PromQL计算gateway指标增量最佳实践及常见问题答疑
普米官方网站
普米官方帮助:Getting started | Prometheus
普米下载地址:Download | Prometheus
普米查询语法:Querying basics | Prometheus
普米函数参考:Query functions | Prometheus
promql计算增量
在PromQL(Prometheus Query Language)中,计算增量(即两个时间点之间的差异)通常涉及到使用rate()函数或者increase()函数。这两种方法各有其适用的场景,下面我将分别解释它们并展示如何在PromQL中实现。
1. 使用rate()函数
rate()函数用于计算在指定时间内的平均速率。这对于计算随着时间的推移而增长的速率非常有用。例如,如果你想计算每秒的请求数,可以使用rate()。
rate(http_requests_total[5m])这里,http_requests_total是一个计数器,[5m]表示在过去5分钟内的数据。rate()函数会计算这5分钟内请求的平均增长速率。
2. 使用increase()函数
increase()函数用于计算在指定时间范围内的绝对增量。如果你需要知道在两个时间点之间有多少次事件发生,使用increase()是合适的。
increase(http_requests_total[5m])这行代码会返回在过去5分钟内http_requests_total计数的增加量,即总共增加了多少次请求。
3. 使用delta()函数(Prometheus 2.8.0及以后版本)
从Prometheus 2.8.0版本开始,还可以使用delta()函数来计算两个时间点之间的差异。这对于需要精确计算两次查询之间差异的场景非常有用。
delta(http_requests_total[5m])这里,delta()同样计算过去5分钟内http_requests_total的增加量,但是它直接返回增加的数量,而不是平均速率。
选择哪种方法?
-
如果你关心的是速率(比如每秒的增长率),使用
rate()。 -
如果你需要知道在特定时间段内发生了多少次事件,使用
increase()或delta()(取决于你的Prometheus版本)。 -
如果你需要精确知道两个时间点之间的差异,使用
delta()。
示例:比较不同方法
假设你想要知道在过去1小时内,每小时有多少个HTTP请求:
使用rate():
rate(http_requests_total[1h]) * 60 * 60 // 将结果转换为每小时的请求数使用increase():
increase(http_requests_total[1h]) // 直接返回过去1小时内的总增加量使用delta():
delta(http_requests_total[1h]) // 直接返回过去1小时内的总增加量选择哪种方法取决于你的具体需求和场景。
最佳实践
场景一:springcloud gateway近二分钟的请求数量(绝对增量)
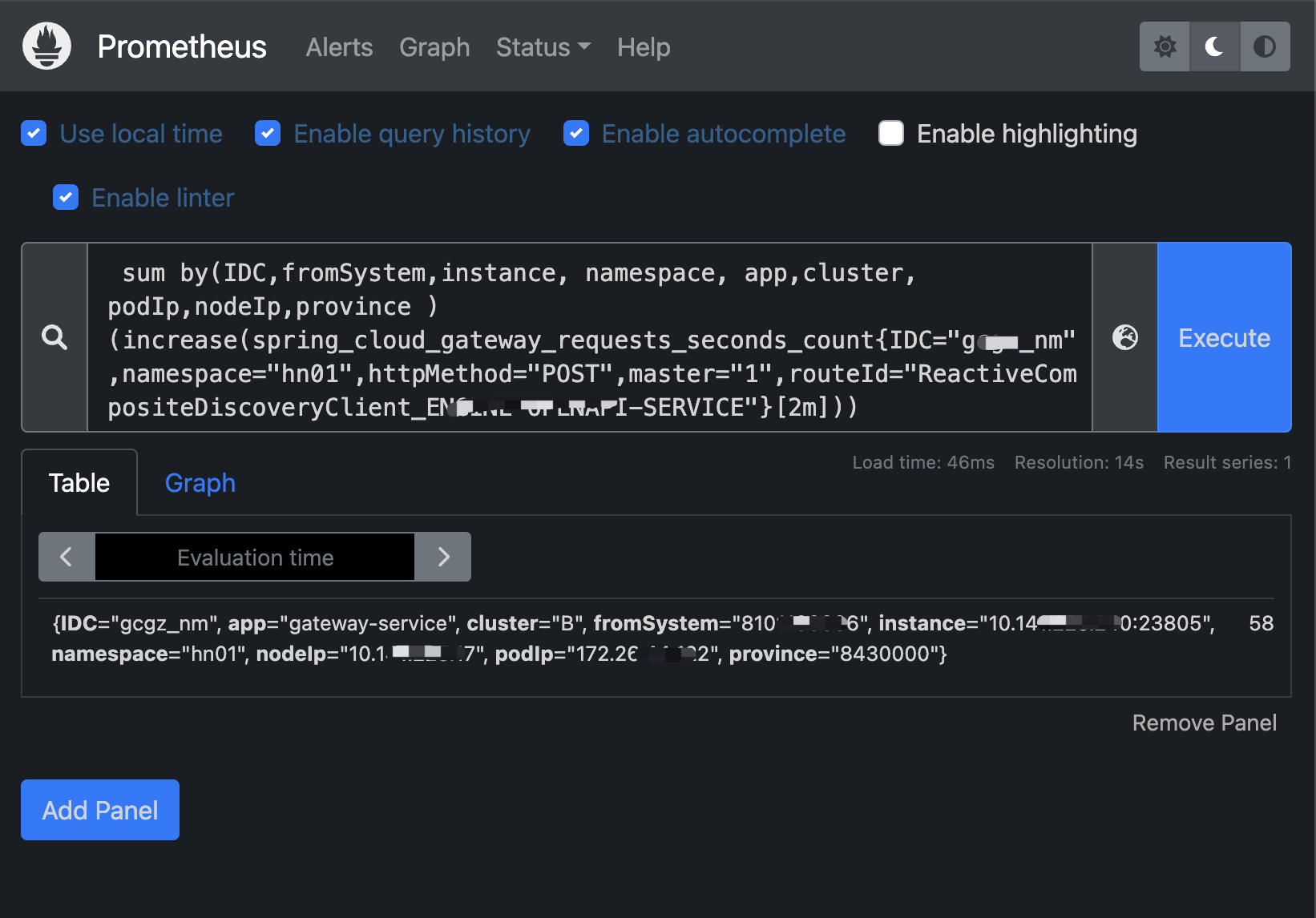
# 近两分钟的调用量(增量查询)
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))注意:查增量时时间区t>=2m(采集间隔的两陪时间) ,否则查不出数据
表达式详解:
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))
IDC: 资源池代码,如:北京、上海、深圳、新加坡(服务器资源)
fromSystem: 来源系统代码(哪个系统的指标数据)
instance: 集群指标采集端点地址
namespace:命名空间,如:湖南集群1
nodeip:gateway所在物理机ip
podIp:gateway 在k8s上的pod ip
province:(内部)省份代码
58 -- 指标值:区间内(2分钟)有58次调用
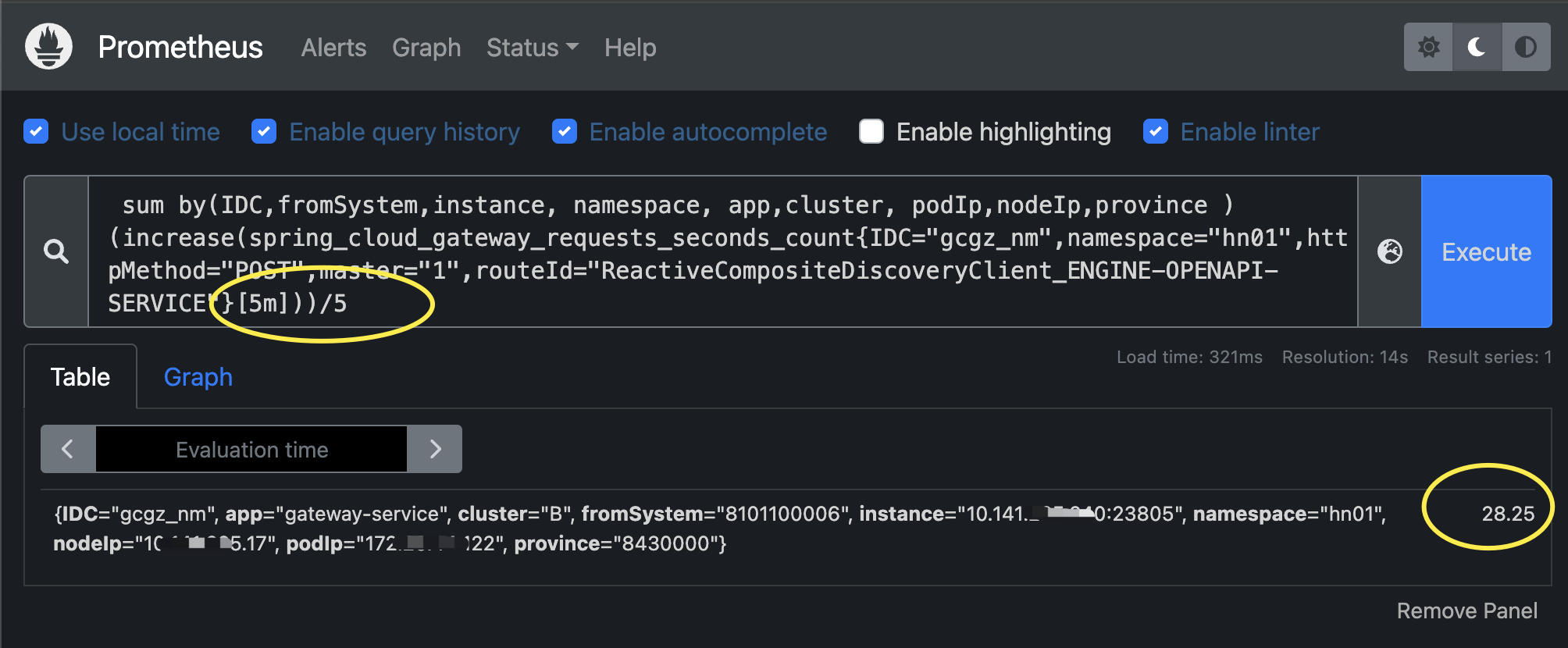
场景二:近5分钟每分钟的平均调用量
# 近5分钟每分钟的平均调用量
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[5m]))/5解析:增量/时间
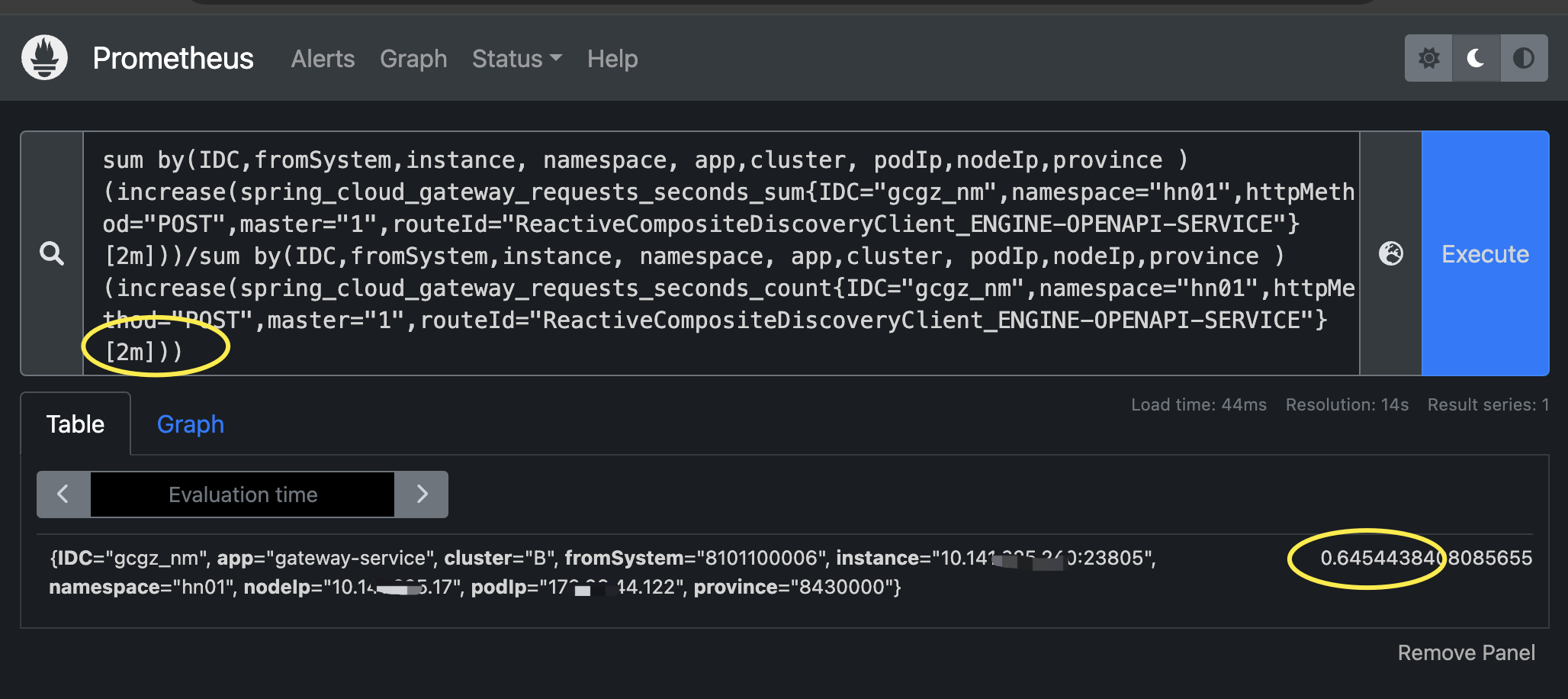
场景三:近2分钟的调用平均耗时
# 近2分钟的调用平均耗时
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_sum{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))/sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))解析:sum/count,sum是耗时,count时调用量
场景四:近2分钟的调用成功率
# 近2分钟的调用成功率
sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",httpStatusCode="200",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))/sum by(IDC,fromSystem,instance, namespace, app,cluster, podIp,nodeIp,province ) (increase(spring_cloud_gateway_requests_seconds_count{IDC="gcgz_nm",namespace="hn01",httpMethod="POST",master="1",routeId="ReactiveCompositeDiscoveryClient_ENGINE-OPENAPI-SERVICE"}[2m]))解析:分母表达式多了个条件:httpStatusCode="200"
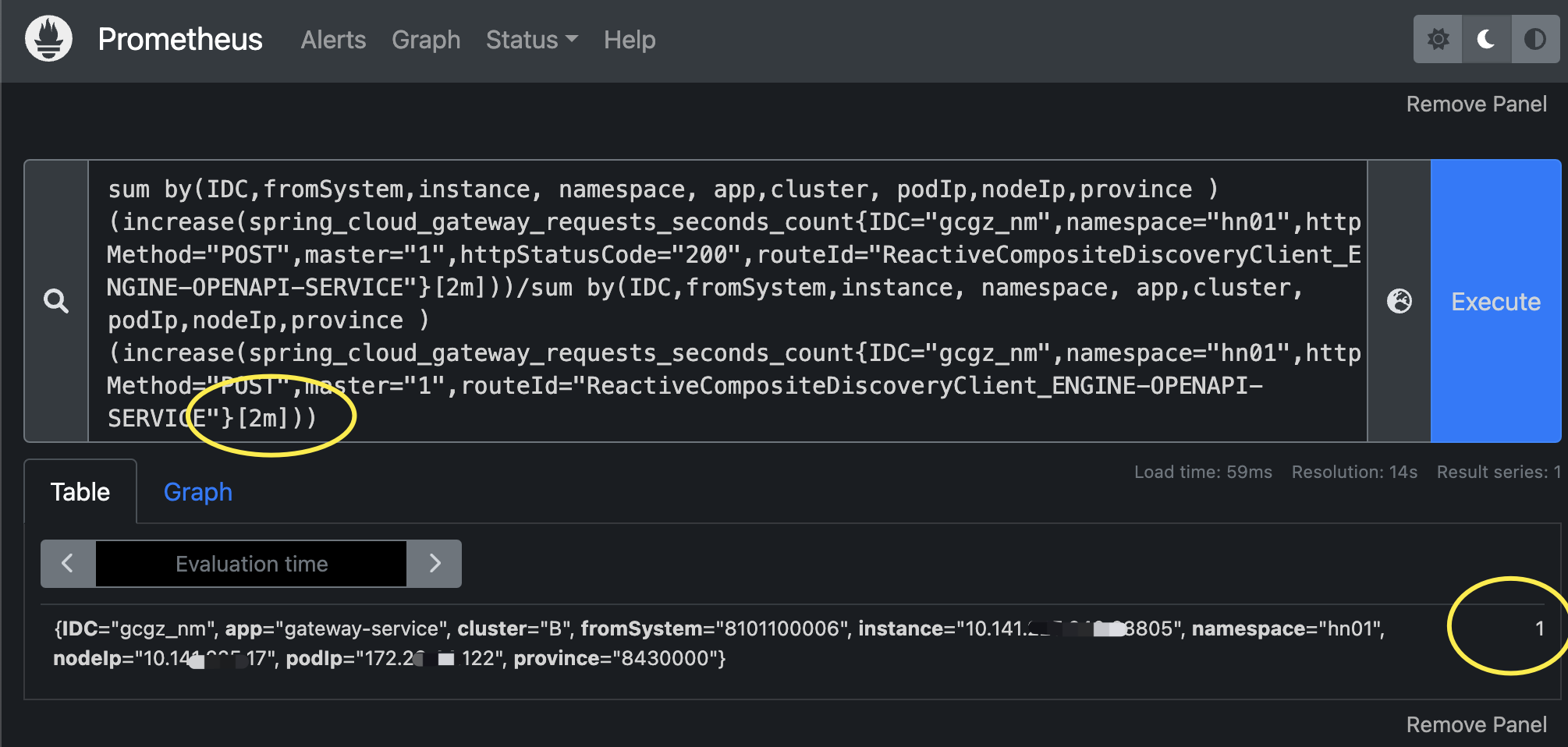
解析:成功率等于1表示100%(存在四舍五入的可能)
常见问题FAQ
Q1:为什么promql 使用increase函数查14分钟的增量与15分钟的增量为什么相差甚远?
A:受时间窗口和采样间隔影响,可能产生较大误差,如:某个时间点的指标丢失。增量就会是累计调用量(差了几个数量级)。实际有时间并不一定是14分钟和15分钟,可能是任意时间点在其范围内查询增量准确,范围外不准确。所以增量尽量缩省范围(减少出错频率、但并不能做到彻底不出错)
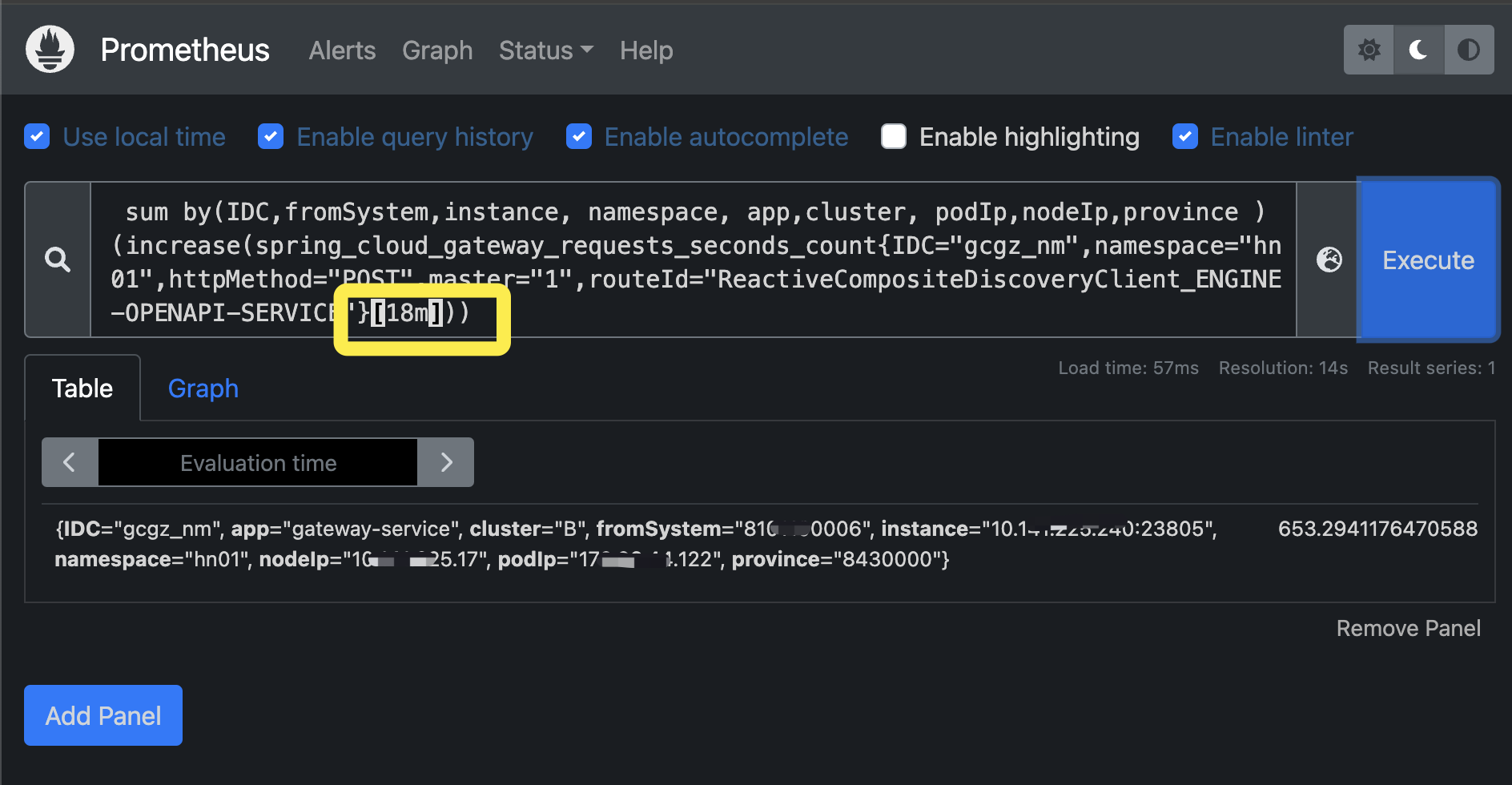
举例:这里查1分钟还是18分钟的增量都是准的,平均每分钟的增量约30(次调用),但19分钟区间查增量就不准了(变成了gateway的累计调用量400多万)
查近二分钟的gateway调用量指标增量数据
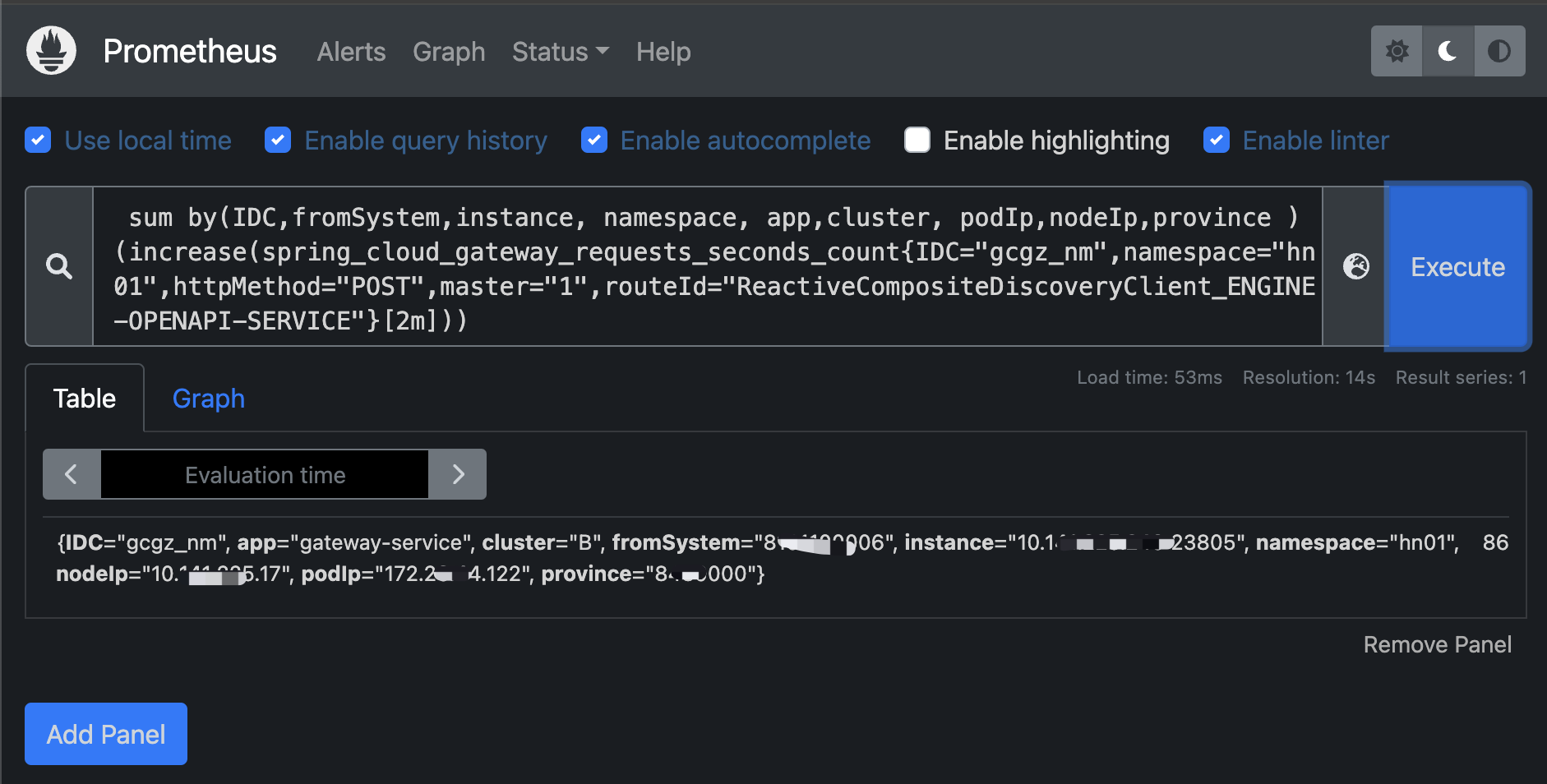
注意:查增量时时间区t>=2m(采集间隔的两陪时间) ,否则查不出数据
查近18分钟的gateway调用量指标增量数据
查近19分钟的gateway调用量指标增量数据(数据异常)

最佳解决方案:
1、使用表达式指标时丢掉较大的指标(如图中丢掉1000以上的指标)从普米采集时直接丢掉
2、使用普米原始指标配置告警时增加上限条件。
可能由以下原因导致:
1. 时间窗口与采样间隔的匹配问题
increase()函数基于时间序列数据的外推算法估算增量,其计算结果受时间窗口与数据采样间隔的倍数关系影响。- 若采样间隔(如 1 分钟)与时间窗口(14 或 15 分钟)不成整数倍,会导致外推算法对首尾样本的修正系数不同。例如:
- 15 分钟窗口可能刚好覆盖整数倍的数据点(如 15 个 1 分钟样本),计算结果更准确。
- 14 分钟窗口可能因未完整覆盖数据周期,导致外推修正后的值与实际偏差较大。
2. 数据点对齐与中断问题
increase()依赖时间窗口内的第一个和最后一个样本值计算增量。若时间窗口存在以下情况,可能导致结果波动:- 数据采集中断:14 分钟内可能存在数据空白(如采集器故障),导致外推算法对缺失数据的补偿不准确。
- 首尾样本异常:若首尾样本值因抖动或异常值突变,14 分钟窗口的短周期会放大这种波动,而 15 分钟窗口可能通过更多样本平滑异常。
3. 计数器重置(Counter Reset)的影响
- Counter 类型指标在发生重置(如应用重启)时,
increase()会自动处理重置事件。 - 若 14 分钟窗口内发生多次重置,可能导致算法对外推增量的修正与 15 分钟窗口不同,进而造成差异。
4. 外推算法的修正系数差异
- Prometheus 的
increase()会对时间窗口边缘的样本进行外推修正,修正系数为时间窗口/采样间隔。- 例如:假设采样间隔为 1 分钟,15 分钟窗口的修正系数为 15,而 14 分钟窗口为 14。两者修正后的增量可能因系数差异而显著不同。
建议解决方案
- 确保时间窗口是采样间隔的整数倍(如采样间隔 1 分钟时,使用 15 分钟而非 14 分钟)。
- 检查数据连续性:通过
up指标或原始时序数据确认是否存在采集中断。 - 结合
rate()验证:对比rate(v[15m]) * 15 * 60与increase(v[15m]),观察外推算法的影响。 - 使用表达式指标时丢掉较大的指标(如图中丢掉1000以上的指标),从普米采集时直接丢掉
- 使用普米原始指标配置告警表达式时增加上限条件。