Python机器学习---7.实战案例:幸福指数分析
项目实战主题:
常⽤缺失值处理⽅法;
数据标准化的含义及使⽤;
数据预处理在实际项⽬中的应⽤;
使⽤KNN、随机森林等算法进⾏幸福感指数项⽬实战。
项目实战⽬标:
掌握异常数据的查找⽅法;
掌握数据归⼀化、标准化的应⽤⽅法;
通过幸福感指数数据了解实际场景中的缺失值填补⽅法;
幸福感指数分类项⽬实战。
知识要点:
什么是数据预处理:通常获取数据通常都是不完整的,缺失值、零值、异常值等情况的出现导致数据的质量⼤打折扣,⽽数据预处理技术就是为了让数据具有更⾼的可⽤性⽽产⽣的。
重复数据的处理:
data.duplicated(),用来查看数据是否有重复值
data.drop_duplicates(),用来删除重复值
数据标准化与最⼤最⼩化处理:
标准化处理:如果通过身⾼体重去分析⼀个正常身材的⼈的胖瘦,假设身⾼的衡量标准为“⽶”,⽽体重的衡量标准为“⽄”,由于⼆者的数量级的差异,会导致判断胖瘦的标准发⽣改变,导致体重⼀项具有了更⼤的影响⼒ ,但是根据经验可以知道,⼀个正常身材⼈的胖瘦是由身⾼和体重共同决定的,对于这样的数据⽽⾔,给计算机使⽤的数据就要进⾏数据标准化。
数据标准化公式:公式中u代表均值,σ代表标准差。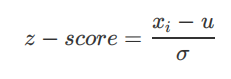
最大最小化处理:数据归⼀化(Min-Max标准化)
数据归⼀化公式:公式中min(x)表示数据中的最⼩值,max(x)表示数据中的最⼤值。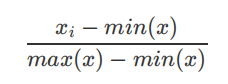
哑变量和独热编码:
哑变量:通常将不能定量处理的变量量化,构造只取“0”或“1”的⼈⼯变量,通常称哑变 量。
例:现在有性别:{男,⼥,其他}。性别特征有三个不同的分类值,需要三个bit的值来表示这些类别。哑变量表示为:男:{01},⼥:{10},其他:{00}。独热编码:
上面的例子中独热编码表示为: 男:{001},⼥:{010},其他:{100},其实总体的思想都是差不多的。
幸福感指数项⽬实战:
项⽬流程:
数据准备
数据概览
- 数据预处理
# 读取数据 data = pd.read_csv(r'C:\Users\ZJJY\Desktop\Python机器学习课件\7.幸福指数分析\happiness_train_complete.csv', encoding='gbk') # print(data.head())# 数据清洗 data['happiness'] = data['happiness'].replace(-8, 3)# 处理空值,因为数据字段太多使用data.info()无法查看完整的内容 # print(data.info())# 使用isnull()和切片来查看前三十调记录,看是否有空值 # print(data.isnull().sum()[:30])# 进一步的将有空值的数据更好的展示,以便处理 miss_series = data.isnull().sum() miss_columns = miss_series[miss_series != 0].sort_values(ascending=False) # print(miss_columns)# 删除空值较多的数据字段 del_feature = list(miss_columns[miss_columns > 5000].index) data.drop(del_feature, axis=1, inplace=True) # print(data.shape)# 填充空值较少的数据字段 data['s_hukou'] = data['s_hukou'].fillna(0) data['s_edu'] = data['s_edu'].fillna(0) data['s_political'] = data['s_political'].fillna(0) data['s_birth'] = data['s_birth'].fillna(0) data['s_income'] = data['s_income'].fillna(0) data['s_work_exper'] = data['s_work_exper'].fillna(0) data['edu_status'] = data['edu_status'].fillna(0) del data['edu_yr'] data['social_neighbor'] = data['social_neighbor'].fillna(7) data['social_friend'] = data['social_friend'].fillna(7) data['minor_child'] = data['minor_child'].fillna(0) data['hukou_loc'] = data['hukou_loc'].fillna(4) data['marital_now'] = data['marital_now'].fillna(2023) data['marital_1st'] = data['marital_1st'].fillna(9997) data['family_income'] = data['family_income'].fillna(data['family_income'].median())# 类型转换,转换时间类型,并且求得出年龄 data['age'] = pd.to_datetime(data['survey_time']).dt.year - data['birth']# 删掉无关紧要的数据 data.drop(['s_birth', 'f_birth', 'm_birth'], axis=1, inplace=True)# 对数值型特征进行标准化处理 numeric_cols = ['income', 'height_cm', 'weight_jin', 's_income', 'family_income', 'family_m', 'house', 'car', 'son', 'daughter', 'minor_child', 'inc_exp', 'public_service_1', 'public_service_2', 'public_service_3', 'public_service_4', 'public_service_5', 'public_service_6', 'public_service_7', 'public_service_8', 'public_service_9', 'floor_area'] data[numeric_cols] = (StandardScaler().fit_transform(data.loc[:, numeric_cols])) 选择模型
建⽴模型
模型评估
- 模型优化
K-最近邻算法(KNN):# KNN建模 # 划分特征列和目标列 X = data.drop(['happiness', 'id'], axis=1) y = data['happiness'] # print(y.value_counts()) #在分类任务中存在严重的类别不平衡时会影响预测,用SMOTE算法实现训练数据集的平衡 # 重采样 s_y = SMOTE(random_state=0) X, y = s_y.fit_resample(X, y) # print(y.value_counts()) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.80, random_state=0) # 实例 Knn = KNeighborsClassifier(n_neighbors=4) # 拟合 Knn.fit(X_train, y_train) # 预测 Y = Knn.predict(X_test) # print(Y) # 评估 # print(accuracy_score(Y, y_test))# # 调优,肘部法则,找到模型最合适的最大深度 # train_score = [] # test_score = [] # for depth in range(1, 13): # tree = DecisionTreeClassifier(random_state=0, max_depth=depth) # tree.fit(X_train, y_train) # train_score.append(tree.score(X_train, y_train)) # test_score.append(tree.score(X_test, y_test)) # plt.figure(figsize=(10, 5)) # plt.plot(train_score, marker='o', c='red', label='训练集') # plt.plot(test_score, marker='o', c='green', label='测试集') # plt.legend() # plt.show()随机森林模型:
# 随机森林模型建模 # 实例 forest_clf = RandomForestClassifier(random_state=0) # 拟合 forest_clf.fit(X_train, y_train) # 预测 Y = forest_clf.predict(X_test) print(Y) # 评估 print(accuracy_score(Y, y_test))