零基础新手小白快速了解掌握服务集群与自动化运维(十五)Redis模块-Redis集群理论、手动部署
Redis集群理论
常见的几种模式对比
| 模式 | 版本 | 优点 | 缺点 |
|---|---|---|---|
| 主从模式 | redis2.8之前 | 1、解决数据备份问题 2、做到读写分离,提高服务器性能 | 1、master故障,无法自动故障转移,需人工介入 2、master无法实现动态扩容 |
| 哨兵模式 | redis2.8级之后的 模式 | 1、Master状态监测 2、master节点故障,自动切换主从,故障自愈 3、所有slave从节点,随之更改新的master节点 | 1、slave节点下线,sentinel不会对其进行故障转移,连接从节点的客户端因为无法获取到新的可用从节点 2、master无法实行动态扩容 |
| redis cluster 模式 | redis3.0版本之后 | 1、有效的解决了redis在分布式方面的需求 2、遇到单机内存,并发和流量瓶颈等问题时,可采用 Cluster方案达到负载均衡的目的 3、可实现动态扩容 4、P2P模式,无中心化 5、通过Gossip协议同步节点信息 6、自动故障转移、Slot迁移中数据可用 7、自动分割数据到不同的节点上 8、整个集群的部分节点失败或者不可达的情况下能够继 续处理命令 | 1、架构比较新,最佳实践较少 2、为了性能提高,客户端需要缓存路由表信息 3、节点发现、reshard操作不够自动化 4、不支持处理多个keys的命令,因为这需要在不同的节点间移动数据 5、Redis集群不像单机Redis那样支持多数据库功能,集群只使用默认的0号数据库,并且不能使用SELECT index命令 |
一、redis cluster 是什么
Redis集群是一个由多个主从节点群组成的分布式服务集群,它具有复制、高可用和分片特性。Redis集群不需要sentinel哨兵也能完成节点移除和故障转移的功能。需要将每个节点设置成集群模式,这种集群模式没有中心节点,可水平扩展,据官方文档称可以线性扩展到上万个节点(官方推荐不超过1000个节点)。redis集群的性能和高可用性均优于之前版本的哨兵模式,且集群配置非常简单。redis集群的运用主要是针对海量数据+高并发+高可用的场景。
二、集群架构图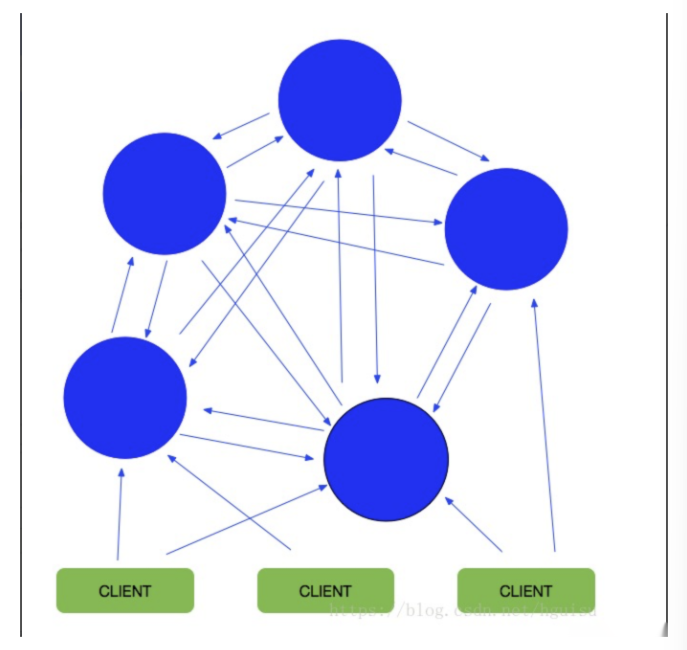
在这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作
三、集群原理图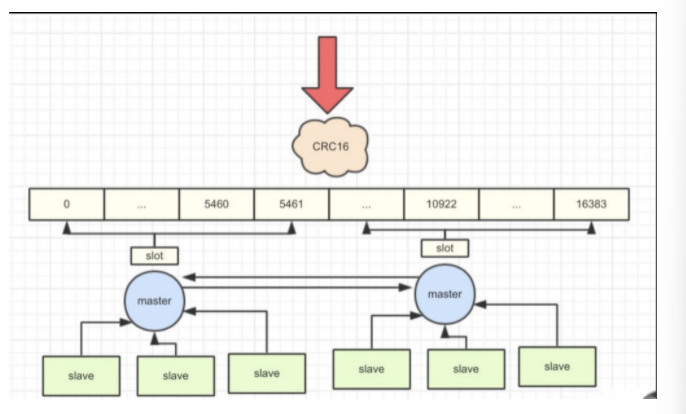
介绍:
对象保存到redis之前先经过CRC16哈希到一个指定的Node上(这个过程即redis cluster的分片),集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。一个Key到底属于哪个Slot由 (HASH_SLOT = CRC16(key) mod 16384) 决定。只有master节点会被分配槽位,slave节点不会分配槽位。
四、集群通信
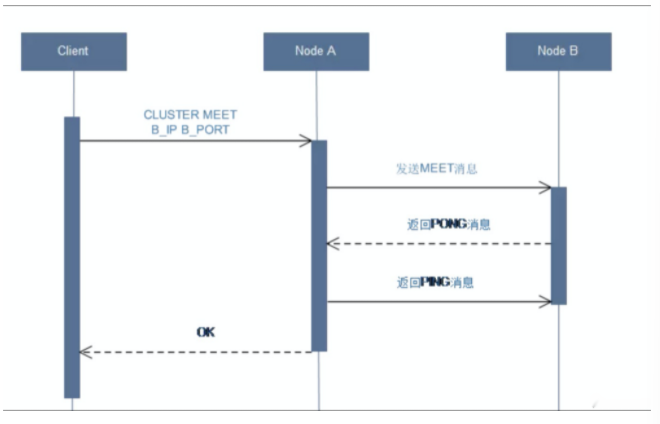
1)集群发现:MEET
最开始时,每个redis实例自己是一个集群,我们通过cluster meet让各个节点互相“握手”,需要续建一个真正可工作的集群,我们必须将各个节点连接起来,构成一个包含多个节点的集群。连接各个节点的工作使用CLUSTER MEET命令来完成。
CLUSTER MEET命令实现:
节点A会为节点B创建一个clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。
节点A根据CLUSTER MEET命令给定的IP地址和端口号,向节点B发送一条MEET消息。
节点B接收到节点A发送的MEET消息,节点B会为节点A创建一个clusterNode结构,并将该结构添加到自己的clusterState.nodes字典里面。
节点B向节点A返回一条PONG消息。
节点A将受到节点B返回的PONG消息,通过这条PONG消息节点A可以知道节点B已经成功的接收了自己发送的MEET消息。
之后,节点A将向节点B返回一条PING消息。
节点B将接收到的节点A返回的PING消息,通过这条PING消息节点B可以知道节点A已经成功的接收到了自己返回的PONG消息,握手完成。
之后,节点A会将节点B的信息通过Gossip协议传播给集群中的其他节点,让其他节点也与节点B进行握手,最终,经过一段时间后,节点B会被集群中的所有节点认识。
2)gossip协议
gossip协议包含多种消息,包含ping、pong、meet、fail等
meet:某个节点在内部发送了一个gossip meet 消息给新加入的节点,通知那个节点去加入我们的集群。然后新节点就会加入到集群的通信中
ping:每个节点都会频繁给其它节点发送 ping,其中包含自己的状态还有自己维护的集群元数据,互相通过 ping 交换元数据
pong:ping 和 meet消息的返回响应,包含自己的状态和其它信息,也用于信息广播和更新
fail:某个节点判断另一个节点 fail 之后,就发送 fail 给其它节点,通知其它节点说这个节点已宕机
五、集群概念
1)多slave选举
选新主的过程基于Raft协议选举方式来实现的
当从节点发现自己的主节点进行已下线状态时,从节点会广播一条CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,要求所有收到这条消息,并且具有投票权的主节点向这个从节点投票
如果一个主节点具有投票权,并且这个主节点尚未投票给其他从节点,那么主节点将向要求投票的从节点返回一条,CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,表示这个主节点支持从节点成为新的主节点
每个参与选举的从节点都会接收CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息,并根据自己收到了多少条这种消息来统计自己获得了多少主节点的支持
如果集群里有N个具有投票权的主节点,那么当一个从节点收集到大于等于集群N/2+1张支持票时,这个从节点就成为新的主节点
如果在一个选举周期没有从能够收集到足够的支持票数,那么集群进入一个新的选举周期,并再次进行选主,直到选出新的主节点为止
2)slot(槽)
Redis Cluster中有一个16384长度的槽的概念,他们的编号为0、1、2、3……16382、16383。这个槽是一个虚拟的槽,并不是真正存在的。正常工作的时候,Redis Cluster中的每个Master节点都会负责一部分的槽,当有某个key被映射到某个Master负责的槽,那么这个Master负责为这个key提供服务,至于哪个Master节点负责哪个槽,这是可以由用户指定的,也可以在初始化的时候自动生成(redis-trib.rb脚本)。这里值得一提的是,在Redis Cluster中,只有Master才拥有槽的所有权,如果是某个Master的slave,这个slave只负责槽的使用,但是没有所有权。
3)数据分片
在Redis Cluster中,拥有16384个slot,这个数是固定的,存储在Redis Cluster中的所有的键都会被映射到这些slot中。数据库中的每个键都属于这16384个哈希槽的其中一个,集群使用公式CRC16(key) % 16384来计算键key属于哪个槽,其中CRC16(key)语句用于计算键key的CRC16校验和。集群中的每个节点负责处理一部分哈希槽。
4)请求重定向
由于每个节点只负责部分slot,以及slot可能从一个节点迁移到另一节点,造成客户端有可能会向错误的节点发起请求。因此需要有一种机制来对其进行发现和修正,这就是请求重定向。有两种不同的重定向场景:
MOVED错误
请求的key对应的槽不在该节点上,节点将查看自身内部所保存的哈希槽到节点ID的映射记录, 节点回复一个MOVED错误。
需要客户端进行再次重试
ASK错误(一般发生在数据迁移的过程中)
请求的key对应的槽目前的状态属于MIGRATING状态,并且当前节点找不到这个key了,节点回 复ASK错误。ASK会把对应槽的IMPORTING节点返回给你,告诉你去IMPORTING的节点尝试找找。
客户端进行重试首先发送ASKING命令,节点将为客户端设置一个一次性的标志(flag),使得 客户端可以执行一次针对IMPORTING状态的槽的命令请求,然后再发送真正的命令请求。
不必更新客户端所记录的槽至节点的映射。
5)数据迁移
当槽x从Node A向Node B迁移时,Node A和Node B都会有这个槽x,Node A上槽x的状态设置为MIGRATING,Node B上槽x的状态被设置为IMPORTING。
MIGRATING状态
如果key存在则成功处理
如果key不存在,则返回客户端ASK,客户端根据ASK首先发送ASKING命令到目标节点,然后发送请求的命令到目标节点
当key包含多个命令
如果都存在则成功处理
如果都不存在,则返回客户端ASK
如果一部分存在,则返回客户端TRYAGAIN,通知客户端稍后重试,这样当所有的 key都迁移完毕的时候客户端重试请求的时候回得到ASK,然后经过一次重定向就 可以获取这批键
此时不刷新客户端中node的映射关系
IMPORTING状态
如果key不在该节点上,会被MOVED重定向,刷新客户端中node的映射关系
如果是ASKING命令则命令会被执行,key不在迁移的节点已经被迁移到目标的节点
Key不存在则新建
6)故障转移
当从节点发现自己的主节点变为已下线(FAIL)状态时,便尝试进Failover,以期成为新的主。
以下是故障转移的执行步骤:
从下线主节点的所有从节点中选中一个从节点
被选中的从节点执行SLAVEOF NO ONE命令,成为新的主节点
新的主节点会撤销所有对已下线主节点的槽指派,并将这些槽全部指派给自己
新的主节点对集群进行广播PONG消息,告知其他节点已经成为新的主节点
新的主节点开始接收和处理槽相关的请求
集群slots必须完整才能对外提供服务
当redis.conf的配置cluster-require-full-coverage为no时,表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,如果为yes则集群不可用。
六、集群健康检查机制
集群的每个节点都会相互发送一个活跃的ping包,当ping包确认返回的时间超过node_timeout的时间,我们认为节点失效
当然,当节点在等待时间超过一半node_timeout的时间还没有收到目标节点对于ping包的回复的时候,就会立马尝试重连该节点,这个机制可以确保链接都保证有效,所以节点之间的失效链接都不会导致错误的失效报告
节点从正常状态到fail状态,需要收集每个节点对不正常节点(B)的确认:1)当节点(A)发送的ping包没有返回,此时将B节点的状态信息标记为(PFAIL)状态,然后将信息发送到集群的其它节点,同理当A收集本地有关B状态的信息,当大多数主节点认为B节点是PFAIL状态时,节点A将标记B的状态为FAIL状态,然后向所有的可达节点发送这个消息
当大多数主节点都将B节点标示为FAIL状态时,B节点才最终被集群标记为FAIL状态,此时B1(B的从节点)提升为主节点提供服务
本质上来说,FAIL 标识只是用来触发从节点提升(slave promotion)算法的安全部分。理论上一个从节点会在它的主节点不可达的时候独立起作用并且启动从节点提升程序,然后等待主节点来拒绝认可该提升(如果主节点对大部分节点恢复连接)。PFAIL -> FAIL 的状态变化、弱协议、强制在集群的可达部分用最短的时间传播状态变更的 FAIL 消息,这些东西增加的复杂性有实际的好处。由于这种机制,如果集群处于错误状态的时候,所有节点都会在同一时间停止接收写入操作,这从使用 Redis 集群的应用的角度来看是个很好的特性。还有非必要的选举,是从节点在无法访问主节点的时候发起的,若该主节点能被其他大多数主节点访问的话,这个选举会被拒绝掉
七、注意事项
redis master 宕机,恢复后不会自动切为主
扩容redis cluster如果我们大量使用redis cluster的话,有一个痛点就是扩容的机器加入集群的时候,分配主从。现在只能使用命令去操作,非常的凌乱。而且如果redis cluster是线上集群或者是有数据的话,极其容易造成丢数据,或者扩容是hang住等..隐患
redis cluster 从节点支持可读的前提下得在执行readonly=yes后执行,程序读取从节点时也需要执行。一次连接需要执行一次,客户端关闭即失效。
redis cluster 启动必须以绝对路径的方式启动,如果不用绝对路径启动,会产生新的nodes.conf 文件,集群的主从对应关系就会变乱,从而导致集群奔溃,如下是正确的启动方式
cd /opt/yidian/redis-cluster/6379/ && nohup /usr/local/bin/redis-server /opt/yidian/redis-cluster/6379/redis-6379.conf &八、业务使用Redis Cluster注意事项
| 操作 | 业务侧需改造内容 | 示例 | 说明 |
|---|---|---|---|
| 批量操作 | 需要保证批量操作的key在同一个slot中 | mset {test4}:test4 6 {test4}:test8 10 | 1.示例中的key是{type}:keyword格式,当key中包含{type}的时候,会使用type进行hash运算去判断slot,keyword不影响运算结果。 2.示例中的test4和test8不在同一个slot,但是这两个slot分配给了同一个server。 |
| 事务操作 | 需要保证事务中的key在同一个slot中 | MULTI set {test4}:test4 14 get {test4}:test4 EXEC | |
| Lua脚本 | 需要保证Lua脚本中的key在同一个slot中 | EVAL "return {KEYS[1],KEYS[2]}" 2 {test4}:key1 {test4}:key2 | |
| PipeLine | 需要保证PipeLine中的key在同一台Server上 | Jedis jedis = new Jedis("10.138.20.141", 6379); Pipeline pipelined = jedis.pipelined(); pipelined.set("test4","pipelineTest4"); pipelined.set("test8","pipelineTest8"); List<Object> objects = pipelined.syncAndReturnAll(); | |
| 代码控制 | 连接方式和命令执行的依赖需要改变 | JedisCluster jedisCluster = new JedisCluster(new HostAndPort("10.138.20.141", 6379)); jedisCluster.set("test4","abcd"); | 1.cluster需要连接到这个key所在的节点上,才能进行操作。 2.一般都会有封装好的依赖包,例如Jedis(Java) |
| 多DB | 不支持多DB | select命令禁用 |
Redis Cluster 手动部署
一、环境规划
| 主机名 | IP地址 | 端口 | 描述 |
|---|---|---|---|
| redis-master | 192.168.166.9 | 6379 | redis-master01 |
| 6381 | redis-master02 | ||
| 6383 | redis-master03 | ||
| redis-slave | 192.168.166.9 | 6380 | redis-slave01 |
| 6382 | redis-slave02 | ||
| 6384 | redis-slave03 |
二、基础环境
1、创建配置目录
mkdir /etc/redis
mv /etc/redis.conf /etc/redis/6379.conf
cd /etc/redis
cat 6379.com
bind 192.168.166.9
protected-mode no
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes
supervised systemd
pidfile /var/run/redis_6379.pid
loglevel notice
logfile /var/log/redis/redis.log
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename "dump.rdb"
dir /var/lib/redis
replica-serve-stale-data yes
replica-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
replica-priority 100
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
replica-lazy-flush no
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
stream-node-max-bytes 4096
stream-node-max-entries 100
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit replica 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
dynamic-hz yes
aof-rewrite-incremental-fsync yes
rdb-save-incremental-fsync yes
2、生成配置文件
[root@localhost redis]# for i in {6380..6384};do cp ./6379.conf ${i}.conf ;done
[root@localhost redis]# ls
6379.conf 6380.conf 6381.conf 6382.conf 6383.conf 6384.conf3、修改监听端口
[root@localhost redis]# for i in {6380..6384};do sed -i "s/port 6379/port ${i}/" ./${i}.conf;done
[root@localhost redis]# for i in {6380..6384};do grep "^port" ./${i}.conf;done
port 6380
port 6381
port 6382
port 6383
port 63844、修改数据目录
[root@localhost redis]# for i in {6379..6384};do sed -i "s#dir /var/lib/redis#dir /var/lib/redis/${i}#" ./${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do grep "^di" ./${i}.conf;done
dir /var/lib/redis/6379
dir /var/lib/redis/6380
dir /var/lib/redis/6381
dir /var/lib/redis/6382
dir /var/lib/redis/6383
dir /var/lib/redis/63845、修改日志目录
[root@localhost redis]# for i in {6379..6384};do sed -i "s#logfile /var/log/redis/redis.log#logfile /var/log/redis/${i}.log#" ./${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do grep "^logfile" ./${i}.conf;done
logfile /var/log/redis/6379.log
logfile /var/log/redis/6380.log
logfile /var/log/redis/6381.log
logfile /var/log/redis/6382.log
logfile /var/log/redis/6383.log
logfile /var/log/redis/6384.log6、修改PID文件目录
[root@localhost redis]# for i in {6379..6384};do sed -i "s#pidfile /var/run/redis_6379.pid#pidfile /var/run/redis/${i}.pid#" ${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do grep "^pidfile" ${i}.conf;done
pidfile /var/run/redis/6379.pid
pidfile /var/run/redis/6380.pid
pidfile /var/run/redis/6381.pid
pidfile /var/run/redis/6382.pid
pidfile /var/run/redis/6383.pid
pidfile /var/run/redis/6384.pid7、修改保护模式
[root@localhost redis]# for i in {6379..6384};do sed -i "s#protected-mode yes#protected-mode no#" ${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do grep "^protected-mode" ${i}.conf;done
protected-mode no
protected-mode no
protected-mode no
protected-mode no
protected-mode no
protected-mode no8、修改进程运行模式
[root@localhost redis]# for i in {6379..6384};do sed -i "s#daemonize no#daemonize yes#" ${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do grep "^daemonize" ${i}.conf;done
daemonize yes
daemonize yes
daemonize yes
daemonize yes
daemonize yes
daemonize yes9、修改监听地址
[root@localhost redis]# for i in {6379..6384};do sed -i "s#bind 127.0.0.1#bind 192.168.166.9#" ${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do grep "^bind" ${i}.conf;done
bind 192.168.166.9
bind 192.168.166.9
bind 192.168.166.9
bind 192.168.166.9
bind 192.168.166.9
bind 192.168.166.910、生成集群配置
[root@localhost ~]# cd /var/lib/redis/
[root@localhost redis]# mkdir {6379..6384}
[root@localhost redis]# ls
6379 6380 6381 6382 6383 6384
[root@localhost ~]# cd /var/run/
[root@localhost run]# mkdir redis
[root@localhost run]# cd /etc/redis
[root@localhost redis]# for i in {6379..6384};do echo -e "cluster-enabled yes\ncluster-config-file nodes-${i}.conf\ncluster-node-timeout 15000" >> ${i}.conf;done
[root@localhost redis]# for i in {6379..6384};do tail -3 ${i}.conf;done
cluster-enabled yes
cluster-config-file nodes-6379.conf
cluster-node-timeout 15000
cluster-enabled yes
cluster-config-file nodes-6380.conf
cluster-node-timeout 15000
cluster-enabled yes
cluster-config-file nodes-6381.conf
cluster-node-timeout 15000
cluster-enabled yes
cluster-config-file nodes-6382.conf
cluster-node-timeout 15000
cluster-enabled yes
cluster-config-file nodes-6383.conf
cluster-node-timeout 15000
cluster-enabled yes
cluster-config-file nodes-6384.conf
cluster-node-timeout 15000
11、启动服务
[root@localhost redis]# for((i=6379;i<=6384;i++));do redis-server /etc/redis/${i}.conf;done
[root@localhost redis]# netstat -anptu | grep redis
tcp 0 0 192.168.166.9:16380 0.0.0.0:* LISTEN 3154/redis-server 1
tcp 0 0 192.168.166.9:16381 0.0.0.0:* LISTEN 3156/redis-server 1
tcp 0 0 192.168.166.9:16382 0.0.0.0:* LISTEN 3160/redis-server 1
tcp 0 0 192.168.166.9:16383 0.0.0.0:* LISTEN 3166/redis-server 1
tcp 0 0 192.168.166.9:16384 0.0.0.0:* LISTEN 3170/redis-server 1
tcp 0 0 192.168.166.9:6379 0.0.0.0:* LISTEN 3150/redis-server 1
tcp 0 0 192.168.166.9:6380 0.0.0.0:* LISTEN 3154/redis-server 1
tcp 0 0 192.168.166.9:6381 0.0.0.0:* LISTEN 3156/redis-server 1
tcp 0 0 192.168.166.9:6382 0.0.0.0:* LISTEN 3160/redis-server 1
tcp 0 0 192.168.166.9:6383 0.0.0.0:* LISTEN 3166/redis-server 1
tcp 0 0 192.168.166.9:6384 0.0.0.0:* LISTEN 3170/redis-server 1
tcp 0 0 192.168.166.9:16379 0.0.0.0:* LISTEN 3150/redis-server 1 三、构建集群
以下操作需要登录某个节点的redis数据库
1、将其他节点加入集群
[root@localhost redis]# redis-cli -h 192.168.166.9
192.168.166.9:6379> CLUSTER MEET 192.168.166.9 6380
OK
192.168.166.9:6379> CLUSTER MEET 192.168.166.9 6381
OK
192.168.166.9:6379> CLUSTER MEET 192.168.166.9 6382
OK
192.168.166.9:6379> CLUSTER MEET 192.168.166.9 6383
OK
192.168.166.9:6379> CLUSTER MEET 192.168.166.9 6384
OK
########或者终端执行如下指令#####
for i in {6380..6384};do redis-cli -h 192.168.166.9 -p 6379 cluster meet 192.168.166.9 $i;done2、分配slot
也是在规划谁是master节点
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6379 cluster addslots {0..5461}
OK
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6381 cluster addslots {5462..10922}
OK
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6383 cluster addslots {10923..16383}
OK3、建立主从关系
查看所有群集节点
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6379 cluster nodes
69ed2c9d99ac83e52851d67e2597927142f47ebf 192.168.166.9:6381 master - 0 1709263044558 5 connected 5462-10922
c3f6d16785ab3de1b88f8ddb8e5bea3e7c6de5d4 192.168.166.9:6382 master - 0 1709263043555 0 connected
a8b96d687e681dd4c606e6959468b2bc1a5b0b1f 192.168.166.9:6379 myself,master - 0 0 2 connected 0-5461
bbdc8d353e2afa87d3d1430eecbbe436206fd213 192.168.166.9:6384 master - 0 1709263042550 4 connected
20a5e5bb03ab273fea553b3ccafeba01e83a6eb2 192.168.166.9:6380 master - 0 1709263043052 1 connected
98fe02fecd9f99d2d220cbf3de921063a9413428 192.168.166.9:6383 master - 0 1709263045565 3 connected 10923-16383
查看master节点ID
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6380 cluster replicate a8b96d687e681dd4c606e6959468b2bc1a5b0b1f
OK
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6382 cluster replicate 69ed2c9d99ac83e52851d67e2597927142f47ebf
OK
[root@localhost redis]# redis-cli -h 192.168.166.9 -p 6384 cluster replicate 98fe02fecd9f99d2d220cbf3de921063a9413428
OK
4、集群操作命令
| 命令 | 作用 |
|---|---|
| cluster info | 打印集群的信息 |
| cluster nodes | 列出集群当前已知的所有节点( node),以及这些节点的相关信息。 |
| cluster meet <ip> <port> | 将 ip 和 port 所指定的节点添加到集群当中,让它成为集群的一份子。 |
| cluster forget <node_id> | 从集群中移除 node_id 指定的节点。 |
| cluster replicate <master_node_id> | 将当前从节点设置为 node_id 指定的master节点的slave节点。只能针对slave节点操作。 |
| cluster saveconfig | 将节点的配置文件保存到硬盘里面。 |
| cluster addslots <slot> [slot ...] | 将一个或多个槽( slot)指派( assign)给当前节点。 |
| cluster delslots <slot> [slot ...] | 移除一个或多个槽对当前节点的指派。 |
| cluster flushslots | 移除指派给当前节点的所有槽,让当前节点变成一个没有指派任何槽的节点。 |
| cluster setslot <slot> node <node_id> | 将槽 slot 指派给 node_id 指定的节点,如果槽已经指派给另一个节点,那么先让另一个节点删除该槽>,然后再进行指派。 |
| cluster setslot <slot> migrating <node_id> | 将本节点的槽 slot 迁移到 node_id 指定的节点中。 |
| cluster setslot <slot> importing <node_id> | 从 node_id 指定的节点中导入槽 slot 到本节点。 |
| cluster setslot <slot> stable | 取消对槽 slot 的导入( import)或者迁移( migrate)。 |
| cluster keyslot <key> | 计算键 key 应该被放置在哪个槽上。 |
| cluster countkeysinslot <slot> | 返回槽 slot 目前包含的键值对数量。 |
| cluster getkeysinslot <slot> <count> | 返回 count 个 slot 槽中的键 。 |
| cluster reset | 重置集群命令 |
四、故障恢复
1、模式故障
kill -9 PID #杀死其中一个redis进程2、故障恢复
启动杀死的redis进程
通过 cluster nodes查看节点状态
通过 cluster info 查看集群状态
登录所有从节点
3、cluster failover命令
Redis Cluster模式下的cluster failover(集群故障转移)的作用是确保Redis集群在主节点(Master)发生故障或不可用的情况下,能够自动将主节点的工作负载转移到备用节点(Slave)上,并使备用节点成为新的主节点,保证Redis集群的高可用性和持续可用性。
当主节点发生故障时,Redis Cluster会自动检测到主节点的不可用,并从备用节点中选出一个合适的备用节点作为新的主节点。该备用节点经过选举后,会接管原主节点的数据和工作负载,并开始对外提供服务。集群的其它节点也会更新集群拓扑信息,以便客户端能够正确地路由请求到新的主节点。
cluster failover的作用主要包括:
高可用性:当主节点发生故障时,能够及时切换到备用节点,保证Redis集群的继续正常运行,避免因单点故障而导致服务不可用。
数据保护:在主节点发生故障时,能够将数据从主节点复制到备用节点,并在故障转移时将备用节点提升为新的主节点,从而保证数据的持久性和一致性。
自动化管理:集群故障转移是自动化过程,无需人工干预,减少了对系统运维的依赖,并提高了系统的可靠性和可维护性。