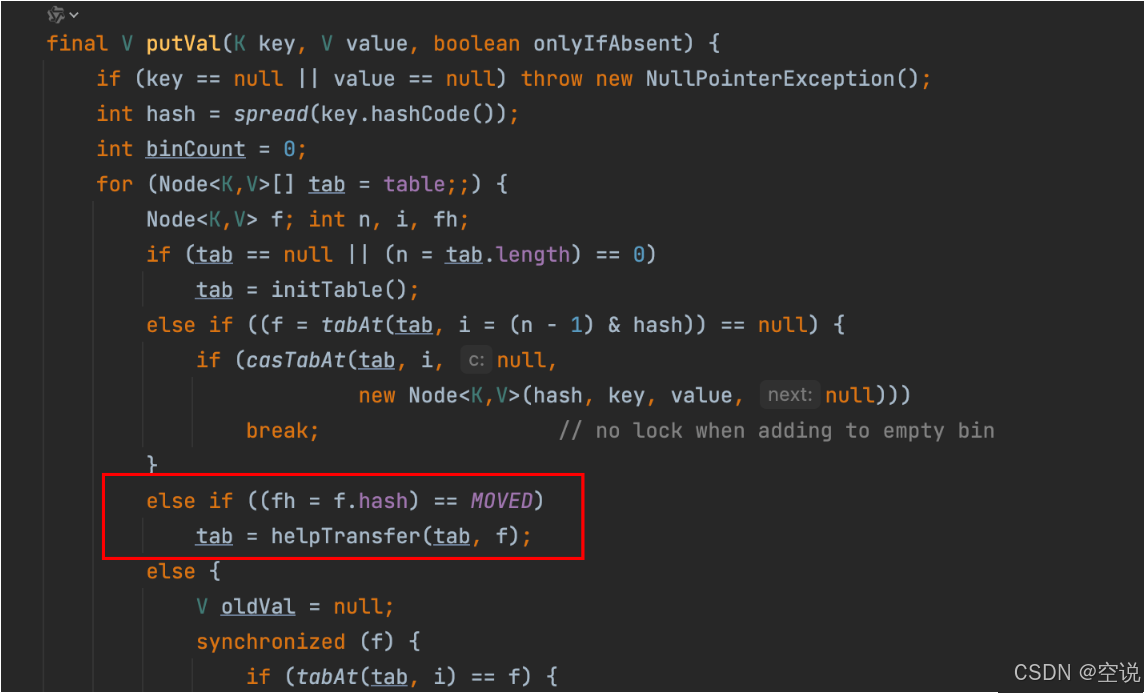
ConcurrentHashMap实现原理
主要可以分为1.7和1.8两个版本 实现
ConcurrentHashMap 1.7
在 JDK 1.7 中它底层是数组+链表的形式,一个ConcurrentHashMap里包含一个固定大小的Segment[]数组,默认大小是16,数组内又存了一些 HashEntry数组,而个 HashEntry 内部是一个链表结构的元素,其实就相当于分配了一些segment,每个segment里面存了一个hashmap
Segment是一种分段锁,继承自ReentrantLock可重入锁,所以每个Segment自身具备加锁的功能,HashEntry则用于存储键值对数据。
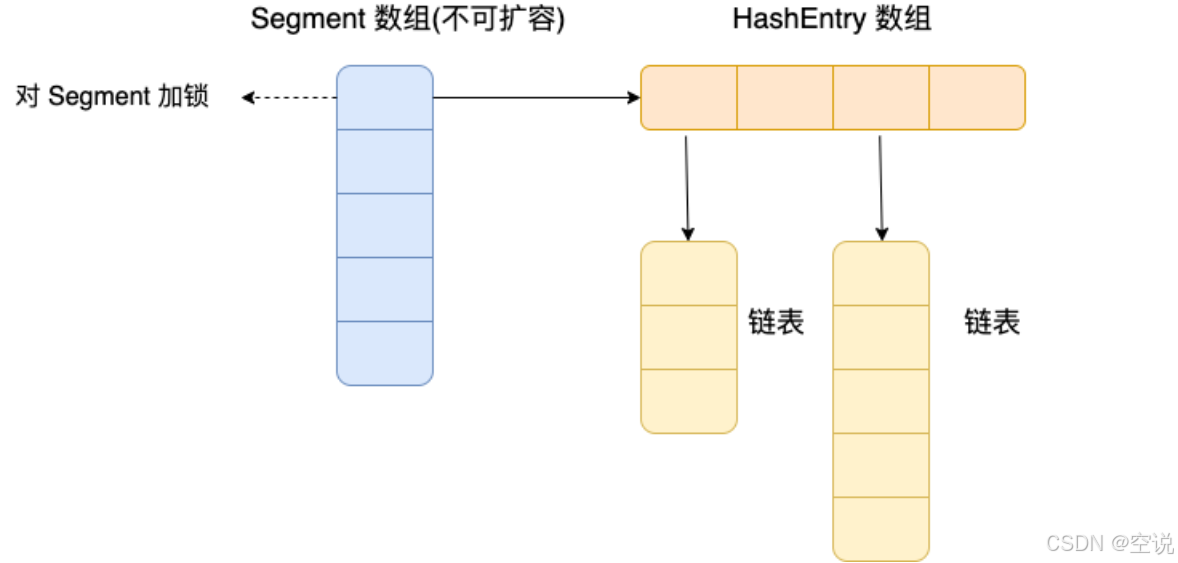
大体的实现跟HashMap没有本质的区别,原理就是:
先通过key的hash值采用特定的算法来得到Segment数组的下标==>将这个 Segment 上锁==>然后通过key的hash&(数组大小-1)得到Segment里HashEntry数组的下标
这里的步骤就和HashMap一样了
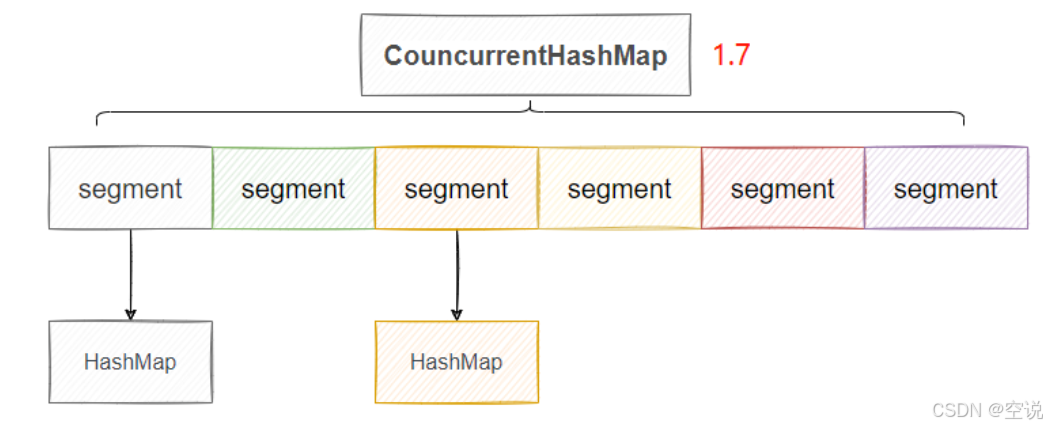
-
可以看到,图上我们有6个 Segment,那么等于有六把锁,因此共可以有六个线程同时操作这个ConcurrentHashMap,并发度就是6
-
相比于直接将 put方法上锁,并发度就提高了,这就是分段锁。
小结
-
1.7的分段锁已经有了细化锁粒度的概念
-
但它的一个缺陷是
Segment数组一旦初始化了之后不会扩容,只有 HashEntry 数组会扩容 -
这就导致并发度过于死板,不能随着数据的增加而提高并发度。
ConcurrentHashMap 1.8
1.8 有更细粒度的锁控制,底层就是Node 数组 + 链表 / 红黑树,我的理解是 1.8 就是舍弃了 Segment,然后把 HashMap 数组的每个结点都加了锁,这样扩容了锁也会变多,并发度也会增加
其次 1.8 也不借助ReentrantLock了,直接用synchronized
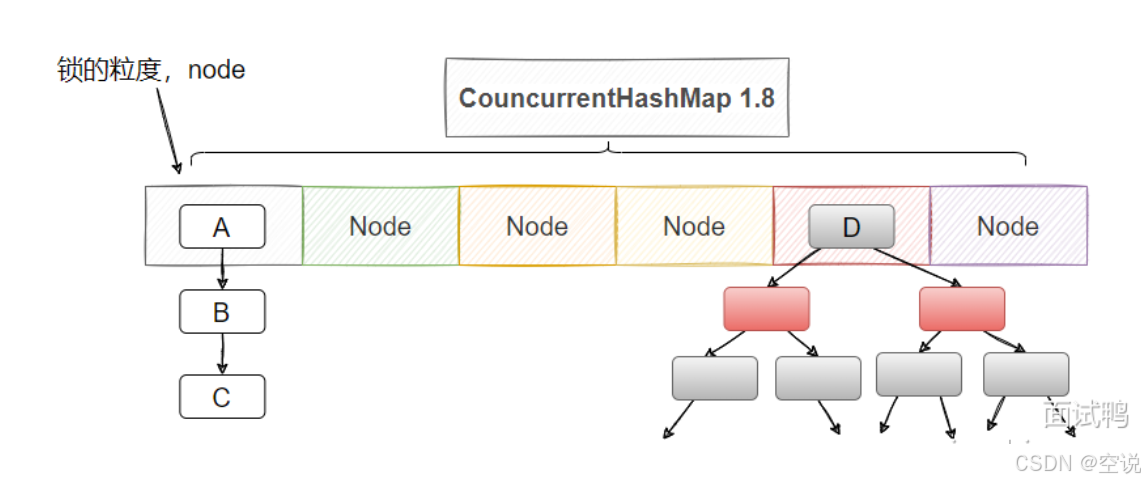
具体实现思路也简单 :
当塞入一个值的时候,先计算 key 的 hash值以及映射后的下标
-
如果计算到的下标还未有结点,那么就通过
CAS塞入新的 Node。 -
如果已经有结点 则通过
synchronized将这个 node 上锁,这样别的线程就无法访问这个 node 及其之后的所有节点。 -
然后判断 key 是否相等,相等则替换 value ,反之则是新增一个 node,这个和 HashMap 是操作一样
已经用了synchronized,为什么还要用CAS呢
主要是一种权衡的考虑
-
使用CAS:插入新元素,若计算出的哈希槽为空时,可以直接使用CAS操作来设置值。这种方式避免了加锁带来的开销,提高了并发性能。
-
使用synchronized:若计算出的哈希槽不为空时,说明发生了哈希碰撞,使用
synchronized能够保证只有一个线程可以修改共享资源。而如果继续用CAS可能会导致大量的重试操作,增加系统负担,
ConcurrentHashMap用了悲观锁还是乐观锁?
-
悲观锁假设冲突是常态,因此在任何时候访问数据时都会先获取锁
-
乐观锁则假设冲突是例外情况,因此不会在读取数据时加锁。
悲观锁和乐观锁都有用到。
添加元素时首先会判断容器是否为空:
-
如果为空则 使用
volatile加 CAS (乐观锁) 来初始化。 -
如果容器不为空,则根据存储的元素计算该位置是否为空。
-
如果根据存储的元素计算结果为空,则利用 CAS(乐观锁) 设置该节点;
-
如果根据存储的元素计算结果不为空,则使用 synchronized(悲观锁)
-
-
然后,遍历桶中的数据,并替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
其次1.8 添加了
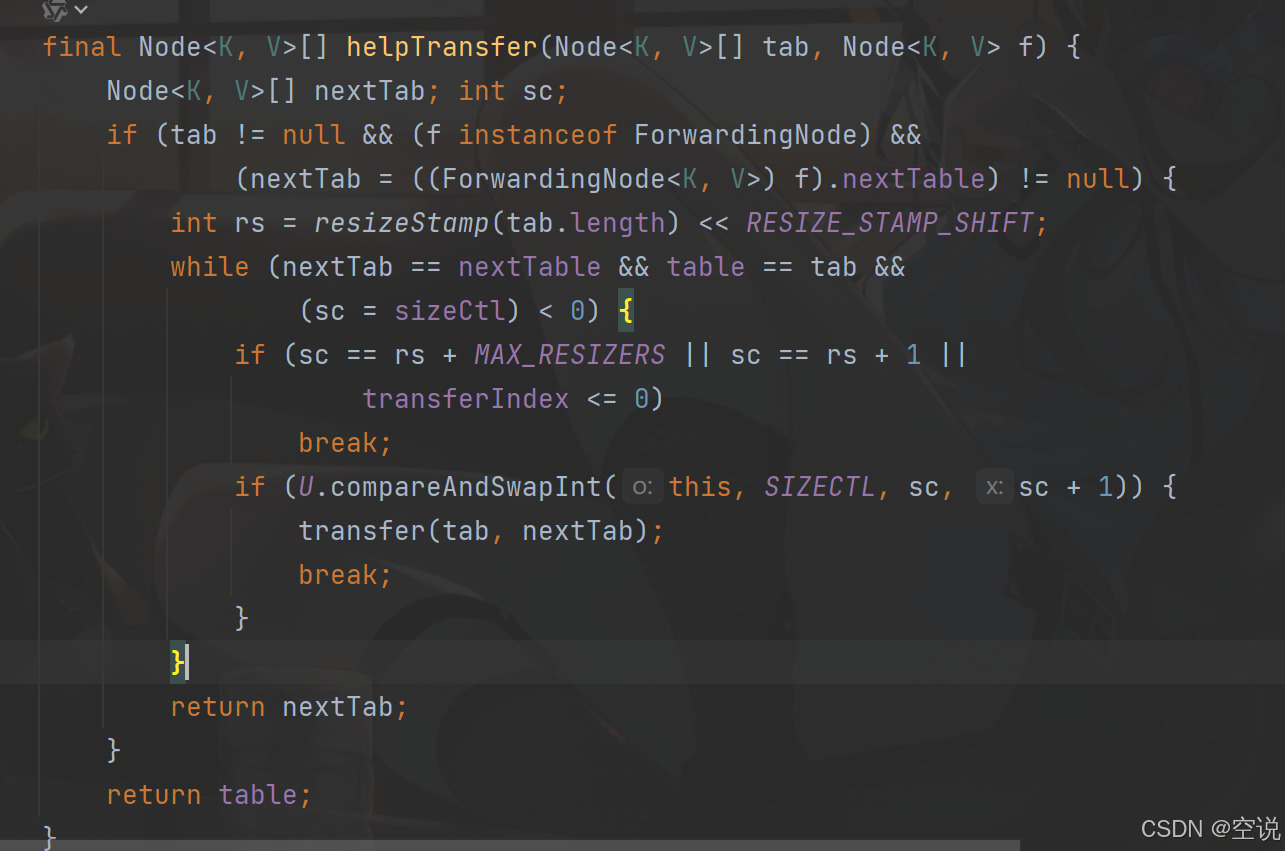
协助扩容,也就是多线程扩容
-
触发扩容:当插入新元素导致超过数组
元素大小*负载因子阈值时,会优先触发扩容操作。 -
ConcurrentHashMap扩容过程中,会创建一个新数组,容量是原数组的两倍。但它不会一次性迁移整个旧表,而是将扩容任务分成多个小段,每次迁移一部分桶(bucket)。 -
多个线程可以同时参与扩容操作。每个线程负责一段桶的迁移,迁移完成后更新迁移进度,其他线程可以继续处理剩余未迁移的部分
-
具体就是
ConcurrentHashMap通过使用一个transferIndex变量来记录当前迁移的进度。初始化为旧数组长度 -
每个线程在扩容时会尝试
CAS抢占transferIndex中的一段桶范围,执行数据迁移并更新transferlndex,其他线程同理 抢占transferIndex获取一部分桶范围