一文速通k8s基础概念原理Kubernetes
大家好,我是此林。
今天我们来从零讲讲 k8s 的核心概念和原理,通俗易懂一遍过。
一、Kubernetes 是什么?
Kubernetes(简称 k8s)是一个容器编排系统,核心任务是:
自动化地部署、扩展和管理容器化的应用。
-
Docker 是在单机上启动和运行容器。
-
Kubernetes 则是在一群机器(集群)上,自动调度和维持容器的运行状态。
二、相关概念(从 Docker 到 Kubernetes 的升级)
| Docker 概念 | 在 Kubernetes 中的对应升级 | 说明 |
|---|---|---|
| 容器(Container) | Pod | Pod 是最小的部署单元,可以包含一个或多个容器 |
| 镜像(Image) | 仍然是镜像 | k8s 依然用 Docker 镜像来运行 Pod |
| docker run | Deployment / Pod 定义文件 | 无需手动 run 容器,而是写 YAML 描述让 k8s 自动管理 |
| docker network | Service / Ingress | 管理容器间通信和外部访问 |
| docker volume | PersistentVolume / PVC | 管理持久存储 |
| docker-compose | Kubernetes manifests(YAML 文件) | 声明式配置,定义整个系统的状态 |
三、Kubernetes 架构图(核心组件)
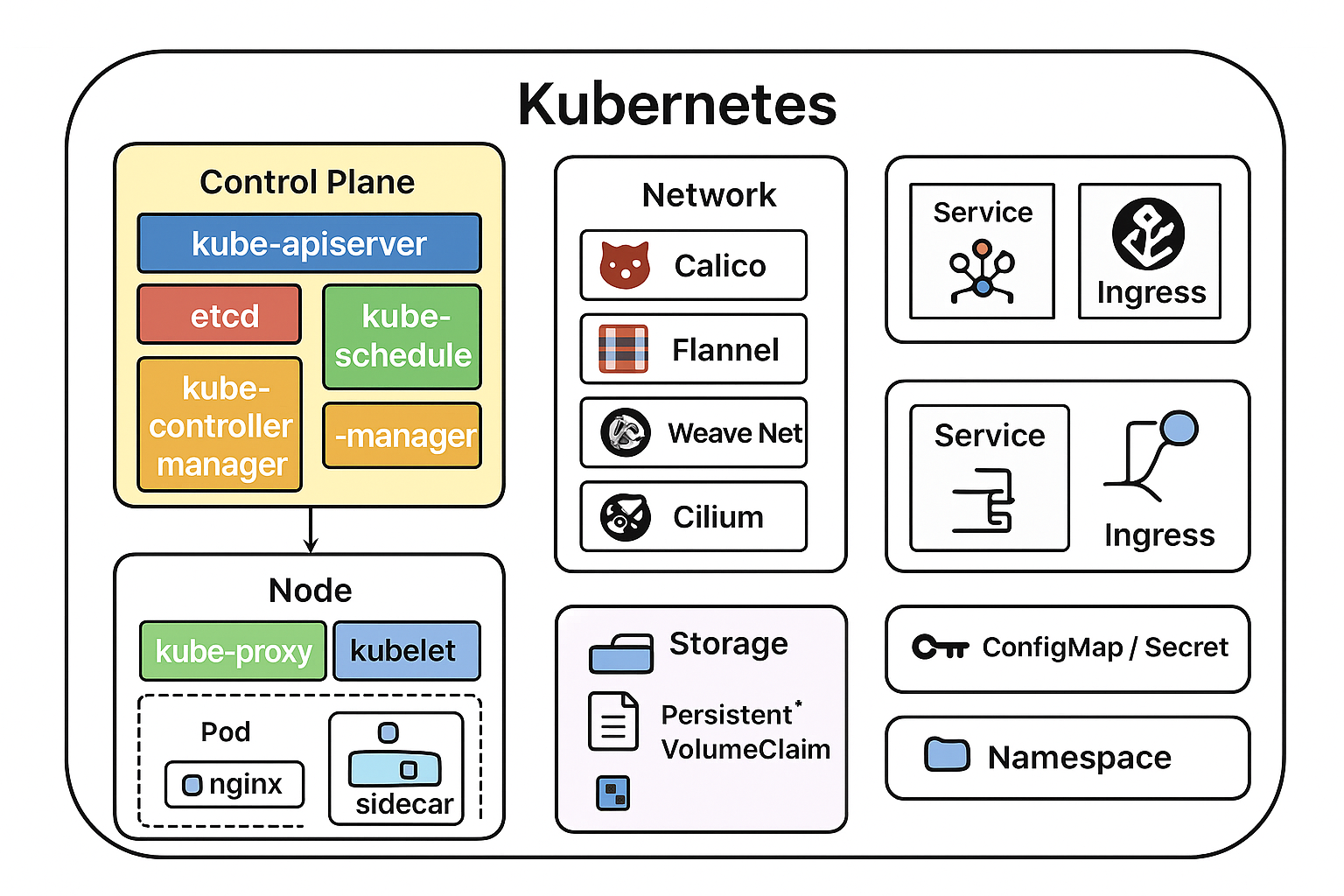
一个典型的 k8s 集群有两类节点:
控制平面(Control Plane)
负责“大脑”层面的决策:
-
kube-apiserver:所有操作的入口(相当于 API 大门)
-
etcd:保存集群状态的数据库
-
kube-scheduler:决定 Pod 放在哪个节点跑
-
kube-controller-manager:负责自动修复(例如重启挂掉的 Pod)
工作节点(Worker Node)
实际运行容器的地方:
-
kubelet:每个节点上的代理,负责和控制平面沟通
-
kube-proxy:处理服务间的网络通信
-
容器运行时(containerd / Docker):执行容器
四、Kubernetes 术语
之前讲述了相关概念从 Docker 到 Kubernetes 的升级,现在正式介绍 k8s 的术语。
| 类型 | 作用 |
|---|---|
| Pod | 最小的可部署单元,运行一个或多个容器 |
| ReplicaSet | 保证指定数量的 Pod 副本一直存在 |
| Deployment | 声明式地管理 Pod(支持滚动更新、回滚) |
| Service | 暴露 Pod 的访问接口(负载均衡) |
| Ingress | 管理 HTTP/HTTPS 流量的路由规则 |
| ConfigMap / Secret | 管理配置数据与敏感信息 |
| Namespace | 逻辑隔离环境(类似项目空间) |
| PersistentVolume / PVC | 管理持久化存储 |
五、核心思想:声明式管理
在 Docker 里,我们通常“命令式”地运行容器:
docker run -d nginx在 Kubernetes 里,我们“声明式”地描述状态:
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploy
spec:replicas: 3selector:matchLabels:app: nginxtemplate:metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:latest
然后执行:
kubectl apply -f nginx.yamlk8s 就会自动保证集群最终符合这个描述(例如:一直保持 3 个 nginx 副本)。
下面我们按这个顺序展开来讲述,k8s的每个具体组件。
1️⃣ Pod 与容器的关系
2️⃣ Deployment 与副本控制
3️⃣ Service 与网络通信
4️⃣ Ingress 与外部访问
5️⃣ 存储(PV / PVC)
6️⃣ Namespace、ConfigMap、Secret
7️⃣ 核心调度与控制器原理
第一部分:Pod 与容器的关系
我们已经知道 Docker 能运行容器,比如:
docker run -d nginx
这会在一台机器上启动一个 nginx 容器。
但在 Kubernetes 里,永远不会直接运行容器。我们运行的是 —— Pod。
1. 什么是 Pod?
Pod 是 Kubernetes 中最小的可部署单元。
你可以理解成:
Pod = “一组共享网络和存储的容器”。
通常情况下,一个 Pod 只包含 一个容器。
但有时多个容器需要共享数据或进程协作时(比如 sidecar 模式),它们就会被放进同一个 Pod。
举例:
apiVersion: v1
kind: Pod
metadata:name: nginx-pod
spec:containers:- name: nginximage: nginx:latestports:- containerPort: 80
这就相当于:
docker run -d -p 80:80 nginx
但区别是:
Kubernetes 负责自动启动、健康检查、重启、迁移这个 Pod。
2. Pod 的三个“共享”
Pod 内的容器共享三个关键环境:
| 共享项 | 含义 |
|---|---|
| 网络命名空间 | 所有容器共用同一个 IP,互相用 localhost 通信 |
| 存储卷(Volumes) | 可以共享文件或持久数据 |
| 生命周期 | Pod 是整体调度、整体重启的 |
这意味着:
-
Pod 内的容器像在同一台机器上协作;
-
但不同 Pod 之间网络隔离(有独立 IP)。
3. Pod 的生命周期(重点)
Pod 有几个关键状态:
| 状态 | 说明 |
|---|---|
| Pending | 还没被调度到节点上 |
| Running | 已调度并且至少有一个容器在运行 |
| Succeeded | 所有容器都正常退出(用于 Job) |
| Failed | 某个容器异常退出 |
| Unknown | 节点通信异常 |
Pod 的生命周期由 kubelet 管理,它会确保:
-
容器挂了会自动重启;
-
节点宕机会迁移到其他节点;
-
你声明的状态和实际状态保持一致。
4. 实际应用场景
| 场景 | 做法 |
|---|---|
| 运行一个简单服务(如 nginx) | 一个 Pod,一个容器 |
| 应用 + 日志收集容器 | 一个 Pod,两容器(sidecar 模式) |
| 应用 + proxy(例如 Envoy) | 也是 sidecar 模式 |
5. 小结
| 概念 | Docker 里 | Kubernetes 里 |
|---|---|---|
| 最小运行单元 | 容器 | Pod |
| 网络范围 | 容器级别 | Pod 级别 |
| 生命周期管理 | 手动操作 | 由控制器自动管理 |
| 调度位置 | 手动启动在哪台机 | 由调度器决定放在哪个节点 |
现在我们来个小练习思考题:
如果一个 Pod 里有两个容器(一个主应用 + 一个日志采集 sidecar),
你觉得它们之间通信时,用什么地址访问?
A. 各自容器的独立 IP
B. Pod 的共享 IP + localhost
C. Kubernetes 分配的 Service IP
正确答案就是 B:Pod 的共享 IP + localhost。
如果你做对了,这说明你已经理解了 Pod 内容器共享网络命名空间 这个关键点。
这也是很多人刚学 k8s 时容易忽略的地方。
我们稍微加深一点理解
为什么 Pod 里的容器能用 localhost 通信?
Kubernetes 在创建 Pod 时,会让其中所有容器共享同一个 网络命名空间。
这意味着:
-
它们看到的
eth0网卡是同一个; -
它们的 IP 地址相同;
-
所以彼此之间就能通过
localhost(127.0.0.1)通信。
例如:
-
容器 A(主程序)监听 8080;
-
容器 B(sidecar)在同一个 Pod 中收集日志;
→ 容器 B 可以直接访问localhost:8080。
过渡一下:为什么 Kubernetes 设计了 “Pod” 这一层?
这个问题很有意思——其实当初 Google 设计 Borg(K8s 的前身)时就发现:
现实中很多服务是由一组紧密协作的进程组成的。
比如:
-
Nginx + sidecar proxy
-
App + 日志收集器
-
App + metrics exporter
如果 Kubernetes 只调度“容器”,就很难保证这些协作组件总是一起运行、一起迁移、一起销毁。
所以它引入了 Pod 这一抽象层,作为“调度和管理的基本单位”。
好,现在我们进入下一章:
第二部分:Deployment 与副本控制(ReplicaSet)
它解决的问题是:
如果我的 Pod 挂了怎么办?我想运行多个副本怎么办?我想滚动更新怎么办?
在进入 Deployment 之前,先问你一个问题来过渡:
假设你用
kubectl apply -f nginx-pod.yaml启动了一个 Pod,
如果这个 Pod 崩溃或节点宕机了,Kubernetes 会自动重新创建它吗?
答案是 会 还是 不会?
其实很多人第一反应也会说“会”,
但这里有个容易混淆的细节 —— 单独创建的 Pod(kind: Pod)实际上不会被自动重建。
原因解释:
当你用:
kubectl apply -f nginx-pod.yaml
直接创建一个 Pod 对象 时,
Kubernetes 只是照你的定义启动一次,
但它不会“守护”这个 Pod 的存在。
如果这个 Pod:
-
容器崩溃 → kubelet 可以重启容器
-
Pod 本身被删除、节点挂掉 → kubelet 不会自动重新创建
所以我们需要一个更强大的控制器来“维持副本数量”,
那就是 ReplicaSet 和它的上层封装 —— Deployment。
第二部分:Deployment 与副本控制
1. Deployment 是什么?
Deployment 是一种“声明式控制器”,
它保证:
指定数量的 Pod 副本始终存在,并支持滚动更新与回滚。
可以理解成:
Deployment = “Pod 的自动驾驶模式”
2. Deployment 的核心结构
apiVersion: apps/v1
kind: Deployment
metadata:name: nginx-deploy
spec:replicas: 3 # 想要几个副本selector:matchLabels:app: nginxtemplate: # Pod 模板(定义 Pod 长什么样)metadata:labels:app: nginxspec:containers:- name: nginximage: nginx:latestports:- containerPort: 80
执行:
kubectl apply -f nginx-deploy.yaml
Kubernetes 会帮你:
-
创建一个 ReplicaSet;
-
ReplicaSet 再创建 3 个 Pod 副本;
-
如果有 Pod 挂了,它会自动补上;
-
更新镜像版本时,会自动滚动更新。
3. Deployment 的核心功能
| 功能 | 说明 |
|---|---|
| 副本数控制(replicas) | 确保运行 N 个 Pod |
| 滚动更新(RollingUpdate) | 平滑更新版本 |
| 回滚(Rollback) | 更新失败可一键回滚 |
| 自愈(Self-healing) | Pod 挂了自动重建 |
| 扩缩容(Scaling) | 一条命令就能调整副本数 |
4. 实际用法举例
# 创建 Deployment
kubectl apply -f nginx-deploy.yaml# 查看 Deployment
kubectl get deploy# 查看 Pod 状态
kubectl get pods# 扩容
kubectl scale deploy nginx-deploy --replicas=5# 滚动更新镜像
kubectl set image deploy/nginx-deploy nginx=nginx:1.25# 回滚
kubectl rollout undo deploy/nginx-deploy
5. 小结对比
| 概念 | 管理单位 | 自动重建 | 支持扩缩容 | 支持更新 |
|---|---|---|---|---|
| Pod | 单个 Pod | ❌ | ❌ | ❌ |
| ReplicaSet | 一组 Pod | ✅ | ✅ | ❌ |
| Deployment | 一组 Pod + 版本控制 | ✅ | ✅ | ✅ |
现在再来一个小思考:
假设 nginx Deployment 有 3 个副本(replicas=3),
其中一个 Pod 挂了。
请问是 Deployment 直接重建 Pod,
还是 ReplicaSet 负责补齐?
你觉得是哪个?
深入一点解释:
Deployment 其实不会直接管理 Pod,
它只是管理一个 ReplicaSet 对象,
而 ReplicaSet 才是那个真正负责“维持副本数量”的控制器。
可以这样理解:
Deployment → 管理 ReplicaSet → 管理 Pod
也就是说:
-
Deployment 关注版本控制(滚动更新、回滚);
-
ReplicaSet 关注数量控制(保持 N 个 Pod);
-
Pod 是实际运行单元(容器所在处)。
举个小例子
当你滚动更新镜像时:
-
Deployment 创建新的 ReplicaSet(新版本的 Pod 模板);
-
逐步增加新 ReplicaSet 的副本数;
-
同时减少旧 ReplicaSet 的副本数;
-
新旧版本完全切换后,旧 ReplicaSet 被保留(用于回滚)。
小结思维图:
[ Deployment ]│├── manages ──> [ ReplicaSet v2 ] → [ Pod v2-1, v2-2, v2-3 ]└── (keeps old) [ ReplicaSet v1 ] → [ Pod v1-1, v1-2, v1-3 ]
到目前为止,我们了解了:
1️⃣ Pod 是最小运行单元
2️⃣ ReplicaSet 维持副本数
3️⃣ Deployment 负责版本管理与更新
下一步,我们要解决另一个现实问题:
“这些 Pod 各自都有独立 IP,那外部或别的服务怎么访问它们呢?”
这就引出了我们的下一章:
第三部分:Service 与网络通信
在我们开始前,先问一个思考题(很重要):
如果一个 Deployment 运行了 3 个 nginx Pod,它们每个都有不同的 IP,
那客户端(比如浏览器)要访问 nginx 时,该怎么选 IP 呢?
Kubernetes 是怎么解决这个问题的?
答案就是 负载均衡。
不过在 Kubernetes 里,它是通过 Service 来实现的,而不仅仅是普通的 LB。
第三部分:Service 与网络通信
1. 为什么需要 Service?
前面说负载均衡是关键原因。
具体问题:
-
Deployment 可能有多个 Pod,每个 Pod IP 是动态的;
-
Pod 崩溃、迁移或扩缩容都会改变 IP;
-
客户端不能直接固定访问 Pod IP。
解决方案:
用一个抽象层 Service,把 Pod 组暴露成一个稳定的访问入口,同时自动负载均衡。
2. Service 类型(最常用三种)
| 类型 | 功能 | 使用场景 |
|---|---|---|
| ClusterIP | 集群内部访问 | 内部微服务调用 |
| NodePort | 集群外部访问,通过节点端口访问 | 小型测试或外部访问 |
| LoadBalancer | 集群外部访问,通过云厂商 LB | 生产环境对外服务 |
| ExternalName | DNS 名称映射 | 访问外部服务 |
3. Service 的核心机制
-
Service 会根据 label selector 选中一组 Pod:
selector:app: nginx
-
给这些 Pod 分配一个 稳定的虚拟 IP(ClusterIP)
-
自动负载均衡请求到 Pod
-
Pod 动态变动(扩缩容、重建)不会影响 Service IP
4. 例子:ClusterIP Service
apiVersion: v1
kind: Service
metadata:name: nginx-svc
spec:selector:app: nginxports:- protocol: TCPport: 80 # Service 对外端口targetPort: 80 # Pod 容器端口type: ClusterIP
访问方式:
kubectl get svc
# 看到 nginx-svc 有一个稳定的 ClusterIP
5. 工作原理(简化图)
客户端│▼
[Service IP] ← kube-proxy 负载均衡│├──> Pod1├──> Pod2└──> Pod3
kube-proxy 会在每个节点上负责把请求分发到后端 Pod。
小结:
-
Service = Pod 的稳定访问入口
-
自动负载均衡,解决 Pod IP 动态变化问题
-
ClusterIP、NodePort、LoadBalancer 三类常用方式
思考题:
如果你有一个 3 副本的 nginx Deployment,客户端访问 Service 的 IP,
请求会每次都打到同一个 Pod 吗?为什么?
答案:
不会,因为kube-proxy做了负载均衡。
解释得再详细一点:
-
为什么不会总打到同一个 Pod?
kube-proxy 会拦截到达 Service IP 的流量,然后按照规则(通常是轮询、随机或 iptables/ipvs 的算法)把请求分发到不同的 Pod。 -
好处:
-
即使某个 Pod 挂掉了,流量会自动分发到剩下的 Pod;
-
客户端完全不用知道 Pod 的具体 IP。
-
拓展知识:Service + DNS
-
Kubernetes 集群内部有一个 CoreDNS 服务
-
每个 Service 会生成一个 DNS 名称,例如:
nginx-svc.default.svc.cluster.local
-
这样 Pod 或客户端就可以直接用名字访问 Service,而不用管 ClusterIP
到这里,我们掌握了:
-
Pod 是最小单元
-
Deployment + ReplicaSet 维持副本和版本
-
Service 提供稳定访问和负载均衡
下一步要讲的,是 Ingress,它解决了:
“当你要用 HTTP/HTTPS 对外提供服务,而不仅仅是 NodePort 或 LoadBalancer,该怎么管理路由和域名?”
好,那我们接着讲 第四部分:Ingress 与外部访问,把 HTTP/HTTPS 暴露和路由管理讲清楚。
第四部分:Ingress
1. 为什么需要 Ingress?
你的集群里有多个服务:
-
nginx、api-server、webapp 等,每个都用 Service 暴露
-
如果用 NodePort,每个服务都要暴露一个不同端口 → 不方便
-
用 LoadBalancer,每个服务都要创建一个 LB → 成本高
解决方案:
Ingress 提供一个统一入口,通过 域名 + 路径 把请求路由到不同的 Service
2. Ingress 的核心概念
| 概念 | 作用 |
|---|---|
| Ingress Resource | 定义路由规则(域名、路径、TLS) |
| Ingress Controller | 真正实现路由功能的组件(如 Nginx Ingress Controller、Traefik) |
注意:Ingress 本身只是规则,不会直接处理流量,必须配合 Controller 才能生效。
3. Ingress 例子
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:name: example-ingress
spec:rules:- host: myapp.example.comhttp:paths:- path: /nginxpathType: Prefixbackend:service:name: nginx-svcport:number: 80- path: /apipathType: Prefixbackend:service:name: api-svcport:number: 8080
解释:
-
域名
myapp.example.com -
/nginx→ 路由到nginx-svc -
/api→ 路由到api-svc
4. Ingress 的高级功能
-
TLS/HTTPS:可以直接在 Ingress 上配置证书
-
虚拟主机:同一个 IP 支持多个域名
-
路径路由:不同路径访问不同服务
-
负载均衡:Controller 内部实现 LB,把请求分发到 Pod
5. 总结
-
Service = Pod 的稳定访问 + 内部/节点负载均衡
-
Ingress = Service 的对外 HTTP/HTTPS 路由 + 域名管理
-
现实应用场景:多个微服务共享一个公网 IP,用域名和路径区分
思考题:
如果有两个服务,一个 web,一个 api,想用同一个域名(myapp.com)访问:
web ->
/api ->
/api
那该用 Service 还是 Ingress?为什么?
答案:
ingress。Service是对pod做负载均衡吗?ingress才对Service做负载均衡。
来稍微梳理一下逻辑,让它更清楚:
理解层次
-
Pod → 容器运行的最小单元
-
Service → 给 Pod 组一个稳定入口,同时在 Pod 间做 负载均衡
-
Ingress → 给 Service 提供外部访问入口,同时根据 域名/路径做路由
-
Ingress 内部也会做负载均衡,把流量分发到对应的 Service
-
Service 再把请求分发到 Pod
-
所以整个链路可以理解为:
客户端请求│▼
[Ingress] --> 根据域名/路径路由到不同 Service│▼
[Service] --> 负载均衡到后端 Pod│▼
[Pod] --> 实际容器处理请求
拓展知识点
-
一个 Ingress 可以管理 多个 Service
-
Ingress Controller 可以支持:
-
SSL/TLS 终端
-
路径重写
-
访问控制
-
-
Service 依旧是 Pod 的“内部负载均衡器”,Ingress 只管把外部请求安全、统一、智能地导到 Service
到这里,我们已经覆盖了:
1️⃣ Pod
2️⃣ ReplicaSet + Deployment
3️⃣ Service
4️⃣ Ingress
下一步,我们讲 存储(PersistentVolume + PersistentVolumeClaim),
它解决了容器/Pod 的 数据持久化问题。
好,那我们接着讲 第五部分:存储(PersistentVolume / PersistentVolumeClaim),这是 Kubernetes 非常重要的一块,因为容器默认是无状态的。
第五部分:存储
1. 为什么需要 PersistentVolume?
容器的文件系统是临时的:
-
Pod 挂了,容器删除 → 容器里的数据也会消失
-
对于数据库、日志等需要持久化的数据,这显然不够
Kubernetes 提供了 PersistentVolume(PV) 和 PersistentVolumeClaim(PVC) 来解决这个问题:
-
PersistentVolume (PV):管理员提供的存储资源(类似物理卷/云盘)
-
PersistentVolumeClaim (PVC):开发者申请的存储请求(类似挂载卷的申请单)
核心思想:声明式存储管理
PV 是“库存”
PVC 是“订单”,匹配库存
2. 核心流程
-
管理员创建 PV(定义存储容量、访问模式、类型)
-
用户创建 PVC(声明自己需要多少存储和访问模式)
-
Kubernetes 自动把 PVC 和符合条件的 PV 绑定
-
Pod 可以通过 PVC 挂载到容器中使用
3. 访问模式
| 模式 | 说明 |
|---|---|
| ReadWriteOnce (RWO) | 单节点读写 |
| ReadOnlyMany (ROX) | 多节点只读 |
| ReadWriteMany (RWX) | 多节点读写(需要支持的存储) |
4. 示例
PV 定义
apiVersion: v1
kind: PersistentVolume
metadata:name: pv-example
spec:capacity:storage: 5GiaccessModes:- ReadWriteOncehostPath:path: "/mnt/data" # 测试环境使用本地目录
PVC 申请
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: pvc-example
spec:accessModes:- ReadWriteOnceresources:requests:storage: 2Gi
Pod 使用 PVC
apiVersion: v1
kind: Pod
metadata:name: nginx-pv-pod
spec:containers:- name: nginximage: nginxvolumeMounts:- mountPath: "/usr/share/nginx/html"name: nginx-storagevolumes:- name: nginx-storagepersistentVolumeClaim:claimName: pvc-example
5. 小结
-
Pod 默认是无状态的 → 数据会丢
-
PV:集群提供的存储
-
PVC:Pod 挂载存储的请求
-
Pod 通过 PVC 挂载到 PV,实现数据持久化
思考题:
如果你有一个 MySQL Pod,需要持久化数据库数据,
你应该直接在 Pod 的容器里写数据,还是用 PVC 挂载 PV?为什么?
答案:
pvc挂载pv,因为pod无状态,重启后数据会丢失。
-
Pod 自身是无状态的,重启或迁移后容器文件系统会丢失。
-
用 PVC 挂载 PV,Pod 可以访问集群提供的持久存储:
-
重启、迁移甚至删除 Pod 都不会丢失数据
-
数据与 Pod 生命周期解耦
-
补充一点:
-
PV 可以来自多种后端:本地磁盘、NFS、云盘(AWS EBS、GCP PD、阿里云盘等)
-
PVC 让开发者不用关心底层存储,只要声明“我需要 5G 空间、可读写”,Kubernetes 会帮你绑定
到这里,我们已经讲完了 Kubernetes 核心的Pod → Deployment → Service → Ingress → PV/PVC 五大模块。
剩下两个必须了解的概念:
1️⃣ Namespace(逻辑隔离,多项目管理)
2️⃣ ConfigMap / Secret(配置管理 + 密钥管理)
好的,我们继续讲 第六部分:Namespace 与 ConfigMap / Secret,这是 Kubernetes 管理和配置的两大重要机制。
第六部分:Namespace(命名空间)
1. 为什么需要 Namespace?
在一个 Kubernetes 集群中,可能有很多团队、项目和环境(开发、测试、生产)在共享同一个集群。
如果没有隔离:
-
Pod 名称、Service 名称可能冲突
-
权限和资源管理混乱
Namespace 提供了逻辑隔离,让同一集群里的不同团队或环境互不干扰。
2. 核心特点
| 特点 | 说明 |
|---|---|
| 资源隔离 | Pod、Service、Deployment 等对象都属于某个 Namespace |
| 名称空间 | 同名对象在不同 Namespace 可以共存 |
| 权限控制 | 可以结合 RBAC 对不同 Namespace 分配不同权限 |
3. 示例
创建 Namespace:
apiVersion: v1
kind: Namespace
metadata:name: dev
创建 Pod 在 dev Namespace:
kubectl apply -f nginx-pod.yaml -n dev
查看 Namespace:
kubectl get ns
默认 Namespace 是
default,不指定的话对象都在 default 下。
ConfigMap 与 Secret(配置与密钥管理)
1. ConfigMap
ConfigMap 用于存储非敏感配置数据(比如 URL、端口号、环境变量),方便 Pod 配置化、解耦。
示例:
apiVersion: v1
kind: ConfigMap
metadata:name: app-config
data:APP_MODE: "dev"LOG_LEVEL: "debug"
Pod 使用 ConfigMap:
envFrom:- configMapRef:name: app-config
2. Secret
Secret 用于存储敏感信息(密码、Token、证书),默认以 base64 编码,保证不直接明文暴露。
示例:
apiVersion: v1
kind: Secret
metadata:name: db-secret
type: Opaque
data:DB_USER: bXlzcWw= # base64 编码后的 "mysql"DB_PASS: cGFzc3dvcmQ= # base64 编码后的 "password"
Pod 使用 Secret:
envFrom:- secretRef:name: db-secret
3. 小结
-
Namespace → 逻辑隔离,资源和权限管理
-
ConfigMap → 存储非敏感配置,灵活注入 Pod
-
Secret → 存储敏感信息,安全注入 Pod
思考题:
你有一个生产环境和开发环境都在同一个集群里,
你应该把 Deployment 和 Service 放在同一个 Namespace,还是不同 Namespace?为什么?
答案:
不同namespace,方便隔离切换。
原因总结一下:
-
不同 Namespace 可以实现环境隔离:
-
资源隔离:生产和开发的 Pod、Service 名称可以相同但不会冲突
-
权限隔离:可以给开发 Namespace 分配更低权限,生产 Namespace 更严格
-
方便管理和切换:比如
kubectl get pods -n devvskubectl get pods -n prod
-
这也是大公司多环境共用一个集群的标准做法。
到这里,我们已经系统讲完了 Kubernetes 核心概念的 六大模块:
1️⃣ Pod
2️⃣ Deployment / ReplicaSet
3️⃣ Service
4️⃣ Ingress
5️⃣ PersistentVolume / PersistentVolumeClaim
6️⃣ Namespace / ConfigMap / Secret
相信你已经对 k8s 有了宏观上的理解。
下面我们重新系统梳理 Kubernetes 想要完整运行起来需要的全部组件和依赖。
一、集群架构核心组件
1. 控制平面(Control Plane)
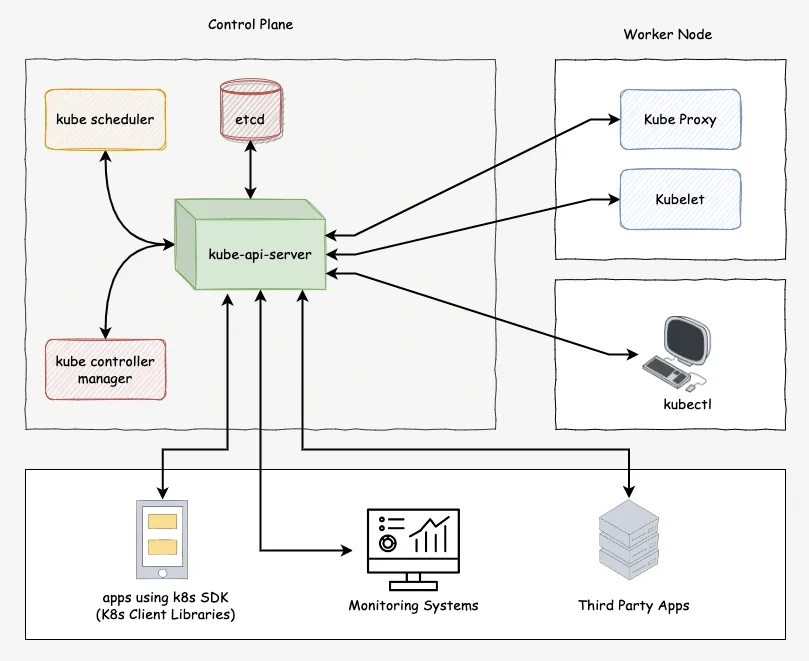
负责管理整个集群状态,是“大脑”层:
| 组件 | 作用 |
|---|---|
| kube-apiserver | 所有操作入口,接收 kubectl 或 API 请求 |
| etcd | 分布式 key-value 数据库,保存集群所有状态 |
| kube-scheduler | 根据调度策略决定 Pod 放哪台节点 |
| kube-controller-manager | 执行各种控制器逻辑,如 Deployment、ReplicaSet、自愈等 |
| cloud-controller-manager | 云环境专用组件,管理云资源(如负载均衡、节点) |
2. 工作节点(Worker Node)
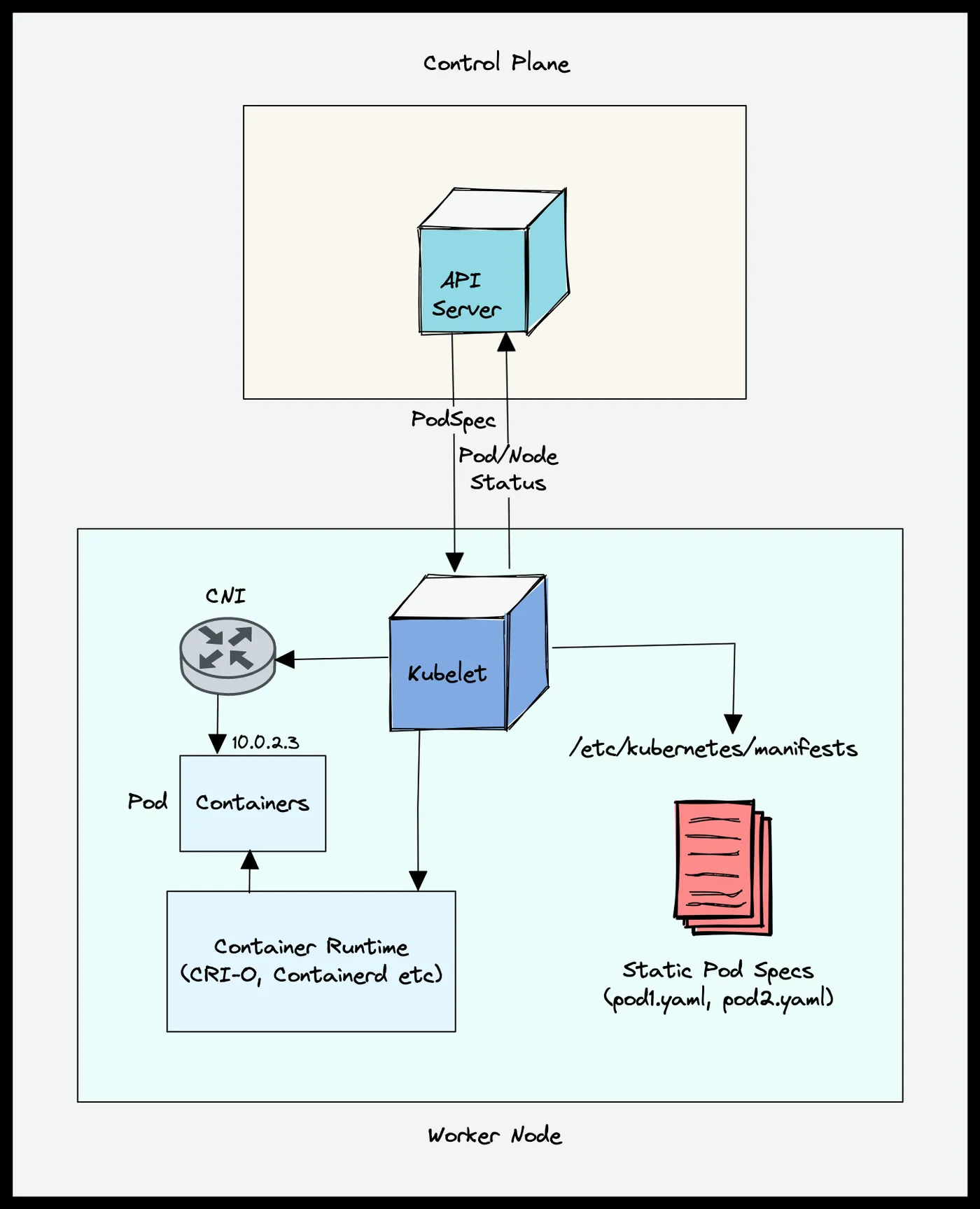
负责实际运行容器,是“执行层”:
| 组件 | 作用 |
|---|---|
| kubelet | 节点代理,确保 Pod 正常运行,向 API server 汇报状态 |
| kube-proxy | 管理 Pod 的网络流量,实现 Service 的负载均衡 |
| 容器运行时 | 实际启动容器(Docker / containerd / CRI-O 等) |
二、网络与通信
1. CNI 插件(Container Network Interface)
负责 Pod 网络互联、IP 分配、跨节点通信:
| 插件 | 功能 |
|---|---|
| Calico | Pod 网络、网络策略、BGP 路由、大规模集群 |
| Flannel | 简单跨节点 Pod 网络,VXLAN 封装 |
| Weave Net | 跨节点网络,支持加密和网络策略 |
| Cilium | 高性能 BPF 网络策略和负载均衡 |
2. Service & Ingress
-
Service:Pod 的稳定访问入口 + 内部负载均衡
-
Ingress + Ingress Controller:HTTP/HTTPS 对外统一访问 + 路由管理 + TLS
三、存储
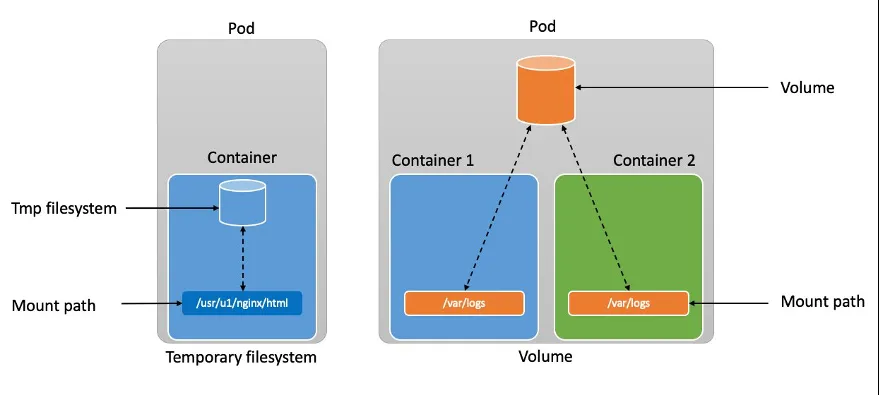
1. PersistentVolume (PV)
管理员提供的集群级存储资源,可以是本地磁盘、NFS、云盘等。
2. PersistentVolumeClaim (PVC)
Pod 用来挂载 PV 的声明,申请指定容量和访问模式。
3. 存储类型示例
-
Local PV(节点本地磁盘)
-
NFS / GlusterFS / Ceph
-
云盘:AWS EBS / GCP PD / 阿里云盘
四、配置与密钥管理
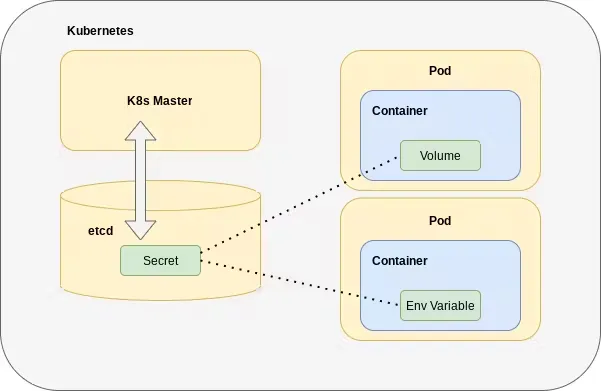
| 类型 | 用途 |
|---|---|
| ConfigMap | 存储非敏感配置,注入 Pod 环境变量或挂载文件 |
| Secret | 存储敏感信息(密码、证书、Token),安全注入 Pod |
五、命名空间与资源隔离
-
Namespace:逻辑隔离,多团队/多环境管理
-
支持 RBAC 权限控制,方便不同环境和项目共享集群
六、集群外依赖(可选但常用)
| 类型 | 用途 |
|---|---|
| DNS(CoreDNS) | Pod 内部域名解析,Service 名称解析 |
| Metrics Server | 采集资源使用情况,用于 HPA 自动扩缩容 |
| Dashboard / UI | 可视化管理集群(非必须) |
| 日志收集 | Fluentd / Loki / ElasticSearch 等 |
| 监控 | Prometheus / Grafana,用于性能和告警 |
| 云负载均衡 | 配合 Service/Ingress 提供公网访问 |
七、Pod 级别组件
| 类型 | 用途 |
|---|---|
| 容器 | 运行实际应用程序 |
| Sidecar | 辅助容器,如日志收集、代理、metrics |
| Init Container | Pod 启动前的初始化任务 |
八、安全与策略
| 类型 | 作用 |
|---|---|
| NetworkPolicy | Pod 访问控制,防火墙级别策略 |
| RBAC | 用户/服务账户权限管理 |
| PodSecurityPolicy(已弃用,可用 OPA Gatekeeper) | Pod 安全策略(容器运行权限) |
| TLS / Secret | 加密和证书管理 |
九、控制器和自愈机制
-
Deployment → 管理 ReplicaSet → 管理 Pod
-
StatefulSet → 管理有状态 Pod(数据库)
-
DaemonSet → 在每个节点运行特定 Pod(如日志收集、监控 agent)
-
Job / CronJob → 执行一次性或定时任务
-
Horizontal Pod Autoscaler (HPA) → 根据指标自动扩缩容
十、总结
要完整运行一个 Kubernetes 集群,需要:
-
控制平面(API Server、etcd、Scheduler、Controller Manager)
-
工作节点(kubelet、kube-proxy、容器运行时)
-
网络(CNI 插件,如 Calico)
-
服务访问(Service + Ingress + Ingress Controller)
-
存储(PV + PVC)
-
配置与密钥管理(ConfigMap + Secret)
-
逻辑隔离与权限(Namespace + RBAC + NetworkPolicy)
-
辅助服务(DNS、Metrics、监控、日志收集)
-
Pod 级别辅助容器(Sidecar、Init Container)
-
控制器与自愈机制(Deployment、StatefulSet、DaemonSet、HPA、Job/CronJob)
如果这些组件全部就位,Kubernetes 就可以完整、稳定、高可用地运行,并管理成百上千个容器化应用。