【论文精读】STREAM:视频生成模型的时空评估新指标
标题:STREAM: Spatio-TempoRal Evaluation and Analysis Metric for Video Generative Models
作者:Pum Jun Kim、Seojun Kim、Jaejun Yoo
单位:Ulsan National Institute of Science and Technology
发表:arXiv preprint arXiv:2403.09669v3 [cs.CV]
论文链接:https://arxiv.org/abs/2403.09669v3
代码链接:https://github.com/pro2nit/STREAM
关键词:视频生成模型、评估指标、时空分离评估、STREAM、Fréchet Video Distance(FVD)、Video Inception Score(VIS)、傅里叶变换(FFT)、空间质量、时序自然性
在图像生成领域,Inception Score(IS)、Fréchet Inception Distance(FID)等成熟指标为模型优化提供了清晰指引,推动了生成图像的真实感与多样性不断突破。然而,视频生成作为更高维度的任务,不仅要求单帧画面的质量,更依赖帧间时序的连贯性,现有评估指标却难以兼顾这两方面需求。
当前主流的视频评估指标如 Video Inception Score(VIS)和 Fréchet Video Distance(FVD),本质上是将图像指标的嵌入网络替换为视频专用网络(如 I3D),并未真正适配视频的 “时空双重属性”。其中,应用最广泛的 FVD 存在三大核心缺陷:过度侧重空间质量而忽视时序自然性、受限于嵌入网络输入尺寸只能评估 16 帧视频、评分不稳定且与人类主观感受偏差较大。
为解决这些痛点,来自韩国蔚山科学技术院(UNIST)的团队提出了STREAM(Spatio-TempoRal Evaluation and Analysis Metric),这是首个能独立评估视频空间与时间维度质量的指标。本文将从研究背景、核心设计、实验验证、相关工作等方面,全面解读这一创新性评估方案。
一、研究背景:视频生成评估的核心挑战
1.1 从图像到视频:评估维度的跃迁
图像生成的核心是 “单帧质量”,而视频生成需要同时满足两个条件:
- 空间维度:每帧画面需具备高真实感与多样性;
- 时间维度:帧间内容需保持连贯、流畅的时序逻辑(如物体运动轨迹连续、场景切换自然)。
传统思路是将图像指标(如 FID)直接应用于视频的每帧,再取平均值,但这种方法完全忽略了时序信息,无法区分 “连续视频” 与 “离散图像集合”。
1.2 现有视频指标的局限性
目前主流的视频评估指标(VIS、FVD)均基于图像指标改造,存在难以克服的缺陷,具体对比如下表所示:
| 指标 | 核心原理 | 关键缺陷 |
|---|---|---|
| VIS | 基于 I3D 网络的 softmax 输出,计算 KL 散度衡量生成视频的类别一致性 | 仅输出单一综合分数,无法区分空间 / 时序质量;对时序连贯性不敏感 |
| FVD | 基于 I3D 网络的特征嵌入,假设真实 / 生成视频特征服从高斯分布,计算 Wasserstein 距离 | 1. 过度侧重空间特征,时序自然性评估能力弱;2. 受 I3D 输入限制,仅支持 16 帧视频;3. 评分范围无界,不同实验间无法直接对比;4. 与人类主观评估偏差大 |
论文通过实验进一步验证了 FVD 的缺陷:例如在 “时序破坏实验” 中(如随机交换视频帧顺序),FVD 的敏感度远低于人类预期;而在 “空间噪声实验” 中(如给所有帧添加相同高斯噪声),FVD 评分波动剧烈,却未反映时序质量无变化的事实。
二、STREAM 核心设计:时空分离的评估框架
STREAM 的核心创新是将视频的空间质量与时间质量解耦评估,分别通过 STREAM-S(空间指标)和 STREAM-T(时序指标)实现,整体流程如图 1 所示。
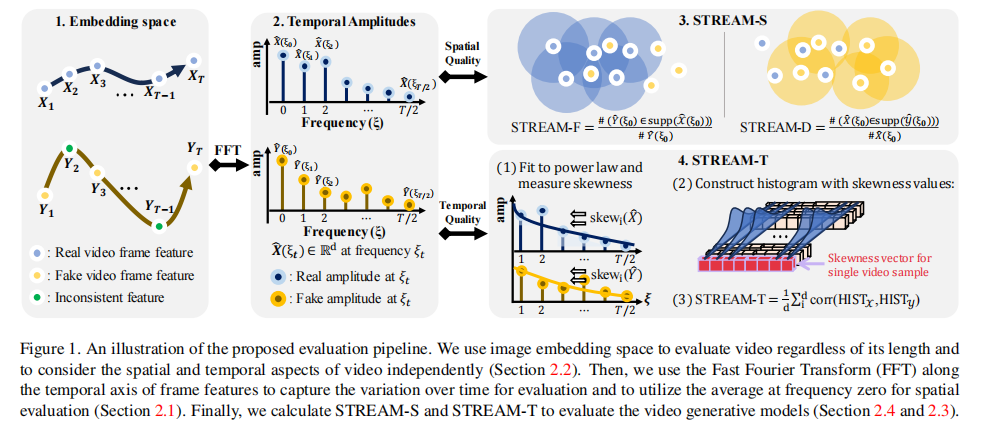
注:STREAM 先通过图像嵌入网络提取每帧特征,再通过 FFT 将特征转换到频域,分别用于空间(频率 0 处的均值振幅)和时序(全频率的功率谱偏度)评估。
2.1 基础准备:符号定义与嵌入网络选择
2.1.1 核心符号定义
为清晰描述算法逻辑,论文定义了以下关键符号:
- 真实视频数据集:
,其中单个视频
(
为帧数);
- 生成视频数据集:
,单个视频
;
- 嵌入特征:通过图像嵌入网络f提取每帧特征,得到
(
为特征维度),简化记为
;
- 频域振幅:对
(
为频率,
对应均值振幅)。
2.1.2 嵌入网络的选择逻辑
现有视频嵌入网络(如 I3D、VideoMAE)存在两大问题:
- 时序信息编码不完整,或与空间信息混合,无法单独分离;
- 输入帧数固定(如 I3D 仅支持 16 帧),无法评估长视频。
因此,STREAM 创新性地采用图像嵌入网络(论文中使用 SimCLR 的改进版),对每帧独立编码。这种选择的优势在于:
- 避免时空信息混合,为后续分离评估奠定基础;
- 不受帧数限制,可评估任意长度视频(从 16 帧到 128 帧甚至更长)。
2.2 STREAM-T:时序自然性评估
时序自然性的核心是 “帧间变化符合真实世界的运动规律”(如物体运动速度连续、无突然跳跃)。论文通过频域分析捕捉这种规律,具体步骤如下:
2.2.1 核心观察:自然信号的 1/f 波动特性
真实世界的时序信号(如物体运动、光线变化)在频域上呈现 “1/f 波动” 特性 —— 低频成分(慢变化)的功率谱密度高,高频成分(快变化)的功率谱密度低,其功率谱可近似为幂律分布:,其中,
是第k维特征在频率
处的振幅,C为归一化系数,
为控制斜率的参数。
2.2.2 幂律分布的偏度计算
为量化真实与生成视频的时序差异,论文引入 “偏度(Skewness)”—— 衡量概率分布的不对称性,公式如下:其中,
为期望,
为方差。偏度能有效反映时序信号的 “变化剧烈程度”:真实视频的偏度分布相对稳定,而时序不连贯的生成视频(如帧顺序错乱)会出现偏度异常。
2.2.3 STREAM-T 的最终计算
- 对真实视频
的嵌入特征做 FFT,得到
和
;
- 对每个特征维度
,拟合幂律分布并计算偏度
和
;
- 分别构建真实与生成视频的偏度直方图
和
;
- 计算两直方图的相关系数,取平均值作为 STREAM-T:
评分解读:STREAM-T 取值范围为[0,1],越接近 1 表示生成视频的时序自然性越接近真实视频。
2.3 STREAM-S:空间质量评估
空间质量包括 “真实感(Fidelity)” 和 “多样性(Diversity)”,论文基于改进的 Precision & Recall(P&R)指标,利用 FFT 中频率 0 处的均值振幅(对应每帧特征的时间平均,即空间特征的整体表征)进行评估,具体分为 STREAM-F(真实感)和 STREAM-D(多样性)。
2.3.1 核心改进:解决视频帧的支持集估计问题
传统 P&R 用于图像时,通过 “k-NN 球体” 估计数据支持集(即真实 / 生成图像的特征分布范围):
- 精确率(Precision):生成图像特征落在真实支持集内的比例(衡量真实感);
- 召回率(Recall):真实图像特征落在生成支持集内的比例(衡量多样性)。
但视频由多帧组成,直接应用 P&R 会导致 “支持集碎片化”(单帧特征分散,球体无法覆盖完整视频的空间特征)。因此,STREAM-S 使用均值振幅 作为单个视频的空间特征表征(即一个视频对应一个特征点),避免碎片化问题。
2.3.2 STREAM-F 与 STREAM-D 的计算
-
STREAM-F(真实感):生成视频的均值振幅落在真实视频支持集内的比例,衡量生成视频的空间真实度:
,其中,
表示支持集,
为指示函数(满足条件取 1,否则取 0)。
-
STREAM-D(多样性):真实视频的均值振幅落在生成视频支持集内的比例,衡量生成视频的空间多样性:
评分解读:两者取值均为[0,1],越接近 1 表示真实感 / 多样性越好。
2.4 STREAM 的四大优势
相较于现有指标,STREAM 具备以下关键特性:
- 时空分离:首次实现空间与时序质量的独立评估,可精准定位模型缺陷(如 “时序连贯但单帧模糊” 或 “单帧清晰但时序错乱”);
- 有界性:所有子指标均取值于[0,1],不同实验、不同模型间可直接对比;
- 通用性:支持任意长度视频(不受 16 帧限制),适配所有视频生成模型;
- 可解释性:通过子指标得分可明确模型的改进方向(如 STREAM-T 低则优化时序建模,STREAM-D 低则提升多样性)。
三、实验验证:STREAM 的有效性与可靠性
论文通过合成数据实验(控制变量,验证指标逻辑)和真实数据实验(评估实际模型,验证实用性),全面验证 STREAM 的性能。所有实验中,真实与生成视频各 2048 个,结果为 5 次重复实验的平均值,阴影区域表示标准差。
3.1 合成数据实验:验证指标逻辑合理性
合成数据实验使用 CATER 数据集(场景简单,可精确控制时空扰动),通过三类扰动验证 STREAM 的响应是否符合预期:
- 空间噪声扰动:给所有帧添加相同噪声(如高斯噪声、椒盐噪声),时序无变化;
- 时序破坏扰动:打乱帧顺序(局部交换:交换同一视频内两帧;全局交换:用其他视频的帧替换),空间质量无变化;
- 时空混合扰动:随机平移每帧(导致空间变形)+ 静态帧替换(导致时序断裂)。
3.1.1 空间噪声扰动实验
实验预期:
- STREAM-T(时序):不受影响,得分稳定;
- STREAM-S(空间):随噪声强度增加而下降;
- FVD:因过度侧重空间,得分波动剧烈且无界。
实验结果如图 2 所示:
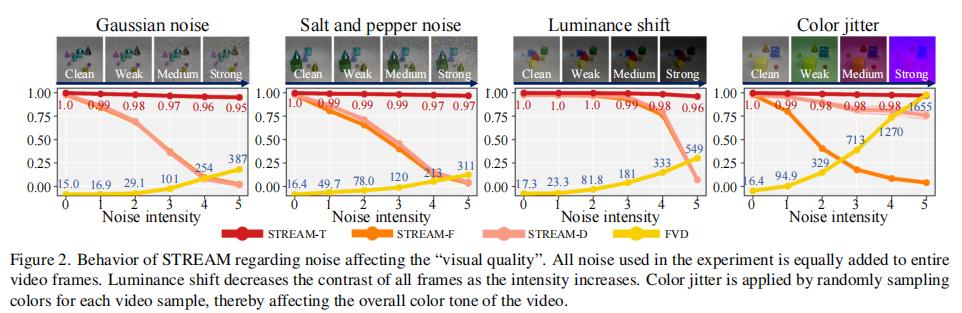
关键结论:
- STREAM-T 在所有噪声类型下均稳定在 0.95 以上,符合 “时序无变化” 的预期;
- STREAM-F 和 STREAM-D 随噪声强度增加逐渐下降至 0,准确反映空间质量退化;
- FVD 得分无界(如椒盐噪声下从 16.9 飙升至 120),且不同噪声类型下趋势不一致,无法统一衡量空间质量。
3.1.2 时序破坏扰动实验
实验预期:
- STREAM-T(时序):随交换次数增加而下降,且全局交换(破坏更严重)下降更快;
- STREAM-S(空间):局部交换无影响(得分稳定),全局交换因引入其他视频帧,多样性可能下降;
- FVD:对时序破坏不敏感,且全局交换时得分异常偏高。
实验结果如图 3 所示:
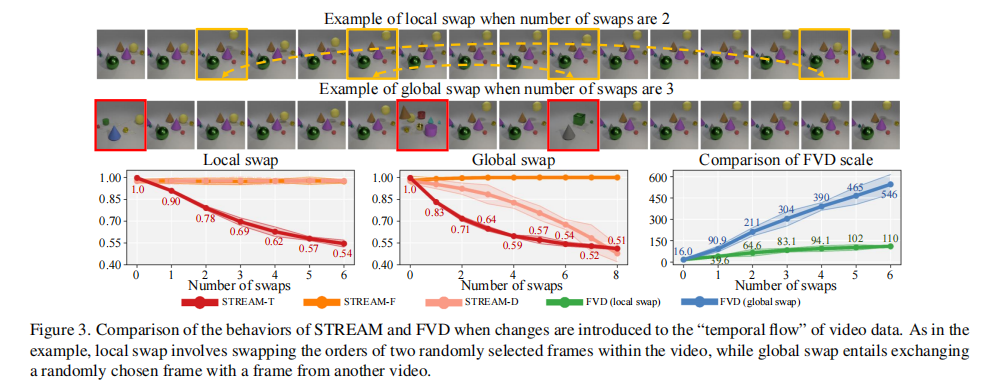
关键结论:
- STREAM-T 随交换次数增加显著下降,且全局交换下降幅度大于局部交换(如交换 4 次时,局部交换得分 0.69,全局交换得分 0.54),准确反映时序破坏程度;
- STREAM-F 在局部交换时稳定(0.85 左右),全局交换时略有下降,符合预期;
- FVD 对局部交换不敏感(得分稳定在 102 左右),全局交换时得分飙升至 450,与 “时序破坏程度” 无明确关联,且无界。
3.1.3 时空混合扰动实验
实验预期:
- STREAM-T:对静态帧替换更敏感(时序断裂更严重),得分下降更快;
- STREAM-S:仅对随机平移敏感(空间变形),随平移强度增加而下降;
- FVD:过度侧重空间,对随机平移的敏感度是静态帧替换的 3 倍以上。
实验结果如图 4 所示:
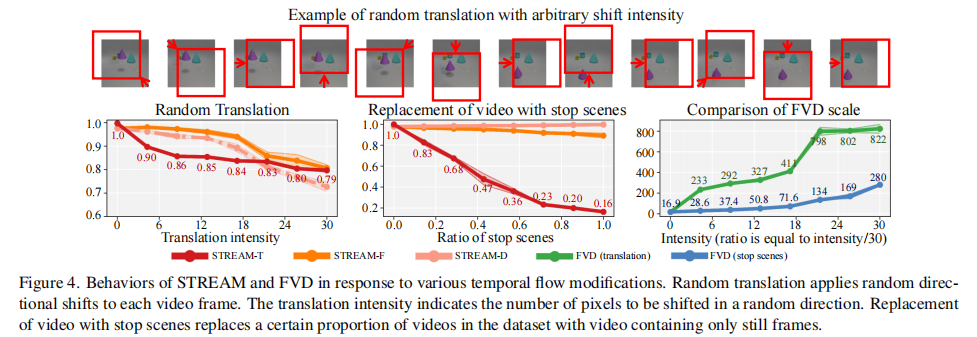
关键结论:
- STREAM-T 在静态帧替换比例为 1.0(全静态)时得分降至 0.2,远低于随机平移(强度 30 时得分 0.8),符合 “时序断裂更严重” 的预期;
- STREAM-F 仅随平移强度增加而下降,静态帧替换时得分稳定,准确区分空间扰动;
- FVD 对随机平移的得分(802)是静态帧替换(134)的 6 倍,严重高估空间因素,低估时序因素。
3.2 真实数据实验:验证指标实用性
真实数据实验使用 UCF-101(动作识别数据集)和 Kinetics-600(大规模视频数据集),验证 STREAM 在实际模型评估中的表现,包括三个核心任务:
- 评估真实视频的时空扰动,验证指标在复杂场景下的稳定性;
- 对比主流视频生成模型,验证指标的区分能力;
- 评估长视频(128 帧)生成,验证指标对长视频的适配性。
3.2.1 真实视频的时空扰动实验
实验设置与合成数据一致,结果如图 5(空间噪声)和图 6(时序破坏)所示:
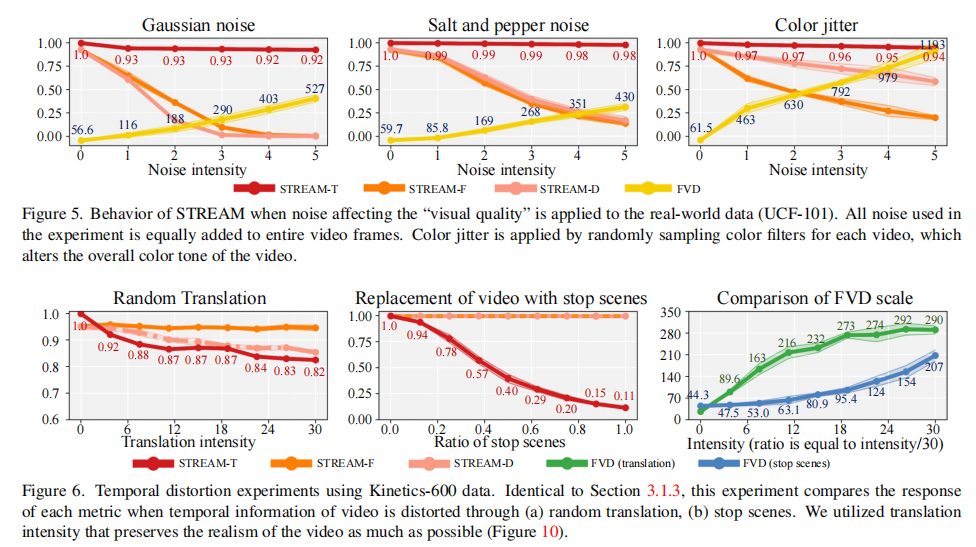
关键结论:STREAM 在真实复杂数据上的响应与合成数据完全一致,证明其稳定性 ——STREAM-T 仅对时序扰动敏感,STREAM-S 仅对空间扰动敏感,而 FVD 仍存在 “时空混淆” 和 “无界” 问题。
3.2.2 主流视频生成模型对比
实验选取 6 种主流无条件视频生成模型(MoCoGAN-HD、DIGAN、TATS-base、VideoGPT、MeBT、PVDM),均在 UCF-101 上训练,生成 16 帧 128×128 视频。评估结果如表 1 所示:
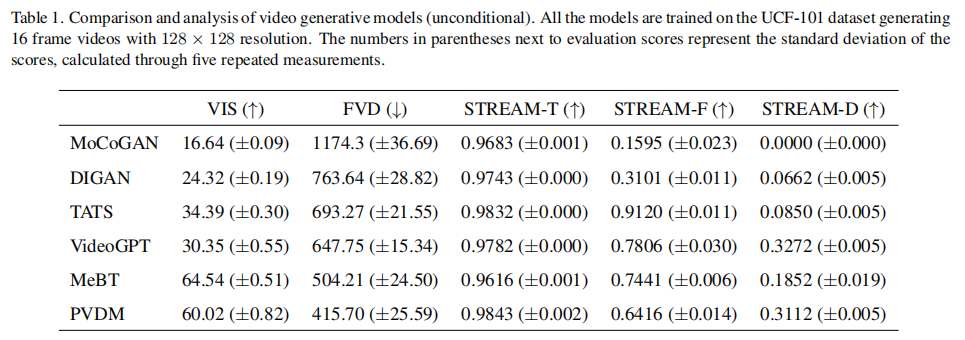
关键发现:
- 单一指标易误导评估:例如 MeBT 的 VIS(64.54)和 FVD(504.21)表现最优,但 STREAM 揭示其 STREAM-F(0.7441)低于 TATS-base(0.9120),即单帧真实感更差;
- 模型缺陷精准定位:
- MoCoGAN-HD:STREAM-D=0,完全缺乏多样性;
- TATS-base:STREAM-F 最高(0.9120),单帧真实感最优,但 STREAM-D 低(0.0850),多样性不足;
- VideoGPT:STREAM-D 最高(0.3272),多样性最优,但 STREAM-F 低于 TATS-base,单帧真实感待提升;
- 与人类主观评估一致:论文通过 81 名评估者对视频真实感和时序连贯性打分,STREAM 与人类评分的 Spearman 相关系数为 0.9(真实感)和 0.6(时序),远高于 FVD 的 0.7 和 0.5。
3.2.3 长视频生成评估(128 帧)
现有指标(FVD、VIS)仅支持 16 帧,论文通过 “滑动窗口” 改造为 sFVD 和 sVIS(每 16 帧计算一次,取平均),与 STREAM 对比。实验选取 4 种模型(MoCoGAN-HD、DIGAN、TATS-base、MeBT),生成 128 帧 128×128 视频,结果如表 2 所示:
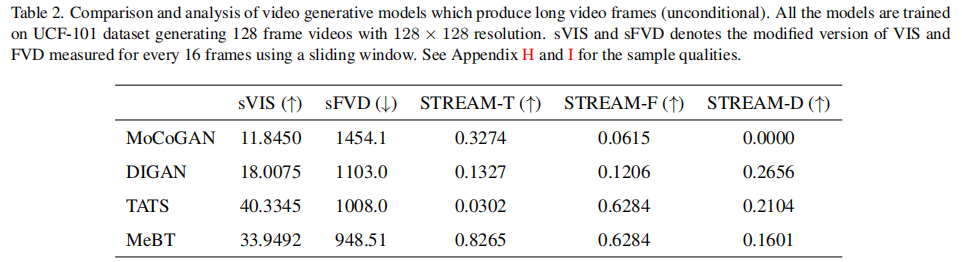
关键发现:
- 长视频时序质量普遍下降:所有模型的 STREAM-T 均远低于 16 帧时的得分(如 TATS-base 从 0.9832 降至 0.0302),揭示当前模型长视频时序建模能力薄弱;
- 空间质量随帧数增加退化:STREAM-F 普遍低于 16 帧时的得分(如 TATS-base 从 0.9120 降至 0.6284),说明模型在长视频生成中难以维持单帧质量;
- sFVD/sVIS 存在局限性:sFVD 得分无界(如 MoCoGAN-HD 达 1454.1),且无法反映长视频的整体时序连贯性(仅能评估局部 16 帧),而 STREAM 可直接评估完整 128 帧的时序质量。
四、相关工作:视频生成与评估的研究现状
4.1 视频生成模型
现有视频生成模型主要通过以下思路提升时空质量:
- 架构创新:如 MoCoGAN-HD 用 2D CNN+RNN 分离内容与运动;TATS-base 用 Transformer 建模长时序依赖;
- 训练策略:如 Progressive GAN 从低分辨率逐步提升至高分辨率;Two-Stream VAN 用两个网络分别学习内容与运动;
- 扩散模型:如 VideoGPT 用 VQ-VAE+Transformer 生成视频;MCVD 用扩散模型提升时序连贯性。
但这些模型的优化均依赖评估指标的指引,现有指标的缺陷导致模型改进方向不明确。
4.2 视频评估指标
除 VIS 和 FVD 外,部分研究尝试改进评估方案,但仍未突破核心局限:
- 基于光流的指标:通过计算帧间光流衡量时序连贯性,但对光流估计误差敏感,且无法评估空间质量;
- 基于人类评分的指标:主观准确但成本高、无法自动化;
- 改进 FID 的指标:如使用更高维度的视频嵌入网络,但仍未解决时空分离和长视频评估问题。
STREAM 的创新在于首次实现 “时空分离评估”,填补了该领域的空白。
五、结论与展望
5.1 研究结论
- 现有视频评估指标(VIS、FVD)因 “时空混淆”“帧数限制”“无界性” 等问题,无法满足视频生成模型的优化需求;
- STREAM 通过 “频域时序分析” 和 “均值振幅空间分析”,实现空间与时序质量的独立评估,具备有界性、通用性和可解释性;
- 实验验证表明,STREAM 与人类主观评估高度一致,可精准定位模型缺陷,且支持任意长度视频评估。
5.2 未来展望
- 扩展评估维度:当前 STREAM-S 仅评估空间真实感与多样性,未来可加入 “细节丰富度”“语义一致性” 等维度;
- 优化嵌入网络:当前使用图像嵌入网络,未来可探索更高效的时空分离嵌入网络,进一步提升评估精度;
- 适配更多任务:当前聚焦无条件视频生成,未来可扩展至条件生成(如文本驱动视频生成)、视频编辑等任务。
STREAM 为视频生成模型的研发提供了强有力的评估工具(代码已开源),有望推动长视频、高真实感视频生成技术的快速发展。