现代机器人学习入门:一份来自Hugging Face与牛津大学的综合教程开源SOTA资源库
随着机器学习,特别是多模态大模型技术的飞速发展,机器人学正在经历一场从经典范式向数据驱动范式的深刻变革。机器人学习(Robot Learning)已成为推动这一领域发展的核心支柱。为了帮助研究人员与实践者系统地掌握这一前沿领域,Hugging Face 与牛津大学的研究者共同撰写了一份全面的技术教程,并配套开源了基于 PyTorch 的机器人学习库 LeRobot。
这篇教程旨在全面勾画现代机器人学习的技术图景:从强化学习(Reinforcement Learning)和模仿学习(Imitation Learning)的基础原理,到能够跨任务、跨形态执行任务的通用机器人策略。

论文标题: Robot Learning: A Tutorial
论文链接: https://arxiv.org/abs/2510.12403v1
GitHub (LeRobot): https://github.com/huggingface/lerobot
模型与数据集: https://huggingface.co/lerobot
点击阅读原文,获取更多相关信息
LeRobot 是一个端到端的开源机器人库,它深度整合了从底层硬件控制、高效数据处理与推理优化,到上层SOTA学习算法的完整技术栈,旨在降低真实世界机器人学习的门槛。
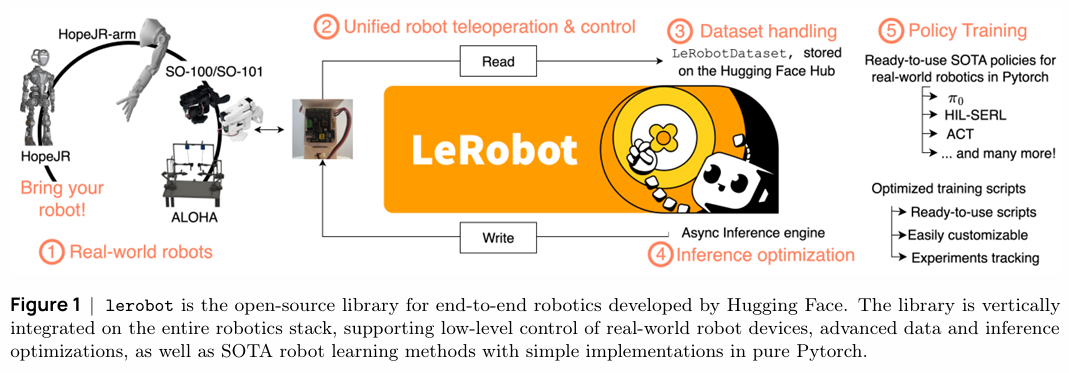
接下来,我们将遵循该教程的结构,深入解读其核心内容。
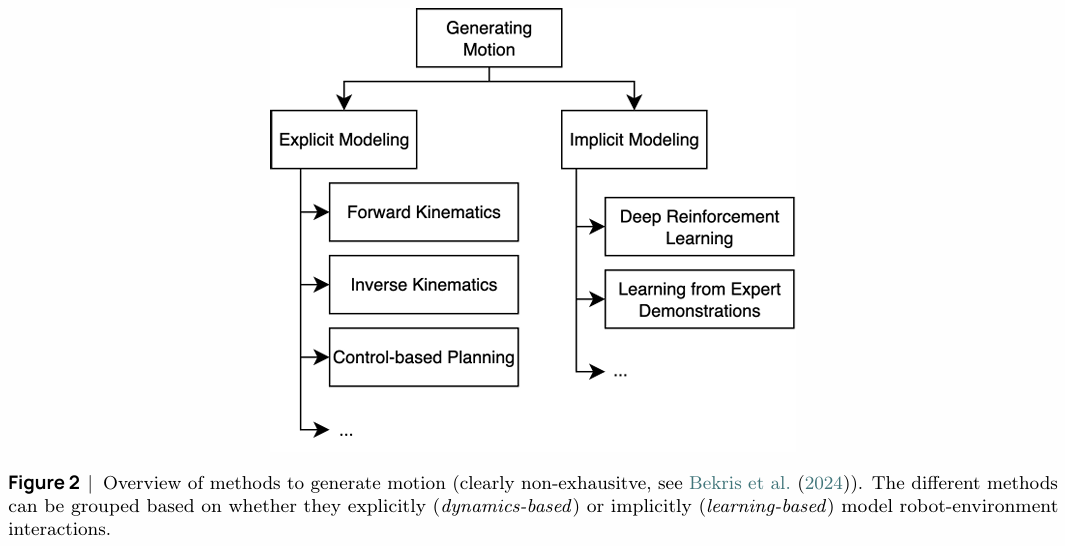
1. 经典机器人学及其局限性
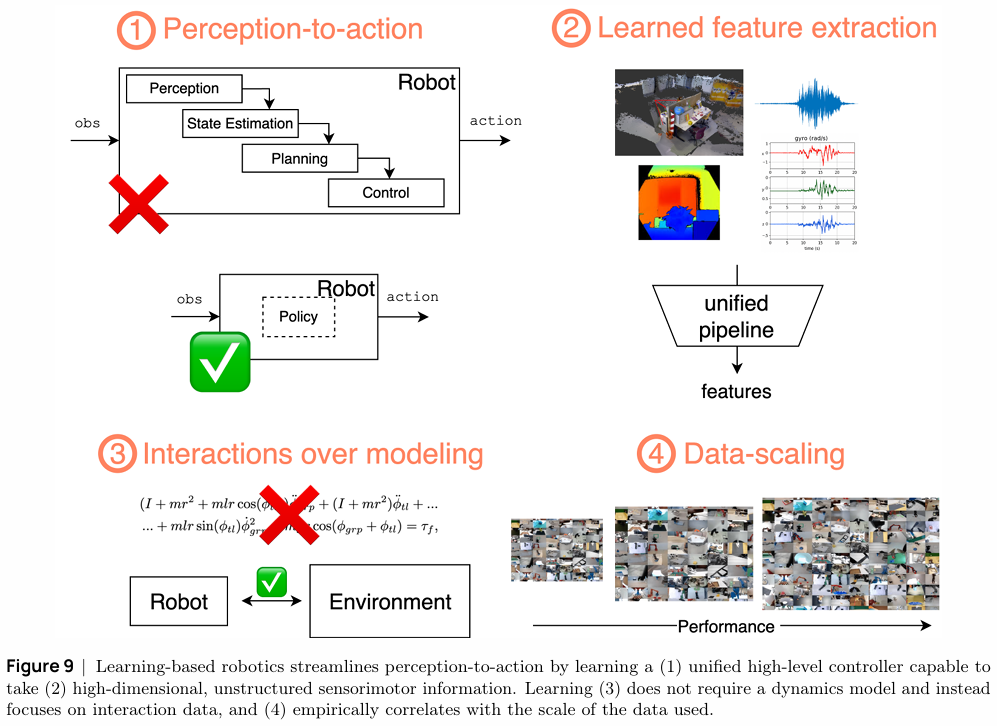
传统机器人学依赖于对世界和机器人自身的显式建模(Explicit Modeling)。如图2所示,运动生成主要通过正向/逆向运动学(FK/IK)、微分逆向运动学(Diff-IK)和基于模型的控制规划来实现。
一个典型的经典机器人系统遵循模块化流水线:感知模块处理传感器数据,状态估计模块推断机器人姿态,规划模块生成轨迹,最后由控制模块执行。然而,这种基于动力学的方法存在显著局限:
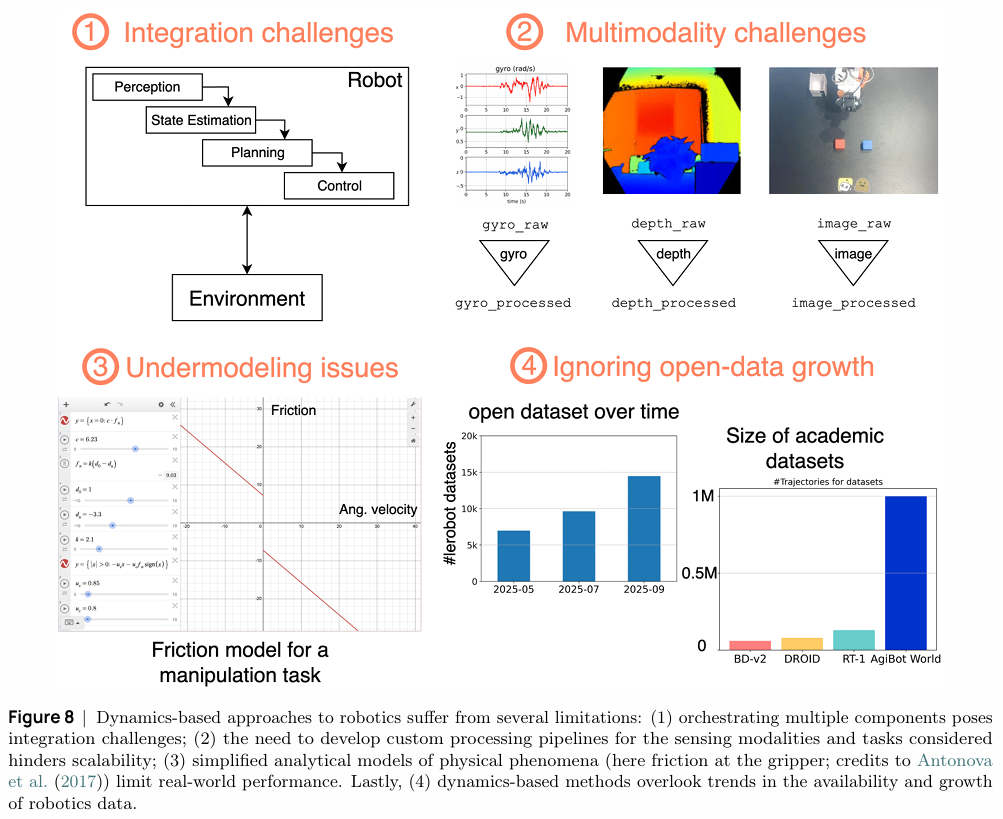
- 集成复杂性:多个独立模块的协同工作使得系统集成过程复杂且易于出错,误差会逐级累积。
- 可扩展性差:针对不同的任务和传感器模态,往往需要定制化的处理流水线,难以扩展到多任务和多模态场景。
- 模型简化:用于描述接触、摩擦等物理现象的解析模型往往是真实世界的过度简化,这限制了机器人在非结构化环境中的性能。
- 数据利用率低:这类方法本质上没有充分利用机器人交互数据的快速增长趋势。
这些局限性促使研究者转向基于学习的方法,旨在实现更紧密的感知-控制闭环、更强的任务与机器人形态泛化能力,并随着数据规模的增长而持续提升性能。
2. 机器人(强化)学习
强化学习(RL)通过试错机制让智能体在与环境的交互中学习最优策略,是实现机器人自主决策的有力工具。基于学习的机器人学具备以下优势:
- 通过训练一个统一的高级控制器,简化了“感知到动作”的流程。
- 能够直接处理高维、非结构化的传感器(如图像)和运动信息。
- 学习过程无需精确的动力学模型,而是依赖于交互数据。
- 模型性能与数据规模呈正相关,为利用大规模数据提供了可能。
然而,将强化学习直接应用于真实机器人面临两大核心挑战:安全与效率。训练初期的探索性动作可能导致硬件损坏;同时,在物理世界中收集大量试错数据的成本极高。
为解决这些问题,教程探讨了一系列先进方法:
- 模拟训练与域随机化(Domain Randomization):在模拟器中训练可以规避物理风险,并通过随机化模拟环境的参数(如摩擦系数、光照、物体质量等),提升策略从模拟到现实(Sim-to-Real)的迁移能力。

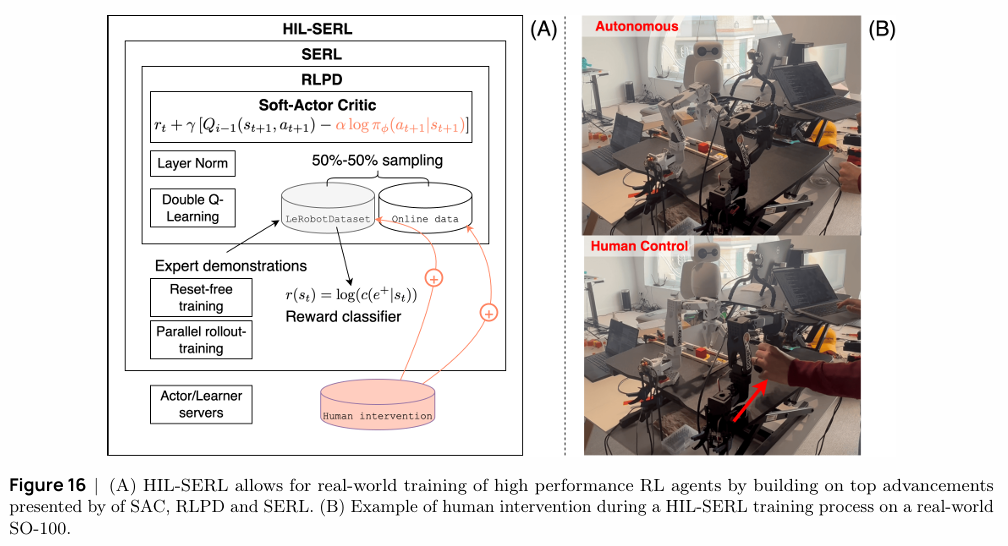
- 离线到在线(Offline-to-Online)RL:为了提高样本效率和安全性,可以利用预先收集的专家数据来引导在线学习过程。HIL-SERL (Human-in-the-Loop, Sample-Efficient Robot RL) 是其中的代表性方法,它结合了SAC、RLPD等算法的优点,并在训练中引入人类的实时干预与监督。通过这种方式,HIL-SERL能够让机器人在1-2小时内掌握复杂的真实世界操作任务,成功率接近100%。
3. 机器人(模仿)学习
相比于RL,模仿学习(Imitation Learning,或称行为克隆 BC)为机器人提供了一条更直接的学习路径:直接从专家演示中学习观察-动作的映射。其核心优势在于完全规避了复杂的奖励函数设计,并通过学习专家数据确保了训练过程的安全性。
然而,简单的行为克隆也面临关键挑战:
- 复合误差(Compounding Errors):由于策略学习的是一个单步预测模型,微小的预测偏差会在序贯决策中迅速累积,导致机器人偏离专家轨迹,进入未见过的状态,从而引发灾难性失败。
- 多模态行为(Multimodal Behaviors):对于同一任务目标,专家可能存在多种同样有效的操作方式(例如,从左侧或右侧抓取一个物体)。单点估计的回归模型(如L2损失)会尝试平均这些不同模式,最终产生一个无效的“中间”动作。
为应对这些挑战,教程重点介绍了一系列基于生成模型的先进模仿学习方法,它们通过学习专家行为的潜在分布来建模多模态数据。
-
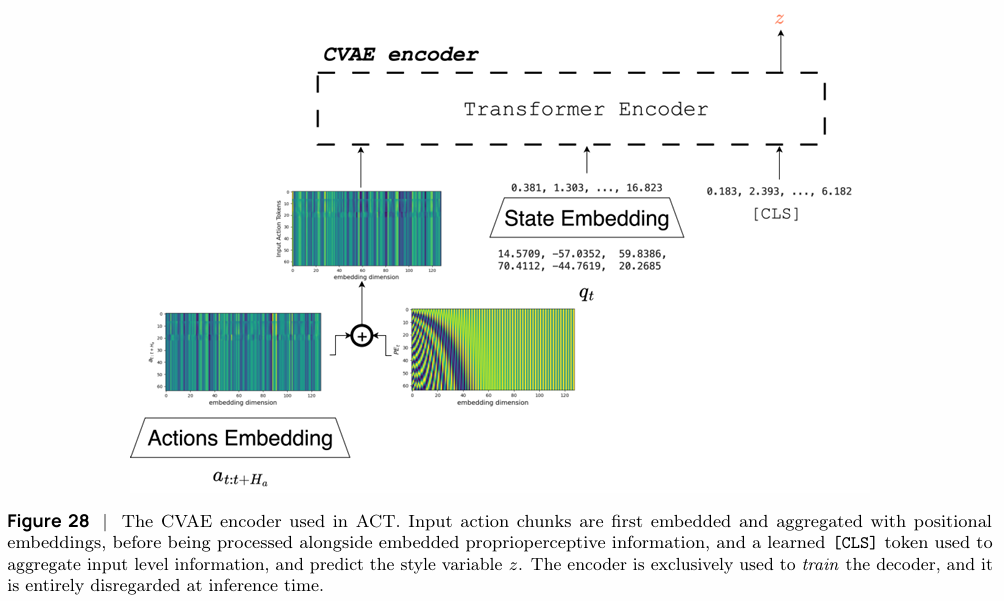
Action Chunking with Transformers (ACT):该方法通过引入动作分块(Action Chunking)和基于CVAE(Conditional Variational Auto-Encoder)的Transformer架构来学习策略。它一次性预测一个动作序列(chunk),并通过隐变量
z来捕获专家演示中的不同风格或模式,从而有效处理多模态问题。- CVAE目标函数 (ELBO)
ELBO=Ez∼qϕ(⋅∣o,a)[logpθ(a∣z,o)]−DKL[qϕ(z∣o,a)∣∣pω(z∣o)]\text{ELBO} = \mathbb{E}_{z \sim q_\phi(\cdot|o,a)}[\log p_\theta(a|z,o)] - D_{KL}[q_\phi(z|o,a) || p_\omega(z|o)] ELBO=Ez∼qϕ(⋅∣o,a)[logpθ(a∣z,o)]−DKL[qϕ(z∣o,a)∣∣pω(z∣o)]
- CVAE目标函数 (ELBO)
-
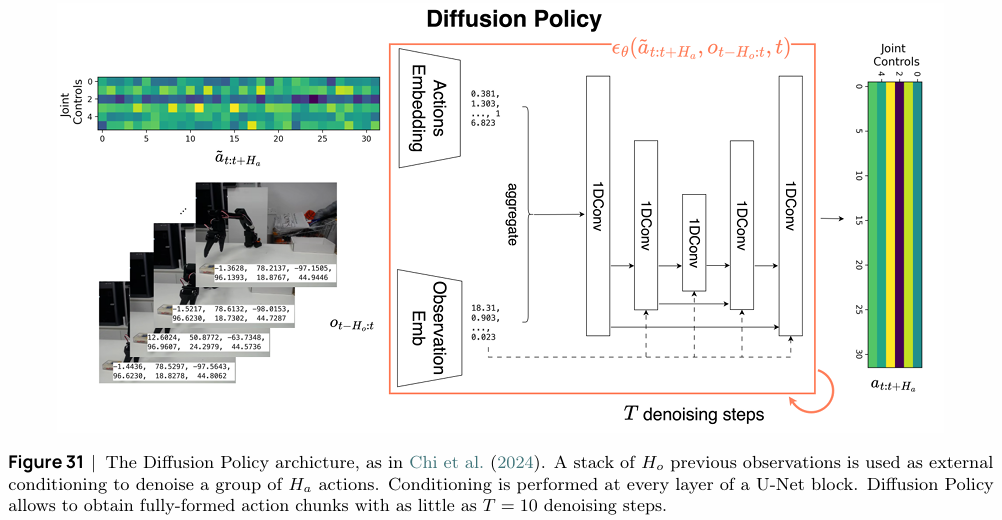
Diffusion Policy:此方法利用扩散模型(Diffusion Models)来生成动作序列。它将动作生成视为一个从随机噪声逐步去噪的过程,并以历史观测作为条件。扩散模型强大的生成能力使其在建模复杂和多模态的动作分布方面表现出色,仅需50-150个演示(约15-60分钟数据)即可训练出高性能策略。
- 扩散模型简化目标
L(θ)=Et,at:t+Ha,ϵ[∥ϵ−ϵθ(αˉtat:t+Ha+ϵ1−αˉt,t,ot−Ho:t)∥2]L(\theta) = \mathbb{E}_{t, a_{t:t+H_a}, \epsilon} \left[ \left\| \epsilon - \epsilon_\theta(\sqrt{\bar{\alpha}_t}a_{t:t+H_a} + \epsilon\sqrt{1-\bar{\alpha}_t}, t, o_{t-H_o:t}) \right\|^2 \right] L(θ)=Et,at:t+Ha,ϵ[ϵ−ϵθ(αˉtat:t+Ha+ϵ1−αˉt,t,ot−Ho:t)2]
- 扩散模型简化目标
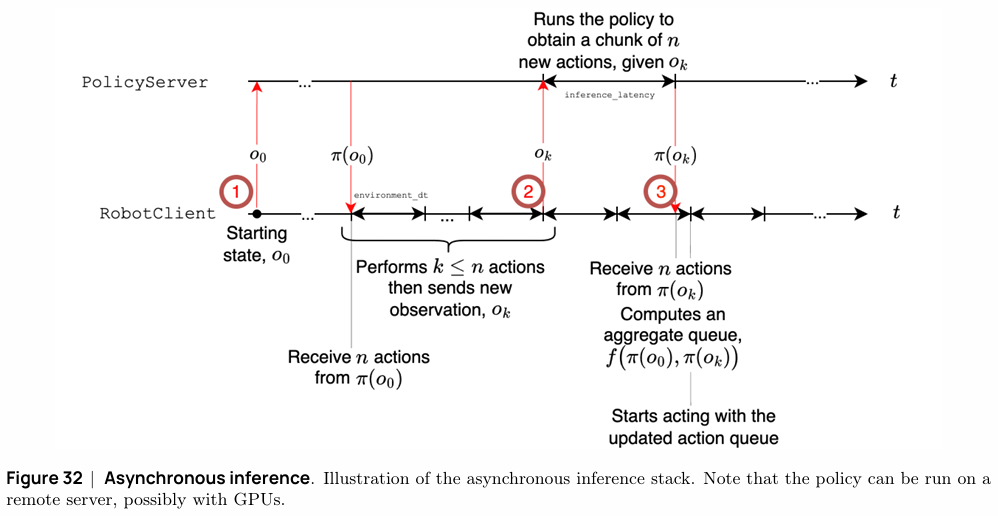
教程还探讨了如何通过 异步推理(Asynchronous Inference) 来优化模型部署,将耗时的策略推理过程(可在远程GPU服务器上运行)与实时的机器人控制解耦,有效提升了机器人在资源受限平台上的响应速度。
4. 通用机器人策略
机器人技术的终极目标之一是构建能够跨任务、跨设备、听从自然语言指令的通用机器人策略,即机器人领域的“基础模型”。大规模开放机器人数据集(如Open X-Embodiment)和强大的视觉-语言模型(VLM)为此提供了可能。
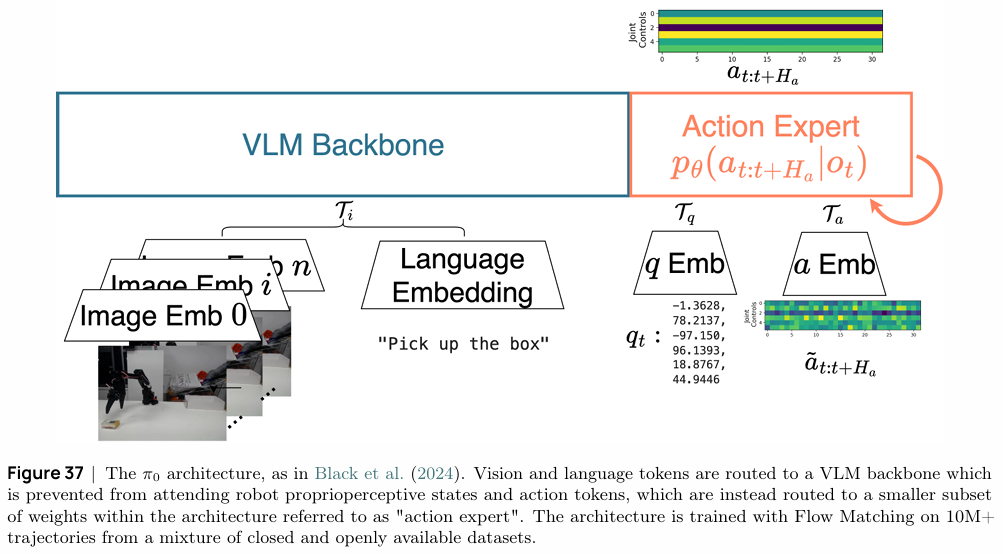
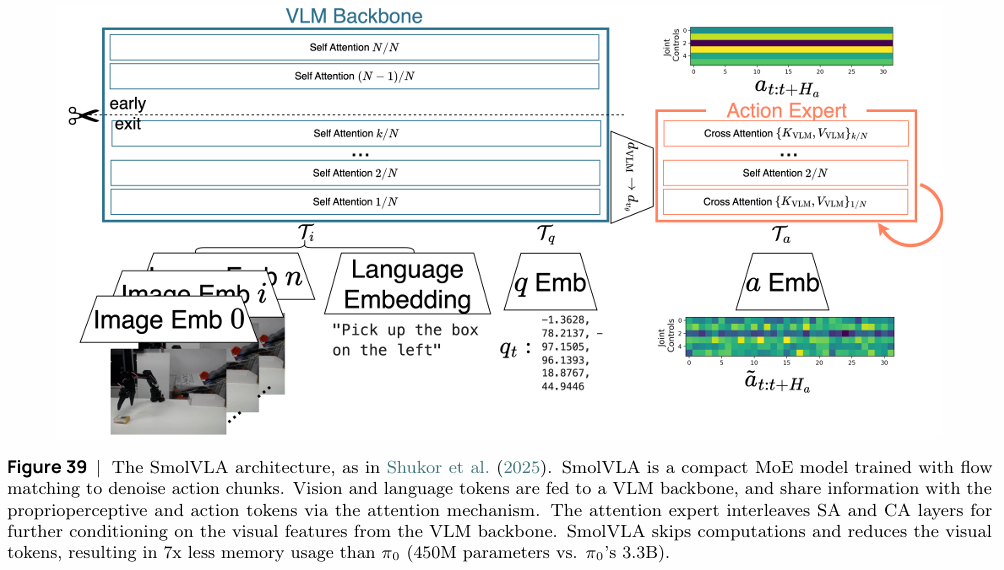
教程重点介绍了两种前沿的视觉-语言-动作模型 (VLA):π₀ 和 SmolVLA。它们均采用混合专家(Mixture of Experts, MoE)架构,将一个预训练的VLM作为强大的“感知主干”,负责理解视觉和语言指令,再结合一个专门的“动作专家”来生成精确的机器人控制指令。
- π₀ 模型:该模型采用大型VLM(Gemma 2.6B)作为骨干,并结合一个动作专家网络。它使用Flow Matching技术在包含超过1000万个轨迹的混合数据集(私有+公开)上进行训练,展现了强大的少样本乃至零样本泛化能力。其架构设计通过注意力掩码,阻止VLM直接关注机器人本体状态和动作,以保护预训练知识不被机器人特定的低维信号“污染”。
- SmolVLA 模型:该模型代表了另一个重要趋势:模型的小型化和完全开源。作为一个从数据、代码到模型权重完全开源的项目,SmolVLA在保证高性能的同时,参数量(4.5亿)仅为π₀(33亿)的约七分之一,内存消耗显著降低。它通过更紧凑的MoE设计、部分计算跳过和视觉Token压缩等技术实现了高效率,极大地降低了前沿机器人模型的应用门槛。
结论
这份教程清晰地描绘了从经典机器人学到现代数据驱动方法的演进路径。它不仅为初学者提供了坚实的理论基础,还通过 LeRobot 这个开源项目,将前沿算法与实践紧密结合。无论是希望理解机器人学基本原理的新手,还是寻求在真实硬件上部署SOTA模型的开发者,都能从中获益匪浅。
更多技术细节、代码示例和深入讨论,强烈建议您参阅教程原文。
点击阅读原文,获取更多相关信息