SCSegamba:用于结构裂缝分割的轻量级结构感知视觉Mamba网络
摘要
在各种场景下对结构裂缝进行像素级分割仍然是一项重大挑战。现有方法在有效建模裂缝形态和纹理方面面临困难,并且难以在分割质量与低计算资源消耗之间取得平衡。为克服这些局限性,我们提出了一种轻量级的结构感知视觉Mamba网络(SCSegamba),该网络能够以极低的计算成本,利用裂缝像素的形态信息和纹理线索生成高质量的像素级分割图。具体而言,我们开发了一种结构感知视觉状态空间模块(SAVSS),该模块结合了轻量级门控瓶颈卷积(GBC)和结构感知扫描策略(SASS)。GBC的关键优势在于其在建模裂缝形态信息方面的有效性,而SASS则通过加强裂缝像素之间语义信息的连续性,增强了对裂缝拓扑结构和纹理的感知。在裂缝基准数据集上的实验表明,我们的方法优于其他最先进的(SOTA)方法,在仅拥有280万参数的情况下取得了最高性能。在多场景数据集上,我们的方法达到了0.8390的F1分数和0.8479的mIoU。代码已公开于 https://github.com/Karl1109/SCSegamba。
1. 引言
沥青路面、混凝土和金属等结构在剪切应力下经常会产生裂缝,因此定期进行健康监测对于避免生产问题至关重要[3, 4, 19, 23, 30]。由于材料特性和环境条件的差异,不同材料的裂缝形态和视觉外观存在显著差异[24]。因此,在多样化的场景中实现像素级裂缝分割仍然是一项复杂的挑战。
最近,卷积神经网络(CNNs),如ECSNet[59]和SFIAN[5],由于其强大的局部归纳特性,在分割任务中表现出有效的裂缝特征提取能力。然而,其有限的感受野限制了它们对整个图像中广泛不规则依赖关系的建模能力,导致分割不连续和背景噪声抑制能力弱。尽管空洞卷积[2]可以扩展感受野,但其固有的归纳偏置仍然无法完全解决此问题[58],尤其是在具有严重背景干扰的复杂裂缝模式中。
Vision Transformer(ViT)[10, 45, 47]的成功证明了Transformer在捕捉不规则像素依赖关系方面的有效性,这对于识别复杂的裂缝纹理至关重要,如DTrCNet[48]、MFAFNet[9]和Crackmer[46]等网络所示。然而,注意力计算的二次复杂度随序列长度增长,导致高内存使用和高分辨率图像的训练挑战,限制了其在资源受限的边缘设备上的部署和实际应用。如图1(a)所示,基于Transformer的方法如CTCrackseg[44]和DTrCNet[48]表现良好,但其庞大的参数量和高计算需求限制了它们在资源受限设备上的可部署性。尽管稀疏Transformer[6]和线性Transformer[21]等变体通过稀疏化或线性化注意力来降低计算需求,但它们牺牲了建模不规则依赖关系和像素纹理的能力,阻碍了像素级检测任务。因此,基于Transformer的方法难以在分割性能和计算效率之间取得平衡。
最近,选择性状态空间模型(SSMs)因其在Mamba[14, 15]中表现出的在序列建模中的强大性能和低计算需求而引起了广泛关注。Vision Mamba(ViM)[62]和VMamba[36]已将Mamba扩展到视觉领域。在低对比度图像中,裂缝区域的不规则延伸和众多分支经常受到无关区域和阴影的影响,这对现有Mamba VSS(视觉状态空间模型)块结构和扫描策略在有效捕捉裂缝形态和纹理方面提出了挑战。大多数基于Mamba的方法[37, 51, 52, 55]通过线性层处理特征图,限制了对裂缝特征相对于无关干扰的选择性增强或抑制,从而降低了对详细形态的提取能力。此外,常见的并行或单向对角线扫描[16]在处理不规则、多方向的像素拓扑结构时难以保持语义连续性,削弱了它们处理复杂纹理和抑制噪声的能力。因此,当前基于Mamba的SSM在多场景裂缝图像中经常产生误检或漏检。此外,尽管这些方法具有参数较少的优势,但在进一步降低其计算需求和增强其在边缘设备上的可部署性方面仍有潜力。如图1(b)所示,CSMamba[37]、MambaIR[16]和PlainMamba[55]在裂缝图像上的表现不尽如人意,在参数数量和计算负载方面仍有改进空间。
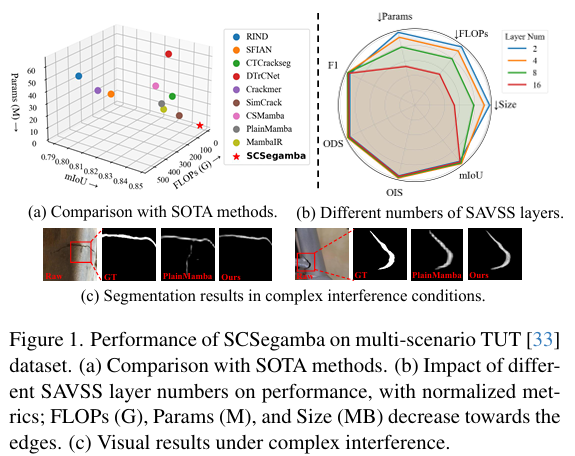
为了解决高分割质量与低计算需求之间的平衡挑战,我们提出了SCSegamba网络,该网络能够以低计算资源生成高质量的像素级裂缝分割图。为了提高Mamba网络对不规则裂缝纹理的感知能力,我们设计了一种结构感知视觉状态空间块(SAVSS),采用结构感知扫描策略(SASS)来增强语义连续性并加强裂缝形态感知。为了在保持低参数和计算成本的同时捕捉裂缝形状线索,我们设计了一种轻量级门控瓶颈卷积(GBC),能够针对复杂背景和变化的形态动态调整权重。此外,多尺度特征分割头(MFS)集成了GBC和多层感知机(MLP),以较低的计算需求生成高质量的分割图。如图1©所示,使用四个SAVSS层实现了最佳的分割性能,生成了清晰的分割图,能够有效屏蔽复杂干扰,同时保持模型的轻量级特性。
本质上,我们工作的主要贡献概述如下:
• 我们提出了一种新颖的轻量级视觉Mamba网络SCSegamba,用于裂缝分割。该模型能够有效捕捉裂缝像素的形态和不规则纹理线索,使用低计算资源生成高质量的分割图。
• 我们设计了SAVSS,结合了轻量级GBC卷积和SASS扫描策略,以增强对裂缝图像中不规则纹理线索的处理和感知。此外,还开发了一种简单而有效的MFS,以相对较低的计算资源生成分割图。
• 我们在跨多种场景的基准数据集上评估了SCSegamba,结果表明我们的方法在保持低参数量的同时优于其他SOTA方法。
2. 相关工作
2.1. 裂缝分割网络
早期的裂缝检测方法通常依赖于传统的特征提取技术,如小波变换[61]、渗透模型[54]和k-means算法[25]。尽管这些方法易于实现,但在抑制背景干扰和实现高分割精度方面面临挑战。随着深度学习的发展,研究人员开发了基于CNN的裂缝分割网络,在SOTA性能上取得了显著成果[5, 7, 18, 26, 40, 49]。例如,DeepCrack[35]实现了端到端的像素级分割,而FPHBN[56]展示了强大的泛化能力。BARNet[17]通过将图像梯度与特征相结合来检测裂缝边界,而ADDUNet[1]在不同条件下捕捉裂缝的精细和粗糙特征。尽管基于CNN的方法显示出巨大潜力,但CNN的局部操作和有限的感受野限制了其充分捕捉裂缝纹理线索和有效抑制背景噪声的能力。
Transformer[45]凭借其自注意力机制,非常适合需要长距离依赖建模的视觉任务,因此在裂缝分割网络中越来越受欢迎[9, 31, 32, 41, 53]。例如,基于Vision Transformer(ViT)的VCVNet[39]专为桥梁裂缝分割而设计,解决了细粒度分割的挑战。SWT-CNN[27]结合了Swin Transformer和CNN进行自动特征提取,而TBUNet[60]是一种基于Transformer的知识蒸馏模型,通过混合损失函数实现了高性能的裂缝分割。尽管基于Transformer的方法在捕捉裂缝纹理线索和抑制背景噪声方面非常有效,但其自注意力机制引入了随序列长度呈二次方增长的计算复杂度。这导致了高参数量和巨大的计算需求,限制了它们在资源受限的边缘设备上的部署。
2.2. 选择性状态空间模型
Mamba模型[14]中引入的选择性状态空间模型(S6)凸显了SSM[12, 13]的潜力。与线性时不变的S4模型不同,S6在保持计算效率的同时,能够高效地捕捉复杂的长距离依赖关系,在NLP、音频和基因组学领域取得了强大性能。因此,研究人员已将Mamba适配到视觉领域,创建了各种VSS块。ViM[62]在不使用注意力机制的情况下实现了与ViT[10]相当的建模能力,同时使用了更少的计算资源,而VMamba[36]则优先考虑高效计算和高性能。PlainMamba[55]采用固定宽度的层堆叠方法,在实例分割和目标检测等任务中表现出色。然而,VSS块和扫描策略需要针对每个视觉任务进行特定优化,因为不同任务对长距离和短距离信息的依赖程度不同,需要定制化的VSS块设计以确保最佳性能。
目前,尚无针对裂缝分割的高性能基于Mamba的模型。因此,设计一个针对裂缝分割优化的VSS结构对于提高性能和效率至关重要。鉴于裂缝的复杂细节和不规则纹理,VSS块需要强大的形状提取能力和方向感知能力,以有效捕捉裂缝纹理线索。此外,它还应在最小化计算资源需求的同时,促进高效的裂缝分割。
3. 方法论
3.1. 预备知识
我们提出的SCSegamba的完整架构如图2所示。它包含两个主要组件:用于提取裂缝形状和纹理线索的SAVSS,以及用于高效特征处理的MFS。为了捕捉关键的裂缝区域线索,我们在SAVSS的初始阶段和MFS的最后阶段集成了GBC。
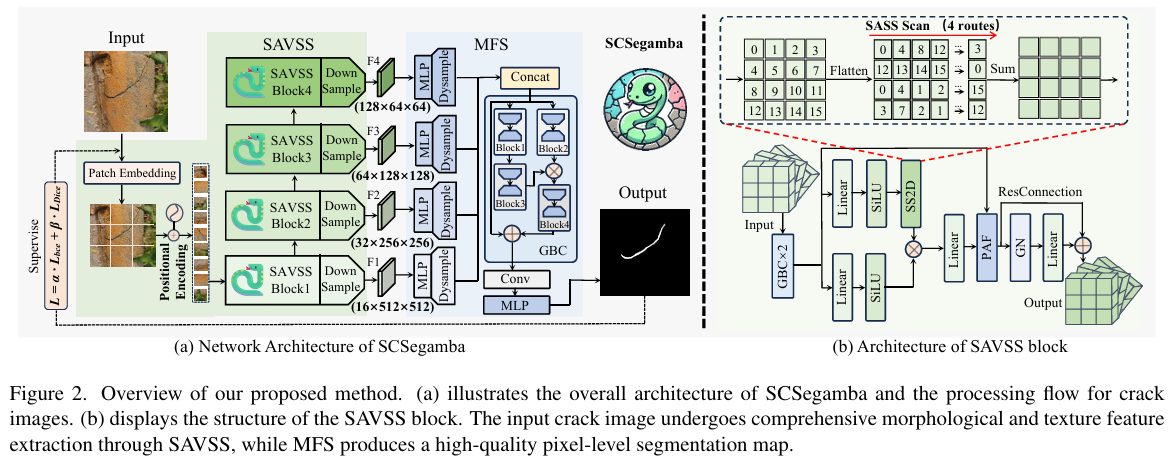
对于单张RGB图像 E∈R3×H×WE\in\mathbb{R}^{3\times H\times W}E∈R3×H×W,空间信息被划分为n个块(patches),形成一个序列 {B1,B2,…,Bn}\{B_{1},B_{2},\ldots,B_{n}\}{B1,B2,…,Bn}。该序列通过SAVSS块进行处理,将关键的裂缝像素线索嵌入到多尺度特征图 {F1,F2,F3,F4}\{F_{1},F_{2},F_{3},F_{4}\}{F1,F2,F3,F4} 中。最后,在MFS中,所有信息被整合到一个张量中,生成精细化的分割输出 W∈R1×H×WW\in\mathbb{R}^{1\times H\times W}W∈R1×H×W。
3.2. 轻量级门控瓶颈卷积
门控机制能够为每个空间位置和通道生成动态特征,从而增强模型捕捉细节的能力[8, 57]。为了进一步减少参数量和计算成本,我们嵌入了具有低秩近似[28]的瓶颈卷积(BottConv),将矩阵从高维空间映射到低维空间,显著降低了计算复杂度。
在卷积层中,假设滤波器的空间大小为p,输入通道数为d,输入为s,则卷积响应可以表示为:
z=Qs+cz=Q s+c z=Qs+c
其中 QQQ 是一个大小为 f×(p2×d)f\times(p^{2}\times d)f×(p2×d) 的矩阵,fff 是输出通道数,c是原始偏置项。假设z位于一个秩为 f0f_{0}f0 的低秩子空间中,则可以表示为 z=V(z−z1)+z1\mathrm{z=V(z-z_{1})+z_{1}}z=V(z−z1)+z1,其中 z1z_{1}z1 抽象了特征的均值向量,作为辅助变量以促进理论推导并校正特征偏移,V=LMTV=L M^{T}V=LMT (L∈Rf×f0,M∈R(p2d)×f0)(L\in\mathbb{R}^{f\times f_{0}},M\in\mathbb{R}^{(p^{2}d)\times f_{0}})(L∈Rf×f0,M∈R(p2d)×f0) 代表低秩投影矩阵。简化的响应变为:
z=LMTs+c′z=L M^{T}s+c^{\prime}z=LMTs+c′
由于 f0 < ff_{0}~<~ff0 < f,计算复杂度从 O(fp2d)O(f p^{2}d)O(fp2d) 降低到 O(f0p2d)+O(ff0)O(f_{0}p^{2}d)+O(f f_{0})O(f0p2d)+O(ff0),其中 O(ff0)≪O(f f_{0})\llO(ff0)≪ O(fp2d)O(f p^{2}d)O(fp2d),表明计算复杂度的降低与原始的 f0/ff_{0}/ff0/f 比例成正比。
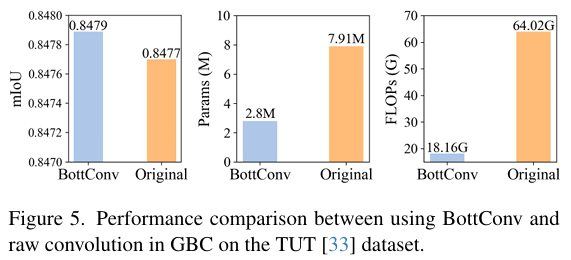
在BottConv中,逐点卷积将特征投影到低秩子空间或从中投影出来,从而显著降低复杂度,而深度卷积则在子空间中执行充分的空间信息提取,保证了可忽略的低复杂度。如图5所示,我们GBC设计中的BottConv与原始卷积相比,显著减少了参数量和计算负载,对性能的影响微乎其微。
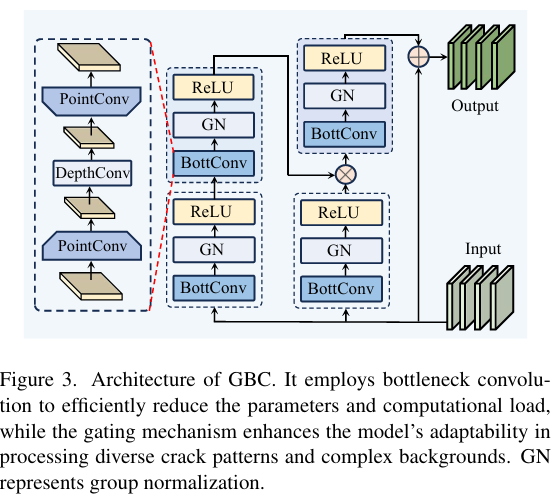
如图3所示,输入特征 x∈RC×H×Wx \in\mathbb{R}^{C\times H\times W}x∈RC×H×W 被保留为 xresidual=xx_{\mathrm{residual}}=xxresidual=x,以方便残差连接。随后,特征x通过BottConv层,再经过归一化和激活函数,得到特征 x1x_{1}x1 和 g2(x)g_{2}(x)g2(x),如下所示:
g1(x)=ReLU(Norm1(f1(x)))g_{1}(x)=ReLU(Norm_{1}(f_{1}(x)))g1(x)=ReLU(Norm1(f1(x)))
x1=ReLU(Norm2(BottConv2(g1(x))))x_{1}=ReLU(Norm_{2}(BottConv_{2}(g_{1}(x))))x1=ReLU(Norm2(BottConv2(g1(x))))
g2(x)=ReLU(Norm3(BottConv3(x)))g_{2}(x)=ReLU(Norm_{3}(BottConv_{3}(x)))g2(x)=ReLU(Norm3(BottConv3(x)))
为了生成门控特征图,x1x_{1}x1 和 g2(x)g_{2}(x)g2(x) 通过Hadamard积(逐元素相乘)进行组合:
m(x)=x1⊙g2(x)m(x)=x_{1}\odot g_{2}(x)m(x)=x1⊙g2(x)
门控特征图 m(x)m(x)m(x) 随后再次通过BottConv进行处理,以进一步细化细粒度细节。应用残差连接后,得到的输出为:
y=ReLU(Norm4(BottConv4(m(x))))y=ReLU(Norm_{4}(BottConv_{4}(m(x))))y=ReLU(Norm4(BottConv4(m(x))))
Output=y+xresidualOutput=y+x_{\mathrm{residual}}Output=y+xresidual
BottConv的设计和更深的门控分支使模型能够在保留基本裂缝特征的同时,动态地细化主分支的细粒度特征表征,从而在细节区域生成更准确的分割图。
3.3. 结构感知视觉状态空间模块
我们设计的SAVSS具有一种针对视觉任务定制的二维选择性扫描(SS2D)。不同的扫描策略会影响模型捕捉连续裂缝纹理的能力。如图4所示,当前的视觉Mamba网络使用了多种扫描方向,包括并行、蛇形、双向和对角线扫描[36, 55, 62]。并行和对角线扫描在行或对角线之间缺乏连续性,这限制了它们对裂缝方向的敏感性。尽管双向和蛇形扫描沿水平或垂直路径保持了语义连续性,但它们难以捕捉对角线或交织的纹理。为了解决这个问题,我们提出的对角蛇形扫描旨在更好地捕捉复杂的裂缝纹理线索。
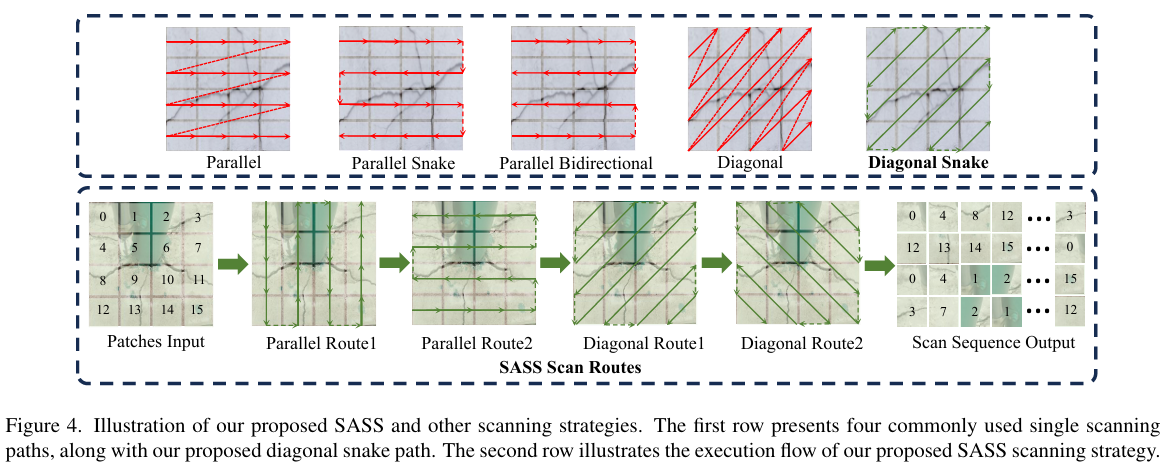
SASS由四条路径组成:两条并行的蛇形路径和两条对角蛇形路径。这种设计能够有效地在规则裂缝区域提取连续的语义信息,同时在多个方向上保持纹理连续性,使其适用于具有复杂背景的多场景裂缝图像。
在RGB裂缝图像经过块嵌入(Patch Embedding)和位置编码(Position Encoding)后,它被作为序列输入到SAVSS块中。为了保持网络的轻量级,我们仅使用4层SAVSS块。处理方程如下:
P‾=eΔP\overline{{P}}=e^{\Delta P}P=eΔP
Q‾=(ΔP)−1(eΔP−I)⋅ΔQ\overline{{Q}}=(\Delta P)^{-1}(e^{\Delta P}-I)\cdot\Delta Q Q=(ΔP)−1(eΔP−I)⋅ΔQ
zk=P‾zk−1+Q‾wkz_{k}=\overline{{P}}z_{k-1}+\overline{{Q}}w_{k}zk=Pzk−1+Qwk
uk=Rzk+Swku_{k}=R z_{k}+S w_{k}uk=Rzk+Swk
在这些方程中,输入 w∈Rt×Dw\in\mathbb{R}^{t\times D}w∈Rt×D,P∈RG×DP\in\mathbb{R}^{G\times D}P∈RG×D 控制隐藏的空间状态,S ∈ RD×DS\;\in\;\mathbb{R}^{D\times D}S∈RD×D 用于初始化输入的跳跃连接,zkz_kzk 代表在时间步 kkk 的特定隐藏状态,Q ∈ RG×DQ\;\in\;\mathbb{R}^{G\times D}Q∈RG×D 和 Rˉ∈RG×D\bar{R}\in\mathbb{R}^{G\times D}Rˉ∈RG×D 是分别具有隐藏空间维度 GGG 和时间维度D的矩阵,通过选择性扫描SS2D获得。这些是可训练的参数,会相应地更新。uku_{k}uk 代表在时间步k的输出。SASS建立了多方向的邻接关系,使得隐藏状态 zkz_{k}zk 能够捕捉更复杂的拓扑和纹理细节,同时使输出 uku_{k}uk 能够更有效地整合多方向特征。
为了有效地将初始序列x与通过SS2D处理后的序列结合起来,我们引入了面向像素注意力的融合(PAF)[33],增强了SAVSS捕捉裂缝形状和纹理细节的能力。在选择性扫描之后,对融合后的信息应用残差连接,以保留细节并促进特征流动。此外,GBC在SAVSS内部对层间输出进行细化,加强了裂缝信息的提取,并提升了后续阶段的性能。
3.4. 多尺度特征分割头
与卷积层不同,MLP能够快速学习特征与标签之间的映射关系,从而降低模型复杂度。当SAVSS产生的四个特征图 F1,F2,F⌣3,F4 ∈ RC⋅×H×W⋅F_{1},F_{2},\overset{\smile}{F}_{3},F_{4}\:\in\:\mathbb{R}^{\overset{\centerdot}{C}\times H\times\overset{\centerdot}{W}}F1,F2,F⌣3,F4∈RC⋅×H×W⋅ 被送入MFS时,它们会分别通过高效的MLP操作和动态上采样[34]进行处理,将其分辨率恢复到原始大小,得到 F1up,F2up~,F3up,F4up∈RC×H×WF_{1}^{\mathrm{up}},\widetilde{F_{2}^{\mathrm{up}}},F_{3}^{\mathrm{up}},F_{4}^{\mathrm{up}}\in\mathbb{R}^{C\times H\times W}F1up,F2up,F3up,F4up∈RC×H×W。公式如下:
Fiup=DySample(MLPi(Fi))F_{i}^{up}=DySample(MLP_{i}(F_{i}))Fiup=DySample(MLPi(Fi))
其中i表示层索引。
为了整合所有多尺度的裂缝形状和纹理表征,这些特征图被聚合到一个张量中,从而获得高质量的裂缝分割图 o∈R1×H×Wo\in\mathbb{R}^{1\times H\times W}o∈R1×H×W,如下所示:
o1=GBC(Concat(F1up,F2up,F3up,F4up))o_{1}=GBC(Concat(F_{1}^{up},F_{2}^{up},F_{3}^{up},F_{4}^{up}))o1=GBC(Concat(F1up,F2up,F3up,F4up))
o=MLP(Conv(o1))o=MLP(Conv(o_{1}))o=MLP(Conv(o1))
3.5. 目标函数
我们使用二元交叉熵损失(BCE)[29]和Dice损失[43]的混合体作为目标函数,这有助于提高网络对像素数据不平衡的鲁棒性。总体损失函数表示如下:
L=α⋅LDice+β⋅LBCEL=\alpha\cdot L_{Dice}+\beta\cdot L_{BCE}L=α⋅LDice+β⋅LBCE
其中超参数α和 β\betaβ 控制两个损失分量的权重。α与 β\betaβ 的比例被设置为1:5。
4. 实验
4.1. 数据集
Crack500 [56]。该数据集中的图像是用手机拍摄的。原始数据集包含500张沥青裂缝图像,通过数据增强扩展到3368张图像。每张图像都配有一张对应的像素级标注的二值图像。
DeepCrack [35]。该数据集包含537张水泥、砖块和沥青裂缝的RGB图像,涵盖了精细、宽大、污渍和模糊等各种条件下的裂缝,确保了多样性和代表性。
CrackMap [22]。该数据集是为道路裂缝分割研究而创建的,包含120张高分辨率RGB图像,捕捉了各种细薄和复杂的沥青道路裂缝。
TUT [33]。与其他背景简单的数据集相比,该数据集包含密集、杂乱的背景,并且裂缝具有精致、复杂的形状。它包含1408张RGB图像,涵盖八种场景:沥青、水泥、砖块、跑道、瓷砖、金属、叶片和管道。
在处理过程中,所有数据集均按7:1:2的比例划分为训练集、验证集和测试集。
4.2. 实现细节
实验设置。我们使用PyTorch v1.13.1构建了SCSegamba网络,并在配备八块Nvidia GeForce RTX 4090 GPU的Intel Xeon Platinum 8336C CPU上进行训练。使用AdamW优化器,初始学习率为 5e−45\mathrm{e-}45e−4,采用PolyLR调度策略,权重衰减为0.01,随机种子为42。网络训练了50个epoch,并选择验证性能最佳的模型进行测试。
对比方法。为了全面评估我们的模型,我们将SCSegamba与9种SOTA方法进行了比较。基于CNN或Transformer的模型包括RIND [38]、SFIAN [5]、CTCrackSeg[44]、DTrCNet[48]、Crackmer [46]和SimCrack [20]。此外,我们还将其与其他基于Mamba的模型进行了比较,包括CSMamba [37]、PlainMamba [55]和MambaIR [16]。
评估指标。我们使用六个指标来评估SCSegamba的性能:精确率(P)、召回率(R)、F1分数 (F1=ˉ2RPR+P)\textstyle(F1={\frac{\bar{}2R P}{R+P}})(F1=R+Pˉ2RP)、最优数据集尺度(ODS)、最优图像尺度(OIS)和平均交并比(mIoU)。ODS在固定阈值m下衡量模型对不同尺度数据集的适应性,而OIS在最优阈值n下评估模型对不同图像尺度的适应性。计算公式如下:
ODS=maxm2⋅Pm⋅RmPm+RmODS=\operatorname*{max}_{m}\frac{2\cdot P_{m}\cdot R_{m}}{P_{m}+R_{m}}ODS=mmaxPm+Rm2⋅Pm⋅Rm
OIS=1N∑i=1Nmaxn2⋅Pn,i⋅Rn,iPn,i+Rn,iOIS=\frac{1}{N}\sum_{i=1}^{N}\operatorname*{max}_{n}\frac{2\cdot P_{n,i}\cdot R_{n,i}}{P_{n,i}+R_{n,i}}OIS=N1i=1∑NnmaxPn,i+Rn,i2⋅Pn,i⋅Rn,i
mIoU用于衡量真实标签与预测结果之间交并比的平均比例。其计算公式为:
mIoU=1N+1∑l=0Npll∑t=0Nplt+∑t=0Nptl−pllmIoU=\frac{1}{N+1}\sum_{l=0}^{N}\frac{p_{ll}}{\sum_{t=0}^{N}p_{lt}+\sum_{t=0}^{N}p_{tl}-p_{ll}}mIoU=N+11l=0∑N∑t=0Nplt+∑t=0Nptl−pllpll
其中N是类别数,我们设为 N=1N=1N=1;t代表真实标签,l代表预测值,ptlp_{tl}ptl 代表被分类为l但实际属于t的像素数量。
此外,我们使用三个指标来评估我们方法的复杂度:FLOPs、Params和Model Size,分别代表计算复杂度、参数复杂度和内存占用。
4.3. 与SOTA方法的比较
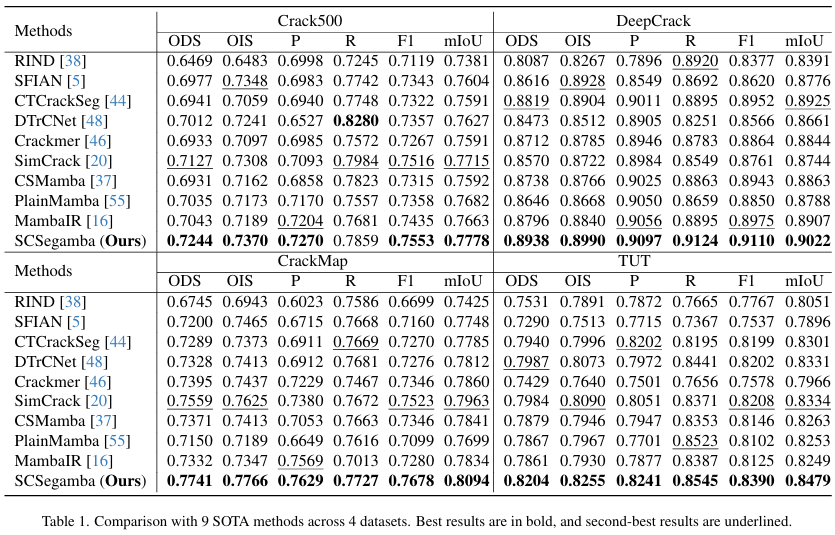
如表1所示,与其它9种SOTA方法相比,我们提出的SCSegamba在四个公共数据集上均取得了最佳性能。具体而言,在包含更大、更复杂裂缝区域的Crack500[56]和DeepCrack[35]数据集上,SCSegamba取得了最高性能。值得注意的是,在DeepCrack数据集上,其F1分数和mIoU分别比次优方法高出1.50%和1.09%。这一改进归功于GBC在大裂缝区域捕捉形态线索的强大能力,增强了模型的表征能力。在包含更细、更细长裂缝的CrackMap[22]数据集上,我们的方法在所有指标上均超越了其他SOTA方法,F1和mIoU分别比次优方法高出2.06%和1.65%。这证明了SASS在捕捉精细纹理和细长裂缝结构方面的有效性。如图6所示,我们的方法生成了更清晰、更精确的特征图,在水泥和沥青等典型场景中,细节捕捉能力优于其他方法。

对于包含八种多样化场景的TUT数据集[33],我们的方法取得了最佳性能,F1和mIoU分别比次优方法高出2.21%和1.74%。如图6所示,无论是在塑料跑道的复杂裂缝拓扑、金属材料和涡轮叶片的高噪声背景,还是在低对比度、光线昏暗的地下管道图像中,SCSegamba始终能生成高质量的分割图,同时有效抑制无关噪声。这表明,我们的方法凭借GBC和SASS增强的裂缝形态和纹理感知能力,表现出卓越的鲁棒性和稳定性。此外,利用MFS进行特征聚合,提高了多尺度感知能力,使我们的模型特别适合于多样化、干扰丰富的场景。
4.4. 复杂度分析
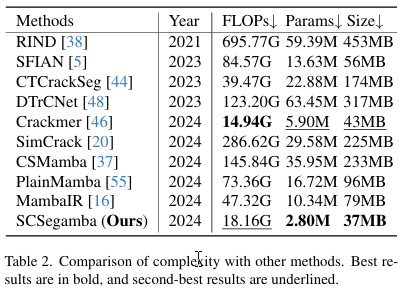
表2显示了当输入图像大小统一设置为512时,我们的方法与其他SOTA方法的复杂度比较。我们的方法仅拥有280万参数和37MB的模型大小,超越了所有其他方法,分别比次优结果低52.54%和13.95%。此外,与优先考虑计算效率的Crackmer[46]相比,我们方法的FLOPs仅高出3.22G。这表明,轻量级SAVSS和MFS的结合能够在参数极少、计算负载低的情况下,在噪声裂缝场景中实现高质量的分割,这对于资源受限的设备至关重要。
4.5. 消融实验
我们在具有代表性的多场景数据集TUT[33]上进行了消融实验。
分割头的消融研究。如表3所示,使用我们设计的MFS,SCSegamba在所有六个指标上均取得了最佳结果,F1和mIoU分数分别比次优方法高出1.57%和1.21%。在复杂度方面,尽管Params、FLOPs和Model Size仅比SegFormer头大0.01M、0.29G和2MB,但我们的方法在F1和mIoU上分别超越了它2.67%和2.07%。这表明MFS增强了SAVSS输出的整合,显著提升了性能,同时保持了模型的轻量级。
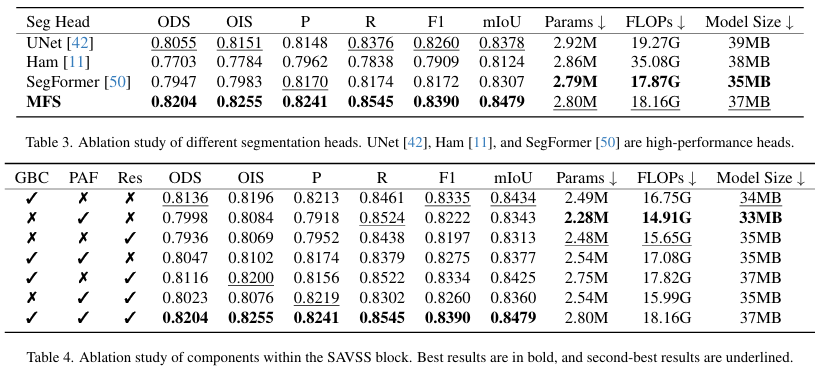
组件的消融研究。表4显示了SAVSS中每个组件对模型性能的影响。当完全利用GBC、PAF和残差连接时,我们的模型在所有指标上都取得了最佳结果。值得注意的是,加入GBC使F1和mIoU分别显著提高了1.57%和1.42%,凸显了其在捕捉裂缝形态线索方面的优势。同样,残差连接使F1和mIoU分别提升了0.13%和2.47%,表明其在聚焦于关键裂缝特征方面的作用。尽管仅使用PAF时Params、FLOPs和Model Size最低,但性能却大幅下降。这些发现表明,我们完全集成的SAVSS能够有效捕捉裂缝形态和纹理线索,在保持轻量级模型的同时,实现了顶级的像素级分割结果。
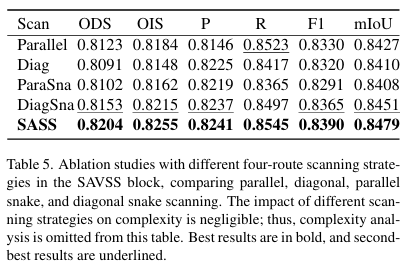
扫描策略的消融研究。如表5所示,在使用四条不同方向扫描路径的相同条件下,我们的模型在采用我们设计的SASS扫描策略时取得了最佳性能,F1和mIoU比对角蛇形策略分别提高了0.30%和0.33%。这证明了SASS能够构建适合裂缝拓扑的语义和依赖信息,增强了后续模块对裂缝像素的感知能力。更全面的实验和真实世界部署见附录。
5. 结论
在本文中,我们提出了SCSegamba,一种用于精确像素级裂缝分割的轻量级结构感知视觉Mamba网络。SCSegamba结合了SAVSS和MFS,以低参数量增强了对裂缝形状和纹理的感知。配备了GBC和SASS扫描的SAVSS,能够捕捉各种结构中的不规则裂缝纹理。在四个数据集上的实验表明,SCSegamba在复杂、嘈杂的场景中表现出卓越的性能。在具有挑战性的多场景数据集上,它仅用18.16G FLOPs和280万参数就达到了0.8390的F1分数和0.8479的mIoU,证明了其在现实世界裂缝检测中的有效性以及在边缘设备上的适用性。未来的工作将结合多模态线索以增强分割质量,同时进一步优化VSS设计和扫描策略,以在低计算资源下实现高质量的结果。
6. 致谢
本工作得到了中国国家自然科学基金(NSFC)项目62272342、62020106004、62306212和T2422015;天津市自然科学基金项目23JCJQJC00070和24PTLYHZ00320;以及玛丽·斯克沃多夫斯卡-居里行动(MSCA)项目101111188的资助。
补充材料
7. SASS细节与消融实验
如第3.3小节所述,SASS策略通过从多个方向扫描纹理线索,增强了在复杂裂缝区域的语义捕捉能力。SASS结合了并行蛇形和对角蛇形扫描,使扫描路径与裂缝的实际延伸和不规则形状对齐,确保了对纹理信息的全面捕捉。
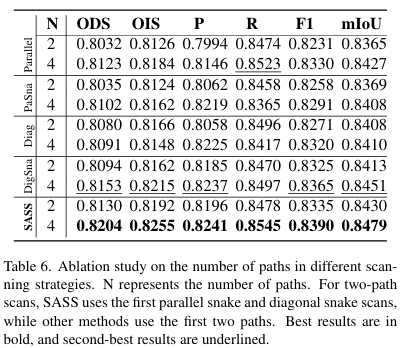
为了评估SASS中使用四条扫描路径的必要性,我们在多场景数据集TUT上对不同路径数量的各种扫描策略进行了消融实验。如表6所示,所有策略在使用四条路径时的表现都显著优于使用两条路径,这可能是因为四条路径允许SAVSS捕捉更精细的裂缝细节和拓扑线索。值得注意的是,除了SASS之外,对角蛇形扫描始终取得第二好的结果,其两路径配置的F1和mIoU分数比对角单向扫描分别高出0.48%和0.45%。这表明对角蛇形扫描提供了更连续的语义信息,从而增强了分割效果。重要的是,我们提出的SASS在两路径和四路径设置下都取得了最佳结果,证明了其在捕捉多样化裂缝拓扑结构方面的有效性。
为了阐明我们提出的SASS的实现,我们在算法1中展示了其执行过程。
8. 目标函数细节与分析
BCE[29]损失和Dice[43]损失的计算公式如下:
LDice=1−2∑j=1Mpjp^j+ϵ∑j=1Mpj+∑j=1Mp^j+ϵL_{Dice}=1-\frac{2\sum_{j=1}^{M}p_{j}\hat{p}_{j}+\epsilon}{\sum_{j=1}^{M}p_{j}+\sum_{j=1}^{M}\hat{p}_{j}+\epsilon}LDice=1−∑j=1Mpj+∑j=1Mp^j+ϵ2∑j=1Mpjp^j+ϵ
LBCE=−1N[pjlog(p^j)+(1−pj)log(1−p^j)]L_{BCE}=-\frac{1}{N}\left[p_{j}\log(\hat{p}_{j})+(1-p_{j})\log(1-\hat{p}_{j})\right]LBCE=−N1[pjlog(p^j)+(1−pj)log(1−p^j)]
其中M表示样本数量,pjp_{j}pj 是第 jjj 个样本的真实标签,p^j\hat{p}_{j}p^j 是第 jjj 个样本的预测概率,ϵ是一个小常数。
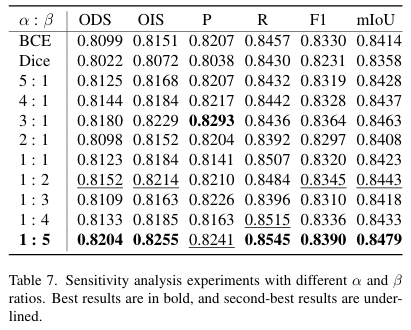
在公式16中,α与 β\betaβ 的比例被设置为1:5。这是在多场景数据集上对各种超参数设置进行实验后选择的α和β的最优比例。如表7所示,将α与 β\betaβ 的比例设置为1:5可获得最佳性能,F1和mIoU分别比1:2的比例提高了0.65%和0.55%。这表明,以1:5的比例平衡Dice损失和BCE损失有助于模型更好地区分背景像素和少数裂缝区域像素,从而提升性能。
9. 可视化对比
为了直观地展示SCSegamba的优势,我们在图7中展示了详细的可视化结果。对于主要包含背景噪声最小、裂缝厚度各异的沥青、混凝土和砖块场景的Crack500[56]、DeepCrack[35]和CrackMap[22]数据集,我们的方法始终能实现准确分割,甚至能捕捉到复杂的细裂缝。这归功于GBC在捕捉裂缝形态方面的强大能力。相比之下,其他方法在连续性和精细分割方面表现较弱,导致出现不连续性和分割区域扩大,与实际裂缝图像不符。

对于包含多样化场景和显著背景噪声的TUT[33]数据集,我们的方法在抑制干扰方面表现出色。例如,在发电机叶片和钢管上的裂缝图像中,它能有效最小化无关噪声并提供精确的裂缝分割。这一性能在很大程度上归功于SAVSS对裂缝拓扑结构的准确捕捉。相比之下,基于CNN的方法如RIND[38]和SFIAN[5]难以区分背景噪声和裂缝区域,突显了它们在上下文依赖捕捉方面的局限性。其他基于Transformer和Mamba的方法在分割连续性和细节处理方面也不及我们的方法。
10. 附加分析
为了全面展示我们提出的SCSegamba中每个组件的必要性,我们进行了更广泛的分析实验。
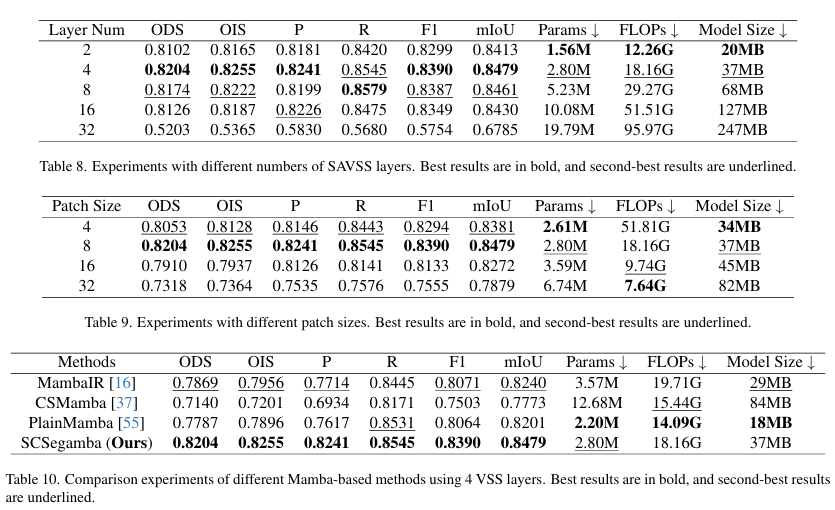
不同SAVSS层数的比较。在我们的SCSegamba中,我们使用了4层SAVSS块来平衡性能和计算需求。如表8所示,4层取得了最佳结果,F1和mIoU分数比8层分别高出0.036%和0.21%,同时减少了243万参数、11.11G计算量和31MB模型大小。尽管仅使用2层能将资源需求降至最低(156万参数),但性能有所下降。相反,使用32层会增加资源消耗并降低性能,因为冗余特征影响了泛化能力。因此,4层SAVSS在性能和资源效率之间取得了有效平衡,非常适合实际应用。

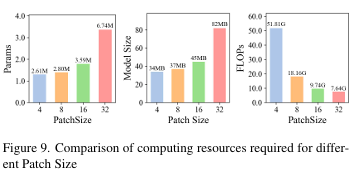
不同块大小(Patch Size)的比较。在我们的SAVSS中,我们在块嵌入(Patch Embedding)时将块大小设置为8。为了验证其有效性,我们对各种块大小进行了实验。如表9所示,块大小为8时性能最佳,F1和mIoU分数比块大小为4时分别高出1.16%和1.17%。尽管较小的块大小4减少了参数和模型大小,但它限制了感受野,阻碍了对更长纹理的有效捕捉,影响了分割效果。如图9所示,随着块大小的增加,参数数量和模型大小减少,但每个块的计算负载增加,影响了效率。当块大小为32时,由于细粒度细节捕捉和对上下文变化的敏感性降低,性能显著下降。因此,块大小为8在细节准确性和泛化能力之间取得了平衡,同时保持了模型效率。
相同VSS层数下的比较。在第4.3小节中,我们将SCSegamba与其他SOTA方法进行了比较,对基于Mamba的模型如MambaIR[16]、CSMamba[37]和PlainMamba[55]使用了默认的VSS层数设置。为了在统一的VSS层数下检查复杂度和性能,我们将所有基于Mamba的模型都设置为4个VSS层并进行比较。如表2和表10所示,尽管MambaIR、CSMamba和PlainMamba的计算需求有所降低,但它们的性能却显著下降。例如,CSMamba的F1和mIoU分数分别降至0.7503和0.7773。虽然具有4层的PlainMamba在参数、FLOPs和模型大小上分别减少了0.60M、4.07G和19MB,但SCSegamba在F1和mIoU上分别超越了它4.04%和3.39%。因此,采用4个SAVSS层,SCSegamba在性能和效率之间取得了平衡,能够捕捉裂缝形态和纹理,实现高质量分割。
11. 真实世界部署应用
为了验证我们提出的SCSegamba在真实世界应用中的有效性,我们进行了实际部署,并将其真实世界性能与其他SOTA方法进行了比较。具体而言,我们的实验系统由两个主要部分组成:智能车辆和服务器。所使用的智能车辆是由Raspberry Pi 4驱动的Turtlebot4 Lite,配备了LiDAR和摄像头。摄像头型号为OAK-D-Pro,配备了OV9282图像传感器,能够捕捉高质量的裂缝图像。服务器是一台配备Core i9-13900 CPU并运行Ubuntu 22.04的笔记本电脑。智能车辆和服务器通过互联网进行通信。该设置模拟了资源受限的设备,以评估我们的SCSegamba在真实世界部署场景中的性能。
如图8所示,在真实世界部署过程中,智能车辆被放置在布满裂缝的室外路面上。我们从服务器终端远程控制车辆,使其以0.15米/秒的速度沿直线向前移动。摄像头以每秒30帧的帧率捕捉视频。车辆通过网络将录制的视频数据实时传输到服务器。为了加速数据从车辆到服务器的传输,我们将录制分辨率设置为 512×512512\times512512×512。服务器在接收到视频数据后,首先将其分割成帧,然后将每一帧输入到在所有数据集上预训练的SCSegamba模型中进行推理。分割完成后,服务器将处理后的帧重新组合成视频,得到最终输出。该设置模拟了真实世界生产过程中的实时裂缝分割。
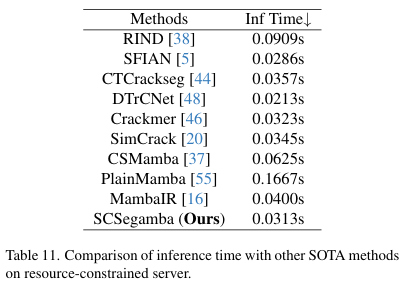
此外,我们在服务器上部署了其他SOTA方法的权重文件进行比较。如表11所示,我们的SCSegamba在资源受限的服务器上实现了每帧0.0313秒的推理速度,优于大多数其他方法。这表明我们的方法具有出色的实时性能,适用于视频数据中裂缝的实时分割。
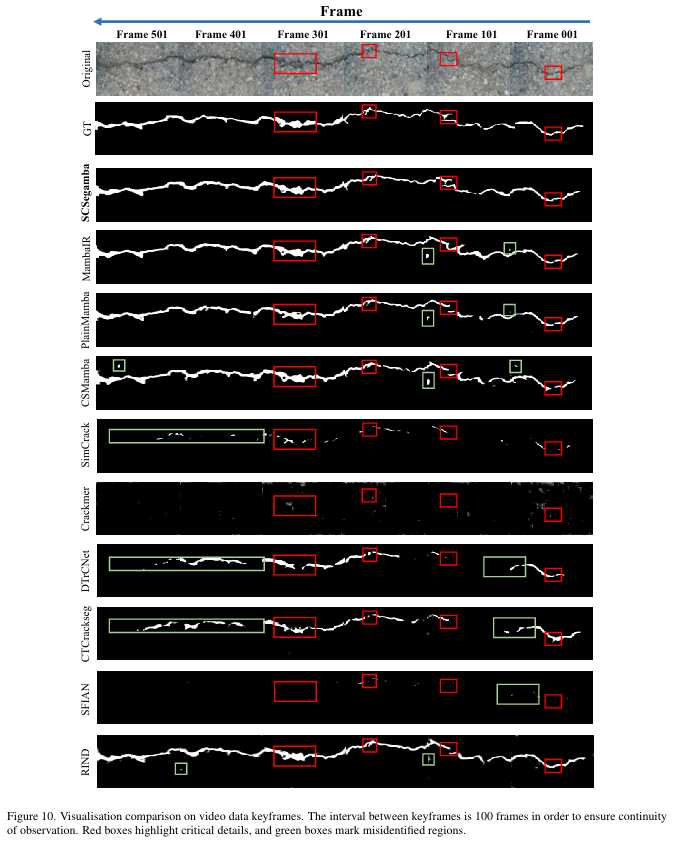
如图10所示,与其他SOTA方法相比,我们的SCSegamba能更好地抑制视频数据中的无关噪声,并生成连续的裂缝区域分割图。例如,尽管PlainMamba[55]、MambaIR[16]和CSMamba[37]等基于SSM的方法实现了连续分割,但它们往往会在一些无关噪声点上产生误报。此外,尽管基于CNN和Transformer的方法在数据集上具有较高的指标和性能以及更快的推理速度,但它们在视频数据上的表现却不尽如人意,通常表现出分割不连续和背景抑制能力差。例如,DTrCNet[48]和CTCrackSeg[44]分割的裂缝表现出明显的不连续性,而Crackmer[46]难以区分裂缝和背景区域。基于上述真实世界部署结果,我们的SCSegamba在裂缝视频数据上以低参数和计算资源生成了高质量的分割结果,使其更适合在资源受限的设备上部署,并在实际生产场景中展现出强大的性能。
