LLMs之Router:vLLM Semantic Router的简介、安装和使用方法、案例应用之详细攻略
LLMs之Router:vLLM Semantic Router的简介、安装和使用方法、案例应用之详细攻略
目录
vLLM Semantic Router的简介
1、工作原理
2、核心架构
3、主要特性
4、价值与意义
5、限制与发展方向
vLLM Semantic Router的安装和使用方法
1、安装
先决条件(System requirements)
T1、本地安装(Local)
T2、其他部署方式
2、使用方法
vLLM Semantic Router的案例应用
vLLM Semantic Router的简介
vLLM Semantic Router 是一个面向高性能推理场景的智能路由框架。它采用 Mixture-of-Models (MoM) 的思路,核心思想是通过语义理解将用户请求智能地分派给最合适的模型或服务。这与传统仅根据服务器负载进行路由的方式不同,它旨在深入理解用户请求的语义内容,从而在提升推理准确性的同时,优化成本与延迟。总的来说,vLLM Semantic Router代表了大模型推理优化领域一个值得关注的发展方向。它通过语义层面的智能路由,将请求定向到最合适的处理单元,为实现高效、低成本且高准确性的大规模模型服务提供了有力的技术支撑。
vLLM Semantic Router 是一个面向开源 LLM 推理栈的“意图感知路由层”(intent-aware routing layer),用于在混合模型池(mixture-of-models)中智能判断请求的语义/复杂度并把请求路由到最合适的推理路径或模型——例如把简单查询走“快速路径”,把复杂或高价值的任务走带 Chain-of-Thought(CoT)或 reasoning 的“慢路径”。它旨在在保证关键任务准确性的同时大幅提升每 token 的效率与延迟表现,从而实现更经济且可控的推理。
vLLM Semantic Router: Next Phase in LLM inference:https://blog.vllm.ai/2025/09/11/semantic-router.html
Github地址:https://github.com/vllm-project/semantic-router
官网:https://vllm-semantic-router.com/
1、工作原理
其核心在于 语义感知的路由(Semantic Router) 。具体工作流程如下:
>> 语义理解:当一条完整的用户请求进入时,系统会首先使用一个轻量的语义编码器对请求进行语义判别和理解。
>> 模型选择:根据理解后的语义,系统一次性决定该请求应该交给哪一个模型或模型组合(Mixture of Models)来处理,而不是像MoE架构那样在Token级别选择专家。
>> 执行推理:请求被路由到选定的最合适的模型上执行任务。
这种方法的优势在于,它能根据完整的用户请求意图而非孤立的Token来做出路由决策。例如,对于一个复杂的数学问题,路由器可以将其分配给擅长深度思考的模型(如DeepSeek-R1);而对于一个简单的天气查询,则会选择更经济、快速的模型,从而节省Token消耗和算力。
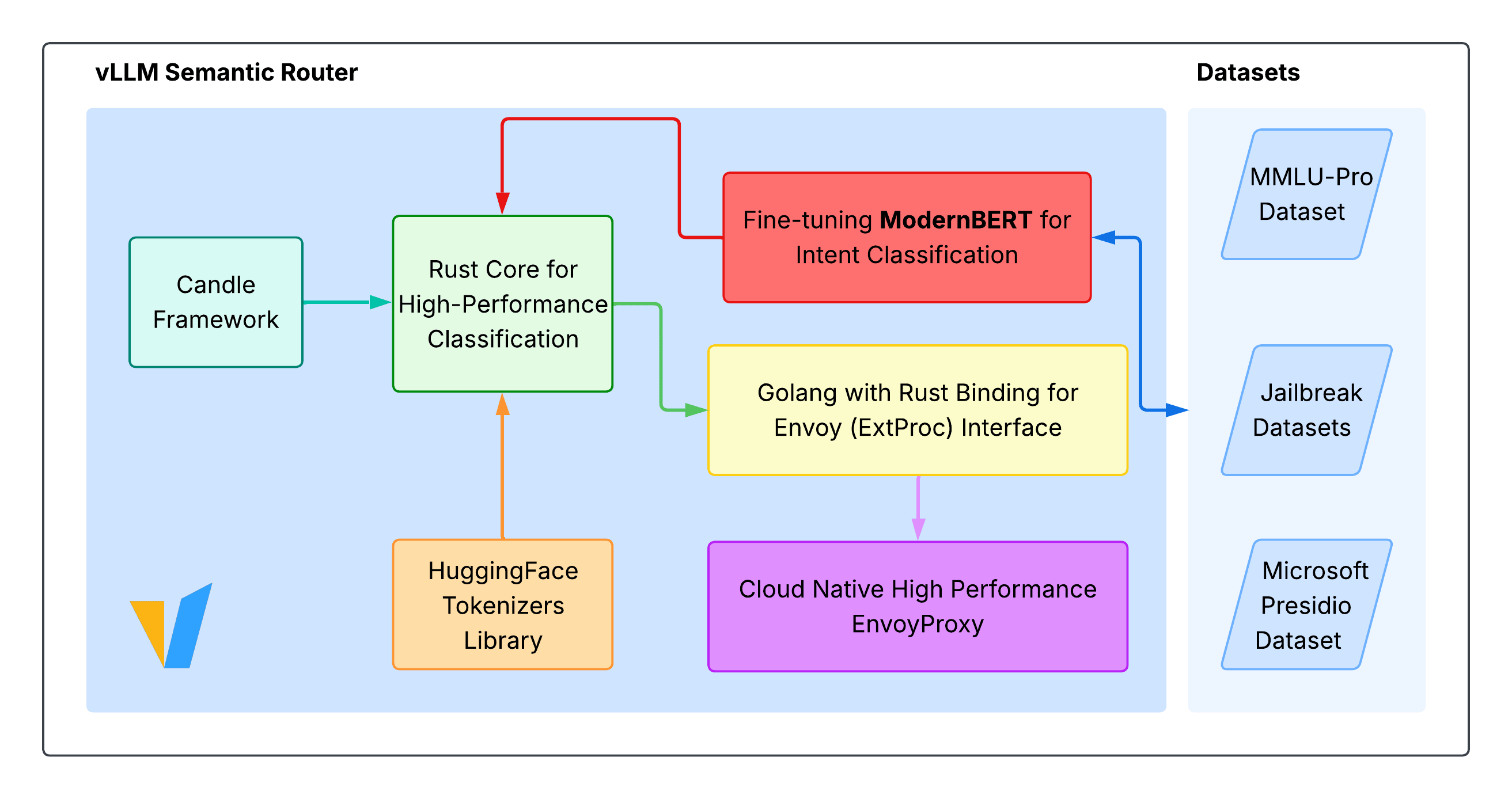
2、核心架构
>> 语义分类(Semantic Classification):在 router 内部采用轻量级的 BERT 系列(文档中称为 ModernBERT)作为分类器,用于判断请求的意图、复杂性和是否涉及敏感内容(PII/jailbreak 等)。这个分类器决定后续路由策略(快速路径 / reasoning 路径 / 指定模型等)。
>> 智能路由(Smart Routing / Mixture-of-Models):概念上类似 Mixture-of-Experts,但路由器选的是“整个模型”或“路径”(例如:轻量模型 vs reasoning-enabled 模型)。路由决策会综合复杂度、工具需求、域(domain)与性能约束。
>> 高性能推理引擎绑定(Engine & bindings):Router 的实现包含 Rust 的高性能 Candle 绑定(zero-copy 推理),并以 Go 语言实现路由二进制。项目通过 Candle + vLLM 生态来实现高并发与低延迟。
>> 云原生与边缘集成(Cloud-native & Networking):提供与 Kubernetes、Envoy(通过 ext_proc 插件)的开箱即用集成,支持在企业级网络与服务网格(service mesh)中部署。路由器会通过 Envoy 代理组合到现有流量链路中。
>> 语义缓存 & 安全控制:内建“语义相似性缓存”(semantic cache)以复用相近提示、降低 token 使用;并提供 PII 检测、Prompt Guard(防越狱)等安全能力。
3、主要特性
基于语义的分类器:支持BERT分类器或MoM路由方式进行智能模型选择。
>> 相似度缓存:通过相似度缓存技术来降低重复计算,有效减少延迟。
>> 企业级安全:集成了PII(个人可识别信息)检测与Prompt守卫等安全特性。
>> 多语言实现:框架主体采用Go语言编写,同时提供了Python基准测试与Rust绑定。
>> 广泛的集成支持:支持与vLLM、Hugging Face Candle等主流后端集成,并提供了Grafana仪表盘示例与部署脚本。
>> 意图/复杂度感知的路由:基于 ModernBERT 做实时分类,自动判断是否需要深度推理(reasoning)。
>> 按需激活 reasoning(按价值分配推理预算):避免“所有请求都做 CoT”所带来的成本和延迟,同时把推理资源留给真正需要的查询。
>> 混合模型选择(Mixture-of-Models):可配置模型池,按任务类型/域分配不同模型。
>> 语义缓存(Semantic Caching):用语义相似性匹配来复用答案或部分结果,从而减少重复 token 消耗并降低延迟。
>> 企业部署友好(K8s + Envoy + observability):支持 Kubernetes、Envoy ext_proc、Prometheus/Grafana/Jaeger 等监控链路与
>> 安全与合规辅助:PII 检测、prompt-guard、路由策略可限制工具调用与模型访问。
4、价值与意义
vLLM Semantic Router的核心价值在于它能够智能地在推理效率、成本与准确性之间取得最佳平衡。
研究表明,对于许多简单的提示而言,进行复杂的推理是不必要的,这会带来显著的延迟和Token消耗成本。Semantic Router通过根据推理需求对查询进行分类,并仅在推理能带来益处时选择性地应用推理,实现了:
>> 显著提升准确性:在MMLU-Pro基准测试中,与直接使用vLLM进行推理相比,准确率提高了10.2%。
>> 大幅降低资源消耗:同时将响应延迟降低了47.1%,令牌消耗降低了48.5%。
这意味着它为企业部署大模型提供了一种有效的机制,能够在开源LLM服务系统中同时兼顾准确率和效率。
>> 提升单位 token 的经济性:通过只在必要时启用昂贵 reasoning,减少不必要的 token 消耗,从而节省成本并降低碳/算力开销。
>> 权衡准确率与成本:在博客与内测里观察到整体可带来 ~10% 的准确率提升、约 50% 的延迟与 token 使用下降(在部分业务域,金融/经济类任务准确率提升可超过 20%),这表明对“何时推理”做决策比一味追求更大模型参数更有实际价值。
>> 落地企业场景:提供可观测的路由决策头(response headers),便于审计与 SLO 控制,适合在有严格延迟和合规要求的企业环境中部署。
5、限制与发展方向
>> 推理预算管理难题:无限制地开启 reasoning 会提高冷启动延迟和资源消耗,路由器需要结合 SLO(TTFT、p95 latency)来做动态控制。
>> 工具调用规模问题(tool catalog bloat):过多工具或超长工具输出会降低整体准确率,router 需在调用前作工具筛选与精简。
>> 目前 classifier 的部署方式:ModernBERT 现在是内嵌在 router 中的轻量分类器,未来计划把分类器或 embedding 模型做成可插拔(pluggable),以便更紧密地与 vLLM 或外部 embedding 服务整合,增强语义缓存与自定义能力。
vLLM Semantic Router的安装和使用方法
1、安装
先决条件(System requirements)
Go ≥ v1.24.1
Rust ≥ v1.90.0(用于 Candle 绑定)
Python ≥ 3.8(用于模型下载脚本)
huggingface_hub CLI(pip install huggingface_hub)
Router 在 CPU 上即可运行(不强制 GPU)。
T1、本地安装(Local)
克隆仓库:
git clone https://github.com/vllm-project/semantic-router.git
cd semantic-router安装/检查依赖(Go / Rust / Python / HF CLI),按文档提示安装 rustup、go、pip 包 等。
构建项目(会同时构建 Rust candle-binding 和 Go 二进制):make build # 可执行文件会被放到 bin/router
下载预训练模型(约 1.5GB,包含分类、PII/jailbreak 模型):make download-models
注:make test 会自动调用 make download-models。
配置后端 LLM endpoint(编辑 config/config.yaml)——示例片段:
vllm_endpoints:- name: "your-endpoint"address: "127.0.0.1"port: 11434models:- "your-model-name"weight: 1
model_config:"your-model-name":pii_policy:allow_by_default: falsepii_types_allowed: ["EMAIL_ADDRESS","PERSON","GPE","PHONE_NUMBER"]preferred_endpoints: ["your-endpoint"]
注意:config 中 address 必须是 IP(如 127.0.0.1),不能使用域名或 localhost;model 名称必须精确匹配 vLLM 服务启动时的 --served-model-name 参数。
vllm-semantic-router.com
启动(两个终端):
终端 1:启动 Envoy(示例命令)
make run-envoy
终端 2:启动 Semantic Router
make run-router
测试(curl 示例):
curl -X POST http://localhost:8801/v1/chat/completions \-H "Content-Type: application/json" \-d '{"model": "auto","messages": [{"role": "user", "content": "What is the derivative of x^2?"}]}'
启动后,Router 会在响应头中加入若干决策追踪字段(x-vsr-selected-category, x-vsr-selected-reasoning, x-vsr-selected-model),便于了解请求是被如何分类与路由的。
T2、其他部署方式
官方文档还提供 Kubernetes / Docker-Compose 的安装说明与全局配置(文档目录包含 “Install in Kubernetes” 与 “Install in Docker Compose”)。若需生产级别部署,推荐参考官方的 Kubernetes 指南与 Envoy 配置。
2、使用方法
>> 配置模型池与路由策略:通过 config/config.yaml 指定多个后端 endpoint、模型权重、PII 策略与 preferred_endpoints,从而按域/任务把请求引导到不同模型。
>> 查看路由决策:响应头中的 x-vsr-* 字段会标记路由器选择的 category、是否启用 reasoning、最终选中模型,便于线上审计与 SLO 分析。
>> 监控与 Dashboard:项目提供 Grafana 仪表板示例,可展示路由拓扑、意图分布与模型性能指标(官方 demo 与 dashboard 已在官网展示)。
vLLM Semantic Router的案例应用
对话机器人/客服系统:把简单 FAQ、检索型问答走快速路径,把复杂的法律/金融/多步规划问题走 reasoning-enabled 模型,从而在响应速度与准确率间取得平衡。官方在行业试验中(尤其是商业与经济领域)观察到显著准确率与效率提升。
企业内部知识检索 + 合规过滤:结合 PII 检测与语义缓存,既能避免敏感数据泄露,又能通过缓存减少重复 token 消耗。
多模型混合(开源模型 + 私有模型)路由:可把轻量开源模型用于低价值请求,把更昂贵或专用模型用于高价值/需要 domain knowledge 的请求。