SQL 性能优化:出现 sql 比较慢怎么办?
文章目录
- 一、优化器成本分析
- 1.1 成本分析步骤
- 1.2 SQL优化
- 1.3 常用数据类型
- 二、EXPLAIN 执行计划
- 2.1 执行计划字段说明
- 关于 type(访问类型)
- Extra 常见信息解析
- select_type(查询类型)
- 2.2 优化器追踪
- 三、慢日志查询
- 3.1 配置与开启
- 3.2 分析慢日志(mysqldumpslow)
- 3.3 SHOW PROFILE(分析 SQL 耗时)
- 3.4 SHOW PROCESSLIST(查看线上 SQL)
- 3.5 统计信息维护
- 四、出现 sql 比较慢怎么办?🌟
一、优化器成本分析
优化器(Optimizer) 的核心任务是为 SQL 语句选择最优的执行路径。
MySQL 优化器主要针对 IO 和 CPU 计算语句的成本;可能不会按照分析的原理来执行语句
- I/O 成本:数据页的读取次数;
- CPU 成本:数据行过滤、排序、比较等操作的开销。
1.1 成本分析步骤
- 识别可用索引:首先判断当前 SQL 语句中涉及哪些列,并列出所有可能使用的索引;
- 计算全表扫描代价:估算读取整张表所需的 I/O 与 CPU 成本;
- 计算各索引执行代价:分析每个可用索引下的扫描行数、过滤比例等;
- 选择最优方案:综合对比后,选择成本最低的访问路径。
1.2 SQL优化
SQL优化:MySQL :: MySQL 5.7 Reference Manual :: 8 Optimization
在 MySQL 优化中,数据类型的选择非常关键。合适的数据类型不仅能减少存储空间,还能降低内存和 I/O 消耗,从而提升查询性能。
一个通用原则是:
在满足业务需求的前提下,数据类型越小越好、越简单越好。
例如:
如果字段值只在 0~1000 之间,可以选择 SMALLINT 而不是 INT;
如果只需要存储“是/否”,可以使用 TINYINT(1) 而不是 CHAR(1)。
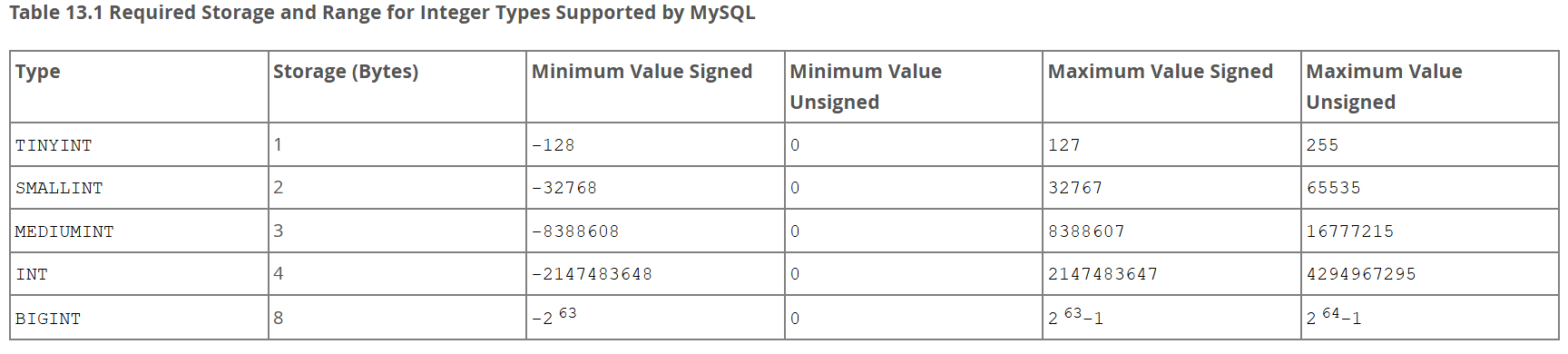
1.3 常用数据类型
| 类型类别 | 数据类型 | 说明 | 存储大小 | 使用建议 |
|---|---|---|---|---|
| 数值类型 | TINYINT | 小整数,范围 -128~127 或 0~255(无符号) | 1 字节 | 状态码、布尔标志(如性别、是否启用) |
SMALLINT | 较小整数,范围 -32768~32767 | 2 字节 | 年龄、分数、数量较小的计数 | |
INT / INTEGER | 常用整数,范围约 -21亿~21亿 | 4 字节 | 一般计数、主键 ID | |
BIGINT | 大整数,范围约 ±9×10¹⁸ | 8 字节 | 大范围计数、雪花 ID、金额分单位存储 | |
DECIMAL(M,D) | 定点数,精确小数,如货币 | M+2 字节 | 金额、精度要求高的计算 | |
FLOAT | 单精度浮点数(约 7 位有效数字) | 4 字节 | 科学计算中非精确值 | |
DOUBLE | 双精度浮点数(约 15 位有效数字) | 8 字节 | 浮点精度要求更高时使用 | |
| 字符类型 | CHAR(n) | 定长字符串(不足补空格) | n 字节 | 长度固定的数据,如性别、身份证号 |
VARCHAR(n) | 变长字符串 | 实际长度 + 1~2 字节 | 一般文本,如用户名、标题 | |
TEXT | 大文本(最大 65,535 字节) | 实际长度 + 2 字节 | 文章、描述类字段 | |
MEDIUMTEXT | 中等文本(最大 16 MB) | 实际长度 + 3 字节 | 博客正文、大段说明 | |
LONGTEXT | 超大文本(最大 4 GB) | 实际长度 + 4 字节 | 日志、文档存储 | |
| 日期时间类型 | DATE | 日期(YYYY-MM-DD) | 3 字节 | 出生日期、注册日期 |
DATETIME | 日期+时间(YYYY-MM-DD HH:MM:SS) | 8 字节 | 一般时间记录 | |
TIMESTAMP | 自动记录时间(随时区变化) | 4 字节 | 创建或更新时间(推荐) | |
| 布尔类型 | BOOLEAN / BOOL | 逻辑值,本质为 TINYINT(1) | 1 字节 | 真假判断字段(如 is_active) |
| 二进制类型 | BLOB | 二进制数据(最大 65 KB) | 实际长度 + 2 字节 | 小型文件、图片 |
MEDIUMBLOB | 中等二进制(最大 16 MB) | 实际长度 + 3 字节 | 大文件、音视频片段 | |
LONGBLOB | 超大二进制(最大 4 GB) | 实际长度 + 4 字节 | 压缩包、大文件存储 |
二、EXPLAIN 执行计划
EXPLAIN 是 MySQL 提供的执行计划分析工具,用于查看 SQL 的实际执行路径。
它能告诉我们优化器选择了哪个索引、扫描了多少行、使用了哪些算法,从而指导后续优化。
语法:EXPLAIN SELECT ...;
2.1 执行计划字段说明
| 字段名 | 说明 |
|---|---|
| id | 查询序列号,决定执行顺序。id 越大,优先级越高。相同 id 从上到下执行。 |
| select_type | 查询类型(如 SIMPLE、PRIMARY、UNION、SUBQUERY 等)。 |
| table | 当前访问的表或临时结果集。可能是物理表、派生表(derivedN)、UNION 结果等。 |
| type | 数据访问类型(访问效率指标,见下文)。 |
| possible_keys | 查询中可能使用的索引(候选集)。 |
| key | 实际使用的索引(如果为 NULL,则未使用索引)。 |
| key_len | 实际使用索引的字节长度(越短越好,代表索引利用率高)。 |
| ref | 索引与常量或其他字段的比较关系。 |
| rows | MySQL 估算的扫描行数(越小越好)。 |
| filtered | 预估过滤比例(百分比,越高越好)。 |
| Extra | 额外执行信息,如 Using index、Using filesort、Using temporary 等。 |
关于 type(访问类型)
访问类型表示 MySQL 从表中取数据的方式,性能由高到低如下:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
| 类型 | 说明 |
|---|---|
| ALL | 全表扫描;若数据量大,需优化。 |
| index | 全索引扫描(效率优于 ALL)。典型场景:① 查询覆盖索引(所需数据可直接从索引获取);② 用索引排序(避免数据重排)。 |
| range | 利用索引做范围查询(避免全索引扫描)。适用操作符:=、<>、>、>=、<、<=、IS NULL、BETWEEN、LIKE、IN()。 |
| index_subquery | 利用索引关联子查询(无需全表扫描)。 |
| unique_subquery | 类似 index_subquery,但基于唯一索引。 |
| index_merge | 查询需多个索引组合使用。 |
| ref_or_null | 字段需“关联条件 + NULL 值匹配”时,优化器选择的访问方式。 |
| ref | 使用非唯一性索引查找数据。 |
| eq_ref | 使用唯一性索引(如主键、唯一索引)查找数据。 |
| const | 表至多有1条匹配行(查询效率极高)。 |
| system | 表只有1行记录(如系统表),是 const 的特例。 |
Extra 常见信息解析
Using index:使用了覆盖索引(无需回表,性能好)。- 同时有
using where,表示索引用于“键值查找”; - 无
using where,表示索引仅用于“数据读取”(非条件查找)。
- 同时有
Using where:使用WHERE条件过滤数据。Using filesort:使用文件排序,需要额外排序(未命中索引排序,性能较差)。Using temporary:使用临时表保存中间结果(如复杂GROUP BY)。Using index condition:启用了索引下推(ICP) 优化,减少回表次数。Using join buffer:使用连接缓存优化多表JOIN。impossible where:WHERE条件恒为 false,返回空结果。
select_type(查询类型)
主要用来分辨查询的类型,是普通查询还是联合查询还是子查询
| 类型 | 含义 |
|---|---|
| SIMPLE | 简单查询(没有联合查询和子查询) |
| PRIMARY | 最外层 SELECT |
| UNION | 若第二个 SELECT 出现在 UNION 之后,则被标记为 UNION |
| DEPENDENT UNION | UNION 或 UNION ALL 联合而成的结果会受外部表影响 |
| UNION RESULT | 从 UNION 表获取结果的 SELECT |
| SUBQUERY | 在 SELECT 或者 WHERE 列表中包含子查询 |
| DEPENDENT SUBQUERY | 子查询要受到外部表查询的影响 |
| DERIVED | FROM 子句中出现的子查询,也叫做派生表 |
| UNCACHEABLE SUBQUERY | 表示使用子查询的结果不能被缓存 |
2.2 优化器追踪
优化器根据解析树可能会生成多个执行计划,然后选择最优的的执行计划
通过 optimizer_trace,我们可以查看 MySQL 的决策过程,了解它为何选择某种执行路径。
SHOW VARIABLES LIKE 'optimizer_trace';
-- 启用优化器的追踪
SET optimizer_trace='enabled=on';
-- 执行一条查询语句
SELECT * FROM user WHERE id<100; -- 执行查询
SELECT * FROM information_schema.optimizer_trace; -- 查看结果
-- 用完关闭
SET optimizer_trace="enabled=off";
SHOW VARIABLES LIKE 'optimizer_trace';
优化器追踪是定位“为什么不走索引”的关键工具,可以直接看到优化器放弃某索引的原因,如“estimated cost too high”。
三、慢日志查询
在生产环境中,SQL 慢的原因通常有两类:
- 执行计划不理想(索引未命中、数据倾斜等);
- SQL 逻辑不合理(条件复杂、数据量过大等)。
MySQL 提供了完整的慢查询分析手段来辅助定位。
3.1 配置与开启
-- 查看配置
SHOW GLOBAL VARIABLES LIKE 'slow_query%';
SHOW GLOBAL VARIABLES LIKE 'long_query%';-- 临时开启
SET GLOBAL slow_query_log = ON; -- on 开启 off 关闭
SET GLOBAL long_query_time = 4; -- 单位秒;默认10s;此时设置为4s
或者修改配置(my.cnf 或 my.ini)
-- 永久开启(配置文件)
[mysqld]
slow_query_log = ON
long_query_time = 4
slow_query_log_file = D:/mysql/mysql57-slow.log
3.2 分析慢日志(mysqldumpslow)
用于统计和筛选慢查询日志中的典型语句:
# 查询最近10条包含“select”的慢SQL,按时间排序
mysqldumpslow -s t -t 10 -g 'select' /data/mysql/slow.log
3.3 SHOW PROFILE(分析 SQL 耗时)
SHOW PROFILE 用于查看 SQL 执行的时间细分(解析、优化、执行阶段)。
SELECT @@profiling; -- 查看是否开启(默认0)
SET profiling = 1; -- 开启
SELECT * FROM user WHERE name LIKE 'Gu%'; -- 执行SQL
show profiles; -- 查看所有profiles(获query_id)
show profile for query 10; -- 查看query_id=10的耗时
SET profiling = 0; -- 关闭
3.4 SHOW PROCESSLIST(查看线上 SQL)
查看连接线程;可以查看此时线上运行的 SQL 语句; 如果要查看完整的 SQL 语句: SHOW FULL PROCESSLIST ; 然后优化该语句;
SHOW PROCESSLIST; -- 简要信息(SQL可能截断)
SHOW FULL PROCESSLIST; -- 完整SQL
- 核心关注:
Time(执行时间,秒)、Info(SQL 语句),定位长时间运行的 SQL。
3.5 统计信息维护
-- 查看索引统计信息
SHOW INDEX FROM student;-- 立即更新 Cardinality 值
ANALYZE TABLE student;-- 调整 Change Buffer 大小
SELECT @@innodb_change_buffer_max_size; -- 默认25(1/4缓冲池)
SET GLOBAL innodb_change_buffer_max_size=30;-- 自适应 Hash 索引
SELECT @@innodb_adaptive_hash_index;
SET GLOBAL innodb_adaptive_hash_index=1; -- 默认开启
注意: 在非高峰时间段,对数据库中几张核心表做 ANALYZE TABLE 操作,这能使优化器和索引更好的工作。
四、出现 sql 比较慢怎么办?🌟
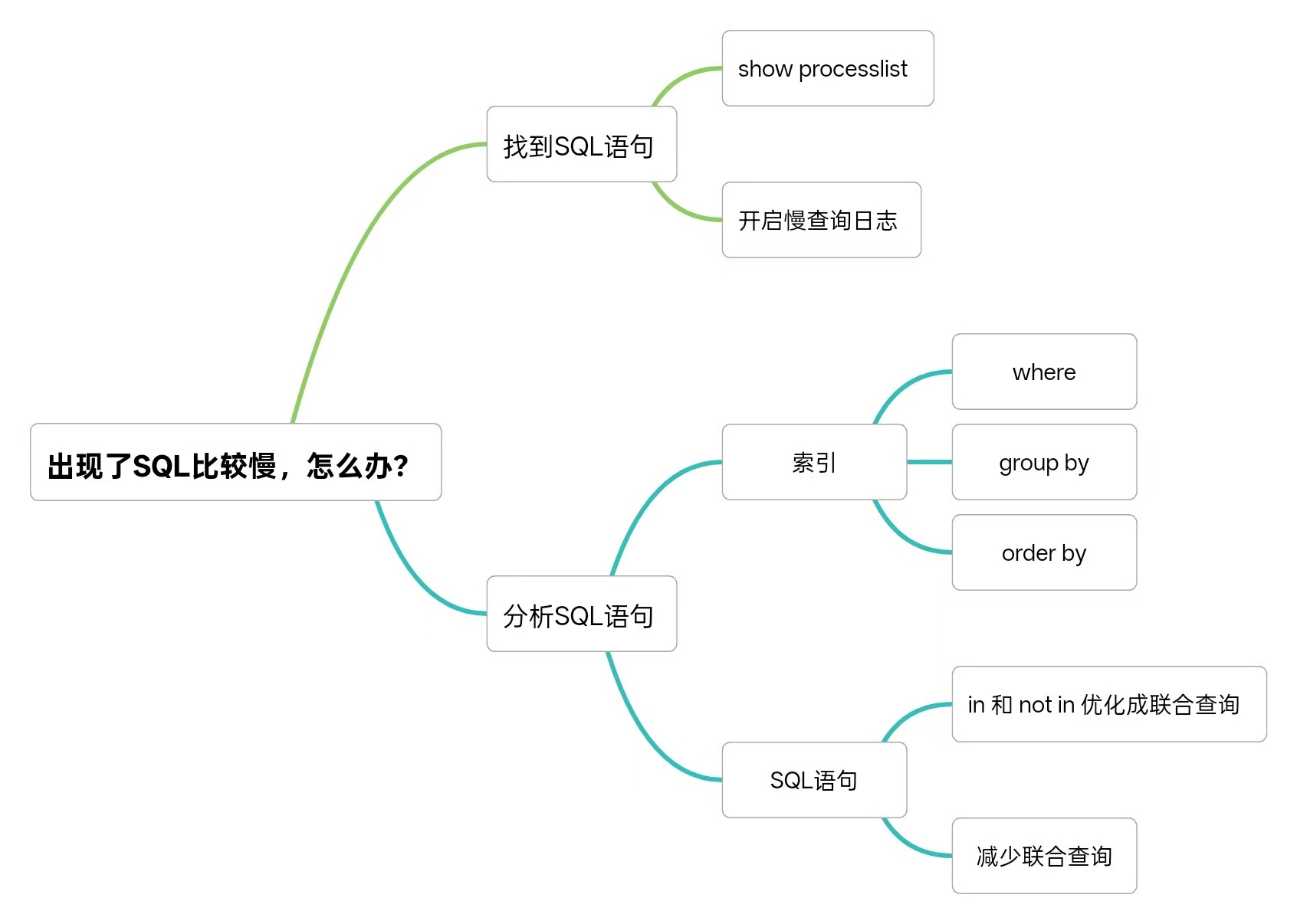
当遇到SQL执行较慢的情况,按“定位问题、分析、优化”的思路处理:
- 首先是定位阶段:
- 通过 show processlist 实时查看运行中的 SQL,重点关注执行时间长的语句;
- 再开启 慢查询日志,并结合工具如 mysqldumpslow 或 pt-query-digest 对日志分析,快速锁定高频或高耗时的慢查询语句。
- 定位到问题后进入分析阶段:
- 通过
explain或explain analyze查看SQL执行计划,重点关注 type、key、rows、Extra 等字段是否合理,比如是否走了索引、是否存在全表扫描
- 通过
- 然后针对性优化:
- 一是检查索引合理性,确保
where、group by、order by子句涉及的字段都有合适的索引,避免全表扫描或索引失效; - 二是优化SQL语句本身,比如把
in或not in替换成更高效的联合查询,同时尽量减少多表联合查询的次数;结构层面优化字段类型、拆分大表或大字段,必要时做分区或分库。
- 一是检查索引合理性,确保
补充:
另外在实际工作中,不要直接存储age字段,而是存储用户的生日(年月日),这样既能灵活计算实时年龄,又能避免后续因年龄变化带来的数据维护成本,最终提升SQL的执行效率。