网站建设汉狮怎么样深圳 骏域网站建设
一、什么是位置编码
位置编码(Positional Encoding)是一种在自然语言处理(NLP)中,特别是在使用 Transformer 架构的模型中,用来给模型提供单词在序列中位置信息的方法。在 Transformer 模型出现之前,循环神经网络(RNN)和长短期记忆网络(LSTM)等模型由于其递归的性质,天然就具有序列信息,即模型能够利用序列中单词的前后顺序来理解上下文。
然而,Transformer 模型不具有这种递归结构,它完全基于注意力机制(Attention Mechanism),并且是并行处理输入序列中的所有单词。这意味着在原始的 Transformer 模型中,单词的位置信息是缺失的。为了解决这个问题,位置编码被引入到模型中,以提供序列中每个单词的位置信息。
位置编码通常是一个固定的向量,它与单词的词嵌入(Word Embedding)向量相加,从而将位置信息注入到模型中。位置编码的设计需要满足以下两个条件:
- 区分性(Distinctness):不同位置的编码应该是不同的,这样模型才能区分序列中不同位置的单词。
- 连续性(Continuity):相对位置接近的单词,其位置编码也应该在某种意义上是接近的,这样模型才能捕捉到序列中单词的相对位置关系。
在原始的 Transformer 论文中,位置编码是通过正弦和余弦函数来计算的,其公式如下:
对于每个位置 ( pos ) 和每个维度 ( 2i )(对于偶数维度)和 ( 2i+1 )(对于奇数维度),位置编码 ( PE ) 的计算公式为:
PE(pos,2i)=sin(pos100002i/dmodel)PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)PE(pos,2i)=sin(100002i/dmodelpos)
PE(pos,2i+1)=cos(pos100002i/dmodel)PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right)PE(pos,2i+1)=cos(100002i/dmodelpos)
其中,dmodeld_{\text{model}}dmodel 是模型的维度大小,通常是词嵌入向量的维度。
这种位置编码的设计允许模型通过不同频率的正弦和余弦波来区分不同的位置,并且能够捕捉到相对位置信息。由于正弦和余弦函数的周期性,这种编码方式能够在理论上处理任意长度的序列。
二、为什么需要位置编码
- 问题根源:Transformer使用的自注意力机制是并行处理所有词的,这虽然高效但丢失了词序信息,而词序对理解语义至关重要。(相比之下,RNN是顺序处理,天然包含顺序信息)。
- 解决方案:需要向模型输入中添加位置编码,即代表每个词位置的额外信息。
- 简单方案的缺陷:
- 方案一(归一化到[0,1]):无法体现不同长度句子中词间距的一致含义(例如,0.2的间隔在10个词的句子和100个词的句子中代表的绝对词数不同)。
- 方案二(线性递增整数):数值可能过大;模型难以处理比训练时更长的句子;泛化性差(可能未见过某些特定长度的句子)。
- 理想编码的标准:提出了一个好的位置编码应满足的四个关键标准:唯一性、跨句子距离一致性、有界性且能泛化到更长句子、确定性。
三、位置编码的发展过程
3.1 用整型值标记位置
一种自然而然的想法是,给第一个token标记1,给第二个token标记2…,以此类推。
这种方法产生了以下几个主要问题:
(1)模型可能遇见比训练时所用的序列更长的序列。不利于模型的泛化。
(2)模型的位置表示是无界的。随着序列长度的增加,位置值会越来越大。
3.2 用[0,1]范围标记位置
为了解决整型值带来的问题,可以考虑将位置值的范围限制在[0, 1]之内,其中,0表示第一个token,1表示最后一个token。比如有3个token,那么位置信息就表示成[0, 0.5, 1];若有四个token,位置信息就表示成[0, 0.33, 0.69, 1]。
但这样产生的问题是,当序列长度不同时,token间的相对距离是不一样的。例如在序列长度为3时,token间的相对距离为0.5;在序列长度为4时,token间的相对距离就变为0.33。
因此,我们需要这样一种位置表示方式,满足于:
(1)它能用来表示一个token在序列中的绝对位置
(2)在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致
(3)可以用来表示模型在训练过程中从来没有看到过的句子长度。
3.3 用二进制向量标记位置
考虑到位置信息作用在input embedding上,因此比起用单一的值,更好的方案是用一个和input embedding维度一样的向量来表示位置。这时我们就很容易想到二进制编码。如下图,假设d_model = 3,那么我们的位置向量可以表示成:
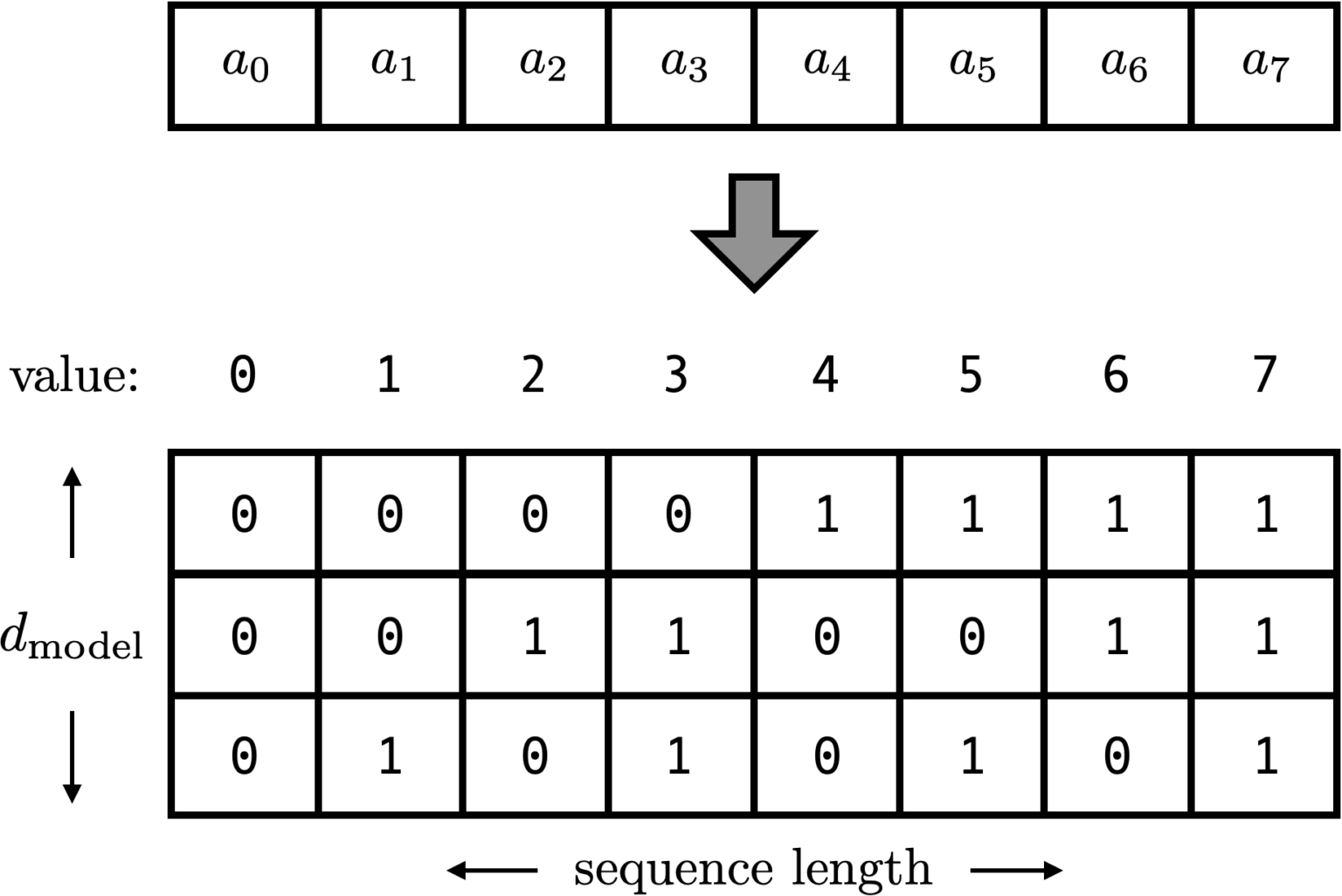
这下所有的值都是有界的(位于0,1之间),且transformer中的d_model本来就足够大,基本可以把我们要的每一个位置都编码出来了。
但是这种编码方式也存在问题:这样编码出来的位置向量,处在一个离散的空间中,不同位置间的变化是不连续的。假设d_model = 2,我们有4个位置需要编码,这四个位置向量可以表示成[0,0],[0,1],[1,0],[1,1]。我们把它的位置向量空间做出来:
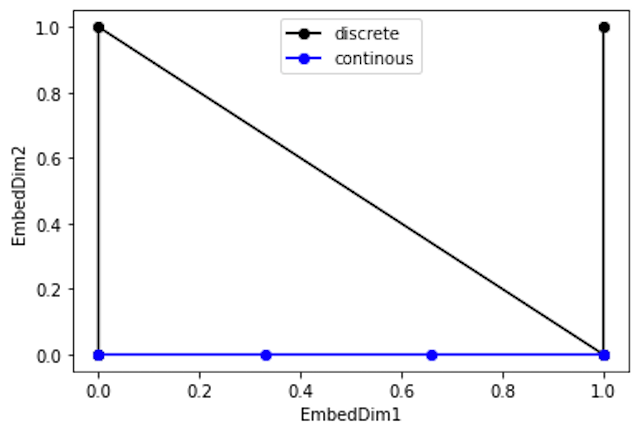
如果我们能把离散空间(黑色的线)转换到连续空间(蓝色的线),那么我们就能解决位置距离不连续的问题。同时,我们不仅能用位置向量表示整型,我们还可以用位置向量来表示浮点型。
3.4 用周期函数(sin)来表示位置
回想一下,现在我们需要一个有界又连续的函数,最简单的,正弦函数sin就可以满足这一点。我们可以考虑把位置向量当中的每一个元素都用一个sin函数来表示,则第t个token的位置向量可以表示为:
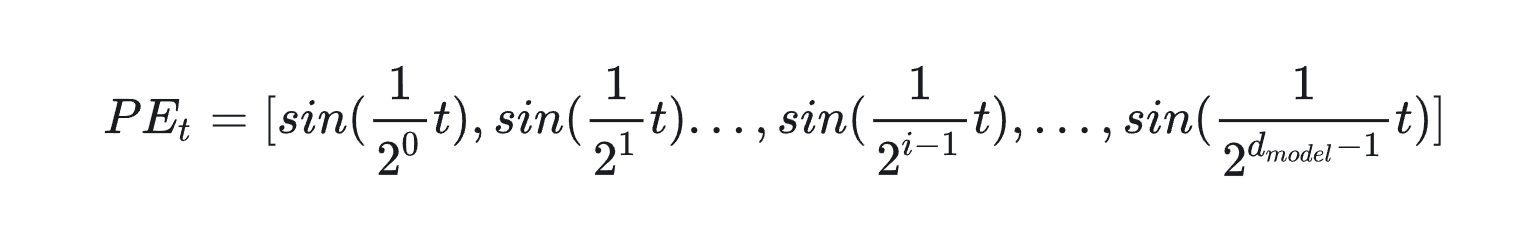
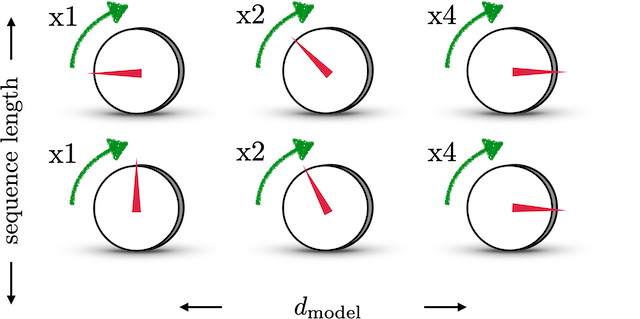
结合下图,来理解一下这样设计的含义。图中每一行表示一个 PEtPE_{t}PEt
,每一列表示 PEtPE_{t}PEt中的第i个元素。旋钮用于调整精度,越往右边的旋钮,需要调整的精度越大,因此指针移动的步伐越小。每一排的旋钮都在上一排的基础上进行调整(函数中t的作用)。通过频率 12(i−1)\frac{1}{2^(i-1)}2(i−1)1
来控制sin函数的波长,频率不断减小,则波长不断变大,此时sin函数对t的变动越不敏感,以此来达到越向右的旋钮,指针移动步伐越小的目的。 这也类似于二进制编码,每一位上都是0和1的交互,越往低位走(越往左边走),交互的频率越慢。
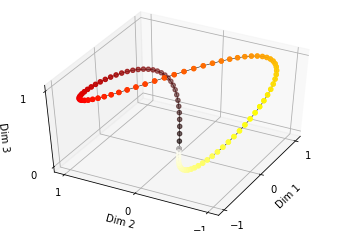
由于sin是周期函数,因此从纵向来看,如果函数的频率偏大,引起波长偏短,则不同t下的位置向量可能出现重合的情况。比如在下图中(d_model = 3),图中的点表示每个token的位置向量,颜色越深,token的位置越往后,在频率偏大的情况下,位置响亮点连成了一个闭环,靠前位置(黄色)和靠后位置(棕黑色)竟然靠得非常近:
为了避免这种情况,我们尽量将函数的波长拉长。一种简单的解决办法是同一把所有的频率都设成一个非常小的值。因此在transformer的论文中,采用了 110000i/dmodel−1\frac{1}{10000^{i/d_{\text{model}}-1}}10000i/dmodel−11这个频率(这里i其实不是表示第i个位置,但是大致意思差不多,下面会细说)
总结一下,到这里我们把位置向量表示为:
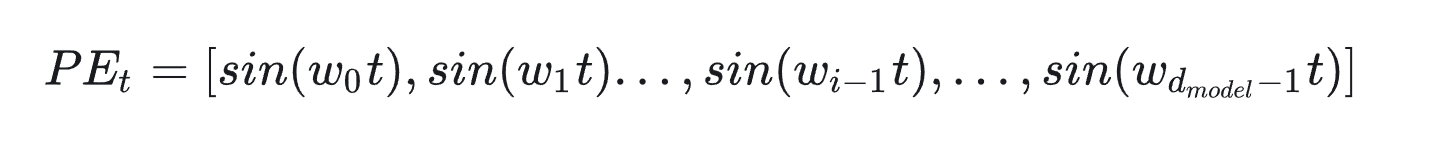
其中, wi = 110000i/dmodel−1\frac{1}{10000^{i/d_{\text{model}}-1}}10000i/dmodel−11
3.5 用sin和cos交替来表示位置
目前为止,我们的位置向量实现了如下功能:
(1)每个token的向量唯一(每个sin函数的频率足够小)
(2)位置向量的值是有界的,且位于连续空间中。模型在处理位置向量时更容易泛化,即更好处理长度和训练数据分布不一致的序列(sin函数本身的性质)
那现在我们对位置向量再提出一个要求,不同的位置向量是可以通过线性转换得到的。这样,我们不仅能表示一个token的绝对位置,还可以表示一个token的相对位置,即我们想要:
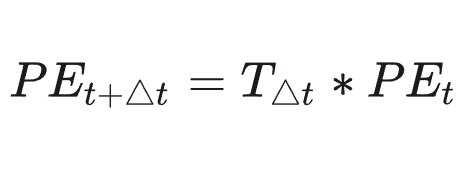
这里,T表示一个线性变换矩阵。观察这个目标式子,联想到在向量空间中一种常用的线形变换——旋转。在这里,我们将t想象为一个角度,那么▲t 就是其旋转的角度,则上面的式子可以进一步写成:
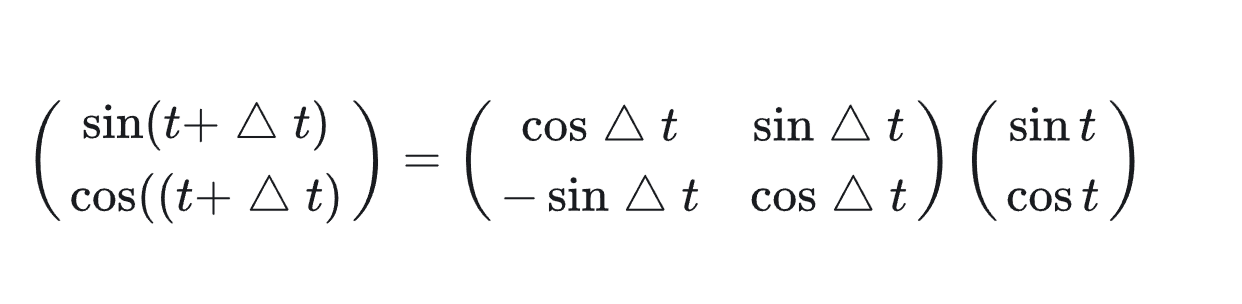
有了这个构想,我们就可以把原来元素全都是sin函数的 PEtPE_{t}PEt做一个替换,我们让位置两两一组,分别用sin和cos的函数对来表示它们,则现在我们有:
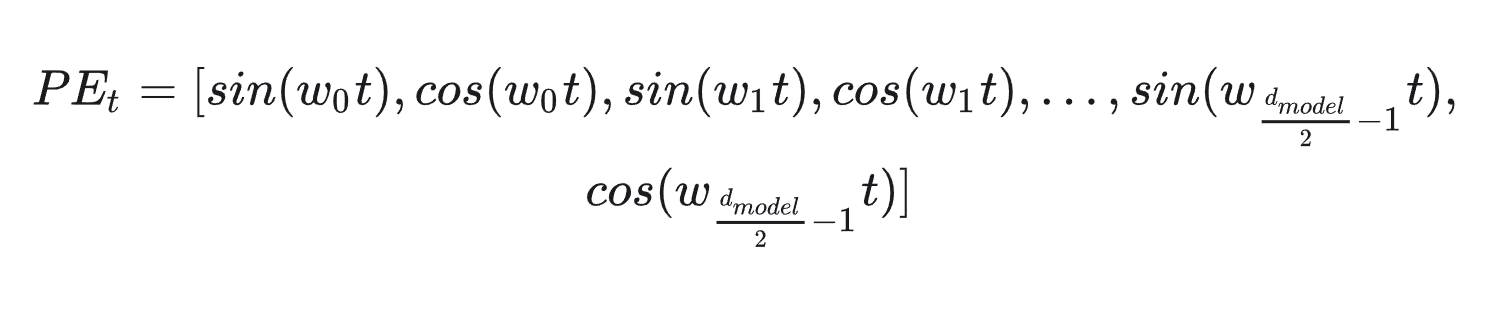
在这样的表示下,我们可以很容易用一个线性变换,把 PEtPE_{t}PEt转变为 PEt+▲tPE_{t+▲t}PEt+▲t
四、一些问题
-
为何是“相加”而非“拼接”?
- 直接原因:为了节省参数量。相加不会增加特征维度,而拼接会。
- 深层理由:作者认为这种操作没有明显的劣势。模型通过训练可以学会将信息分配到不同的维度中。具体来说,网络可能将前几个维度专门用于存储位置信息,而将后面的维度用于存储词汇的语义信息,从而避免干扰。相加操作反而可能为模型提供更丰富的特征组合以供学习。
-
位置信息如何传递到深层?
- 通过残差连接(Residual Connections)。残差连接允许底层信息(包括原始输入中的位置嵌入)直接 bypass 到更深的层,有效缓解了梯度消失问题,确保了位置信息能参与高层复杂的交互计算。
-
为何同时使用正弦和余弦函数?
- 核心优势在于线性变换性。同时使用正弦和余弦使得模型能够通过线性变换轻松地学习到相对位置关系(即对于某个位置偏移k,可以用sin(x)和cos(x)线性组合出sin(x+k)和cos(x+k))。这是使用单一正弦或余弦函数无法实现的特性,它极大地帮助了模型对位置关系的泛化。
参考:
Transformer Architecture: The Positional Encoding
Master Positional Encoding:
Transformer学习笔记一:Positional Encoding(位置编码)