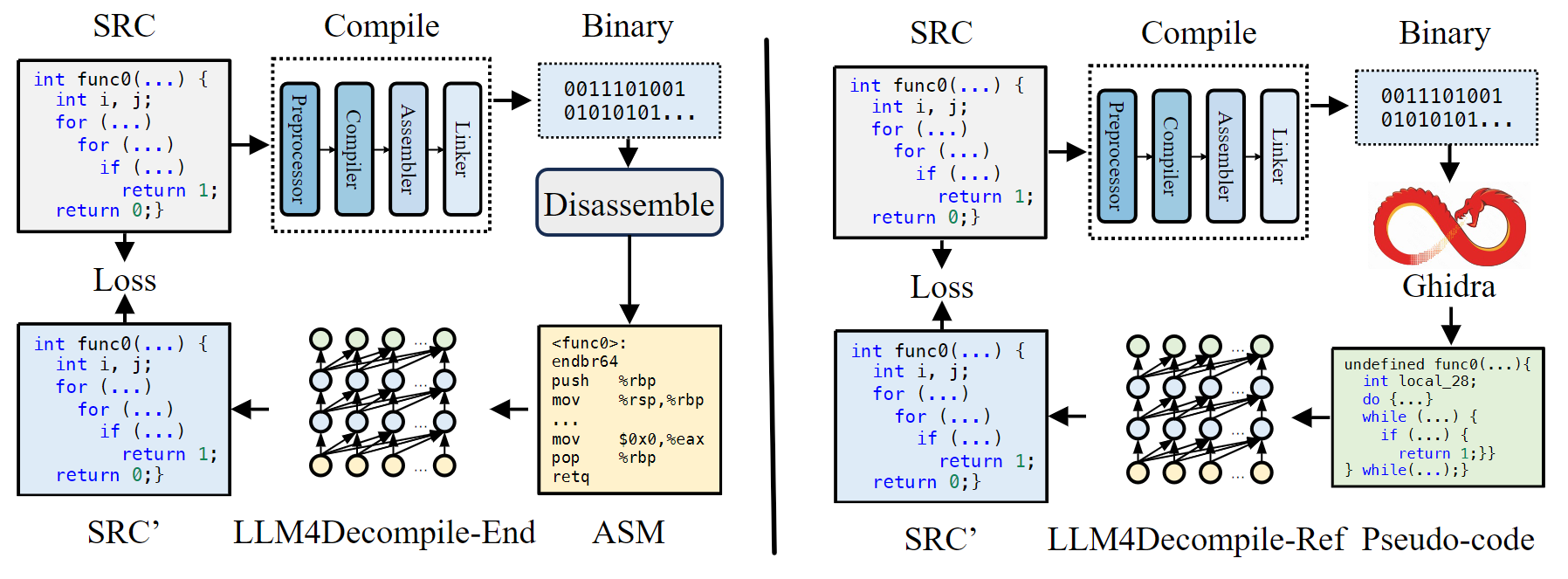
LLM4Decompile-End 是一种为直接反编译二进制文件而优化的大模型训练策略。该模型专门针对反编译过程中的挑战进行了优化,以提高反编译的准确性和效率。通过训练大规模的语言模型(LLM),LLM4Decompile-End 能够自动处理和优化从二进制文件反编译得到的代码,进而提高反编译工具的性能。该模型的设计旨在使得反编译的过程更加精确,并能够理解并修正可能出现的错误或不完整的反编译结果。
LLM4Decompile-Ref 是在 LL4Decompile-End 基础上进行微调的优化模型,旨在进一步改善 Ghidra 反编译结果的质量。该模型通过对 Ghidra 输出的高级伪代码进行优化,从而增强其可读性和准确性。具体而言,LLM4Decompile-Ref 针对 Ghidra 生成的伪代码进行微调,使其能够解决可能存在的语法错误或可读性问题,同时保留底层逻辑。该优化能够显著提升 Ghidra 在面对复杂二进制文件时的反编译效果,从而使分析者在理解二进制代码时更为轻松。