知识掘金者:API+Dify工作流,开启「深度思考」的搜索革命
注意:不是广告!!!不是广告!!!

目录
项目背景
API
注册与获取密钥
详细接入流程
设置研究深度
创建深度数组
迭代研究控制
LLM-主题分解
JSON解析与主题传递
Tavily在线搜索集成
研究结果合并与整合
LLM-研究成果整理
项目总结
项目背景
在当今信息爆炸的时代,高效获取和处理网络信息成为企业和个人的核心需求。蓝耘API接入项目旨在构建一个智能研究助手,通过自动化的工作流程,深度挖掘网络信息,为用户提供全面、准确的研究分析报告。该项目结合了大语言模型的推理能力与实时搜索引擎的数据获取能力,解决了传统研究中信息收集不全面、分析深度不足的问题。
如何安装Dify请参考:https://lethehong.blog.csdn.net/article/details/151078946
API
蓝耘平台为开发者和企业提供了丰富的AI模型服务与算力资源,其API是实现AI应用联动的关键。下面这个表格汇总了其API的核心服务类别,帮助你快速了解其主要用途。
| 服务类别 | 核心功能 | 典型应用场景 |
| 大模型服务 | 提供多种预训练大模型的推理API,支持复杂的自然语言处理、对话、代码生成等任务。 | 智能客服、内容创作、私人助理 |
| 算力与服务 | 提供强大的云计算资源和模型部署环境,支持模型训练与推理。 | 模型训练与微调、高性能推理、AI应用托管 |
| 工作流与集成 | 通过API将AI能力嵌入自动化流程,或使用平台工具构建复杂的AI应用工作流。 | 自动化写作流程、智能客服工作流、多步骤AI任务 |
注册与获取密钥
点击蓝耘访问蓝耘MaaS平台官网完成注册。登录后,在控制台的"API KEY管理"页面,你可以创建专属的API密钥,这是调用所有服务的前提
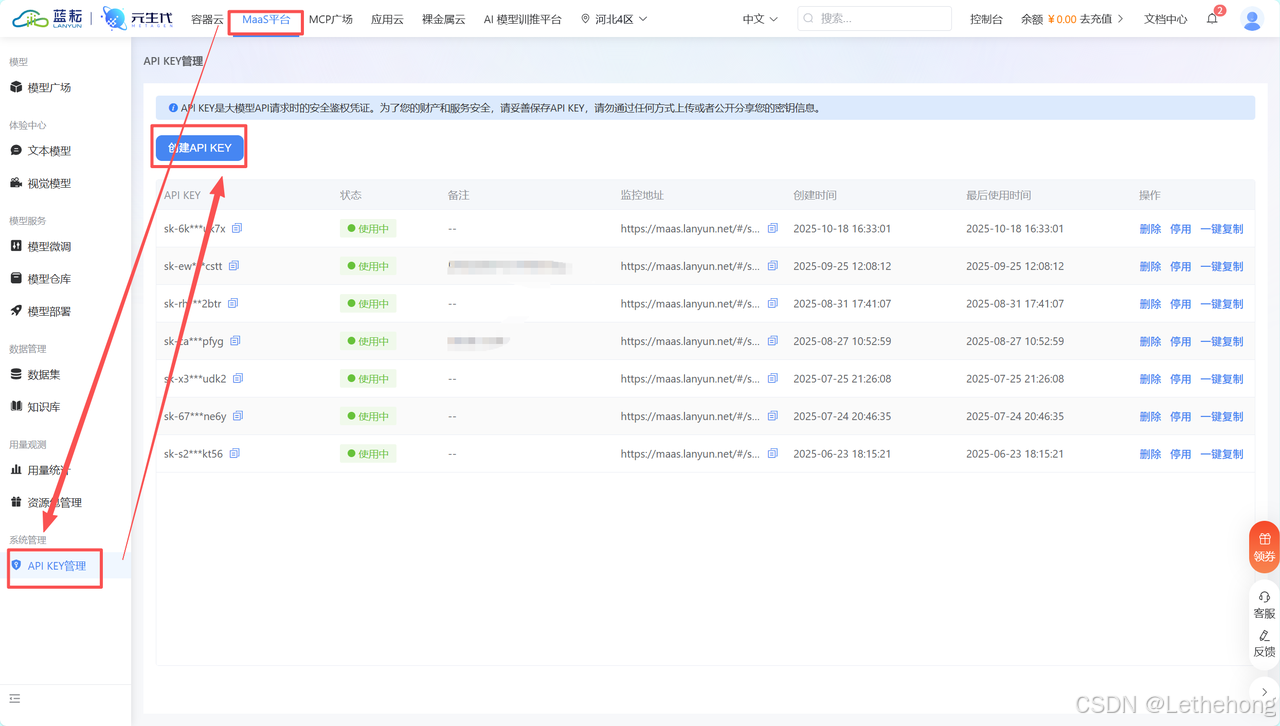
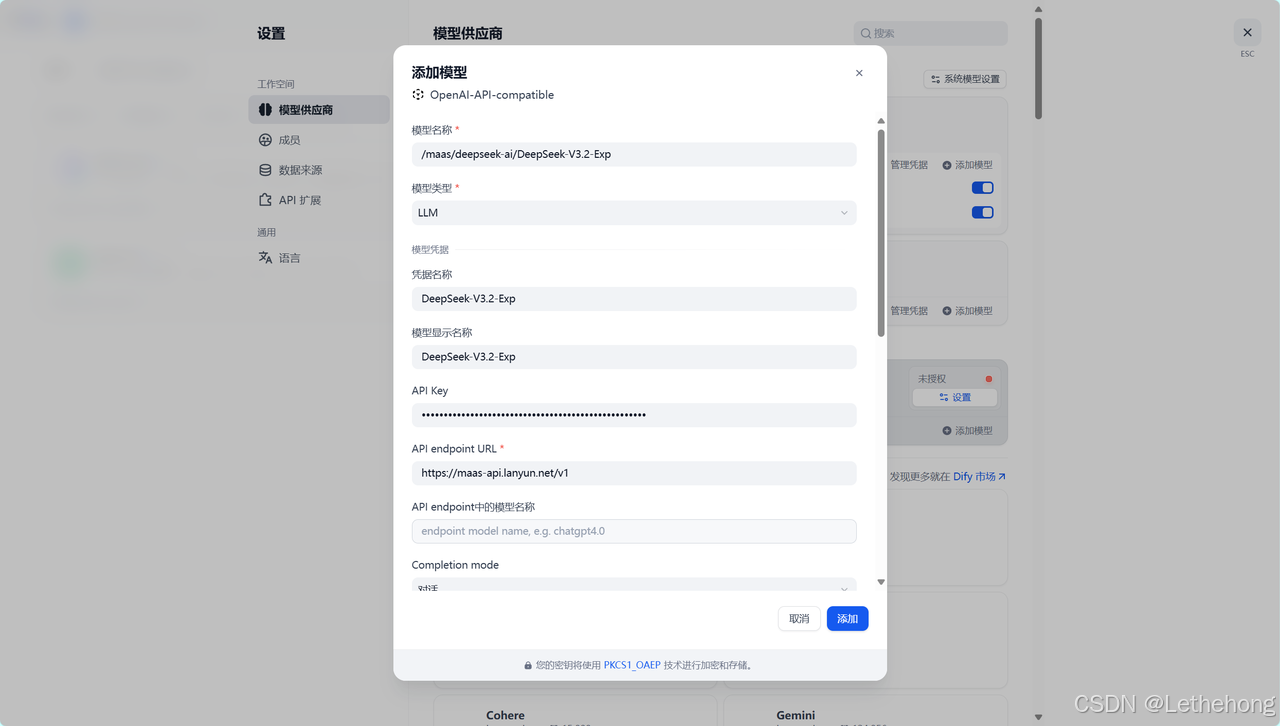
然后在Dify进行添加模型,输入相关信息和API
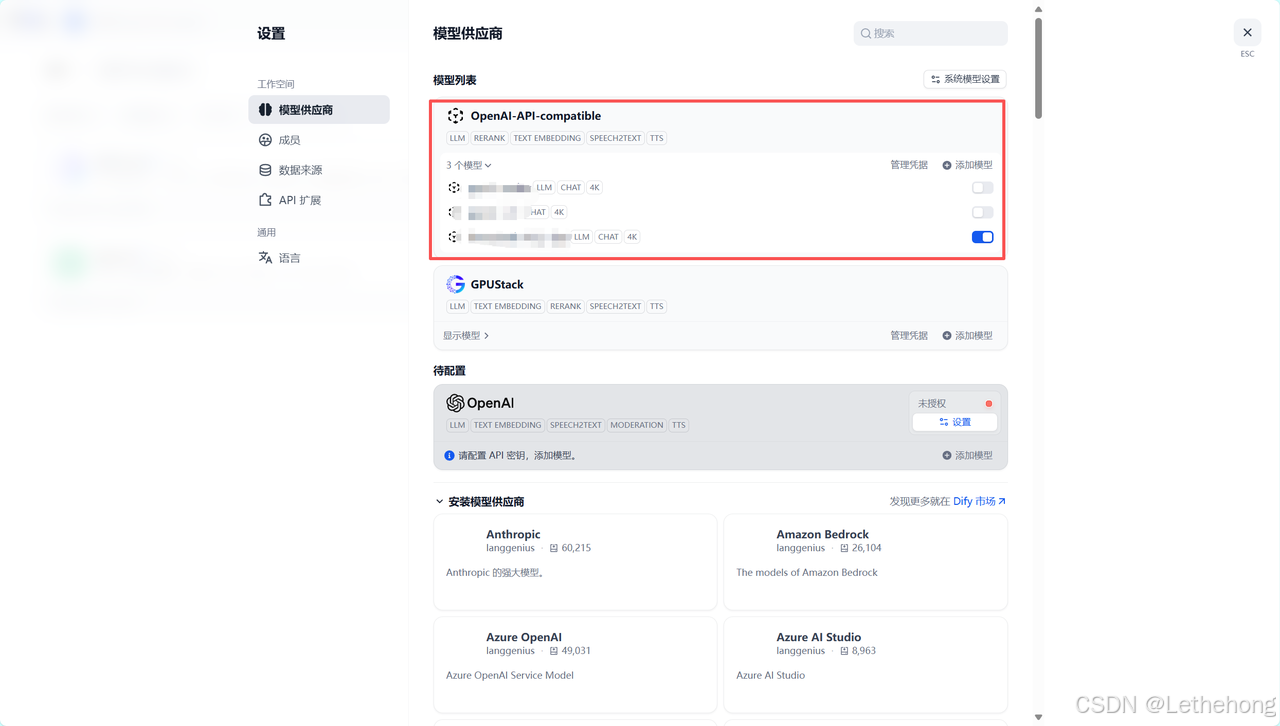
详细接入流程
设置研究深度
登录Dify平台,进入工作台界面,点击"工作室"选项,进入应用管理页面,选择"创建空白应用",开始构建新的工作流。
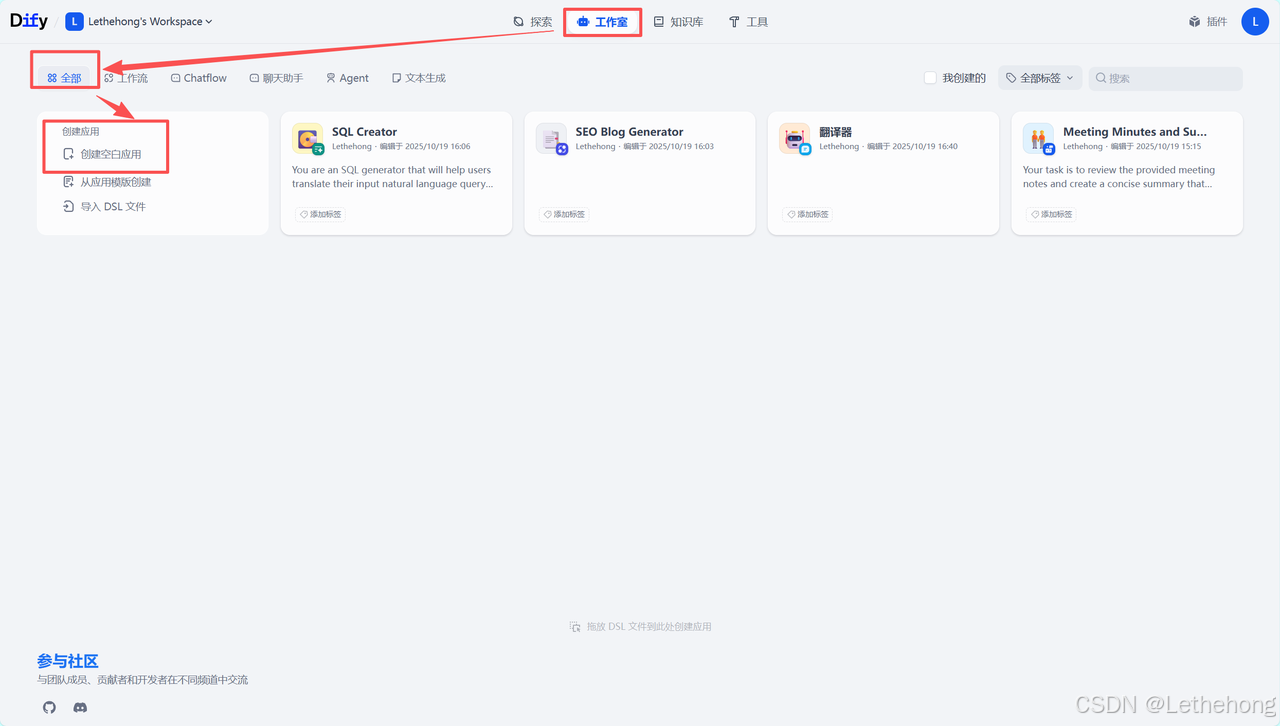
在应用类型中选择"Chatflow",输入具有辨识度的应用名称。
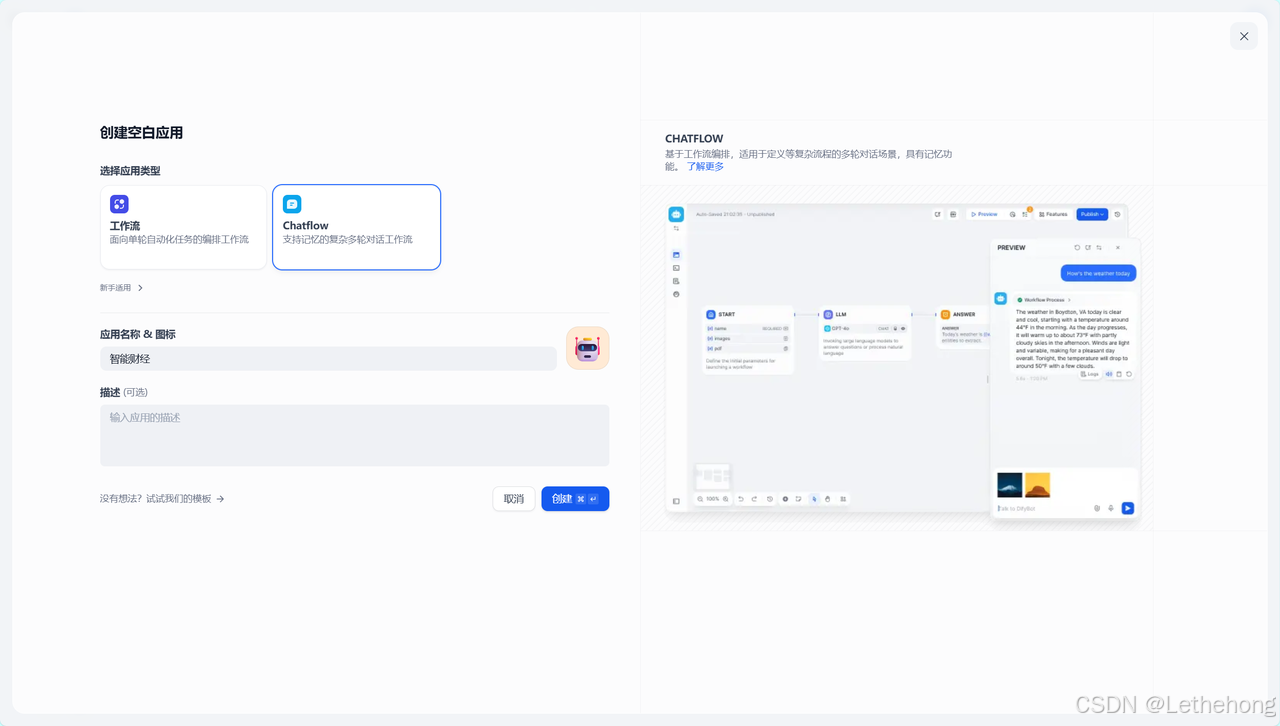
在开始节点处,设置研究深度参数,该数值决定了研究的迭代次数和详细程度。
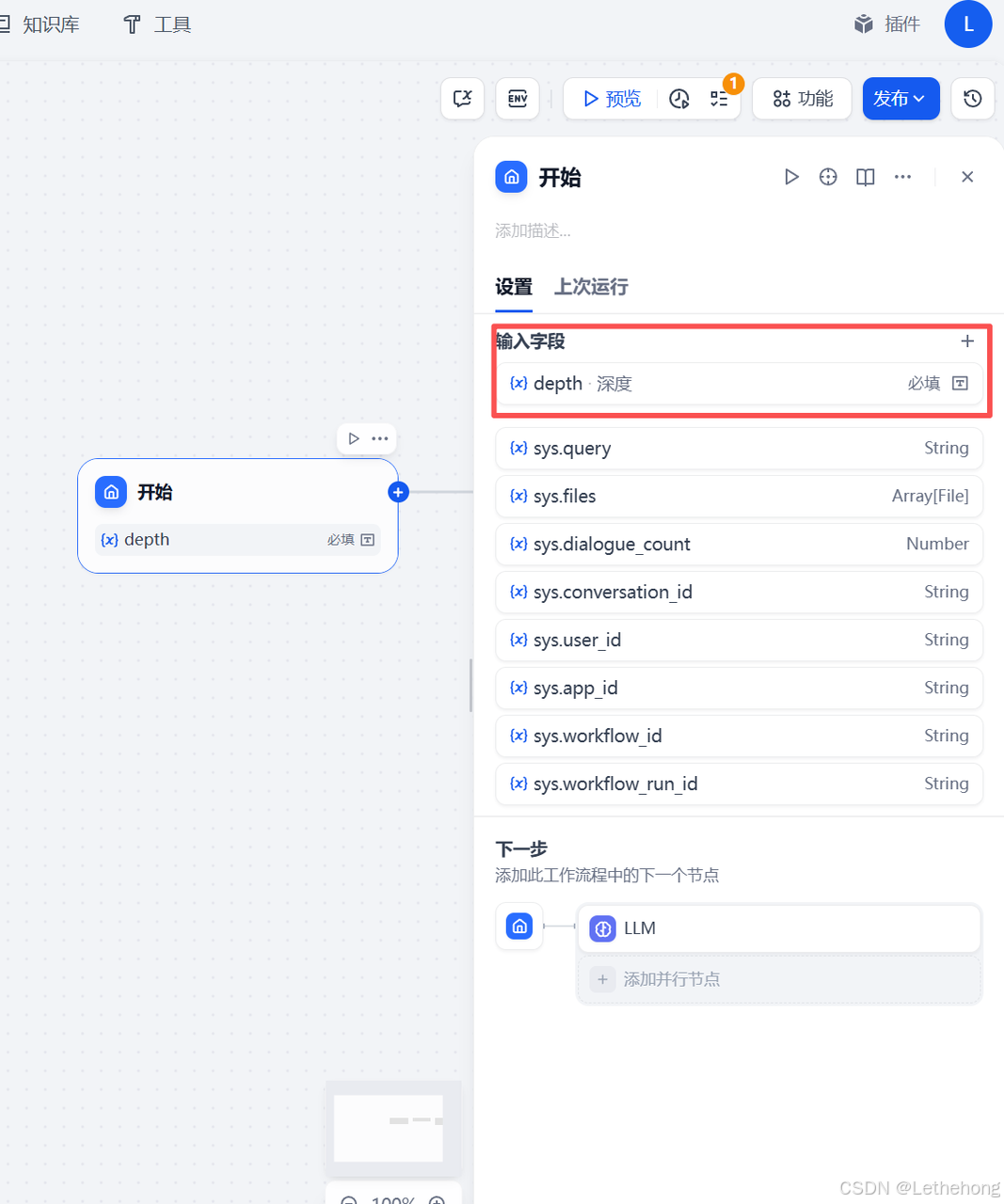
创建深度数组
创建深度数组,并存储每次循环研究结果
-
输入:
-
depth:开始
-
-
输出:
-
array:Array[Number]
-
depth:Number
-
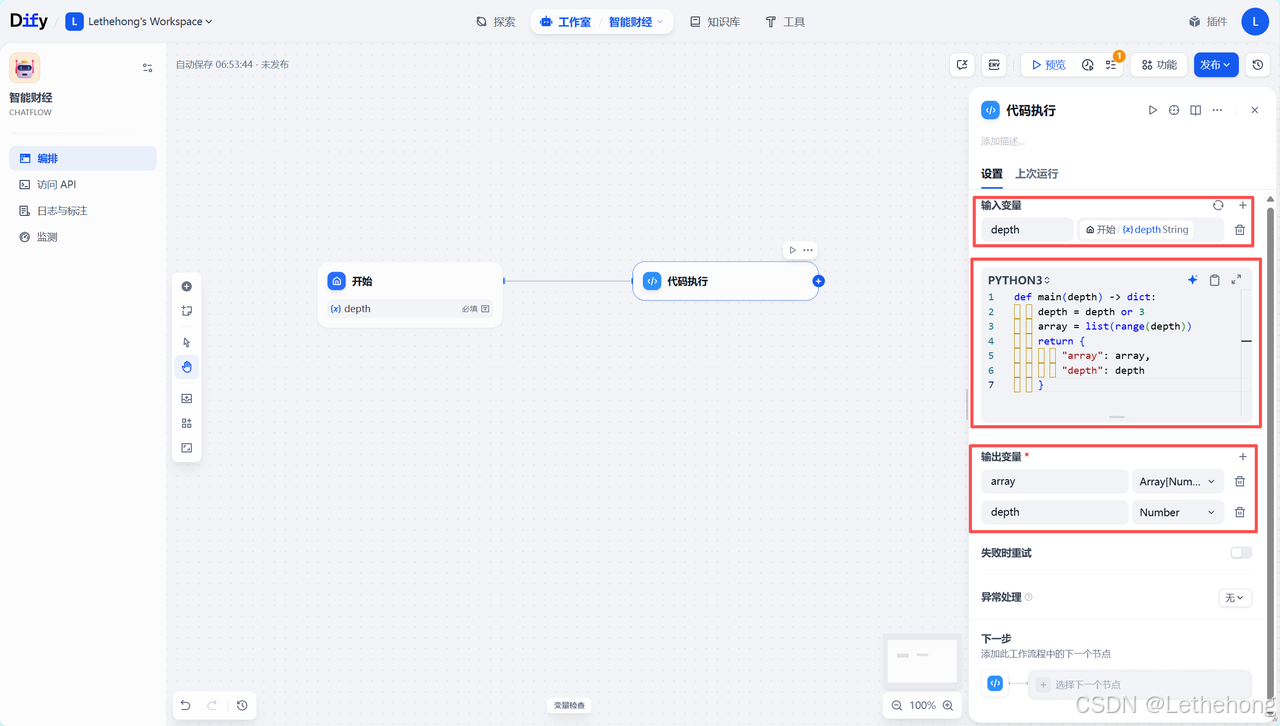
def main(depth: int) -> dict:depth = depth or 3array = list(range(depth))return {"array": array,"depth": depth}功能说明:
该步骤生成一个深度控制数组,用于管理后续迭代研究的过程。数组中的每个元素对应一次研究循环,确保研究过程有序进行。
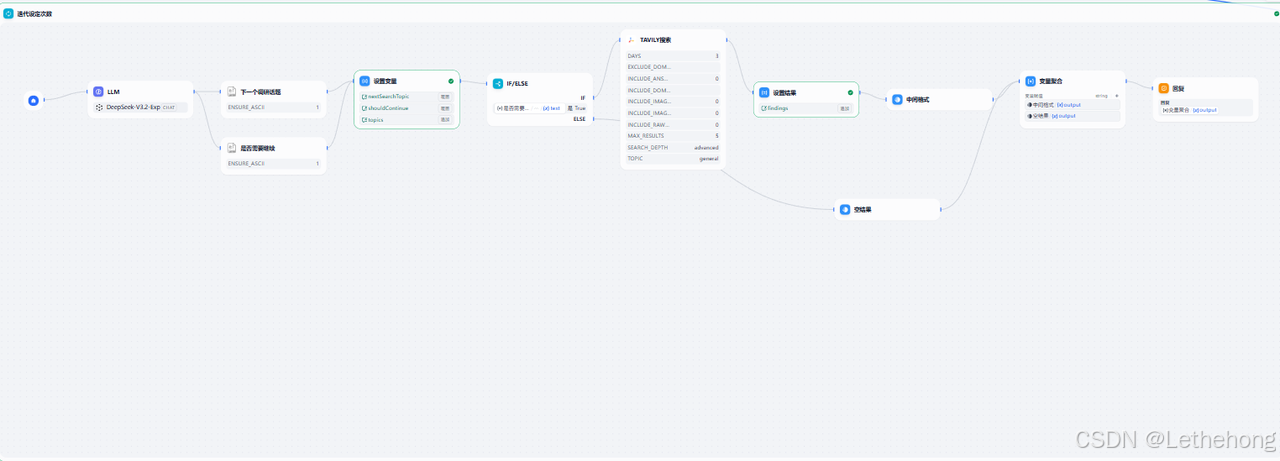
迭代研究控制
工作机制:
-
系统根据深度数组的长度确定迭代次数
-
每次迭代都会在前一次研究基础上深入挖掘
-
通过循环控制确保研究不会无限进行
-
在深度耗尽或满足终止条件时自动结束
LLM-主题分解
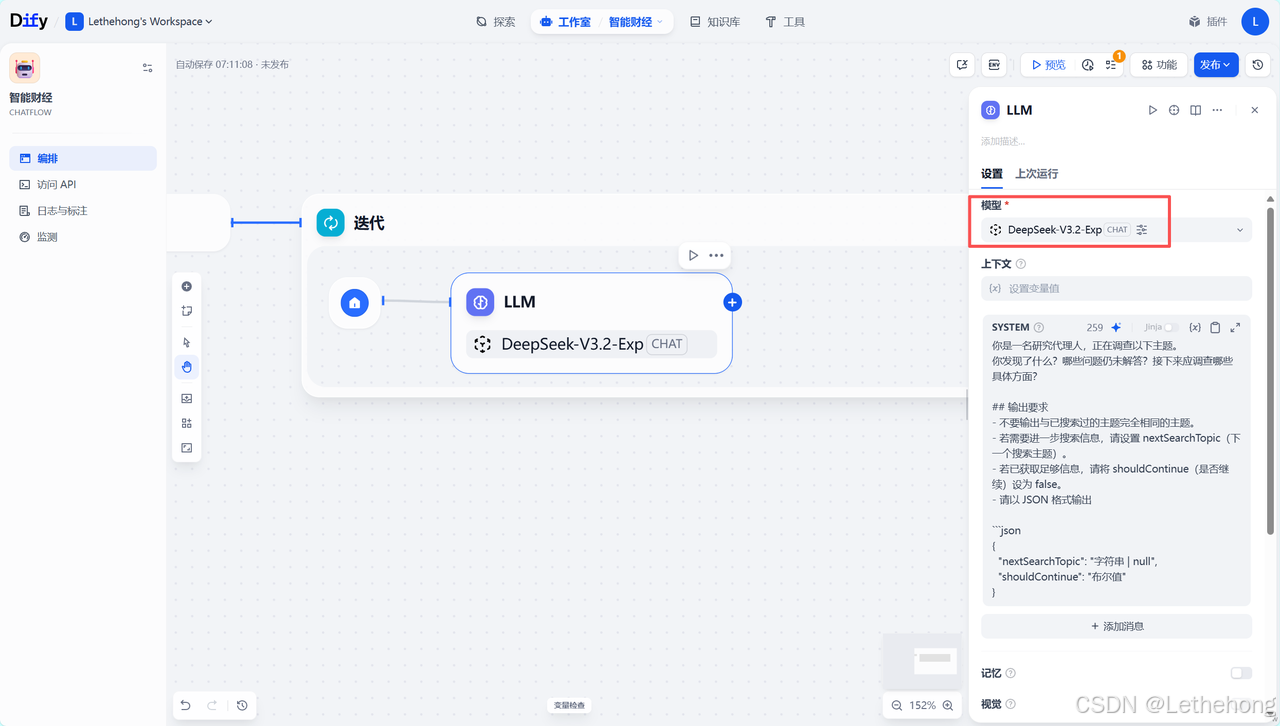
首先使用大模型对用户输入的问题进行差分,生成待分析主题,大模型提示词如下:
你是一名研究代理人,正在调查以下主题。
你发现了什么?哪些问题仍未解答?接下来应调查哪些具体方面?## 输出要求
- 不要输出与已搜索过的主题完全相同的主题。
- 若需要进一步搜索信息,请设置 nextSearchTopic(下一个搜索主题)。
- 若已获取足够信息,请将 shouldContinue(是否继续)设为 false。
- 请以 JSON 格式输出```json
{"nextSearchTopic": "字符串 | null","shouldContinue": "布尔值"
}
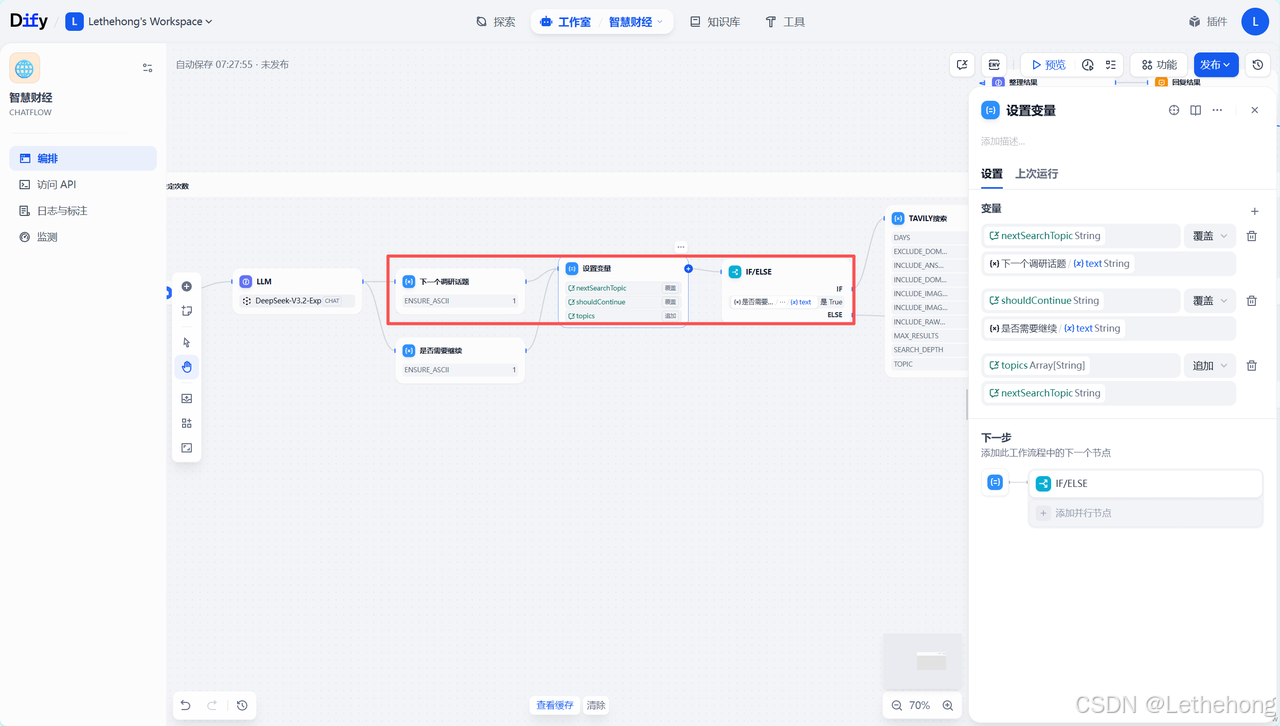
JSON解析与主题传递
接收LLM输出的JSON字符串,验证JSON格式的完整性,提取nextSearchTopic和shouldContinue字段,将解析后的数据传递给搜索模块,记录研究路径用于后续分析。
Tavily在线搜索集成
访问Tavily官网(app.tavily.com),获取API密钥和端点地址,在Dify中配置Tavily工具节点,设置搜索参数(时效性、数量、深度等),测试搜索连接有效性。
搜索优化:
-
支持实时网络搜索
-
可过滤低质量信息来源
-
提供相关度评分
-
支持多种内容格式获取
将API复制过来即可
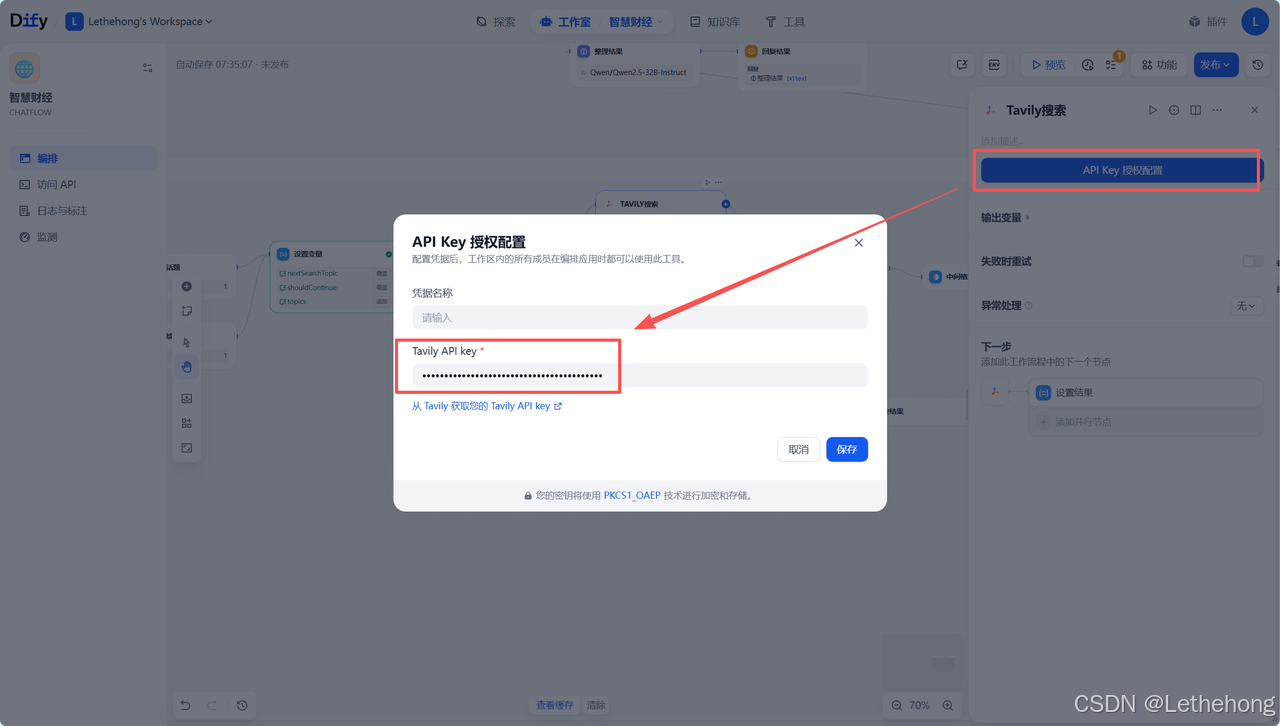
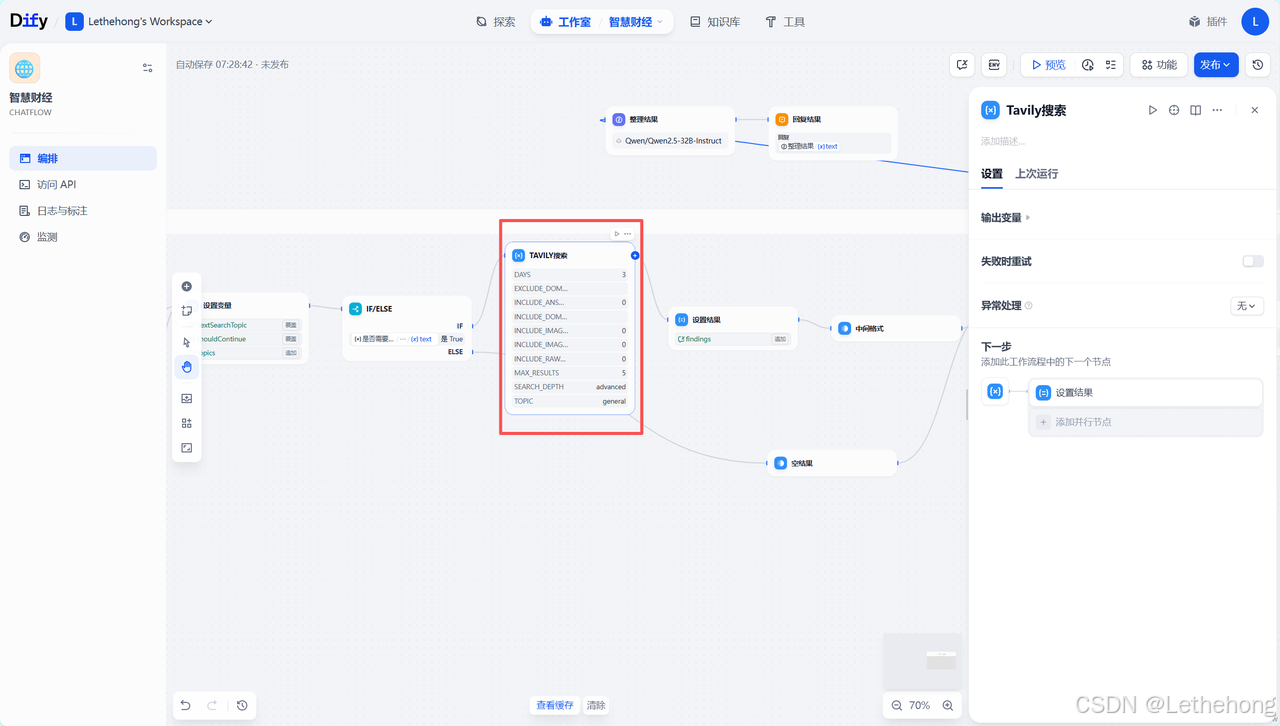
研究结果合并与整合
增量式合并每次迭代的搜索结果,保持研究数据的完整性和一致性,去除重复信息和噪声数据,建立研究数据的时间序列记录。
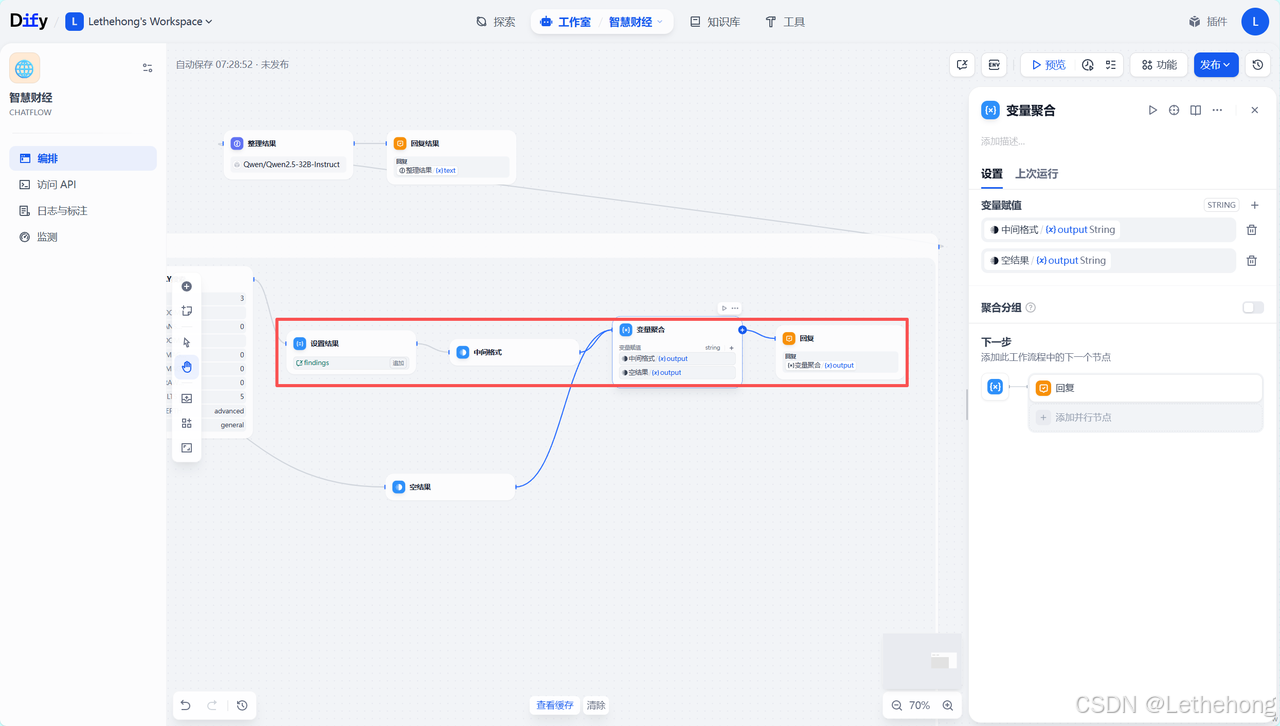
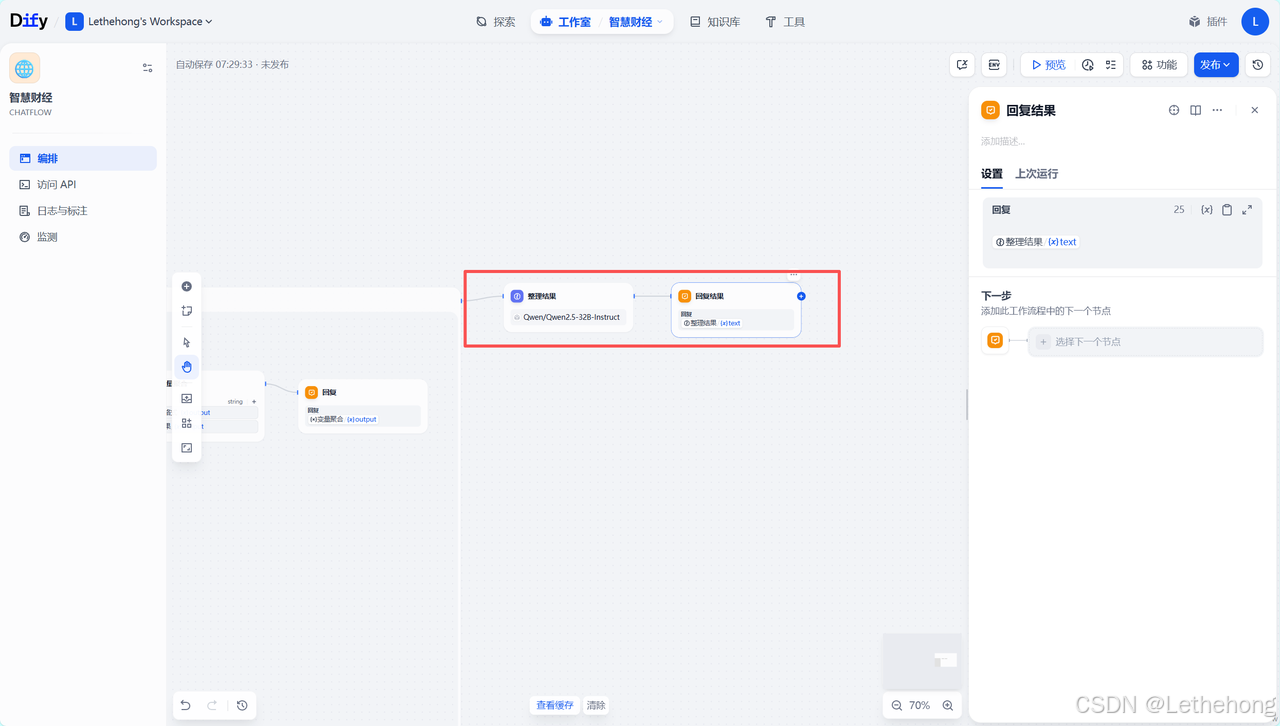
LLM-研究成果整理
最终报告生成提示词:
根据调查结果,对该主题进行全面分析。
提供重要见解、结论以及尚存的不确定性,并在适当处引用来源。此分析需具备高度的全面性与详细性,应以长文本形式呈现。## 主题(Topic)
{{#sys.query#}}## 调查结果(Findings)
{{#conversation.findings#}}完成整理后返回给用户即可。
验证结果
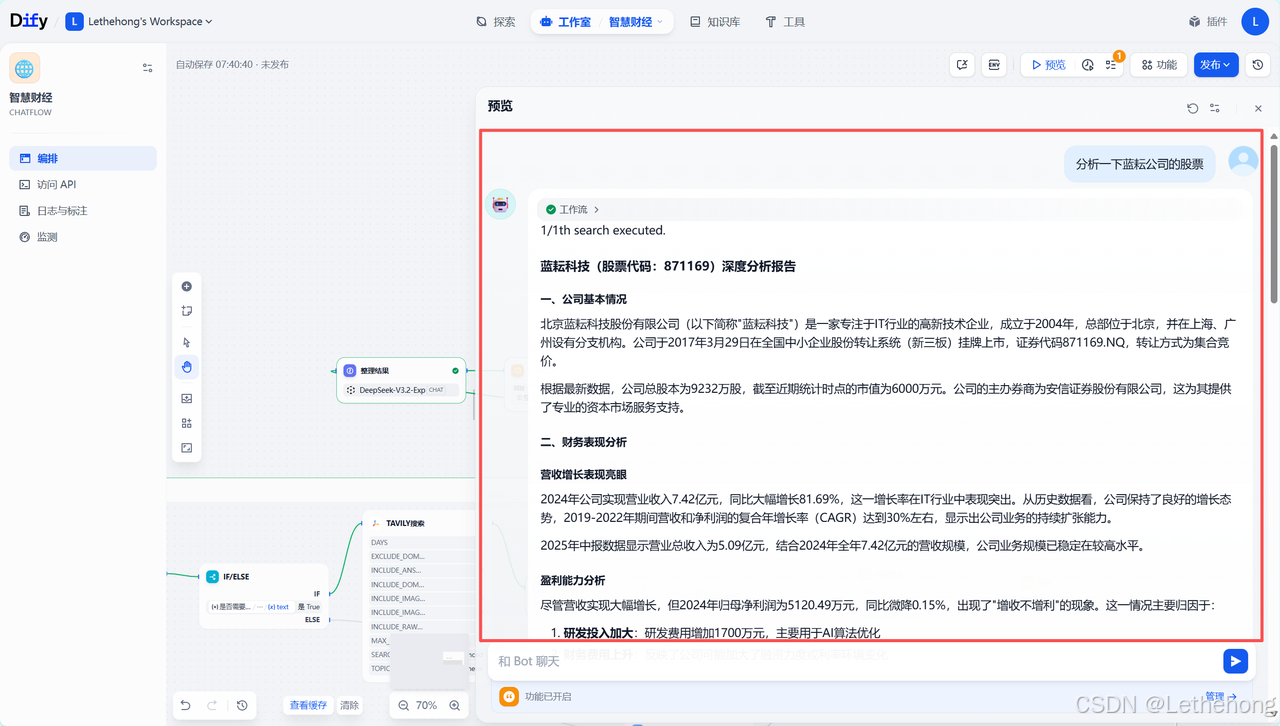
项目总结
通过蓝耘API的接入和实施,我们成功构建了一个高效、智能的股票分析系统。该系统具备以下核心优势:
-
自动化研究流程
-
深度迭代机制
-
智能方向调整
-
高质量输出