RL-100:基于现实世界强化学习的高性能机器人操作
25年10月来自上海姚期智研究院、上海交大、香港大学、清华大学、北卡大学、CMU和中科院大学的论文“RL-100: Performant Robotic Manipulation with Real-World Reinforcement Learning”。
在家庭和工厂中,现实世界中的机器人操控要求可靠性、效率和稳健性接近甚至超越熟练的人类操作员。RL-100,是一个基于监督学习训练的扩散视觉运动策略的真实世界强化学习训练框架。RL-100 引入一个三阶段流程。首先,模仿学习利用人类先验知识。其次,迭代离线强化学习使用离线策略评估程序(简称 OPE)来门控应用于去噪过程的 PPO 式更新,以实现保守可靠的改进。第三,在线强化学习消除残余故障模式。额外的轻量级一致性蒸馏头,将扩散中的多步采样过程压缩为单步策略,从而实现高频控制,并将延迟降低一个数量级,同时保持任务性能。该框架与任务、具体化和表示无关,支持 3D 点云和 2D RGB 输入、各种机器人平台以及单步和动作块策略。在七项真实机器人任务中评估 RL-100,这些任务涵盖动态刚体控制,例如 Push-T 和 Agile Bowling、流体和颗粒倾倒、可变形布料折叠、精确灵巧拧螺丝以及多阶段榨橙汁。RL-100 在总共 900 个回合(共 900 次)的评估试验中获得 100% 的成功率,其中包括在单个任务中连续 250 次试验中高达 250 次的成功率。该方法实现了接近人类水平或更佳的时间效率,并展现出长达数小时的稳健性,可连续运行长达两小时。由此产生的策略将零样本推广到新的动态,平均成功率为 92.5%,并以少量样本的方式适应重大任务变化,经过一到三个小时的额外训练后,平均成功率达到 86.7%。
如图所示,本文方法包含三个阶段:(1) 从人类演示中进行模仿学习;(2) 逐步扩展数据的迭代离线强化学习;以及 (3) 在线微调。关键创新在于通过在扩散去噪步骤中应用共享的 PPO 式目标函数,统一离线和在线强化学习。
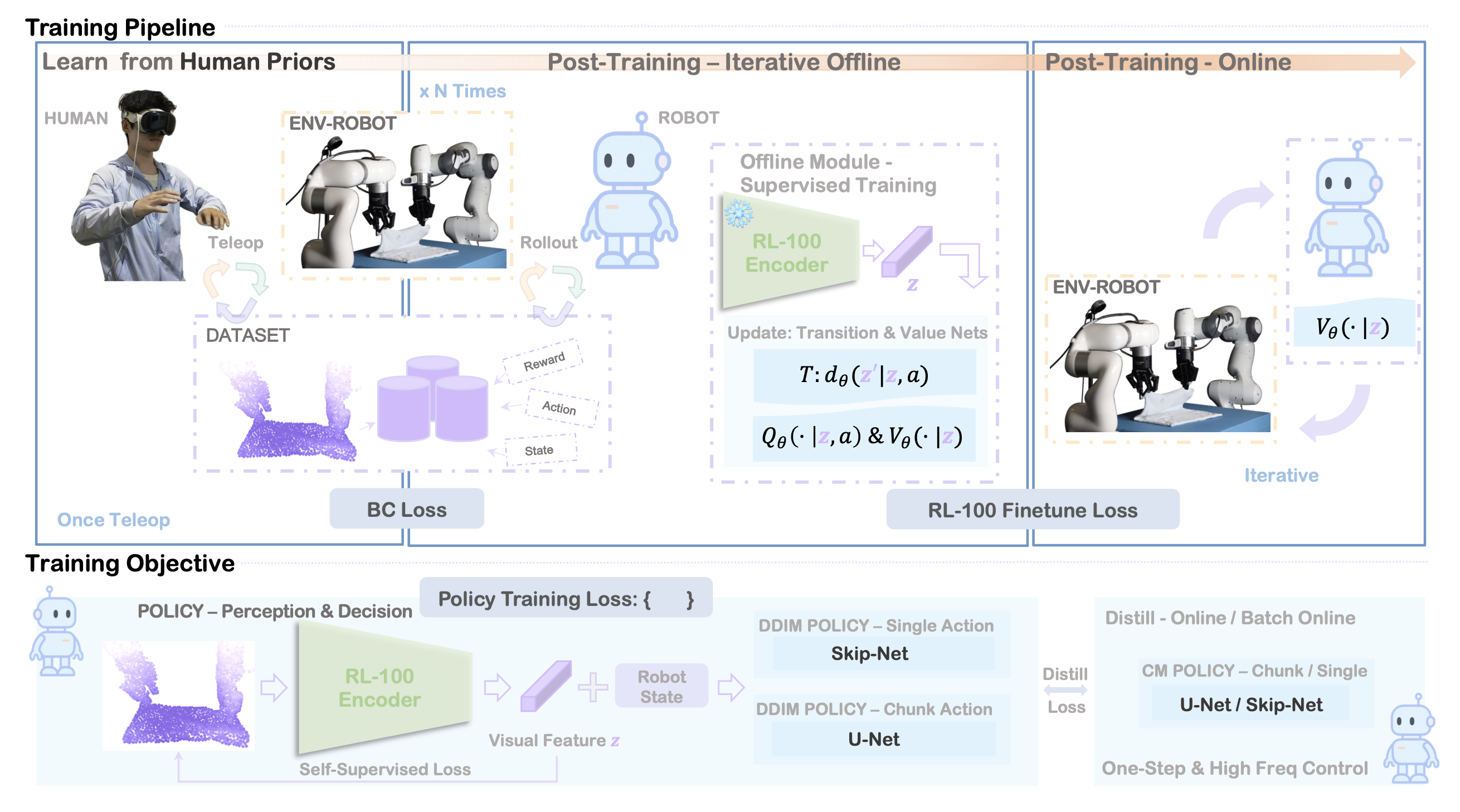
模仿学习
通过在人类遥控轨迹上进行行为克隆来初始化策略。该方法使用条件扩散,从演示中学习鲁棒的视觉运动策略。每个场景提供同步元组,其中 o_t 表示视觉观测值(RGB 图像或 3D 点云),q_t 表示机器人本体感觉(关节位置/速度、夹持器状态),a_t 表示单步动作或动作块。
条件化和预测范围。将最近的观测值融合成一个条件向量 c_t,其中感知编码器 φ(·) 处理最近的 n_o 帧(通常 n_o = 2),[·] 是连接多个向量的算子。时间步 t 的纯净扩散目标 aτ_0_t 设置为单个动作 aτ_0_t =u_t 或动作块 aτ_0 = [u_t,…,u_t+n_c-1],其中 n_c 是块大小(通常为 8–16)。动作按维度进行归一化;会在适用的情况下预测末端执行器姿态的增量。
扩散参数化。在对动作进行条件扩散之后,通过前向过程将 aτ_0_t 污染为 aτ_K_t。降噪器 ε_θ (aτ, τ , c_t) 使用噪声预测目标 L_IL(θ) 进行训练,其中 D 为演示数据集,τ ∈ {τ_K > · · · > τ_1} 表示 K 步调度,ε ∼ N (0, I)。策略主干在不同控制模式之间共享;只有输出头不同:Rd_a(单步)或 Rn_cd_a(分块)。
视觉和本体感觉编码器。对于 RGB 输入,用预训练的 ResNet/ViT 主干网络;对于点云输入,调整 DP3 (Ze et al. 2024) 的 3D 编码器,并使用重建正则化来确保强化学习微调期间的稳定性。视觉嵌入被投影并与本体感受特征连接起来形成c_t。所有编码器都使用L_IL 进行端到端训练。
在适用的情况下,添加重建 (Recon) 和变分信息瓶颈 (VIB) 正则化:L_recon,其中 o 和 q 表示观测点云和本体感受向量;oˆ 和 qˆ 是给定编码嵌入 φ(o,q) 的重建观测值;d_Chamfer 是两组点云之间的倒角距离。完整的模仿学习目标函数为:LIL_total = L_IL + L_recon + L_KL。
在强化学习微调过程中,将 β_recon 和 β_KL 减小 10 倍,以便在保持表征稳定性的同时改进策略。
推理和控制。在部署时,K 步 DDIM 采样(公式 (5))生成动作:aˆτ_0。单步控制立即执行 u ← aˆτ_0;分块控制在接下来的 n_c 个时间步执行 [u_t , . . . , u_t+n_c −1 ] ← aˆτ_0_t。单步控制在反应性任务(例如动态保龄球)中表现出色,而动作分块则可减少精准任务(例如组装)中的抖动。两种模式共享相同的架构,从而实现任务自适应部署。
统一的离线和在线强化学习微调
处理单个动作与动作块。该框架支持单步和分块动作执行,这会影响价值计算和信用分配:
单个动作:标准 MDP 公式,每步奖励为 R_t,折扣为 γ。
动作块:每个包含 n_c 个动作的块被视为一个决策。每个块的累积奖励为 R_chunk = R_t:t+nc−1 = sum(γj R_t+j)_j=0:n_c-1,各块之间的等效折扣因子为 γn_c。
为了清晰起见,只介绍单动作的情况;分块情况的工作原理类似,只需将每步的数量替换为相应的块。
双层MDP结构。该方法在两个时间尺度上运行:
- 环境MDP:标准机器人控制,状态为s_t,动作为a_t,奖励为R_t
- 去噪MDP:K步扩散过程,通过迭代细化生成每个aτ_0_t
去噪MDP嵌入到每个环境时间步中,创建一个分层结构,其中K个去噪步骤产生一个环境动作。
去噪步骤的统一PPO目标。鉴于双层MDP结构,通过对所有去噪步骤k求和,优化迭代i中每个时间步t相对于K步扩散过程的PPO目标 J_i(π),而损失函数是 Loff_RL =J_i(π)。
其中 r_k(π) 是每个去噪步骤的重要性比率,A_t 是与环境时间步 t 相关的任务优势。其中,π_i 表示 PPO 第 i 次迭代中的行为策略,ρ_π 是当前策略 π 下的(折扣)状态分布。关键在于在所有 K 个去噪步骤中共享相同的环境级优势 A,从而在整个去噪过程中提供密集的学习信号,同时保持与环境奖励结构的一致性。
离线强化学习
设置。给定离线数据集 D,用从 IL 获得的扩散策略初始化行为策略:π_0 :=πIL。在此纯离线阶段不收集任何新数据。
D 的策略改进。在离线迭代 i 中,用离线策略比率 roff_k(π) 和标准裁剪,优化应用于 K 个去噪步骤的 PPO 风格代理(J_i(π))。离线优势 Aoff_t,其中critics (Q_ψ,V_ψ) 按照 IQL (Kostrikov et al. 2022) 在 D 上进行预训练。这将通过在 D 上进行多个迭代的梯度更新,从 π_i 生成候选策略 π。
OPE 门控和迭代推进。用 AM-Q(Lei et al. 2024)进行离线策略评估(OPE),无需与环境进行进一步交互,将候选策略与当前行为策略进行比较得到JAM-Q(π)。这种 OPE 门控规则在 D 上产生保守、单调的行为策略改进。
共享和冻结编码器。为了确保稳定的表征学习和高效的计算,离线强化学习流水线中的所有组件共享同一个固定的视觉编码器 φ,该编码器在模仿学习期间进行预训练。在离线强化学习期间,保持 φIL 固定,并且只更新每个模块的任务特定头。
在线强化学习
在线阶段使用在线策略组件。对每个扩散步骤 ron_k(π) 使用一个在线策略比率,并使用 GAE 计算优势Aon_t,在所有 K 个产生时间 t 环境动作的去噪步骤中共享相同的 Aon_t。
最小化总损失:Lon_RL。
蒸馏到一步一致性策略
高频控制对于机器人应用至关重要。虽然扩散策略实现强大的性能,但 K 步去噪过程引入延迟,这可能会限制实时部署。为了解决这个问题,联合训练一个一致性模型 c_w,该模型学习在一步内将噪声直接映射到动作,并从多步扩散教师 π_θ 中蒸馏知识。
在离线和在线强化学习训练中,都使用一致性蒸馏损失 L_CD(θ) 来增强策略优化目标:L_total = L_RL + λ_CD · L_CD,其中 L_RL 是离线目标(基于 IQL 的优势)或在线目标(基于 GAE 的优势)。在一致性损失函数 L_CD 中教师策略是扩散策略 π_θ,它以观察结果为条件进行 K 步去噪。停止梯度算子确保教师策略通过强化学习目标持续改进,同时充当蒸馏目标。
高频控制对于工业环境中实际部署至关重要。首先,更快的控制回路直接转化为更高的任务完成效率——与 10 Hz 运行相比,以 20 Hz 运行的机器人可以在一半的时间内完成相同的轨迹,从而显著提高工厂自动化的吞吐量,因为周期时间直接影响生产率。其次,许多操作任务本质上需要高频反馈才能可靠地执行。诸如捕捉移动物体、在滑动过程中保持接触或从意外干扰中恢复等动态任务需要低于 50 毫秒的响应时间,而多步扩散策略无法提供。此外,当控制频率低于临界阈值时,涉及柔顺控制、力反馈或人机协作的任务通常会灾难性地失败,因为系统无法足够快速地做出反应来防止过大的力或保持稳定的接触。
在推理过程中,一致性模型在单次前向传递中生成动作:aτ_0 = c_w (aτ_K , τ_K |o),实现 K 倍加速(例如,从 100 毫秒到 10 毫秒的延迟),同时保持扩散策略的性能。这种数量级的改进使其能够部署在现实世界的制造场景中,在这些场景中,机器人必须保持一致的周期时间,响应传送带速度,并与人类工人一起安全操作——这些要求对于标准的多步扩散策略来说是不可行的。
整体训练框架
虽然上述每个组件都可以独立使用,但该文提出一个迭代过程,将它们组合起来以逐步改进。不是将离线强化学习一次性应用于固定的演示,而是交替进行:在当前数据集上训练学习逻辑策略,通过离线强化学习进行保守更新改进,使用改进的策略收集新数据,然后在扩展的数据集上重新训练学习逻辑策略,这些步骤在 如下算法1中进行了总结。这形成了一个良性循环,更好的策略产生更好的数据,进而能够学习到更好的策略。

IL 重训练的重要性。在扩展数据集上使用 IL 进行重训练(算法 1 第 13 行)至关重要,原因如下:
分布偏移:随着更高质量轨迹的添加,IL 能够自然地适应不断变化的数据分布
稳定性:在混合质量数据上,监督学习比强化学习更稳定
多模态性:IL 保留扩散策略对多种解模式进行建模的能力
蒸馏:IL 有效地将人工演示和强化学习改进提炼成统一的策略
最终在线微调。在迭代离线过程收敛后,应用在线强化学习进行最终性能优化。此阶段的优势在于:(1) 迭代离线训练的强大初始化,(2) 加速学习的预训练值函数,以及 (3) 用于重放和正则化的多样化数据集。
方差裁剪,实现稳定探索。为了确保强化学习微调过程中的稳定学习,在随机 DDIM 采样过程中引入方差裁剪。具体来说,限制每个去噪步骤的标准差:σ ̃_k =clip(σ_k,σ_min,σ_max),其中 σ_k 是原始 DDIM 方差参数,[σ_min , σ_max ] 定义允许的范围。这种修改有效地限制行为策略π_θ(aτ_k−1|aτ_k, τ_k) = N(μ_θ(aτ_k, τ_k), σ ̃2_k I)的随机性,从而防止:
当σ_t过大时,过度探索会导致分布外的行为,从而破坏训练的稳定性或导致物理系统的安全违规。
当σ_t趋近于零时,过早收敛会导致探索失效,从而阻止策略发现更优模式。
在实践中,设置σ_min = 0.01,以便在后期去噪步骤中保持最小探索;设置σ_max = 0.8,以防止在早期步骤中出现破坏性探索。
这种有界方差确保重要性比率 r_k (π) = π(aτ_k−1 |sk ) π_i (aτ_k−1 |sk ) 在 PPO 更新期间保持良好表现,因为当前策略和行为策略之间避免极端的方差差异。
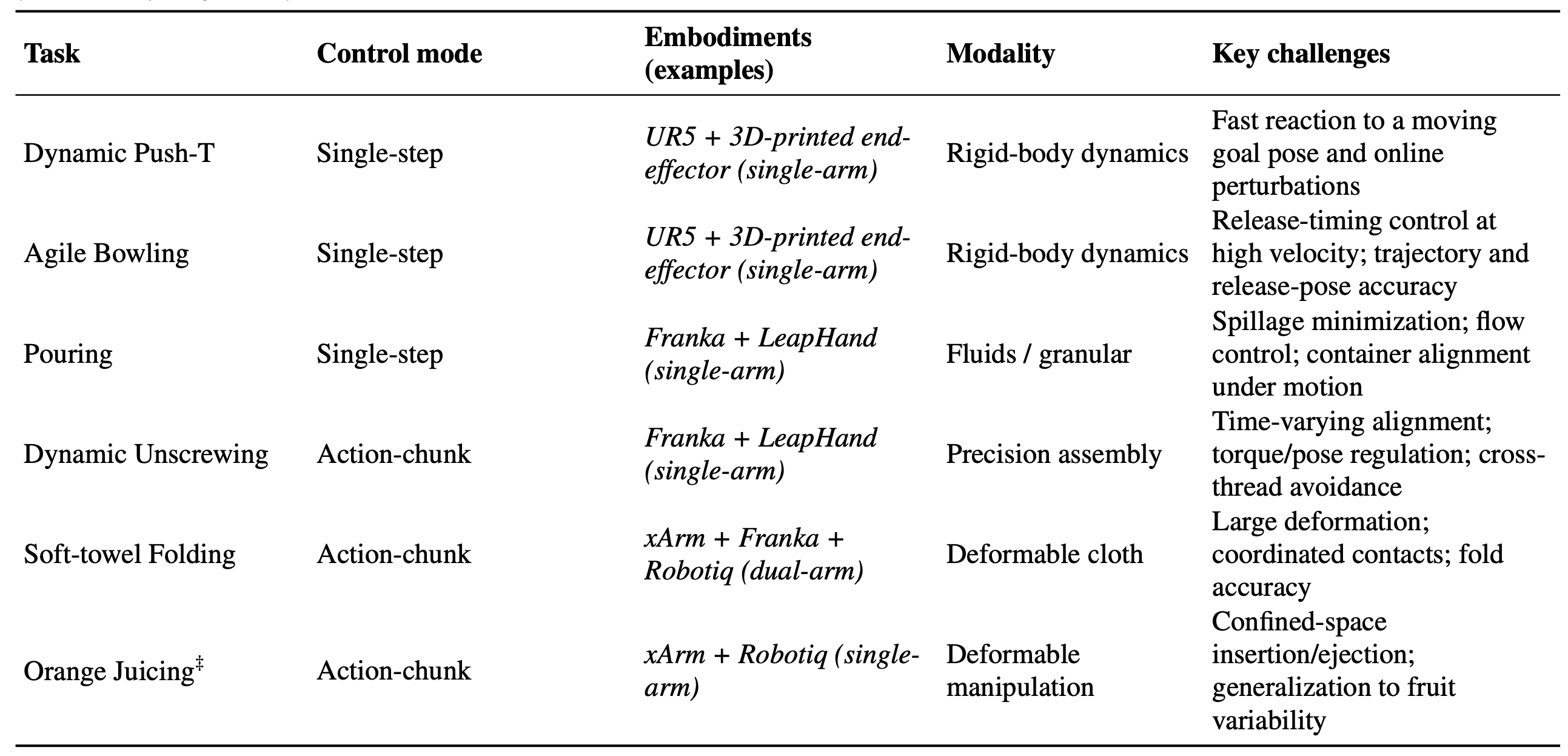
在七项现实世界的操控任务中评估 RL-100,这些任务涵盖动态刚体控制、可变形体处理和精密装配(如表任务套件、实施例和控制模式,如图所示真实机器人快照),以全面评估框架的多功能性。该套件涵盖单臂和双臂实施例(UR5、Franka 搭配 LeapHand、xArm–Franka)以及两种控制模式(单步操作 vs. 分块操作序列)。

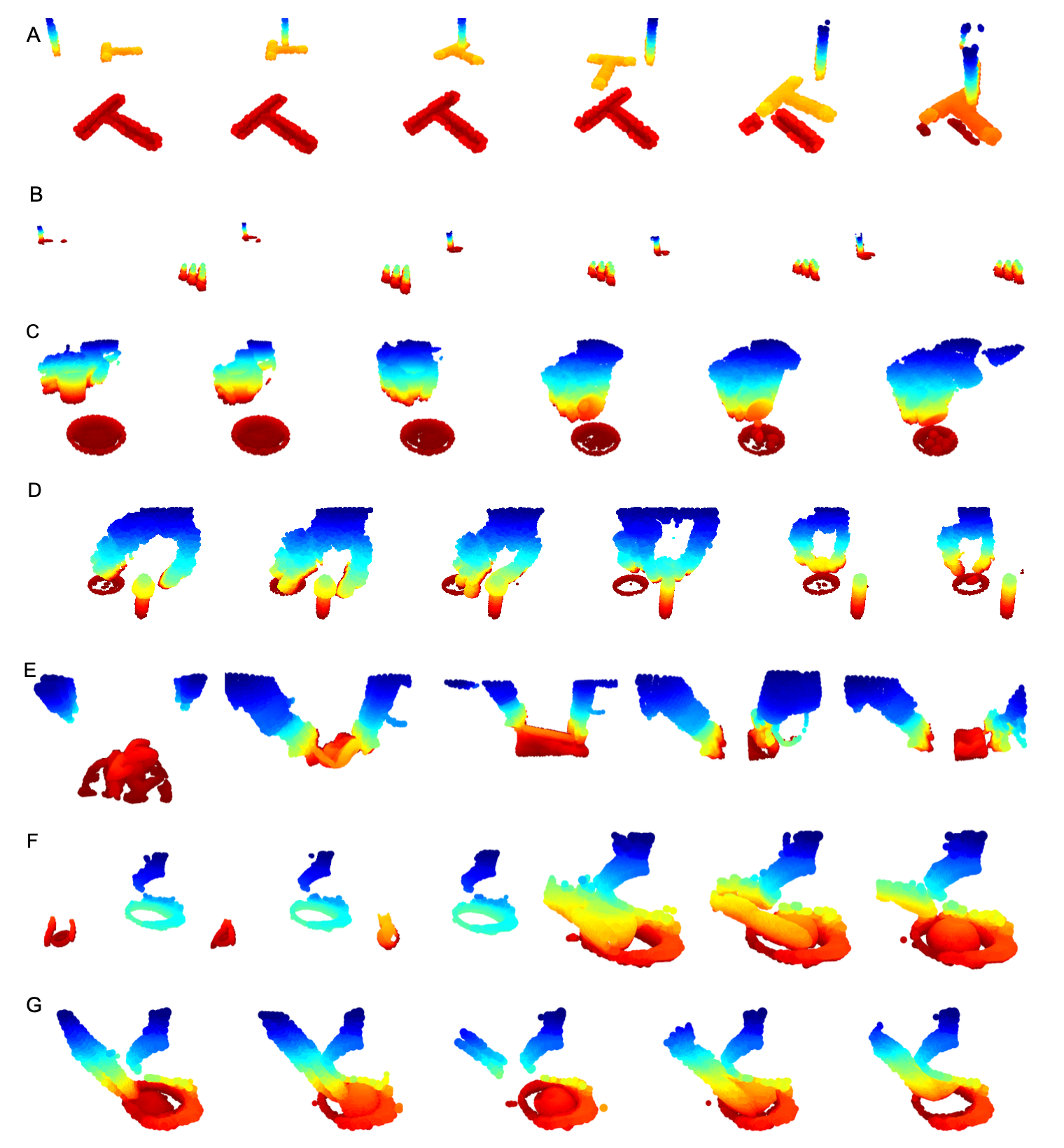
每个任务的轨迹可视化图像和点云分别如下图所示:

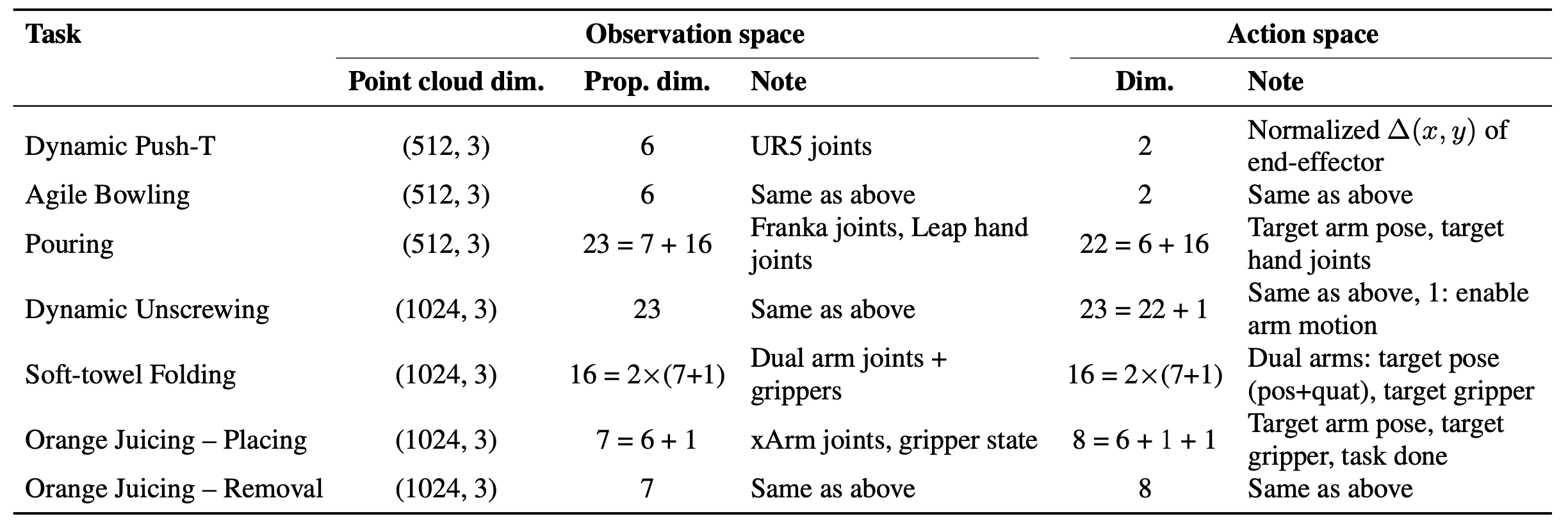
下表总结所有任务的观测空间和动作空间的关键规范:
为了促进策略泛化,会随机化每次试验的初始物体位置,如图展示每个任务的具体范围。任务采用两种奖励结构。对于除动态 Push-T 之外的五项任务,用稀疏奖励函数,其中状态在成功完成任务时获得 +1 的奖励,在所有其他时间步获得 0 的奖励,由人类监督者按下键盘进行标记。动态 Push-T 任务需要连续、高精度的控制,因此采用了密集形状的奖励。每个时间步 t 的总奖励为 r_t = r_pose + r_static + r_smooth,其中 r_pose = exp(−3e) − 1 惩罚 T 块与期望姿势之间的 SE(3) 差异 e;如果 T 块在某个时间步的移动低于给定阈值,则 r_static = −1,否则为 0;r_smooth = −5||a_t − a_t−1||2_2 惩罚不稳定的动作。

在各项任务中,RL-100 的成功率和完成时间均高于基线模型和人类操作员,尤其是在需要快速在线校正(动态接触、狭窄间隙)或在姿态变化下保持稳定灵巧抓取的场景中,其提升尤为显著。全面的鲁棒性协议评估零样本或少样本迁移在复杂变化(例如,物体变化、视觉干扰、外部扰动)下的性能表现。结果表明,在这些变化下,RL-100 的性能保持率始终如一。
为了补充在真实机器人上的评估,在模拟环境中对 RL-100 进行基准测试,并将其与最先进的基于扩散/流的离线到在线强化学习方法进行比较,包括 DPPO(Ren,2024)、ReinFlow(Zhang,2025)和 DSRL(Wagenmaker,2025)。